

Scaling Automated Programming Assessment Systems




Abstract
:1. Introduction
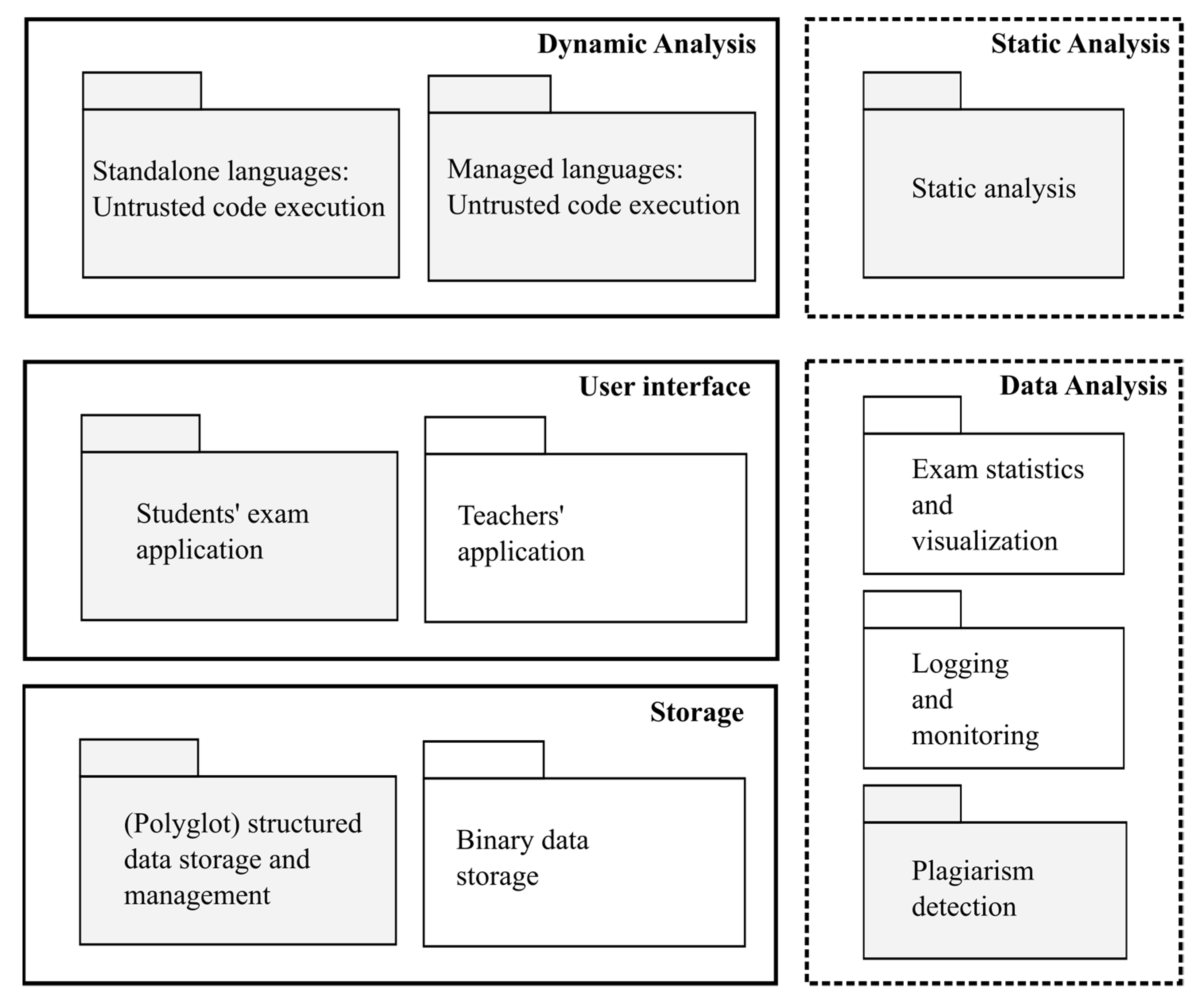
2. APAS Modules
3. Core APAS Modules
3.1. (Polyglot) Structured Data Storage and Management
- Vertical scaling of databases is limited and eventually reaches the limit where additional resources (CPU, memory, etc.) no longer improve performance,
- Horizontally database scaling can be achieved either by (asynchronous) replication (e.g., PostgreSQL’s streaming replication, where the logical log is streamed and replayed on the replica server) or by using out-of-the-box master-slave database management systems such as MongoDB, which provide N replicas, but only for the read operations, and
- Write operations with strong consistency guarantees will always be subject to the CAP theorem [35] and can hardly scale horizontally.
Structured Data Storage in APAS Edgar
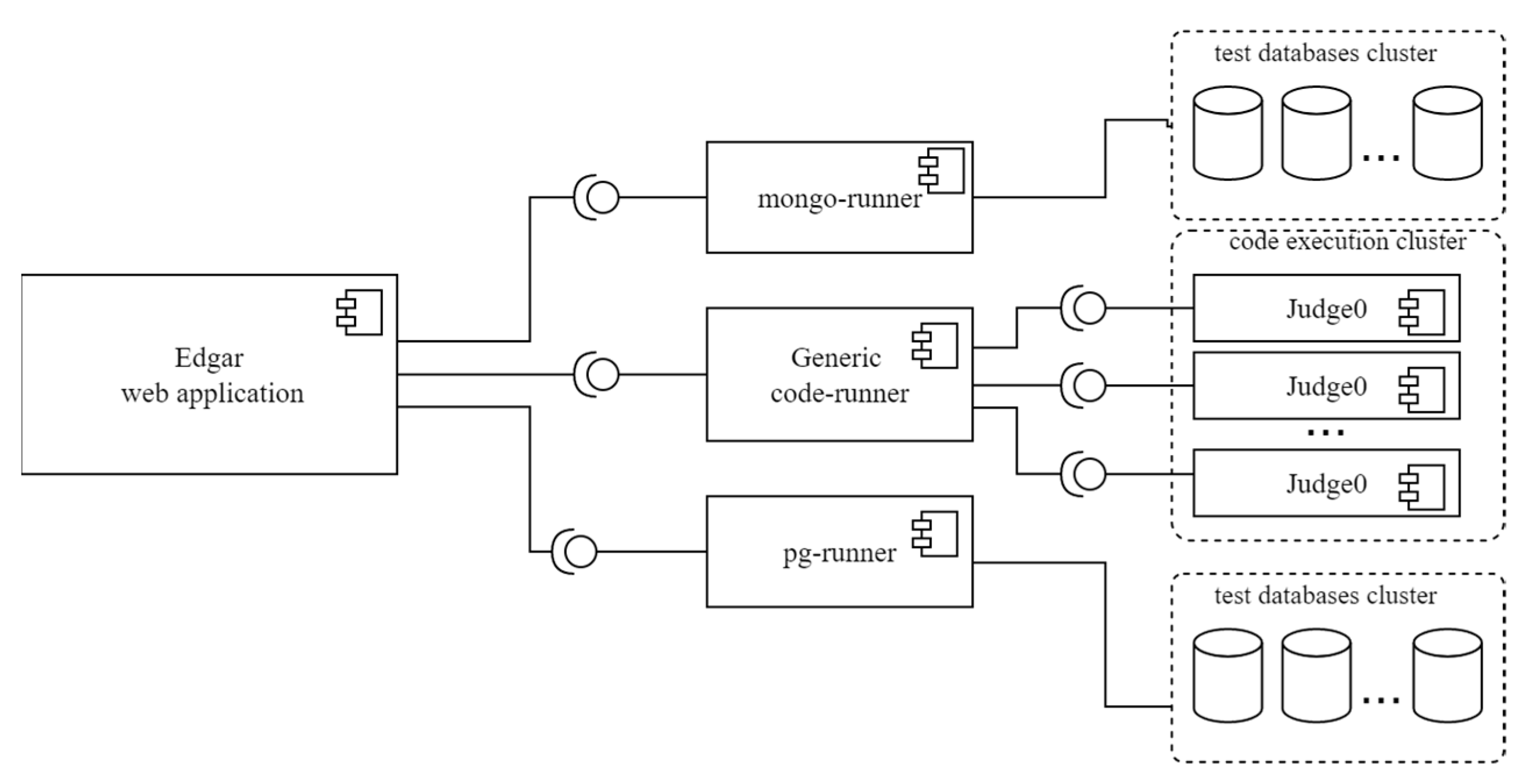
3.2. Dynamic Analysis—Untrusted Code Execution
3.2.1. Sandboxing Untrusted Code
- Begin transaction,
- Execute an arbitrary number of DML (select, update, insert, delete) or even DDL (create and alter table, create index, etc.) statements,
- Retrieve the temporary results by querying the tables or system catalog, and
- Rollback transaction.
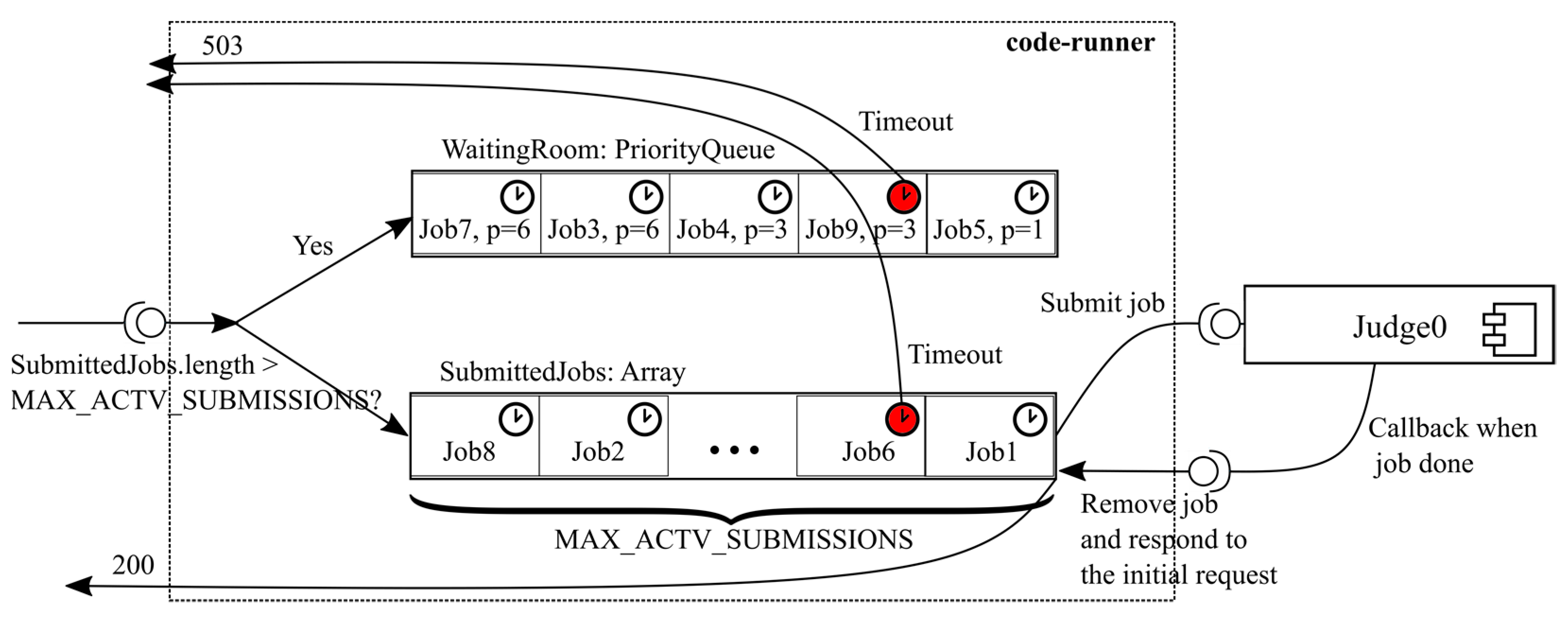
3.2.2. Performance Considerations
- Delayed (asynchronous execution) paradigm—code is submitted, queued for execution, and results (as well as feedback) are computed seconds, minutes, or even hours after the submission. This paradigm is more commonly used when submissions are “projects”, usually submitted as a zipped folder containing multiple files. This paradigm is much easier to implement but can hardly be used to implement e-learning scenarios with rapid feedback. Some APAS use only this paradigm (e.g., Jack [1]).
- Immediate (synchronous execution and feedback) paradigm—the code is processed as soon as it is submitted, and feedback is retrieved within seconds. This paradigm is more difficult to implement, but it enables a much better user experience for students and allows for a broader range of usage scenarios. For example, it can be used to support e-learning systems (not just exam evaluation).
3.2.3. Dynamic Analysis in APAS Edgar
- Only two servers were used, just as in the previous successful winter semester, when the same number of students took similar exams—but in the C language. Java is much more resource intensive than C. The compiler is slower, and the execution of the bytecode generated by the JVM is significantly slower than the machine code generated by the GCC compiler. On average, C code questions are executed in approximately 1 s and Java code questions in approximately 2.5 s.
- The disruption of the 09:00–12:00–15:00 exam schedule allowed students to load the system unevenly, with most students opting for the last three hours from 15:00 to 18:00 (some of them probably sought experience from colleagues).
- Client-side throttling—if resources are insufficient to scale the code runner cluster, a throttling mechanism can be imposed on clients to prevent them from flooding the server with requests. After the incident, the pace concept was introduced in APAS Edgar. The pace is defined via an array of seconds that specifies how many seconds a student must wait before being able to execute the code. For instance, pace1 = [0, 0, 5, 10, 17 × 106] states that one must wait:
- ○
- 0 s before running the code for the first time,
- ○
- 0 s before running the code for the second time,
- ○
- 5 s before running the code for the third time,
- ○
- 10 s before running the code for the fourth time, and
- ○
- 16 s before running the code for the fifth time, i.e., there is no fifth time.
- Obviously, one can use the pace feature to limit the maximum number of runs. Pace can be used (and is combined) at two levels:
- ○
- Question pace—the pace array is applied to each individual question;
- ○
- Exam pace—the pace array is applied with regard to the cumulative number of runs (of all questions).
- When using two paces (question and exam), the one with the longer wait times wins. To illustrate, let us say we have an exam with two questions, where question_pace = [0, 5, 10, 15] and exam_pace = [0, 0, 30, 40]. The initial wait time is 0, i.e., the student does not have to wait to run the question. Student runs:
- ○
- Question 1 for the first time, now we get P = max(5, 0) = 5 s;
- ○
- Question 1 for the second time, now we get P = max(10, 30) = 30 s;
- ○
- Question 2 for the first time, now we get P = max(0, 40) = 40 s.
- Server-side pushback—in this approach, the server protects itself from the excessive load by responding with 503 Service Unavailable message. Clients can interpret this message as a pushback and introduce a cool-down period that allows the server to recover from the heavy load.
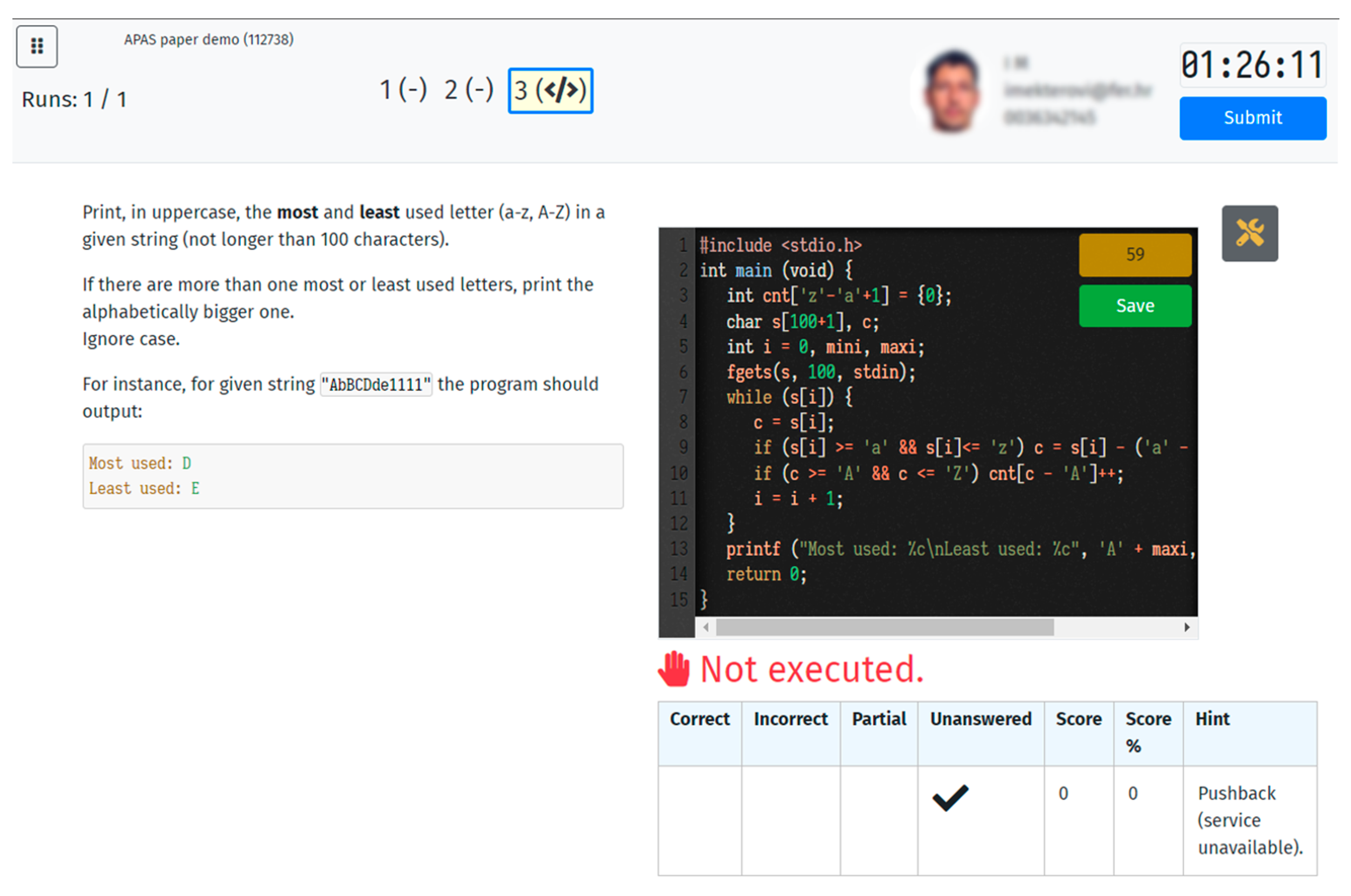
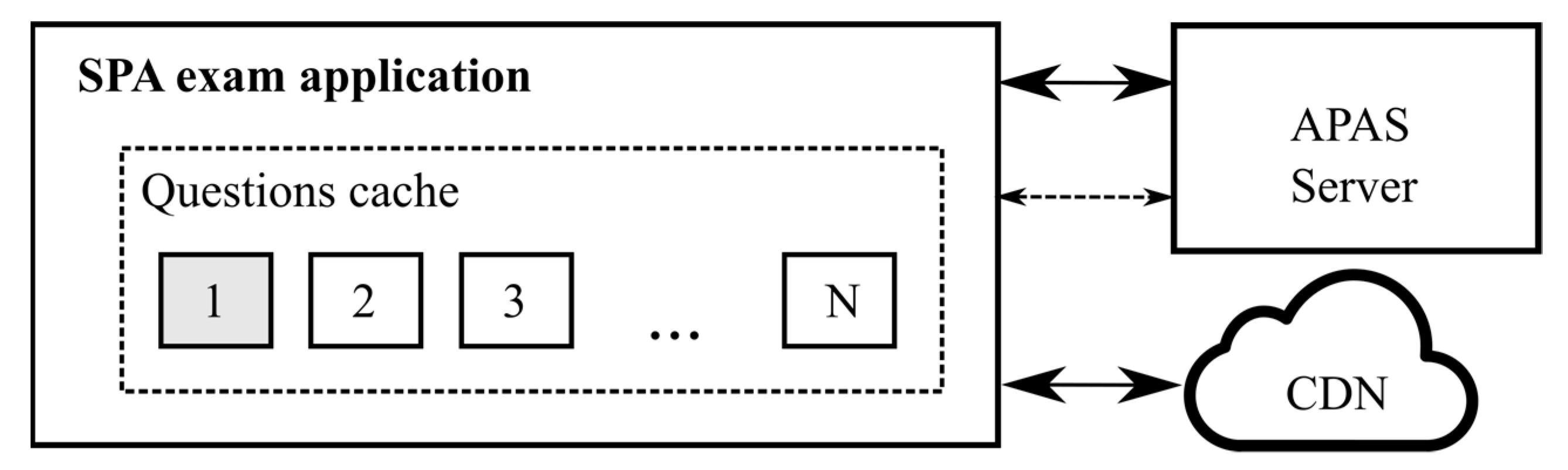
3.3. Students’ Exam Application
- ○
- CDN—delivering various web libraries (fonts, JS libs, etc.), and
- ○
- APAS server delivering the custom JavaScript SPA web application.
4. Optional Advanced APAS Modules
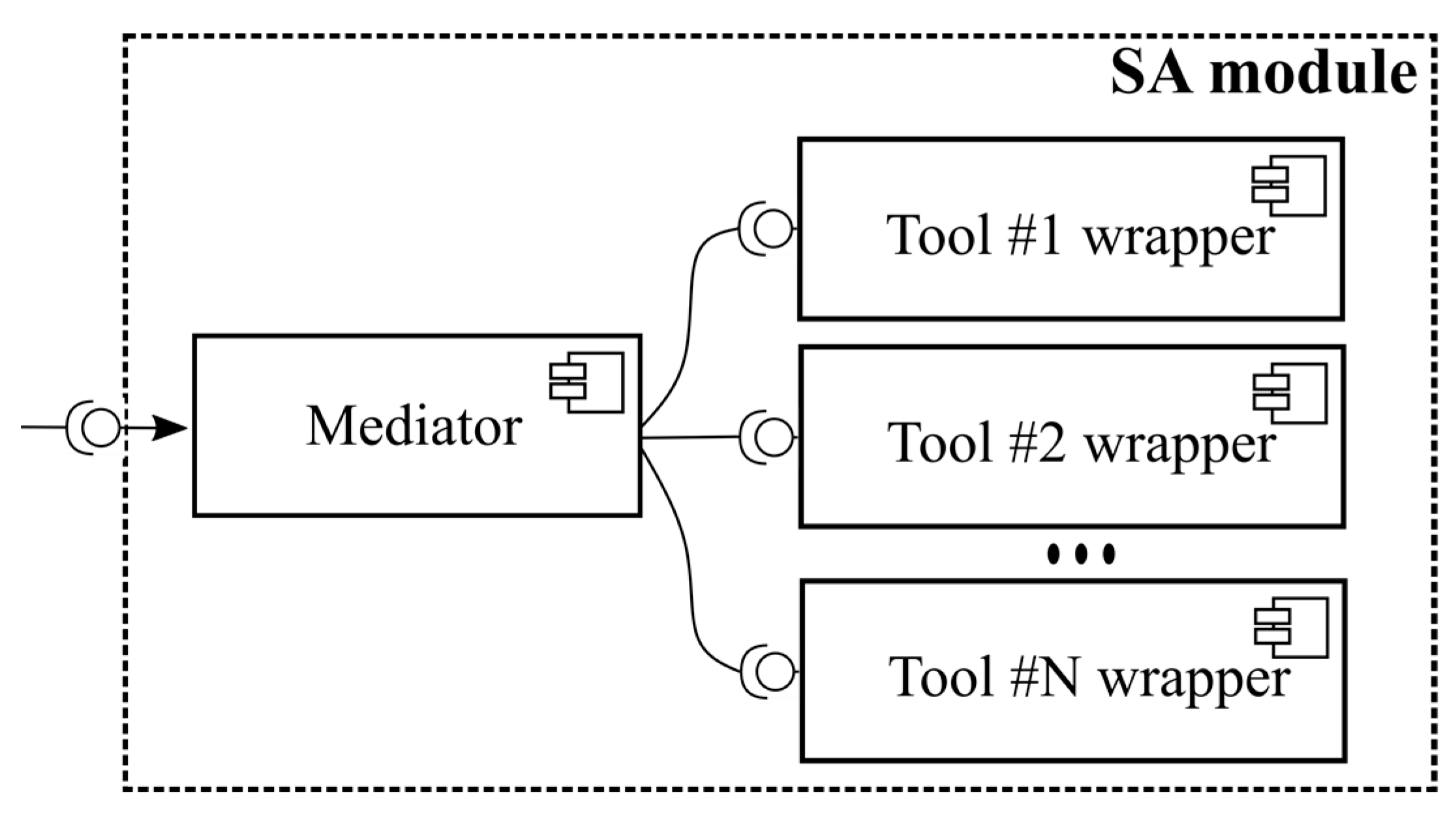
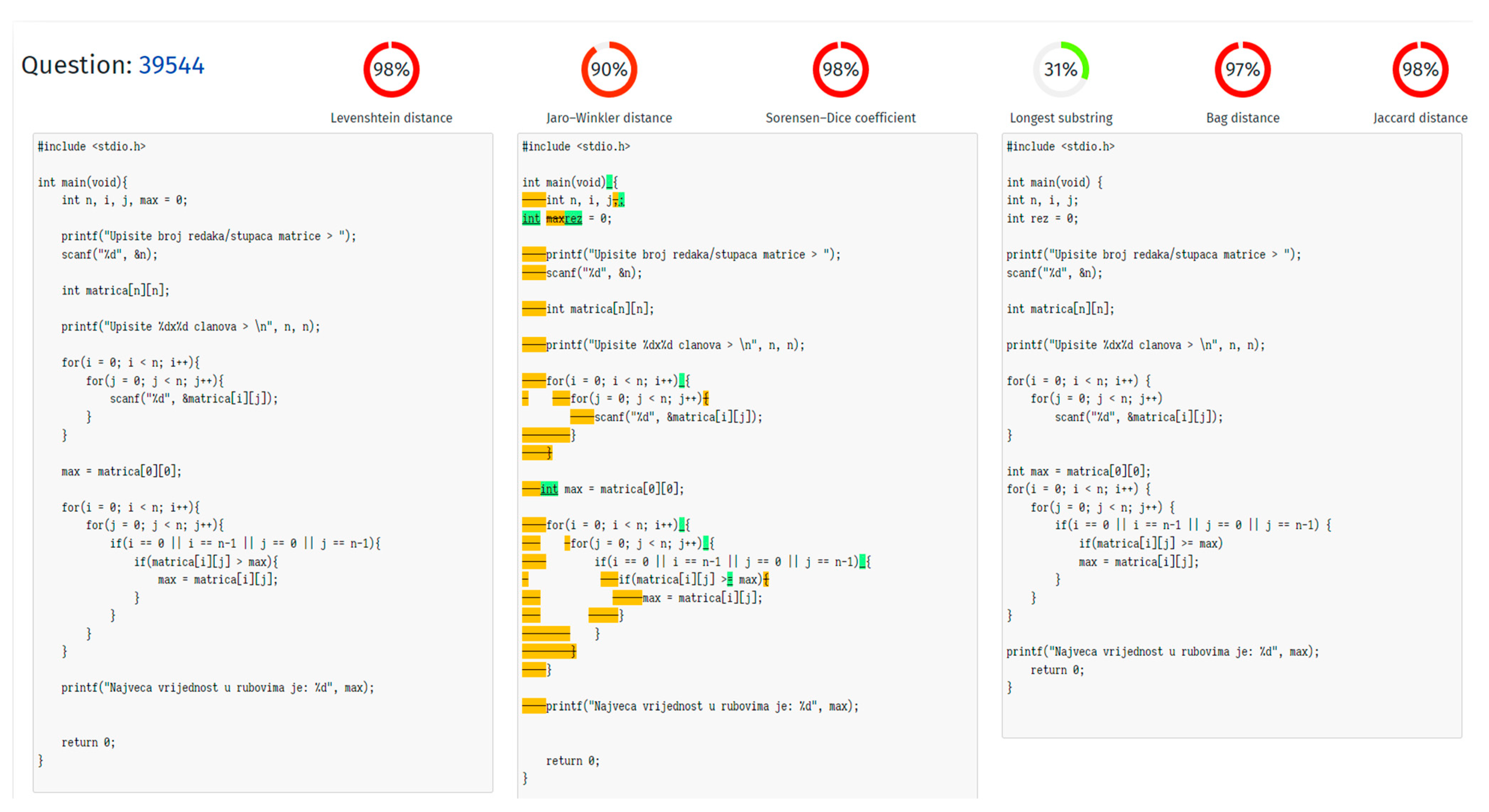
4.1. Static Analysis
Static Analysis in APAS Edgar
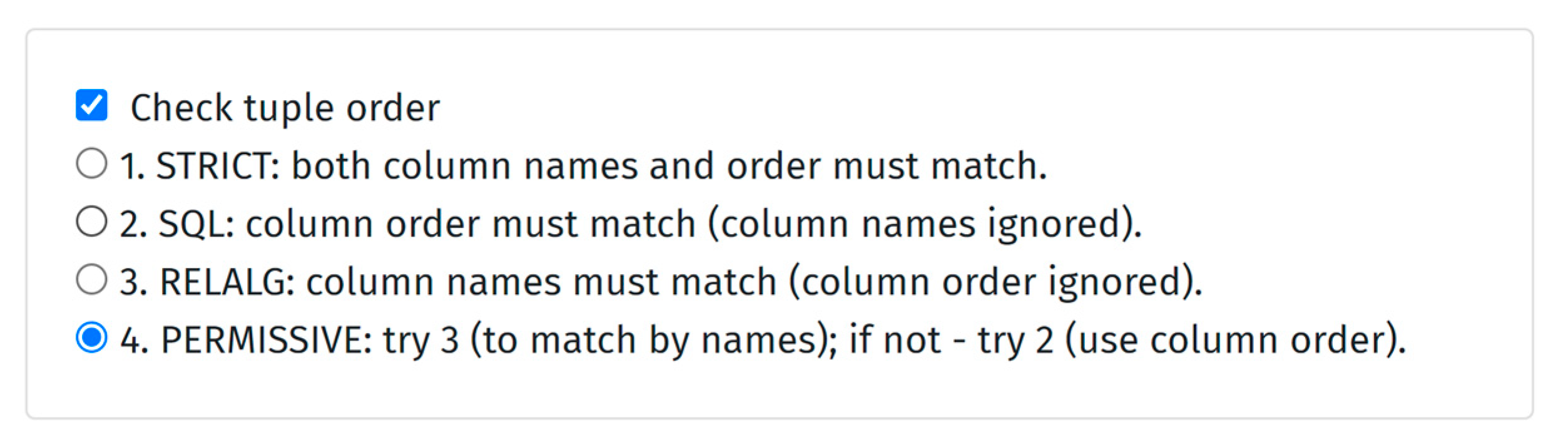
4.2. Plagiarism Detection
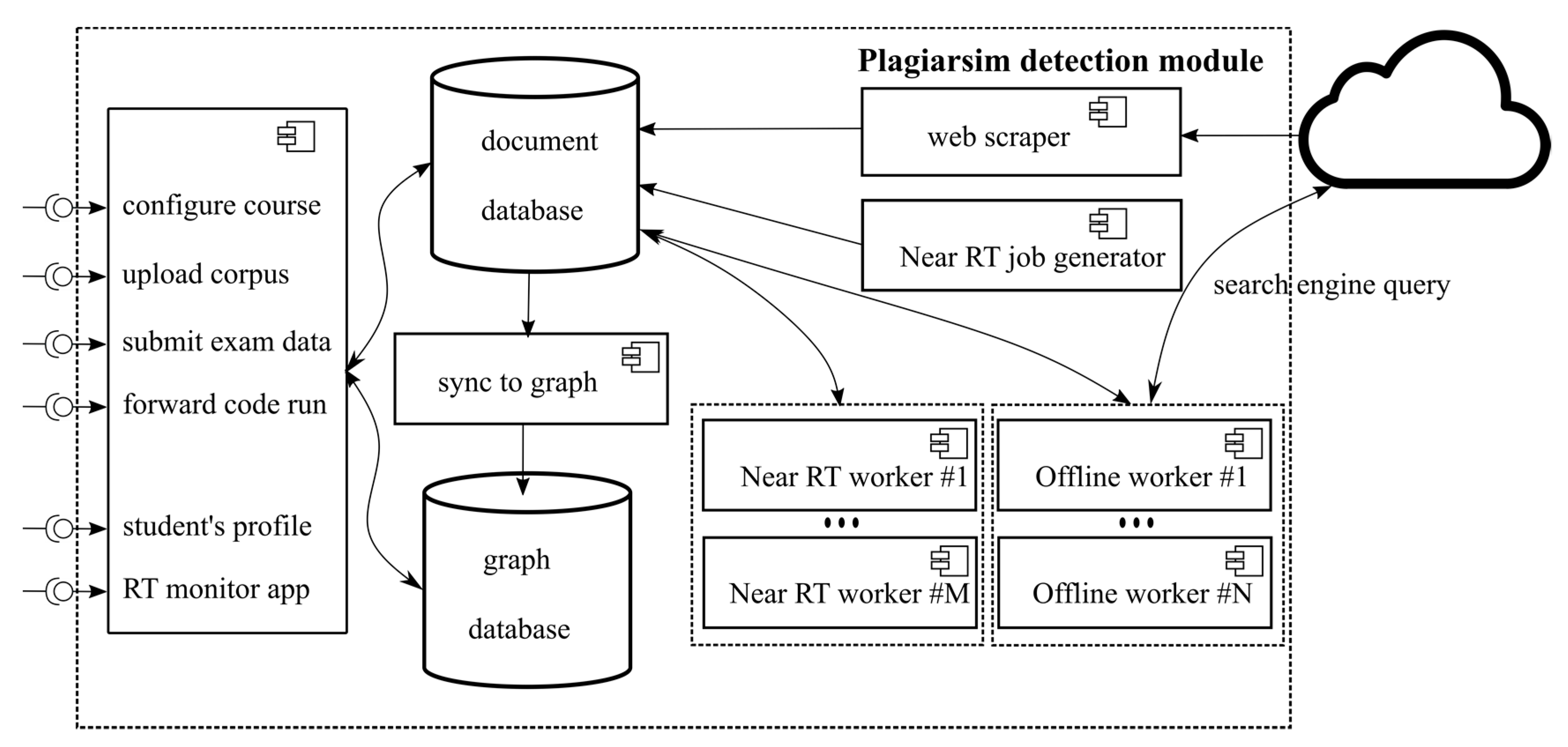
Plagiarism Detection in APAS Edgar
- The plagiarism detection module should be a configurable stand-alone service that continuously scans for potential cheaters and creates an integrated “plagiarism profile” for each student enrolled in the course.
- Profiles, as well as standardized reports will be available to teachers on demand, but the module will also allow for notifications to be sent on high fraud scores.
- The configuration, which includes the definition of the algorithms, the scope of the corpus used for plagiarism detection (exam, course, previous years, assigned datasets, internet sources), the working hours of the module (e.g., 00–06) or CPU thresholds (e.g., 10 min of less than X% CPU).
- Whether the plagiarism profile is visible to the student will also be configurable. An interesting research question is whether such profiles, which include a clear message that the code is being checked for plagiarism, help reduce plagiarism (and to what extent).
- Multiple consecutive runs of the correct code, with the code changing slightly—the student is not motivated to change the successful code except maybe to cover their tracks by changing variable names, etc.
- Correct code, followed by incorrect code—again, similar pattern, probably the result of covering tracks.
- Incorrect code, followed by the significantly different correct code—the student might have acquired the correct solution and pasted the correct code, etc.
- Offline or queued plagiarism detection which continuously searches for plagiarism in the configured working hours
- Near real-time plagiarism detection. APAS systems should only forward the code to the module’s API, which can be achieved even if they have responded to their clients, so there is minimal load on the production APAS. The main service stores only the code to conserve resources and be available to receive new code runs. A separate job generator, operating in near real time, expands the new data received into jobs that are queued for processing. Another worker cluster retrieves the jobs, computes code similarities, and stores them back. Such a setup of stateless workers facilitates scaling because most of the work is processed by the workers. Simultaneously, a subset of the data about processed jobs is replicated asynchronously to the graph database to support graph queries for elegant detection of cheating patterns—the suspicious patterns listed above can all be expressed as Cypher queries.
5. Non-Resource-Intensive APAS Modules
- Logging and monitoring exam writing process, which must be custom developed within the APAS. This entails logging students’ actions during the exam, network client information, etc., and a corresponding monitoring application that teachers can use during the exam to monitor and gain insight about the process.
- Logging and collecting/monitoring distributed web application logs. For this part, APAS Edgar used the ELK stack, but we have since downscaled (to reduce the complexity of the system) to a custom solution that stores the logs in the MongoDB database and makes them visible in the web application menu.
- Logging and monitoring operating systems (CPU, memory, disk, network) of all servers in the APAS ecosystem. For this, we use Prometheus [52] and Grafana [53] combination. Besides out-of-the-box OS metrics, we have added metrics to both pg-runner and code-runner so that we can monitor important exam parameters in real-time such as SubmittedJobs ans WaitingRoom queues.
6. Discussion and Related Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Striewe, M. An architecture for modular grading and feedback generation for complex exercises. Sci. Comput. Program. 2016, 129, 35–47. [Google Scholar] [CrossRef]
- Pietrikova, E.; Juhár, J.; Šťastná, J. Towards automated assessment in game-creative programming courses. In Proceedings of the 2015 13th International Conference on Emerging eLearning Technologies and Applications (ICETA), Stary Smokovec, Slovakia, 26–27 November 2016. [Google Scholar] [CrossRef]
- Paiva, J.C.; Leal, J.P.; Queirós, R.A. Enki: A pedagogical services aggregator for learning programming languages. In Proceedings of the Innovation and Technology in Computer Science Education Conference, ITiCSE, Arequipa, Peru, 11–13 July 2016; pp. 332–337. [Google Scholar] [CrossRef]
- Krugel, J.; Hubwieser, P.; Goedicke, M.; Striewe, M.; Talbot, M.; Olbricht, C.; Schypula, M.; Zettler, S. Automated measurement of competencies and generation of feedback in object-oriented programming courses. In Proceedings of the 2020 IEEE Global Engineering Education Conference (EDUCON), Porto, Portugal, 27–30 April 2020; pp. 329–338. [Google Scholar] [CrossRef]
- Petit, J.; Roura, S.; Carmona, J.; Cortadella, J.; Duch, A.; Gimenez, O.; Mani, A.; Mas, J.; Rodriguez-Carbonella, E.; Rubio, A.; et al. Jutge.org: Characteristics and Experiences. IEEE Trans. Learn. Technol. 2018, 11, 321–333. [Google Scholar] [CrossRef]
- Enstrom, E.; Kreitz, G.; Niemela, F.; Soderman, P.; Kann, V. Five years with Kattis—Using an automated assessment system in teaching. In Proceedings of the 2011 Frontiers in Education Conference (FIE), Rapid City, SD, USA, 12–15 October 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, X.; Woo, G. Applying Code Quality Detection in Online Programming Judge. In Proceedings of the 2020 5th International Conference on Intelligent Information Technology, Hanoi, Vietnam, 19–22 February 2020; pp. 56–60. [Google Scholar] [CrossRef]
- Yu, Y.; Tang, C.; Poon, C. Enhancing an automated system for assessment of student programs using the token pattern approach. In Proceedings of the 2017 IEEE 6th International Conference on Teaching, Assessment, and Learning for Engineering (TALE), Hong Kong, China, 12–14 December 2017; pp. 406–413. [Google Scholar] [CrossRef]
- Peveler, M.; Tyler, J.; Breese, S.; Cutler, B.; Milanova, A. Submitty: An Open Source, Highly-Configurable Platform for Grading of Programming Assignments (Abstract Only). In Proceedings of the 48th ACM Technical Symposium on Computer Science Education, Seattle, WA, USA, 8–11 March 2017; p. 641. [Google Scholar]
- Pärtel, M.; Luukkainen, M.; Vihavainen, A.; Vikberg, T. Test my code. Int. J. Technol. Enhanc. Learn. 2013, 5, 271–283. [Google Scholar] [CrossRef]
- Vesin, B.; Klasnja-Milicevic, A.; Ivanovic, M. Improving testing abilities of a programming tutoring system. In Proceedings of the 2013 17th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 11–13 October 2013; pp. 669–673. [Google Scholar] [CrossRef]
- Bez, J.L.; Tonin, N.A.; Rodegheri, P.R. URI Online Judge Academic: A tool for algorithms and programming classes. In Proceedings of the 2014 9th International Conference on Computer Science & Education, Vancouver, BC, Canada, 22–24 August 2014; pp. 149–152. [Google Scholar] [CrossRef]
- Hu, Y.; Ahmed, U.Z.; Mechtaev, S.; Leong, B.; Roychoudhury, A. Re-factoring based program repair applied to programming assignments. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 11–15 November 2019; pp. 388–398. [Google Scholar] [CrossRef]
- Edwards, S.H.; Perez-Quinones, M.A. Web-CAT: Automatically grading programming assignments. In Proceedings of the 13th Annual Conference on Innovation and Technology in Computer Science Education, Madrid, Spain, 30 June–2 July 2008; p. 328. [Google Scholar] [CrossRef]
- Robinson, P.E.; Carroll, J. An online learning platform for teaching, learning, and assessment of programming. In Proceedings of the IEEE Global Engineering Education Conference (EDUCON), Athens, Greece, 25–28 April 2017; pp. 547–556. [Google Scholar] [CrossRef]
- Lobb, R.; Harlow, J. Coderunner: A tool for assessing computer programming skills. ACM Inroads 2016, 7, 47–51. [Google Scholar] [CrossRef]
- Vander Zanden, B.; Berry, M.W. Improving Automatic Code Assessment. J. Comput. Sci. Coll. 2013, 29, 162–168. [Google Scholar]
- Brito, M.; Goncalves, C. Codeflex: A web-based platform for competitive programming. In Proceedings of the 14th Iberian Conference on Information Systems and Technologies (CISTI), Coimbra, Portugal, 19–22 June 2019; pp. 19–22. [Google Scholar] [CrossRef]
- Benetti, G.; Roveda, G.; Giuffrida, D.; Facchinetti, T. Coderiu: A cloud platform for computer programming e-learning. In Proceedings of the IEEE 17th International Conference on Industrial Informatics (INDIN), Helsinki, Finland, 22–25 July 2019; pp. 1126–1132. [Google Scholar] [CrossRef]
- Staubitz, T.; Klement, H.; Teusner, R.; Renz, J.; Meinel, C. CodeOcean—A versatile platform for practical programming excercises in online environments. In Proceedings of the IEEE Global Engineering Education Conference (EDUCON), Abu Dhabi, United Arab Emirates, 10–13 April 2016; pp. 314–323. [Google Scholar] [CrossRef]
- Edwards, S.H.; Murali, K.P. CodeWorkout: Short programming exercises with built-in data collection. In Proceedings of the Innovation and Technology in Computer Science Education, ITiCSE, Bologna, Italy, 3–5 July 2017; pp. 188–193, Part F1286. [Google Scholar] [CrossRef]
- Duch, P.; Jaworski, T. Dante—Automated assessments tool for students’ programming assignments. In Proceedings of the 2018 11th International Conference on Human System Interaction (HIS’18), Gdansk, Poland, 4–6 July 2018; IEEE: New York, NY, USA, 2018; pp. 162–168. [Google Scholar] [CrossRef]
- Mekterovic, I.; Brkic, L.; Milasinovic, B.; Baranovic, M. Building a Comprehensive Automated Programming Assessment System. IEEE Access 2020, 8, 81154–81172. [Google Scholar] [CrossRef]
- Paiva, J.C.; Leal, J.P.; Figueira, Á. Automated Assessment in Computer Science Education: A State-of-the-Art Review. ACM Trans. Comput. Educ. 2022, 22, 1–40. [Google Scholar] [CrossRef]
- Shivakumar, S.K. Architecting High Performing, Scalable and Available Enterprise Web Applications. In Architecting High Performing, Scalable and Available Enterprise Web Applications; Morgan Kaufmann: Burlington, MA, USA, 2014; pp. 1–265. [Google Scholar] [CrossRef]
- Ullah, F.; Babar, M.A. On the scalability of Big Data Cyber Security Analytics systems. J. Netw. Comput. Appl. 2022, 198, 103294. [Google Scholar] [CrossRef]
- Altalhi, A.H.; Al-Ghamdi, A.A.-M.; Ullah, Z.; Saleem, F. Developing a framework and algorithm for scalability to evaluate the performance and throughput of CRM systems. Intell. Autom. Soft Comput. 2016, 23, 149–152. [Google Scholar] [CrossRef]
- Zhu, J.; Patros, P.; Kent, K.B.; Dawson, M. Node.js scalability investigation in the cloud. In Proceedings of the 28th Annual International Conference on Computer Science and Software Engineering (CASCON 2018), Markham, ON, Canada, 29–31 October 2018; pp. 201–212. Available online: https://researchcommons.waikato.ac.nz/handle/10289/12862 (accessed on 2 December 2022).
- Xie, J.; Yu, F.R.; Huang, T.; Xie, R.; Liu, J.; Liu, Y. A Survey on the Scalability of Blockchain Systems. IEEE Netw. 2019, 33, 166–173. [Google Scholar] [CrossRef]
- Edgar-Group—GitLab. Available online: https://gitlab.com/edgar-group/ (accessed on 2 December 2022).
- Combéfis, S. Automated Code Assessment for Education: Review, Classification and Perspectives on Techniques and Tools. Software 2022, 1, 3–30. [Google Scholar] [CrossRef]
- Souza, D.M.; Felizardo, K.R.; Barbosa, E.F. A systematic literature review of assessment tools for programming assignments. In Proceedings of the 2016 IEEE 29th International Conference on Software Engineering Education and Training (CSEET), Dallas, TX, USA, 5–6 April 2016; pp. 147–156. [Google Scholar] [CrossRef]
- Keuning, H.; Jeuring, J.; Heeren, B. A Systematic Literature Review of Automated Feedback Generation for Programming Exercises. ACM Trans. Comput. Educ. 2018, 19, 1–43. [Google Scholar] [CrossRef]
- Croft, D.; England, M. Computing with CodeRunner at Coventry University Automated summative assessment of Python and C++ code. In Proceedings of the 4th Conference on Computing Education Practice (CEP’20), Durham, UK, 9 January 2020. [Google Scholar] [CrossRef]
- Gilbert, S.; Lynch, N. Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services. ACM Sigact News 2002, 33, 51–59. [Google Scholar] [CrossRef]
- Sadalage, P.J.; Fowler, M. NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence; Pearson Education: London, UK, 2012. [Google Scholar]
- Mekterović, I.B.L. Edgar’s Database Schema Dump v.1.3.7. 2017. Available online: https://gitlab.com/edgar-group/edgar/-/blob/master/db/db-schema/dumps/edgar-schema-dump-v1-3-7.sql (accessed on 9 February 2023).
- Dosilovic, H.Z.; Mekterovic, I. Robust and scalable online code execution system. In Proceedings of the 2020 43rd International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 28 September–2 October 2020; pp. 1627–1632. [Google Scholar] [CrossRef]
- Mareš, M.; Blackham, B. A New Contest Sandbox. Olymp. Inform. 2012, 6, 113–119. Available online: https://ioi.te.lv/oi/pdf/INFOL094.pdf (accessed on 23 November 2022).
- Varnish HTTP Cache—Varnish HTTP Cache. Available online: https://varnish-cache.org/ (accessed on 29 November 2022).
- Baldoni, R.; Coppa, E.; D’Elia, D.C.; Demetrescu, C.; Finocchi, I. A survey of symbolic execution techniques. ACM Comput. Surv. 2018, 51, 1–39. [Google Scholar] [CrossRef]
- Do, L.N.Q.; Wright, J.R.; Ali, K. Why Do Software Developers Use Static Analysis Tools ? A User-Centered Study of Developer Needs and Motivations. IEEE Trans. Softw. Eng. 2020, 48, 835–847. [Google Scholar] [CrossRef]
- Rahman, A.; Rahman, R.; Parnin, C.; Williams, L. Security Smells in Ansible and Chef Scripts. ACM Trans. Softw. Eng. Methodol. 2021, 30, 1–31. [Google Scholar] [CrossRef]
- Code Quality and Code Security|SonarQube. Available online: https://www.sonarqube.org/ (accessed on 6 December 2022).
- PMD. Available online: https://pmd.github.io/ (accessed on 6 December 2022).
- Find and Fix Problems in Your JavaScript Code—ESLint—Pluggable JavaScript Linter. Available online: https://eslint.org/ (accessed on 6 December 2022).
- SARIF Home. Available online: https://sarifweb.azurewebsites.net/ (accessed on 19 January 2023).
- Sutherland, E.H.; Cressey, D.R.; Luckenbill, D.F. Principles of Criminology. 1992. Available online: https://books.google.com/books?hl=hr&lr=&id=JVB3AAAAQBAJ&oi=fnd&pg=PP1&ots=mOPdm7zPB9&sig=64VSdr3R8j_ksaO3yykzJI4cIkw (accessed on 6 December 2022).
- Albluwi, I. Plagiarism in Programming Assessments. ACM Trans. Comput. Educ. 2019, 20, 1–28. [Google Scholar] [CrossRef]
- Prechelt, L.; Malpohl, G.; Philippsen, M. Finding Plagiarisms among a Set of Programs with JPlag. Available online: http://www.jplag.de (accessed on 30 November 2022).
- MinIO|High Performance, Kubernetes Native Object Storage. Available online: https://min.io/ (accessed on 1 December 2022).
- Prometheus—Monitoring System & Time Series Database. Available online: https://prometheus.io/ (accessed on 1 December 2022).
- Grafana: The Open Observability Platform|Grafana Labs. Available online: https://grafana.com/ (accessed on 1 December 2022).
- Checkstyle—Checkstyle 10.5.0. Available online: https://checkstyle.sourceforge.io/ (accessed on 8 December 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool | Refs | Storage | Dynamic Analysis | Static Analysis | Plag Detection | Supported PL | Feedback |
|---|---|---|---|---|---|---|---|
| Arena | [2] | UT | C, Java | Delayed | |||
| CloudCoder | [13] | MySQL | OC | C/C++, Java, Python, Ruby | |||
| CodeAssessor | [17] | MySQL | OC | C/C++, Java, Python, Ruby | Instant | ||
| Codeflex | [18] | MySQL | OC | ✓ | C++, C#, Java, Python, | Instant | |
| Coderiu | [19] | File Storage Service(FSS) | UT | Multi | Delayed | ||
| CodeOcean | [20] | PostgreSQL | OC and UT | Multi | Instant | ||
| CodeWorkout | [21] | MySQL | UT | C++, Java, Python, Ruby | Instant | ||
| Dante | [22] | Relational | OC | ✓ | C | Delayed | |
| Edgar | [23] | PostgreSQL, MongoDB | OC | ✓ | Multi | Instant | |
| Enki (Mooshak) | [3] | OC | Multi | Instant | |||
| JACK | [1,4] | Relational | OC | ✓ | ✓ | Multi | Instant and Delayed |
| Jutge.org | [5] | OC | ✓ | Multi | Instant | ||
| Kattis | [6] | PostgreSQL, File system | OC | ✓ | Multi | Instant | |
| Moodle+VPL+ CodeRunner | [15,16] | Any relational | OC | ✓ in VPL | Multi | Instant | |
| neoESPA | [7] | File system | OC | ✓ | C/C++, Java, Python | Instant | |
| PASS | [8] | OC | ✓ | ✓ | C/C++, Java | Instant | |
| Submitty | [9] | PostgreSQL | OC and UT | ✓ | Multi | Instant | |
| TestMyCode | [10] | Relational | UT | ✓ | Multi | Instant | |
| Testovid within Protus | [11] | UT | ✓ | Multi | Instant and delayed | ||
| URI Online Judge | [12] | Relational | OC | ✓ | Multi | ||
| Web-CAT | [14] | Relational | OC and UT | ✓ | ✓ | Multi |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mekterović, I.; Brkić, L.; Horvat, M. Scaling Automated Programming Assessment Systems. Electronics 2023, 12, 942. https://doi.org/10.3390/electronics12040942
Mekterović I, Brkić L, Horvat M. Scaling Automated Programming Assessment Systems. Electronics. 2023; 12(4):942. https://doi.org/10.3390/electronics12040942
Chicago/Turabian StyleMekterović, Igor, Ljiljana Brkić, and Marko Horvat. 2023. "Scaling Automated Programming Assessment Systems" Electronics 12, no. 4: 942. https://doi.org/10.3390/electronics12040942
APA StyleMekterović, I., Brkić, L., & Horvat, M. (2023). Scaling Automated Programming Assessment Systems. Electronics, 12(4), 942. https://doi.org/10.3390/electronics12040942