


SODAS: Smart Open Data as a Service for Improving Interconnectivity and Data Usability



Abstract
1. Introduction
2. Related Work
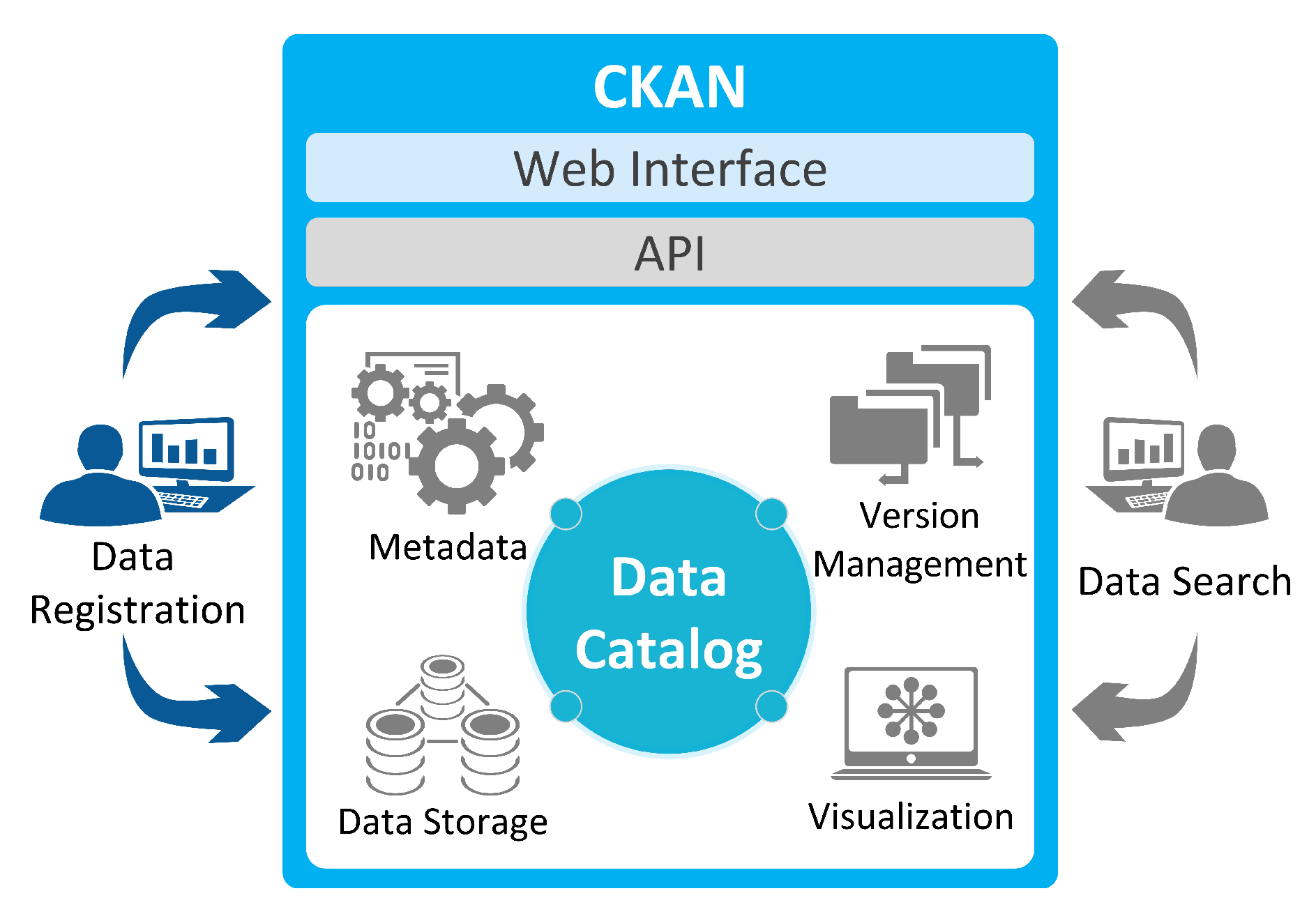
2.1. Open Data Platform
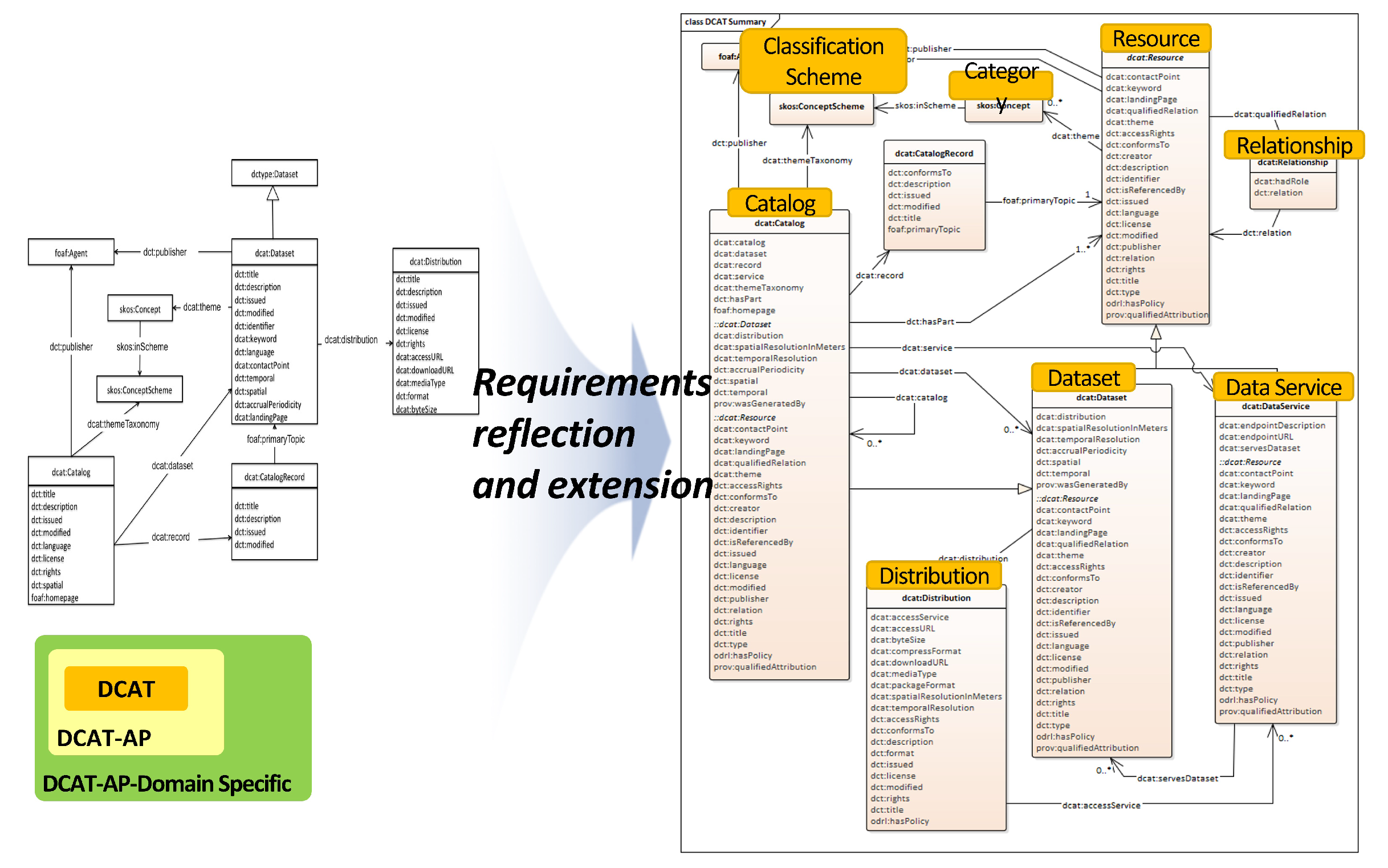
2.2. DCAT
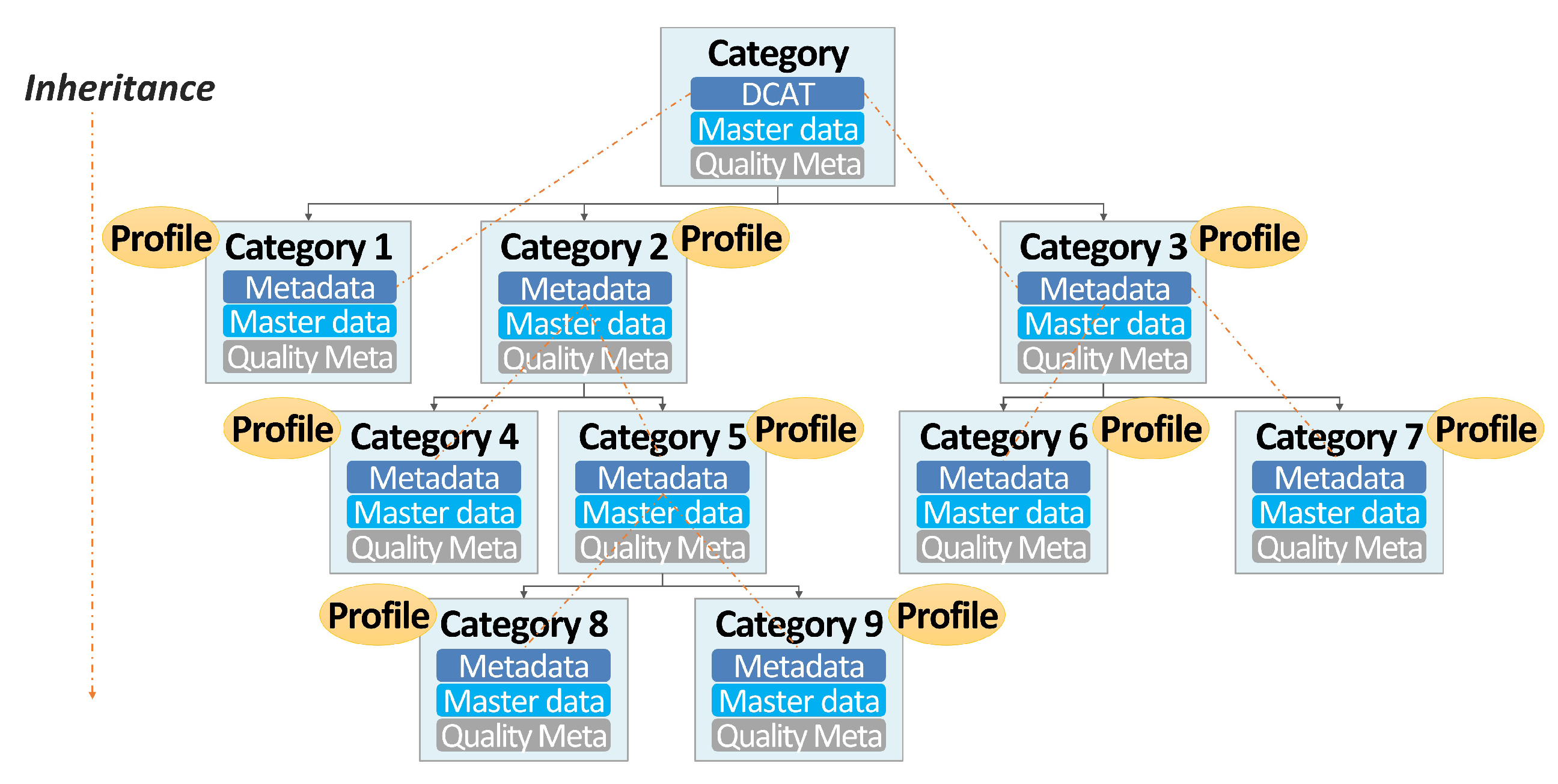
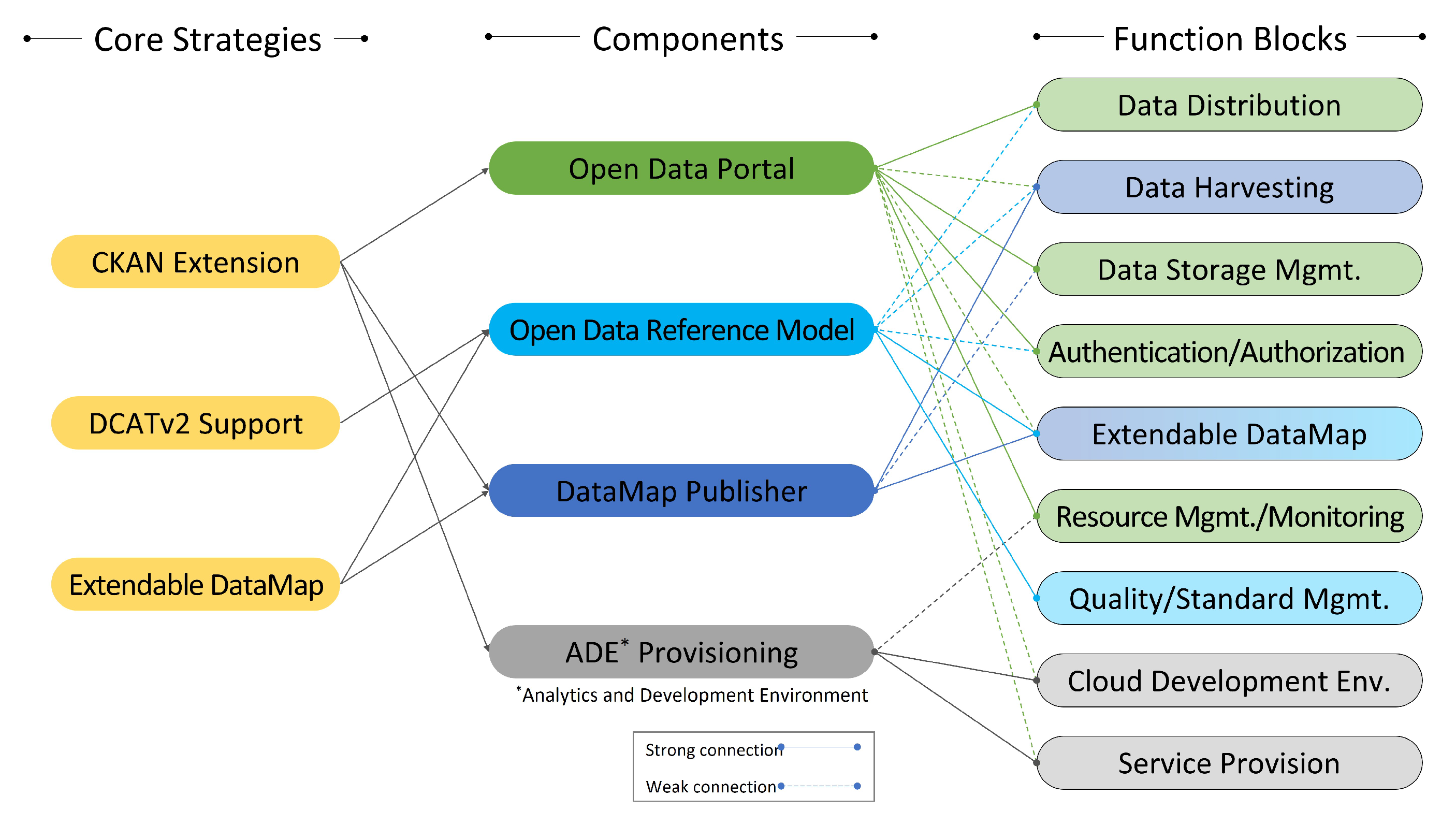
3. Problem Analysis and Core Strategies
4. SODAS Framework
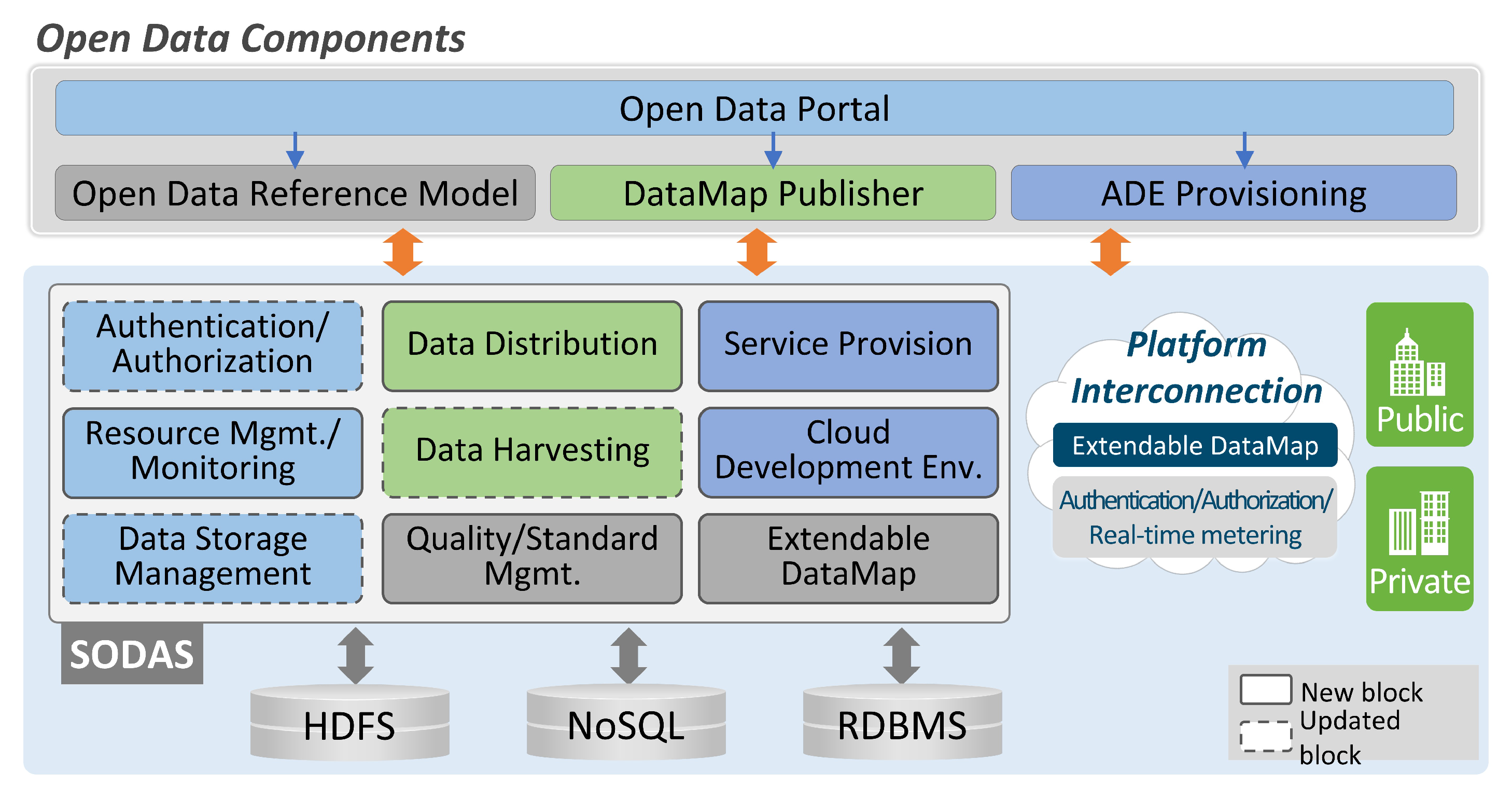
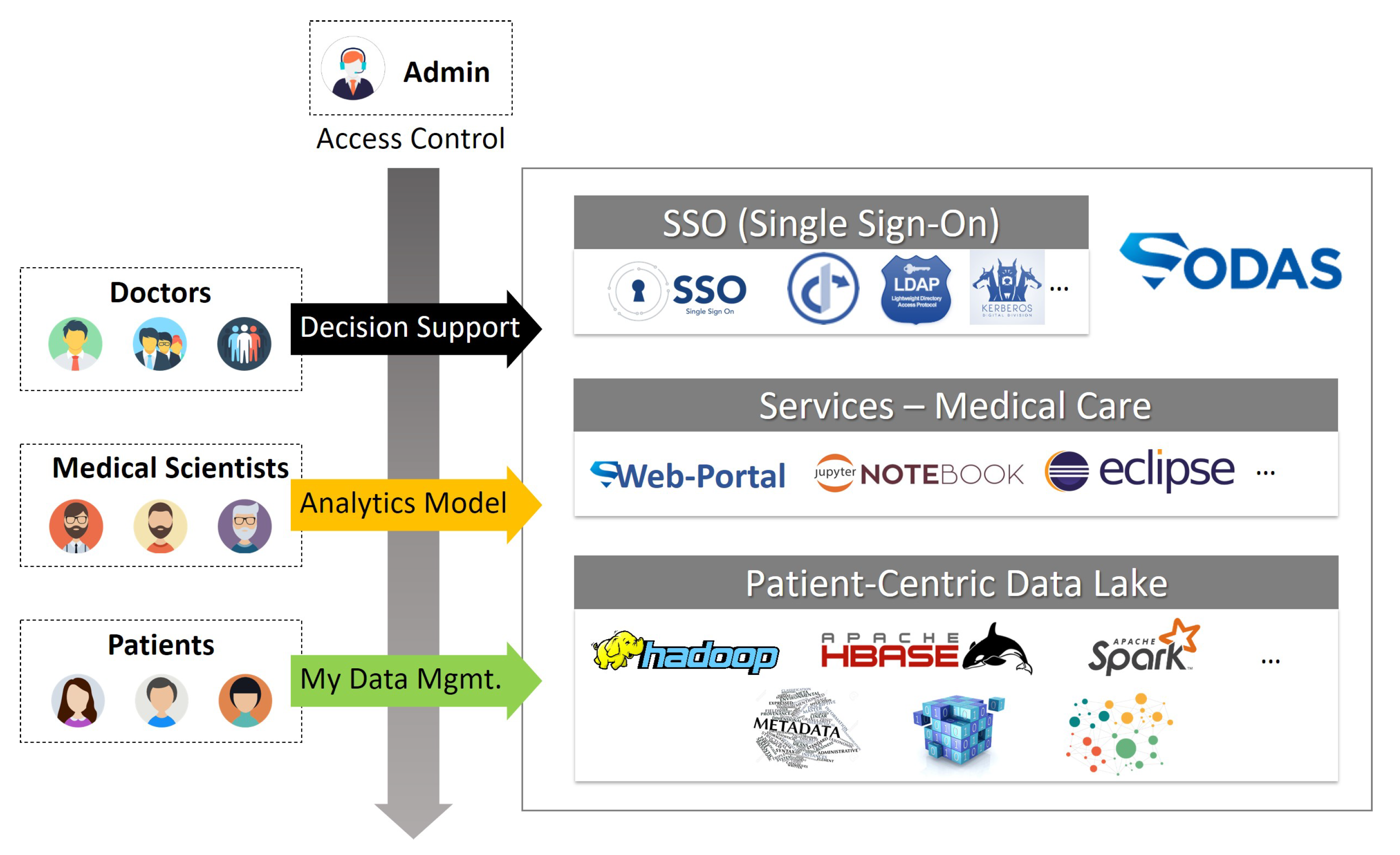
4.1. Overall Framework
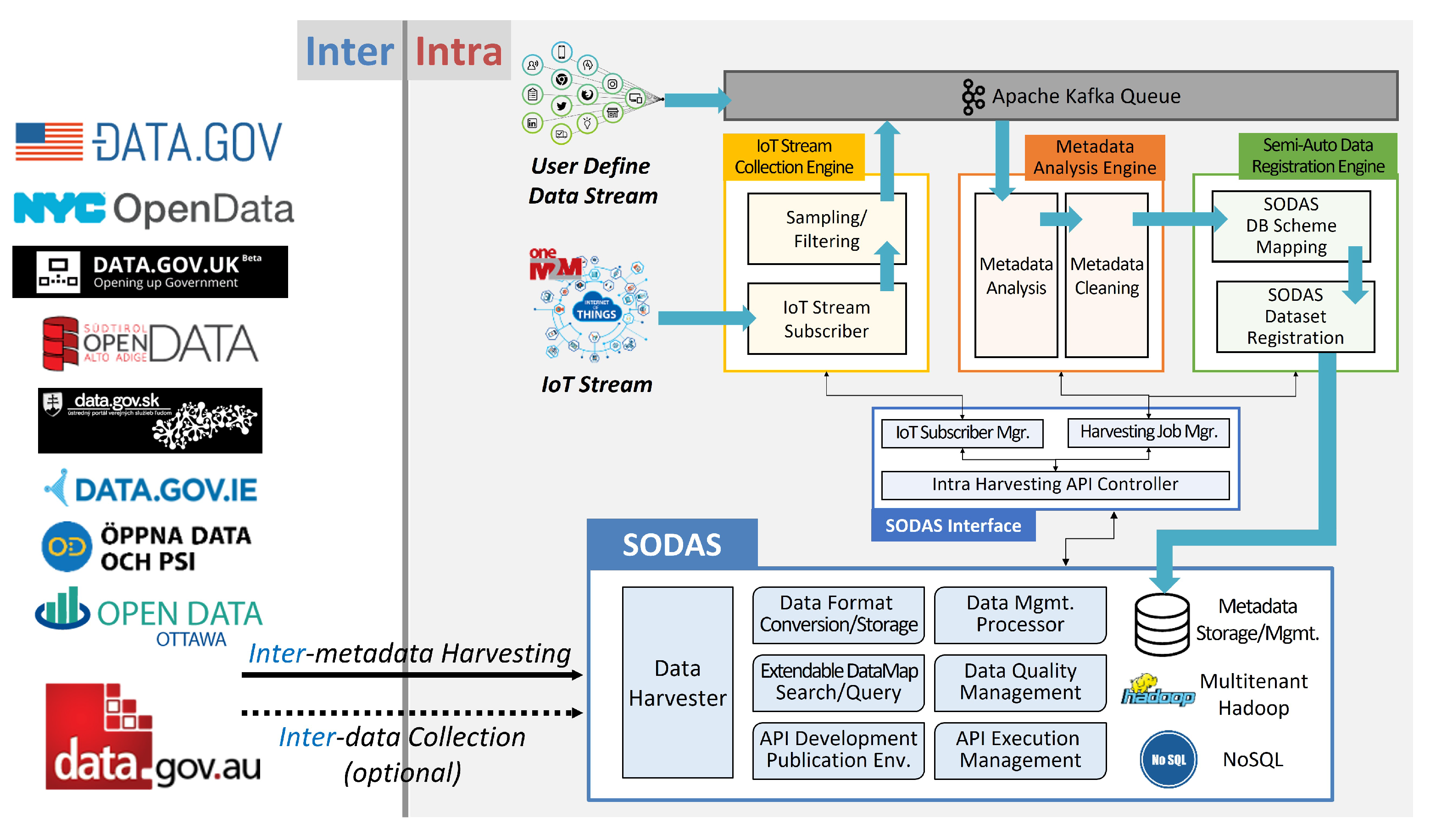
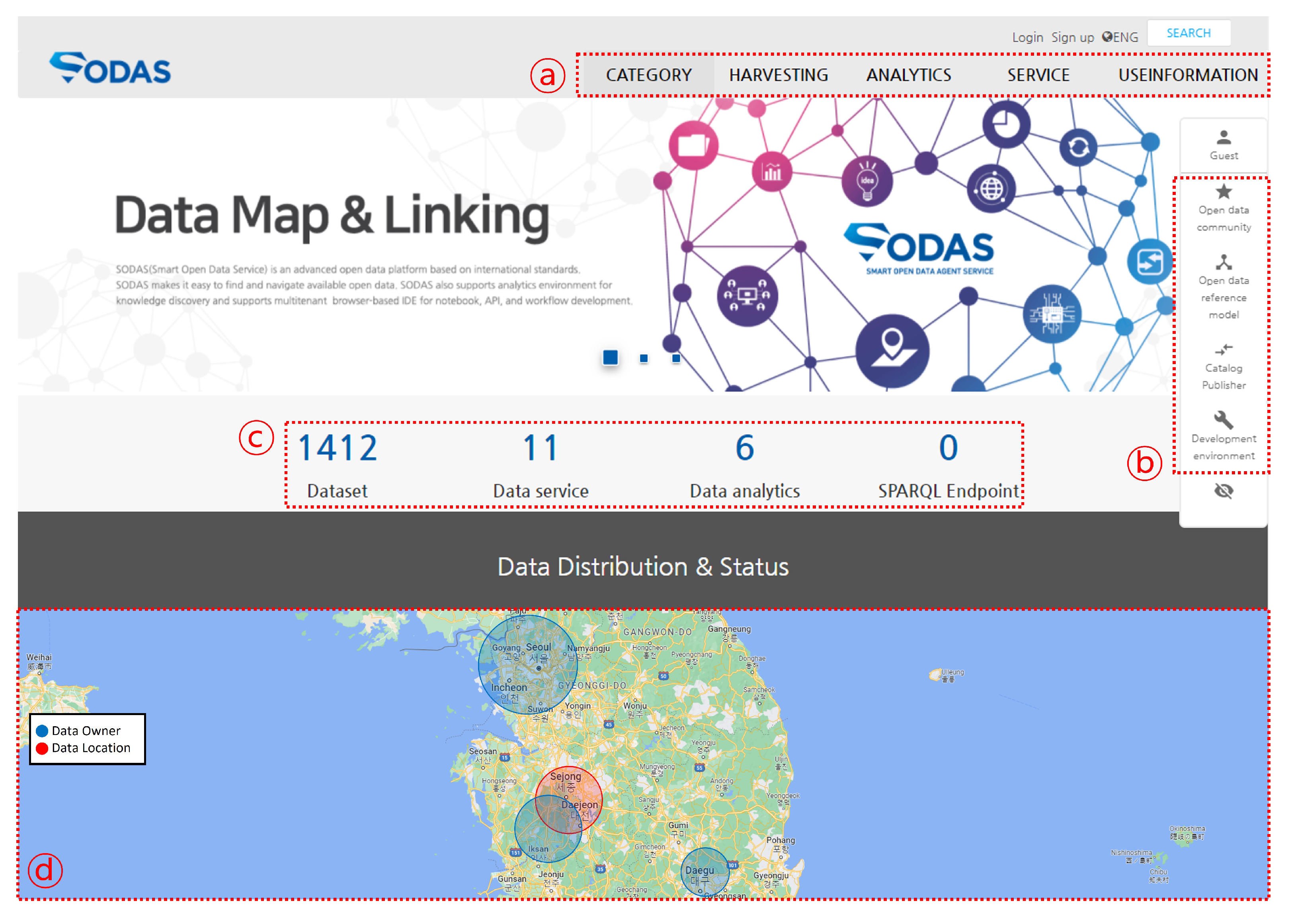
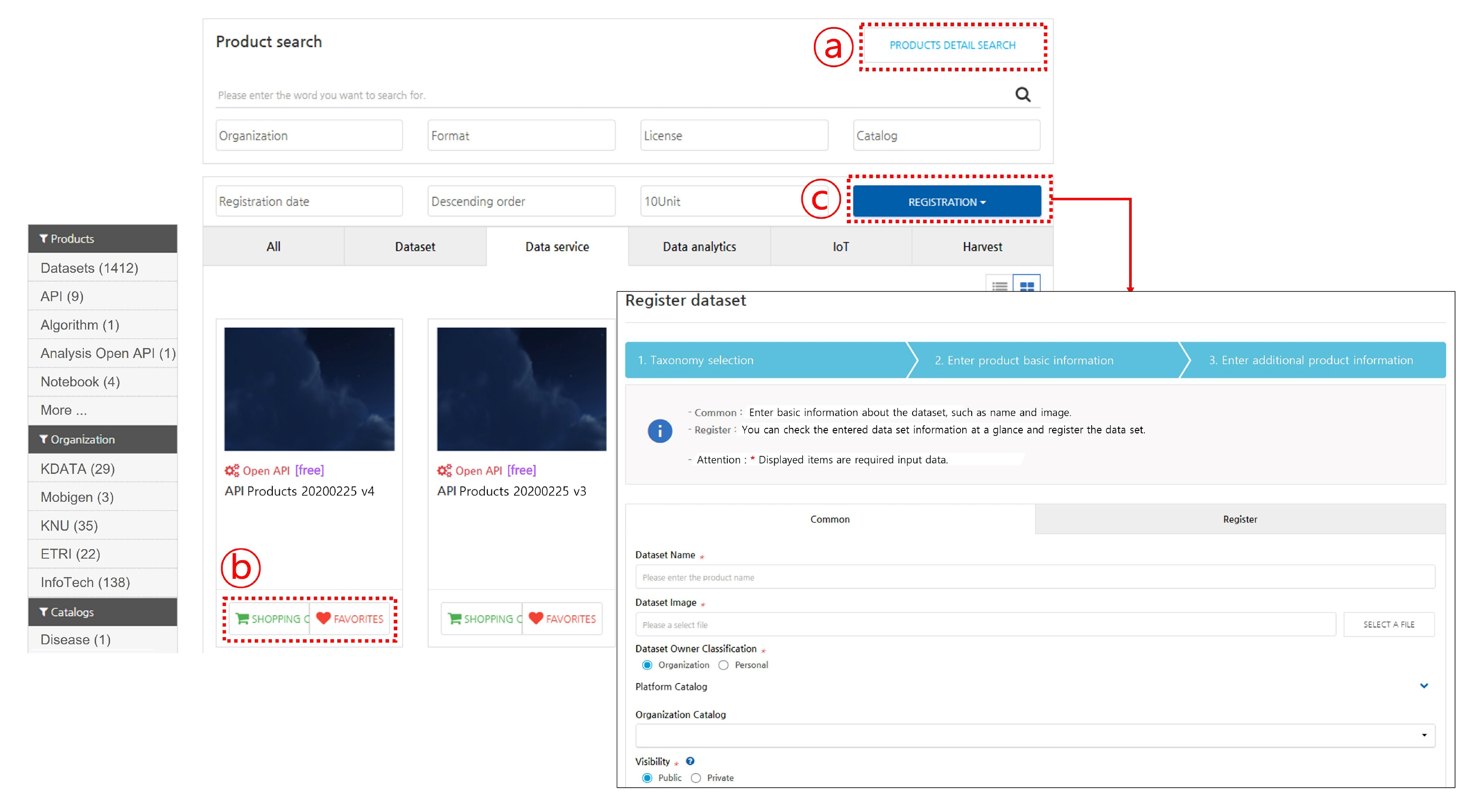
4.2. Open Data Portal
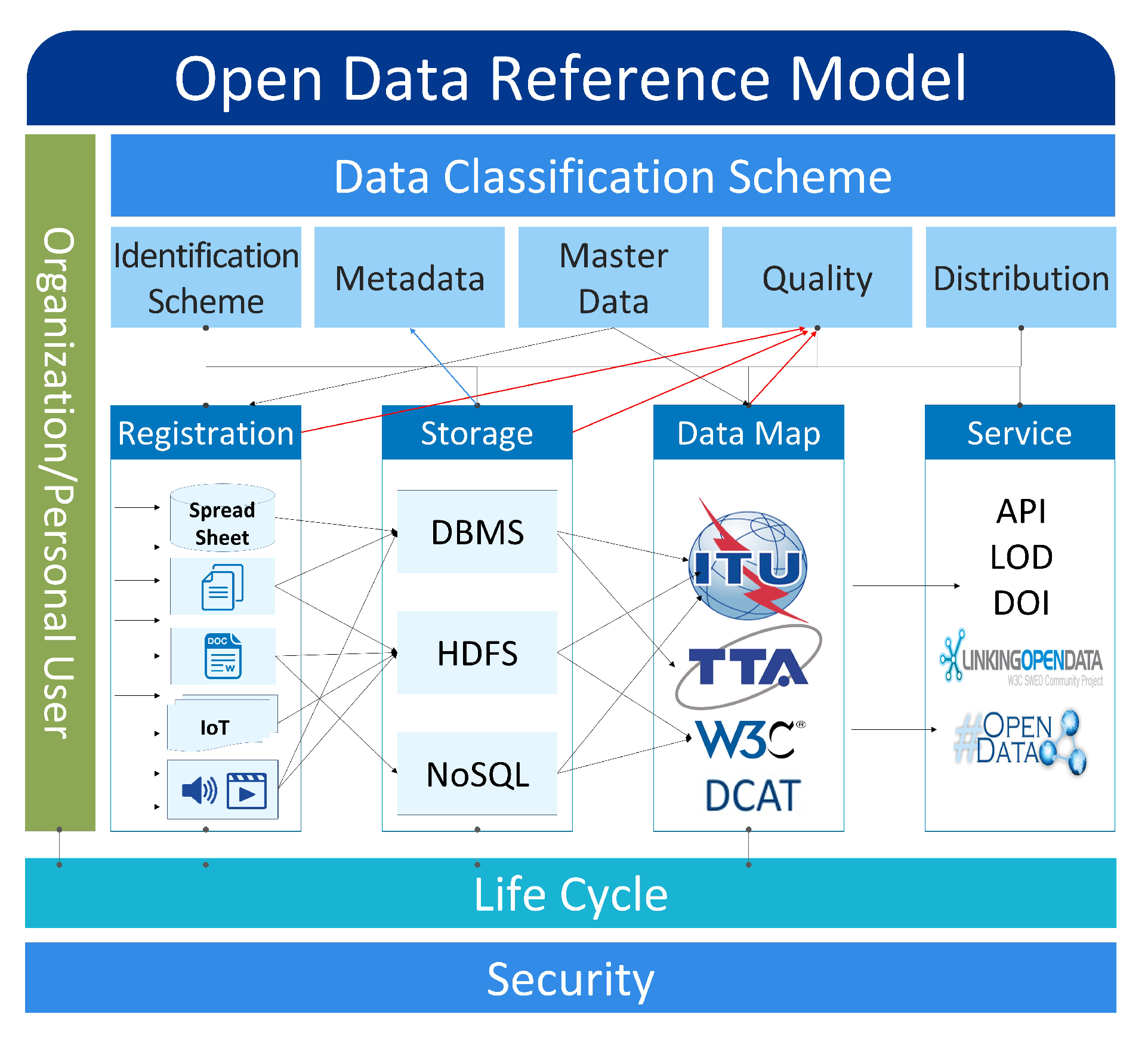
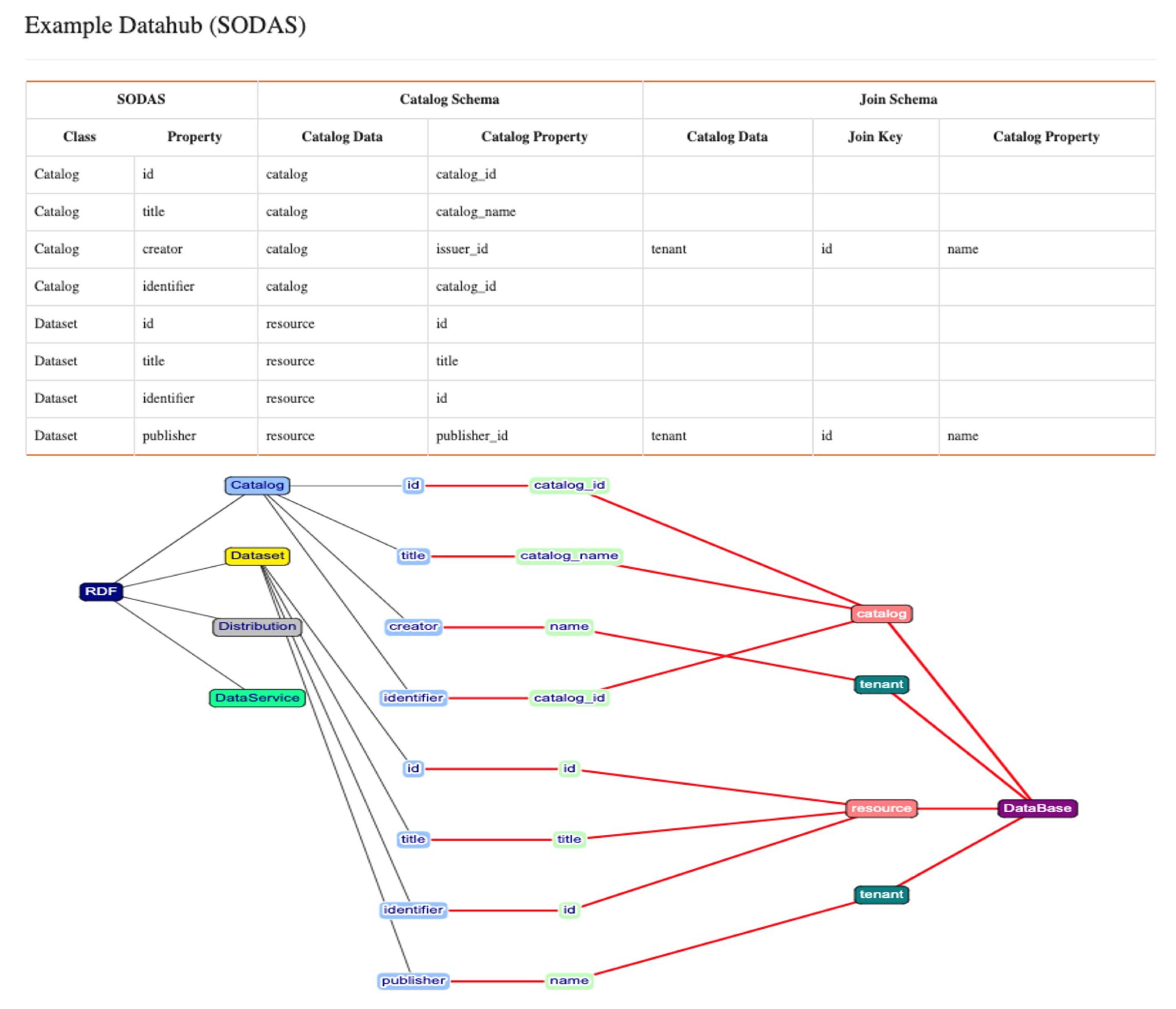
4.3. Open Data Reference Model
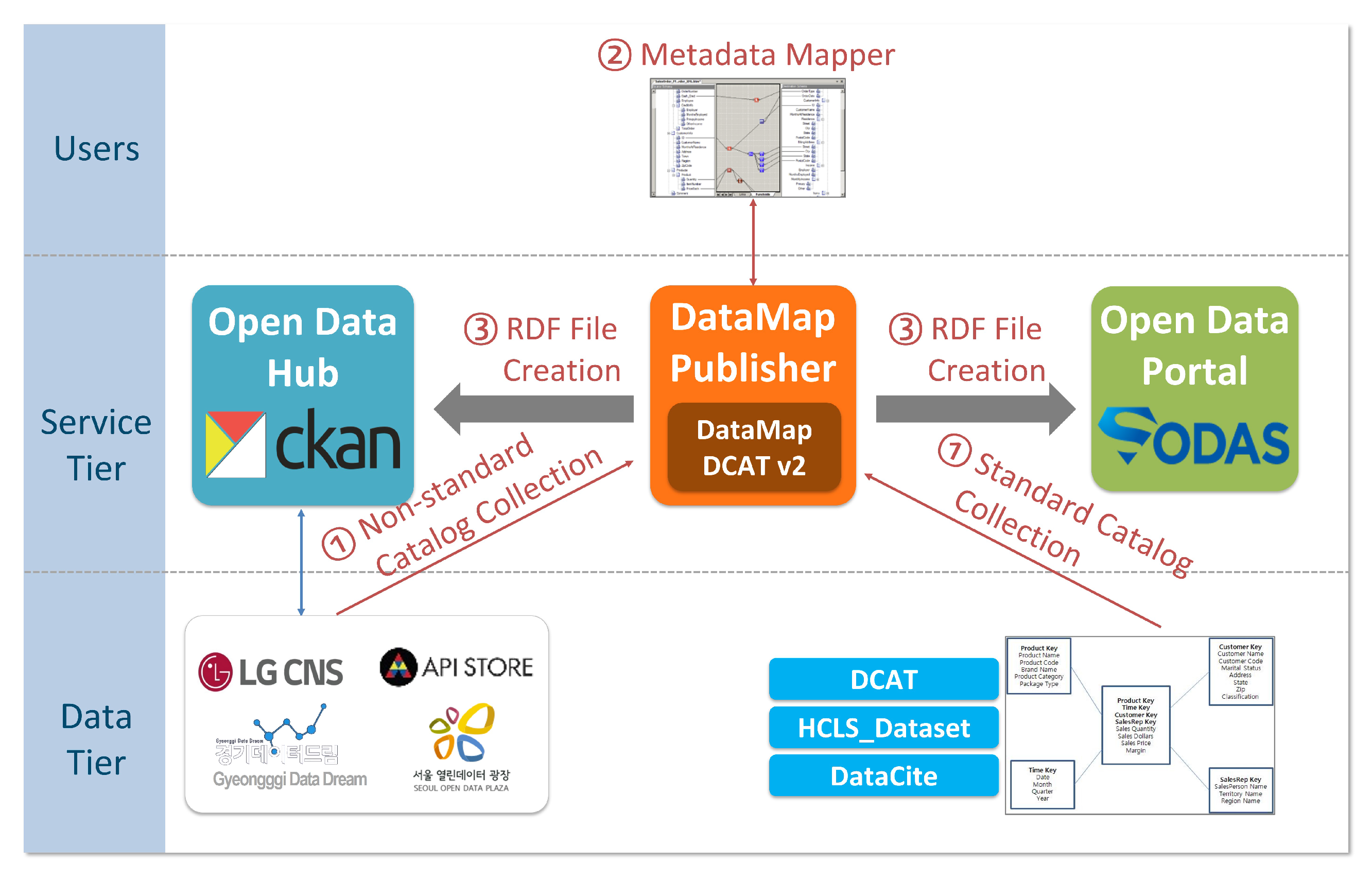
4.4. DataMap Publisher
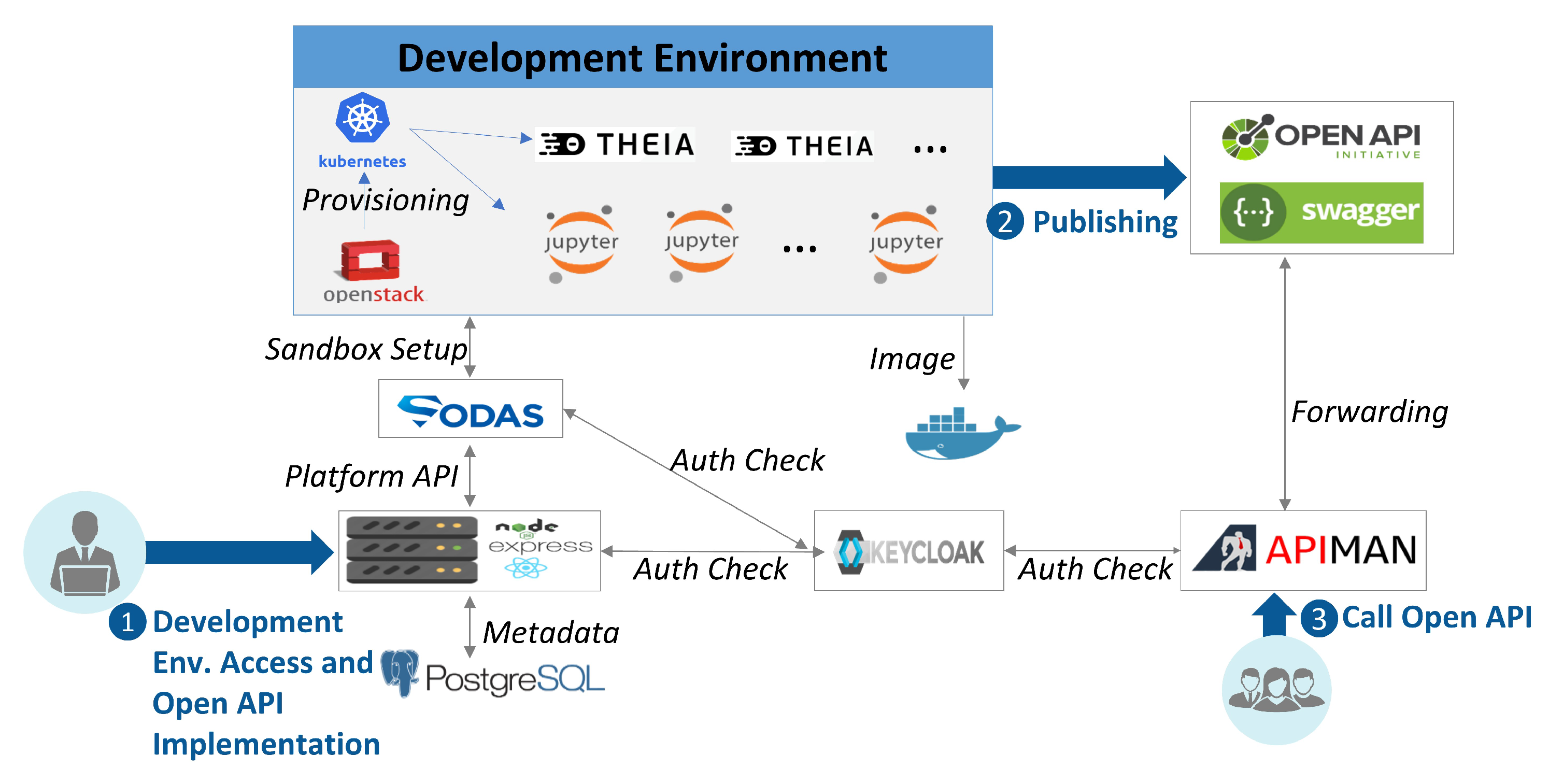
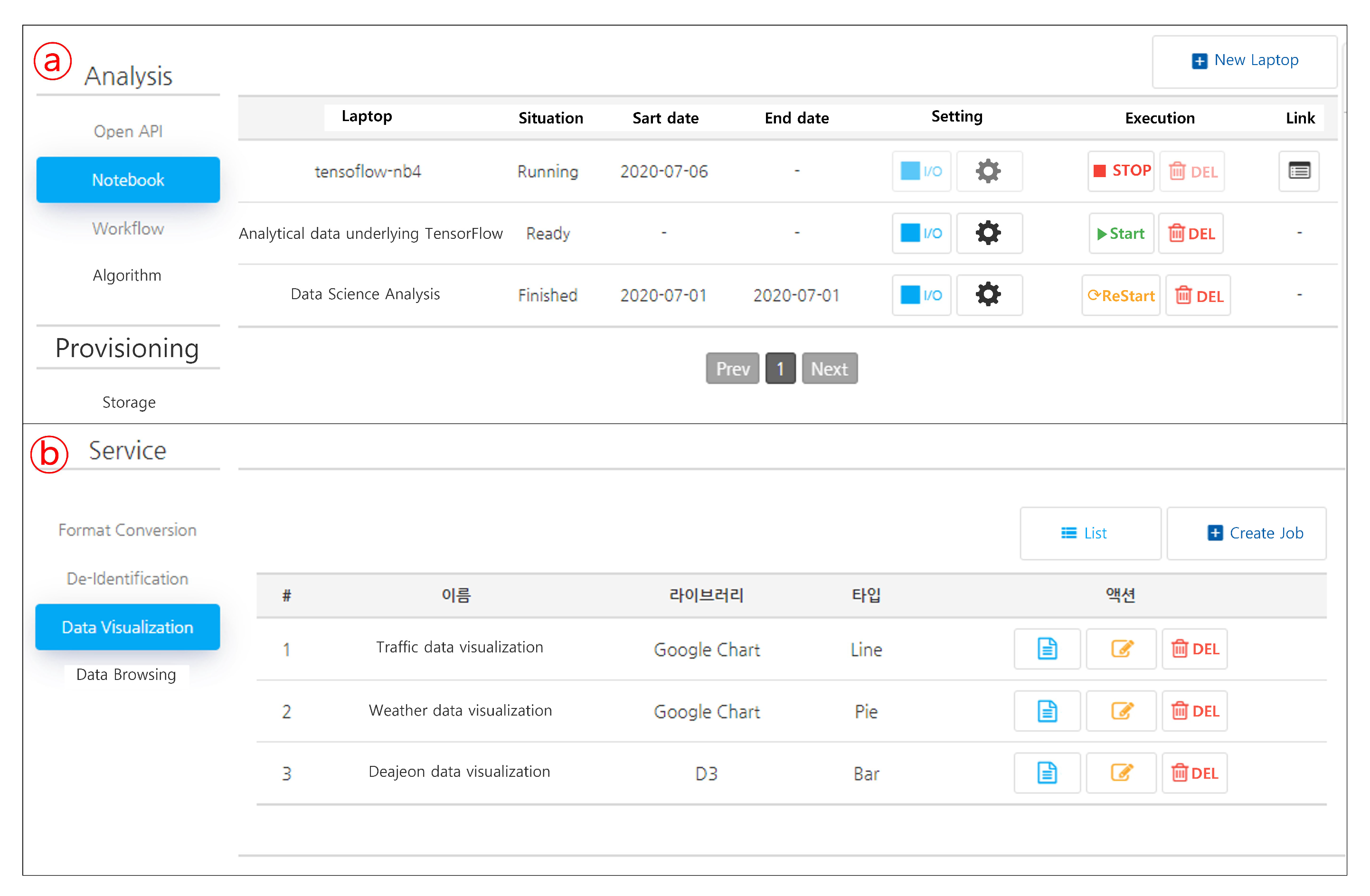
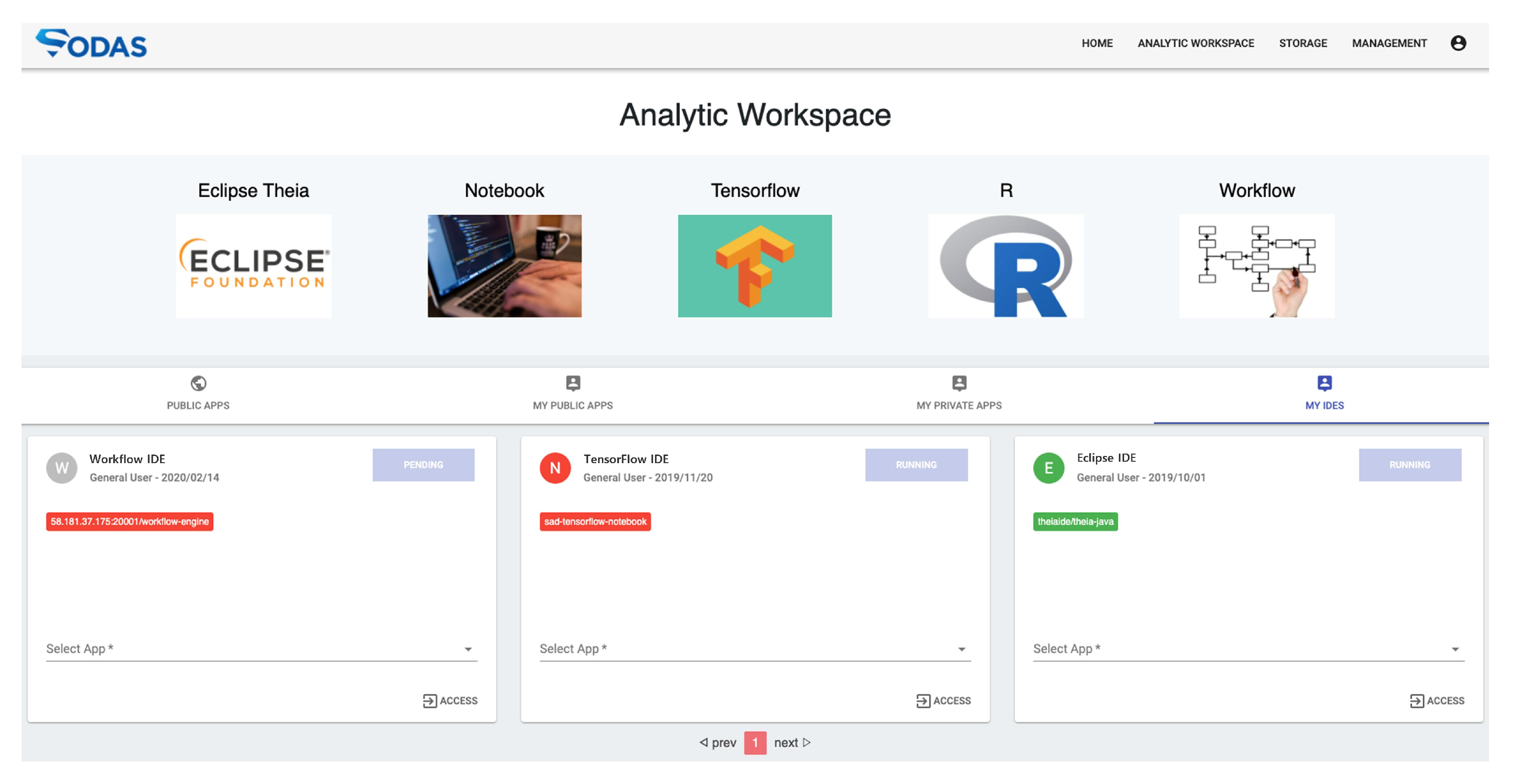
4.5. ADE Provisioning
5. System Implementation and Substantiation
5.1. Results of SODAS Platform Development
- Dataset collection efficiency: We measure the number of datasets finally gathered by liking SODAS with other open data platforms to verify the efficiency of collecting datasets from SODAS. As a result of connecting with 7 Korean and 16 other countries’ data distribution portals through DataMap Publisher, a total of 261,683 datasets are collected. This result means that SODAS can more easily collect open data by interconnecting with the existing CKAN-based platform. In addition, since SODAS directly stores data with an improved harvester, it can provide data reliably even if the original data link is damaged.
- Related dataset detection rate: This detection rate is to evaluate how well SODAS finds datasets similar to those selected by the user through Open Data Reference Model. For evaluation, we prepare correct answer sets for each field and perform experiments to find datasets related to the dataset given as a query. In this experiment, the measured value represents the percentage of the search results including correct answers. According to the experimental results, SODAS shows an average of 74.65% of the related dataset detection rate. SODAS utilizes these results to support users with high-accuracy data recommendation functions without unnecessary search processes.
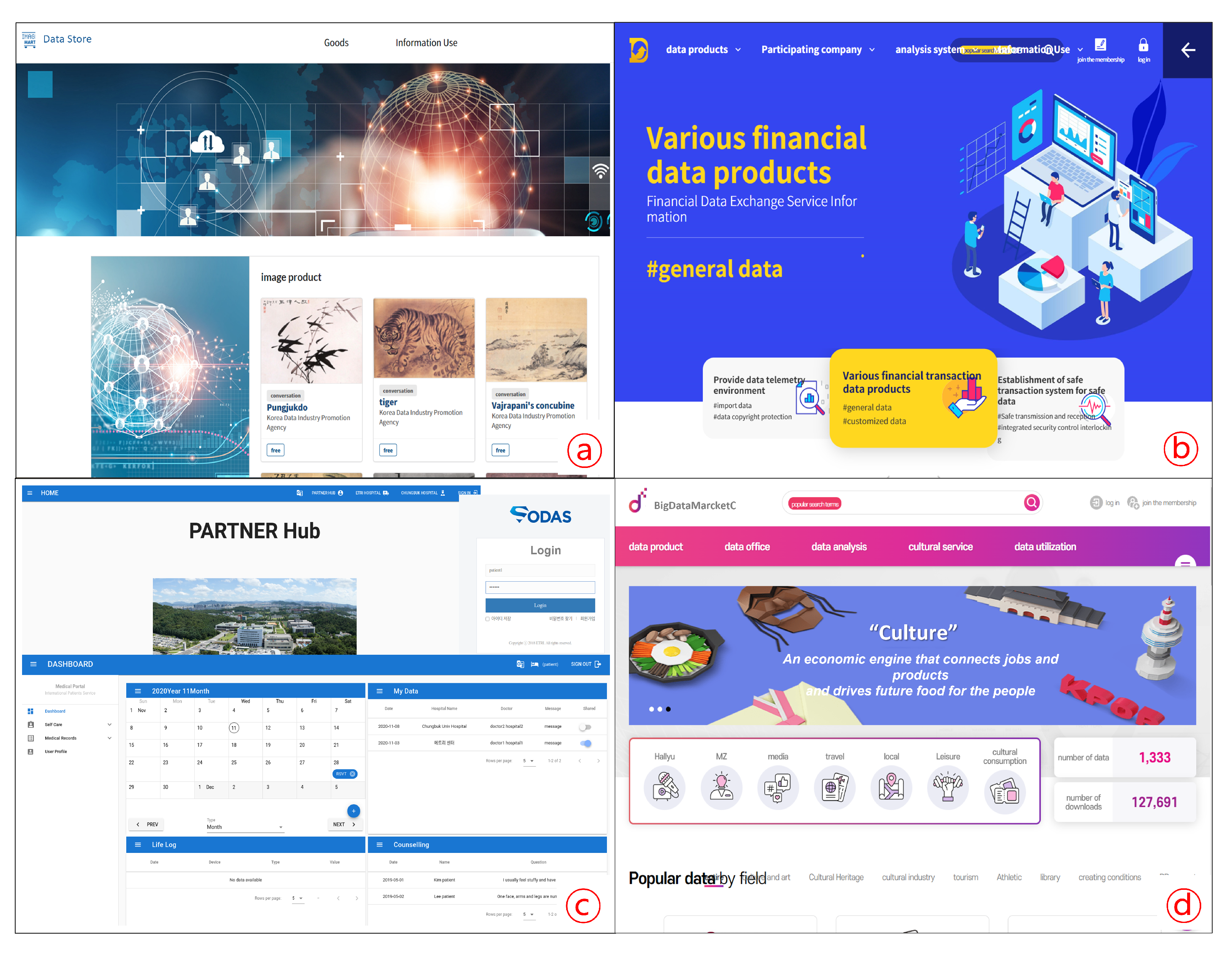
5.2. SODAS Application Sites
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- CKAN Documentation. Available online: http://docs.ckan.org/ (accessed on 26 January 2023).
- Open Government Platform (OGPL). Available online: https://ogpl.github.io/ (accessed on 26 January 2023).
- Socrata. Available online: https://dev.socrata.com/ (accessed on 26 January 2023).
- Albertoni, R.; Browning, D.; Cox, S.; Beltran, A.G.; Perego, A.; Winstanley, P. Data Catalog Vocabulary (DCAT)—Version 2; The World Wide Web Consortium (W3C): Cambridge, MA, USA, 2020. [Google Scholar]
- PARTNER Project. Available online: https://itea3.org/project/partner.html (accessed on 26 January 2023).
- Open Knowledge Foundation (OKFN), Why Open Data. Available online: https://okfn.org/opendata/why-open-data/ (accessed on 26 January 2023).
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In Proceedings of the International Semantic Web Conference, Busan, Korea, 11–15 November 2007; pp. 722–735. [Google Scholar]
- Li, Y.; Jiang, Y.; Goldstein, J.C.; Mcgibbney, L.J.; Yang, C. A Query Understanding Framework for Earth Data Discovery. Appl. Sci. 2020, 10, 1127. [Google Scholar] [CrossRef]
- Yang, P.; Evans, J.; Cole, M.; Marley, S.; Alameh, N.; Bambacus, M. The Emerging Concepts and Appli-cations of the Spatial Web Portal. Photogramm. Eng. Remote Sens. 2007, 73, 691–698. [Google Scholar] [CrossRef]
- Vítor, G.; Rito, P.; Sargento, S. Smart City Data Platform for Real-time Processing and Data Sharing. In Proceedings of the IEEE Symp. on Computers and Communications, Athens, Greece, 5–8 September 2021; pp. 1–7. [Google Scholar]
- Li, C.; Zhang, J.; Kale, A.; Que, X.; Salati, S.; Ma, X. Toward Trust-Based Recommender Systems for Open Data: A Literature Review. Information 2022, 13, 334. [Google Scholar] [CrossRef]
- Moreno, A.; Molano-Pulido, J.; Gomez-Morantes, J.E.; Gonzalez, R.A. ADACOP: A Big Data Platform for Open Government Data. In Proceedings of the International Conference on Theory and Practice of Electronic Governance, Guimarães, Portugal, 4–7 October 2022; pp. 369–375. [Google Scholar]
- Janssen, M.; Charalabidis, Y.; Zuiderwijk, A. Benefits, Adoption Barriers and Myths of Open Data and Open Government. Inf. Syst. Manag. 2012, 29, 258–268. [Google Scholar] [CrossRef]
- Winn, J. Open Data and the Academy: An Evaluation of CKAN for Research Data Management. In Proceedings of the International Association for Social Science Information Services & Technology, Cologne, Germany, 28–31 May 2013; pp. 28–31. [Google Scholar]
- Junar. Available online: https://www.junar.com/ (accessed on 26 January 2023).
- Momjian, B. PostgreSQL: Introduction and Concepts; Addison-Wesley: New York, NY, USA, 2001; Volume 192. [Google Scholar]
- Copeland, R. Essential SQLAlchemy; O’Reilly Media: Cambridge, MA, USA, 2008. [Google Scholar]
- O’Neil, E. Object/Relational Mapping 2008: Hibernate and the Entity Data Model (EDM). In Proceedings of the International Conference on Management of Data, ACM SIGMOD, Vancouver, BC, Canada, 10–12 June 2008; pp. 1351–1356. [Google Scholar]
- Smiley, D.; Pugh, E.; Parisa, K.; Mitchell, M. Apache Solr Enterprise Search Server; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Guha, R.V.; Brickley, D.; Macbeth, S. Schema.org: Evolution of Structured Data on The Web. Commun. ACM 2016, 59, 44–51. [Google Scholar] [CrossRef]
- Brickley, D.; Burgess, M.; Noy, N. Google Dataset Search: Building a Search Engine for Datasets in An Open Web Ecosystem. In Proceedings of the International World Wide Web Conference Committee, San Francisco, CA, USA, 13–17 May 2019; pp. 1365–1375. [Google Scholar]
- Zhu, Y. Introducing Google Chart Tools and Google Maps API in Data Visualization Courses. IEEE Comput. Graph. Appl. 2012, 32, 6–9. [Google Scholar] [PubMed]
- D3.js. Available online: https://d3js.org/ (accessed on 26 January 2023).
- Chart Builder. Available online: https://github.com/plotly/react-chart-editor (accessed on 26 January 2023).
- Keycloak. Available online: https://www.keycloak.org/ (accessed on 26 January 2023).
- Profiles Vocabulary. Available online: https://www.w3.org/TR/dx-prof/ (accessed on 26 January 2023).
- Kim, D.; Gil, M.-S.; Nguyen, M.C.; Won, H.; Moon, Y.-S. Comprehensive Knowledge Archive Network Harvester Improvement for Efficient Open-Data Collection and Management. ETRI J. 2021, 43, 835–855. [Google Scholar] [CrossRef]
- Eclipse Theia. Available online: https://theia-ide.org/ (accessed on 26 January 2023).
- Jupyter Notebook. Available online: https://jupyter.org/ (accessed on 26 January 2023).
- Swagger. Available online: https://swagger.io/ (accessed on 26 January 2023).
- Sefraoui, O.; Aissaoui, M.; Eleuldj, M. OpenStack: Toward an Open-Source Solution for Cloud Computing. Int. J. Comput. Appl. 2012, 55, 38–42. [Google Scholar] [CrossRef]
- Burns, B.; Grant, B.; Oppenheimer, D.; Brewer, E.; Wilkes, J. Borg, Omega, and Kubernetes. Queue 2016, 14, 70–93. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SODAS Component | Related Problems | Solutions (Strategies) |
|---|---|---|
| Open Data Portal | Problems 1, 2, 4, 5 | CKAN expansion |
| Open Data Reference Model | Problems 3, 4 | DCATv2 support, extendable DataMap |
| DataMap Publisher | Problems 3, 4, 5 | CKAN expansion, extendable DataMap |
| ADE Provisioning | Problems 1, 5 | CKAN expansion |
| Name (Release) | Pros. | Cons. |
|---|---|---|
| CKAN (2007) | Open-source; Frequently used | Lack of operational/functional stability; Non-standard |
| OGPL (2013) | Open-source; Suitable for government | Infrequently used (only used in India); Non-standard |
| Socrata (2007), Junar (2010) | Supports various functions compared to open-source; Providing customized functions | High installation cost (commercial); Low scalability; Non-standard |
| Block Name | Main Actions |
|---|---|
| Data Distribution | Data registration/modification/deletion/purchase function, data landing page management |
| Authentication/Authorization | Single Sign On (SSO) management, organization/user role management, authorization management according to data purchase |
| Quality/Standards Mgmt. | Classification system/category/metadata management, quality verification rules, quality measurement & history management |
| Data Harvesting | Open data harvesting, real-time data (IoT) harvesting |
| Extendable DataMap | DCATv2-based catalog sharing & distribution, metadata conversion tool |
| Cloud Development Env. | Analysis/development environment (Theia, Notebook, TensorFlow, etc.), sandbox resource management and provisioning |
| Data Storage Mgmt. | HDFS/HBase/MongoDB/Jena/RDBMS integrated management, capacity control by organization & user |
| Resource Mgmt./Monitoring | Computing resource allocation and monitoring by tenants(organization and uses) |
| Service Provision | Algorithm & service distribution, currently for dataset search |
| Component | Open-Source (License) | Purpose of Usage |
|---|---|---|
| Open Data Portal | Keycloak (Apache) | Integrated user authentication |
| Loopback (MIT), Play (Apache) | System REST API provisioning | |
| Hadoop (Apache), Hbase (Apache), Jena (Apache), MongoDB (AGPL), PostgreSQL (PostgreSQL) | Data storage by data size/purpose | |
| Spark (Apache) | Data analysis | |
| Grafana (Apache), InfluxDB (MIT) | Platform monitoring UI and log storage | |
| Open Data Reference Model | Express (MIT), Axios (MIT) | System API interworking and provision |
| Ejs (Apache), Multer (MIT) | Web UI and file upload development | |
| DataMap Publisher | Kafka (Apache), Jena (Apache) | Data stream queuing, RDF storage |
| Spring (Apache) | System API development | |
| ADE Provisioning | Express (MIT) | System REST API provisioning |
| Notebook (Jupyter), Eclipse Theia (Apache) | Cloud-based user analysis/development | |
| Openstack (Apache), Kubernetes (Apache), Docker (Apache) | Virtual machine/execution environment management |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Won, H.; Han, J.; Gil, M.-S.; Moon, Y.-S. SODAS: Smart Open Data as a Service for Improving Interconnectivity and Data Usability. Electronics 2023, 12, 1237. https://doi.org/10.3390/electronics12051237
Won H, Han J, Gil M-S, Moon Y-S. SODAS: Smart Open Data as a Service for Improving Interconnectivity and Data Usability. Electronics. 2023; 12(5):1237. https://doi.org/10.3390/electronics12051237
Chicago/Turabian StyleWon, Heesun, Jiwoo Han, Myeong-Seon Gil, and Yang-Sae Moon. 2023. "SODAS: Smart Open Data as a Service for Improving Interconnectivity and Data Usability" Electronics 12, no. 5: 1237. https://doi.org/10.3390/electronics12051237
APA StyleWon, H., Han, J., Gil, M.-S., & Moon, Y.-S. (2023). SODAS: Smart Open Data as a Service for Improving Interconnectivity and Data Usability. Electronics, 12(5), 1237. https://doi.org/10.3390/electronics12051237