




Hyperspectral Image Classification with Deep CNN Using an Enhanced Elephant Herding Optimization for Updating Hyper-Parameters

 ,
,  ,
,  and
and 
Abstract
1. Introduction
- To provide efficient accuracy for hyperspectral images, an improved and enhanced EHO method with an AdaBound optimizer updating a hyper-parameter algorithm was developed. As matriarch, the fittest elephant in the clan with the most recent position is chosen. Fixing the clan operator in EEHO improved the evaluation by enhancing its population randomly and removing inappropriate convergence towards the source. In EEHO–AdaBound, the algorithm’s global convergence performance is improved. It has a better convergence speed and a higher convergence accuracy rate than traditional optimization techniques. It can also determine the best CNN hyper-parameters.
- In this study, the EEHO–AdaBound was designed to optimize the CNN’s initial threshold values and weights. The results of the experiments reveal that the proposed method achieves the best accuracy for classification issues while also overcoming the drawbacks of CNN, which are readily trapped in local minimum values and have low stability. In addition, when compared to other CNN approaches, CNN–EEHO–AdaBound classification is greatly enhanced.
- The proposed enhanced elephant herding optimization with the AdaBound optimizer on the CNN classifier verifies and validates HIS datasets, and shows that they are superior to the optimization algorithms.
2. Related Work EHO
2.1. Basics of EHO
- (1)
- The elephant clan population is confined to a specific number of elephants in each clan.
- (2)
- From each generation, a predetermined number of male elephants from the chief group will leave their associated family and live alone in a remote location.
- (3)
- Each clan’s elephants are governed by a matriarch.
2.1.1. Clan-Updating Operator
2.1.2. Separating Operator
| Algorithm 1: Elephant herding optimization algorithm |
| Start |
| Initialize. Set the number of iterations E = 1; set P for population initialization; choose Gen Max for maximum generation and elephant count as. |
| While searching, do |
| Sorting the individual elephant’s actual fitness is used to classify the population. |
| For all clans, generate count |
| For elephant j in the family clan |
| Compute and update by Equation (1). |
| Sort the population according to the fitness of individuals. |
| For all clans’ ci do |
| For elephant in the clan do |
| Generate and update by Equation (1). |
| If then |
| Produce and update by Equation (2). |
| End if |
| End for |
| End for |
| For all present clans’ do |
| Interchange the worst individual by Equation (4). |
| End for |
| Estimate each elephant individual in the clan for new position, respectively. |
| Incrementing the generation count K = K + 1. |
| End while |
| Output: the optimal best elephant position |
| End. |
3. Methodology
3.1. AdaBound Optimizer as Hyper-Parameter Updating Method in Enhancing EHO
- Unreasonable convergence towards the updated operator in the origin has a lower effect on expanding further.
- Initial elephant position allocation is uneven.
AdaBound Optimizer
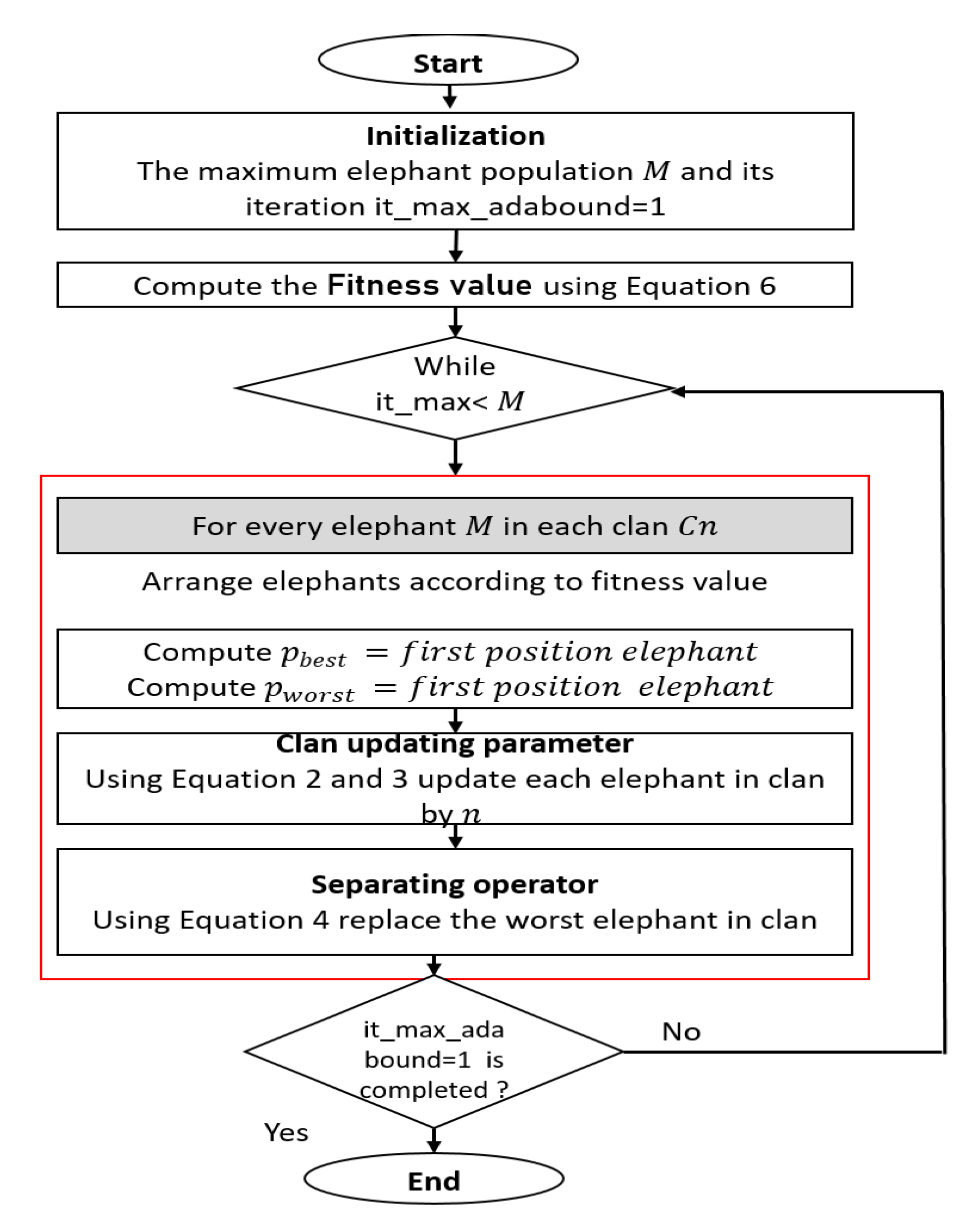
| Algorithm 2: EEHO with AdaBound approach for updating hyper-parameters |
| # it_max denotes the maximum number of iterations for the EHO algorithm |
| # it_max_adabound denotes the maximum number of iterations for the AdaBound method |
| # C_it_adabound denotes the present iteration number of the AdaBound algorithm |
| # C_it_EHO denotes the present iteration number of the EHO algorithm |
| # Start Initializations |
| Initialize the input feature parameters: it_max, it_max_adabound, , and . |
| Set the present position of elephants |
| ForC_it_adabound = 1: it_max_adabound |
| # Develop EEHO |
| Compute the fitness function of each elephant in the clan |
| To obtain the best and worst new elephants’ position, calculate and update clan operator |
| For C_it_EHO = 1: it_max |
| Equation (1) is used to update the new position of each elephant, respectively |
| Using Equation (3), evaluate the centre position of elephants |
| Update the new best value for the elephant’s position using Equation (2) |
| Calculate the worst value using Equation (4) to update the elephant’s position. |
| Repeat and evaluate new fitness function for each elephant |
| The best and worst elephant’s position is recognized |
| End for |
| Update the individual elephant’s positions |
| # End of EHO |
| Compute learning and loss error using Equation (10) |
| Update the new values for hyper-parameters using Equations (6)–(10). |
| End for |
3.2. The EEHO–CNN Approach
4. Experimental Results and Analysis
4.1. Dataset
4.2. Experiments Compared with Existing Approaches
4.3. Experiment Parameter Settings
5. Results Analysis and Discussion
5.1. Accuracy of HSI Classification
5.2. Convergence Analysis of CNN–EEHO–AdaBound Approach
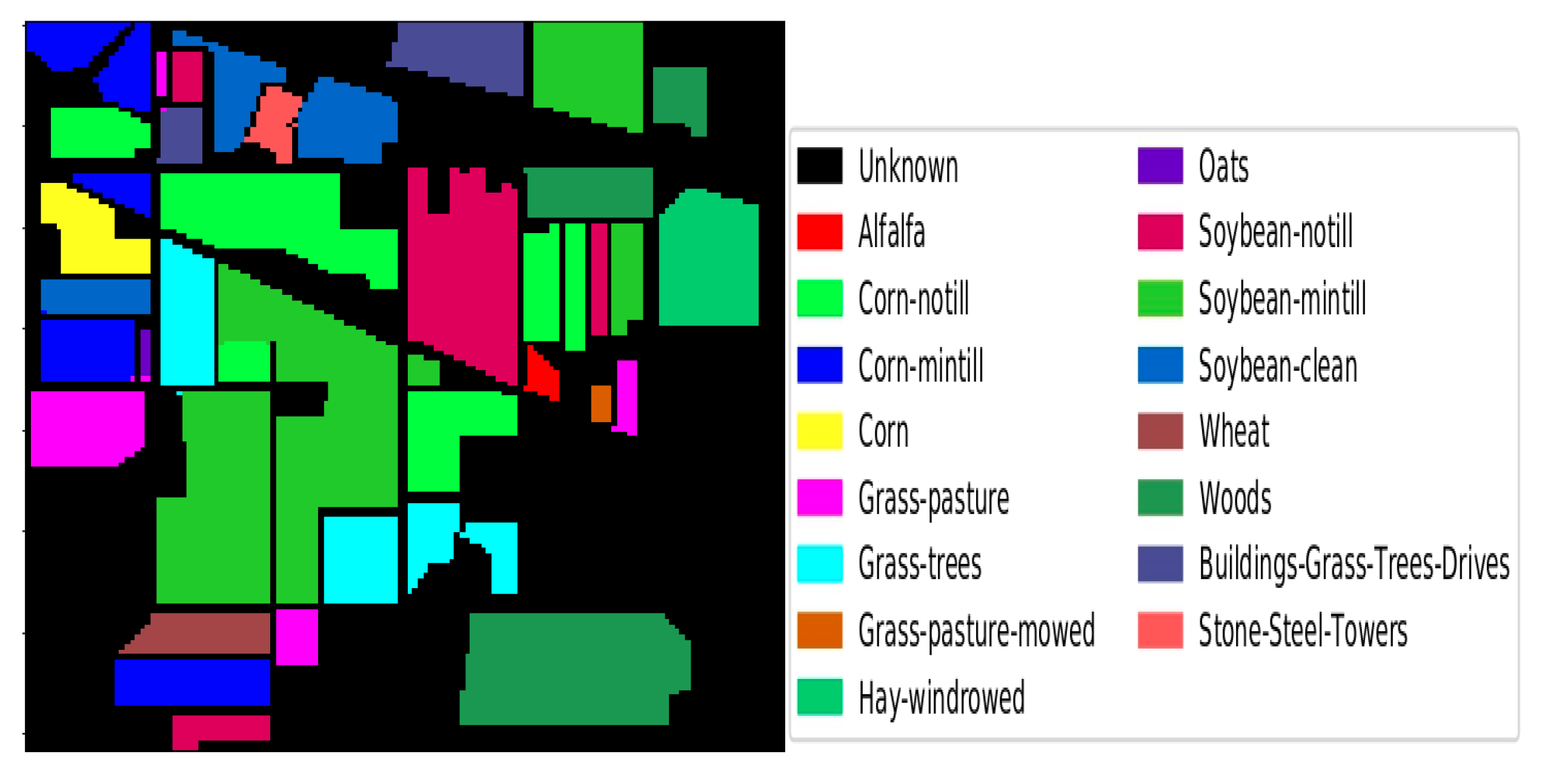
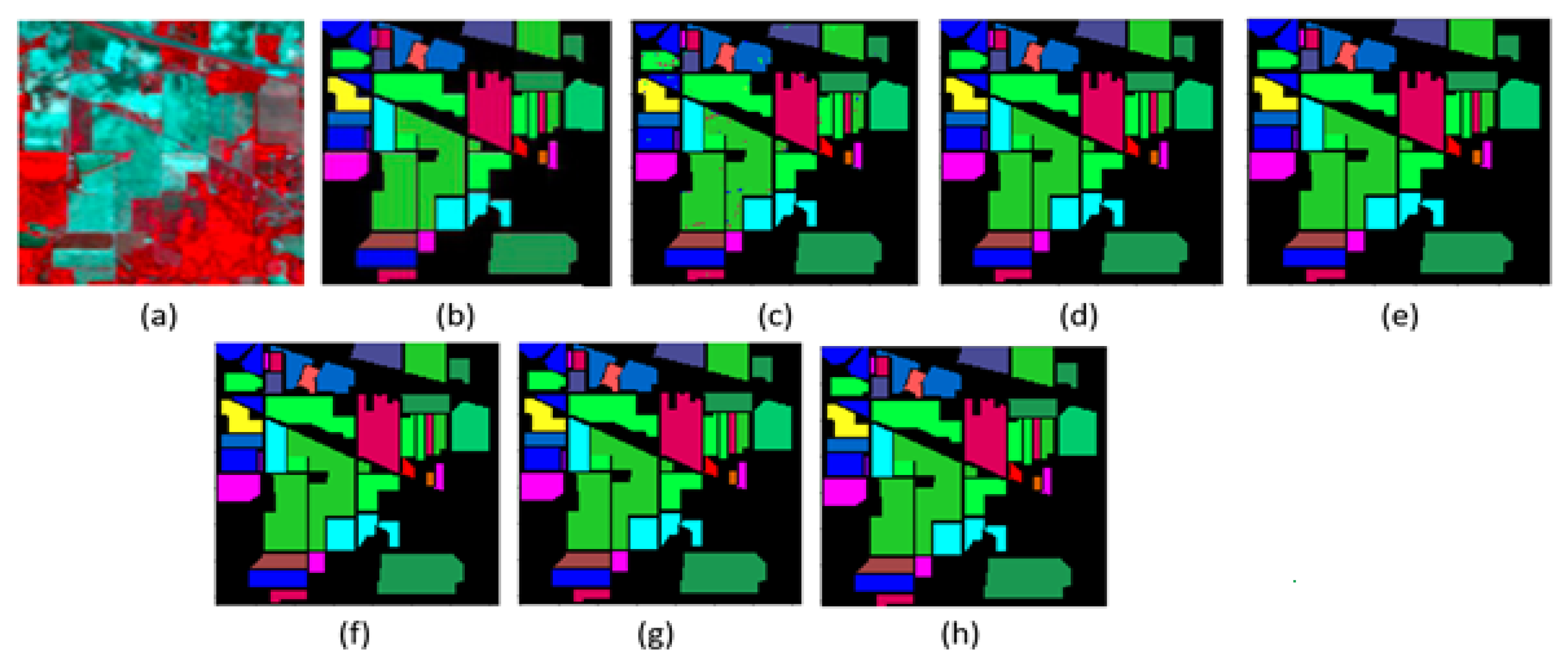
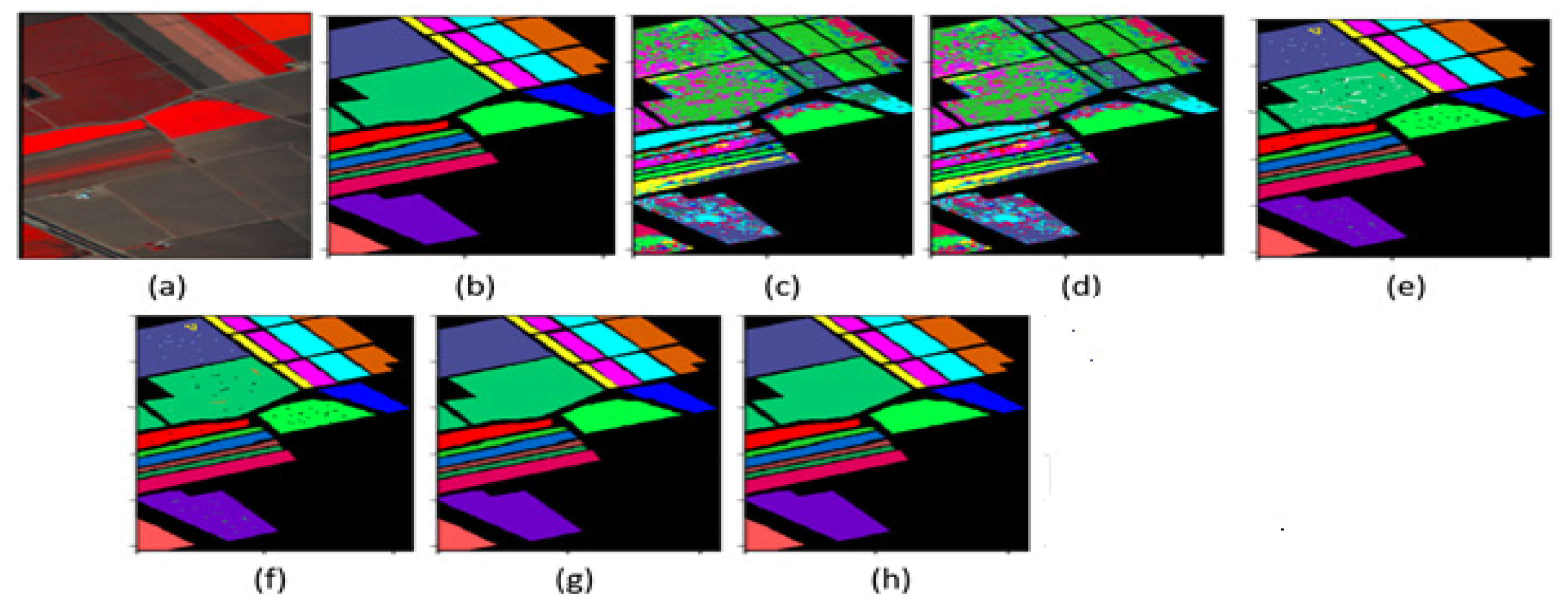
5.3. HSI Classification Maps
5.4. Comparisons of CNN–EEHO–AdaBound Performance with Other Optimization Algorithms
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lee, H.; Kwon, H. Going deeper with contextual CNN for hyperspectral image classification. IEEE Trans. Image Process. 2017, 26, 4843–4855. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; Xu, X. MugNet: Deep learning for hyperspectral image classification using limited samples. ISPRS J. Photogramm. Remote Sens. 2018, 145, 108–119. [Google Scholar] [CrossRef]
- Yi, C.; Zhao, Y.Q.; Chan, J.C.W. Hyperspectral image super-resolution based on spatial and spectral correlation fusion. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4165–4177. [Google Scholar] [CrossRef]
- El-Sharkawy, Y.H.; Elbasuney, S. Hyperspectral imaging: Anew prospective for remote recognition of explosive materials. Remote Sens. Appl. Soc. Environ. 2019, 13, 31–38. [Google Scholar] [CrossRef]
- Junior, F.E.F.; Yen, G.G. Particle swarm optimization of deep neural networks architectures for image classification. Swarm Evol. Comput. 2019, 49, 62–74. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, X.; Wang, G.; Cai, Z. Particle swarm optimization based deep learning architecture search for hyperspectral image classification. In IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium; IEEE: New York, NY, USA, 2020; pp. 509–512. [Google Scholar]
- Sharma, S.; Buddhiraju, K.M. Spatial–spectral ant colony optimization for hyperspectral image classification. Int. J. Remote Sens. 2018, 39, 2702–2717. [Google Scholar] [CrossRef]
- Sawant, S.S.; Prabukumar, M.; Samiappan, S. A modified Cuckoo Search algorithm based optimal band subset selection approach for hyperspectral image classification. J. Spectr. Imaging 2020, 9, A6. [Google Scholar] [CrossRef]
- Zhu, X.; Nan, L.; Pan, Y. Optimization Performance Comparison of Three Different Group Intelligence Algorithms on a SVM for Hyperspectral Imagery Classification. Remote Sens. 2019, 11, 734. [Google Scholar] [CrossRef]
- Wang, G.-G.; Deb, S.; Gao, X.-Z.; Coelho, L.D.S. A New Metaheuristic Optimisation Algorithm Motivated by Elephant Herding Behaviour. Int. J. Bio-Inspired Comput. 2016, 8, 394–409. [Google Scholar] [CrossRef]
- Santara, A.; Mani, K.; Hatwar, P.; Singh, A.; Garg, A.; Padia, K.; Mitra, P. BASS Net: Band-adaptive spectral-spatial feature learning neural network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5293–5301. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Ince, T.; Abdeljaber, O.; Avci, O.; Gabbouj, M. May. 1-d convolutional neural networks for signal processing applications. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: New York, NY, USA, 2019; pp. 8360–8364. [Google Scholar]
- Zhang, M.; Li, W.; Du, Q. Diverse region-based CNN for hyperspectral image classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef] [PubMed]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar] [CrossRef]
- Sellami, A.; Farah, M.; Farah, I.R.; Solaiman, B. Hyperspectral imagery classification based on semi-supervised 3-D deep neural network and adaptive band selection. Expert Syst. Appl. 2019, 129, 246–259. [Google Scholar] [CrossRef]
- He, M.; Li, B.; Chen, H. Multi-scale 3D deep convolutional neural network for hyperspectral image classification. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: New York, NY, USA, 2017; pp. 3904–3908. [Google Scholar]
- Liu, B.; Yu, X.; Zhang, P.; Tan, X.; Yu, A.; Xue, Z. A semi-supervised convolutional neural network for hyperspectral image classification. Remote Sens. Lett. 2017, 8, 839–848. [Google Scholar] [CrossRef]
- Zhang, J.; Wei, F.; Feng, F.; Wang, C. Spatial–spectral feature refinement for hyperspectral image classification based on attention-dense 3D-2D-CNN. Sensors 2020, 20, 5191. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Jayanth, J.; Shalini, V.S.; Ashok Kumar, T.; Koliwad, S. Land-use/land-cover classification using elephant herding algorithm. J. Indian Soc. Remote 2019, 47, 223–232. [Google Scholar] [CrossRef]
- Prabowo, A.S.; Sihabuddin, A.; Azhari, S.N. Adaptive moment estimation on deep belief network for rupiah currency forecasting. Indones. J. Comput. Cybern. Syst. 2019, 13, 31–42. [Google Scholar] [CrossRef]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive gradient methods with dynamic bound of learning rate. arXiv 2019, arXiv:1902.09843. [Google Scholar]
- Strumberger, I.; Minovic, M.; Tuba, M.; Bacanin, N. Performance of elephant herding optimization and tree growth algorithm adapted for node localization in wireless sensor networks. Sensors 2019, 19, 2515. [Google Scholar] [CrossRef]
- El Shaarawy, I.A.; Houssein, E.H.; Ismail, F.H.; Hassanien, A.E. An exploration-enhanced elephant herding optimization. Eng. Comput. 2019, 36, 3029–3046. [Google Scholar] [CrossRef]
- Hassanien, A.E.; Kilany, M.; Houssein, E.H.; Hameed, A. Intelligent Human Emotion Recognition Based on Elephant Herding Optimization Tuned Support Vector Regression. Biomed. Signal Process. Control. 2018, 45, 182–191. [Google Scholar] [CrossRef]
- Li, Y.; Xiao, J.; Chen, Y.; Jiao, L. Evolving deep convolutional neural networks by quantum behaved particle swarm optimization with binary encoding for image classification. Neurocomputing 2019, 362, 156–165. [Google Scholar] [CrossRef]
- Gao, Y.; Qin, L. A Segmented Particle Swarm Optimization Convolutional Neural Network for Land Cover and Land Use Classification of Remote Sensing Images. Remote Sens. Lett. 2019, 10, 1182–1191. [Google Scholar] [CrossRef]
- Qiao, H.; Wan, X. Object-Based Classification from Tiangong-2 Using Support Vector Machine Optimized with Evolutionary Algorithm. In Proceedings of the Tiangong-2 Remote Sensing Application Conference; Springer: Singapore, 2019; pp. 222–231. [Google Scholar]
- Shang, Y.; Zheng, X.; Li, J.; Liu, D.; Wang, P. A comparative analysis of swarm intelligence and evolutionary algorithms for feature selection in SVM-based hyperspectral image classification. Remote Sens. 2022, 14, 3019. [Google Scholar] [CrossRef]
- Kilany, M.; Hassanien, A.E. A Hybrid Elephant Herding Optimization and Support Vector Machines for Human Behavior Identification. In Proceedings of the 2017 Eighth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2017; pp. 178–184. [Google Scholar]
- Rajendran, G.B.; Kumarasamy, U.M.; Zarro, C.; Divakarachari, P.B.; Ullo, S.L. Land-use and land-cover classification using a human group-based particle swarm optimization algorithm with an LSTM Classifier on hybrid pre-processing remote-sensing images. Remote Sens. 2020, 12, 4135. [Google Scholar] [CrossRef]
- Landgrebe, D.A. Available online: http://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes (accessed on 17 June 2021).
- Yu, C.; Han, R.; Song, M.; Liu, C.; Chang, C.I. A simplified 2D-3D CNN architecture for hyperspectral image classification based on spatial–spectral fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2485–2501. [Google Scholar] [CrossRef]
- Feng, F.; Wang, S.; Wang, C.; Zhang, J. Learning Deep Hierarchical Spatial–Spectral Features for Hyperspectral Image Classification Based on Residual 3D-2D CNN. Sensors 2019, 19, 5276. [Google Scholar] [CrossRef] [PubMed]
- Paoletti, M.; Haut, J.; Plaza, J.; Plaza, A. Deep&Dense convolutional neural network for hyperspectral image classification. Remote Sens. 2018, 10, 1454. [Google Scholar]
- Kavitha, M.; Gayathri, R.; Polat, K.; Alhudhaif, A.; Alenezi, F. Performance Evaluation of Deep e-CNN with Integrated Spatial-Spectral Features in Hyperspectral Image Classification. Measurement 2022, 191, 110760. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Number | Class Name | No. of Training Samples | No. of Test Samples |
|---|---|---|---|
| 1 | Alfalfa | 5 | 41 |
| 2 | Corn-not ill | 143 | 1285 |
| 3 | Corn-mintill | 83 | 747 |
| 4 | Corn | 24 | 213 |
| 5 | Grass-pasture | 49 | 434 |
| 6 | Grass-trees | 73 | 657 |
| 7 | Grasspasture-mowed | 3 | 25 |
| 8 | Hay-windrowed | 48 | 430 |
| 9 | Oats | 2 | 18 |
| 10 | Soybean-notill | 98 | 874 |
| 11 | Soybean-mintill | 246 | 2209 |
| 12 | Soybean-clean | 60 | 533 |
| 13 | Wheat | 21 | 184 |
| 14 | Woods | 127 | 1138 |
| 15 | Buildings-Grass-Trees-Drives | 39 | 347 |
| 16 | Stone-Steel-Towers | 10 | 83 |
| 17 | TOTAL | 1031 | 9218 |
| Class Number | Class Name | No. of Training Samples | No. of Test Samples |
|---|---|---|---|
| 1 | Brocoli_green_weeds_1 | 101 | 1908 |
| 2 | Brocoli_green_weeds_2 | 187 | 3539 |
| 3 | Fallow | 99 | 1877 |
| 4 | Fallow_rough_plow | 70 | 1324 |
| 5 | Fallow_smooth | 134 | 2544 |
| 6 | Stubble | 198 | 3761 |
| 7 | Celery | 179 | 3400 |
| 8 | Grapes_untrained | 564 | 10,707 |
| 9 | Soil_vinyard_develop | 311 | 5892 |
| 10 | Corn_senesced_green_weeds | 164 | 3114 |
| 11 | Lettuce_romaine_4wk | 54 | 1014 |
| 12 | Lettuce_romaine_5wk | 97 | 1830 |
| 13 | Lettuce_romaine_6wk | 46 | 870 |
| 14 | Lettuce_romaine_7wk | 54 | 1016 |
| 15 | Vinyard_untrained | 364 | 6904 |
| 16 | Vinyard_vertical_trellis | 91 | 1716 |
| 17 | Total | 2713 | 51,416 |
| Literals | Considering Parameter | Parameter Value |
|---|---|---|
| M | Number of input layer nodes | 220 |
| Number of output layer nodes | 16 | |
| Number of hidden layer nodes | 300 | |
| CNN learning rate | 0.01 | |
| CNN training target error | 0.001 | |
| epochs | CNN maximum number of cycles | 100 |
| it_max_adabound | CNN–EEHO maximum number of iterations | 50 |
| Population size of the quantum elephant herding | 30 | |
| Number of clans | 5 | |
| Number of elephants in each clan | 6 | |
| Influencing factor | 0.4 |
| Class | 2D–3D CNN | SSRN | ResNet | DenseNet | e-CNN | CNN–EEHO–AdaBound |
|---|---|---|---|---|---|---|
| 1 | 71.24 | 95.26 | 97.98 | 99.29 | 89.79 | 99.72 |
| 2 | 72.65 | 95.67 | 97.63 | 94.36 | 97.45 | 98.64 |
| 3 | 75.13 | 96.36 | 96.64 | 97.58 | 97.02 | 97.58 |
| 4 | 87.20 | 88.83 | 88.10 | 99.68 | 94.32 | 100.00 |
| 5 | 69.36 | 97.68 | 98.57 | 99.28 | 95.19 | 97.64 |
| 6 | 93.57 | 96.79 | 100.05 | 89.57 | 99.41 | 100.00 |
| 7 | 64.28 | 98.25 | 99.98 | 100.00 | 97.23 | 98.26 |
| 8 | 98.10 | 99.15 | 95.14 | 95.12 | 99.56 | 96.76 |
| 9 | 83.13 | 77.28 | 94.25 | 94.50 | 87.05 | 98.86 |
| 10 | 77.16 | 97.79 | 99.34 | 96.37 | 97.34 | 100.00 |
| 11 | 85.15 | 98.63 | 98.28 | 98.54 | 99.02 | 100.00 |
| 12 | 74.87 | 100.00 | 100.00 | 99.01 | 99.34 | 97.26 |
| 13 | 98.24 | 98.38 | 94.83 | 100.00 | 99.67 | 95.21 |
| 14 | 94.87 | 99.14 | 97.28 | 99.15 | 99.00 | 96.84 |
| 15 | 81.89 | 89.37 | 89.64 | 90.16 | 99.46 | 88.29 |
| 16 | 77.37 | 93.48 | 99.06 | 89.87 | 94.93 | 99.04 |
| OA | 83.39 | 96.91 | 98.26 | 99.03 | 99.36 | 99.47 |
| AA | 82.29 | 96.06 | 97.75 | 98.89 | 98.81 | 98.99 |
| ĸ × 100 | 81.26 | 95.79 | 97.78 | 98.71 | 97.94 | 98.32 |
| Class | 2D–3D CNN | SSRN | ResNet | DenseNet | e-CNN | CNN–EEHO–AdaBound |
|---|---|---|---|---|---|---|
| 1 | 94.11 | 98.46 | 95.67 | 99.49 | 99.67 | 99.67 |
| 2 | 98.46 | 96.76 | 95.79 | 97.12 | 98.78 | 99.39 |
| 3 | 86.03 | 88.32 | 92.46 | 98.63 | 100.00 | 98.66 |
| 4 | 98.45 | 97.68 | 96.89 | 98.79 | 99.12 | 97.70 |
| 5 | 85.65 | 92.59 | 95.26 | 100.00 | 98.34 | 100.00 |
| 6 | 97.68 | 98.14 | 89.35 | 100.00 | 99.49 | 100.00 |
| 7 | 95.09 | 99.06 | 97.06 | 99.36 | 99.37 | 98.49 |
| 8 | 96.98 | 75.79 | 92.37 | 99.89 | 99.18 | 97.71 |
| 9 | 97.12 | 98.45 | 98.28 | 96.78 | 99.47 | 98.30 |
| 10 | 77.44 | 77.60 | 88.92 | 97.45 | 98.31 | 99.63 |
| 11 | 84.60 | 79.23 | 97.56 | 99.15 | 98.99 | 100.00 |
| 12 | 98.36 | 97.11 | 100.00 | 100.00 | 99.26 | 100.00 |
| 13 | 97.65 | 89.98 | 87.16 | 98.38 | 99.46 | 97.28 |
| 14 | 89.89 | 88.59 | 89.03 | 100.00 | 99.38 | 99.18 |
| 15 | 44.23 | 59.04 | 91.27 | 90.45 | 99.11 | 92.84 |
| 16 | 85.18 | 89.11 | 98.89 | 97.59 | 99.98 | 98.87 |
| OA | 90.87 | 97.15 | 98.14 | 99.04 | 99.01 | 99.99 |
| AA | 89.16 | 97.56 | 98.08 | 99.29 | 99.19 | 99.58 |
| ĸ × 100 | 88.04 | 95.83 | 96.51 | 97.57 | 97.04 | 98.12 |
| Performance Evaluation for Indian Pines Dataset | CSO–CNN | ACO | PSO–CNN | CNN–EEHO–AdaBound |
|---|---|---|---|---|
| OA | 91.54 | 94.61 | 96.18 | 99.47 |
| AA | 95.49 | 95.83 | 96.27 | 98.99 |
| K × 100 | 90.53 | 93.75 | 95.84 | 98.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Munishamaiaha, K.; Kannan, S.K.; Venkatesan, D.; Jasiński, M.; Novak, F.; Gono, R.; Leonowicz, Z. Hyperspectral Image Classification with Deep CNN Using an Enhanced Elephant Herding Optimization for Updating Hyper-Parameters. Electronics 2023, 12, 1157. https://doi.org/10.3390/electronics12051157
Munishamaiaha K, Kannan SK, Venkatesan D, Jasiński M, Novak F, Gono R, Leonowicz Z. Hyperspectral Image Classification with Deep CNN Using an Enhanced Elephant Herding Optimization for Updating Hyper-Parameters. Electronics. 2023; 12(5):1157. https://doi.org/10.3390/electronics12051157
Chicago/Turabian StyleMunishamaiaha, Kavitha, Senthil Kumar Kannan, DhilipKumar Venkatesan, Michał Jasiński, Filip Novak, Radomir Gono, and Zbigniew Leonowicz. 2023. "Hyperspectral Image Classification with Deep CNN Using an Enhanced Elephant Herding Optimization for Updating Hyper-Parameters" Electronics 12, no. 5: 1157. https://doi.org/10.3390/electronics12051157
APA StyleMunishamaiaha, K., Kannan, S. K., Venkatesan, D., Jasiński, M., Novak, F., Gono, R., & Leonowicz, Z. (2023). Hyperspectral Image Classification with Deep CNN Using an Enhanced Elephant Herding Optimization for Updating Hyper-Parameters. Electronics, 12(5), 1157. https://doi.org/10.3390/electronics12051157