




Low Complexity Speech Enhancement Network Based on Frame-Level Swin Transformer

 ,
,
Abstract
1. Introduction
- Our study is the first work to explore the application of Swin Transformer structure in speech enhancement tasks.
- We propose a novel frame-level Swin Transformer structure suitable for speech processing tasks, which adopts the frame-level shifted window mechanism for attention calculation. The proposed structure greatly saves computing resources, facilitates the construction of speech stream processing, and provides a new solution for future speech enhancement systems.
- The proposed FLSTN model utilizes frame-level Swin Transformer modules as the backbone, maintaining low computational complexity and achieving outstanding performance.
2. Related Work
2.1. CNN-Based Speech Enhancement Methods
2.2. Transformer-Based Speech Enhancement Methods
3. Problem Formulation
4. Method
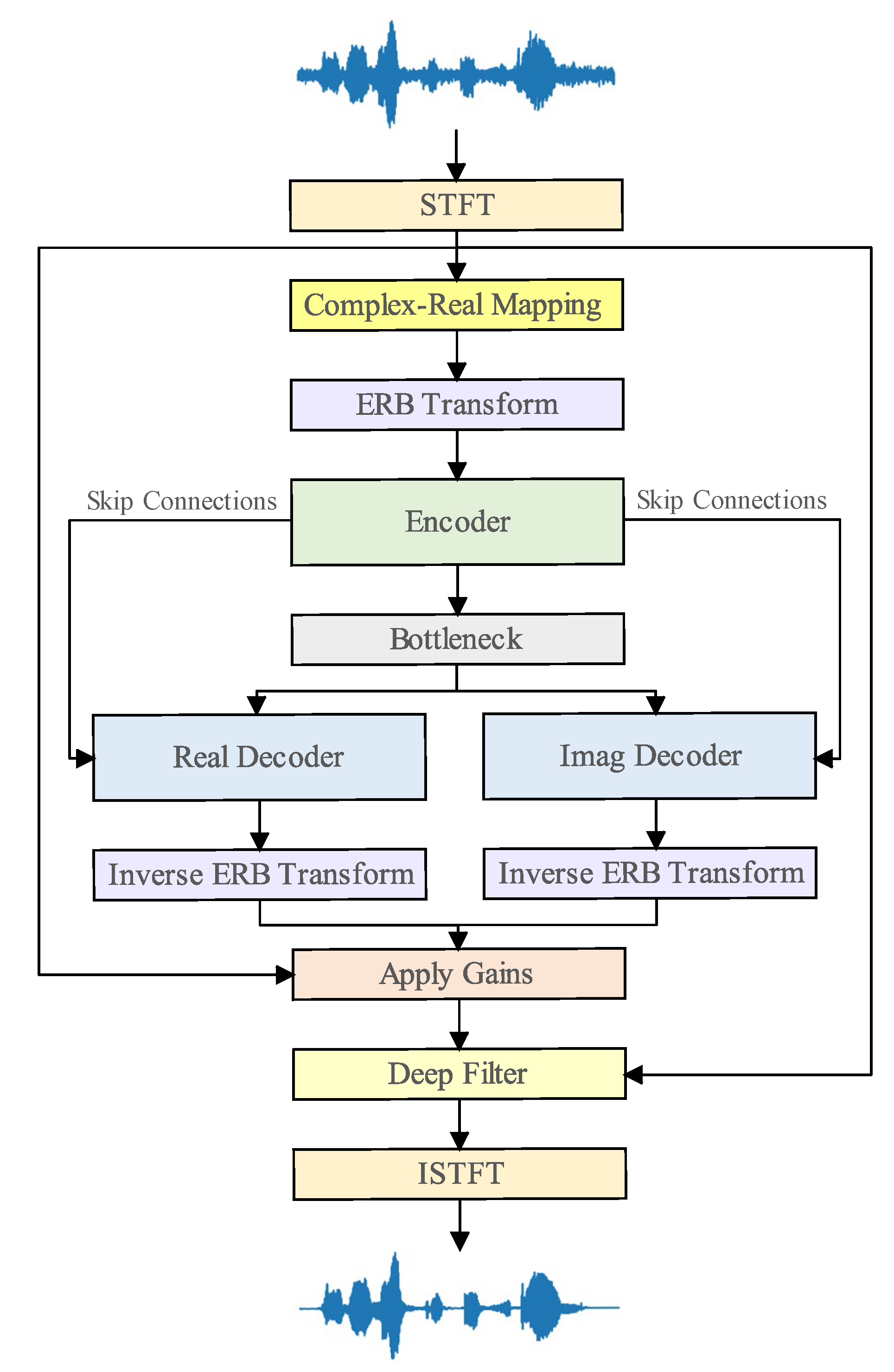
4.1. Architecture Overview
4.2. Complex-Real Mapping Module
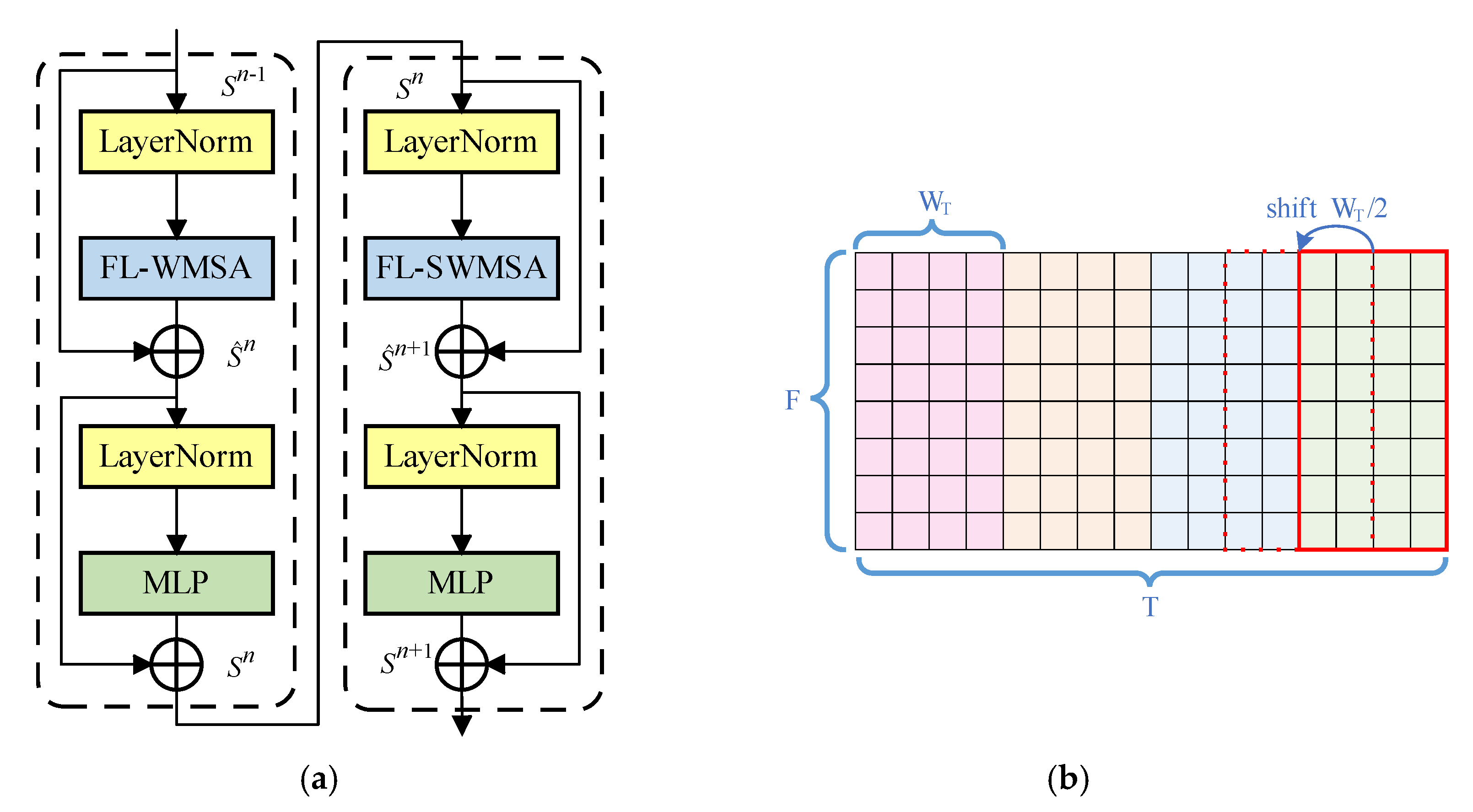
4.3. Frame-Level Swin Transformer
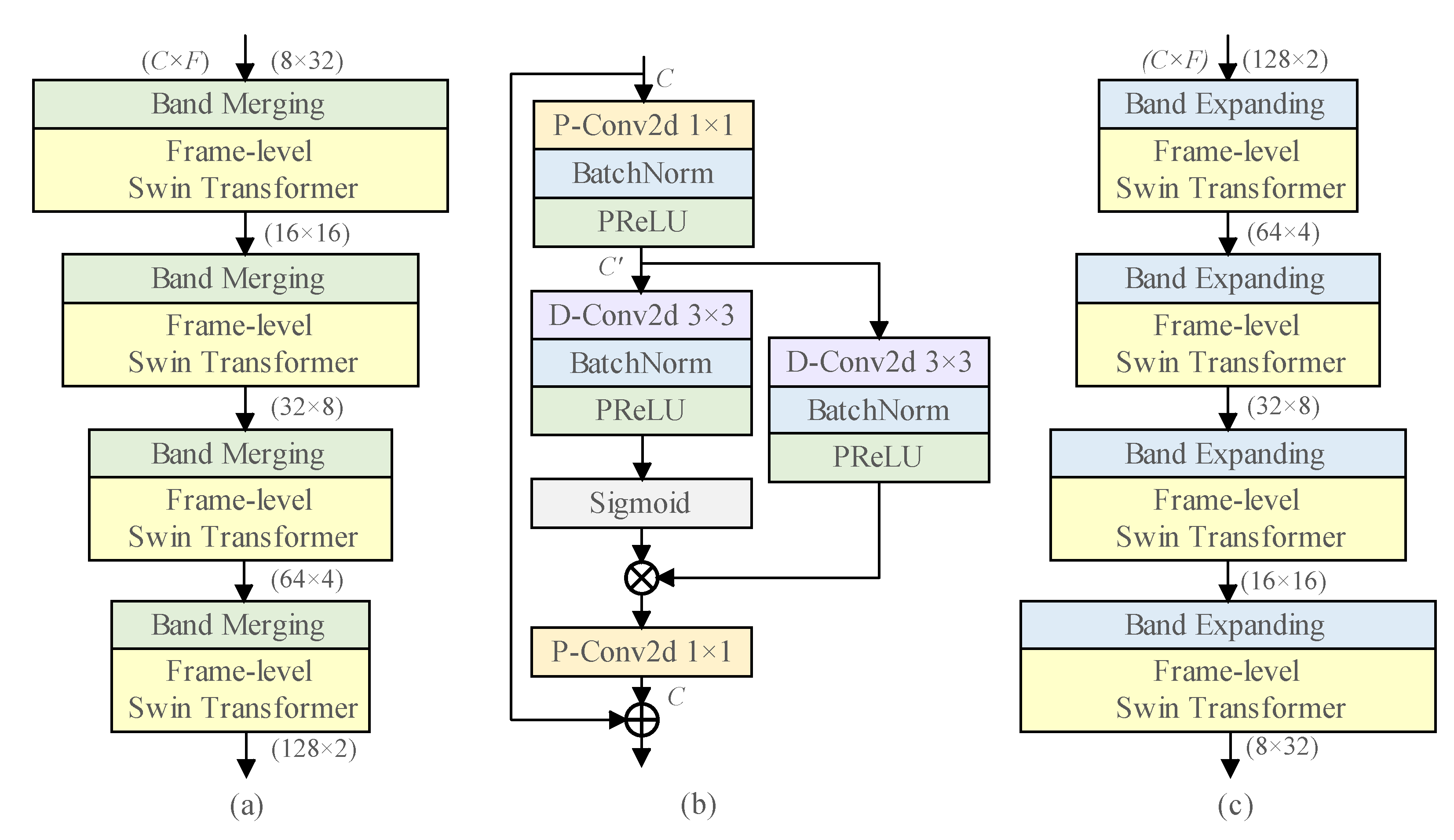
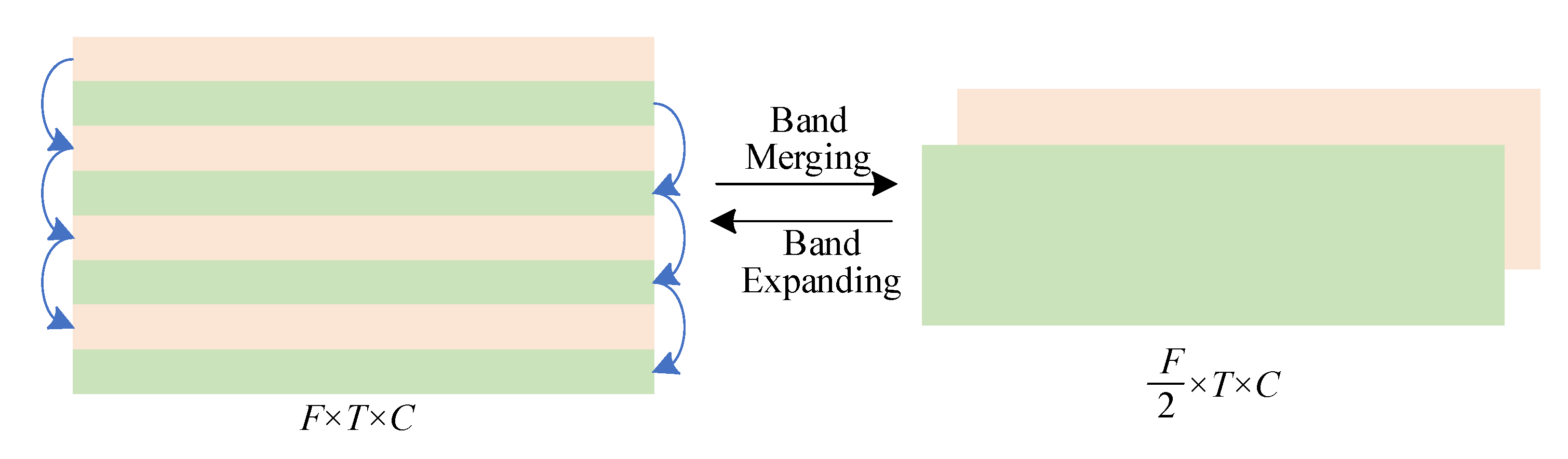
4.4. Band Merging and Expanding
4.5. Lightweight TFCM
4.6. Apply Gains
4.7. Deep Filter
4.8. Loss Function
5. Experiment
5.1. Experiment I
5.1.1. Dataset and Evaluation Metric
5.1.2. Experimental Setup and Baselines
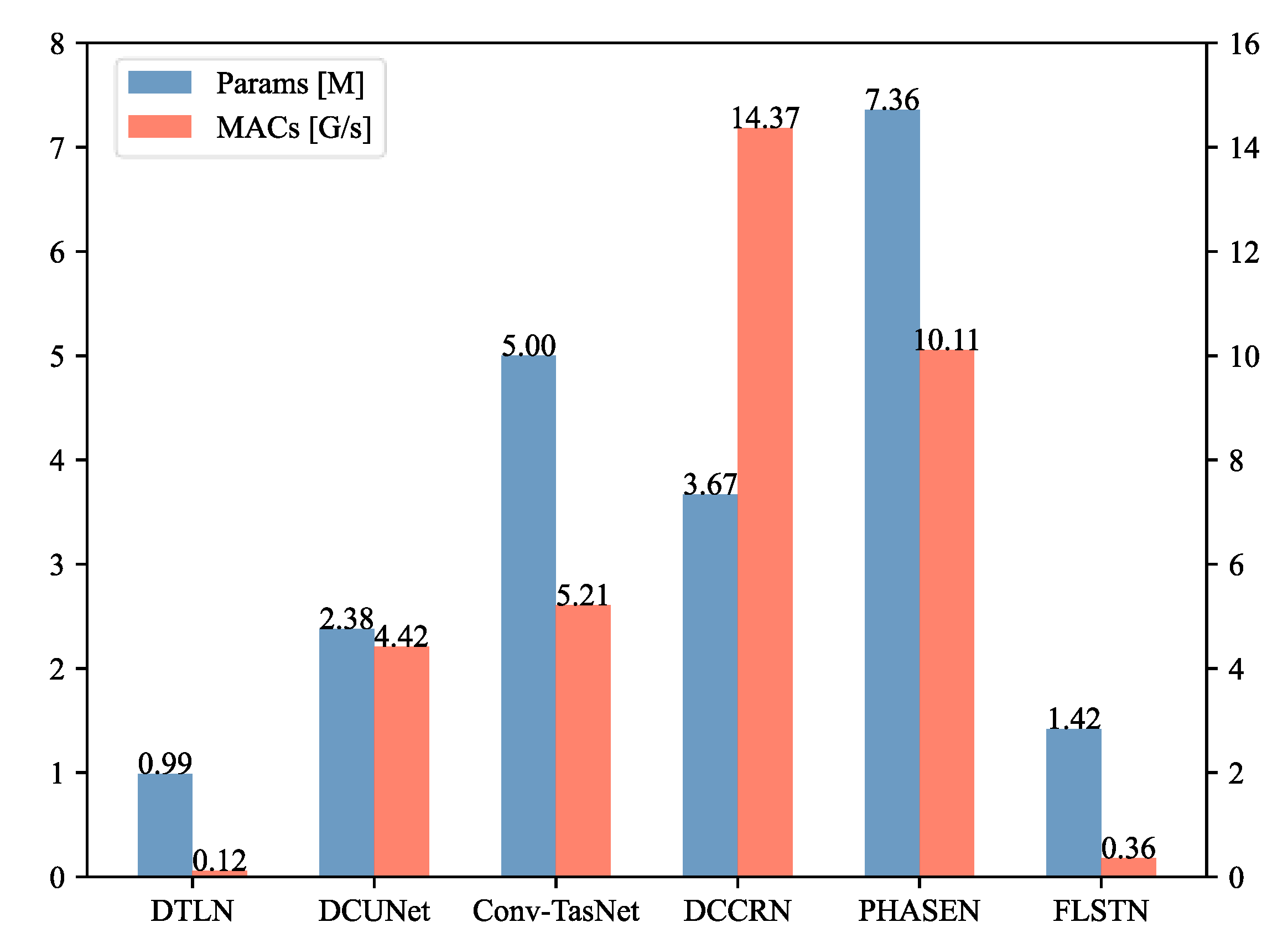
5.1.3. Experimental Results
5.2. Experiment II
5.2.1. Dataset and Evaluation Metric
5.2.2. Experimental Setup and baselines
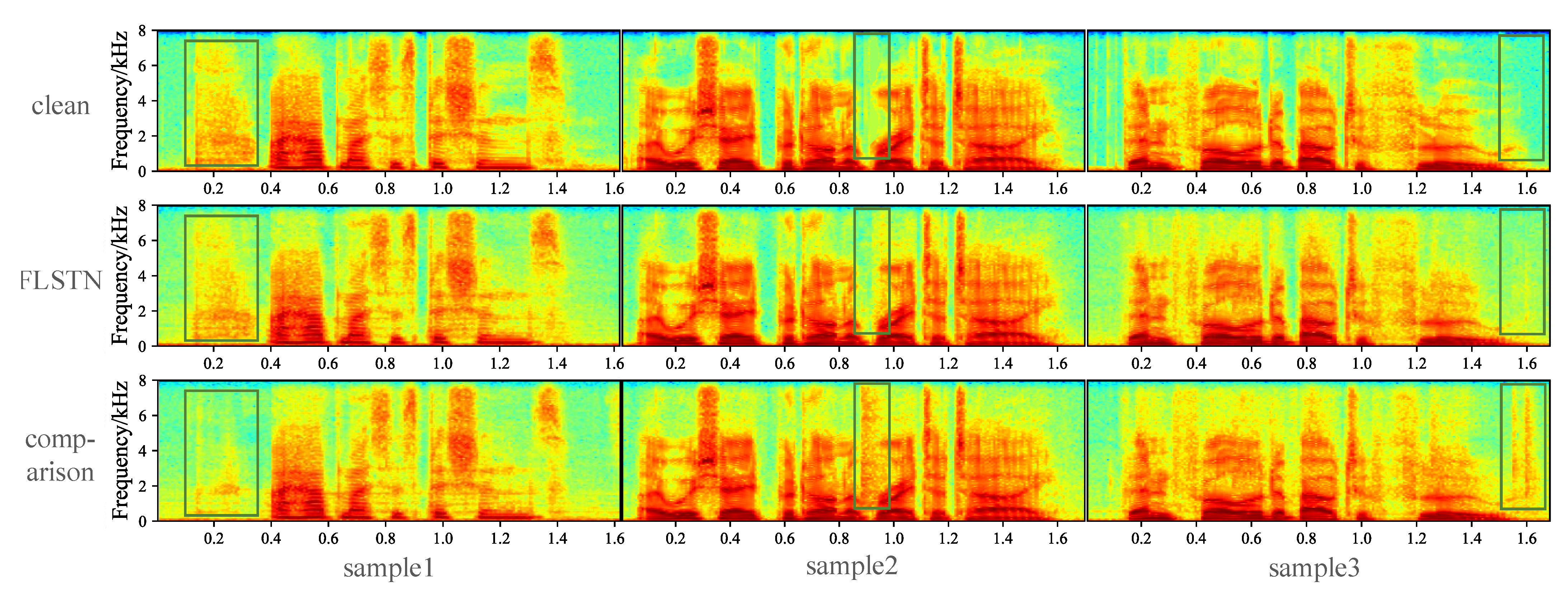
5.2.3. Experimental Results
5.2.4. The Influence of Frame-Level Swin Transformer
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Loizou, P.C. Speech Enhancement: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Kumar, S.; Kumar, B.; Kumar, N. Speech enhancement techniques: A review. Rungta Int. J. Electr. Electron. Eng. 2016, 1, 183–185. [Google Scholar]
- Boll, S. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech Signal Process. 1979, 27, 113–120. [Google Scholar] [CrossRef]
- Scalart, P. Speech enhancement based on a priori signal to noise estimation. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference, Atlanta, GA, USA, 9 May 1996; pp. 629–632. [Google Scholar]
- Zhou, N.; Du, J.; Tu, Y.-H.; Gao, T.; Lee, C.-H. A speech enhancement neural network architecture with SNR-progressive multi-target learning for robust speech recognition. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 1 June 2019; pp. 873–877. [Google Scholar]
- Wu, B.; Yu, M.; Chen, L.; Xu, Y.; Weng, C.; Su, D.; Yu, D. Distortionless multi-channel target speech enhancement for overlapped speech recognition. arXiv 2020, arXiv:2007.01566. [Google Scholar]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Yu, W.; Zhou, J.; Wang, H.; Tao, L. SETransformer: Speech Enhancement Transformer. Cogn. Comput. 2022, 14, 1152–1158. [Google Scholar] [CrossRef]
- Wang, K.; He, B.; Zhu, W.-P. TSTNN: Two-stage Transformer based neural network for speech enhancement in the time domain. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7098–7102. [Google Scholar]
- Fu, Y.; Liu, Y.; Li, J.; Luo, D.; Lv, S.; Jv, Y.; Xie, L. Uformer: A unet based dilated complex & real dual-path conformer network for simultaneous speech enhancement and dereverberation. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7417–7421. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chen, K.; Du, X.; Zhu, B.; Ma, Z.; Berg-Kirkpatrick, T.; Dubnov, S. HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection. arXiv 2022, arXiv:2202.00874. [Google Scholar]
- Hu, Y.; Liu, Y.; Lv, S.; Xing, M.; Zhang, S.; Fu, Y.; Wu, J.; Zhang, B.; Xie, L. DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement. arXiv 2020, arXiv:2008.00264. [Google Scholar]
- Pandey, A.; Wang, D. TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6875–6879. [Google Scholar]
- Choi, H.-S.; Kim, J.-H.; Huh, J.; Kim, A.; Ha, J.-W.; Lee, K. Phase-aware speech enhancement with deep complex u-net. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Sun, C.; Zhu, Q.; Wan, M. A novel speech enhancement method based on constrained low-rank and sparse matrix decomposition. Speech Commun. 2014, 60, 44–55. [Google Scholar] [CrossRef]
- Williamson, D.S.; Wang, Y.; Wang, D. Complex ratio masking for monaural speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 24, 483–492. [Google Scholar] [CrossRef] [PubMed]
- Mack, W.; Habets, E.A. Deep filtering: Signal extraction and reconstruction using complex time-frequency filters. IEEE Signal Process. Lett. 2019, 27, 61–65. [Google Scholar] [CrossRef]
- Lv, S.; Hu, Y.; Zhang, S.; Xie, L. Dccrn+: Channel-wise subband dccrn with snr estimation for speech enhancement. arXiv 2021, arXiv:2106.08672. [Google Scholar]
- Paul, D.B.; Baker, J. The design for the Wall Street Journal-based CSR corpus. In Speech and Natural Language, Proceedings of the Workshop on Speech and Natural Language, Harriman, New York, NY, USA, 23–26 February 1992; Association for Computational Linguistics: Stroudsburg, PA, USA, 1992. [Google Scholar]
- Reddy, C.K.; Dubey, H.; Koishida, K.; Nair, A.; Gopal, V.; Cutler, R.; Braun, S.; Gamper, H.; Aichner, R.; Srinivasan, S. Interspeech 2021 deep noise suppression challenge. arXiv 2021, arXiv:2101.01902. [Google Scholar]
- Varga, A.; Steeneken, H.J. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time–frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. Evaluation of objective quality measures for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2007, 16, 229–238. [Google Scholar] [CrossRef]
- Westhausen, N.L.; Meyer, B.T. Dual-signal transformation lstm network for real-time noise suppression. arXiv 2020, arXiv:2005.07551. [Google Scholar]
- Luo, Y.; Mesgarani, N. Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [PubMed]
- Yin, D.; Luo, C.; Xiong, Z.; Zeng, W. Phasen: A phase-and-harmonics-aware speech enhancement network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 17–20 February 2020; pp. 9458–9465. [Google Scholar]
- Veaux, C.; Yamagishi, J.; King, S. The voice bank corpus: Design, collection and data analysis of a large regional accent speech database. In Proceedings of the 2013 International Conference Oriental COCOSDA Held Jointly with 2013 Conference on Asian Spoken Language Research and Evaluation (O-COCOSDA/CASLRE), Gurgaon, India, 25–27 November 2013; pp. 1–4. [Google Scholar]
- Thiemann, J.; Ito, N.; Vincent, E. The Diverse Environments Multi-Channel Acoustic Noise Database (DEMAND): A database of multichannel environmental noise recordings. Proceedings of Meetings on Acoustics (ICA2013), Montreal, QC, Canada, 2–7 June 2013; p. 3591. [Google Scholar]
- Valin, J.-M. A hybrid DSP/deep learning approach to real-time full-band speech enhancement. In Proceedings of the 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018; pp. 1–5. [Google Scholar]
- Braun, S.; Gamper, H.; Reddy, C.K.; Tashev, I. Towards efficient models for real-time deep noise suppression. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 656–660. [Google Scholar]
- Valin, J.-M.; Isik, U.; Phansalkar, N.; Giri, R.; Helwani, K.; Krishnaswamy, A. A perceptually-motivated approach for low-complexity, real-time enhancement of fullband speech. arXiv 2020, arXiv:2008.04259. [Google Scholar]
- Lv, S.; Fu, Y.; Xing, M.; Sun, J.; Xie, L.; Huang, J.; Wang, Y.; Yu, T. S-dccrn: Super wide band dccrn with learnable complex feature for speech enhancement. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7767–7771. [Google Scholar]
- Schroter, H.; Escalante-B, A.N.; Rosenkranz, T.; Maier, A. DeepFilterNet: A low complexity speech enhancement framework for full-band audio based on deep filtering. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7407–7411. [Google Scholar]
- Chen, J.; Wang, Z.; Tuo, D.; Wu, Z.; Kang, S.; Meng, H. FullSubNet+: Channel Attention FullSubNet with Complex Spectrograms for Speech Enhancement. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7857–7861. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | SNR | Babble | Factory1 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PESQ | STOI | CSIG | CBAK | COVL | PESQ | STOI | CSIG | CBAK | COVL | ||
| Noisy | 0 dB | 1.09 | 0.684 | 2.30 | 1.40 | 1.58 | 1.06 | 0.683 | 2.22 | 1.43 | 1.54 |
| DTLN | 1.29 | 0.780 | 2.65 | 1.94 | 1.89 | 1.34 | 0.805 | 2.61 | 2.06 | 1.92 | |
| DCUNet | 1.31 | 0.794 | 2.54 | 2.02 | 1.84 | 1.36 | 0.820 | 2.59 | 2.14 | 1.91 | |
| Conv-TasNet | 1.32 | 0.838 | 2.85 | 2.12 | 2.03 | 1.32 | 0.837 | 2.78 | 2.15 | 2.01 | |
| DCCRN | 1.35 | 0.828 | 2.52 | 1.65 | 1.86 | 1.33 | 0.836 | 2.44 | 1.72 | 1.83 | |
| PHASEN | 1.33 | 0.810 | 2.67 | 1.60 | 1.92 | 1.43 | 0.830 | 2.76 | 1.74 | 2.04 | |
| FLSTN(Pro.) | 1.45 * | 0.825 | 3.04 | 2.20 | 2.19 | 1.54 | 0.843 | 3.09 | 2.33 | 2.27 | |
| Noisy | 5 dB | 1.18 | 0.799 | 2.68 | 1.73 | 1.85 | 1.13 | 0.803 | 2.58 | 1.74 | 1.79 |
| DTLN | 1.63 | 0.886 | 3.19 | 2.32 | 2.36 | 1.62 | 0.889 | 3.04 | 2.37 | 2.30 | |
| DCUNet | 1.68 | 0.895 | 3.11 | 2.47 | 2.34 | 1.70 | 0.903 | 3.03 | 2.53 | 2.32 | |
| Conv-TasNet | 1.68 | 0.915 | 3.34 | 2.49 | 2.48 | 1.64 | 0.912 | 3.21 | 2.49 | 2.40 | |
| DCCRN | 1.79 | 0.916 | 3.14 | 1.94 | 2.43 | 1.70 | 0.917 | 2.95 | 1.94 | 2.29 | |
| PHASEN | 1.77 | 0.907 | 3.27 | 1.90 | 2.48 | 1.80 | 0.912 | 3.21 | 1.97 | 2.47 | |
| FLSTN(Pro.) | 1.97 | 0.916 | 3.65 | 2.72 | 2.78 | 2.00 | 0.918 | 3.58 | 2.76 | 2.77 | |
| Noisy | 10 dB | 1.37 | 0.887 | 3.09 | 2.13 | 2.18 | 1.32 | 0.894 | 3.01 | 2.13 | 2.13 |
| DTLN | 2.10 | 0.939 | 3.71 | 2.70 | 2.88 | 2.01 | 0.938 | 3.49 | 2.68 | 2.73 | |
| DCUNet | 2.19 | 0.946 | 3.69 | 2.96 | 2.92 | 2.18 | 0.948 | 3.54 | 2.98 | 2.84 | |
| Conv-TasNet | 2.15 | 0.954 | 3.83 | 2.88 | 2.98 | 2.10 | 0.952 | 3.69 | 2.86 | 2.89 | |
| DCCRN | 2.39 | 0.956 | 3.76 | 2.27 | 3.06 | 2.24 | 0.958 | 3.51 | 2.23 | 2.86 | |
| PHASEN | 2.34 | 0.954 | 3.83 | 2.23 | 3.07 | 2.30 | 0.954 | 3.70 | 2.25 | 2.99 | |
| FLSTN(Pro.) | 2.55 | 0.957 | 4.19 | 3.23 | 3.36 | 2.50 | 0.957 | 4.04 | 3.20 | 3.27 | |
| Noisy | AVG. | 1.21 | 0.790 | 2.69 | 1.75 | 1.87 | 1.17 | 0.793 | 2.60 | 1.77 | 1.82 |
| DTLN | 1.67 | 0.868 | 3.18 | 2.32 | 2.38 | 1.66 | 0.878 | 3.05 | 2.37 | 2.31 | |
| DCUNet | 1.73 | 0.878 | 3.11 | 2.48 | 2.37 | 1.75 | 0.891 | 3.05 | 2.55 | 2.36 | |
| Conv-TasNet | 1.72 | 0.902 | 3.34 | 2.50 | 2.50 | 1.69 | 0.900 | 3.23 | 2.50 | 2.43 | |
| DCCRN | 1.84 | 0.902 | 3.14 | 1.95 | 2.45 | 1.76 | 0.903 | 2.97 | 1.96 | 2.33 | |
| PHASEN | 1.81 | 0.890 | 3.26 | 1.91 | 2.49 | 1.84 | 0.899 | 3.22 | 1.99 | 2.50 | |
| FLSTN(Pro.) | 1.99 | 0.899 | 3.63 | 2.72 | 2.78 | 2.01 | 0.906 | 3.57 | 2.77 | 2.77 | |
| Model | Year | Params[M] | MACs[G/s] | PESQ | STOI | CSIG | CBAK | COVL |
|---|---|---|---|---|---|---|---|---|
| Noisy | - | - | - | 1.97 | 0.921 | 3.34 | 2.44 | 2.63 |
| RNNoise | 2018 | 0.06 * | 0.04 | 2.33 | 0.922 | 3.40 | 2.51 | 2.84 |
| PercepNet | 2020 | 8.00 | 0.80 | 2.73 | - | - | - | - |
| DCCRN | 2020 | 3.70 | 14.36 | 2.54 | 0.938 | 3.74 | 3.13 | 2.75 |
| NSNet2 | 2021 | 6.17 | 0.43 | 2.47 | 0.903 | 3.23 | 2.99 | 2.90 |
| DCCRN+ | 2021 | 3.30 | - | 2.84 | - | - | - | - |
| S-DCCRN | 2022 | 2.34 | - | 2.84 | 0.940 | 4.03 | 2.97 | 3.43 |
| DeepFilterNet | 2022 | 1.78 | 0.35 | 2.81 | 0.942 | 4.14 | 3.31 | 3.46 |
| FullSubNet+ | 2022 | 8.67 | 30.06 | 2.88 | 0.940 | 3.86 | 3.42 | 3.57 |
| FLSTN | 2022 | 1.42 | 0.38 | 2.88 | 0.944 | 4.18 | 3.43 | 3.53 |
| Model | PESQ | STOI | CSIG | CBAK | COVL |
|---|---|---|---|---|---|
| FLSTN | 2.88 * | 0.944 | 4.18 | 3.43 | 3.53 |
| comparison | 2.57 | 0.939 | 3.86 | 3.27 | 3.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, W.; Sun, C.; Chen, F.; Leng, Y.; Guo, Q.; Sun, J.; Peng, J. Low Complexity Speech Enhancement Network Based on Frame-Level Swin Transformer. Electronics 2023, 12, 1330. https://doi.org/10.3390/electronics12061330
Jiang W, Sun C, Chen F, Leng Y, Guo Q, Sun J, Peng J. Low Complexity Speech Enhancement Network Based on Frame-Level Swin Transformer. Electronics. 2023; 12(6):1330. https://doi.org/10.3390/electronics12061330
Chicago/Turabian StyleJiang, Weiqi, Chengli Sun, Feilong Chen, Yan Leng, Qiaosheng Guo, Jiayi Sun, and Jiankun Peng. 2023. "Low Complexity Speech Enhancement Network Based on Frame-Level Swin Transformer" Electronics 12, no. 6: 1330. https://doi.org/10.3390/electronics12061330
APA StyleJiang, W., Sun, C., Chen, F., Leng, Y., Guo, Q., Sun, J., & Peng, J. (2023). Low Complexity Speech Enhancement Network Based on Frame-Level Swin Transformer. Electronics, 12(6), 1330. https://doi.org/10.3390/electronics12061330