
A Semantic Learning-Based SQL Injection Attack Detection Technology

Abstract
1. Introduction
- (i)
- We collect a more comprehensive malicious dataset, covering the full range of SQL injection attacks. Moreover, benign samples are selected not only from the plain text but also from normal SQL statements. This method has the potential to reduce the number of false alarms.
- (ii)
- For raw traffic, we detect injection attacks not only in URL fields but also in request body and request header fields. To some extent, this reduces the possibility of underreporting.
- (iii)
- (iv)
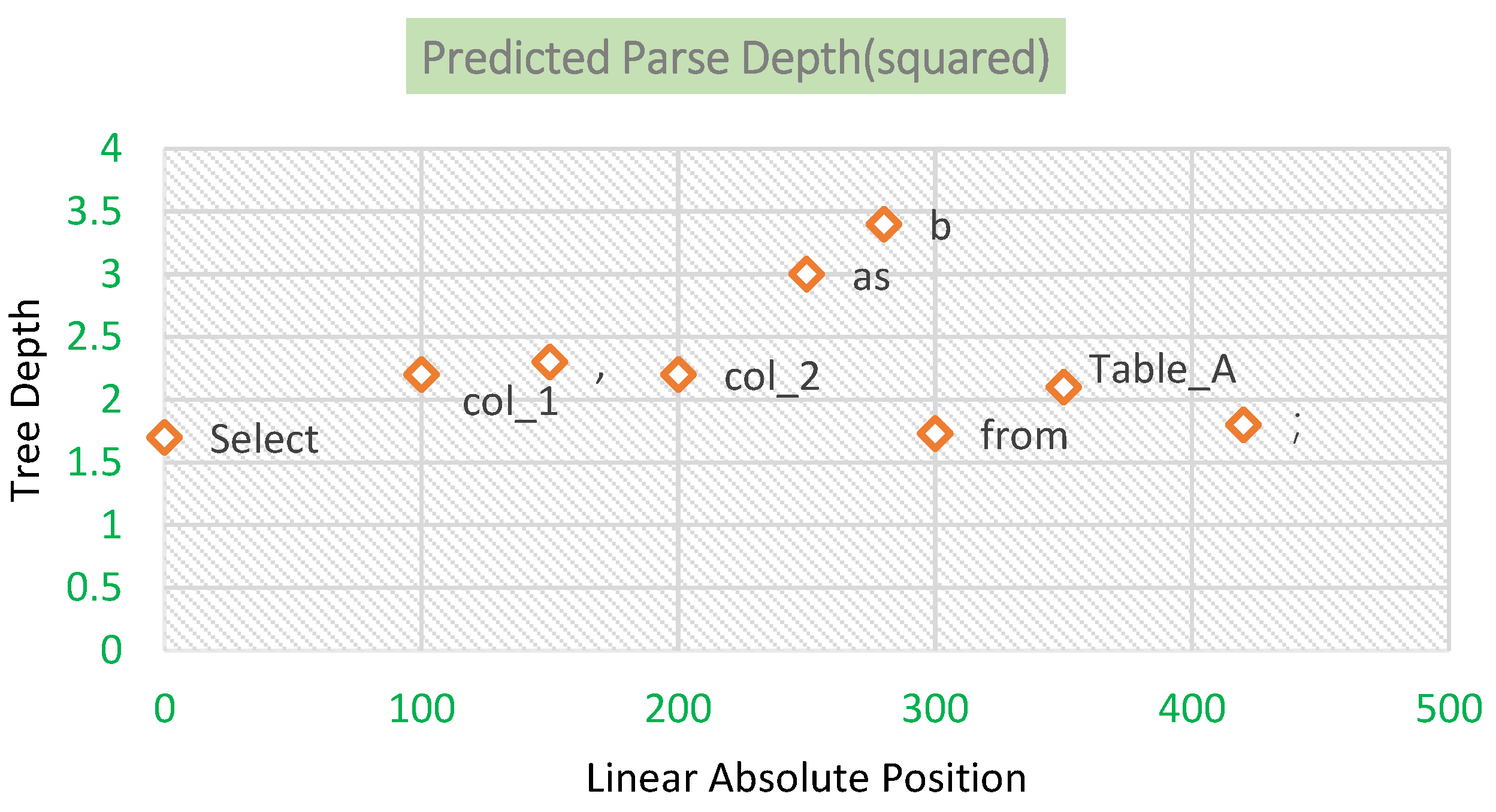
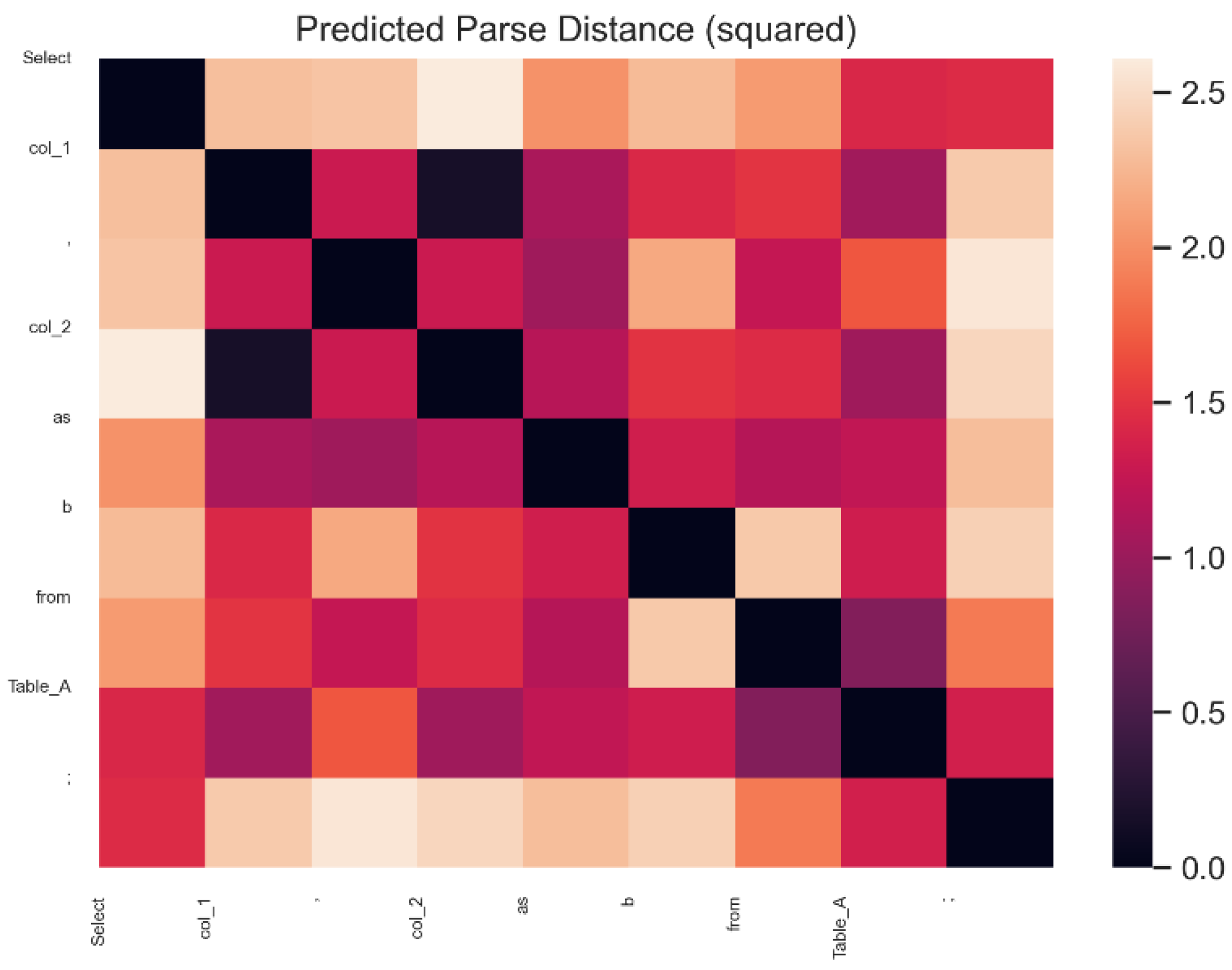
- We use a structural probe to assess how well the synBERT model learns sentence-level semantic information, and we visualize it with heat maps and tree maps.
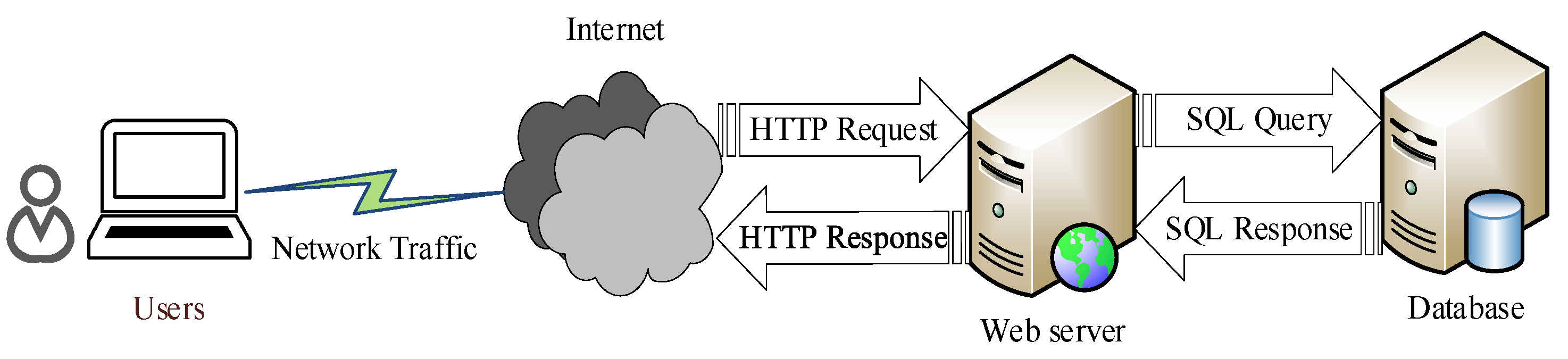
2. Background and Related Work
2.1. SQL Injection Attacks
- (a)
- SQL+ Distributed Denial of Service (DDoS): This attack is used to hang the server and exhaust the resources so that users cannot access it. To track the DDoS attack, the commands that can be used in SQL injection are encoding, compression, connection, etc.
- (b)
- SQL+ Domain Name System (DNS) Hijacking: By using this type of attack, the attacker intends to embed a SQL query in the DNS request and capture it to make it propagate across the internet.
- (c)
- SQL+ Cross Site Scripting (XSS): XSS is a client-side code injection attack where an attacker can inject malicious code into the input fields of an application. After inserting the XSS script, it will execute and try to connect to the application’s database. The code to extract the data from the database can be obtained using the iframe command [11].
- (d)
- SQL+ Insufficient authentication: if the security parameters are not initialized, an attacker can access sensitive content without verifying the user’s identity. So attackers exploit this vulnerability to inject SQL injection code.
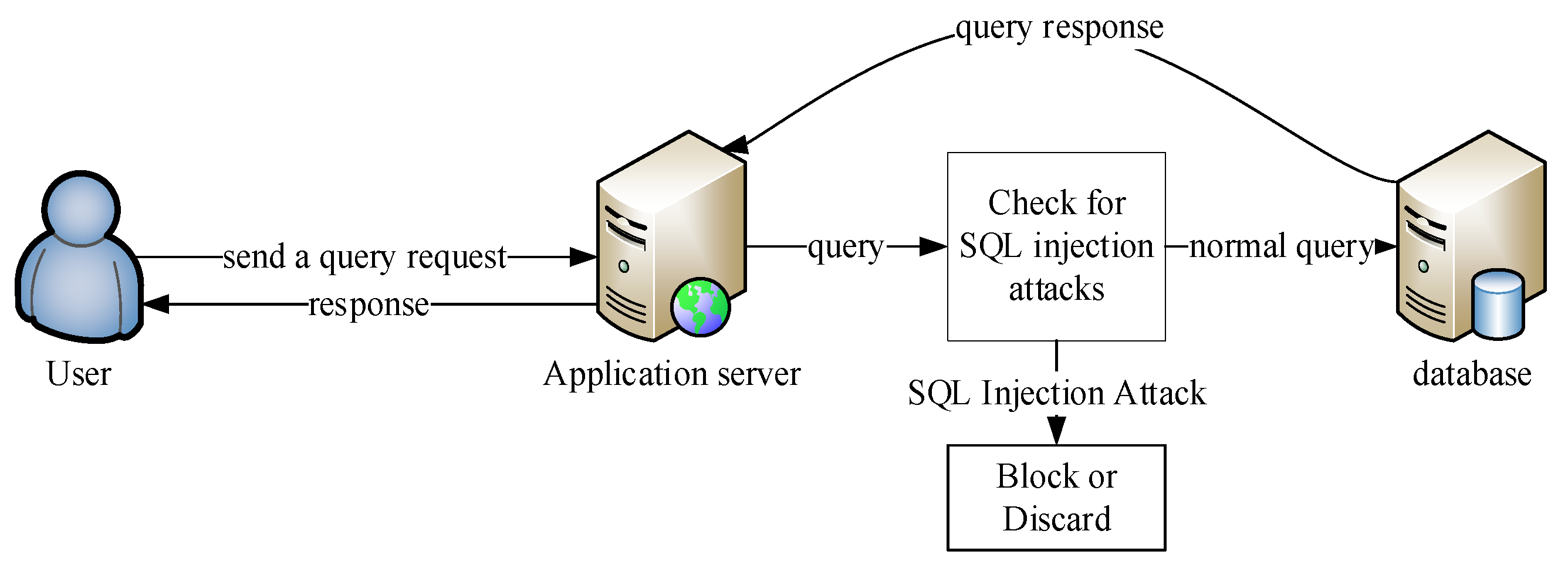
2.2. Traditional Detection Methods
2.3. Artificial Intelligence-Based Detection Methods
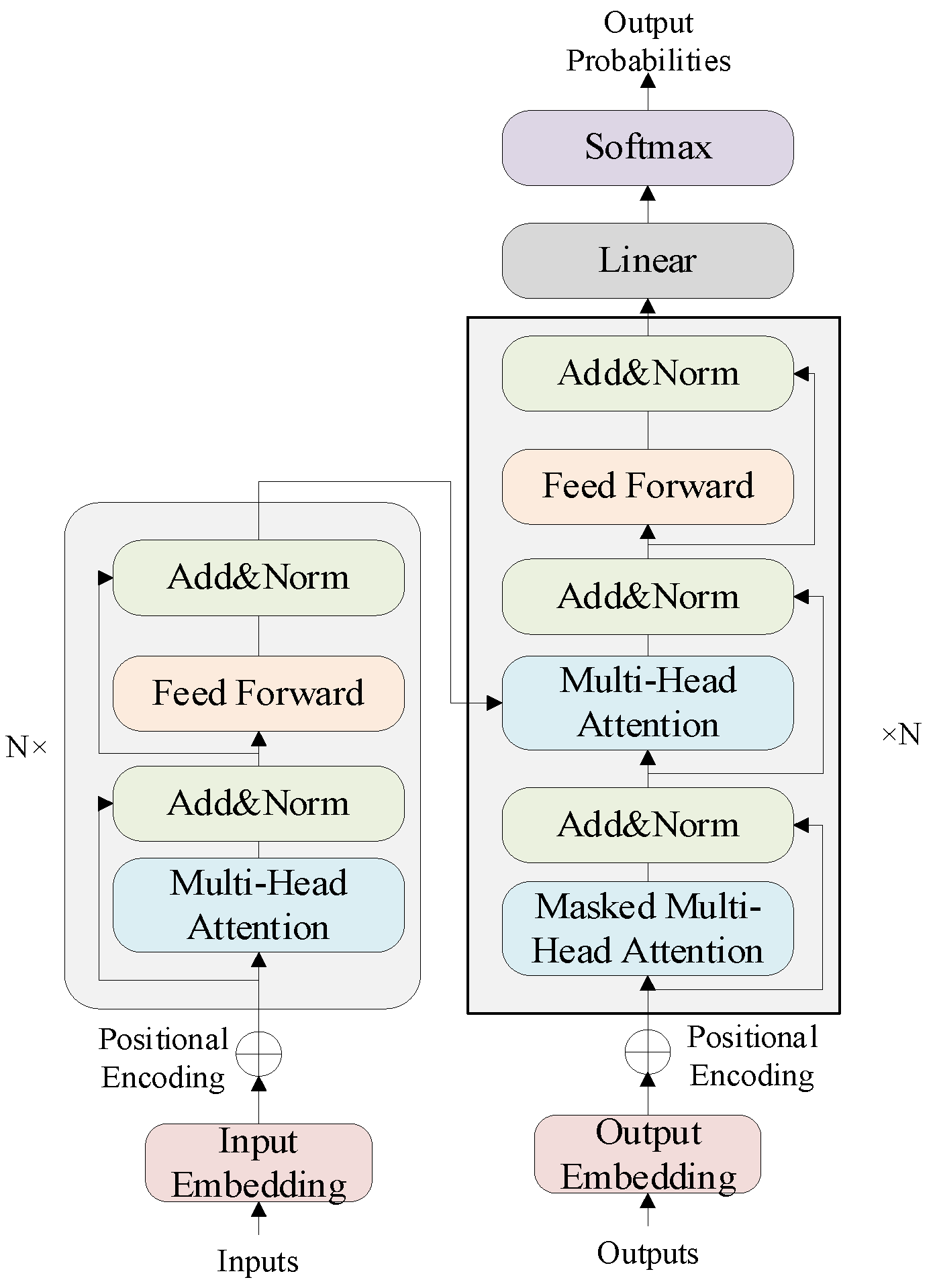
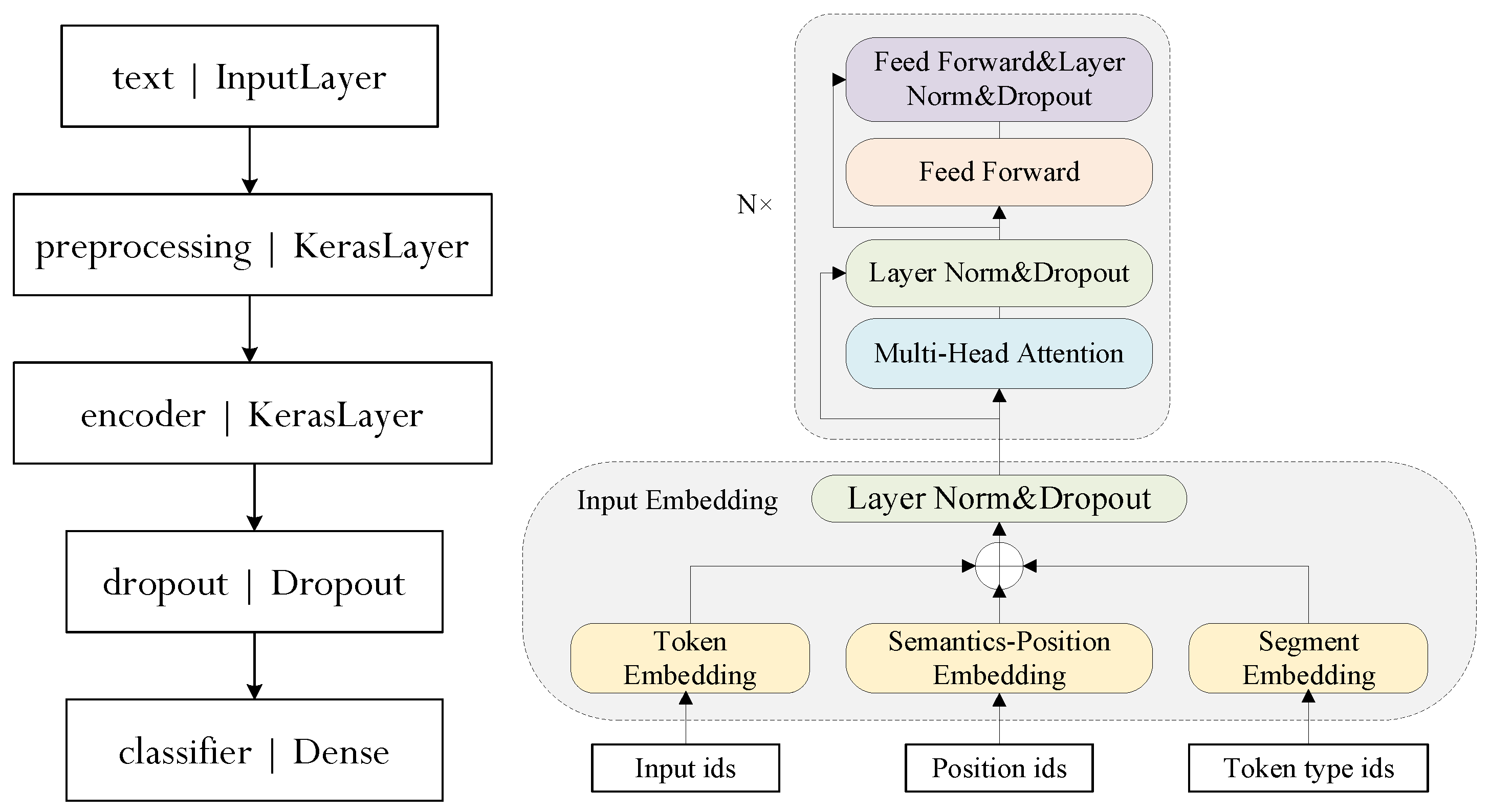
3. Detection Model synBERT
4. Structure Probe
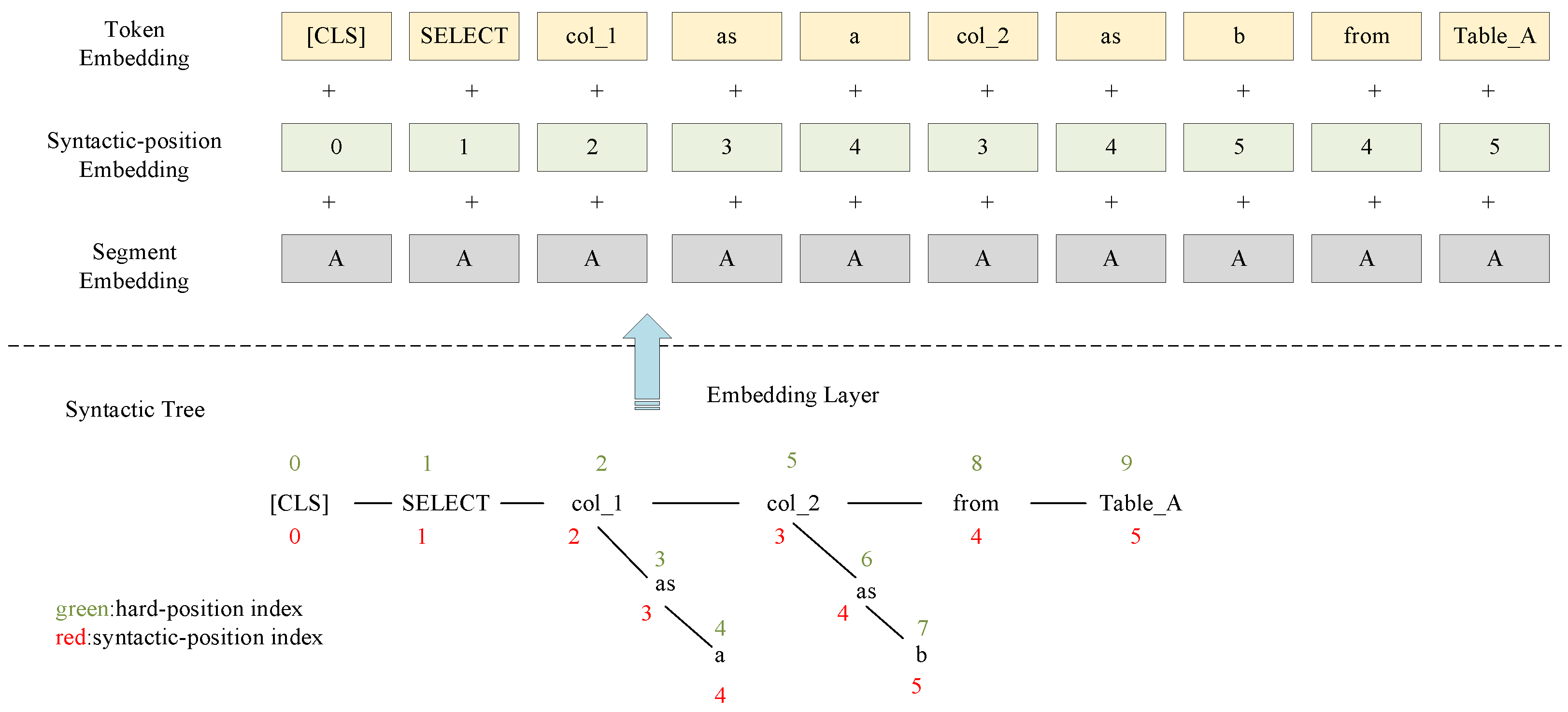
4.1. Syntax Tree of SQL Statements
| |- 0 DML ‘Select’ |- 1 Whitespace ‘ ’‘ |- 2 IdentifierList ‘col_1,… ‘ |- 0 Identifier ‘col_1’ | `- 0 Name ‘col_1’ |- 1 Punctuation ‘,’ |- 2 Whitespace ‘ ’ | `- 3 Identifier ‘col_2,…’ |- 0 Name ‘col_2’ |- 1 Whitespace ‘ ’ |- 2 Keyword ‘as’ |- 3 Whitespace ‘ ’ | `- 4 Identifier ‘b’ | `- 0 Name ‘b’ |- 3 Whitespace ‘ ’ |- 4 Keyword ‘from’ |- 5 Whitespace ‘ ’ |- 6 Identifier ‘DT_A’ | `- 0 Name ‘ DT_A’ `- 7 Punctuation ‘;’ |
4.2. Structure Probe for synBERT
| Algorithm 1: Structure Probe Resolution Dependency Algorithm |
| Input: Sentence of n words , a sequence of vector representations , a linear transformation , a positive semidefinite symmetric matrix Output: parse depth Steps:
|
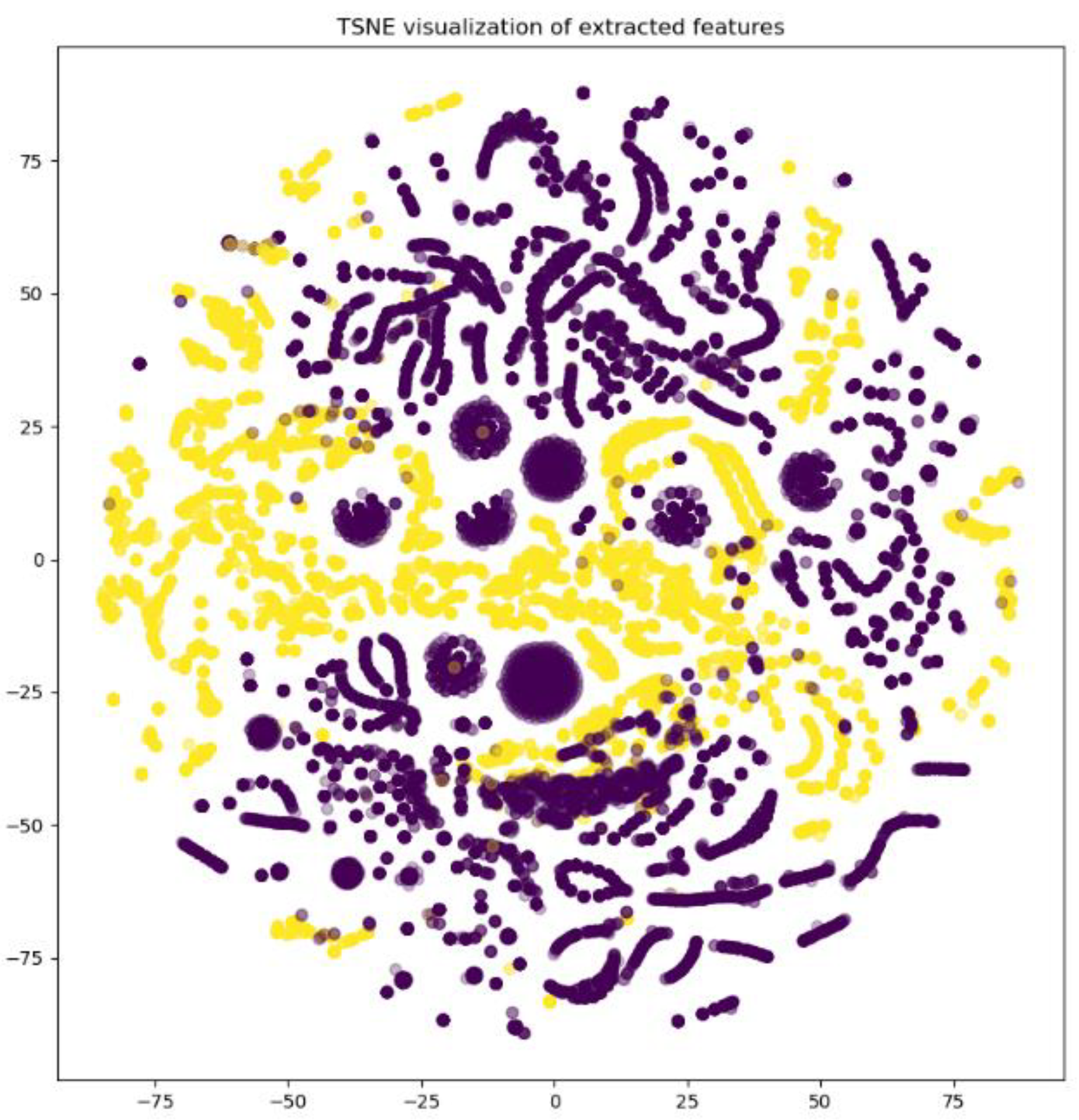
5. Experimental Results and Analysis
5.1. Evaluation Indicators
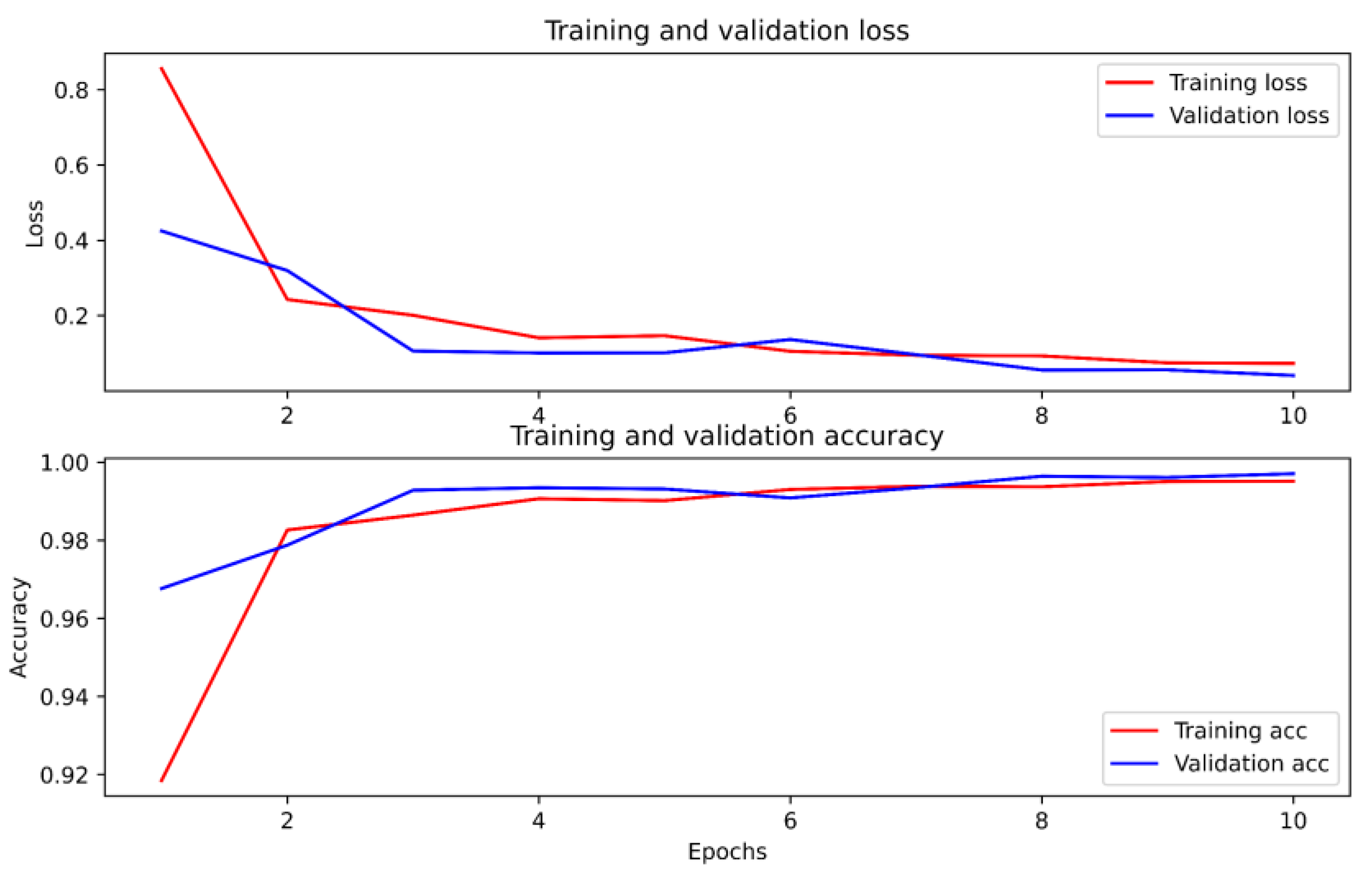
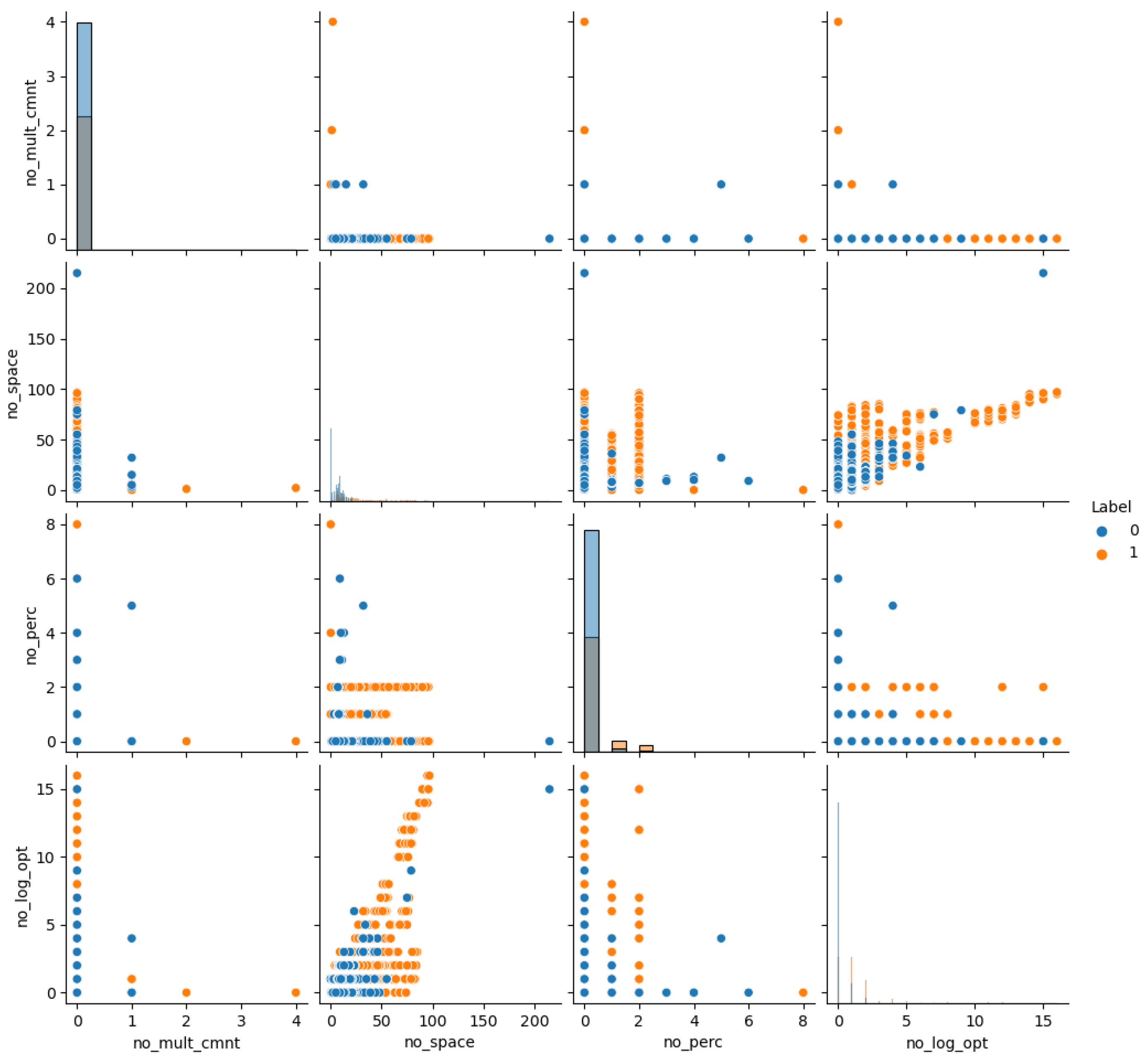
5.2. Dataset Evaluation
5.3. Generalizability Testing
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, D.; Yan, Q.; Wu, C.; Zhao, J. SQL Injection Attack Detection and Prevention Techniques Using Deep Learning. J. Phys. Conf. Ser. 2021, 1757, 012055. [Google Scholar] [CrossRef]
- Salih, N.; Samad, A. Protection Web Applications Using Real-Time Technique to Detect Structured Query Language Injection Attacks. IJCA 2016, 149, 26–32. [Google Scholar] [CrossRef]
- Abdulqadir, H.R.; Zeebaree, S.R.; Shukur, H.M.; Sadeeq, M.M.; Salim, B.W.; Salih, A.A.; Kak, S.F. A Study of Moving from Cloud Computing to Fog Computing. QAJ 2021, 1, 60–70. [Google Scholar] [CrossRef]
- Zhu, Z.; Jia, S.; Li, J.; Qin, S.; Guo, H. SQL Injection Attack Detection Framework Based on HTTP Traffic. In Proceedings of the ACM Turing Award Celebration Conference—China (ACM TURC 2021), Hefei China, 30 July 2021; ACM: Rochester, NY, USA, 2021; pp. 179–185. [Google Scholar]
- Jothi, K.R.; Pandey, N.; Beriwal, P.; Amarajan, A. An Efficient SQL Injection Detection System Using Deep Learning. In Proceedings of the 2021 International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, 17 March 2021; IEEE: Piscataway, NJ, USA, 2017; pp. 442–445. [Google Scholar]
- Li, Q.; Wang, F.; Wang, J.; Li, W. LSTM-Based SQL Injection Detection Method for Intelligent Transportation System. IEEE Trans. Veh. Technol. 2019, 68, 4182–4191. [Google Scholar] [CrossRef]
- Zhuo, Z.; Cai, T.; Zhang, X.; Lv, F. Long Short-term Memory on Abstract Syntax Tree for SQL Injection Detection. IET Softw. 2021, 15, 188–197. [Google Scholar] [CrossRef]
- Tang, P.; Qiu, W.; Huang, Z.; Lian, H.; Liu, G. Detection of SQL Injection Based on Artificial Neural Network. Knowl.-Based Syst. 2020, 190, 105528. [Google Scholar] [CrossRef]
- Li, Q.; Li, W.; Wang, J.; Cheng, M. A SQL Injection Detection Method Based on Adaptive Deep Forest. IEEE Access 2019, 7, 145385–145394. [Google Scholar] [CrossRef]
- Hassan, R.J.; Zeebaree, S.R.M.; Ameen, S.Y.; Kak, S.F.; Sadeeq, M.A.M.; Ageed, Z.S.; AL-Zebari, A.; Salih, A.A. State of Art Survey for IoT Effects on Smart City Technology: Challenges, Opportunities, and Solutions. AJRCoS 2021, 8, 32–48. [Google Scholar] [CrossRef]
- Singh, J.P. Analysis of SQL Injection Detection Techniques. Theor. Appl. Inf. 2017, 28, 37–55. [Google Scholar] [CrossRef]
- Rodríguez, G.E.; Torres, J.G.; Flores, P.; Benavides, D.E. Cross-Site Scripting (XSS) Attacks and Mitigation: A Survey. Comput. Netw. 2020, 166, 106960. [Google Scholar] [CrossRef]
- Fu, X.; Lu, X.; Peltsverger, B.; Chen, S.; Qian, K.; Tao, L. A Static Analysis Framework For Detecting SQL Injection Vulnerabilities. In Proceedings of the 31st Annual International Computer Software and Applications Conference—Vol. 1—(COMPSAC 2007), Beijing, China, 24–27 July 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 87–96. [Google Scholar]
- Pan, Y.; Sun, F.; Teng, Z.; White, J.; Schmidt, D.C.; Staples, J.; Krause, L. Detecting Web Attacks with End-to-End Deep Learning. J. Internet Serv. Appl. 2019, 10, 16. [Google Scholar] [CrossRef]
- Shin, Y. Improving the Identification of Actual Input Manipulation Vulnerabilities. In Proceedings of the 14th ACM SIGSOFT Symposium on Foundations of Software Engineering ACM, Portland, OR, USA, 5–11 November 2006. [Google Scholar]
- Qu, B.; Liang, B.; Jiang, S.; Ye, C. Design of Automatic Vulnerability Detection System for Web Application Program. In Proceedings of the 2013 IEEE 4th International Conference on Software Engineering and Service Science, Beijing, China, 23–25 May 2013; IEEE: Piscataway, NJ, USA; pp. 89–92. [Google Scholar]
- Mui, R.; Frankl, P. Preventing SQL Injection through Automatic Query Sanitization with ASSIST. Electron. Proc. Theor. Comput. Sci. 2010, 35, 27–38. [Google Scholar] [CrossRef]
- Halfond, W.G.J.; Orso, A. AMNESIA: Analysis and Monitoring for NEutralizing SQL-Injection Attacks. In Proceedings of the 20th IEEE/ACM International Conference on Automated Software Engineering, Long Beach, CA, USA, 7 November 2005; ACM: Rochester, NY, USA, 2005; pp. 174–183. [Google Scholar]
- Qing, W.; He, C. The Research of an AOP-Based Approach to the Detection and Defense of SQL Injection Attack. In Proceedings of the 2016 International Conference on Advanced Electronic Science and Technology (AEST 2016), Shenzhen, China, 19–21 August 2016; Atlantis Press: Dordrecht, The Netherlands, 2016. [Google Scholar]
- Li, L.; Qi, J.; Liu, N.; Han, L.; Cui, B. Static-Based Test Case Dynamic Generation for SQLIVs Detection. In Proceedings of the 2015 10th International Conference on Broadband and Wireless Computing, Communication and Applications (BWCCA), Krakow, Poland, 4–6 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 173–177. [Google Scholar]
- Katole, R.A.; Sherekar, S.S.; Thakare, V.M. Detection of SQL Injection Attacks by Removing the Parameter Values of SQL Query. In Proceedings of the 2018 2nd International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 19–20 January 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 736–741. [Google Scholar]
- Makiou, A.; Begriche, Y.; Serhrouchni, A. Improving Web Application Firewalls to Detect Advanced SQL Injection Attacks. In Proceedings of the 2014 10th International Conference on Information Assurance and Security, Okinawa, Japan, 28–30 November 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 35–40. [Google Scholar]
- Choi, J.; Kim, H.; Choi, C.; Kim, P. Efficient Malicious Code Detection Using N-Gram Analysis and SVM. In Proceedings of the 2011 14th International Conference on Network-Based Information Systems, Tirana, Albania, 7–9 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 618–621. [Google Scholar]
- Deva Priyaa, B.; Devi, M.I. Fragmented Query Parse Tree Based SQL Injection Detection System for Web Applications. In Proceedings of the 2016 International Conference on Computing Technologies and Intelligent Data Engineering (ICCTIDE’16), Kovilpatti, India, 7–9 January 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5. [Google Scholar]
- Stalmans, E.; Irwin, B. A Framework for DNS Based Detection and Mitigation of Malware Infections on a Network. In Proceedings of the 2011 Information Security for South Africa, Johannesburg, South Africa, 15–17 August 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–8. [Google Scholar]
- Fang, Y.; Peng, J.; Liu, L.; Huang, C. WOVSQLI: Detection of SQL Injection Behaviors Using Word Vector and LSTM. In Proceedings of the 2nd International Conference on Cryptography, Security and Privacy, Guiyang, China, 16 March 2018; ACM: Rochester, NY, USA; pp. 170–174. [Google Scholar]
- Gong, X.; Zhou, Y.; Bi, Y.; He, M.; Sheng, S.; Qiu, H.; He, R.; Lu, J. Estimating Web Attack Detection via Model Uncertainty from Inaccurate Annotation. In Proceedings of the 2019 6th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2019 5th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), Paris, France, 21–23 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 53–58. [Google Scholar]
- Liu, M.; Li, K.; Chen, T. DeepSQLi: Deep Semantic Learning for Testing SQL Injection. In Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual Event USA, 18 July 2020; ACM: Rochester, NY, USA; pp. 286–297. [Google Scholar]
- Abdulmalik, Y. An Improved SQL Injection Attack Detection Model Using Machine Learning Techniques. Int. J. Innov. Comput. 2021, 11, 53–57. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding 2019. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the NIPS’13: Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Linzen, T.; Dupoux, E.; Goldberg, Y. Assessing the Ability of LSTMs to Learn Syntax-Sensitive Dependencies. TACL 2016, 4, 521–535. [Google Scholar] [CrossRef]
- Vig, J. Visualizing Attention in Transformer-Based Language Representation Models 2019. arXiv 2019, arXiv:1904.02679. [Google Scholar]
- Hewitt, J.; Manning, C.D. A Structural Probe for Finding Syntax in Word Representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Coenen, A.; Reif, E.; Yuan, A.; Kim, B.; Pearce, A.; Viégas, F.; Wattenberg, M. Visualizing and Measuring the Geometry of BERT 2019. arXiv 2019. [Google Scholar] [CrossRef]
- Farooq, U. Ensemble Machine Learning Approaches for Detection of SQL Injection Attack. Teh. Glas. 2021, 15, 112–120. [Google Scholar] [CrossRef]
- Chen, Z.; Guo, M.; Zhou, L. Research on SQL Injection Detection Technology Based on SVM. MATEC Web Conf. 2018, 173, 01004. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Base Types and Sub-Attributes | Examples | Example of Regular Expressions |
|---|---|---|
| Comment | -- | --|)#\+.*?(\r\n|\r|\n|$ |
| Assignment | var:=val | := |
| Operator | + | [+/@#%^&|^-]+ |
| Comparison | =, > | [<>=~!]+ |
| Text | \r\n | “.*?” |
| Whitespace | \s | |
| Newline | \r | \r\n|\r|\n |
| Punctuation | ; : ( ) [ ] , . | [;:()\ [\ ],\…] |
| Keyword | from, GROUP BY | CASE|IN|VALUES|USING|FROM|GROUP\s+BY |
| DDL | CREATE, ALTER | CREATE(\s+OR\s+REPLACE)?\b |
| DML | SELECT, UPDATE | SELECT|INSERT|UPDATE|DELETE |
| Name | c | (?<![\w\])])(\ [[^\ ]\ []+\ ]) |
| Placeholder | ?, * | (?<!\w)[$:?]\w+ |
| Literal | hello | \d+|\w+|.+ |
| String | aaaa | ‘\’.*?\’ |
| Number | 111 | \d |
| Identifier | database, table, column | \w |
| Wildcard | * | \* |
| Predicted | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual | Positive | TP | FN |
| Negative | FP | TN | |
| Type | Malicious | Benign |
|---|---|---|
| MySQL | 896 | 3155 |
| Oracle | 1035 | |
| SQL Server | 957 | |
| PostgreSQL | 48 | |
| Plain Text | / | |
| Total | 2936 | 3155 |
| Coding Methods | Before Decoding | After Decoding |
|---|---|---|
| URL decoding | ?id=1%20union%20Select%201,2,group_concat(concat(username,0x7e,password))%20from%20iwebsec.users%0A1%0A | ?id=1 union Select 1,2,group_concat(concat(username,0x7e,password)) from iwebsec.users |
| UNICODE decoding | se%u006cect | select |
| BASE64 decoding | 4oCdIHVuaW9uIHNlbGVjdCAxLDIsZGF0YWJhc2UoKSM= | union select 1,2,database()# |
| Parameters | Parameter Meaning | Parameter Value |
|---|---|---|
| num_hidden_size | number of hidden layer neurons | 256 |
| num_hidden_layers | number of hidden layers in Transformer encoder | 2 |
| num_attention_heads | number of heads in multi-head attention | 4 |
| hidden_func | hidden layer activation function | gelu |
| hidden_dropout | hidden layer dropout rate | 0.1 |
| attention_dropout | dropout rate of the attention | 0.1 |
| epoch | number of training epochs | 10 |
| Feature | Meaning | |
|---|---|---|
| 1 | query_len | Length of each query |
| 2 | num_word_query | The total number of words in a query |
| 3 | no_single_qts | The number of single quotes in the query |
| 4 | no_double_qts | The number of double quotes in the query |
| 5 | no_punct | Total number of punctuation marks in a query |
| 6 | no_single_cmnt | Number of single line comments in the query |
| 7 | no_double_cmnt | Number of multi-line comments in the query |
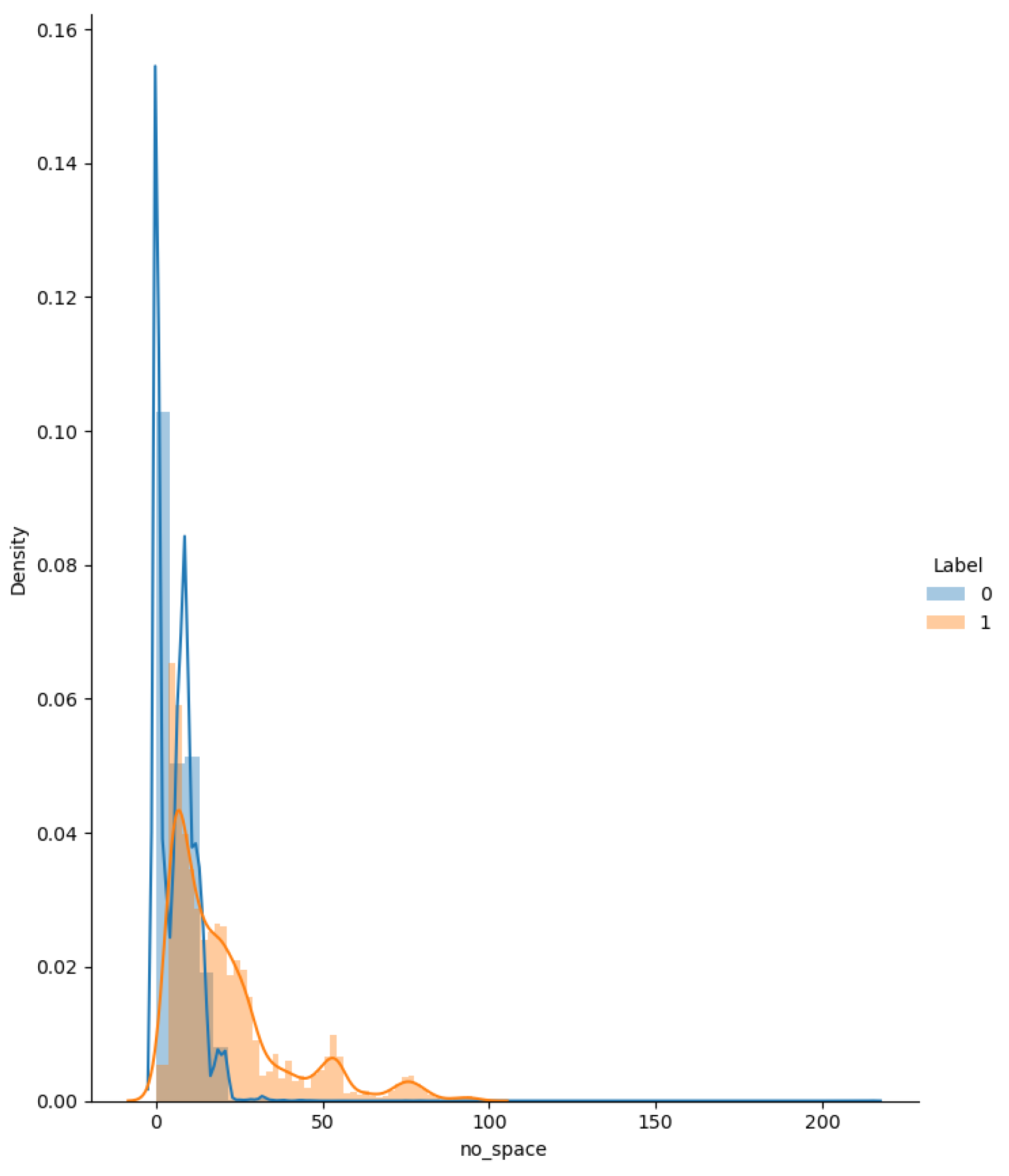
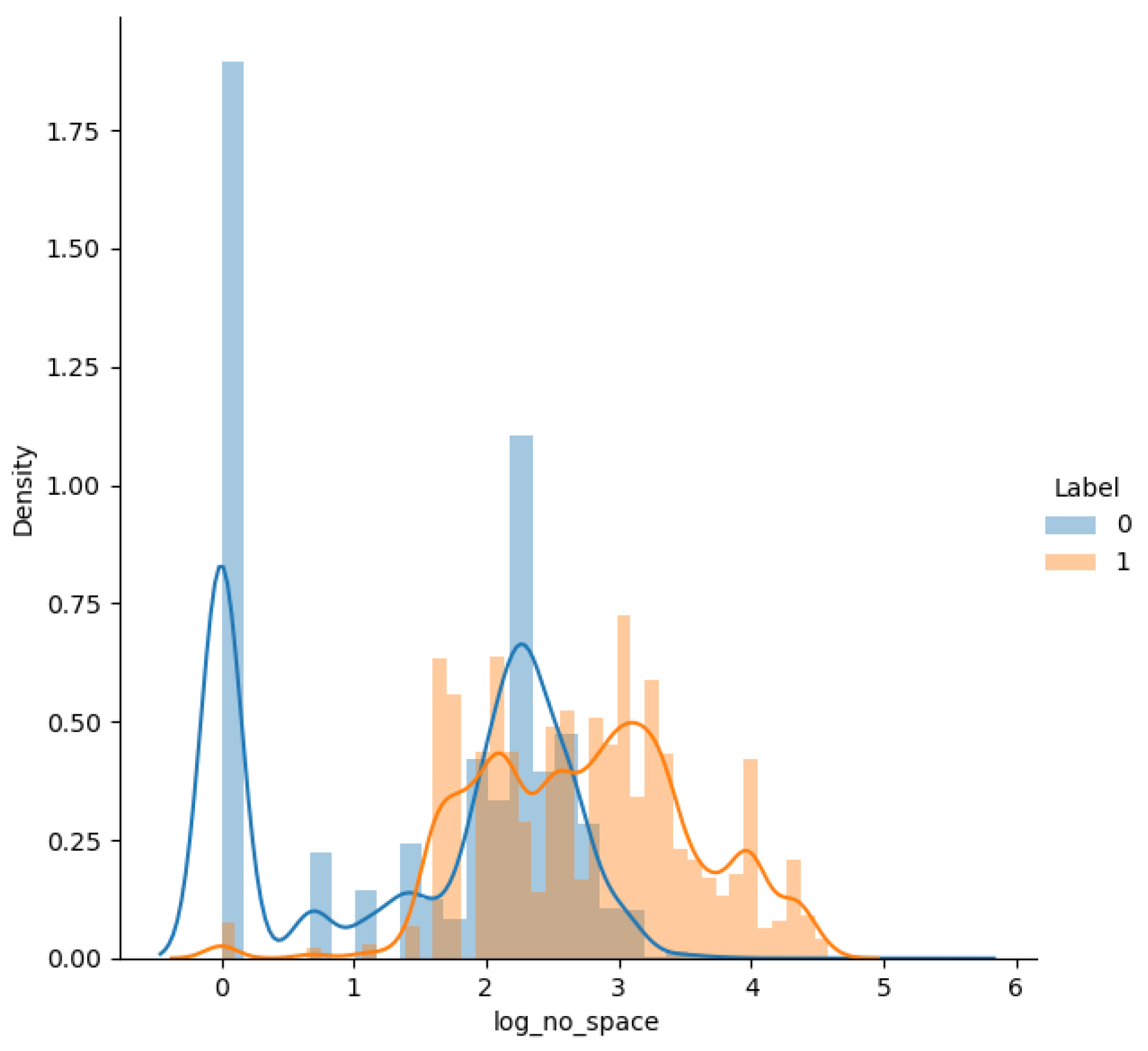
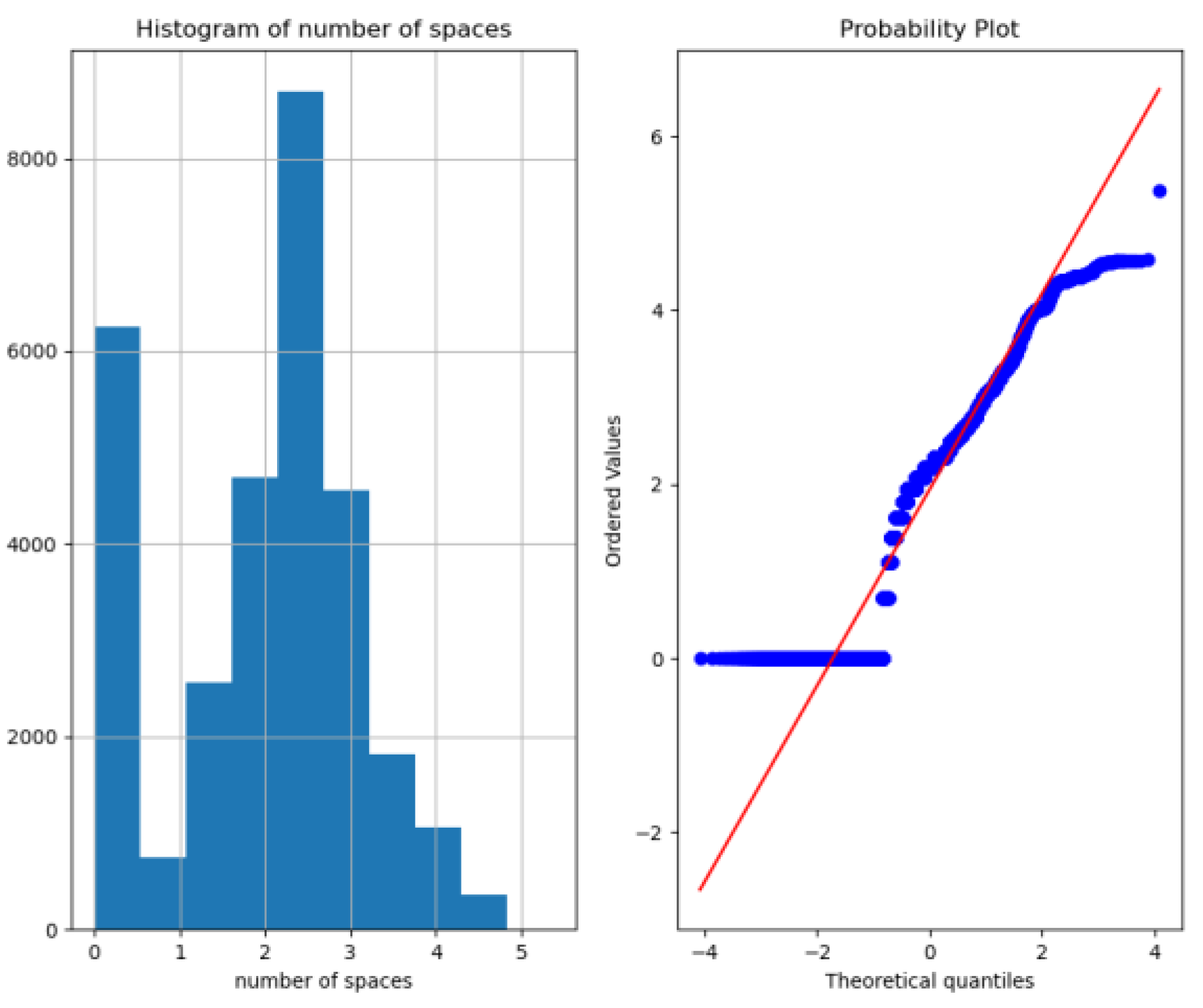
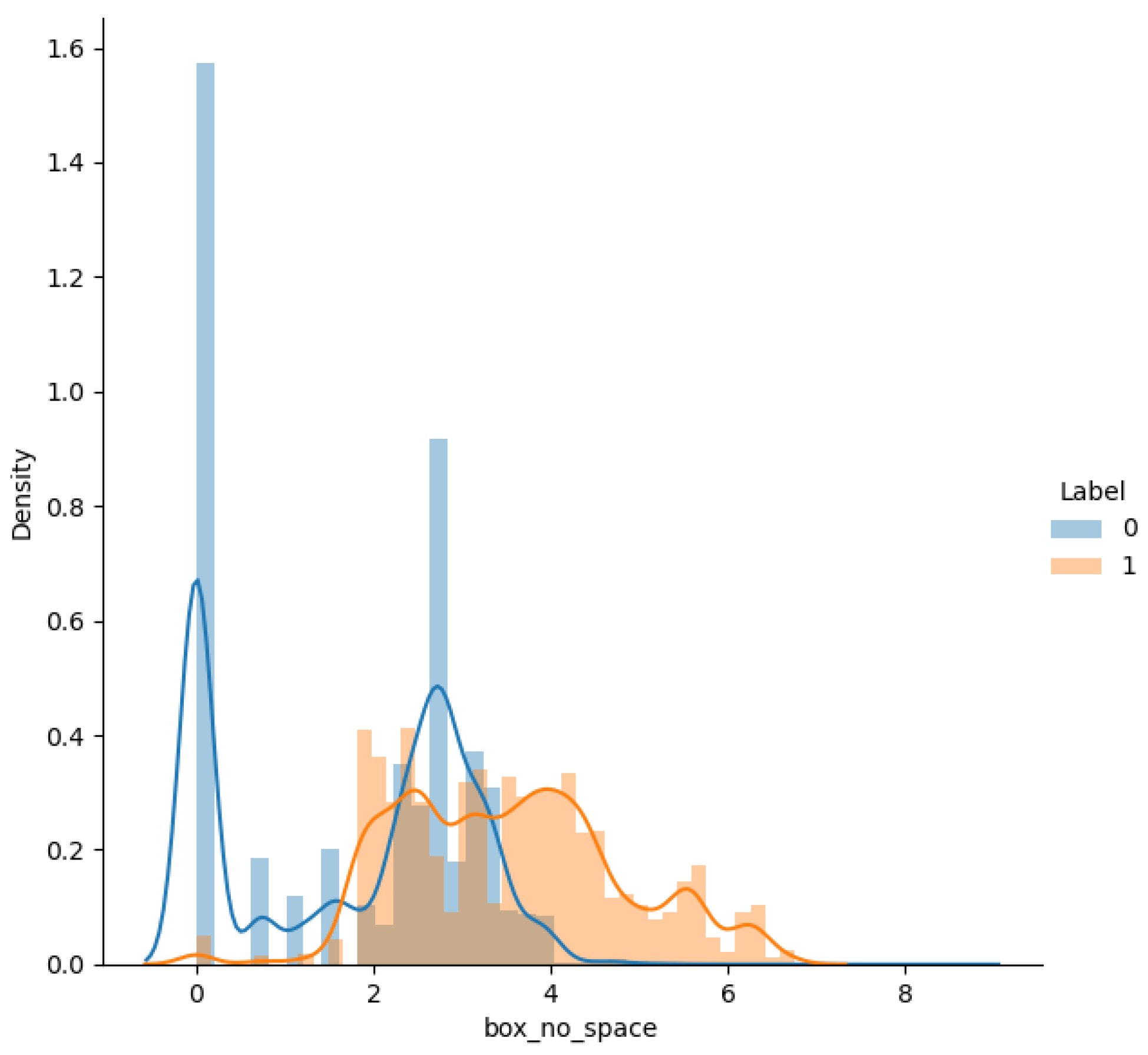
| 8 | no_white_space | The number of spaces in the query |
| 9 | no_percent | Number of percent signs |
| 10 | no_log_optr | Total number of logical operators in the query |
| 11 | no_arith_oprtr | Total number of arithmetic operators |
| 12 | no_null_val | Total number of null values in a query |
| 13 | no_hexdec_val | Total number of hexadecimal values |
| 14 | no_alphabet | Total number of letters in a query |
| 15 | no_digits | Total number of digits |
| 16 | len_of_chr_char_nul | Total number of chr + char + null keywords |
| 17 | genuine_keywords | Total number of keywords select, top, order, fetch, join, avg, count, sum, rows, etc. |
| Experimental Methods | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) | FPR (%) |
|---|---|---|---|---|---|
| Statistical features + MLP1 | 87.84 | 90.63 | 84.01 | 87.19 | 13.06 |
| Statistical features + LSTM1 | 81.47 | 82.56 | 80.80 | 81.67 | 17.45 |
| Statistical features + CNN1 | 88.83 | 88.32 | 85.78 | 87.03 | 10.24 |
| TF-IDF + MLP2 | 89.37 | 85.53 | 71.09 | 77.64 | 10.12 |
| TF-IDF + LSTM2 | 92.11 | 85.03 | 73.40 | 78.79 | 8.01 |
| TF-IDF + CNN2 | 93.16 | 82.56 | 80.80 | 81.67 | 6.98 |
| Word2Vec + MLP3 | 92.82 | 90.67 | 92.91 | 91.78 | 7.52 |
| Word2Vec + LSTM3 | 93.14 | 93.56 | 92.43 | 92.99 | 6.40 |
| Word2Vec + CNN3 | 96.10 | 97.28 | 99.11 | 98.18 | 3.83 |
| Method of our paper | 99.74 | 99.68 | 99.52 | 99.60 | 0.56 |
| Experimental Method | Number of Test Samples | Predicted Number of Correct Samples | Accuracy (%) |
|---|---|---|---|
| Statistical features + MLP1 | 796 | 133 | 16.71 |
| TF-IDF + CNN2 | 796 | 329 | 41.33 |
| Word2Vec + CNN3 | 796 | 610 | 76.63 |
| Method of our paper | 796 | 751 | 94.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, D.; Fei, J.; Liu, L. A Semantic Learning-Based SQL Injection Attack Detection Technology. Electronics 2023, 12, 1344. https://doi.org/10.3390/electronics12061344
Lu D, Fei J, Liu L. A Semantic Learning-Based SQL Injection Attack Detection Technology. Electronics. 2023; 12(6):1344. https://doi.org/10.3390/electronics12061344
Chicago/Turabian StyleLu, Dongzhe, Jinlong Fei, and Long Liu. 2023. "A Semantic Learning-Based SQL Injection Attack Detection Technology" Electronics 12, no. 6: 1344. https://doi.org/10.3390/electronics12061344
APA StyleLu, D., Fei, J., & Liu, L. (2023). A Semantic Learning-Based SQL Injection Attack Detection Technology. Electronics, 12(6), 1344. https://doi.org/10.3390/electronics12061344