


Detecting Human Falls in Poor Lighting: Object Detection and Tracking Approach for Indoor Safety




Abstract
1. Introduction
- A novel deep-learning-based approach for vision-based fall detection is proposed, integrating YOLOv7 for object detection and the Deep SORT algorithm for tracking and trajectory analysis.
- The proposed method incorporates dual illumination estimation, utilizing a Retinex-based image enhancement algorithm, to effectively tackle the issue of inconsistent lighting conditions and exposure levels.
- The effectiveness and superiority of the proposed approach over current state-of-the-art methods are extensively demonstrated, offering a robust solution for vision-based fall detection.
2. Related Works
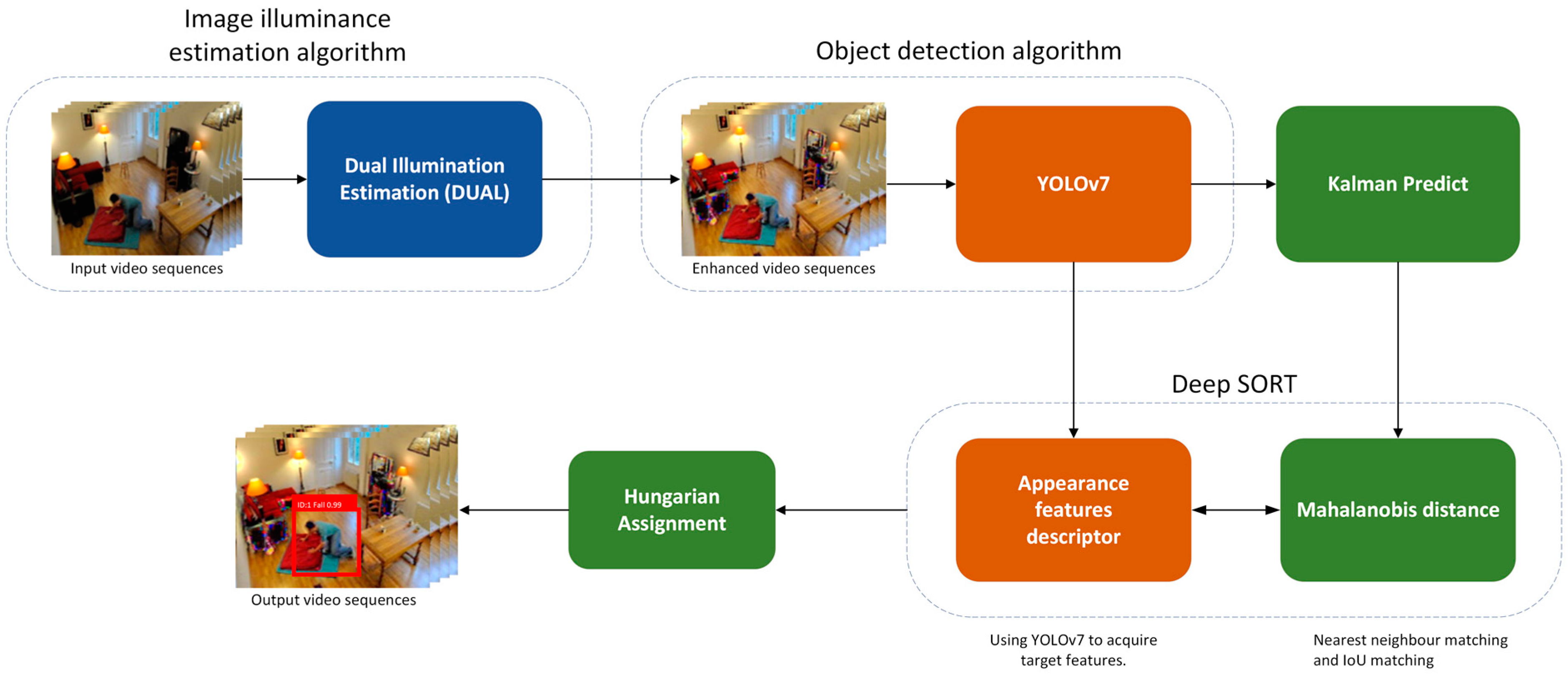
3. Methodology
3.1. Experimental Data
3.2. Annotation
3.3. Proposed Framework
3.3.1. Object Detection
3.3.2. Object Tracking
3.3.3. Dual Illumination Estimation (DUAL)
4. Experimental Evaluation
4.1. Experimental Setup
4.2. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization (WHO). Falls. 2021. Available online: https://www.who.int/news-room/fact-sheets/detail/falls (accessed on 17 July 2022).
- Alam, E.; Sufian, A.; Dutta, P.; Leo, M. Vision-based human fall detection systems using deep learning: A review. Comput. Biol. Med. 2022, 146, 105626. [Google Scholar] [CrossRef] [PubMed]
- Burns, E.; Kakara, R. Deaths from Falls Among Persons Aged ≥ 65 Years—United States, 2007–2016. MMWR. Morb. Mortal. Wkly. Rep. 2018, 67, 509–514. [Google Scholar] [CrossRef]
- Kelsey, J.L.; Procter-Gray, E.; Hannan, M.T.; Li, W. Heterogeneity of Falls Among Older Adults: Implications for Public Health Prevention. Am. J. Public Health 2012, 102, 2149–2156. [Google Scholar] [CrossRef]
- Vishnu, C.; Datla, R.; Roy, D.; Babu, S.; Mohan, C.K. Human Fall Detection in Surveillance Videos Using Fall Motion Vector Modeling. IEEE Sensors J. 2021, 21, 17162–17170. [Google Scholar] [CrossRef]
- Mubashir, M.; Shao, L.; Seed, L. A survey on fall detection: Principles and approaches. Neurocomputing 2013, 100, 144–152. [Google Scholar] [CrossRef]
- Saleh, M.; Jeannes, R.L.B. Elderly Fall Detection Using Wearable Sensors: A Low Cost Highly Accurate Algorithm. IEEE Sensors J. 2019, 19, 3156–3164. [Google Scholar] [CrossRef]
- Wang, X.; Ellul, J.; Azzopardi, G. Elderly Fall Detection Systems: A Literature Survey. Front. Robot. AI 2020, 7. [Google Scholar] [CrossRef]
- Albawendi, S.; Lotfi, A.; Powell, H.; Appiah, K. Video Based Fall Detection using Features of Motion, Shape and Histogram. In Proceedings of the 11th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 26–29 June 2018; pp. 529–536. [Google Scholar] [CrossRef]
- Yadav, S.K.; Luthra, A.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. ARFDNet: An efficient activity recognition & fall detection system using latent feature pooling. Knowl. Based Syst. 2022, 239, 107948. [Google Scholar] [CrossRef]
- Sehairi, K.; Chouireb, F.; Meunier, J. Elderly fall detection system based on multiple shape features and motion analysis. In Proceedings of the 2018 IEEE International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 2–4 April 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Lu, N.; Wu, Y.; Feng, L.; Song, J. Deep Learning for Fall Detection: Three-Dimensional CNN Combined with LSTM on Video Kinematic Data. IEEE J. Biomed. Health Inform. 2018, 23, 314–323. [Google Scholar] [CrossRef]
- Han, Q.; Zhao, H.; Min, W.; Cui, H.; Zhou, X.; Zuo, K.; Liu, R. A Two-Stream Approach to Fall Detection with MobileVGG. IEEE Access 2020, 8, 17556–17566. [Google Scholar] [CrossRef]
- Khraief, C.; Benzarti, F.; Amiri, H. Elderly fall detection based on multi-stream deep convolutional networks. Multimed. Tools Appl. 2020, 79, 19537–19560. [Google Scholar] [CrossRef]
- Li, J.; Han, L.; Zhang, C.; Li, Q.; Liu, Z. Spherical Convolution Empowered Viewport Prediction in 360 Video Multicast with Limited FoV Feedback. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–23. [Google Scholar] [CrossRef]
- Feng, Q.; Feng, Z.; Su, X. Design and Simulation of Human Resource Allocation Model Based on Double-Cycle Neural Network. Comput. Intell. Neurosci. 2021, 2021, 7149631. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Liu, M.; Li, D.; Zheng, W.; Yin, L.; Wang, R. Recent Advances in Pulse-Coupled Neural Networks with Applications in Image Processing. Electronics 2022, 11, 3264. [Google Scholar] [CrossRef]
- Qin, X.; Liu, Z.; Liu, Y.; Liu, S.; Yang, B.; Yin, L.; Liu, M.; Zheng, W. User OCEAN Personality Model Construction Method Using a BP Neural Network. Electronics 2022, 11, 3022. [Google Scholar] [CrossRef]
- Lu, H.; Zhu, Y.; Yin, M.; Yin, G.; Xie, L. Multimodal Fusion Convolutional Neural Network with Cross-Attention Mechanism for Internal Defect Detection of Magnetic Tile. IEEE Access 2022, 10, 60876–60886. [Google Scholar] [CrossRef]
- Zhou, W.; Wang, H.; Wan, Z. Ore Image Classification Based on Improved CNN. Comput. Electr. Eng. 2022, 99, 107819. [Google Scholar] [CrossRef]
- Huang, C.-Q.; Jiang, F.; Huang, Q.-H.; Wang, X.-Z.; Han, Z.-M.; Huang, W.-Y. Dual-Graph Attention Convolution Network for 3-D Point Cloud Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–13. [Google Scholar] [CrossRef]
- Xu, S.; He, Q.; Tao, S.; Chen, H.; Chai, Y.; Zheng, W. Pig Face Recognition Based on Trapezoid Normalized Pixel Difference Feature and Trimmed Mean Attention Mechanism. IEEE Trans. Instrum. Meas. 2023, 72, 3500713. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, L. SA-FPN: An effective feature pyramid network for crowded human detection. Appl. Intell. 2022, 52, 12556–12568. [Google Scholar] [CrossRef]
- Shi, Y.; Xu, X.; Xi, J.; Hu, X.; Hu, D.; Xu, K. Learning to Detect 3D Symmetry from Single-View RGB-D Images With Weak Supervision. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Zhu, T.; Wang, S.; Wang, S.; Xiong, Z. LFRSNet: A robust light field semantic segmentation network combining contextual and geometric features. Front. Environ. Sci. 2022, 10, 1443. [Google Scholar] [CrossRef]
- Sheng, H.; Cong, R.; Yang, D.; Chen, R.; Wang, S.; Cui, Z. UrbanLF: A Comprehensive Light Field Dataset for Semantic Segmentation of Urban Scenes. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7880–7893. [Google Scholar] [CrossRef]
- Galvão, Y.M.; Ferreira, J.; Albuquerque, V.A.; Barros, P.; Fernandes, B.J. A multimodal approach using deep learning for fall detection. Expert Syst. Appl. 2020, 168, 114226. [Google Scholar] [CrossRef]
- Ramirez, H.; Velastin, S.A.; Meza, I.; Fabregas, E.; Makris, D.; Farias, G. Fall Detection and Activity Recognition Using Human Skeleton Features. IEEE Access 2021, 9, 33532–33542. [Google Scholar] [CrossRef]
- Cheng, S.; Liu, J.; Li, Z.; Zhang, P.; Chen, J.; Yang, H. 3D error calibration of spatial spots based on dual position-sensitive detectors. Appl. Opt. 2023, 62, 933–943. [Google Scholar] [CrossRef] [PubMed]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. 2022. Available online: http://arxiv.org/abs/2207.02696 (accessed on 14 December 2022).
- Abbate, S.; Avvenuti, M.; Bonatesta, F.; Cola, G.; Corsini, P.; Vecchio, A. A smartphone-based fall detection system. Pervasive Mob. Comput. 2012, 8, 883–899. [Google Scholar] [CrossRef]
- Palmerini, L.; Klenk, J.; Becker, C.; Chiari, L. Accelerometer-Based Fall Detection Using Machine Learning: Training and Testing on Real-World Falls. Sensors 2020, 20, 6479. [Google Scholar] [CrossRef] [PubMed]
- Bagalà, F.; Becker, C.; Cappello, A.; Chiari, L.; Aminian, K.; Hausdorff, J.M.; Zijlstra, W.; Klenk, J. Evaluation of Accelerometer-Based Fall Detection Algorithms on Real-World Falls. PLoS ONE 2012, 7, e37062. [Google Scholar] [CrossRef] [PubMed]
- Irtaza, A.; Adnan, S.M.; Aziz, S.; Javed, A.; Ullah, M.O.; Mahmood, M.T. A framework for fall detection of elderly people by analyzing environmental sounds through acoustic local ternary patterns. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 1558–1563. [Google Scholar] [CrossRef]
- Fan, X.; Zhang, H.; Leung, C.; Shen, Z. Robust unobtrusive fall detection using infrared array sensors. In Proceedings of the 2017 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Daegu, Republic of Korea, 16–18 November 2017; pp. 194–199. [Google Scholar] [CrossRef]
- Muheidat, F.; Tawalbeh, L.A.; Tyrer, H. Context-Aware, Accurate, and Real Time Fall Detection System for Elderly People. In Proceedings of the 2018 IEEE 12th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 31 January–2 February 2018; pp. 329–333. [Google Scholar] [CrossRef]
- Chaccour, K.; Darazi, R.; el Hassans, A.H.; Andres, E. Smart carpet using differential piezoresistive pressure sensors for elderly fall detection. In Proceedings of the 2015 IEEE 11th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Abu Dhabi, United Arab Emirates, 19–21 October 2015; pp. 225–229. [Google Scholar] [CrossRef]
- Ren, L.; Peng, Y. Research of Fall Detection and Fall Prevention Technologies: A Systematic Review. IEEE Access 2019, 7, 77702–77722. [Google Scholar] [CrossRef]
- Wang, S.; Sheng, H.; Yang, D.; Zhang, Y.; Wu, Y.; Wang, S. Extendable Multiple Nodes Recurrent Tracking Framework With RTU++. IEEE Trans. Image Process. 2022, 31, 5257–5271. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Sheng, H.; Zhang, Y.; Wang, S.; Xiong, Z.; Ke, W. Hybrid Motion Model for Multiple Object Tracking in Mobile Devices. IEEE Internet Things J. 2022, 1. [Google Scholar] [CrossRef]
- Xiong, S.; Li, B.; Zhu, S. DCGNN: A single-stage 3D object detection network based on density clustering and graph neural network. Complex Intell. Syst. 2022, 1–10. [Google Scholar] [CrossRef]
- Lu, S.; Liu, S.; Hou, P.; Yang, B.; Liu, M.; Yin, L.; Zheng, W. Soft Tissue Feature Tracking Based on Deep Matching Network. Comput. Model. Eng. Sci. 2023, 136, 363–379. [Google Scholar] [CrossRef]
- Zhao, L.; Lu, S.-P.; Chen, T.; Yang, Z.; Shamir, A. Deep Symmetric Network for Underexposed Image Enhancement with Recurrent Attentional Learning. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 12055–12064. [Google Scholar] [CrossRef]
- Zhang, Q.; Nie, Y.; Zheng, W. Dual Illumination Estimation for Robust Exposure Correction. Comput. Graph. Forum 2019, 38, 243–252. Available online: http://arxiv.org/abs/1910.13688 (accessed on 21 July 2022). [CrossRef]
- Charfi, I.; Miteran, J.; Dubois, J.; Atri, M.; Tourki, R. Optimized spatio-temporal descriptors for real-time fall detection: Comparison of support vector machine and Adaboost-based classification. J. Electron. Imaging 2013, 22, 41106. [Google Scholar] [CrossRef]
- Kwolek, B.; Kepski, M. Human fall detection on embedded platform using depth maps and wireless accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Cheng, E.J.; Prasad, M.; Yang, J.; Khanna, P.; Chen, B.-H.; Tao, X.; Young, K.-Y.; Lin, C.-T. A fast fused part-based model with new deep feature for pedestrian detection and security monitoring. Measurement 2019, 151, 107081. [Google Scholar] [CrossRef]
- Hong, G.-J.; Li, D.-L.; Pare, S.; Saxena, A.; Prasad, M.; Lin, C.-T. Adaptive Decision Support System for On-Line Multi-Class Learning and Object Detection. Appl. Sci. 2021, 11, 11268. [Google Scholar] [CrossRef]
- Cheng, E.J.; Prasad, M.; Yang, J.; Zheng, D.R.; Tao, X.; Mery, D.; Young, K.Y.; Lin, C.T. A novel online self-learning system with automatic object detection model for multimedia applications. Multimed. Tools Appl. 2020, 80, 16659–16681. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; Kwon, Y.; Michael, K.; Liu, C.; Fang, J.; Abhiram, V.; Skalski, S.P. Ultralytics/yolov5: V6.0—YOLOv5n ‘Nano’ models, Roboflow integration, TensorFlow export, OpenCV DNN support. Zenodo Tech. Rep. 2021. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. Available online: http://arxiv.org/abs/1804.02767 (accessed on 20 January 2023).
- Huang, C.-J. Integrate the Hungarian Method and Genetic Algorithm to Solve the Shortest Distance Problem. In Proceedings of the 2012 Third International Conference on Digital Manufacturing & Automation, Guilin, China, 31 July–2 August 2012; pp. 496–499. [Google Scholar] [CrossRef]
- Chang, L.C.; Pare, S.; Meena, M.S.; Jain, D.; Li, D.L.; Saxena, A.; Prasad, M.; Lin, C.T. An Intelligent Automatic Human Detection and Tracking System Based on Weighted Resampling Particle Filtering. Big Data Cogn. Comput. 2020, 4, 27. [Google Scholar] [CrossRef]
- Poonsri, A.; Chiracharit, W. Fall detection using Gaussian mixture model and principle component analysis. In Proceedings of the 2017 9th International Conference on Information Technology and Electrical Engineering (ICITEE), Phuket, Thailand, 12–13 October 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Chamle, M.; Gunale, K.G.; Warhade, K.K. Automated unusual event detection in video surveillance. In Proceedings of the 2016 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–27 August 2016; pp. 1–4. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| File Name | Xmin | Ymin | Xmax | Ymax | YOLOv5 Annotations | Manually Corrected Annotations |
|---|---|---|---|---|---|---|
| 000018.jpg | 120 | 101 | 187 | 200 | person | upright |
| 000019.jpg | 109 | 113 | 194 | 198 | person | upright |
| 000020.jpg | 108 | 116 | 195 | 197 | person | fall |
| 000021.jpg | 107 | 125 | 198 | 200 | person | fall |
| 000022.jpg | 107 | 125 | 198 | 200 | person | fall |
| 000023.jpg | 107 | 125 | 198 | 200 | person | fall |
| Parameters | The Proposed Method | YOLOv7 | YOLOv5 | RetinaNet |
|---|---|---|---|---|
| Learning Rate | 0.01–0.1 | 0.01–0.1 | 0.001–0.01 | 0.00025 |
| Batch Size | 8 | 8 | 32 | 8 |
| Epochs | 100 | 100 | 100 | 100 |
| Data Enhancement | Yes | - | - | - |
| Method | RetinaNet | YOLOv5 | YOLOv7 |
|---|---|---|---|
| YOLOv7 | <0.001 | 0.0095 | 1 |
| Method | Accuracy (%) | 0.5 mAP | Precision of Fall |
|---|---|---|---|
| Poonsri et al. [58] | 91.38 | - | 0.886 |
| Chamle et al. [59] | 79.31 | - | 0.794 |
| RetinaNet [49] | 59.02 | 0.842 | 0.775 |
| YOLOv5 [54] | 86.0 | 0.947 | 0.896 |
| YOLOv7 [32] | 90.5 | 0.966 | 0.935 |
| The proposed method | 94.5 | 0.986 | 0.970 |
| Method | RetinaNet | YOLOv5 | YOLOv7 |
|---|---|---|---|
| YOLOv7 | <0.001 | 0.085 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zi, X.; Chaturvedi, K.; Braytee, A.; Li, J.; Prasad, M. Detecting Human Falls in Poor Lighting: Object Detection and Tracking Approach for Indoor Safety. Electronics 2023, 12, 1259. https://doi.org/10.3390/electronics12051259
Zi X, Chaturvedi K, Braytee A, Li J, Prasad M. Detecting Human Falls in Poor Lighting: Object Detection and Tracking Approach for Indoor Safety. Electronics. 2023; 12(5):1259. https://doi.org/10.3390/electronics12051259
Chicago/Turabian StyleZi, Xing, Kunal Chaturvedi, Ali Braytee, Jun Li, and Mukesh Prasad. 2023. "Detecting Human Falls in Poor Lighting: Object Detection and Tracking Approach for Indoor Safety" Electronics 12, no. 5: 1259. https://doi.org/10.3390/electronics12051259
APA StyleZi, X., Chaturvedi, K., Braytee, A., Li, J., & Prasad, M. (2023). Detecting Human Falls in Poor Lighting: Object Detection and Tracking Approach for Indoor Safety. Electronics, 12(5), 1259. https://doi.org/10.3390/electronics12051259