

Research on Spectrum Prediction Technology Based on B-LTF


Abstract
1. Introduction
- We study the problem of spectrum availability prediction and discuss the time spectrum occupancy characteristics together.
- We proposed the B-LTF algorithm, combined the BP network with LSTM, built a new network structure and realized the spectrum prediction from the neural network. We studied the influence of the sequence length of spectrum data and the model prediction rate in detail and effectively improved the accuracy of spectrum prediction.
- We show that the analysis of simulation prediction values obtained by simulating the current channel state shows that a long short-term memory network and its improved model can effectively process the time series, the GRU model has a simpler structure and the training time of the GRU model will be significantly reduced compared with the LSTM network, and the improved B-LTF algorithm compared with the LSTM, BP and GRU has better predictive performance. In addition, when the sequence length of spectrum data increases, the model prediction rate tends to be saturated or reduced.
2. System Model
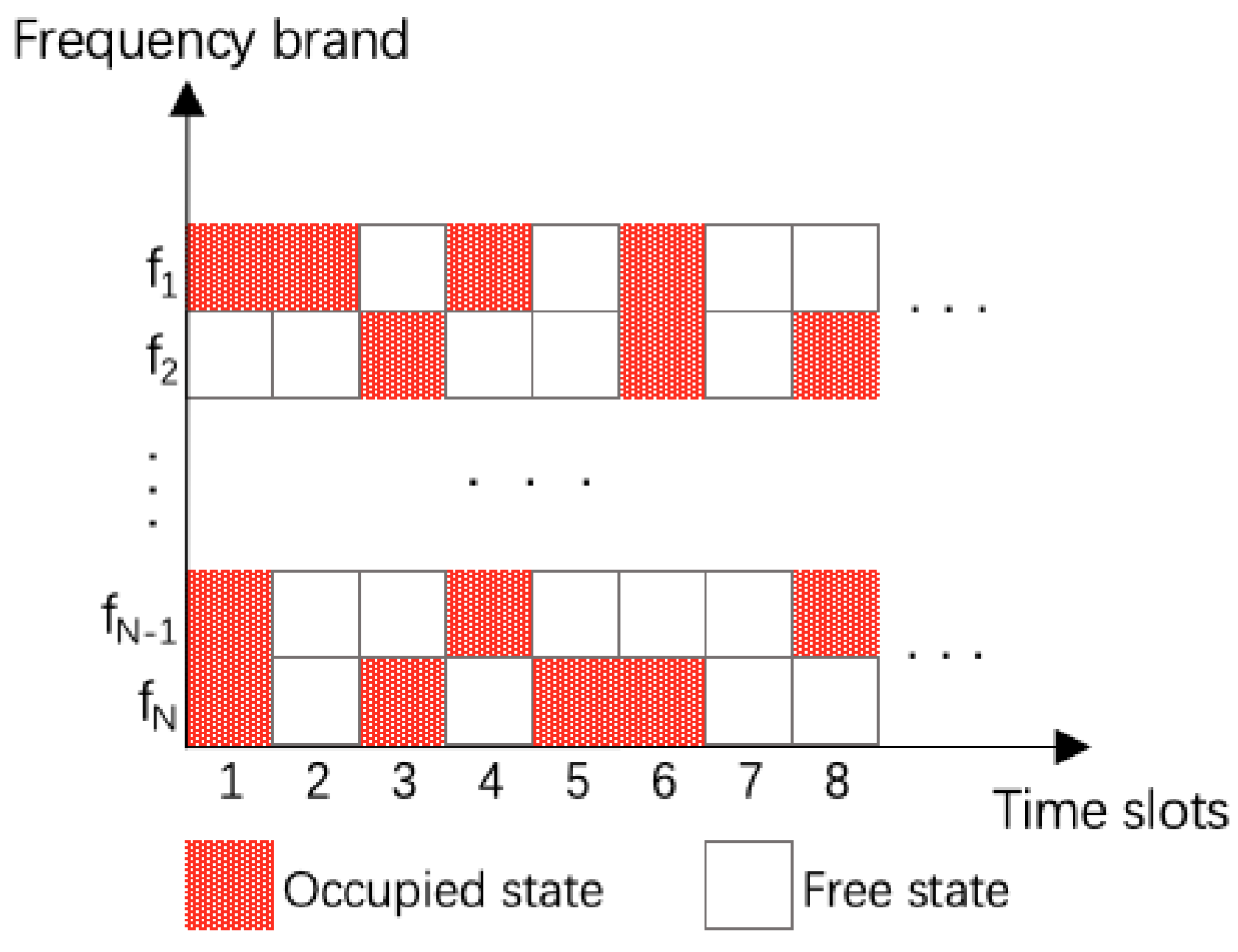
2.1. Spectrum Prediction Model
2.2. Deep Learning Model
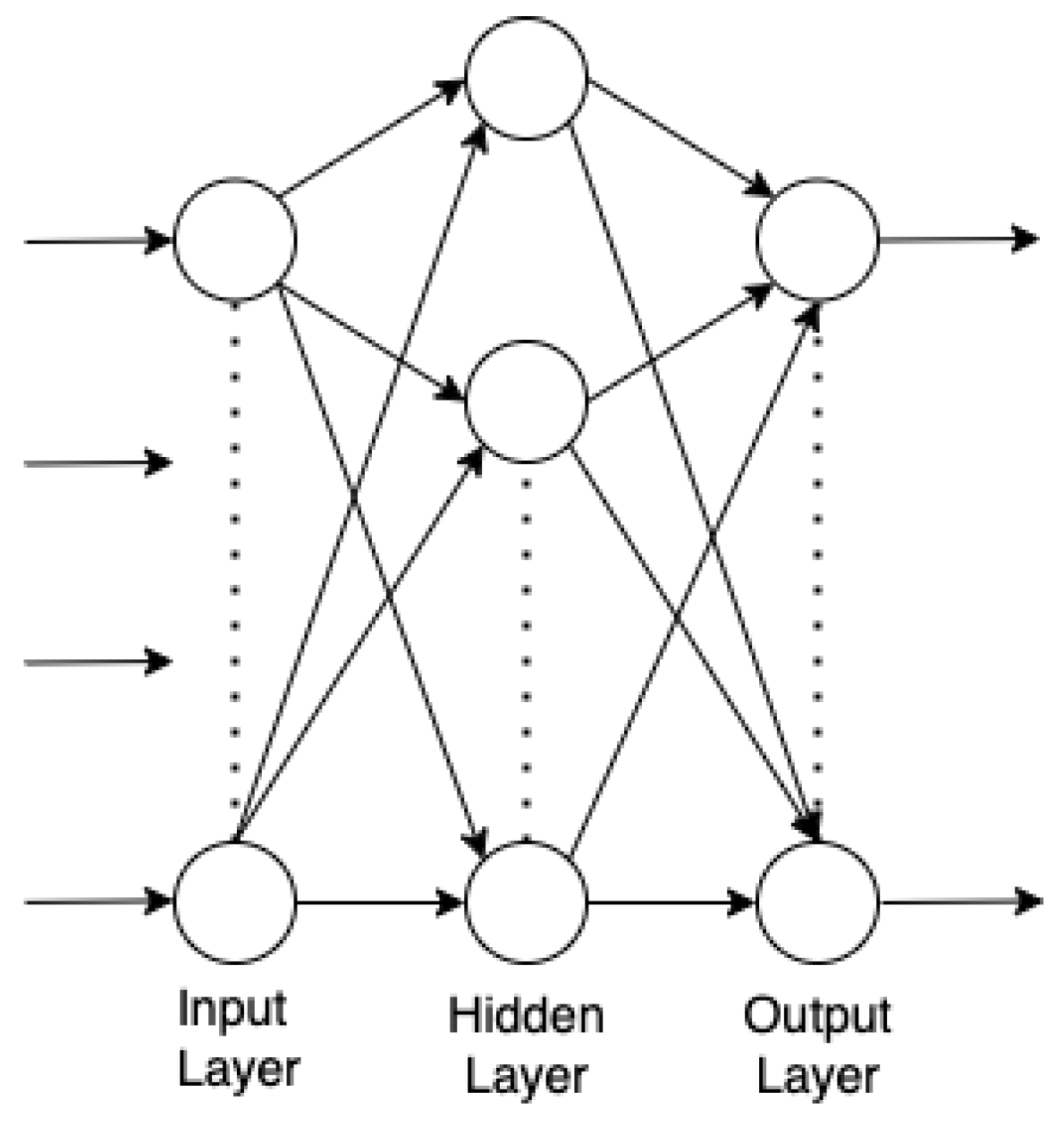
2.2.1. Conventional BP Network
| Algorithm 1. BP-neural network algorithm | |
| 1. | Get the training data set XTrain and test data set XTest. |
| 2. | Set the structure parameters of BP neural network model. |
| 3. | Input XTrain, by passing forward: from input layer to hidden layer to output layer, get X_Train. |
| 4. | compare the XTrain with the YTrain to obtain the prediction error. |
| 5. | When the prediction error e > eth is satisfied and the number of iterations Nit < n, the error backward propagation process is performed to update the weights and then go back to 1, otherwise to 6. |
| 6. | When e < eth or Nit = n, the training is finished and obtain the trained network model. |
| 7. | Put the XTest into the trained BP neural network to obtain YTest. |
2.2.2. Emerging LSTM Network
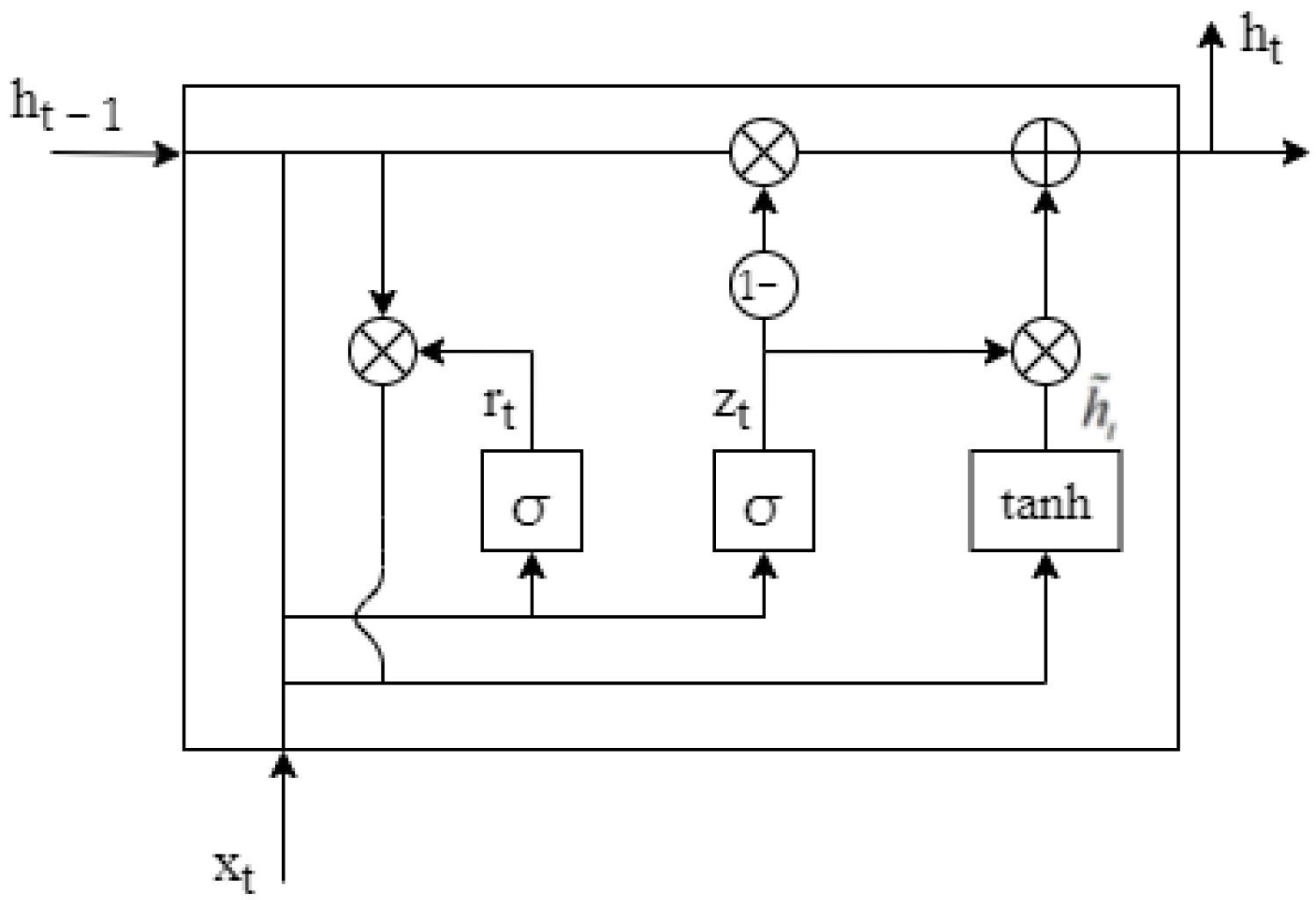
2.2.3. GRU Network Model
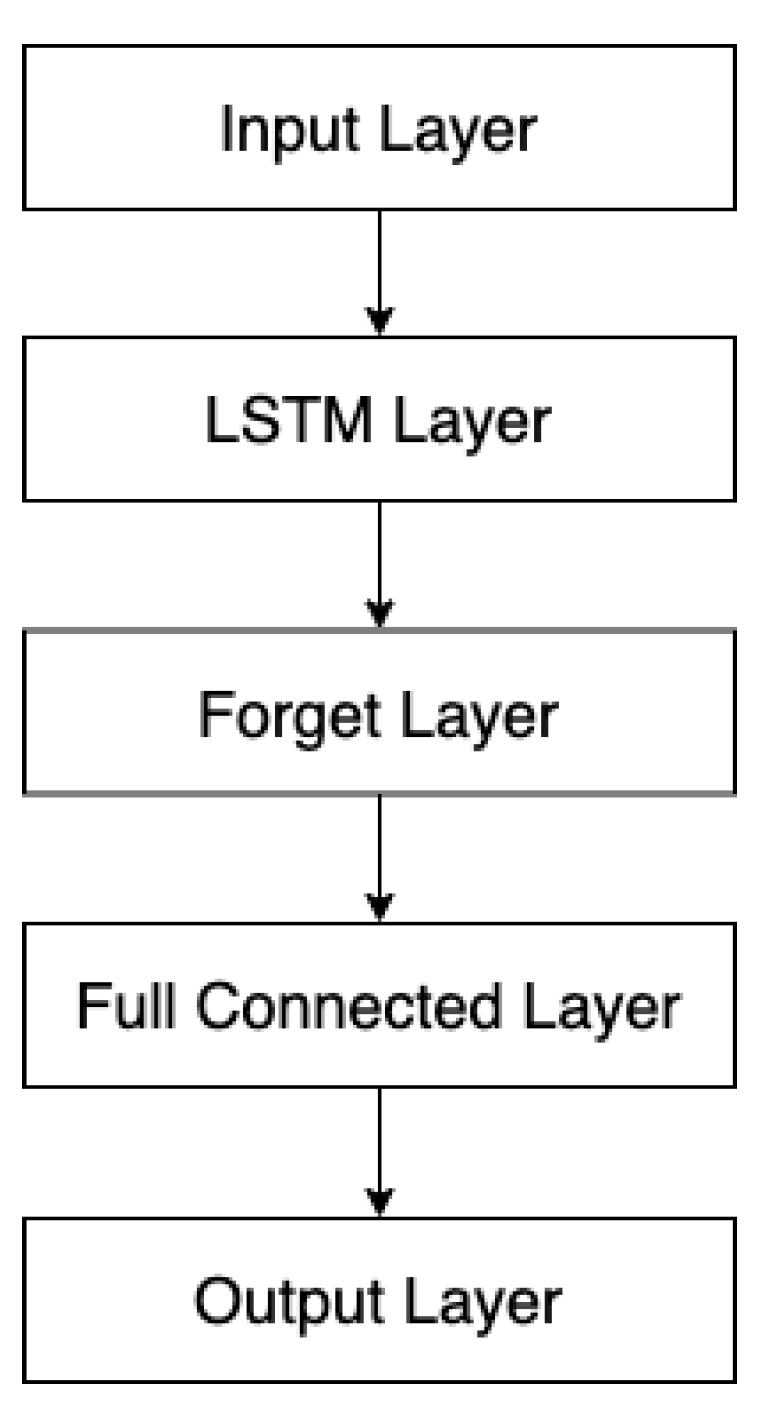
3. B-LTF Model
3.1. Related Theories and Formulas
3.2. Model Introduction
| Algorithm 2. B-LTF algorithm |
| Input: Historical spectrum data {X1, X2, …, Xt}, Time dimension T; |
| Output: The spectrum prediction results; |
| //Construct the dataset; |
| 1. The spectrum data is preprocessed according to the threshold value, so as to turn the data into a sequence composed of [0,1] “Sp” represents the frequency band state |
| 2. ←∅ |
| 3.Put the sample Sp into |
| 4. A segment is randomly selected in and divided into Train and Test according to the ratio of training set to test set |
| //Train the model; |
| 5. Initialize all learnable parameters W, b in BP-LSTM |
| 6. Repeat |
| 7. Randomly select a batch of instances from Train |
| 8. Update W, b in the network |
| 9. Until the training epochs are met |
| //Test the model; |
| 10.Put Test into the trained model |
| 11. Output the prediction results |
4. Experiment Evaluation
4.1. Channel State Prediction
4.1.1. Data Preprocessing
4.1.2. Calculate the Channel Occupancy
4.1.3. Evaluation Criterion
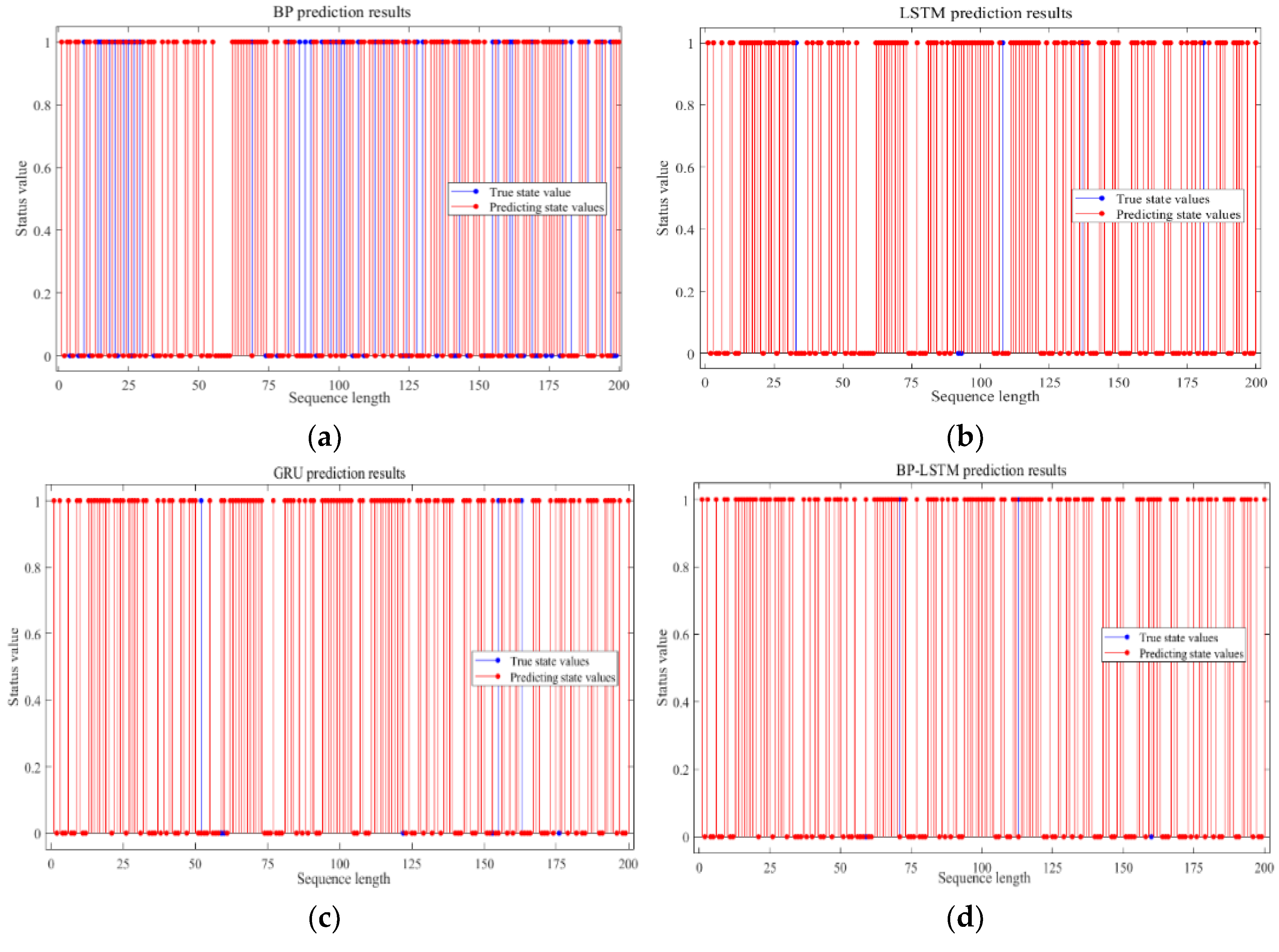
4.1.4. Comparison of Simulation Results
4.2. Prediction of the Trend of the Spectrum Signal
4.2.1. Data Processing and Parameter Setting
4.2.2. Experimental Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kolodzy, P. Spectrum Policy Task Force Report; FCC ET Docket No. 02-155; Federal Communications Commission: Washington, DC, USA, 2002; Volume 40, pp. 147–158. [Google Scholar]
- Kiftaro, F.; El-Tarhuni, M.; Assaleh, K. UHF Spectrum Occupancy Measurements in Sharjah—UAE. In Proceedings of the 2017 9th IEEE-GCC Conference and Exhibition (GCCCE), Manama, Bahrain, 8–11 May 2017. [Google Scholar]
- Yu, X.; Kong, M.; Li, X. Spectrum occupancy in the 87.5–108 MHz band: Measurement and analysis. In Proceedings of the 2017 IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 25–26 March 2017. [Google Scholar]
- Ramirez, D.; Cardenas-Juarez, M.; Pineda-Rico, U. Spectrum Occupancy Measurements in the Sub-6 GHz Band for Smart Spectrum Applications. In Proceedings of the 2018 IEEE 10th Latin-American Conference on Communications (LATINCOM), Guadalajara, Mexico, 14–16 November 2018. [Google Scholar]
- Engiz, B.K.; Rajab, Y.A. Investigation of Spectrum Occupancy in GSM Band in Samsun, Turkey. In Proceedings of the 2019 6th International Conference on Electrical and Electronics Engineering (ICEEE), Istanbul, Turkey, 16–17 April 2019. [Google Scholar]
- Zulfiqar, M.D.; Ismail, K.; Hassan, N.U. Radio Spectrum Occupancy Measurement from 30MHz-1030MHz in Pakistan. In Proceedings of the 2019 UK/ China Emerging Technologies (UCET), Glasgow, UK, 21–22 August 2019. [Google Scholar]
- Tandra, R.; Sahai, A. Fundamental limits on detection in low SNR under noise uncertainty. In Proceedings of the 2005 International Conference on Wireless Networks, Communications and Mobile Computing, Maui, HI, USA, 13–16 June 2005. [Google Scholar]
- Mitola, J.; Maguire, G.Q. Cognitive radio: Making software radios more personal. IEEE Pers. Commun. 1999, 6, 13–18. [Google Scholar] [CrossRef]
- Woods, T.; Furman, S. All-domain Spectrum Command and Control via Hierarchical Dynamic Spectrum Sharing with Implemented Dynamic Spectrum Access Toolchain. In Proceedings of the MILCOM 2021–2021 IEEE Military Communications Conference (MILCOM), San Diego, CA, USA, 29 November–2 December 2021. [Google Scholar]
- Madhavan, A.; Govindarajan, Y. Wideband Spectrum Sensing in Dynamic Spectrum Access Systems Using Bayesian Learning. J. Phys. Conf. Ser. 2021, 1964, 62067–62075. [Google Scholar] [CrossRef]
- Toma, O.H.; Lopez-Benitez, M. Cooperative Spectrum Sensing: A New Approach for Minimum Interference and Maximum Utilisation. In Proceedings of the 2021 IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, QC, Canada, 14–23 June 2021. [Google Scholar]
- Solanki, S.; Dehalwar, V. Spectrum Sensing in Cognitive Radio Using CNN-RNN and Transfer Learning. IEEE Access 2022, 10, 113482–113492. [Google Scholar] [CrossRef]
- Huang, P.; Liu, C.J. Wireless Spectrum Occupancy Prediction Based on Partial Periodic Pattern Mining. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1925–1934. [Google Scholar] [CrossRef]
- Saad, A.; Staehle, B.; Knorr, R. Spectrum prediction using hidden Markov models for industrial cognitive radio. In Proceedings of the 2016 IEEE 12th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), New York, NY, USA, 17–19 October 2016. [Google Scholar]
- Wu, J.W.; Li, Y. HMM Cooperative Spectrum Prediction Algorithm Based on Density Clustering. J. Comput. Appl. 2018, 45, 129–134. [Google Scholar] [CrossRef]
- Liu, X.N.; Shi, R. Spectrum Occupancy Prediction Method Based on Segmented Markov Model. Radio Eng. 2020, 50, 690–695. [Google Scholar]
- Wang, D.; Cao, P. High frequency cognitive frequency selection mechanism based on hidden Markov model. J. Comput. Appl. 2016, 36, 1179–1182, 1187. [Google Scholar]
- Lin, G.; Cheng, Y.P. Performance Analysis of Three-State HMM in HF Channel Estimation. Commun. Technol. 2016, 49, 286–292. [Google Scholar]
- Chauhan, P.; Deka, S.K. Cooperative Spectrum Prediction-Driven Sensing for Energy Constrained Cognitive Radio Networks. IEEE Access 2021, 10, 26107–26118. [Google Scholar] [CrossRef]
- Zhao, J.L.; Wang, M.W.; Yuan, J.S. Based on neural network spectrum prediction of cognitive radio. In Proceedings of the 2011 International Conference on Electronics, Communications and Control (ICECC), Ningbo, China, 9–11 September 2011. [Google Scholar]
- He, Y.; Meng, Z. A dynamic model of evaluating differential automatic method for solving plane problems based on BP neural network algorithm. Phys. A Stat. Mech. Its Appl. 2020, 556, 1–11. [Google Scholar] [CrossRef]
- Tang, Z.; Li, S. Deep recurrent neural network for multiple time slot frequency spectrum predictions of cognitive radio. KSII Trans. Internet Inf. Syst. 2017, 11, 3029–3045. [Google Scholar]
- Yu, L.; Chen, J.; Ding, G. Spectrum prediction via long short-term memory. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017. [Google Scholar]
- Yu, L.; Chen, J. Spectrum Prediction Based on Taguchi Method in Deep Learning With Long Short-Term Memory. IEEE Access 2018, 6, 45923–45933. [Google Scholar] [CrossRef]
- Chen, A.M.; Zhang, C.Y. UAV cognitive radio spectrum prediction based on long short-term memory network. Foreign Electron. Meas. Technol. 2021, 40, 37–43. [Google Scholar]
- Shawel, B.S.; Woldegebreal, D.H.; Pollin, S. Convolutional LSTM-based Long-Term Spectrum Prediction for Dynamic Spectrum Access. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019. [Google Scholar]
- Li, X.; Liu, Z.C. Deep Learning for Spectrum Prediction From Spatial-Temporal-Spectral Data. IEEE Commun. Lett. 2021, 25, 1216–1220. [Google Scholar] [CrossRef]
- Yang, C.; Peng, T.; Zuo, P. A Spectrum Prediction Method for Bursty Frequency Bands. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Nanjing, China, 29 March 2021. [Google Scholar]
- Gao, Y.L.; Zhao, C.Y.; Fu, N. Joint multi-channel multi-step spectrum prediction algorithm. In Proceedings of the 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Norman, OK, USA, 27–30 September 2021. [Google Scholar]
- Huang, Q.Y. Research On Cognitive Radio Spectrum Prediction Based On LSTM Neural Network. Master’s Thesis, Harbin Institute of Technology, Harbin, China, June 2020. [Google Scholar]
- Radhakrishnan, N.; Kandeepan, S. Performance Analysis of Long Short-Term Memory-Based Markovian Spectrum Prediction. IEEE Access 2021, 9, 149582–149595. [Google Scholar] [CrossRef]
- Aygul, M.A.; Nazzal, M. Efficient Spectrum Occupancy Prediction Exploiting Multidimensional Correlations through Composite 2D-LSTM Models. Sensors 2021, 21, 135. [Google Scholar] [CrossRef] [PubMed]
- Radhakrishnan, N.; Kandeepan, S. An Improved Initialization Method for Fast Learning in Long Short-Term Memory-Based Markovian Spectrum Prediction. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 729–738. [Google Scholar] [CrossRef]
- Radhakrishnan, N.; Kandeepan, S.; Yu, X.H. Soft Fusion based Cooperative Spectrum Prediction using LSTM. In Proceedings of the 15th International Conference on Signal Processing and Communication Systems (ICSPCS), Sydney, Australia, 13–15 December 2021. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Pezeshki, M. Sequence Modeling using Gated Recurrent Neural Networks. Comput. Sci. 2015, 9, 1–7. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Slot | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Channel | ||||||||||
| 1 | −97.799 | −96.879 | −98.058 | −101.042 | −100.307 | −100.696 | −100.751 | −101.346 | −100.867 | |
| 2 | −101.126 | −100.244 | −100.150 | −101.270 | −103.100 | −102.444 | −102.598 | −102.805 | −102.943 | |
| 3 | −99.644 | −100.088 | −99.616 | −100.602 | −100.106 | −100.632 | −101.950 | −101.225 | −100.784 | |
| 4 | −99.763 | −97.423 | −99.049 | −98.909 | −97.472 | −98.264 | −100.034 | −97.922 | −99.077 | |
| 5 | −99.010 | −96.495 | −99.228 | −99.385 | −99.082 | −98.963 | −100.305 | −98.338 | −98.964 | |
| 6 | −96.176 | −97.853 | −97.399 | −99.4540 | −99.284 | −98.286 | −97.975 | −99.013 | −100.780 | |
| Slot | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Channel | ||||||||||
| 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 3 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 4 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | |
| 5 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | |
| 6 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | |
| Occupancy | 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Frequency Band | |||||||||||
| Uplink band of GSM900 | 0.44 | 0.456 | 0.456 | 0.488 | 0.504 | 0.512 | 0.512 | 0.528 | 0.544 | 1 | |
| Downlink band of GSM900 | 0.696 | 0.848 | 0.864 | 0.864 | 0.872 | 0.88 | 0.888 | 0.888 | 0.888 | 1 | |
| Evaluation Index | RMSE | MAE | |
|---|---|---|---|
| Model | |||
| BP | 3.927 | 1.6417 | |
| LSTM | 3.2344 | 2.1965 | |
| GRU | 3.3741 | 2.3031 | |
| B-LTF | 1.6746 | 0.6309 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Chen, Q.; Yu, X. Research on Spectrum Prediction Technology Based on B-LTF. Electronics 2023, 12, 247. https://doi.org/10.3390/electronics12010247
Wang X, Chen Q, Yu X. Research on Spectrum Prediction Technology Based on B-LTF. Electronics. 2023; 12(1):247. https://doi.org/10.3390/electronics12010247
Chicago/Turabian StyleWang, Xue, Qian Chen, and Xiaoyang Yu. 2023. "Research on Spectrum Prediction Technology Based on B-LTF" Electronics 12, no. 1: 247. https://doi.org/10.3390/electronics12010247
APA StyleWang, X., Chen, Q., & Yu, X. (2023). Research on Spectrum Prediction Technology Based on B-LTF. Electronics, 12(1), 247. https://doi.org/10.3390/electronics12010247