1. Introduction
In recent years, Unmanned aerial vehicles (UAVs) have been widely used in traffic monitoring, sea area search and rescue, aerial photography, and other fields due to their small size, convenient operation, and high imaging resolution. UAV object detection is one of the important branches of computer vision tasks, and the target instances in the images can be captured efficiently by processing the images captured by UAVs.
The design of traditional object detection algorithms is mainly based on artificially constructed features, such as scale invariant feature transform (SIFT) [
1], Haar-like (Haar) [
2], Deformable Part Model (DPM) [
3], etc.
However, its limitations are that the manually designed features require a large amount of prior knowledge, fail to make full use of deep semantic information, and have weak generalization ability. In recent years, with the rise and development of deep learning technology, the use of Convolutional Neural Networks (CNNs) has been applied to object detection tasks.
CNN-based object detection algorithms are generally divided into two categories, namely, two-stage algorithms and single-stage algorithms. The two-stage algorithm is to first generate a series of candidate frames as samples by the algorithm, and then classify the samples through CNNs. The single-stage object detection algorithm does not need to generate a candidate frame, but directly predicts the bounding box and target type of the object. Typical representatives of two-stage algorithms include region-CNN (R-CNN) [
4], Faster R-CNN [
5], Mask R-CNN [
6], etc. Typical representatives of single-stage algorithms include You Only Look Once (YOLO) [
7], single shot multi-box detector (SSD) [
8], RetinaNet [
9], etc. Aiming at the problems of object detection in UAV aerial images, many scholars have carried out a series of studies. Liu et al. [
10] designed and added a multi-branch parallel feature pyramid network (MPFPN) on the Faster R-CNN and introduced a supervised spatial attention module (SSAM) to effectively improve the detection performance of UAV image targets in complex backgrounds, but the detection of small targets still needs to be improved. Liang et al. [
11] proposed a spatial context analysis method for object re-inference based on the SSD algorithm, which greatly improves the detection accuracy of small targets, but there are false detection cases for targets in complex contexts. Zhou et al. [
12] designed a metric-based object classification method to solve the classification problem of untrained subclass objects and modified the localization loss function to improve the localization performance of small objects.
As for the object detection algorithm, it can be divided into anchor-based algorithm and anchor-free algorithm according to the setting of anchor frame or not. The anchor-based method needs to pre-set a certain number of anchors at each position in the feature map of the image, and then classify and regress each anchor. The anchor-free method does not need to pre-set the anchor and directly detects the object on the image. The main difference between the two methods is whether to use anchor to generate proposal. Compared with the anchor-based algorithm, the anchor-free algorithm can greatly reduce the amount of additional parameters and reduce the memory occupied by the calculation. Many anchor-free networks that have emerged in recent years are also suitable for object detection of UAV aerial images. For example, CornerNet [
13] proposed for the first time to predict the target as a pair of key points through a single neural network, using box-to-corner prediction instead of anchor for localization and target detection. CenterNet [
14] models the detection object as a single center point of the bounding box and uses the heat map generated by the convolutional network to predict and classify the single centroid. Zhang et al. [
15] improved on the basis of YOLOX network and proposed the skip scale feature enhancement module BiNet, which effectively improved the detection accuracy of small targets. Inspired by FoveaBox, Liu et al. [
16] reset the target detection layer and proposed a HollowBox algorithm for multi-size features, which effectively reduces the false detection probability of drone detection. Hou et al. [
17] applied the fully convolutional one-stage object detection (FCOS) algorithm to ship detection to further improve the detection performance of ship targets. Mao et al. [
18] proposed ResSARNet based on the improvement of FCOS to obtain powerful detection performance by compressing the model parameters. The above anchor-free frame algorithm, in which FCOS performs detection by pixel-by-pixel point-wise regression, not only gets rid of the anchor frame but also outperforms most target detection algorithms in terms of performance. However, it still has limitations. Although the algorithm uses feature pyramid network (FPN) for multi-level prediction, the detection effect is still unsatisfactory for targets with large scale changes and cases where different targets overlap each other.
Therefore, this paper uses the single-stage target detection algorithm FCOS without anchor frames as the benchmark algorithm to improve it. The main contributions of the article are as follows: (1) To improve the backbone network, introduce the Global Context Block (GC-Block) into the residual block of the ResNet50 network, and improve the network’s capture of UAV targets in complex backgrounds ability. (2) Propose the Adaptive Feature Balancing Subnet (AFBS) structure, which can effectively balance the low-level and high-level features from the multi-level feature map, avoiding the dilution of its information flow when passing across layers, thus effectively improving the detection accuracy of small targets. (3) Use complete intersection over union (CIOU) Loss to optimize the regression loss, thus giving the model regression process scale sensitivity and strengthening the algorithm’s ability to detect multi-scale targets.
2. Materials and Methods
2.1. Baseline
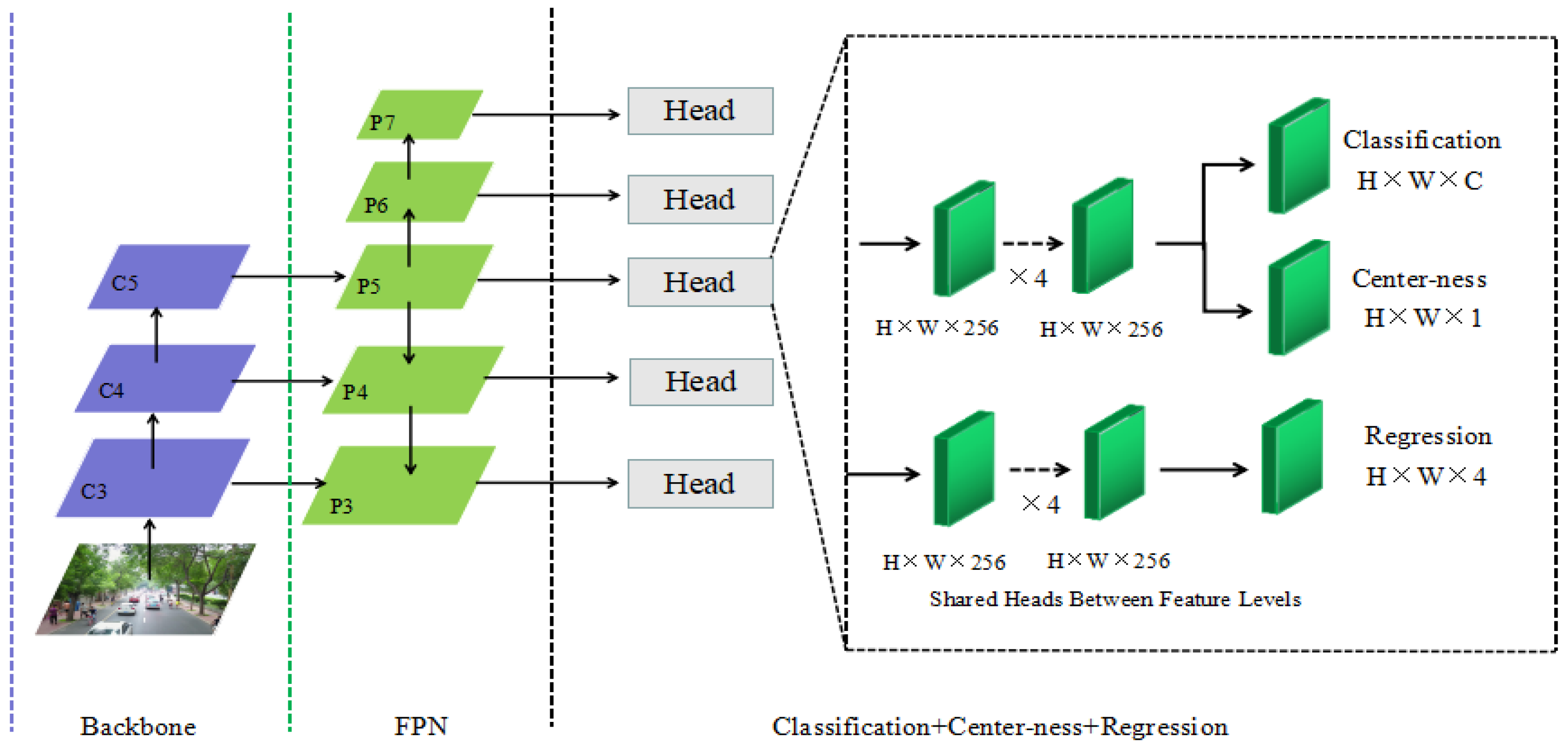
FCOS is a single-stage anchor-free object detection algorithm based on FCN proposed by Tian Z et al. [
19], which detects by means of pixel-by-pixel regression. The specific method is that FCOS performs a regression operation on each feature point on the feature map to predict four values (l,r,t,d), which, respectively, represent the distance from the feature point to the upper, lower, left, and right sides of the target boundary frame. As shown in
Figure 1, the network consists of three parts: the backbone network (Backbone), the feature pyramid (Feature Pyramid Network, FPN) [
20], and the output section Detection head, which includes Classification, Regression, and Center-ness branches.
FCOS mainly has the following advantages: (1) By getting rid of the anchor box, it avoids the complex intersection over union (IOU) calculation and reduces the training memory footprint. (2) It can be used as a Region Proposal Network (RPN) for two-stage detectors, and its performance is significantly better than anchor-based RPN. (3) Strong universality, the improved model can be applied to other visual tasks. In summary, this paper chooses the FCOS algorithm as the benchmark algorithm.
2.2. Algorithm of This Paper
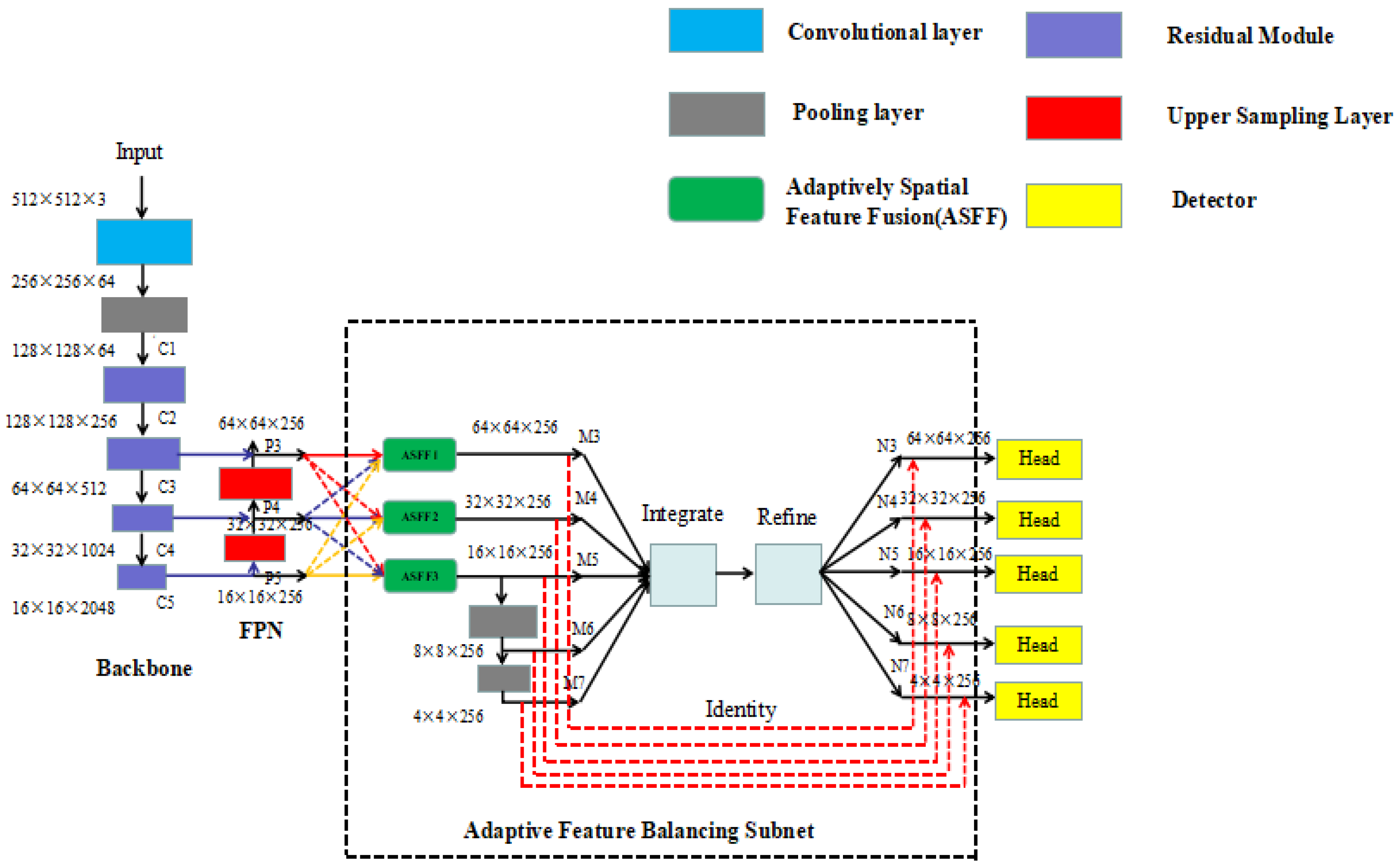
The algorithmic network architecture of this paper is shown in
Figure 2.
The model uses the ResNet50 network for feature extraction of the input image to obtain the initial features, selects the obtained C3, C4, and C5 features to send to FPN for feature fusion, and then uses the outputs P3, P4, and P5 as the input feature map of adaptively spatial feature fusion (ASFF) [
21]. Firstly, ASFF adjusts and integrates the features of other levels to the same resolution and then multiplies and, finally, sums the fusion with the corresponding weights of the feature maps at each level, and the features of different levels are adaptively fused to achieve the purpose of filtering conflicting information. The output feature maps from this network are M3, M4, M5, and M5 are down-sampled twice to obtain M6 and M7, respectively. The five-level features of M3, M4, M5, M6, and M7 are used as the input of balanced feature pyramid (BFP) [
22], which first integrates the five-level features to generate more balanced semantic features and then refines to obtain the more differentiated feature maps N3, N4, N5, N6, and N7. Finally, the identity (layer-by-layer addition) operation is executed to add M3~M7 to N3~N7, correspondingly, to enhance the original features. The detection head located at the end of the network detects the enhanced 5-layer features, which enter the detection head first through 4 H×W×256 convolutional layers for feature enhancement and then upstream in parallel through H×W×C and H×W×1 convolution to obtain two branches of classification and center-ness. The center-ness reflects the distance of a point on the feature map from the target center. By multiplying the predicted category probability with the corresponding center-ness, the bounding boxes with high scores are kept in order according to their scores, so that low-quality bounding boxes are filtered out in the non-maximum suppression (NMS) process, and the regression detection results are obtained by H×W×4 convolution in the downstream.
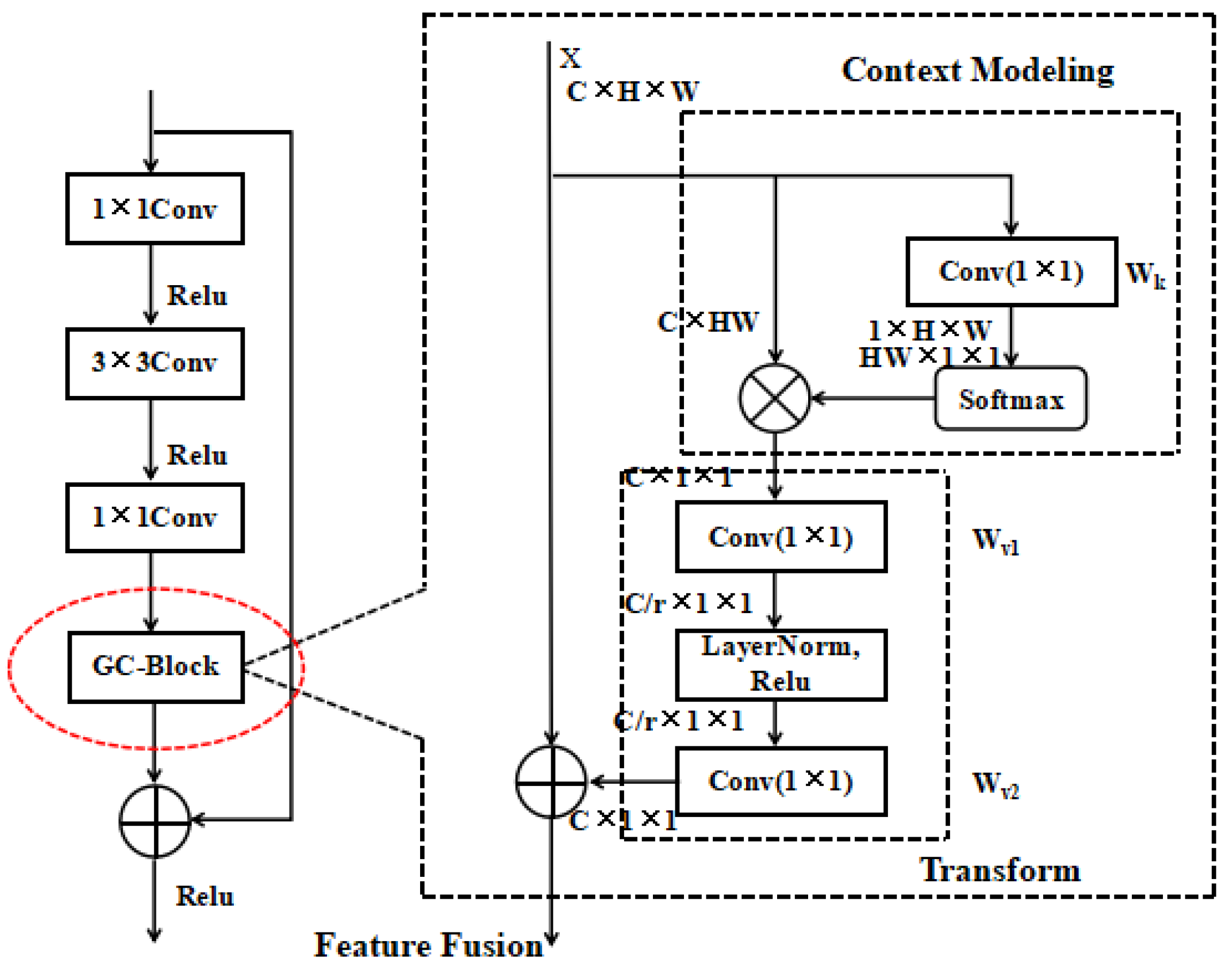
2.2.1. Improved Backbone Network
The general target detection model uses convolution operation to extract image features, but, since the convolution kernel only acts on the local receptive field, only the depth stacking of the convolution layer can associate all the regional information of the image. Multiple convolution stacking will increase the difficulty of training, and the network learning efficiency will be low, which will greatly reduce the positioning accuracy of the model for UAV image targets. In order to solve the above problems, this paper introduces the global context block (GC-Block) [
23] to improve the residual block of ResNet50, strengthens the ability of ResNet50 to capture long-distance dependencies, and uses the self-attention mechanism in the module to model the dependencies between long-distance pixels on the image. The improved backbone network is shown in
Figure 3.
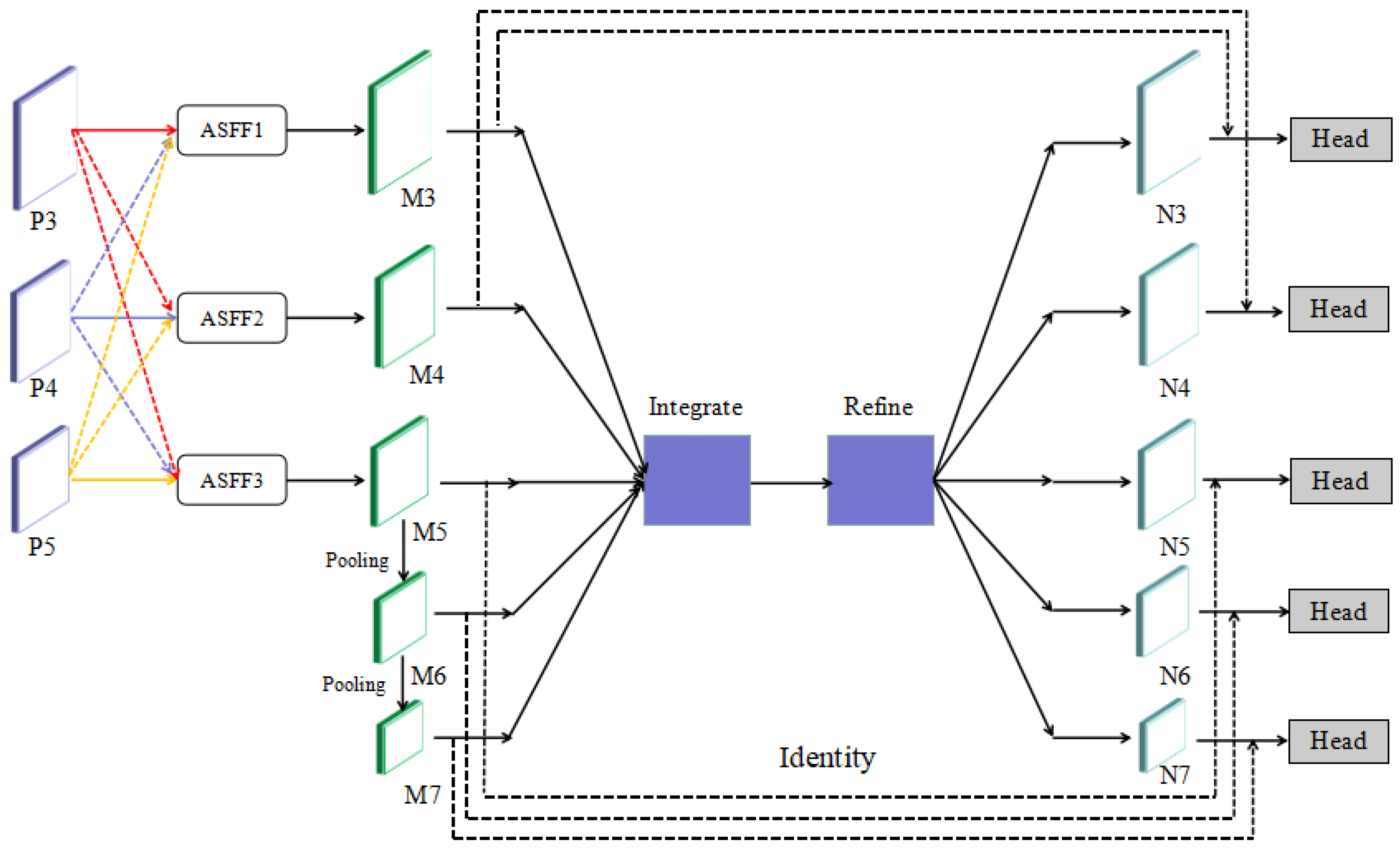
2.2.2. Adaptive Feature Equalization Subnetwork
Adaptive Feature Balancing Subnet (AFBS) consists of two parts: ASFF and BFP. The sub-network can not only adaptively learn the spatial weight of the multi-scale feature map, but also use the deeply integrated balanced semantic features to balance and strengthen the multi-level feature information, thus the information of small objects can be completely displayed. The network structure is shown in
Figure 4.
Adaptive Spatial Feature Fusion Module
The key idea of adaptive spatial feature fusion is to learn the fused spatial weights of features at different scales. multiply the learned parameters of each weight with the input to filter conflicting information and retain useful information to solve the problem of conflicting information when multi-layer features are fused. The specific implementation steps of this method are as follows:
- (1)
Feature input. Input the feature maps of different scales in the backbone network.
- (2)
Feature scaling. Scaling is to keep the channel of feature fusion the same. For the feature layer that needs to be upsampled, first use 1 × 1 convolution to adjust the number of channels to be consistent with the target layer, and then use interpolation to increase the resolution and adjust the size. For the 1/2 scale downsampling layer, a convolution of size 3 × 3 with stride 2 is used. For the 1/4 scale downsampling layer, it is necessary to add a maximum pooling layer with a stride of 2 to the convolution with a size of 3 × 3 and a stride of 2.
- (3)
Feature Fusion. Assuming that the target layer is , represents the feature vector adjusted from layer to layer at feature map (i, j), and , , and are the spatial weight parameters of features , , and fused to layer (i, j) at , respectively. The feature vectors of different feature maps at (i, j) are multiplied with their respective weights and then summed. layer fusion outputs the following equation:
where the weights
represent the spatial importance of the features at different levels, ranging from [0, 1] and summing to 1, generated using the Softmax function and with
,
,
as control parameters, calculated as follows:
Balanced Feature Pyramid
The balanced feature pyramid fully fuses the multi-dimensional features of different depth feature maps; thus, the fused features take into account both powerful semantic information and rich geometric information. The work process is divided into four steps:
- (1)
Feature size adjustment
The five features M3, M4, M5, M6, and M7 participating in feature fusion are adjusted to the same resolution through interpolation and maximum pooling operations. Because choosing a larger resolution will increase the network computing burden, a smaller resolution will be detrimental to small target detection. Therefore, this paper uniformly adjusts the same size as M5, and this process can avoid the input of additional parameters.
- (2)
Feature fusion
Feature fusion is to integrate features of different sizes and resolutions to remove redundant information, as to obtain better feature expression. The fusion is performed as follows to obtain balanced semantic features:
Among them, represent the layer feature, and denote the highest and lowest layer features, respectively.
- (3)
Feature refinement
The Gaussian non-local module [
24] is used to refine the fused features. This module can refine the fused semantic features to make them more distinguishable, thereby further improving the performance of object detection in the UAV scene.
- (4)
Feature enhancement
The idea of strengthening comes from the design concept of the residual structure. M3~M7 are added correspondingly to the optimized features through cross-connection and finally output N3~N7.
2.2.3. Loss Function
The loss function, as the basis for the deep neural network to judge the false detection samples, largely influences the model’s convergence effect, while providing optimization direction for the training of object detection network. The loss function of the algorithm in this paper contains three main components: Focal Loss is used as the classification loss function, Binary Cross Entropy (BCE) is used as the loss function of center-ness branch, and CIOU [
25] is used as the regression loss function. The total loss L is defined as follows:
Lcls is the classification loss, Lcenter is the loss of center-ness branch, and Lreg is the regression loss.
- (1)
Classification loss function
Focal Loss is a loss function used to deal with unbalanced sample classification. When there are too many negative samples, the classification accuracy will be reduced. By reducing the weight of easily classified samples, Focal loss enables the model to learn difficult classified samples in a centralized manner, as to prevent a large number of easily classified negative samples from dominating model training in the training process. The formula is as follows:
Among them, y is the real value, y* is the predicted value, which is a balance factor to balance the importance of positive and negative samples, and the value range is [0, 1], which is an adjustable focal length parameter.
- (2)
Binary Cross Entropy loss function.
FCOS uses the center-ness branch to suppress low-quality detection frames in UAV image samples. The regression object’s center-ness of a certain position in the sample is defined as follows:
Among them, the represent vertical distances from the point to the upper, lower, left, and right boundaries of the ground truth box, respectively.
- (3)
Improved regression loss function
The regression loss is mainly used to train the ability of the model to accurately locate the small target of the UAV. The benchmark algorithm uses IOU Loss as the regression loss. The value of IOU is 0 when the two boundary frames do not overlap. It is effective only when the two boundary frames overlap, the actual distance between the predicted frame and the real frame cannot be judged.
Therefore, this paper adopts CIOU Loss instead of IOU Loss. CIOU not only considers the overlap area and center point distance but also the aspect ratio in the process of bounding box regression, CIOU Loss can overcome its own defects while making full use of the advantages of IOU Loss and is sensitive to the transformation of the target’s bounding box shape, which is more conducive to the detection of UAV multi-scale targets. The expressions of IOU and CIOU are as follows:
is a positive trade-off parameter, and is used to measure the consistency of the aspect ratio. B is the predicted frame, Bgt is the ground truth, and C is the minimum frame diagonal length containing two frames.
2.3. Experimental Conditions
2.3.1. Dataset
The data used in this paper comes from the VisDrone [
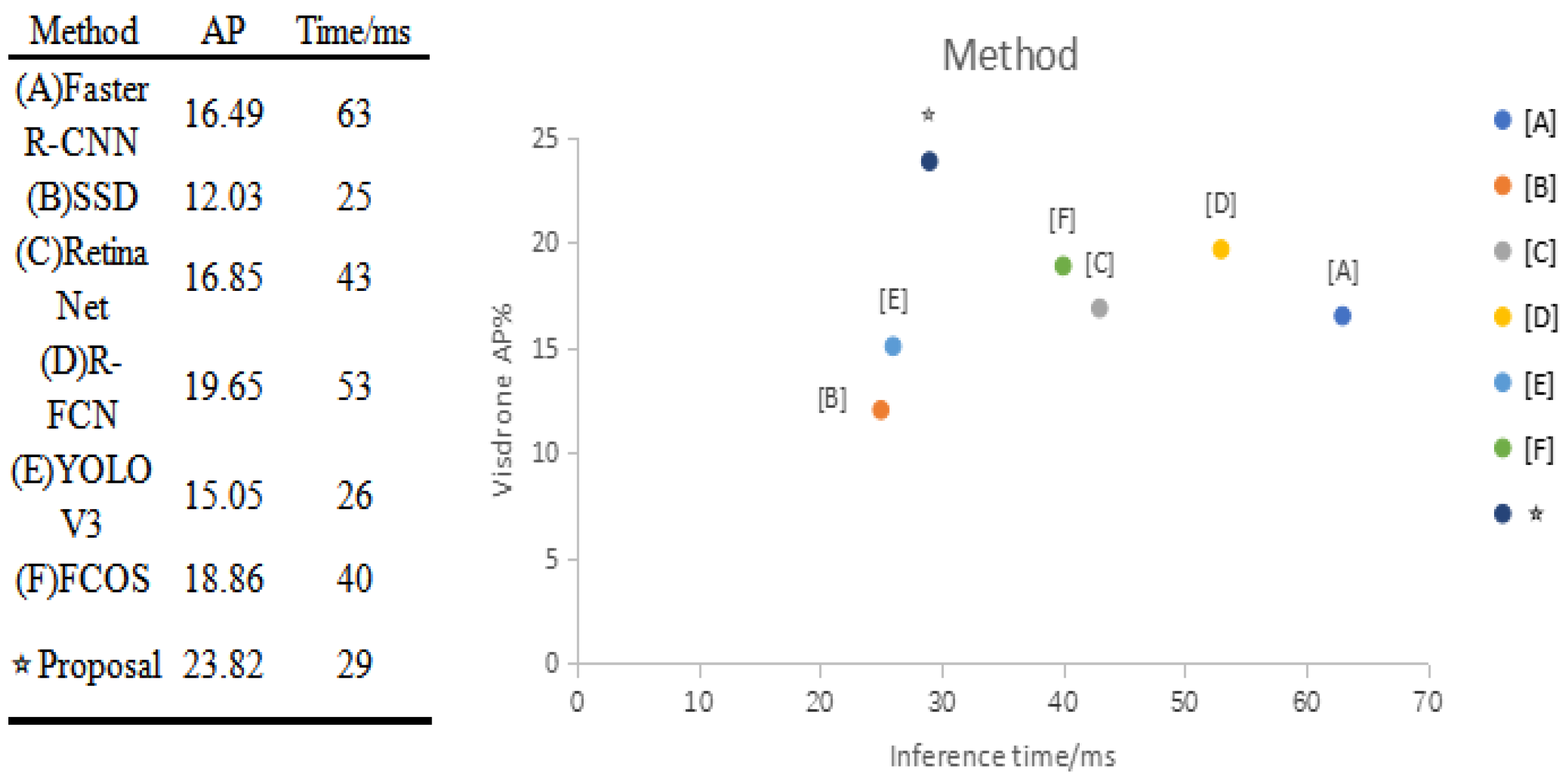
26] image target detection public dataset. The dataset includes 10 categories: pedestrians (people with walking or standing posture), people (people with other posture), cars, vans, buses, trucks, motorcycles, bicycles, awning tricycles, and tricycles. The VisDrone dataset is composed of 288 video clips, providing a total of 10,209 static images captured by drones of different heights, including 6471 images for training, 548 images for validation, and 3190 images for testing, totaling 2.6 million target instance samples.
2.3.2. Experiment Settings
The experimental platform in this paper used the Ubuntu 18.04 operating system. The GPU was an RTX A4000 16 G, and the CPU was an Intel(R) Xeon(R) Gold 5320 CPU @ 2.20 GHz. The deep learning framework chosen was PyTorch, and the input image size was 512 × 512. When building the network, the batch size was 8, the training was 100 epochs, the initial learning rate was set to 0.001, and the Adam optimizer was used.
2.4. Evaluation Metrics
In order to verify the effectiveness of the algorithm in this paper, evaluation was performed from both qualitative and quantitative aspects. Qualitative analysis was mainly evaluated from a subjective perspective, and quantitative analysis was mainly evaluated from objective evaluation indexes as a reference.
In this paper, comprehensive average precision AP (Average Precision), AP
S, AP
M, AP
L, FPS (Frame Per Second), Params (Parameters), and FLOPs (Floating Point Operations) indicators are used to evaluate the performance of the model.
AP means that the IOU is within the range of [0.50, 0.95], with a step of 0.05. A total of 10 thresholds are used to change the comprehensive average precision. The higher the
AP value, the better the detection effect of the algorithm. The formula is shown in (11).
In the formula, classes and thresholds represent the number of target categories and the IOU threshold, respectively. c is the element in classes, and t represents the value in the threshold interval. TP is True Positives, representing positive samples that are correctly classified. FP stands for False Positives, which represent positive samples that have been misclassified. FPS is used to evaluate the real-time performance of the model, and the higher the value the better the real-time performance of the algorithm. According to the COCO evaluation system, APS, APM, and APL, respectively, represent the absolute pixel area of the object under small (area less than 322), medium (area greater than 322, less than 962), and large (area greater than 962) average precision.
Params is the total number of parameters in the network layer including parameters, which measures the space resource occupation of the model, the formula is shown in (12).
Among them, D represents the total number of layers of the network, Kl, Nl − 1, and Nl are the convolution kernel size, the number of input and output channels, respectively.
FLOPs measure the number of floating-point operations of the model, reflecting the computational complexity of the model. The formula is shown in (13).
In the formula, D represents the total number of layers of the network, Hl, Wl represent the height and width of the output feature map of the layer, and Kl, Nl − 1, and Nl are the convolution kernel size and the number of input and output channels, respectively.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}