3.1. Body Representation
We present an adaptive point set representation that uses the center point together with several human-part related points to represent the human instance. The proposed representation introduces the adaptive human-part related points, whose features are used to encode the per-part information, thus can sufficiently capture the structural pose information. Meanwhile, they serve as the intermediate nodes to effectively model the relationship between the human instance and keypoints. In contrast to the fixed hierarchical representation in SPM [
33], The adaptive part related points are predicted by center feature dynamically and not pre-defined locations, thus avoid the accumulated error propagated along the fixed hierarchical path. Furthermore, instead of using the root feature to encode all keypoints, the features of adaptive points are also leveraged to encode keypoints of different parts respectively in our method.
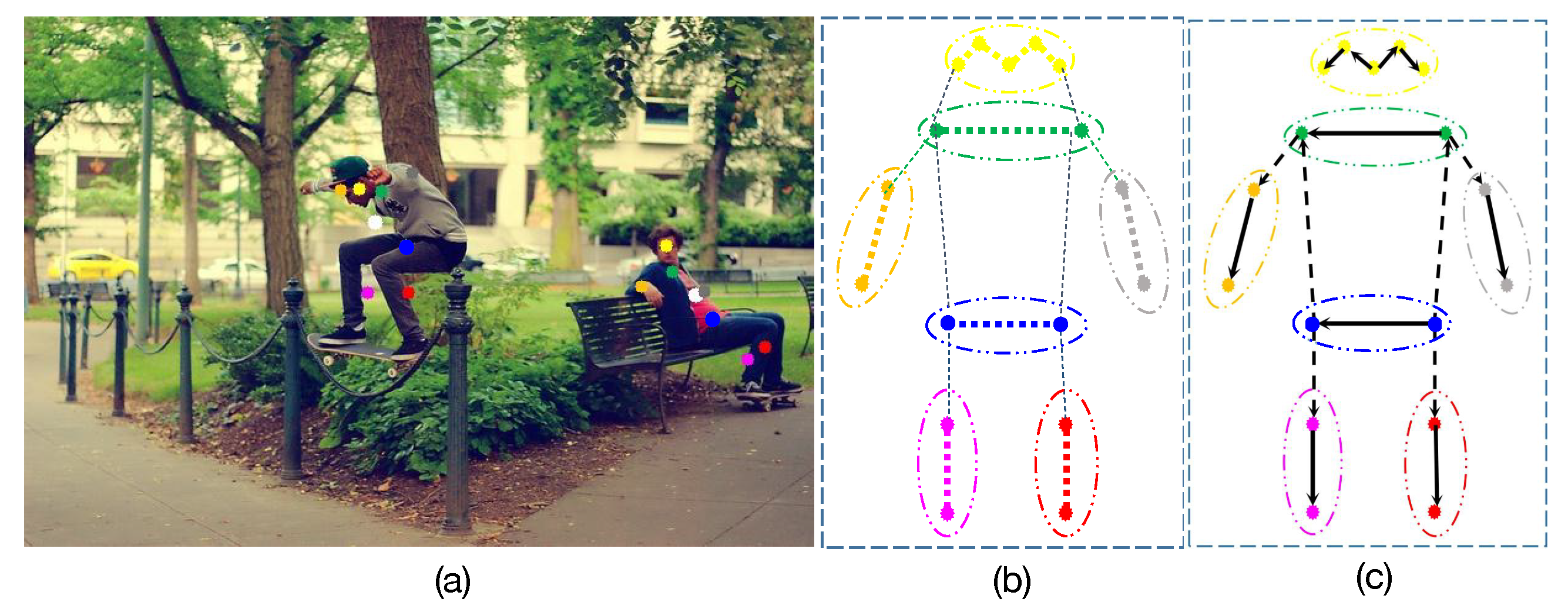
Our body representation is built upon the pixel-wise keypoint regression framework, which estimates the candidate pose at each pixel. For a human instance, we manually divide the human body into seven parts (i.e., head, shoulder, left arm, right arm, hip, left leg and right leg) according to the inherent structure of human body, as shown in
Figure 3b. Each divided human part is a rigid structure; we represent it via an adaptive human-part related point, which is dynamically regressed from the human center. The process can be formulated as:
where
refers to the instance center, others indicate seven adaptive human-part related points corresponding to head, shoulder, left arm, right arm, hip, left leg and right leg. Human pose is finely-grained represented by a point set
. By introducing the adaptive human-part related points, the semantic and position information of different keypoints can be encoded by the specific human-part related point’s feature, instead of only using the limited center feature to encode all keypoints’ information. For convenience,
is used to indicate the seven human-part related points
. Then, the feature on each human-part related point is responsible for regressing the keypoints belonging to corresponding parts as follows:
The novel representation starts from the human center to the adaptive human-part related points, then to body keypoints, to build up the connection between the instance position and corresponding keypoint position in a single-forward pass without any non-differentiable process.
Based on the proposed representation, we delivered a single-stage differentiable solution to estimate multi-person pose. Concretely, the Part Perception Module was proposed to predict seven human-part related points. By using the adaptive human-part related points, the Enhanced Center-aware Branch was introduced to perceive the center of human with various deformation and scales. In parallel, the Two-hop Regression Branch is presented to regress keypoints via the adaptive part-related points.
3.2. Single-Stage Network
Overall Architecture. As shown in
Figure 4, given an input image, we first extracted the semantic feature via the backbone, following three well-designed components to predict specific information. We leveraged the Part Perception Module to regress seven adaptive human-part related points from the assumed center for each human instance. Then, we conducted the receptive field adaptation in the Enhanced Center-aware Branch by aggregating the features of the adaptive points to predict the center heatmap. In addition, the Two-hop Regression Branch adopts the adaptive human-part related points as one-hop nodes to indirectly regress the offsets from the center to each keypoint. Our network followed the pixel-wise keypoint regression paradigm, which estimates the candidate pose at each pixel (called center pixel) by predicting an 2K-dimensional offset vector from the center pixel to the K keypoints. We only take a pixel position as an example to describe the single-stage network.
Part Perception Module. With the proposed body representation, we artificially divided each human instance into seven local parts (i.e., head, shoulder, left arm, right arm, hip, left leg, right leg) according to the inherent structure of the human body. The Part Perception Module is proposed to perceive the human parts by predicting seven adaptive human-part related points. For each part, we automatically regressed an adaptive point from center pixel
c without explicit supervision. Each adaptive part related point was considered as encoding the informative features for the keypoints belonging to this part. As shown in
Figure 5, we fed the regression branch specific feature
into the 3×3 convolutional layer to regress 14-channel x-y offsets
from the center
c to seven adaptive human-part related points on each pixel. These adaptive points acted as intermediate nodes, which were used for subsequent center positioning and keypoint regression.
Enhanced Center-aware Branch. In previous works [
32,
33,
46], the center of human instances with various scales and deformation were predicted via the features with a fixed receptive field for each position. However, the pixel position which predicts the center of larger human body ought to have a larger receptive field compared with the position for predicting the center of a smaller human body. Thus, we propose a novel Enhanced Center-aware Branch which consists of a receptive field adaptation process to extract and aggregate the features of seven adaptive human-part related points for precise center localization.
As shown in
Figure 5, we used the structure of 3 × 3 conv-relu to generate the branch-specific features. In Enhanced Center-aware Branch,
is a branch-specific feature with the fixed receptive field for each pixel position. We firstly used the 1 × 1 convolution to compress the 256-channel feature
and obtain the 64-channel feature
. Then, we extracted the feature vectors of the adaptive points via bilinear interpolation (named ’Warp’ in
Figure 5) on
. Taking the head part as an example, the bilinear interpolation can be formulated as
, where
c indicates the center pixel and
is offset from center to adaptive points of head part. The extracted features {
,
,
,
,
,
,
} correspond to seven divided human parts (i.e., head, shoulder, left arm, right arm, hip, left leg, right leg). We concatenated them with
along the channel dimension to generate the feature
. Since the predicted adaptive points located on the seven divided parts are relatively evenly distributed on the human body region, the process above can be regarded as the receptive field adaptation according to the human scale, as well as capture the various pose information sufficiently. Finally, we used
with an adaptive receptive field to predict the 1-channel probability map for the center localization.
We used the normalized Gaussian kernel
with mean
and adaptive variance
calculated by human scale to generate the ground-truth center heatmap. Concretely, we calculated the Gaussian kernel radius by the size of an object by ensuring that a pair of points within the radius would generate a bounding box with at least IoU 0.7 with the ground-truth annotation. The adaptive variance is 1/3 of the radius. For the loss function of the Enhanced Center-aware Branch, we employed the pixel-wise focal loss in a penalty-reduced manner as follows:
where
N refers to the number of positive sample,
and
indicate the predicted per-pixel confidence and corresponding ground truth.
and
are hyper-parameters and set to 2 and 4, following CenterNet [
32] and CornerNet [
42]. In the above loss, only center pixels with peak 1.0 are positive samples and all others are negative samples.
Two-hop Regression Branch. We leveraged a two-hop regression method to predict the displacements instead of directly regressing the center-to-joint offsets. In this manner, the adaptive human-part related points predicted by Part Perception Module act as one-hop nodes to build up the connection between human instance and keypoints more effectively.
We firstly leveraged the structure of 3 × 3 conv-relu to generate a branch-specific feature, named
, in the Two-hop Regression Branch. Then, we fed 256-channel
into the deformable convolutional layer [
47,
48] to generate 64-channel feature
. Then we extracted the features at the adaptive part related points via the bilinear interpolation operation (called ’Warp’ in
Figure 5) on
for corresponding keypoint regression. We denoted the extracted features as {
,
,
,
,
,
,
}, corresponding to seven divided parts (i.e., head, shoulder, left arm, right arm, hip, left leg and right leg). For the extracted feature
, the above process can be formulated as
These features encode the keypoint information of different human parts respectively, instead of using center features to regress all keypoints. Afterward, the extracted features were responsible for locating the keypoints belonging to the corresponding part by regressing the offsets from adaptive part related point to specific keypoints
via different 1 × 1 convolutional layers. For example,
was used to localize the eyes, ears and nose,
was used to localize the left wrist and left elbow,
was used to localize the left knee and left ankle.
The Two-hop Regression Branch outputs a 34-channel tensor corresponding to x-y offsets
from the center to 17 keypoints, which is predicted by the two-hop manner as follows:
where
and
respectively indicate the offset from the center to adaptive human-part related point (One-hop offset mentioned in
Figure 5) and the offset from human-part related point to specific keypoints (second-hop offset mentioned in
Figure 5). The predicted offsets
are supervised by vanilla L1 loss and the supervision only acts at positive keypoint locations; the other background locations are ignored. Furthermore, we added an additional loss term to learn the rigid bone connection between adjacent keypoints, termed Skeleton-Aware Regression Loss. In particular, as shown in
Figure 3c, we denoted a bone connection set as
, where
I is the number of bone connections in pre-defined set
. Each bone is formulated as
, in which
is the joint position and the function
return the adjacent joints for input joint. The total regression loss is formulated as follows:
where
and
are the ground truth center-to-keypoint offset and bone connection.
N indicates the number of human instances.
K is the number of valid keypoint locations. We find that employing the supervision on the bone connections can bring 0.3 AP improvements on CrowdPose [
34].












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}