



Machine Learning-Based Prediction of Orphan Genes and Analysis of Different Hybrid Features of Monocot and Eudicot Plants



Abstract
1. Introduction
2. Related Works
3. Materials and Methods
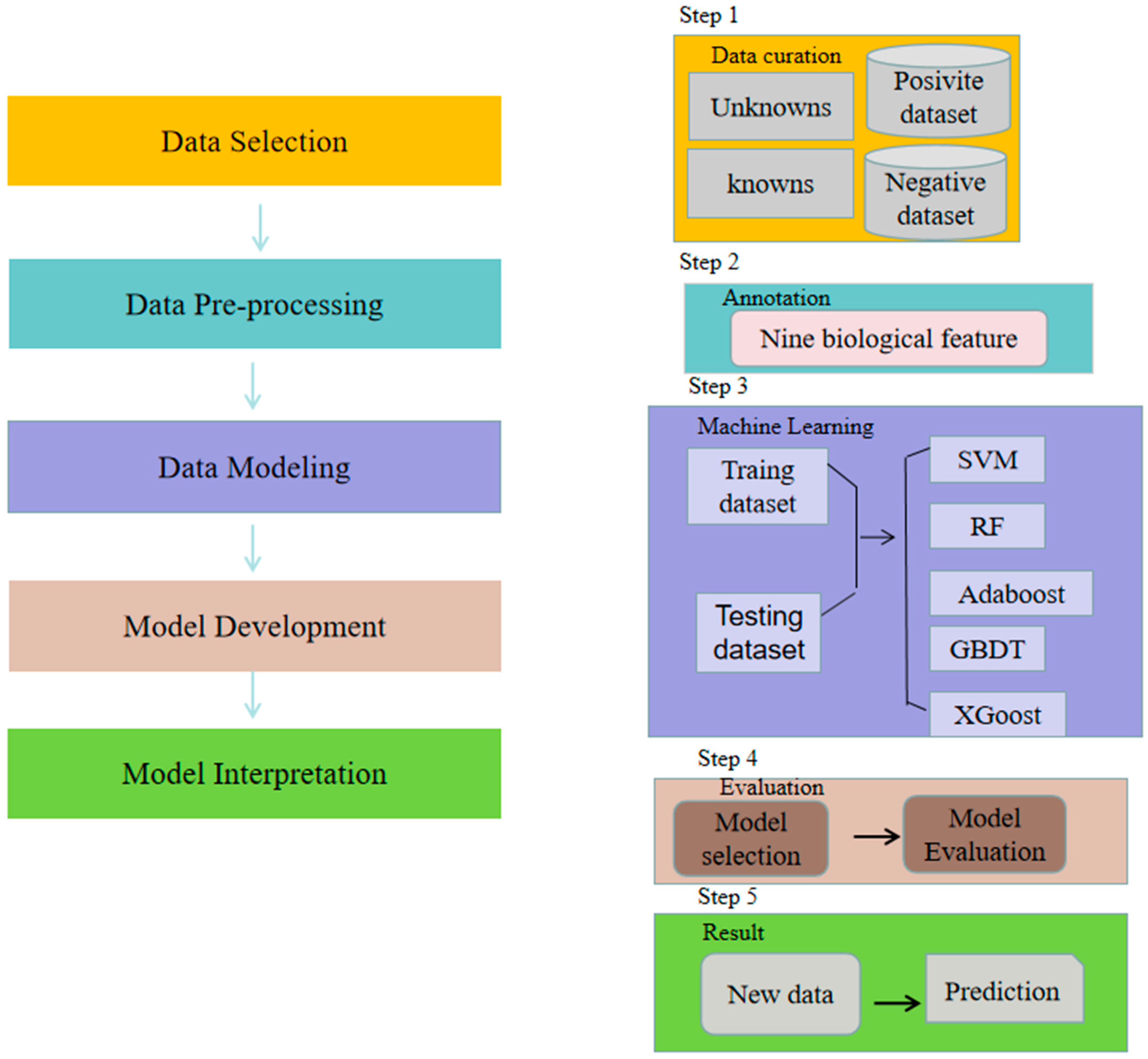
3.1. The Framework of the XGBoost-A2OG Model
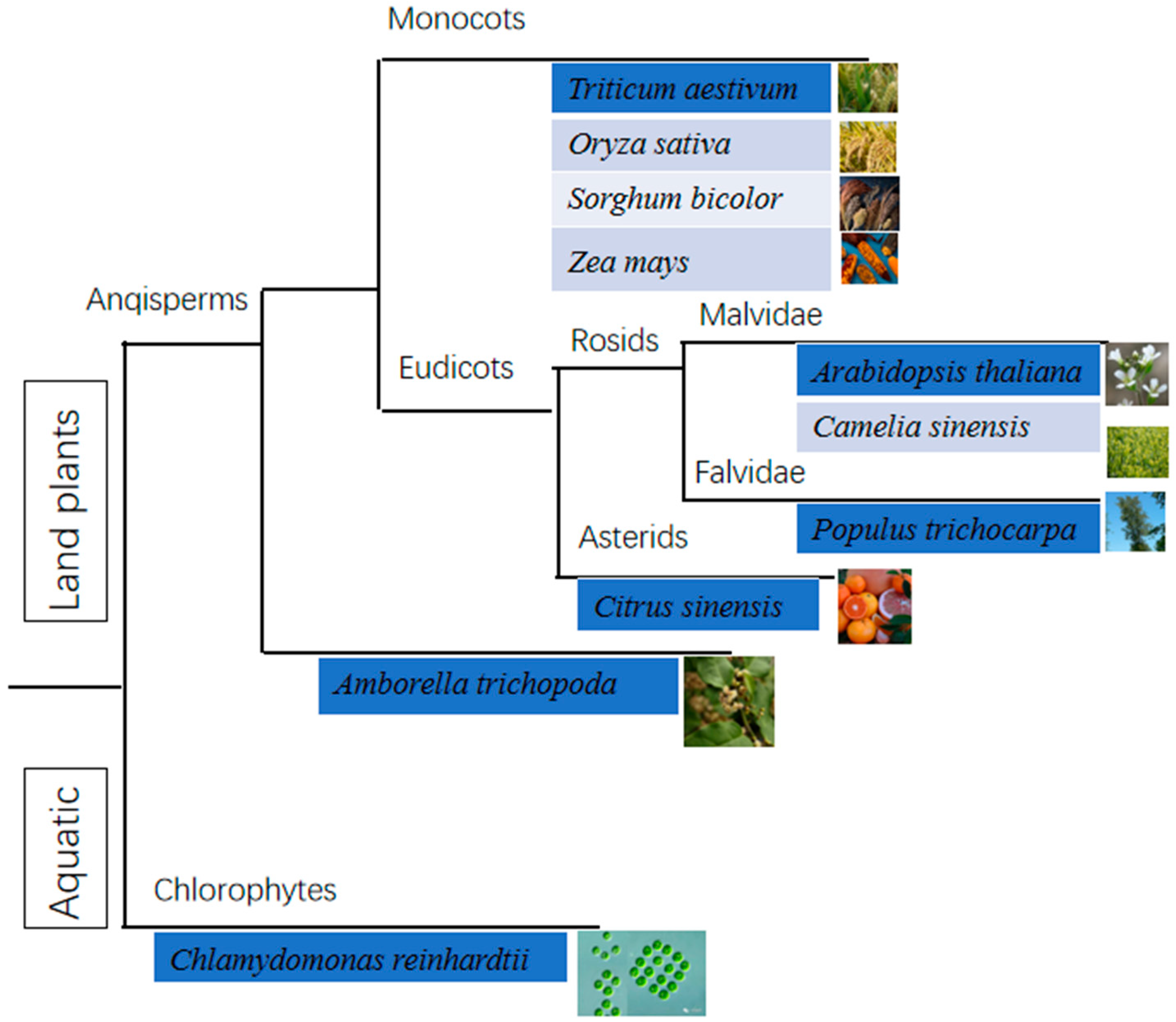
3.2. Data Collection
3.3. Ensemble Algorithm
3.4. Data Preparation and Feature Selection Settings
3.5. Validation Strategies and Evaluation Metrics
4. Results and Discussion
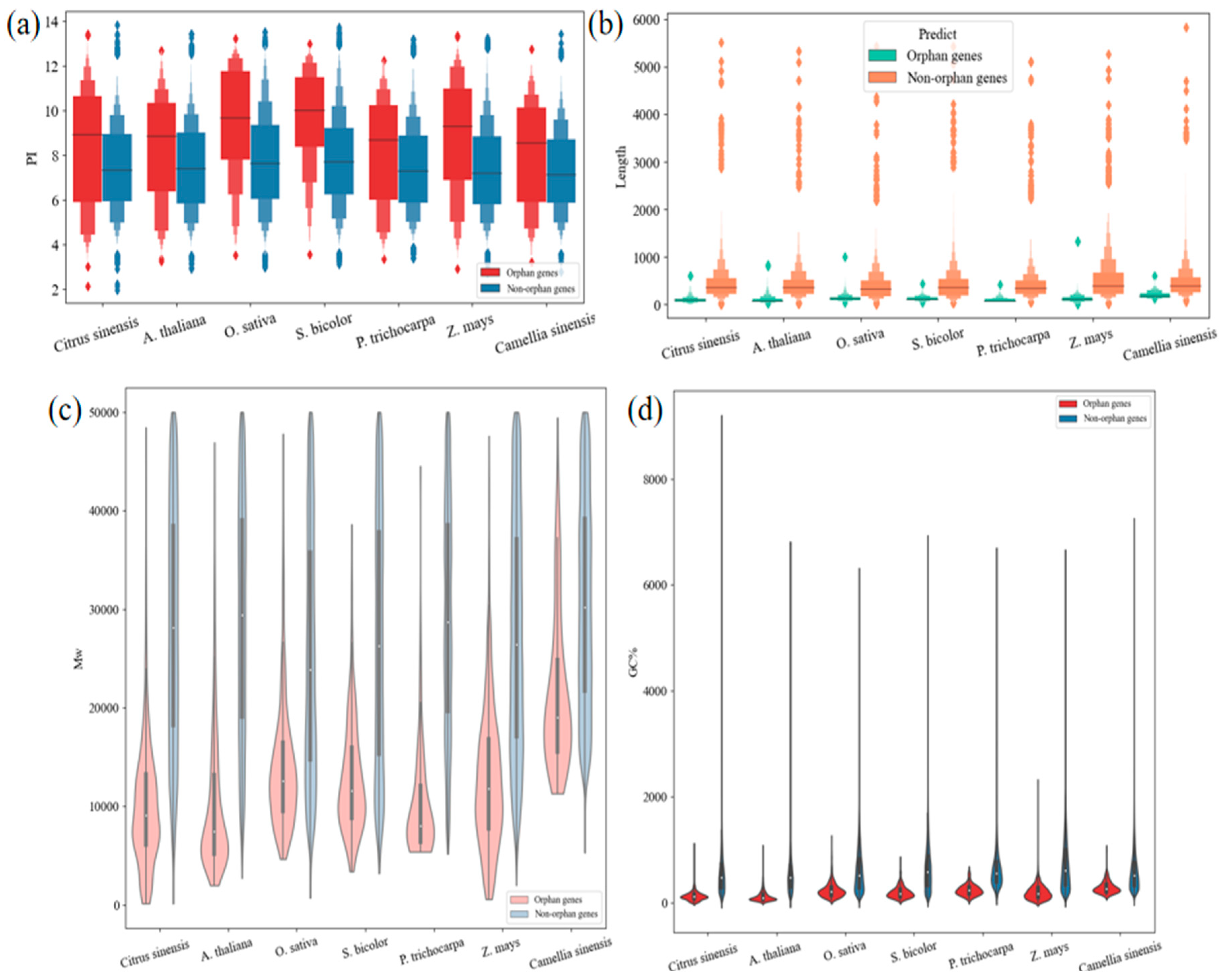
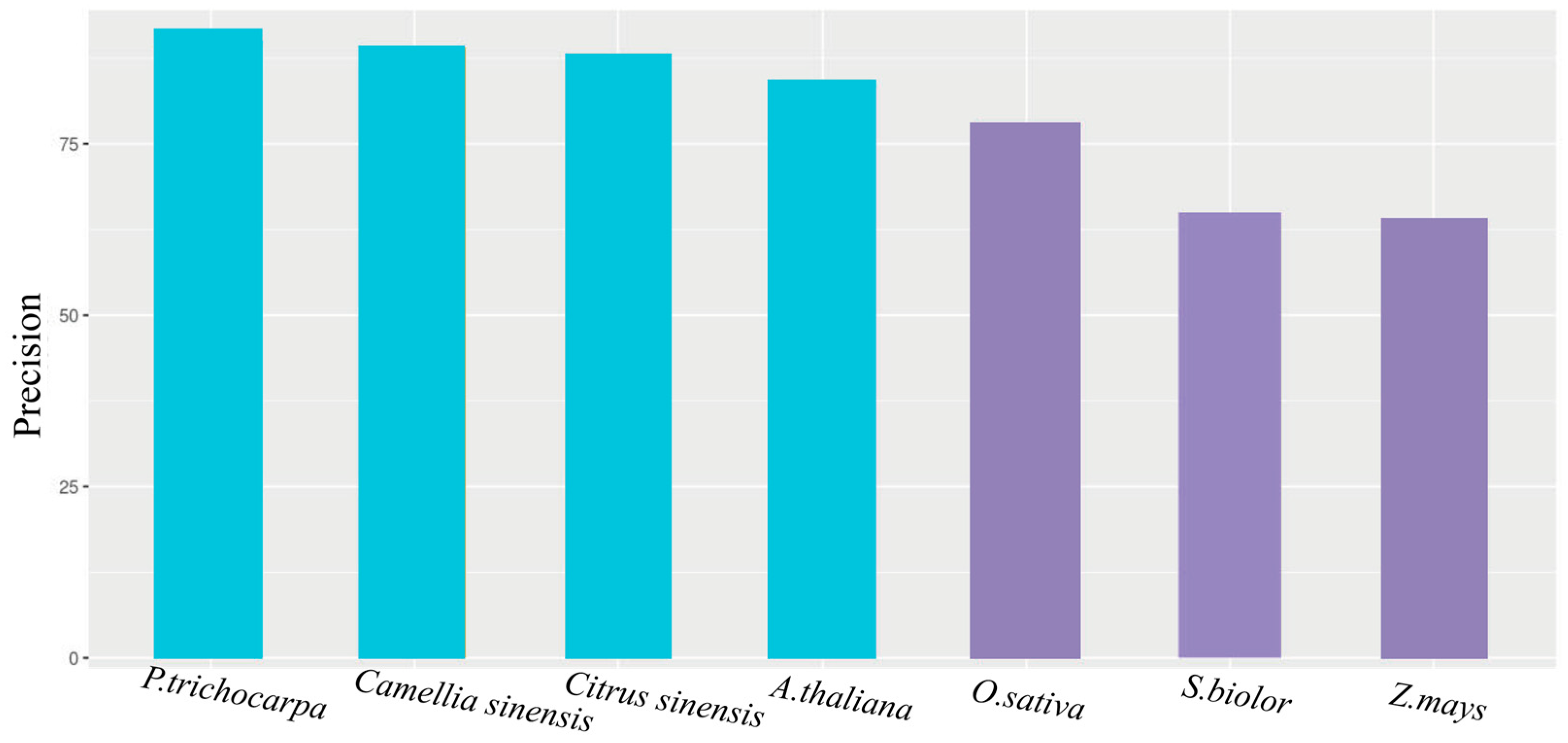
4.1. The Compared Features between OGs and NOGs in Different Species
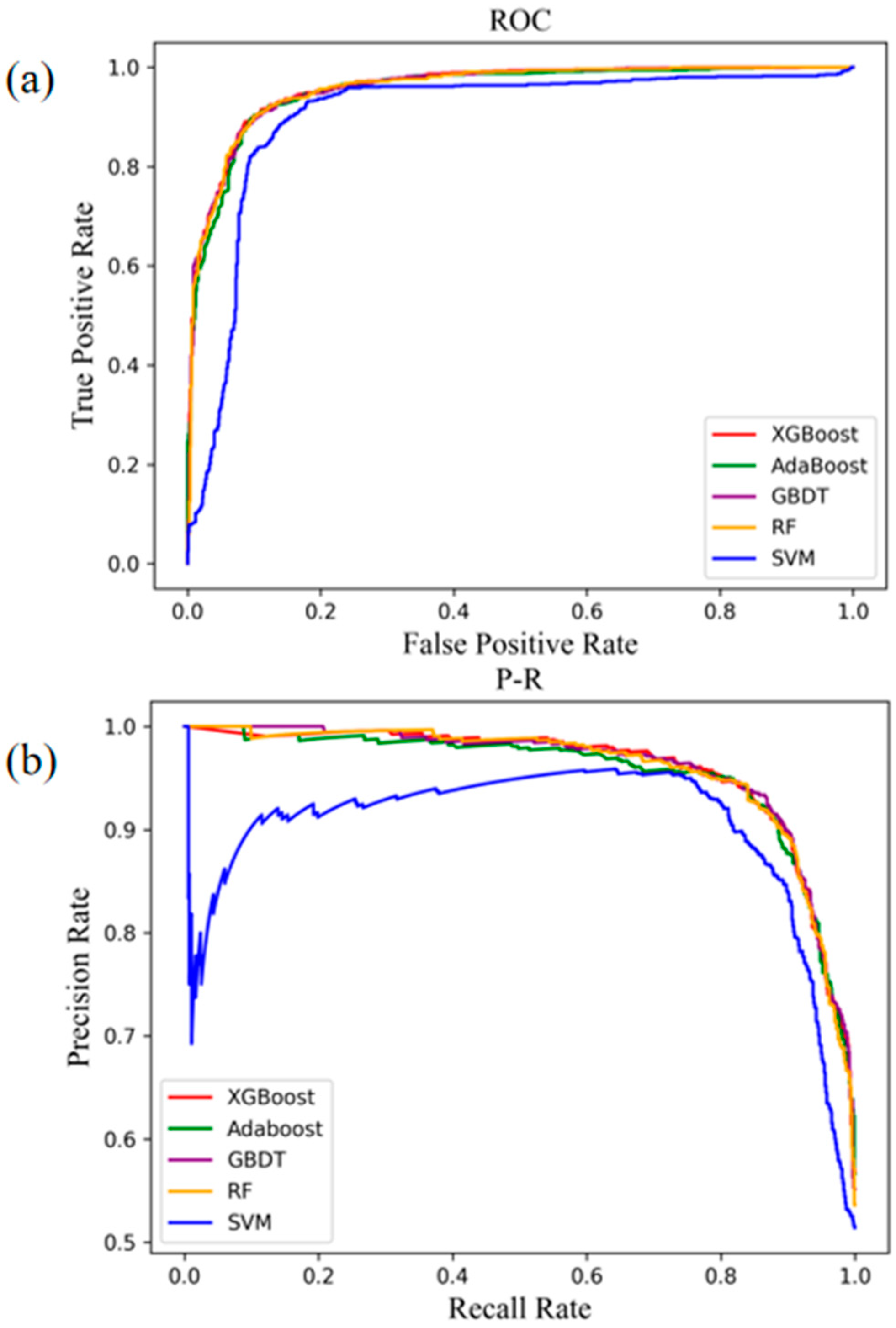
4.2. Comparison with Other Methods for Predicting Cross-Species OGs
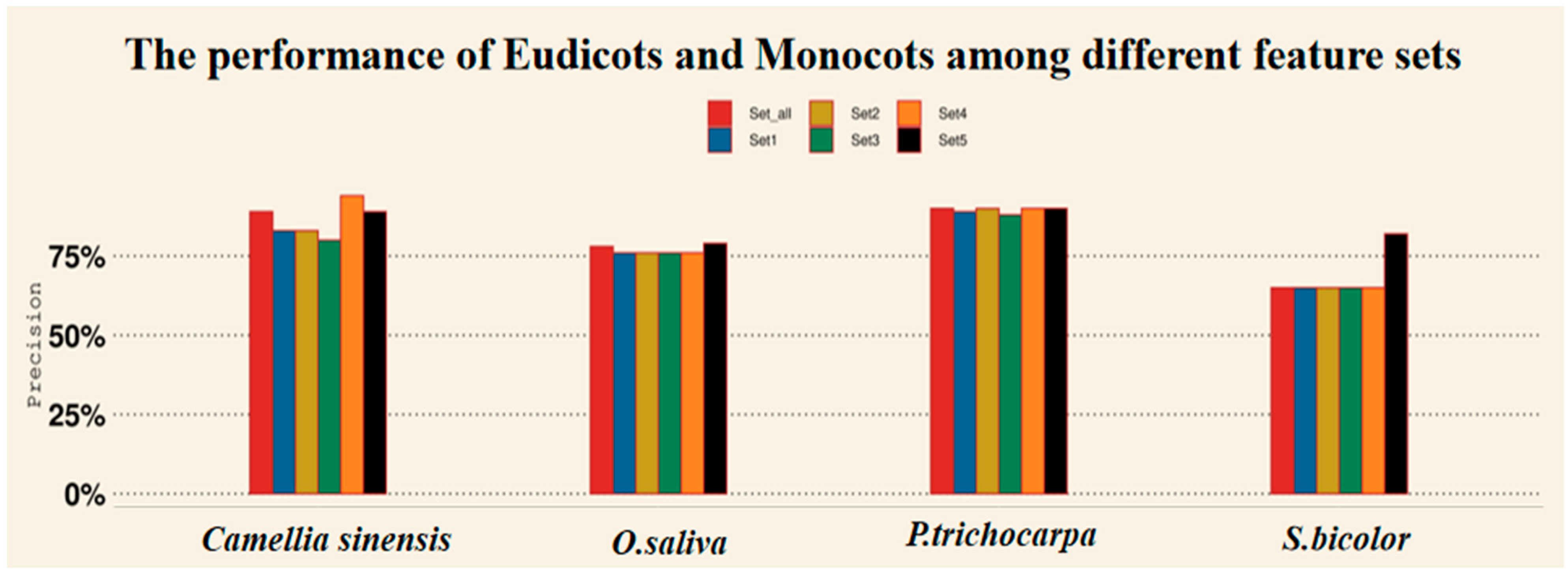
4.3. Predicting OGs with Different Feature Sets in Eudicot and Monocot Species via XGBoost-A2OGs
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bomblies, K.; Madlung, A. Polyploidy in the Arabidopsis genus. Chromosome Res. Int. J. Mol. Supramol. Evol. Asp. Chromosome Biol. 2014, 22, 117–134. [Google Scholar] [CrossRef] [PubMed]
- Wilson, G.A.; Bertrand, N.; Patel, Y.; Hughes, J.B.; Feil, E.J.; Field, D. Orphans as taxonomically restricted and ecologically important genes. Microbiology 2005, 151, 2499–2501. [Google Scholar] [CrossRef] [PubMed]
- Donoghue, M.T.A.; Keshavaiah, C.; Swamidatta, S.H.; Spillane, C. Evolutionary origins of Brassicaceae specific genes in Arabidopsis thaliana. BMC Evol. Biol. 2011, 11, 47. [Google Scholar] [CrossRef] [PubMed]
- Lin, W.L.; Cai, B.; Cheng, Z.M. Identification and characterization of lineage-specific genes in Populus trichocarpa. Plant Cell Tissue Organ Cult. 2013, 116, 217–225. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, G.; Hao, B.; Chen, L.; Deng, X.; Xu, Q. Identification, characterization and expression analysis of lineage-specific genes within sweet orange (Citrus sinensis). BMC Genom. 2015, 16, 995. [Google Scholar] [CrossRef]
- Perochon, A.; Kahla, A.; Vranić, M.; Jia, J.; Malla, K.B.; Craze, M.; Wallington, E.; Doohan, F.M. A wheat NAC interacts with an orphan protein and enhances resistance to Fusarium head blight disease. Plant Biotechnol. J. 2019, 17, 1892–1904. [Google Scholar] [CrossRef]
- Li, G.; Wu, X.; Hu, Y.; Muñoz-Amatriaín, M.; Luo, J.; Zhou, W.; Wang, B.; Wang, Y.; Wu, X.; Huang, L.; et al. OGs are involved in drought adaptations and ecoclimatic-oriented selections in domesticated cowpea. J. Exp. Bot. 2019, 70, 3101–3110. [Google Scholar] [CrossRef] [PubMed]
- Shen, S.; Peng, M.; Fang, H.; Wang, Z.; Zhou, S.; Jing, X.; Zhang, M.; Yang, C.; Guo, H.; Li, Y.; et al. An Oryza specific hydroxycinnamoyl tyramine gene cluster contributes to enhanced disease resistance. Sci. Bull. 2021, 66, 2369–2380. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Ma, D. Genome-wide identification, characterization and function analysis of lineage-specific genes in the tea plant Camellia sinensis. Front. Genet. 2021, 12, 770570. [Google Scholar] [CrossRef]
- Cardoso-Silva, C.B.; Aono, A.H.; Mancini, M.C.; Sforca, D.A.; da Silva, C.C.; Pinto, L.R.; de Souza, A.P. Taxonomically restricted genes are associated with responses to biotic and abiotic stresses in Sugarcane (Saccharum spp.). bioRxiv 2022. [Google Scholar] [CrossRef]
- Ma, S.W.; Yuan, Y.; Tao, Y.; Jia, H.Y.; Ma, Z.Q. Identification characterization and expression analysis of lineage-specific genes within Triticeae. Genomics 2020, 112, 1343–1350. [Google Scholar] [CrossRef] [PubMed]
- Arendsee, Z.W.; Li, L.; Wurtele, E.S. Coming of age: OGs in plants. Trends Plant Sci. 2014, 19, 698–708. [Google Scholar] [CrossRef] [PubMed]
- Jiang, M.; Li, X.; Dong, X.; Zu, Y.; Zhan, Z.; Iiao, Z.; Lang, H. Research advances and prospects of OGs in plants. Front. Plant Sci. 2022, 13, 947129. [Google Scholar] [CrossRef] [PubMed]
- O’Conner, S.; Neudorf, A.; Zheng, W.; Qi, M.; Zhao, X.; Du, C.; Nettleton, D.; Li, L. From Arabidopsis to crops: The Arabidopsis QQS orphan gene modulates nitrogen allocation across species. In Engineering Nitrogen Utilization in Crop Plants; Springer: Cham, Switzerland, 2018; pp. 95–117. [Google Scholar]
- Altschul, S.F.; Gish, W.; Miller, W.; Myers, E.W.; Lipman, D.J. Basic local alignment search tool. J. Mol. Biol. 1990, 215, 403–410. [Google Scholar] [CrossRef] [PubMed]
- Zhu, S.L.; Dong, J.; Zhang, C.; Huang, Y.B.; Pan, W. Application of machine learning in the diagnosis of gastric cancer based on noninvasive characteristics. PLoS ONE 2020, 15, e0244869. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Gao, Q.; Jin, X.; Xia, E.; Wu, X.; Gu, L.; Yan, H.; Xia, Y.; Li, S. Identification of orphan genes in unbalanced datasets based on ensemble learning. Front. Genet. 2020, 11, 820. [Google Scholar] [CrossRef]
- Casola, C.; Owoyemi, A.; Pepper, A.E.; Ioerger, T.R. Accurate identification of de novo genes in plant genomes using machine learning algorithms. bioRxiv 2022. [Google Scholar] [CrossRef]
- Zhang, X.; Xuan, J.; Yao, C.; Gao, Q.; Wang, L.; Jin, X.; Li, S. A deep learning approach for orphan gene identification in moso bamboo (Phyllostachys edulis) based on the CNN+ Transformer model. BMC Bioinform. 2022, 23, 162. [Google Scholar] [CrossRef]
- Carvunis, A.R.; Rolland, T.; Wapinski, I.; Calderwood, M.A.; Yildirim, M.A.; Simonis, N.; Charloteaux, B.; Hidalgo, C.A.; Barbette, J.; Santhanam, B.; et al. Proto-genes and de novo gene birth. Nature 2012, 487, 370–374. [Google Scholar] [CrossRef]
- Prabh, N.; Rödelsperger, C. De novo, divergence, and mixed origin contribute to the emergence of orphan genes in Pristionchus Nematodes. G3 2019, 9, 2277–2286. [Google Scholar] [CrossRef]
- Schlötterer, C. Genes from scratch-the evolutionary fate of de novo genes. Trends Genet. 2015, 31, 215–219. [Google Scholar] [CrossRef]
- Zhang, W.Y.; Gao, Y.X.; Long, M.Y.; Shen, B.R. Origination and evolution of orphan genes and de novo genes in the genome of Caenorhabditis elegans. Sci. China Life Sci. 2019, 62, 579–593. [Google Scholar] [CrossRef]
- Singh, U.; Wurtele, E.S. How new genes are born. Elife 2020, 9, e55136. [Google Scholar] [CrossRef]
- Albà, M.M.; Castresana, J. On homology searches by protein blast and the characterization of the age of genes. BMC Evol. Biol. 2007, 7, 53. [Google Scholar] [CrossRef]
- Domazet-Lošo, T.; Brajković, J.; Tautz, D. A phylostrati graphy approach to uncover the genomic history of major adaptations in metazoan lineages. Trends Genet. 2007, 23, 533–539. [Google Scholar] [CrossRef]
- Goodstein, D.M.; Shu, S.; Howson, R.; Neupane, R.; Hayes, R.D.; Fazo, J. Phytozome: A comparative platform for green plant genomics. Nucleic Acids Res. 2012, 40, D1178–D1186. [Google Scholar] [CrossRef]
- Wheeler, D.L.; Barrett, T.; Benson, D.A.; Bryant, S.H.; Canese, K.; Church, D.M.; Yaschenko, E. Database resources of the National Center for Biotechnology Information. Nucleic Acids Res. 2005, 33, D39–D45. [Google Scholar] [CrossRef]
- Bolser, D.; Staines, D.M.; Pritchard, E.; Kersey, P. Ensembl plants: Integrating tools for visualizing, mining, and analyzing plant genomics data. In Plant Bioinformatics; Humana Press: New York, NY, USA, 2016; pp. 115–140. [Google Scholar]
- Halim, Z. An ensemble filter-based heuristic approach for cancerous gene expression classification. Knowl.-Based Syst. 2021, 234, 107560. [Google Scholar]
- Ispandi, R.; Wahono, S. Application of genetic algorithms to optimize parameters in support vector machine to increase direct marketing predictions. J. Intell. Syst. 2015, 1, 115–119. [Google Scholar]
- Chaw, S.M.; Chang, C.C.; Chen, H.L.; Li, W.H. Dating the monocot dicot divergence and the origin of core eudicots using whole chloroplast genomes. J. Mol. Evol. 2004, 58, 424–441. [Google Scholar]
- Bowman, M.J.; Pulman, J.A.; Liu, T.L.; Childs, K.L. A modified GC-specific MAKER gene annotation method reveals improved and novel gene predictions of high and low GC content in Oryza sativa. BMC Bioinform. 2017, 18, 522. [Google Scholar] [CrossRef]
- Singh, R.; Ming, R.; Yu, Q. Comparative analysis of GC content variations in plant genomes. Trop. Plant Biol. 2016, 9, 136–149. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Real Positive | Real Negative | |
|---|---|---|
| Predict positive | TP | FP |
| Predict negative | FN | TN |
| Index | SVM | RF | GBDT | AdaBoost | XGBoost |
|---|---|---|---|---|---|
| Accuracy | 0.88 | 0.85 | 0.88 | 0.88 | 0.91 |
| Precision | 0.86 | 0.79 | 0.87 | 0.87 | 0.90 |
| Recall | 0.91 | 0.97 | 0.89 | 0.88 | 0.91 |
| F1-Score | 0.88 | 0.87 | 0.88 | 0.88 | 0.91 |
| Type | Species | Filter Method | Precision | Accuracy | AUC |
|---|---|---|---|---|---|
| Eudicots | P. trichocarpa | variation | 0.92 | 0.93 | 0.94 |
| Eudicots | P. trichocarpa | Chi2 | 0.9 | 0.92 | 0.94 |
| Eudicots | Camellia sinensis | variation | 0.82 | 0.69 | 0.85 |
| Eudicots | Camellia sinensis | Chi2 | 0.82 | 0.69 | 0.85 |
| Monocots | O. sativa | variation | 0.78 | 0.83 | 0.9 |
| Monocots | O. sativa | Chi2 | 0.78 | 0.83 | 0.9 |
| Monocots | S. bicolor | variation | 0.81 | 0.87 | 0.94 |
| Monocots | S. bicolor | Chi2 | 0.81 | 0.87 | 0.94 |
| Type | Species | Feature | Precision | Accuracy | AUC |
|---|---|---|---|---|---|
| Eudicots | P. trichocarpa | Set_all | 0.9 | 0.9 | 0.92 |
| Eudicots | P. trichocarpa | Set1 | 0.89 | 0.87 | 0.89 |
| Eudicots | P. trichocarpa | Set2 | 0.9 | 0.9 | 0.91 |
| Eudicots | P. trichocarpa | Set3 | 0.88 | 0.9 | 0.92 |
| Eudicots | P. trichocarpa | Set4 | 0.9 | 0.9 | 0.94 |
| Eudicots | P. trichocarpa | Set5 | 0.9 | 0.92 | 0.94 |
| Eudicots | Camellia sinensis | Set_all | 0.89 | 0.74 | 0.85 |
| Eudicots | Camellia sinensis | Set1 | 0.83 | 0.68 | 0.84 |
| Eudicots | Camellia sinensis | Set2 | 0.83 | 0.69 | 0.82 |
| Eudicots | Camellia sinensis | Set3 | 0.80 | 0.69 | 0.85 |
| Eudicots | Camellia sinensis | Set4 | 0.94 | 0.76 | 0.87 |
| Eudicots | Camellia sinensis | Set5 | 0.89 | 0.74 | 0.88 |
| Type | Species | Feature | Precision | Accuracy | AUC |
|---|---|---|---|---|---|
| Monocots | O. sativa | Set_all | 0.78 | 0.83 | 0.9 |
| Monocots | O. sativa | Set1 | 0.76 | 0.81 | 0.9 |
| Monocots | O. sativa | Set2 | 0.76 | 0.81 | 0.88 |
| Monocots | O. sativa | Set3 | 0.76 | 0.81 | 0.93 |
| Monocots | O. sativa | Set4 | 0.76 | 0.81 | 0.9 |
| Monocots | O. sativa | Set5 | 0.79 | 0.83 | 0.9 |
| Monocots | S. bicolor | Set_all | 0.65 | 0.73 | 0.6 |
| Monocots | S. bicolor | Set1 | 0.65 | 0.73 | 0.6 |
| Monocots | S. bicolor | Set2 | 0.65 | 0.73 | 0.62 |
| Monocots | S. bicolor | Set3 | 0.65 | 0.73 | 0.62 |
| Monocots | S. bicolor | Set4 | 0.65 | 0.73 | 0.6 |
| Monocots | S. bicolor | Set5 | 0.82 | 0.87 | 0.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Q.; Zhang, X.; Yan, H.; Jin, X. Machine Learning-Based Prediction of Orphan Genes and Analysis of Different Hybrid Features of Monocot and Eudicot Plants. Electronics 2023, 12, 1433. https://doi.org/10.3390/electronics12061433
Gao Q, Zhang X, Yan H, Jin X. Machine Learning-Based Prediction of Orphan Genes and Analysis of Different Hybrid Features of Monocot and Eudicot Plants. Electronics. 2023; 12(6):1433. https://doi.org/10.3390/electronics12061433
Chicago/Turabian StyleGao, Qijuan, Xiaodan Zhang, Hanwei Yan, and Xiu Jin. 2023. "Machine Learning-Based Prediction of Orphan Genes and Analysis of Different Hybrid Features of Monocot and Eudicot Plants" Electronics 12, no. 6: 1433. https://doi.org/10.3390/electronics12061433
APA StyleGao, Q., Zhang, X., Yan, H., & Jin, X. (2023). Machine Learning-Based Prediction of Orphan Genes and Analysis of Different Hybrid Features of Monocot and Eudicot Plants. Electronics, 12(6), 1433. https://doi.org/10.3390/electronics12061433