1. Introduction
Nowadays, there are more and more areas of life wherein people utilize the help of artificial intelligence (AI). From medical applications [
1,
2], through industrial settings [
3] to household gadgets [
4], most products are already using or will use some machine learning (ML) or AI technique. This is also true for transportation, where researchers, stakeholders, companies, and also investors see great potential in autonomous vehicles (AVs), smart infrastructures, and intelligent traffic signals [
5,
6]. Among others, safety, security, and efficiency are the main motivations for developing such systems. The techniques of AI can be built into systems, which can be extrapolated and generalized to situations that have not been encountered before, unlike their classic rule-based controller ancestors [
2]. This is fitting, especially in the case of reinforcement learning (RL), where the agents learn by interactions. There are a vast amount of successful applications in the literature where the AI created with RL shows superhuman performance [
7,
8,
9]. From simple games such as the Atari domain, to more complicated strategic quests such as [
10] or the complex game of Go, researchers have demonstrated that powerful results could be generated from scratch. In domains where the situations are endless, and there is no excellent and final amount of data, supervised learning (SL) methods can be used poorly. This is why RL algorithms may give a better solution in a traffic scenario, be it commuting cars or the supporting infrastructure.
With rapid population growth and urbanization, the traffic demand is steadily rising in metropolises worldwide, which causes more traffic jams and thus wastes people’s time. Existing intersections and infrastructure must become highly efficient to satisfy the rising needs of modern traffic. To tackle this problem, intelligent traffic lights and signal control devices were used in the US as early as the 1970s, and AI-based solutions were introduced in 2012 [
11]. Thanks to modern technological advances, rapidly accelerated communication, and connectivity options, traffic control devices can be efficiently inserted into our daily commute. Apart from the vehicle-to-anything (V2X) communication, where the vehicles communicate with the infrastructure, a smart intersection without communication also holds promise in optimizing existing road network throughput, emergency, and priority vehicle allowance, reducing waiting times, and allowing more efficient flows, fewer traffic jams, and optimized emissions. In the city of Surrey in Canada [
12], for instance, the traffic throughput is managed by a central control center with adaptive control signal periods.
Accordingly, different types of systems can be developed based on the infrastructural possibilities. Solutions to optimize a traffic flow in a neighborhood based on some requirements have been published and applied with different approaches in recent years [
13,
14,
15]. However, most of the current working algorithms are rule-based, which are limited in their adaptivity, the most desired attribute of AI. These algorithms optimize for a particular goal forged into the training or coding at the programming time of the algorithms. Standard DRL also has a single or multi-objective function but is not adaptive to new tasks emerging after training. Even with a multi-objective target function, it can only be optimized for multiple goals at once (e.g., optimize traffic signal scheduling and timing to ameliorate traffic congestion at moderately and heavily busy single or multiple intersections), and we are unable to change it after training [
16,
17,
18]. In the field of RL, recent works provide an adaptable framework for training agents, where the preferences can be altered even after the agent is deployed [
19].
In this work, we intend to tackle the problem of traffic signal control (TSC) with RL methods to make the flows effective, environmentally friendly, and sustainable. Moreover, utilizing successor features (SFs), we provide an adaptive framework where the flow can be controlled based on our preferences after deploying the trained model. In some sustainable scenarios, we show how our proposed method compares to the classical rule-based and more advanced traffic-based algorithms. In addition to the classical, already applied solutions, we compare our solution to a Deep-Q-Network (DQN) agent to emphasize why our method is more viable and flexible. The novelty in our solution lies in the combination of the different reward signals and the possible adaptation to the current preferences of the network flow. Unlike other works, our multi-objective learning can be personalized and is not fixed to a value during training. With this, we present a more viable option for adaptive TSC. To the best of our knowledge, we are the first to report SF usage in the domain of TSC.
Our goal is to show that the SFs can be used in traffic signal problems. The paper progresses as follows:
Section 2 shows the recent research literature in RL and TSC. The methodology is provided in
Section 3, where SFs, General Policy Evaluation (GPE), and Improvement (GPI) are detailed. The following
Section 4 shows our experimental settings and the ablation study setup. Finally, in
Section 5, we highlight the results of our method and show the advantages of our method compared to classical, adaptive, and deep RL techniques. Lastly,
Section 6 summarizes our paper and provides future work possibilities and opportunities.
2. Related Work
Traffic congestion is a persistent issue that affects urban areas and harms individuals and society. The trend of flocking to urban areas further accelerates these adverse outcomes over time. For instance, in 2020, traffic congestion cost Americans over USD 101 billion in lost productivity and wasted over 1.7 billion gallons of fuel. Traffic congestion was also attributed to over 18 million tons of harmful greenhouse gases [
20]. The more troubling news is that this is due to the pandemic. The years before 2020 showed almost double the amount of waste and lost productivity. Reducing congestion would substantially benefit the economy, the environment, and society. One way to do this is by improving signalized intersections, a common cause of traffic bottlenecks in cities, and thus TSC plays a vital role in urban traffic management. A significant amount of research is being done on TSC systems to improve traffic flow at intersections by adjusting traffic phase splits. As the complexity and size of the control problem increase, classic approaches lack the required computational resources to provide a real-time solution. Hence, besides the classic control applications, adaptive methods started appearing in traffic control in recent decades. New solutions became feasible as the technology advanced for sensing and controlling hardware. One of the modern control applications is ML-based solutions. From the domain of ML, as stated above, RL has been the preferred unsupervised technique for accomplishing a fully dynamic TSC. Recent developments in RL, specifically deep RL, have made it possible to efficiently handle high-dimensional input data such as images or LiDAR measurements. This allows the agent to learn a state abstraction and a policy approximation directly from the input states. These advances have led to outstanding performance in various transportation-related domains and have potential for real-time application and in solving complex sequential decision-making problems [
21,
22].
There is a vast amount of research building around TSC and RL synergy. The following papers justify the usage of RL in this domain.
The suitable algorithms in the TSC problem have expanded along with the advances in RL. Some have originated from the value-based and policy-based solutions, such as DQN and Policy Gradient (PG), and evolved to the Actor-Critic approaches. Generally, the methods and solutions target three main areas of learning.
State-space: One is the state and action space representation, where authors work on their environment descriptions fed to the agent. In [
23], the authors developed a state representation by utilizing Convolutional Neural Networks (CNN). Their method is called discrete traffic state encoding (DTSE). The authors of [
24] utilized high-resolution event-based data for state representation, outperforming fixed-time and actuated controllers in queue length and total delay metrics. In [
25], for decision-making, the authors construct signal groups and represent them as individual agents that operate on the intersection level. As for action space modification, an interesting example is shown in [
26]. The authors developed an agent with a hybrid action space that combines discrete and continuous actions. Additionally, they compared their solution to deep reinforcement learning (DRL) algorithms with discrete and continuous action spaces and fixed-time control. The results showed that the proposed method outperformed all other methods in average travel time, queue length, and average waiting time.
Communication: The second area is communication. Connecting vehicles to the infrastructure results in valuable data that cannot be wasted. In [
27], the researchers introduced an algorithm that builds on communication between the traffic signals and the traffic monitoring sensors in complex real-world networks. Recent advancements in this field have taken advantage of V2X technologies, which involve collaboration between vehicles and infrastructure to reduce delay and carbon emissions [
28,
29,
30].
Rewarding: The last concept that RL practitioners consider is the rewarding concept. From the aspect of performance, rewarding is one of the most influential components of RL. It can ruin or advance the same algorithms by falsely assigning credit to non-relatable actions. In single TSC problems, the environment is the road traffic condition. The agent controls the traffic signal based on preset objectives, including reducing emissions, fuel consumption stops, delay times, managing vehicle density, queue lengths, increasing speed, and increasing throughput. Most traditional traffic control methods are single-objective, which means that they focus on optimizing a single parameter, e.g., [
31]. However, the literature presents various multi-objective RL solutions to the TSC problem by selecting and optimizing these metrics. Multi-objective RL is comparable to single-objective RL in terms of time complexity since it only requires extending the reward signal with additional components. This means that significant performance improvements can be achieved at a low computational cost, unlike with traditional algorithms. However, with a more complex reward signal, the agent has a more challenging task. It is more difficult to decipher the environment and the results of the control signals.
The authors of [
32] present an algorithm tailored to three traffic scenarios, where adaptation occurs offline based on the vehicle count in a given time frame. In [
33], the authors introduced a dynamically changing discount factor in the DQN setting, modifying the target value of the Bellman equation. The coder in [
34] decomposes the original RL problem into sub-problems, thus leading to straightforward RL goals. A new, rewarding concept is investigated by [
35] with the DQN algorithm, combined with a coordination algorithm for controlling multiple intersections. Others, such as Ref. [
36], proposed a Multi-Agent Advantage Actor-Critic (A2C) algorithm for solving the multi-intersection TSC problem. Most recently, Ref. [
37] proposed a novel rewarding concept and compared its performance with the most common rewarding strategies in the literature. We refer the reader to [
38,
39,
40] for other examples in the domain. Most similar to our proposed method are [
17,
18]. Their contribution shows a multi-objective RL-TSC algorithm, where they replace the single-objective reward with a scalarized signal, which is a weighted sum of the reward. Their objectives are one for light and one for heavy traffic. The onus is on the user to select weightings that will give good results. They showed a reduced convergence time and decreased the average delay in the network compared to a single-objective approach. While performance gains appear, selecting appropriate values for the weightings of rewards ought to be a time-consuming task, especially if there are various demands in the intersections. In [
31], the authors extended their work further, considering a total of seven different parameters in the reward function.
The problem with the above-mentioned methods is that the agent has to solve the Markov Decision Process (MDP) and reveal the underlying reward components, which can be complex and error-prone. In contrast, by default, our solution decomposes the different reward functions, resulting in a more straightforward setting for training. Moreover, the composition of different reward components is a matter of preference change. The method can be quickly adapted to not only one or two setups but any arbitrary settings. We intend to propose a novel approach to the problem, where the different multi-objectives can be decomposed into individual ones and later, based on the inferencing preference, combined for a more tailored behavior. As a remark, one should mention the approaches based on Multi-Agent RL (MARL), traffic networks consisting of multiple intersections, where an independent RL agent controls the signals. These cases are much more relevant to real-world TSC problems than the Single-Agent RL (SARL) cases. From 2000, Ref. [
41] was one of the most significant early works in Multi-Agent RL-TSC. The model-based approach clearly outperformed fixed-time controllers at high levels of network saturation. Although there are MARL algorithms in the literature, we limit our current work to the single-agent setup because we want to argue that the SFs can indeed be used with TSC as well.
Limitations: Various assumptions are often made to simplify the simulation process to make the optimization problem manageable. However, these assumptions often do not reflect real-world situations in which traffic conditions are influenced by a range of factors, such as driver behavior, interactions with vulnerable road users (e.g., pedestrians, cyclists), weather, and road conditions. These factors can hardly be fully described in a traffic model [
40].
Based on the aforementioned works, we also restrict our optimization problem to random traffic flows; we discard any vulnerable road users (pedestrians, cyclists, or such). The intersection is a straight and right-way one. There is no signal for the left turn; thus, there is no possible blocking of one another. It should be noted that many of the proposed reward definitions above rely on information that is easy to obtain in a simulation but quite difficult or impractical to obtain in a real-world setting using current technologies. Data about ATWT, ATT, fuel usage, or emissions could not be collected reliably without some form of vehicle to junction (V2J) communication [
42].
Contribution: As shown above, it has been presented several times that classical control algorithms can be beaten by RL technology on TSC. They can minimize the delay and improve the average throughput of the traffic intersection [
14,
15,
37].
However, our goal is not to show this once again but to provide significant development in the domain of adaptivity and information decomposition and representation. Thus, after presenting our algorithm and methodology in
Section 3, we compare our method to the DQN agent as most of the aforementioned works measure their solution to the original DQN agent and some fixed-time controller. Thus, our evaluation is also designed based on these works. Finally, we provide insight into how and why our method is preferable to previous ones.
3. Methodology
In RL, we distinguish an actor (agent) and its surroundings (an environment). They have continuous interaction. The agent selects an action based on the current state of the environment, with which it changes its state. In response, the agent receives feedback (reward), and the new state indicates the effect of the applied action. In the case of a TSC setting, the states might be lane occupancy, flow rate, standing vehicles, or lamp states. The state generally contains valuable information about the environment that helps the agent to make decisions. RL agents aim to observe the changes and their effects and devise a policy to maximize the rewards. Rewards, typically scalar signals, describe the goodness of the selected action. Due to the abstraction of the reward signal, RL opens the door for solving problems where the exact right answer is unknown; only an approximate estimate is given. One might imagine the RL training similarly to human learning. We learn based on the interaction and its consequences. Moreover, deciding the goodness of a complete process comes naturally because evaluating each step and assessing exactly which move was good or bad is intractable. By using the trial and error mechanism, RL agents explore their options of interactions and come to a conclusion about how best to act in a specific state. On the other hand, one must mention the credit assignment problem, which can hinder the training. Deciding what the optional action is depends on the planning horizon, long-term strategy, the problem itself, and the available action possibilities.
3.1. Markov Decision Processes
MDPs are used for the formulation of RL problems. It is a mathematical framework for decision-making in a situation where the system’s output (environment) is partially randomized but depends on the current action. Suppose that an MDP system has the Markov property. In this case, it means that the conditional probability distribution of the following state of a random process depends only on the current state, given all the previous states [
43]. This implies that the state should contain all information needed to draw this probability and also helps us to make decisions based on the current observable state.
An MDP usually is characterized by a 4-element tuple, . Interactions create episodes. At each time step t, an RL agent manipulates the environment with arbitrary action . This results in an observation for every as state , and a reward . The agent’s goal is to maximize the sum of the expected rewards along the interactions of the episodes.
As discussed above, multi-objective RL has several reward functions, but, during the steps, it is compressed into a scalar value by weighting the reward components preferably. One can think of these reward functions as different tasks, and, thus, the goal of RL is to find a policy
that maximizes the value of every state–action pair for a given reward component (task):
where
denotes the expectation over the trajectories induced by
, and
is the discount factor, used for discounting future rewards. Having (
1), the next step is to introduce the formulation of GPE and GPI with SFs.
3.2. SFs, GPE, and GPI
Successor Features (SFs) were formalized to aid multi-objective RL algorithms, where the reward functions are complicated. Their utilization helps to decompose complex reward functions into simpler ones, meanwhile enabling the exchange of information between tasks and promoting the reuse of the skills [
19]. This section briefly introduces the method and provides the necessary equations without the full deduction. We refer the reader to [
19] for a more detailed description.
First, we choose
as our arbitrarily selected feature function vector, where each element is a “feature”. It is selected smartly to create our goal tasks, as described in
Section 4.2. Then, according to [
44], with any arbitrary preference vector
, we can define the reward function as
Basically, Equation (
2) results in a scalar value that displays a weighted sum of multi-objective reward components, where
is the preference vector. In general RL, this multiplication is included inside the environment, where the different components of the reward are “hard-codedly” weighted and thus cannot be changed rapidly. However, using (
2), the reward function values can be modified instantly by simply changing
.
Following [
19], the SFs are defined as the expected values of the discounted feature functions along a trajectory when acting on policy
. This yields Equation (
3).
By multiplying (
3) with
, we arrive at (
4).
characterizes the same Q-function as (
1) does; however, additionally, it is parametrized by
, and, most favorably, it is simplified to the inner product of
. In terms of dimensionality, for
n policies
and
,
where
d is the number of feature functions and
k is the number of policies (training tasks). Using (
4) as an efficient form of GPE, thus, for all policies, we can calculate the value function rapidly. For a deeper explanation of the deduction and proof of (
4), see [
19].
The last missing piece of the method is GPI. In this context, after Barreto et al., the improved policy yields
Basically, we evaluate the value function of the state–action pair over all policies (GPE). (In [
44], Theorem 1 shows that Equation (
5) is a legitimate form of GPI). Based on (
5), we choose the actions with the highest values.
The following section deals with the environment and provides the details of the applied neural networks and training settings.
5. Results
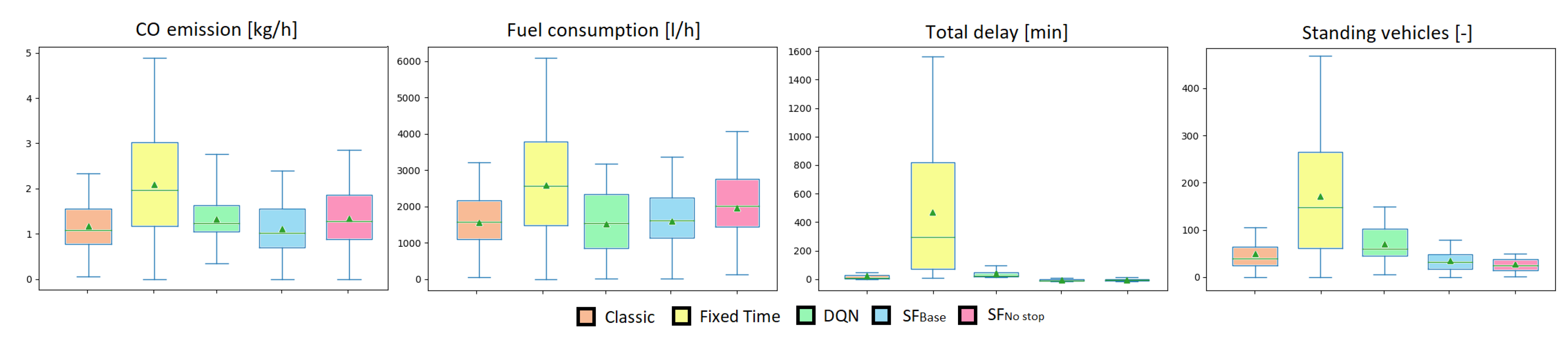
First, we look at a uniform flow distribution and compare the rule-based and learning algorithms by using boxplots in
Figure 1. Each agent is given 1000 random episodes, and their performance is compared with the metrics of CO, fuel consumption, total delay, and standing vehicles. Each boxplot represents the average values based on 1000 random episodes that are identical. With the help of the boxplots, we can see the mean (green triangle) and the median (green line) of the data. Meanwhile, the boxes show points between the lower and upper quartiles (Q1–Q3), and the whiskers on top of the boxes are for the minimum and maximum ranges. The lower the values and the smaller the boxes are, the better.
In
Figure 1, values are as expected; the
fixed time agent scores the worst in each metric, followed by the
classic agent. Although
classic optimizes for the delay, the
DQN and
SF techniques perform better, as was shown before in the literature. The difference between
and
DQN is marginal in CO and fuel usage, while the
agent did not explicitly learn to optimize the objective generated by
. A more apparent advantage is observable when comparing the total delays of an episode. Both
agents reduce the average delay minutes of the network. Note:
tries to optimize the number of vehicles halting in the scene. Interestingly, despite the different perspectives, it performs almost as well as
. The reason lies in our method. Each policy has its SF prediction, and when combined with
, each has an idea of the best action. Furthermore,
knows how to minimize the halting, but in situations when the scene is optimal for
, the others can contribute to the decision, as Equation (
5) suggests. This performs similarly to the all-optimizing
. In regard to performing better than
DQN, we can state that the complex reward function of five components allows the agent to optimize for the one with the highest magnitude: fuel consumption.
Table 2 indicates the mean values of
Figure 1 and displays the percentage of the improvement compared to the
fixed time baseline. We can observe that
DQN has the best score in fuel consumption as anticipated, but is closely followed by the
agents. Meanwhile, the other metrics show a more significant difference in favor of our method.
Table 2 also highlights the PV total waiting time average among the 1000 episodes, and it is clear that the
methods allow the PV to pass approximately four times faster on average.
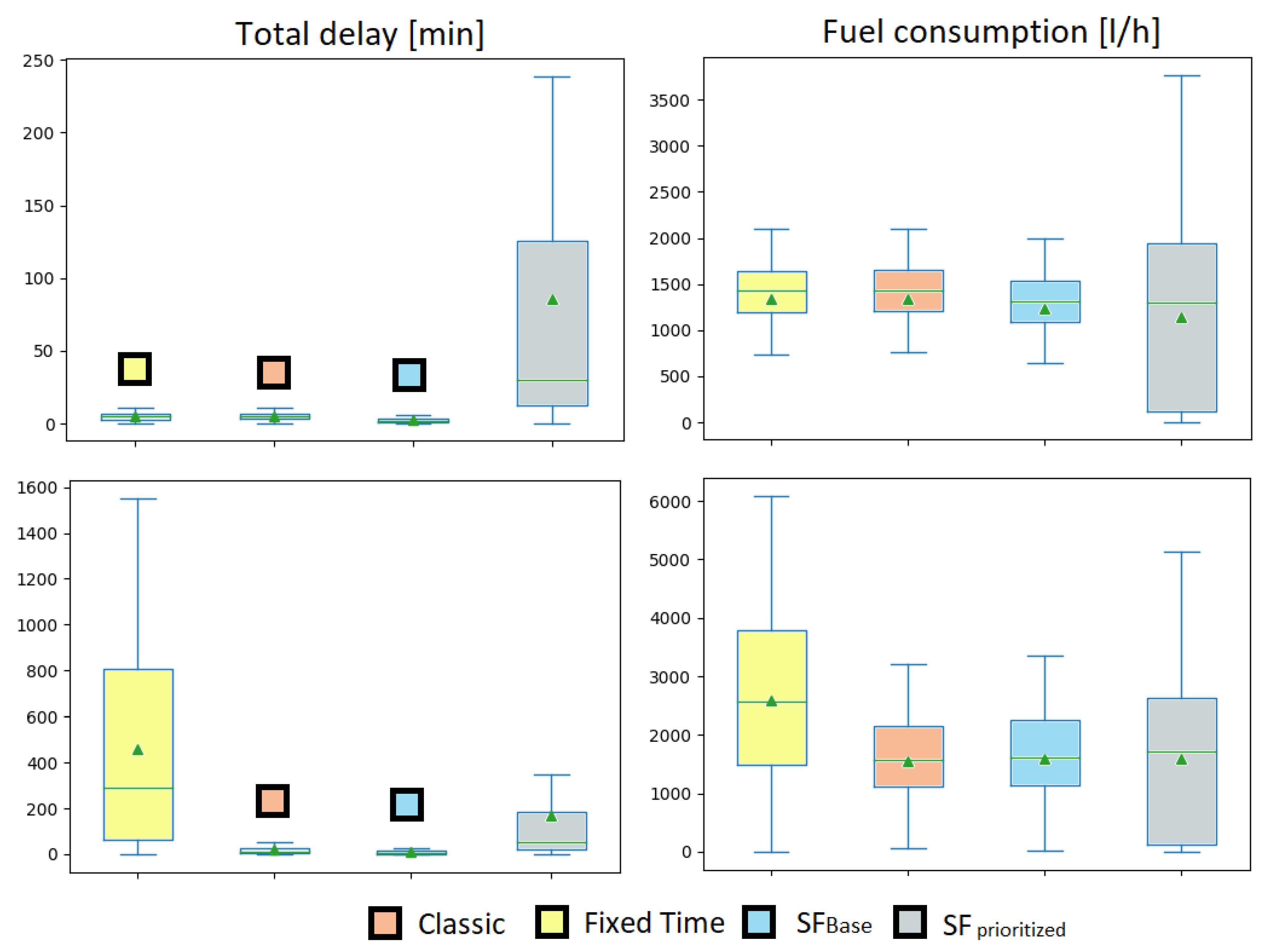
As an ablation of the possibilities using SF-based agents, we investigated 1000 scenarios using asymmetric flows. This meant that either the EW or the NS lanes had drastically more incoming vehicles. As seen in
Figure 2, the metrics of the
fixed time agent suffered the most. This can be also seen in
Table 3. It is natural that switching between the methods equally in an uneven load results in the worst performance. Our attention is guided toward our learning methods.
DQN falters the most in standing vehicles because, as mentioned before, it learns to optimize primarily for fuel consumption.
could perform the best in all metrics except fuel. Visibly,
could achieve the most negligible variance and mean regarding standing vehicles, but all other metrics were affected. Due to the long queues trying to pass the intersections,
increased for all agents, but
could keep it small. In reality, as the prioritized vehicle entered the scene, it opened the route and allowed all preceding cars to pass. This caused some degradation in other metrics, but it seems reasonable and acceptable.
Lastly,
Figure 3 shows how selected metrics change when evaluating the only prioritized interested policy
. The total delay and fuel consumption worsening is significant in both the uniform and asymmetric cases, but
managed to achieve
. In the case of uneven loads, the
outperformed the baseline. This indicates that with our adaptive preferences, we could allow the prioritized vehicles to move when needed and optimize the network emissions altogether otherwise. By using SF values to estimate the
Q values, we gained a method to set the traffic preferences on the fly adaptively. We can change the
any time and have a more suitable local solution for the intersection. Additionally, our method needs no supplementary sensors, as we have loop detectors. The PV’s location measurement can be based on GPS and internet communication with the traffic control system.
6. Conclusions
In summary, our work emphasizes the adaptivity of our method, which uses SFs for TSC optimization. By introducing reward components or features, we can design multi-objective RL that can be used to train agents for various target tasks.
To the best of our knowledge, we are the first to use SFs in TSC optimization and have successfully demonstrated their advantages over other baselines. Our approach allows for the alteration of a trained agent’s behavior within the range of the SF combinations simply by adjusting the weight vector . This means that we can prioritize different objectives, such as queue length or total CO emissions, without a significant performance deterioration.
We have thoroughly tested our method in different scenarios and shown that it outperforms known algorithms for optimizing a single four-way intersection. Additionally, our approach remains capable of adapting to new and personalized preferences without requiring the agent to be retrained. Furthermore, we demonstrate that prioritized vehicles could be given the freeway when necessary, thus helping services such as public transport or emergency vehicles.
Moving forward, we plan to extend our method to complex networks and multiple intersections with cooperation between them. An exciting direction for future research is investigating the objective preferences of individual networks, which poses significant challenges but also has high potential. Furthermore, we aim to broaden our method and explore how a general optimizing network could recognize different scenarios and select preferences based on them.
Overall, our work provides yet another powerful ML-based method for optimizing traffic at intersections, with promising applications for real-world traffic management systems.









{kind=link}
{kind=link}
{kind=link}