
Supervised Character Resemble Substitution Personality Adversarial Method



Abstract
:1. Introduction
- Effectiveness: The adversarial examples must be able to successfully attack the personality classifier so that the classifier can make incorrect judgments, but it will not affect human understanding;
- Readability: The adversarial examples are complete and fluent sentences without obvious grammatical errors;
- Semantic similarity: The adversarial examples should achieve semantic retention and be similar to the semantics of the original texts;
- Robustness: The adversarial examples need to be able to deal with defenses and maintain characteristics that can successfully attack the personality classifier.
- We propose a calculation method of “label contribution”. Since texts are discrete, it is difficult to directly generate adversarial examples by attacking the original examples. We use the FGSM in CV as the basic method. We determine the words that are most affected by the gradient by calculating the similarity between the adversarial examples and the original examples. It is considered that its label contribution is the highest. Perturbing the words using the highest possible label contribution, we consider the highest degree to which the antagonistic samples cause errors in the classifier’s judgments;
- We design a character-level resemble substitution to modify N words with high label contribution to ensure that human comprehension errors are minimized;
- We use the BERT multi-label classification model for verification. The results show that our adversarial examples are effective for personal privacy protection, and the readability of adversarial examples is relatively high.
2. Related Work
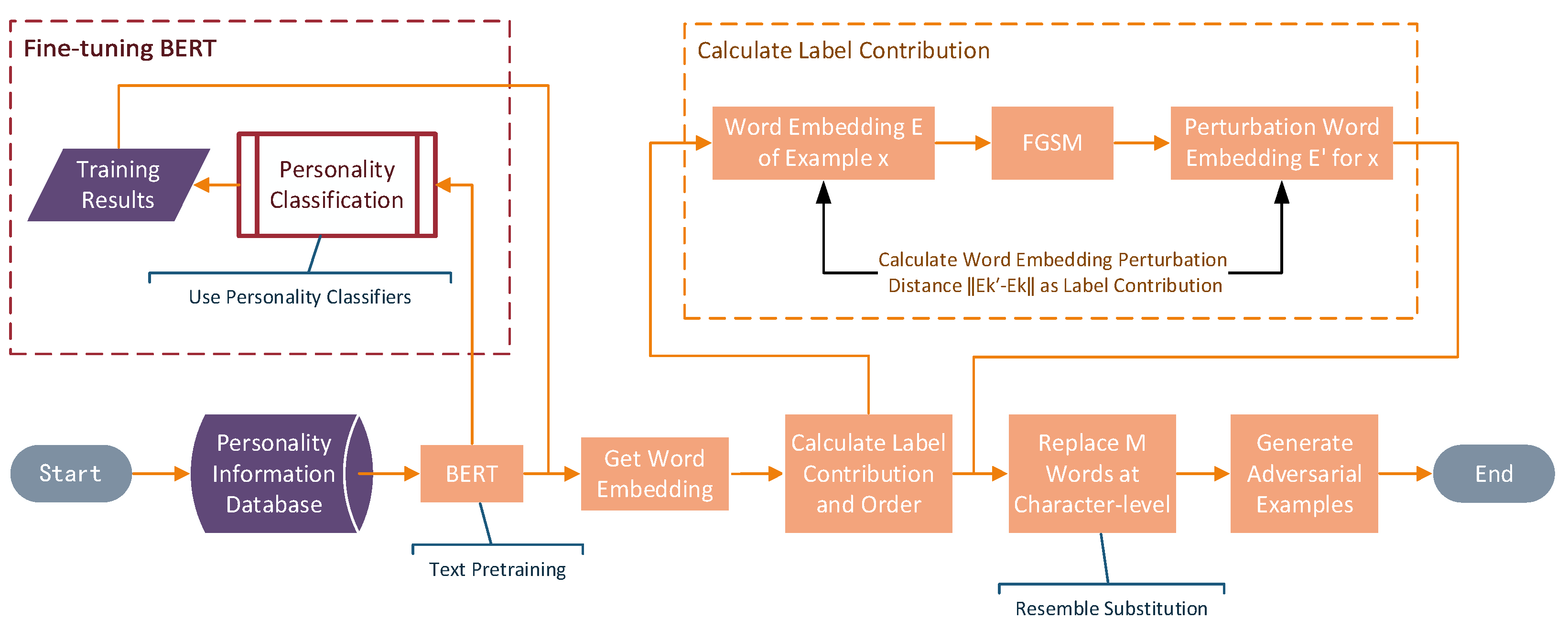
3. SCRS of Personality Adversarial Method
3.1. SCRS
3.2. Design Strategy
3.2.1. Label Contribution Calculation Strategy
3.2.2. Character-Level Resemble Substitution Strategy
3.2.3. Whole Process
| Algorithm 1. Algorithm for the SCRS method. |
| Input: examples , personality classifier , attack strength parameter of FGSM, word substitution dictionary T, replace word proportion θ |
| 1: |
| 2: |
| 3: for = 1… do |
| 4: |
| 5: |
| 6: |
| 7: for = 1… do |
| 8: = |
| 9: |
| 10: end for |
| 11: end for |
| 12: return |
4. Experiments
4.1. Datasets and Text Pre-Trained Models
4.2. Experimental Settings
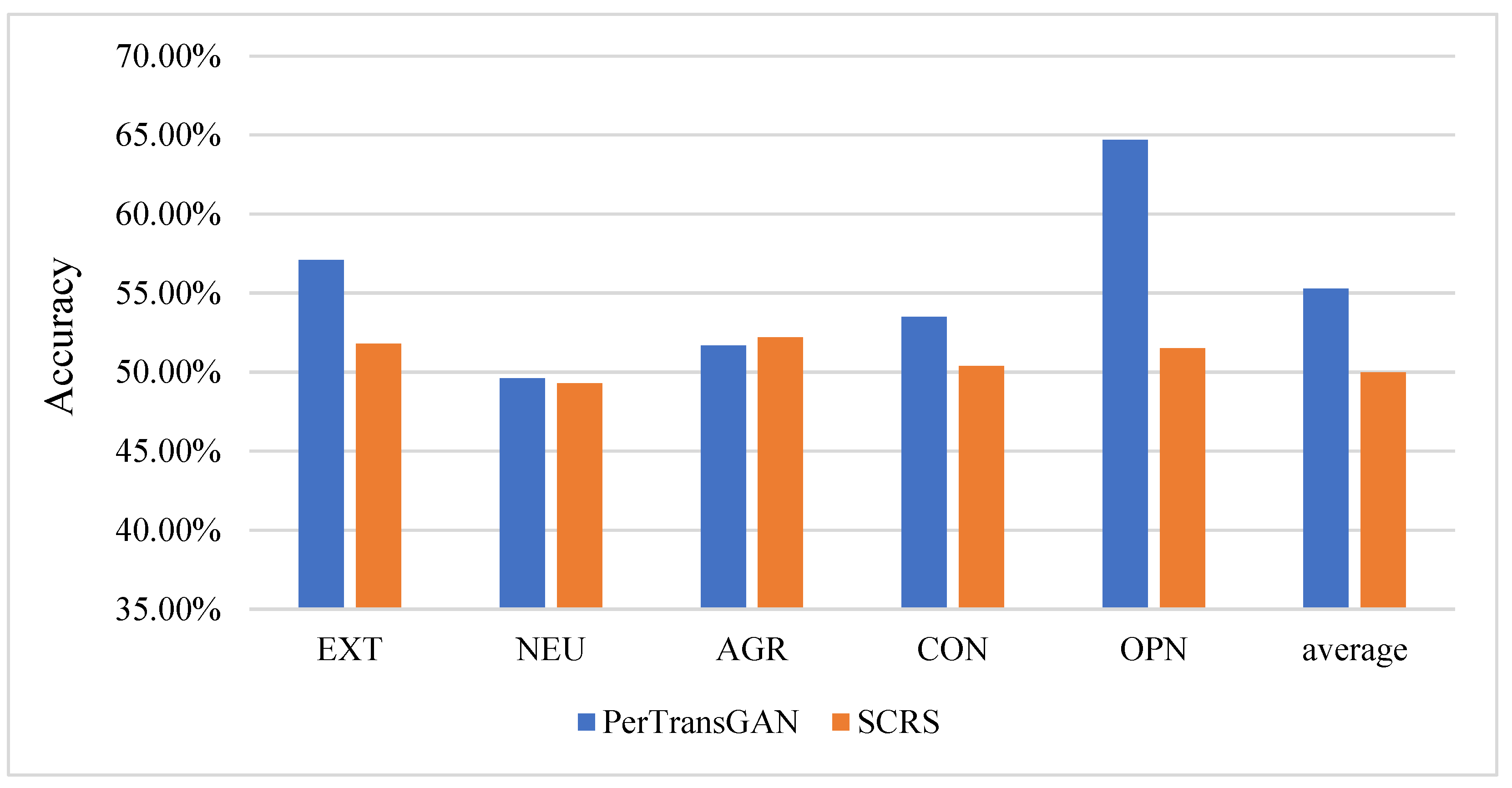
4.3. Adversarial Examples Results
4.4. Attack Effect Display
- (1)
- Experimental results
- (2)
- Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wegener, D.T.; Fabrigar, L.R.; Pek, J.; Hosington-Shaw, K.J. Evaluating Research in Personality and Social Psychology: Considerations of Statistical Power and Concerns about False Findings. Personal. Soc. Psychol. Bull. 2021, 48, 1105–1117. [Google Scholar] [CrossRef]
- Rastogi, R.; Chaturvedi, D.K.; Satya, S.; Arora, N.; Singh, A. Intelligent Personality Analysis on Indicators in IoT-MMBD-Enabled Environment. In Multimedia Big Data Computing for IoT Applications; Springer: Singapore, 2020; Volume 163, pp. 185–215. [Google Scholar]
- Alireza, S.; Shafigheh, H.; Masoud, R.A. Personality classification based on profiles of social networks’ users and the five-factor model of personality. Hum. Cent. Comput. Inf. Sci. 2018, 8, 24. [Google Scholar]
- Keh, S.S.; Cheng, I.T. Myers-Briggs Personality Classification and Personality-Specific Language Generation Using Pre-trained Language Models. arXiv 2019, arXiv:1907.06333. [Google Scholar]
- Sood, A.; Bhatia, R. Baron-Cohen Model Based Personality Classification Using Ensemble Learning. Data Sci. Big Data Anal. 2019, 16, 57–65. [Google Scholar]
- Zhang, W.E.; Sheng, Q.Z.; Alhazmi, A.; Li, C. Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–41. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, H.; Miao, N.; Li, L. Generating Fluent Adversarial Examples for Natural Languages. In Proceedings of the ACL, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wang, C.; Zeng, J.; Wu, C. Generating Fluent Chinese Adversarial Examples for Sentiment Classification. Proceedings of 14th International Conference on Anti-Counterfeiting, Security, and Identification (ASID), Xiamen, China, 30 October–1 November 2020. [Google Scholar]
- Samanta, S.; Mehta, S. Towards Crafting Text Adversarial Samples. arXiv 2017, arXiv:1707.02812. [Google Scholar]
- Samanta, S.; Mehta, S. Generating Adversarial Text Samples. In Proceedings of the European Conference on Information Retrieval (ECIR), Grenoble, France, 26–29 March 2018. [Google Scholar]
- Ebrahimi, J.; Rao, A.; Lowd, D.; Dou, D. HotFlip: White-Box Adversarial Examples for Text Classification. In Proceedings of the Association for Computational Linguistics (ACL), Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Ebrahimi, J.; Lowd, D.; Dou, D. On Adversarial Examples for Character-Level Neural Machine Translation. In Proceedings of the 27th International Conference on Computational Linguistics (COLING), Santa Fe, NM, USA, 20–26 August 2018. [Google Scholar]
- Gao, J.; Lanchantin, J.; Soffa, M.L.; Qi, Y. Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018. [Google Scholar]
- Jin, D.; Jin, Z.; Zhou, J.T.; Szolovits, P. Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Liang, B.; Li, H.; Su, M.; Bian, P.; Li, X.; Shi, W. Deep Text Classification Can be Fooled. In Proceedings of the International Joint Conferences on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Cheng, Y.; Jiang, L.; Macherey, W. Robust Neural Machine Translation with Doubly Adversarial Inputs. In Proceedings of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P.D. Adversarial Examples for Malware Detection. In Proceedings of the European Symposium on Research in Computer Security (ESORICS), Oslo, Norway, 11–15 September 2017. [Google Scholar]
- Blohm, M.; Jagfeld, G.; Sood, E.; Yu, X.; Vu, N.T. Comparing Attention-Based Convolutional and Recurrent Neural Networks: Success and Limitations in Machine Reading Comprehension. In Proceedings of the Conference on Computational Natural Language Learning (CoNLL), Brussels, Belgium, 31 October–1 November 2018. [Google Scholar]
- Siino, M.; Di Nuovo, E.; Tinnirello, I.; La Cascia, M. Fake News Spreaders Detection: Sometimes Attention Is Not All You Need. Information 2022, 13, 426. [Google Scholar] [CrossRef]
- Siino, M.; Cascia, M.; Tinnirello, I. McRock at SemEval-2022 Task 4: Patronizing and Condescending Language Detection using Multi-Channel CNN, Hybrid LSTM, DistilBERT and XLNet. In Proceedings of the 16th International Workshop on Semantic Evaluation, Seattle, WA, USA, 14–15 July 2022. [Google Scholar]
- Bevendorff, J.; Chulvi, B.; Fersini, E.; Heini, A.; Kestemont, M.; Kredens, K.; Mayerl, M.; Ortega-Bueno, R.; Pezik, P.; Potthast, M.; et al. Overview of PAN 2022: Authorship Verification, Profiling Irony and Stereotype Spreaders, and Style Change Detection. In Experimental IR Meets Multilinguality, Multimodality, and Interaction, Proceedings of the Thirteenth International Conference of the CLEF Association (CLEF 2022), Bologna, Italy, 5–8 September 2022; Barron-Cedeno, A., Martino, G.D.S., Esposti, M.D., Sebastiani, F., Macdonald, C., Pasi, G., Hanbury, A., Potthast, M., Faggioli, G., Ferro, N., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13390, p. 13390. [Google Scholar]
- Marco, S.; Ilenia, T.; Marco, L.C. T100: A modern classic ensemble to profile irony and stereotype spreaders. In Proceedings of the CLEF 2022 Labs and Workshops, Bologna, Italy, 5–8 September 2022. [Google Scholar]
- Wentao, Y.; Benedikt, B.; Dorothea, K. BERT-based ironic authors profiling. In Proceedings of the CLEF 2022 Labs and Workshops, Bologna, Italy, 5–8 September 2022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N. Attention is all you need. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Red Hook, NY, USA, 4–9 December 2017. [Google Scholar]
- Sui, Y.; Wang, X.; Zheng, K.; Shi, Y.; Cao, S. Personality Privacy Protection Method of Social Users Based on Generative Adversarial Networks. Comput. Intell. Neurosci. 2022, 2022, 13. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
| Original Character | Substitution Characters |
|---|---|
| a | α |
| c | < |
| z | 2 |
| x | × |
| o | 0 |
| l | 1 |
| r | γ |
| p | ρ |
| Replace 10% of the total sentence length with words |
| He likes the sound of thunder. |
| He likes the 5ound of thunder. |
| Replace 20% of the total sentence length with words |
| She is on her way up north to face her judgment. |
| She is on her wαy up north t0 fαce her judgment |
| Replace 30% of the total sentence length with words |
| He is about to lose his mind on account of the Dodgers right now. |
| He is about to lose hi5 mind 0n account of the D0dgers right n0w. |
| Replace 40% of the total sentence length with words |
| Dolphins can see the future with perfect clarity, that is why they are always screaming! |
| Dolphins <an see the futuγe with perfect clarity, thαt i5 why they αre αlways screaming! |
| Replace 50% of the total sentence length with words |
| He kind of likes getting up early and getting more done in my morning than I would otherwise. |
| He kind 0f 1ikes getting uρ eαrly αnd getting m0re done in my m0rning thαn I w0uld otheγwise. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Cao, S.; Zheng, K.; Guo, X.; Shi, Y. Supervised Character Resemble Substitution Personality Adversarial Method. Electronics 2023, 12, 869. https://doi.org/10.3390/electronics12040869
Wang X, Cao S, Zheng K, Guo X, Shi Y. Supervised Character Resemble Substitution Personality Adversarial Method. Electronics. 2023; 12(4):869. https://doi.org/10.3390/electronics12040869
Chicago/Turabian StyleWang, Xiujuan, Siwei Cao, Kangfeng Zheng, Xu Guo, and Yutong Shi. 2023. "Supervised Character Resemble Substitution Personality Adversarial Method" Electronics 12, no. 4: 869. https://doi.org/10.3390/electronics12040869
APA StyleWang, X., Cao, S., Zheng, K., Guo, X., & Shi, Y. (2023). Supervised Character Resemble Substitution Personality Adversarial Method. Electronics, 12(4), 869. https://doi.org/10.3390/electronics12040869