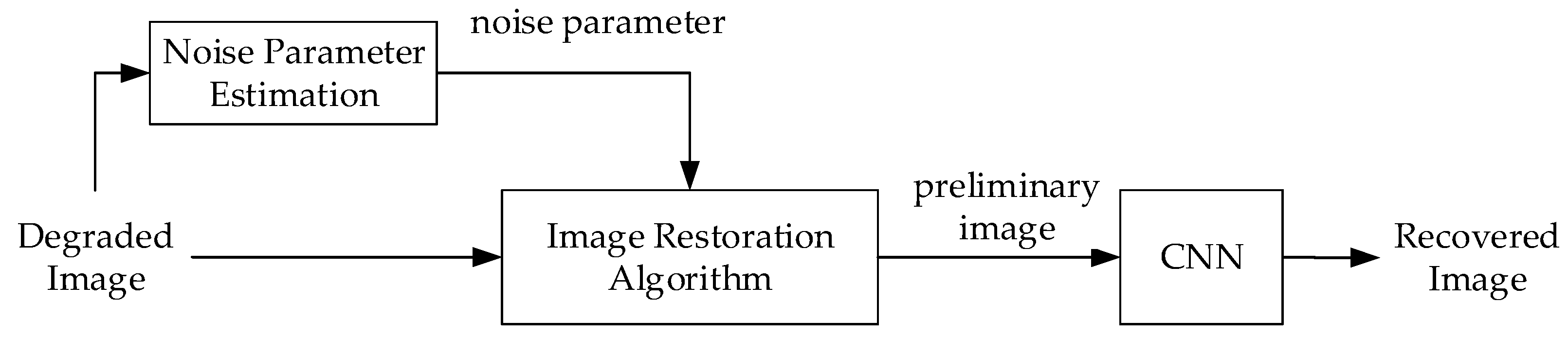
1. Introduction
Image denoising is a classic and indispensable research topic in low-level vision tasks, which is the premise of high-level vision tasks [
1]. The clear and high-quality images obtained by denoising serve the high-level vision and make completing the tasks better. This paper mainly introduces the denoising of signal-dependent noisy images.
With the continuous updating of digital image acquisition technology, equipment for acquiring images and the number of acquired images are also increasing, and people’s requirements for image quality are also increasing. However, due to the imperfections of imaging systems, imaging equipment, and transmission media, many different types of noise are introduced during the formation of images in different devices, which can affect the imaging effect, and thus the quality of the image. Noise-contaminated images will have a considerable impact on subsequent image processing. Noise pollution will affect the quality of subsequent image processing, such as image recognition, segmentation, classification, and so on [
2].
In this paper, we model the signal-independent noise in the image, and then input it into the denoising network to solve the problem. During training and testing, networks that take the noise level of the input image and the noise image as input have a wider range of noise levels than networks with a single noise image as the input. The success of CNN denoisers is significantly dependent on whether the distributions of synthetic and real noises are well matched. Therefore, realistic noise models are the foremost issue for blind denoising of real photographs. According to [
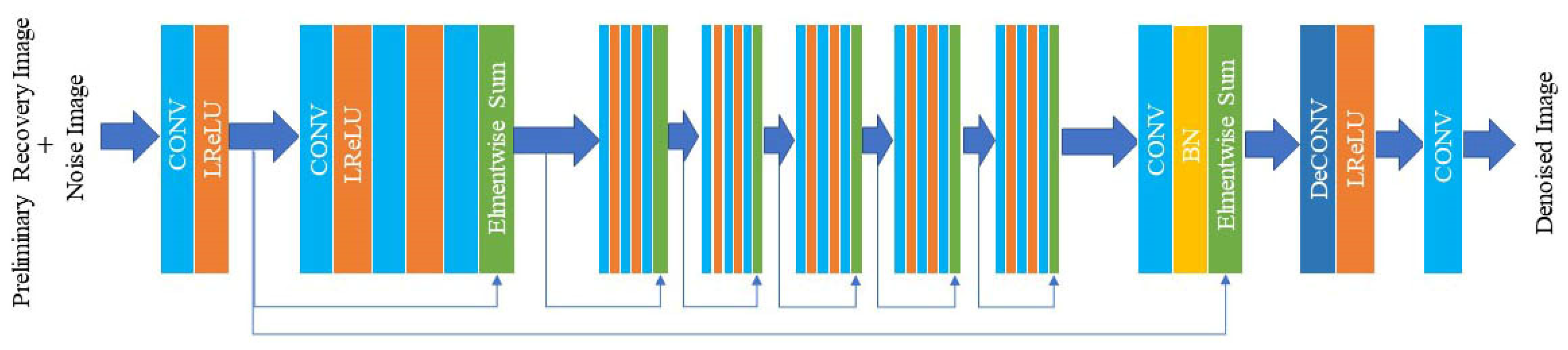
3], signal-dependent noise can be modeled by signal-dependent Gaussian noise distribution, and the signal-dependent Gaussian model has been considered as a more appropriate alternative than other models for real raw noise modeling. In addition, it is necessary to further optimize the graph after noise modeling. Because there are two unavoidable errors in modeling, the first one is the error generated in the estimation of noise parameters. The second is when pixel values are obtained by the local statistical feature method, which also has errors. Thus, after acquiring the preliminary picture, we use the preliminary image and the noise image together as the input into the denoising network. The two errors are reduced through the network.
At present, image denoising relies on the image degradation model, but most of the image degradation model algorithms are simple and do not match the complex noise in the real image. It leads to the less ideal denoising effect. Therefore, it is necessary to design a more reasonable model or an algorithm with better performance. This paper proposes a method combining the model method and the convolutional neural network. The preliminary image obtained by the model method is used as a part of the network’s input, and the final image is output through the continuous iteration of the network.
Most image denoising is Gaussian noise denoising. The variance of the noise is constant and does not change with the position and intensity of the pixel, the noise level is the only parameter required for modeling. The model of this degradation process is generally defined as:
where
is the degraded image pixel value,
is the original image pixel value,
is Additive White Gaussian Noise (AWGN) with a standard deviation of
. Since Gaussian white noise has only one unknown parameter, the variance of the noise, DnCNN enumerates the variance of different values in the process of training the network model [
4], meaning that the network can remove AWGN in the case of unknown noise variance. However, because there are other noises in the real image, the Gaussian modeling of the image cannot achieve a good denoising effect.
Alessandro Foi [
5] modeled the real noise as a signal-dependent Poisson–Gaussian noise model and proposed an estimation method for Poisson–Gaussian noise parameters. However, he trimmed the underexposure and overexposure data when experimenting. Despite achieving good performance, the method is limited to Poisson–Gaussian noise due to modeling problems. The model needs to know the Gaussian and Poisson components a and b, the model is as follows:
where
is the pixel position in the domain.
is the observed signal, and
is the original signal.
is zero-mean independent random noise with a standard deviation equal to 1.
is a function that gives the standard deviation of the overall noise component. The variance is an expression for the Poisson Gaussian noise component from which estimates of
and
are obtained.
Liu et al. [
6] proposed a generalized signal-dependent noise model.
where
is the noisy pixel value,
is the noise-free pixel value, and
and
are zero-mean Gaussian variables.
is an exponential parameter that controls signal dependence by changing the three NLF parameters
,
, and
, and the noise model can represent various types of noise by changing these three parameters. Existing models usually assume that one parameter is known, and only estimate the remaining two parameters to simplify the problem. This method requires three parameters; thus, the amount of calculation is large.
The model we propose in this paper is a noise parameter estimation for real camera noise, which can be modeled with a signal-dependent Gaussian distribution [
3].
where
is the degraded image pixel value,
is the original image pixel value, and the noise parameters
and
are fixed and only change with the gain of the sensor. The main reasons for adopting this model are as follows: similar to the generalized noise model shown in [
6], the exponential coefficient will make the calculation of the numerical solution difficult, and the number of unknown parameters in the Gaussian correlated noise model is less than that of the generalized signal-dependent noise model, thus the estimation difficulty will be much less. The model we use is more accurate in parameter estimation than the Poisson–Gaussian noise model, and the denoising effect is better.
In this paper, we propose a deep signal-dependent denoising noise algorithm. The algorithm further improves the noise suppression ability and improves the visual effect of the restored image. The denoising algorithm in this paper can effectively improve image quality, which plays an important role in many fields. First, we find a more reasonable model for the signal-related noise image, which has a wider range of application scenarios and a higher accuracy of parameter estimation. Second, we combine the model with the convolutional neural network to further improve the image-denoising effect. The algorithm further improves the noise suppression ability and improves the visual effect of the restored image. The denoising algorithm in this paper can effectively improve the image quality, which has a wide range of applications for the multimedia, military, medical, and other industries.
2. The Related Work
Ben et al. [
3] proposed a technique for jointly denoising bursts of images taken from a handheld camera. Burst image noise parameter estimation operates on a set of successive, rapidly taken images to compute a single, noise-free result. In particular, they propose a convolutional neural network architecture for predicting spatially varying kernels that can both align and denoise frames: a synthetic data generation approach based on a realistic noise formation model. The method for burst denoising they proposed has the signal-to-noise ratio benefits of multi-image denoising and the large capacity and generality of a convolution neural network.
Liu et al. [
7] proposed a segmentation-based image denoising algorithm for signal dependent noise. First, they identify the noise level function for a given single noisy image. Then, after initial denoising, segmentation is applied to the prefiltered image.
Tan et al. [
8] proposed a deep convolutional neural network named “deep residual noise estimator” (DRNE) for pixel-wise noise-level estimation. The DRNE framework they designed consists of a stack of customized residual blocks without any pooling or interpolation operations. The noise level estimation graph obtained by DRNE, and the ground truth graph are used as the input of the convolutional neural network, which makes the original network achieve better results.
Talmaj et al. [
9] improved KPN, and they proposed a deep neural network-based approach called Multi-Kernel Prediction Networks (MKPN) for burst image denoising. MKPN predicts kernels of not just one size but of varying sizes and performs a fusion of these different kernels resulting in one kernel per pixel. This enables MKPN to better extract information from images. MKPN has achieved good results in texture and homogeneous area denoising. Bingyang et al. [
10] proposed a novel network including noise estimation module and removal module (NERNet). The noise estimation module automatically estimates the noise level map corresponding to the information extracted by symmetric dilated block and pyramid feature fusion block. To fuse noisy multi-modality image pairs accurately and efficiently, Huanqiu et al. [
11] proposed a multi-modality image simultaneous fusion and denoising method.
Zhonghua et al. [
12] proposed a novel model-guided boosting framework. By using the Regularization by Denoising (RED), they could apply explicit regularization equipped with powerful image denoising engine to establish the global minimization problem, making the obtained model clearly defined and well optimized. The framework enjoyed the advantage of easily extending to the case of composite denoising via superadding a regularization term.
Gang Liu et al. [
13] proposed a true wide CNN (WCNN) to reorganize several convolutional layers. Each subnetwork had its own input and output and was supervised by its own loss function to capture image features with a specific direction and scale, allowing the WCNN to have sufficient convolutional layers to capture image features while avoiding vanishing/exploding gradients. Jiechao Shen et al. [
14] proposed the sparse representation-based network (SRNet). They considered combining the sparse representation with deep learning to make this traditional model more effective and efficient. They embedded the convolutional neural network (CNN) into the sparse representation framework. Laya et al. [
15] proposed the Multi Scaling Aided Double Decker (MUS-ADD) convolutional neural network. It solved the disadvantages of the traditional method, which required a large number of models, etc. Shuang Xu et al. [
16] built a more interpretable network. An observation model was proposed to account for modality gap between target and guidance images. Then, they formulated a deep prior regularized optimization problem, and solved it by the alternating direction method of multipliers (ADMM) algorithm. Yang Ou et al. [
17] proposed a novel multi-scale weighted group sparse coding model (MS-WGSC). It better restored the structure and the edges of images contaminated by noise. Lei Zhang et al. [
18] proposed the Robust Low-Rank Analysis with Adaptive Weighted Tensor (AWTD) method. It obtained the low-rank approximation of the tensor by adding adaptive weights to the unfolding matrix of the tensor. By decomposing true image into a cartoon part and texture part, Xiao Li et al. [
19] proposed a fractional image denoising model with two-component regularization terms. Sunder Ali et al. [
20] proposed a cascaded and recursive convolutional neural network (CRCNN) framework, which could cope with spatial variant noise and blur artifacts in a single denoising framework. Lei Zhang et al. [
21] designed a novel denoising model named Kronecker Component with Low-Rank Dictionary (KCLD), which replaced the Frobenius norm with a Nuclear norm in order to capture the low-rank property better. Phan et al. [
22] proposed an adaptive model that used the mean curvature of an image surface to control the strength of smoothing. A fast method for noise level estimation is proposed to improve the effectiveness of the proposed model.
In [
23], Heng Yao et al. proposed an algorithm to efficiently estimate the noise level function (NLF), which is defined as the noise standard deviation with respect to image intensity. The method divided the input image into overlapping patches. The confidence levels of the noise samples and the prior of the camera response function were then employed as constraints for the recovery of the NLF. The NLF was incorporated into other denoising schemes to obtain better results than the original scheme.
Guo et al. [
24] trained a convolutional blind denoising network (CBDNet) with a more realistic noise model and real-world noisy–clean image pairs. To further provide an interactive strategy to rectify denoising results conveniently, a noise estimation subnetwork with asymmetric learning to suppress under-estimation of noise level was embedded into CBDNet. They adopted an asymmetric loss by imposing more penalty on an under-estimation error of noise level, making CBDNet perform robustly when the noise model was not well matched with real-world noise.
Zhao et al. [
25] proposed a simple but robust network called SDNet to improve the effectiveness and practicability of deep denoising models. Additionally, there is no need to estimate the noise level. The model learning had exploited clean–noisy image pairs, newly produced, built on a generalized signal-dependent noise model. To separate the noise from image content as fully as possible, a kind of lifting residual module was specifically proposed for discriminative feature extraction. The network emphasized separating the noise from image content via a direct, fully end-to-end residual learning strategy.
In [
26], Dong et al. proposed a grouped residual dense network (GRDN). The core part of DRDN is defined as a grouped residual dense block (GRDB) and used as a building module of GRDN. They experimentally show that image-denoising performance can be significantly improved by cascading GRDBs. Meanwhile, they developed a new generative adversarial network-based real-world noise modeling method.
4. Experiment
In this section, we assess the performance of the proposed method and compare it with other methods to show the improvement of the method relative to other methods.
The experimental environment comprised an Intel Core i7-9700k CPU, 128 GB RAM, and a NVIDIA GeForce RTX 2070 GPU. In addition, the deep learning framework used was Pytorch.
The paper uses the Berkeley Segmentation Dataset (Berkeley segmentation dataset, BSD) (BSD500 for short) as the network training dataset. The BSD500 dataset contains 500 grayscale images, and all images are of size 481 × 321. In the experiment, 200 sets of noise are added to each image to construct an image with real noise. Therefore, the training dataset consists of 105 training samples in total. The noise parameters and are randomly sampled from [10−3, 10−2] to [10−2.5, 10−1], respectively.
In the selection of test data sets, we use Kodak, McMaster, and Set12 as test data sets, and compare the more advanced methods proposed on these data sets. Although KPN [
3] is designed for multi-frame image input, it can be adjusted to a single-frame image by changing the network input to compare with our method.
For comparison with other methods, we evaluated the noise levels corresponding to three fixed sets of
and
. Similar to [
29], gamma correction was performed first, then we added signal-dependent Gaussian noise, took the generated noise image as the input:
, where
was the intensity of image pixels and the noise parameters
and
were randomly sampled from [10
−3, 10
−2] to [10
−2.5, 10
−1]. Furthermore, similar to [
4], the noise level was estimated as:
. Note that the noise Equation (6) assigned three single sets of parameter values, i.e.,
(
= 2.0 × 10
−2,
= 10
−1),
(
= 6.0 × 10
−2,
= 2 × 10
−1), and
(
= 9.0 × 10
−2,
= 3 × 10
−1), to generate clean-noisy image pairs for image denoising. We claim that harnessing noise Equation (6) with combinations of different parameter settings may lead to better results. In spite of that, it was found that the parameter setting as above is a more robust candidate than several other choices.
Similar to most CNNs used for image denoising, the optimizer chooses the adaptive moment estimation (Adam) method in setting network parameters, and the loss function is MSE. The whole training process contains 180 epochs, and the batch size is set to 20, thus the training data set can be divided into 5000 batches. However, for each epoch, we only sample the first 3000 batches for training. Before the next epoch training, we shuffle the order of all batches and select the top 3000 batches for training. The training adopts a linear piecewise learning rate, the learning rate of the top 90 epochs is 10−3, the next 60 epochs are 10−4, and the last 30 epochs are 10−5.
To test the effectiveness of each block for our network on image denoising, we used ablation experiments to analyze the performance. The images in the Set12 dataset were selected for the experiment, and the noise level
(
= 2.0 × 10
−2,
= 10
−1) was added. Then, we denoised the images separately in groups. The denoising results are shown in
Table 2, which shows the PSNR. The results show that residuals made the denoising effect better. Additionally, the addition of preliminary image made the denoising effect better.
The paper selects four methods: KPN [
3], CBDNet [
24], SRNet [
14], and WCNN [
13]. The link to the code is posted in references [
30,
31,
32,
33]. Five methods are compared on all the datasets used in the paper. KPN generates a stack of per-pixel filter kernels that jointly aligns, averages, and denoises a burst to produce a clean version of the reference frame. The establishment of the CBD model takes into account both the Poisson–Gaussian model and the in-camera processing pipeline. However, the Poisson–Gaussian model does not have a wider range of scenarios than the signal-dependent Gaussian model in the paper. Each subnetwork of WCNN has its input and output and is supervised by its loss function to capture image features with a specific direction and scale, allowing the WCNN to have sufficient convolutional layers to capture image features while avoiding vanishing/exploding gradients. SRNet embeds the CNN into the sparse representation framework. In each phase, two subnetworks are designed with MSR block to model the updating of the sparse coefficient and image, respectively. However, it suffers from performance bottlenecks and large time consumption.
Figure 4a–d is a diagram of each stage of the paper. To see the contrast, we enlarge the green part of the image into the red part. It can be seen that the images have more detail loss and less clarity even if the preliminary image can see the denoising effect. The denoising effect of the restored image is better. The picture detail loss is less, the recovery effect is better.
Figure 5a–e shows a visual comparison of different algorithms in the Set12 dataset. The KPN image effect is normal, the details are lost, and the denoising effect of the shadow area is not very ideal. CBDNet is better than KPN in detail recovery. It loses less detail and restores the shadow part well, but the overall image is not clear. CBDNet is better at processing low-noise images. While SRNet and WCNN performed well in terms of image sharpness and detail, there is still room for improvement. The algorithm proposed in this paper can recover image details more clearly and obtain a better visual effect. It still does not effectively remove all real noise, because the noise model does not perfectly represent real noise.
Table 3 shows the average PSNR in Set12 data sets.
Table 4 shows the average SSIM of different algorithms in Set12 data sets. The average PSNR of the algorithm in the paper is higher than the other algorithms. Except for low-noise images, the denoising effect of CBDNet is slightly better than that of the method in this paper. The performance of SRNet and WCNN is similar to that of the proposed algorithm. However, in terms of SSIM, our algorithm is superior to other algorithms. It shows that the proposed algorithm is superior to the previous algorithms in denoising performance. The average SSIM index of the restored image is close to that of the original image, indicating that the quality of the restored image is close to that of the original noiseless image.
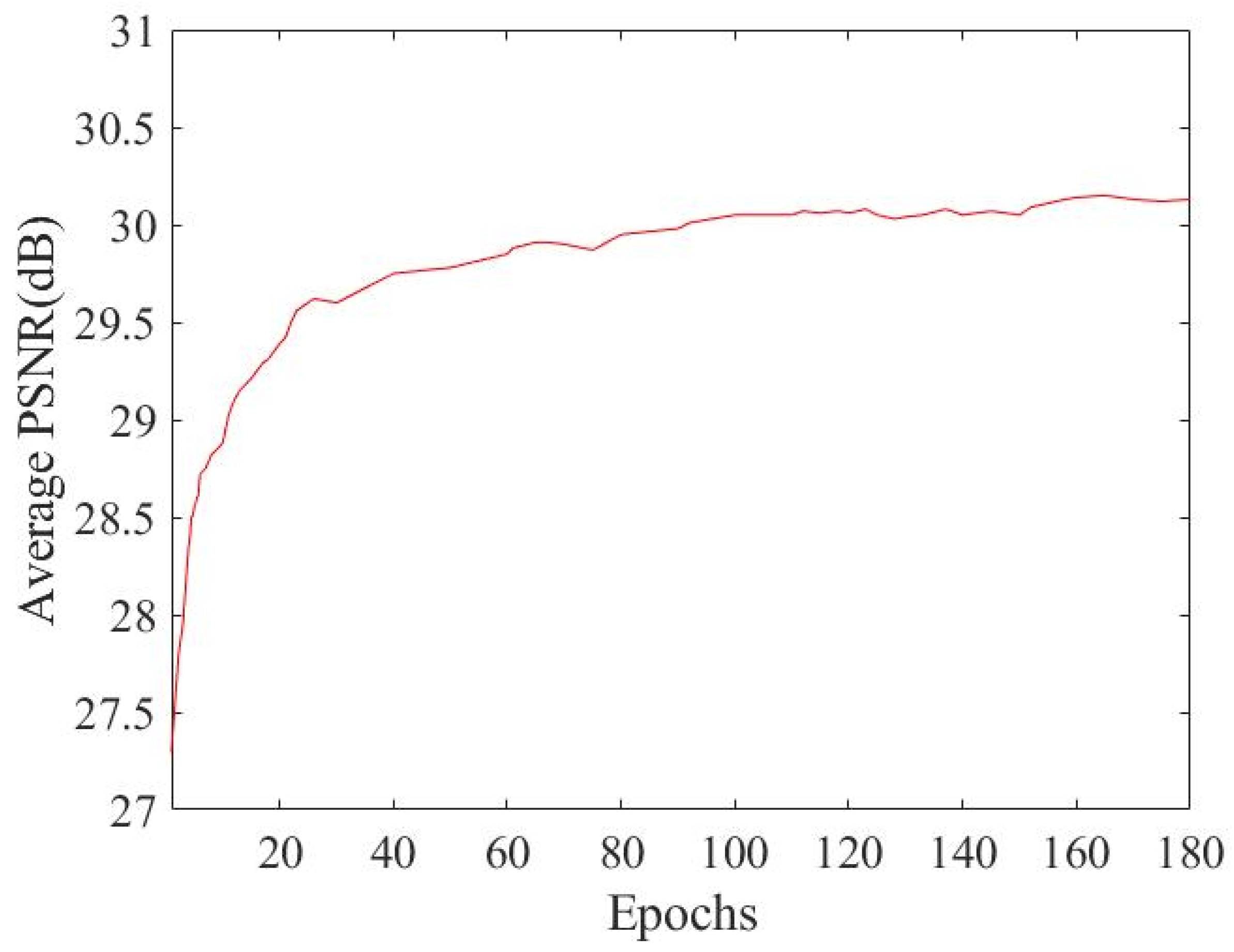
Figure 6 shows the average PSNR of our algorithm on the Set12 test set at the noise level of
(
= 9.0 × 10
−2,
= 3 × 10
−1). It shows the line graph of PSNR changing with the number of iterations. As the number of iterations increases, PSNR gradually flattens out.
Figure 7 shows the loss of our algorithm on the Set12 test set at the noise level of
(
= 9.0 × 10
−2,
= 3 × 10
−1). It shows the line graph of loss changing with the number of iterations. As the number of iterations increases, loss decreases and gradually flattens out.
To verify the denoising effect of our algorithm under high noise, we added a set of denoising experiments
(
= 9.0 × 10
−1,
= 3.0 × 1) for verification.
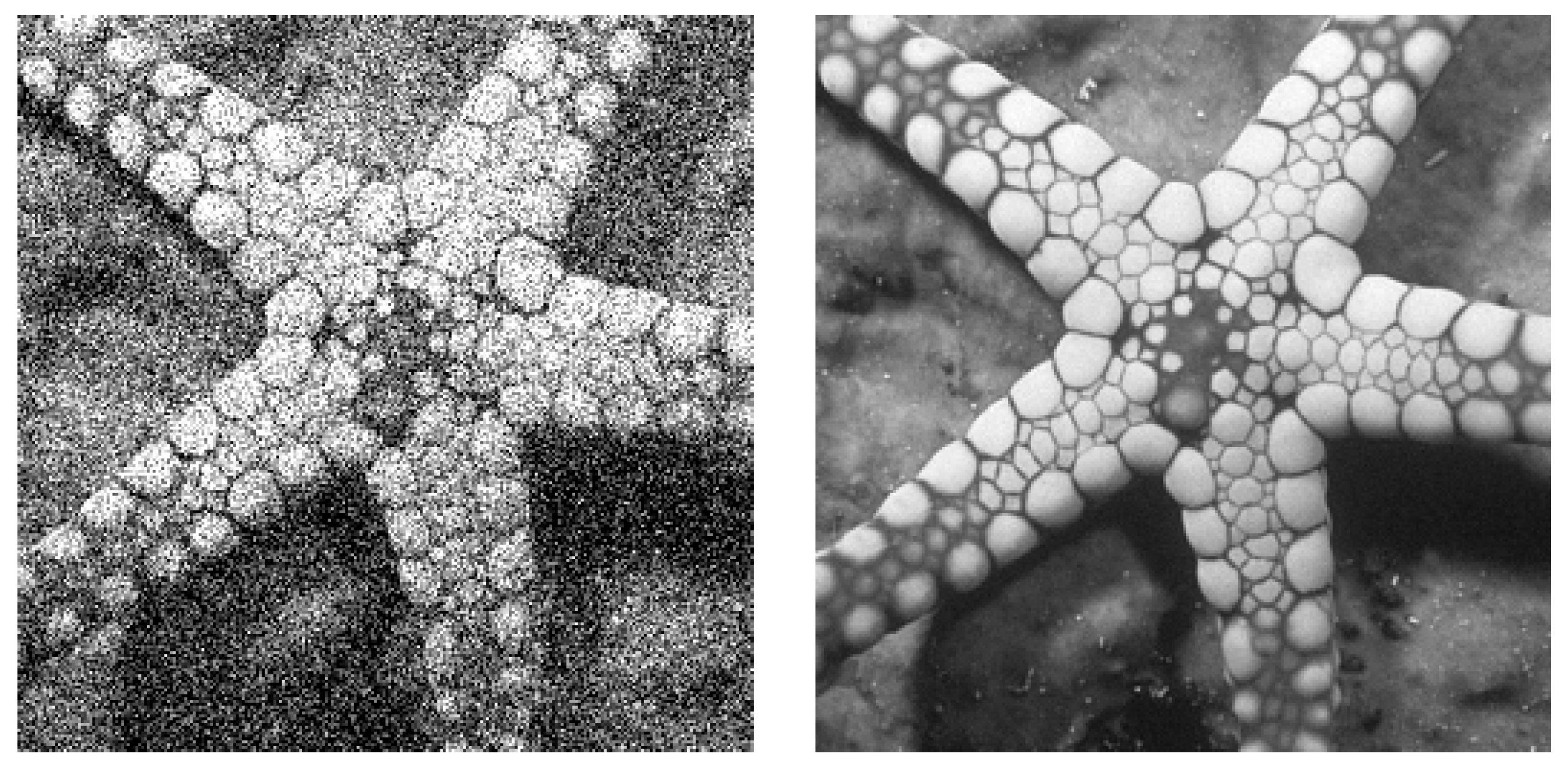
Figure 8a,b shows a comparison of the denoising effect of the proposed method in the case of high noise.
To verify the performance of the denoising algorithm in real scenes, we selected the α57 digital cameras launched by Sony to collect 30 images. To evaluate the performance of our method in terms of visual quality, we performed a subjective evaluation as a qualitative analysis experiment. The evaluation was carried out as a rating experiment where 40 users experienced in image processing viewed, in random order, a set of images. The users were asked to provide ratings for each image according to the following attributes: noise and detail. The final result of the ratings averaged over the observers is illustrated in
Figure 9 and
Figure 10.
Figure 11a–f shows two images we randomly selected. From the first picture, the details of the houses in the shaded part of the image restored by KPN are missing, and the overall effect of the image is not ideal. The local detail of the CBDNet algorithm is stronger than KPN, but the overall visual effect is a bit fuzzy, and the image quality is not good. WCNN and SRNet are better than the first two algorithms in terms of sharpness and image detail, but there is still room for improvement. In the marked areas in the image, we can see that other algorithms are rough in detail recovery in the shadow area, and the denoising effect is not ideal. Our algorithm performs well in this respect. The algorithm in this paper has the strongest local detail retention ability, and the restored image has fine details and a clear texture. In the second picture, KPN is missing some details in the recovered image. The text in the book is obscured, and the overall picture is poor in definition. In the image recovered by CBDNet, the text of the book can be seen, but it is not clear, and the overall image is a little fuzzy. The images recovered by WCNN and SRNet are good, but lower than the algorithm in this paper. In the marked areas in the images, we can see that the labels in the images recovered by other algorithms are fuzzy, and the denoising effect around the labels is not ideal, while the label recovered by our algorithm is clear and the denoising effect is ideal. The algorithm in this paper has a good performance in detail recovery and overall quality.
Figure 12a,b shows the comparison before and after denoising of our algorithm. It can be intuitively seen from comparison figures that the noise in the images is greatly reduced after denoising by our algorithm. The image recovery effect is good, and the details are perfectly restored.
In general, our algorithm can reconstruct the detailed features more successfully. Although it does not achieve the best denoising effect in low noise images, the overall denoising effect is better and the restored images are clear, which is better than other algorithms.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}