
Cooperative Decisions of a Multi-Agent System for the Target-Pursuit Problem in Manned–Unmanned Environment

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- A novel formulation of the differential game as a target-pursuit strategy in a manned–unmanned environment that can be applied in various manned–unmanned cooperative systems.
- We propose a hierarchical decision-making approach for target-pursuit scenarios. The proposed method can enable the multi-agent system to cooperate with the manned platforms in a reasonable manner, ultimately achieving team cohesion while capturing the target. Furthermore, we discuss scenarios where the target is in different forms of motion. The method proposed in this paper can be applied to the static target, the target moving along fixed trajectories, and it can be extended to situations where the target adopts escape strategies.
- Simulations prove that the proposed method can pursue the target in a manned–unmanned environment successfully. And the effects of each parameter are analyzed through comparative simulations.
2. Problem Formulation
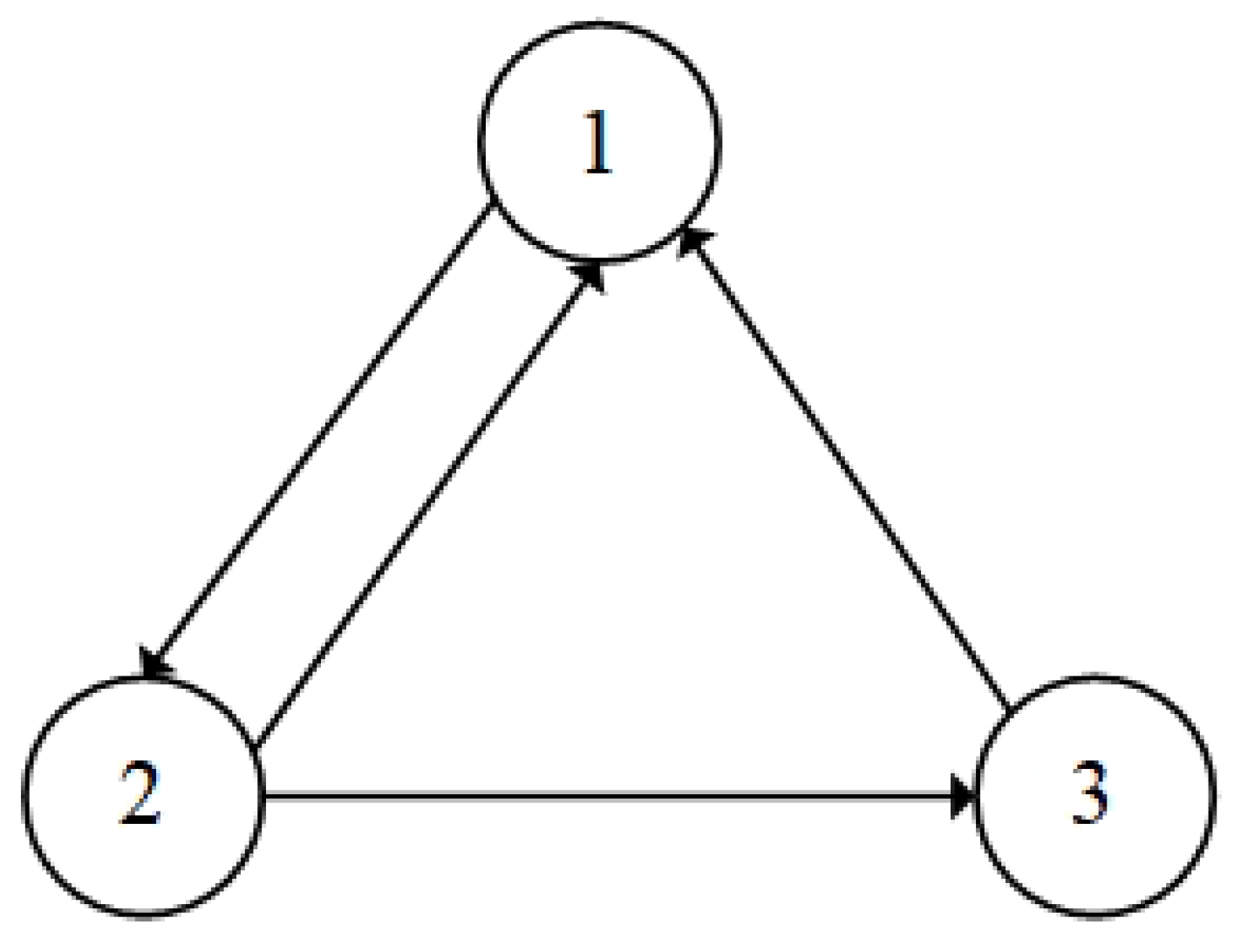
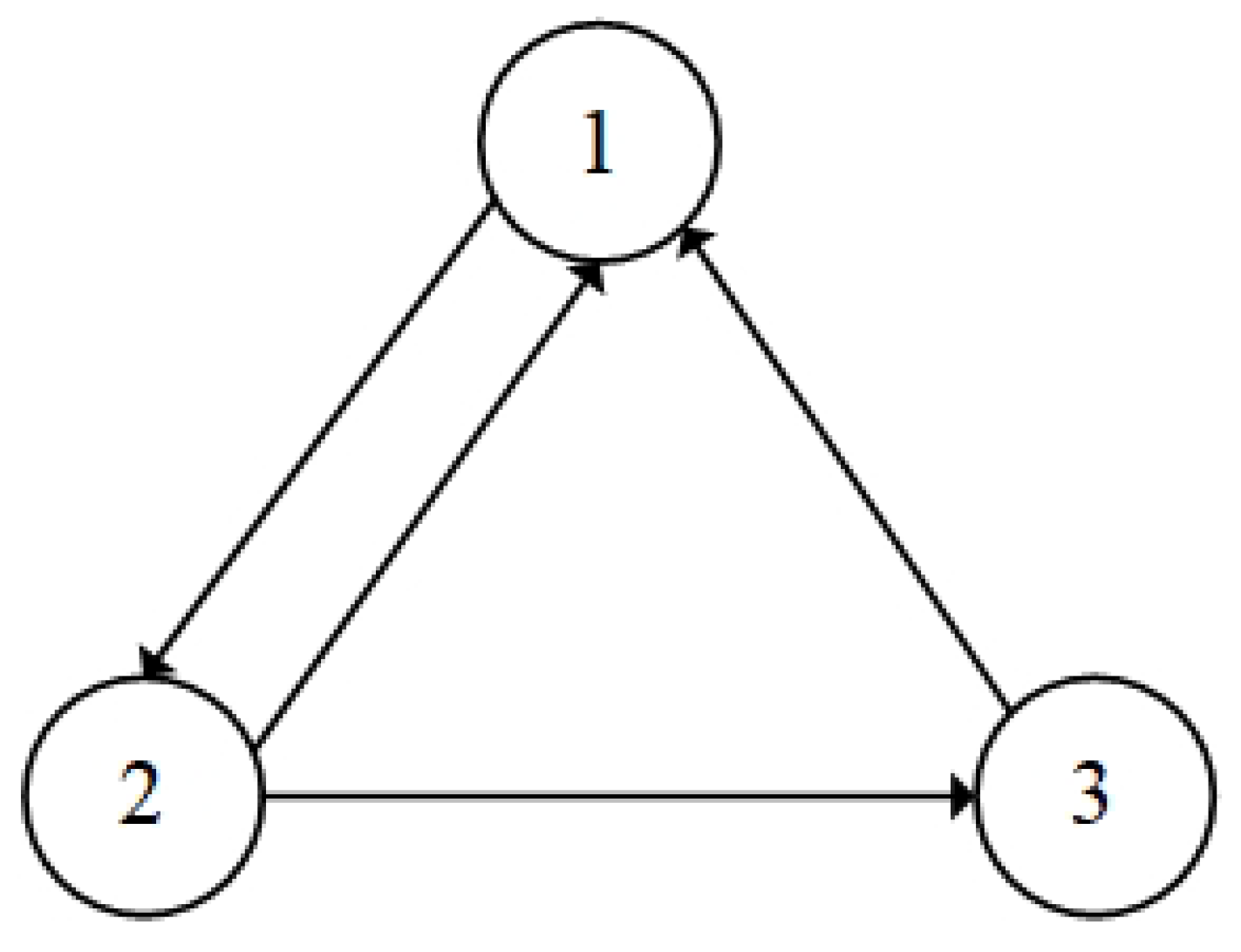
2.1. Communication Graph
2.2. Game Model of Target-Pursuit Problem
3. Results
3.1. Solution to the Target-Pursuit Problem
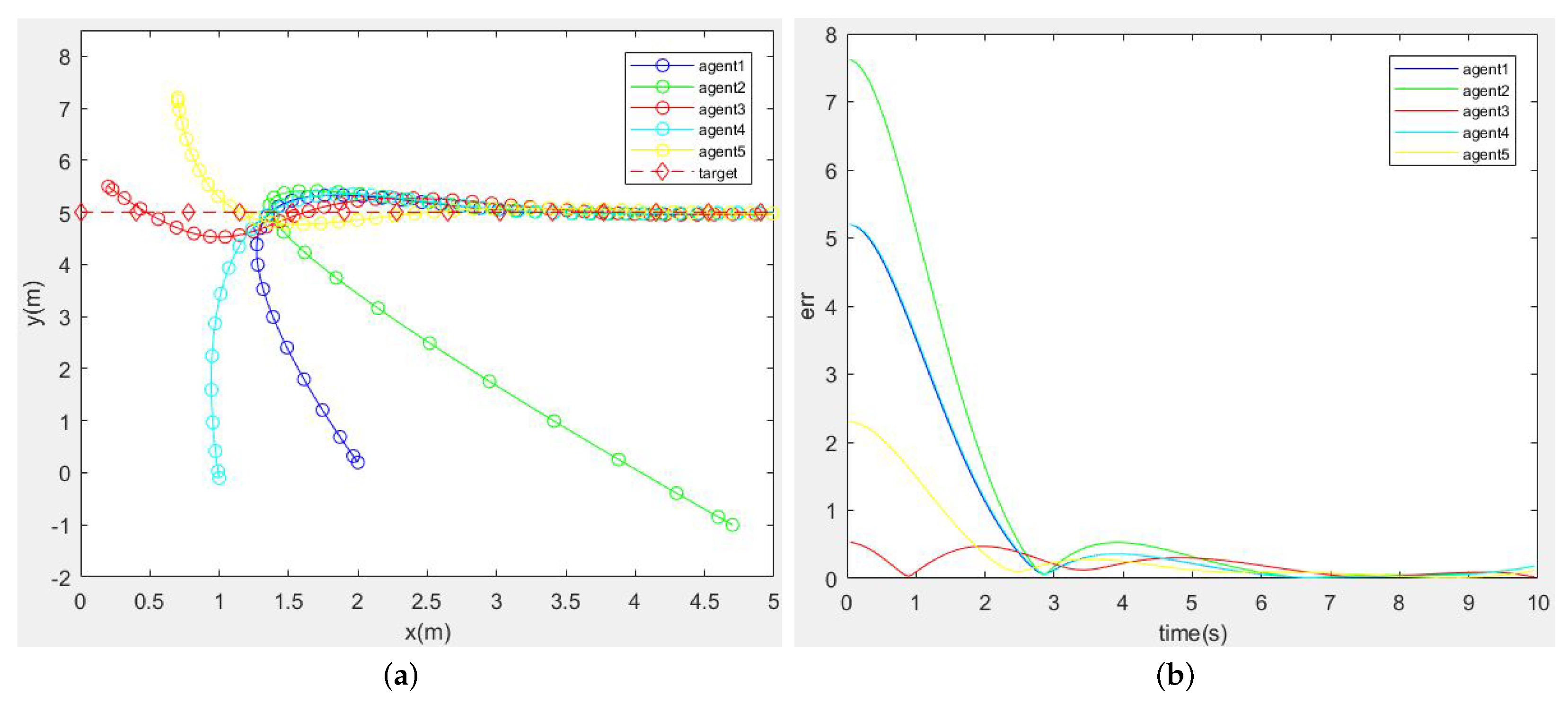
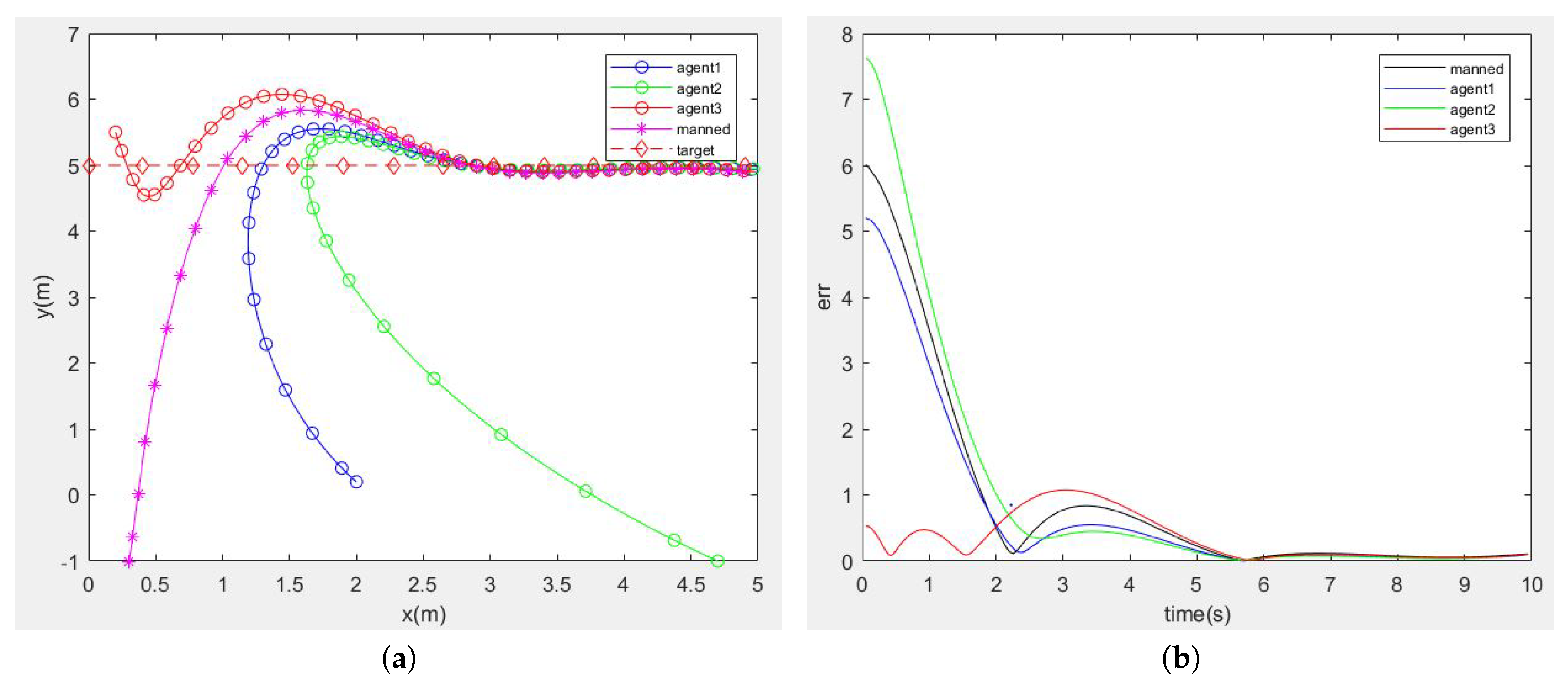
3.2. Simulation
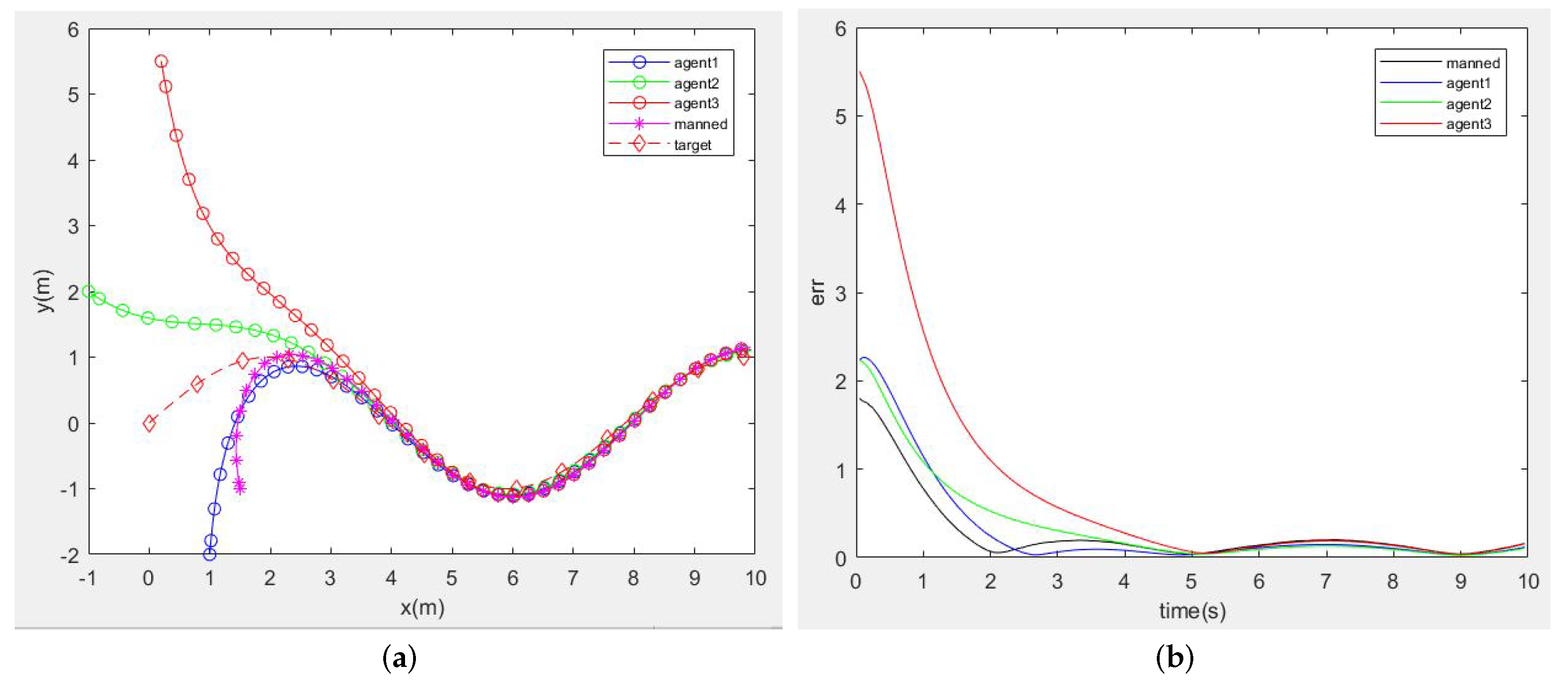
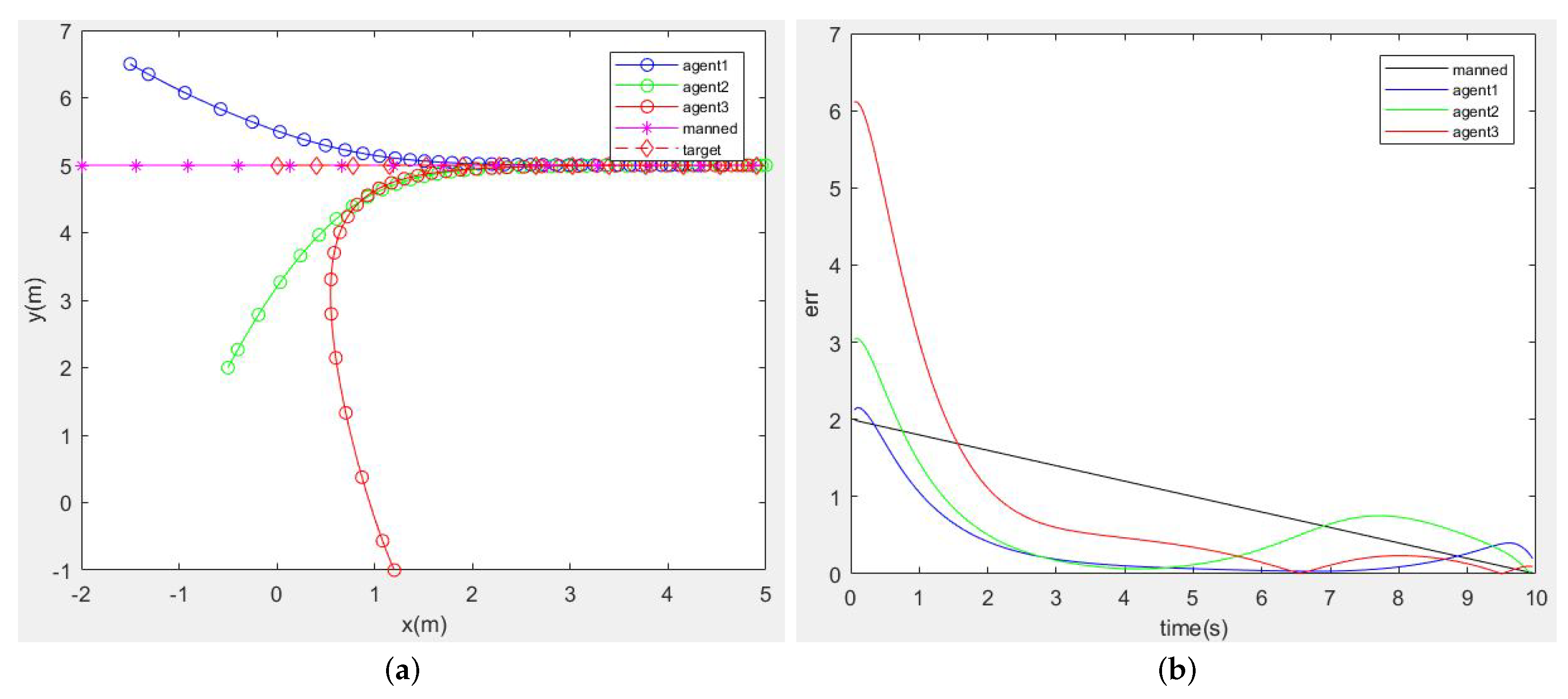
3.2.1. Simulations under Different Target Trajectories
- (1)
- A Target Moving along a Fixed Trajectory
- (2)
- Stationary Target
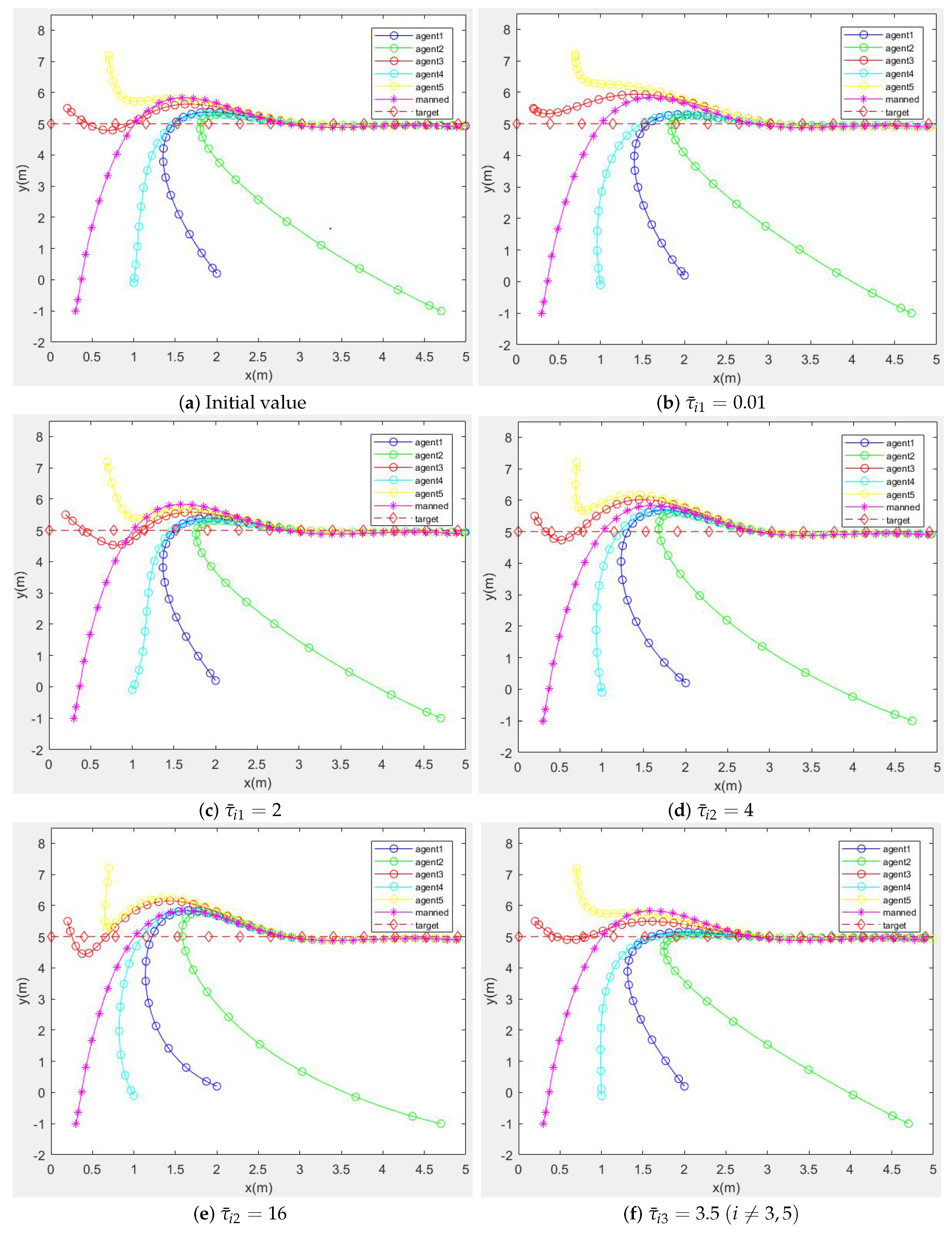
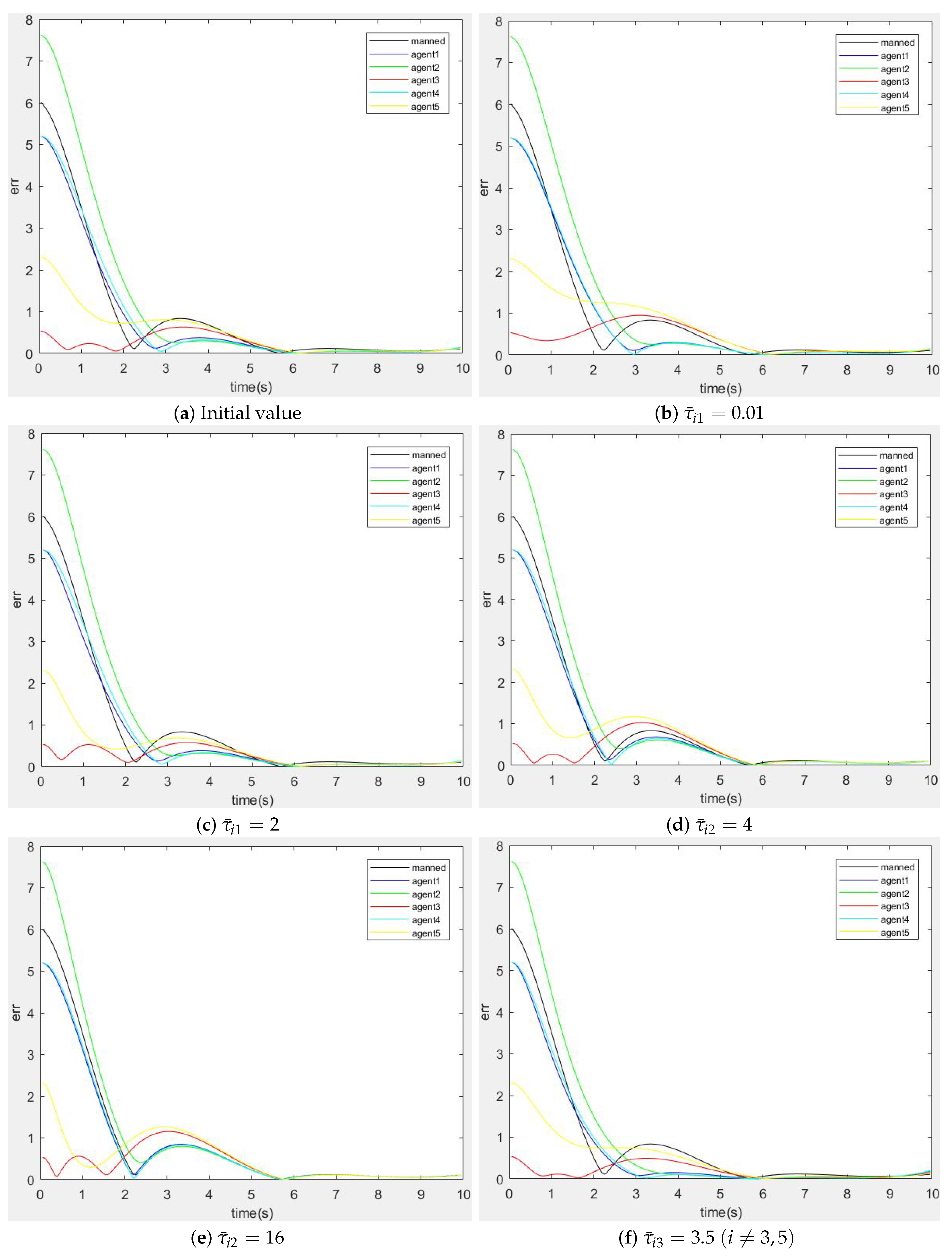
3.2.2. The Influence of Different Weight Coefficients on Strategies
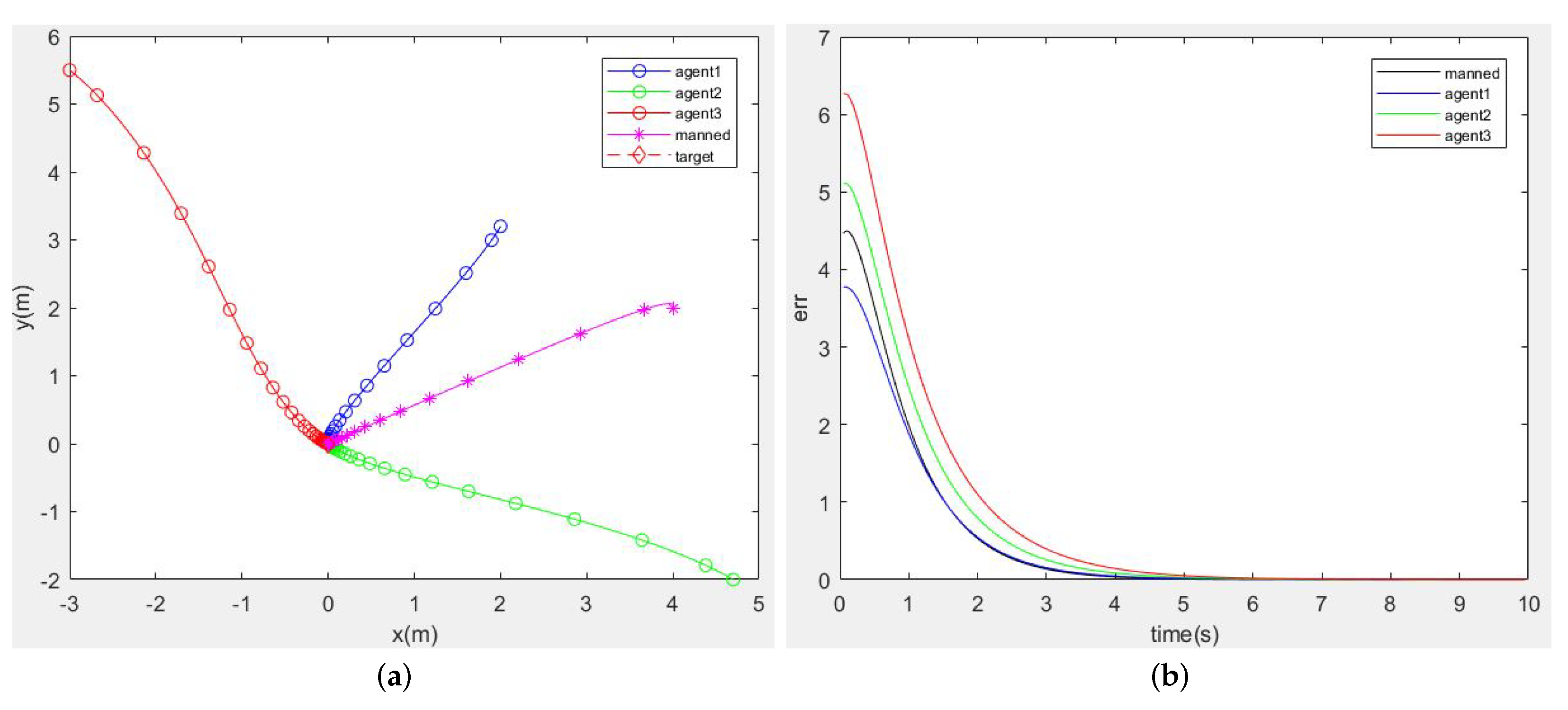
3.2.3. Comparison with the Target-Pursuit Problem in the Multi-Agent System
4. Discussion
- The environment in this paper is relatively ideal; we will consider the target-pursuit problem when obstacles exist. At the same time, we will consider the situation of multiple targets, so that the strategy can adapt to more practical scenarios.
- For the situation where the target adopts an escape strategy, we will conduct further analysis, introduce reinforcement learning methods in cases where the model is difficult to obtain, and balance the relationship between computational cost and algorithm performance.
- The cooperation between multi-agent systems and the manned platform is passive in this paper. In the future, we will introduce trajectory prediction methods for the manned platform, so that agents can make active decisions based on a certain degree of predictive information, thereby improving the efficiency of team task execution.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, X.; Su, H.; Wang, X.; Chen, G. An Overview of Coordinated Control for Multi-agent Systems Subject to Input Saturation. Perspect. Sci. 2016, 7, 133–139. [Google Scholar] [CrossRef]
- Ge, S.; Liu, X.; Goh, C.; Xu, L. Formation Tracking Control of Multiagents in Constrained Space. IEEE Trans. Control Syst. Technol. 2016, 24, 992–1003. [Google Scholar] [CrossRef]
- Wu, H.; Karkoub, M.; Hwang, C. Mixed Fuzzy Slidingmode Tracking with Backstepping Formation control for Multinonholonomic Mobile Robots subject to Uncertainties. J. Intell. Robot. Syst. 2015, 79, 73–86. [Google Scholar] [CrossRef]
- Kawa, A.; Pawlewski, P.; Golinska, P.; Hajdul, M. Cooperative Purchasing of Logistics Services among Manufacturing Companies Based on Semantic Web and Multi-agent System. In Proceedings of the International Conference on Practical Applications of Agents and Multiagent Systems, Salamanca, Spain, 26–28 April 2010. [Google Scholar]
- Zuiani, F.; Vasile, M. Multi-agent Collaborative Search with Tchebycheff Decomposition and Monotonic basin Hopping Steps. In Bioinspired Optimization Methods & Their Applications; BIOMA: Bohinj, Slovenia, 2012. [Google Scholar]
- Marden, J.; Shamma, J. Game Theory and Distributed Control. In Handbook of Game Theory with Economic Applications; Elsevier: Amsterdam, The Netherlands, 2015; Volume 4, pp. 861–899. [Google Scholar]
- Barreiro-Gomez, J. Distributed Formation Control using Population Games. In The Role of Population Games in the Design of Optimization-Based Controllers; Springer: Berlin/Heidelberg, Germany, 2019; pp. 97–110. [Google Scholar]
- Qin, J.; Ban, X.; Li, X. Evolutionary Dynamics of Multiagent Formation. In Proceedings of the Chinese Control and Decision Conference, Guilin, China, 17–19 June 2009; pp. 3557–3561. [Google Scholar]
- Mcgrew, T.M. Army Aviation Addressing Battlefield Anomalies in Real Time with the Teaming and Collaboration of Manned and Unmanned Aircraft. Geochem. Geophys. Geosyst. 2009. [Google Scholar] [CrossRef]
- Dubois, T.; Host, C.; Butt, J.; Clemens, J.A.; Blanton, B. Manned/unmanned Collaborative Mission Concepts with Tiltrotor Aircraft in Support of Maritime Patrol and Search-and-rescue Operations. In Proceedings of the Australian International Aerospace Congress, Melbourne, Australia, 25–28 February 2013. [Google Scholar]
- Das, A.; Kol, P.; Lundberg, C.; Doelling, K.; Sevil, H.; Lewis, F. A Rapid Situational Awareness Development Framework for Heterogeneous Manned-Unmanned Teams. In Proceedings of the National Aerospace and Electronics Conference, Dayton, OH, USA, 23–26 July 2018; pp. 417–424. [Google Scholar]
- Zhou, H.; Wang, X.; Shan, Y.-Z.; Zhao, Y.; Cui, N. Synergistic Path Planning for Multiple Vehicles based on an Iimproved Particle Swarm Optimization Method. Acta Autom. Sin. 2020, 46, 2670–2676. [Google Scholar]
- Garcia, E.; Casbeer, D.; Moll, A.; Pachter, M. Multiple Pursuer Multiple Evader Differential Games. IEEE Trans. Autom. Control 2020, 66, 2345–2350. [Google Scholar] [CrossRef]
- Nourbakhsh, I.; Sycara, K.; Koes, M.; Yong, M.; Lewis, M.; Burion, S. Human-Robot Teaming for Search and Rescue. Pervasive Comput. 2005, 4, 72–79. [Google Scholar] [CrossRef]
- Benda, M.; Jagannathan, V.; Dodhiawalla, R. On Optimal Cooperation of Knowledge Sources: An Empirical Investigation; Technical Report BCS-G2010-28; The Boeing Company: Seattle, WA, USA, 1986. [Google Scholar]
- Kitamura, Y.; Teranishi, K.; Tatsumi, S. Organizational Strategies for Multiagent Real-time Search. In Proceedings of the International Conference on Multi-agent Systems, Kyoto, Japan, 9–13 December 1996; pp. 150–156. [Google Scholar]
- Undeger, C.; Polat, F. Multi-agent Real-time Pursuit. Auton. Agents Multi-Agent Syst. 2010, 21, 69–107. [Google Scholar] [CrossRef]
- Keshmiri, S.; Payandeh, S. Toward Opportunistic Collaboration in Target Pursuit Problems. In Proceedings of the Autonomous and Intelligent Systems-Second International Conference, Burnaby, BC, Canada, 22–24 June 2011. [Google Scholar]
- Pei, H.; Chen, S.; Lai, Q. Multi-target Consensus Circle Pursuit for Multi-agent Systems via a Distributed Multi-flocking Method. Int. J. Syst. Sci. 2015, 47, 3741–3748. [Google Scholar] [CrossRef]
- Hamed, O.; Hamlich, M. Improvised Multi-robot Cooperation Strategy for Hunting a Dynamic Target. In Proceedings of the 2020 International Symposium on Advanced Electrical and Communication Technologies (ISAECT), Marrakech, Morocco, 25–27 November 2020; p. 168691. [Google Scholar]
- Liu, K.; Zheng, X.; Lin, Y.; Han, L.; Xia, Y. Design of Optimal Strategies for the Pursuit-evasion Problem based on Differential Game. Acta Autom. Sin. 2021, 47, 15. [Google Scholar]
- István, H.; Skrzypczyk, K. Robot Team Coordination for Target Tracking using Fuzzy Logic Controller in Game Theoretic Framework. Robot. Auton. Syst. 2009, 57, 75–86. [Google Scholar]
- Bhattacharyya, A. Forbidden Minors for a Pursuit Game on Graphs. Sr. Proj. Spring 2013, 408. [Google Scholar]
- Talebi, S.; Simaan, M.; Qu, Z. Cooperative, Non-cooperative and Greedy pursuers Strategies in Multiplayer Pursuit-evasion Games. In Proceedings of the IEEE Conference on Control Technology and Applications, Mauna Lani, HI, USA, 27–30 August 2017; pp. 2049–2056. [Google Scholar]
- Talebi, S.; Simaan, M. Multi-pursuer Ppursuit-evasion Games under Parameters Uncertainty: A Monte Carlo approach. In Proceedings of the System of Systems Engineering Conference, Waikoloa, HI, USA, 18–21 June 2017; pp. 1–6. [Google Scholar]
- Qu, Z.; Simaan, M. A Design of Distributed Game Strategies for Networked Agents. IFAC Proc. Vol. 2009, 42, 270–275. [Google Scholar] [CrossRef]
- Liu, R.; Cai, Z. A Novel Approach based on Evolutionary Game Theoretic Model for Multi-player Pursuit Evasion. In Proceedings of the International Conference on Computer, Mechatronics, Control and Electronic Engineering, Changchun, China, 24–26 August 2010; pp. 107–110. [Google Scholar]
- Fu, L.; Liu, J.; Meng, G.; Wang, D. Survey Of Manned/Unmanned Air Combat Decision Technology. In Proceedings of the Chinese Control and Decision Conference, Qingdao, China, 23–25 May 2015. [Google Scholar]
- Liu, Y.; Zhang, A. Cooperative Task Assignment Method of Manned/unmanned Aerial Vehicle Formation. Xi Tong Gong Cheng Yu Dian Zi Ji Shu/Syst. Eng. Electron. 2010, 32, 584–588. [Google Scholar]
- Xu, L.; Pan, X.; Wu, M. Analysis on Mmanned/unmanned Aerial Vehicle Cooperative Operation in Antisubmarine Warfare. Chin. J. Ship Res. 2018, 13, 154–159. [Google Scholar]
- Liu, J.; Yuan, S.; Qi, Y.; Ye, W. Research on the Key Technology of the Cooperative Combat System of Manned Vehicle and Unmanned Aerial Vehicle. Ship Electron. Eng. 2012, 32, 1–3. [Google Scholar]
- Engwerda, J. LQ Dynamic Optimization and Differential Games; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Li, M.; Qin, J.; Ma, Q.; Zheng, W.; Kang, Y. Hierarchical Optimal Synchronization for Linear Systems via Reinforcement Learning: A Stackelberg-Nash Game Perspective. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 1600–1611. [Google Scholar] [CrossRef] [PubMed]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, L.; Song, W.; Yang, T.; Tian, Z.; Yu, X.; An, X. Cooperative Decisions of a Multi-Agent System for the Target-Pursuit Problem in Manned–Unmanned Environment. Electronics 2023, 12, 3630. https://doi.org/10.3390/electronics12173630
Han L, Song W, Yang T, Tian Z, Yu X, An X. Cooperative Decisions of a Multi-Agent System for the Target-Pursuit Problem in Manned–Unmanned Environment. Electronics. 2023; 12(17):3630. https://doi.org/10.3390/electronics12173630
Chicago/Turabian StyleHan, Le, Weilong Song, Tingting Yang, Zeyu Tian, Xuewei Yu, and Xuyang An. 2023. "Cooperative Decisions of a Multi-Agent System for the Target-Pursuit Problem in Manned–Unmanned Environment" Electronics 12, no. 17: 3630. https://doi.org/10.3390/electronics12173630
APA StyleHan, L., Song, W., Yang, T., Tian, Z., Yu, X., & An, X. (2023). Cooperative Decisions of a Multi-Agent System for the Target-Pursuit Problem in Manned–Unmanned Environment. Electronics, 12(17), 3630. https://doi.org/10.3390/electronics12173630