
ARMOR: Differential Model Distribution for Adversarially Robust Federated Learning

Abstract
:1. Introduction
- Differential Model Robustness: To the best of our knowledge, we are the first to formalize the notion of differential model robustness (DMR) under the FL context. Roughly speaking, the goal of DMR is to attain the same level of utility while keeping the client models as different as possible against adversarial attacks.
- Differential Model Distribution: We explore how can DMR be realized in concrete FL protocols based on neural networks (NNs). Specifically, we develop the differential model distribution technique, which distributes different NN models using differential adversarial training.
- Thorough Experiments and Ablation Studies: We provided detailed ablation studies and thorough experiments to study the utility and robustness of client models in our ARMOR framework. Through experiments, we show that, by carefully designing the DMD, the ASR and AATR can be reduced by as much as 85% and 80% respectively, at an accuracy cost of only 8% over the MNIST dataset for a 35-client FL system.
2. Background
2.1. Notation
2.2. Federated Learning
| Algorithm 1: Federated Averaging. |
 |
| Algorithm 2:. |
 |
2.3. Adversarial Attack
2.4. Adversarial Training
3. Related Works
3.1. Federated Adversarial Training
3.2. Byzantine-Robust Federated Learning
3.3. Research Gaps and Our Goal
4. Methodology
4.1. Definition
4.2. Threat Model
- To access the local training data of the compromised client, but have no knowledge of the private training datasets of other benign clients.
- To launch white-box attacks at its will, as any client participating in the training process of FL has direct access to its own local model parameters and the global model parameters.
4.3. Intuitions and Framework Overview
- Targeted Problem: As described in Section 4.2, we consider adversarial attacks launched by Byzantine clients inside the FL systems. A Byzantine client has direct access to the global model and can construct effective adversarial samples efficiently. In traditional FL protocols, the server distributes the same global model to each client. Consequently, adversarial samples constructed by the Byzantine client can easily attack all of other benign clients. We aim at preventing such Byzantine adversarial attacks from generalizing inside the FL system.
- General Solution: Our main insight is that model differentiation can reduce the transferability of adversarial samples among clients in FL systems. However, if we conduct trivial model differentiation, such as adding noise in the way similar to differential privacy, a satisfactory level of differential model robustness will be accompanied by high levels of utility deteriorations. We manage to attain the same level of utility over normal inputs while keeping the client models as different as possible against adversarial inputs. We discover that combining with suitable differentiating operations, adversarial training can be useful to produce differentially robust models.
- Intuition: In traditional FL systems, there is only one aggregated model known as global model (or federated model). If we develop our differential client models from the same global model, the differentiation can be too weak to powerful Byzantine clients. We try to find out how to decide the directions in which we differentiate the global model.
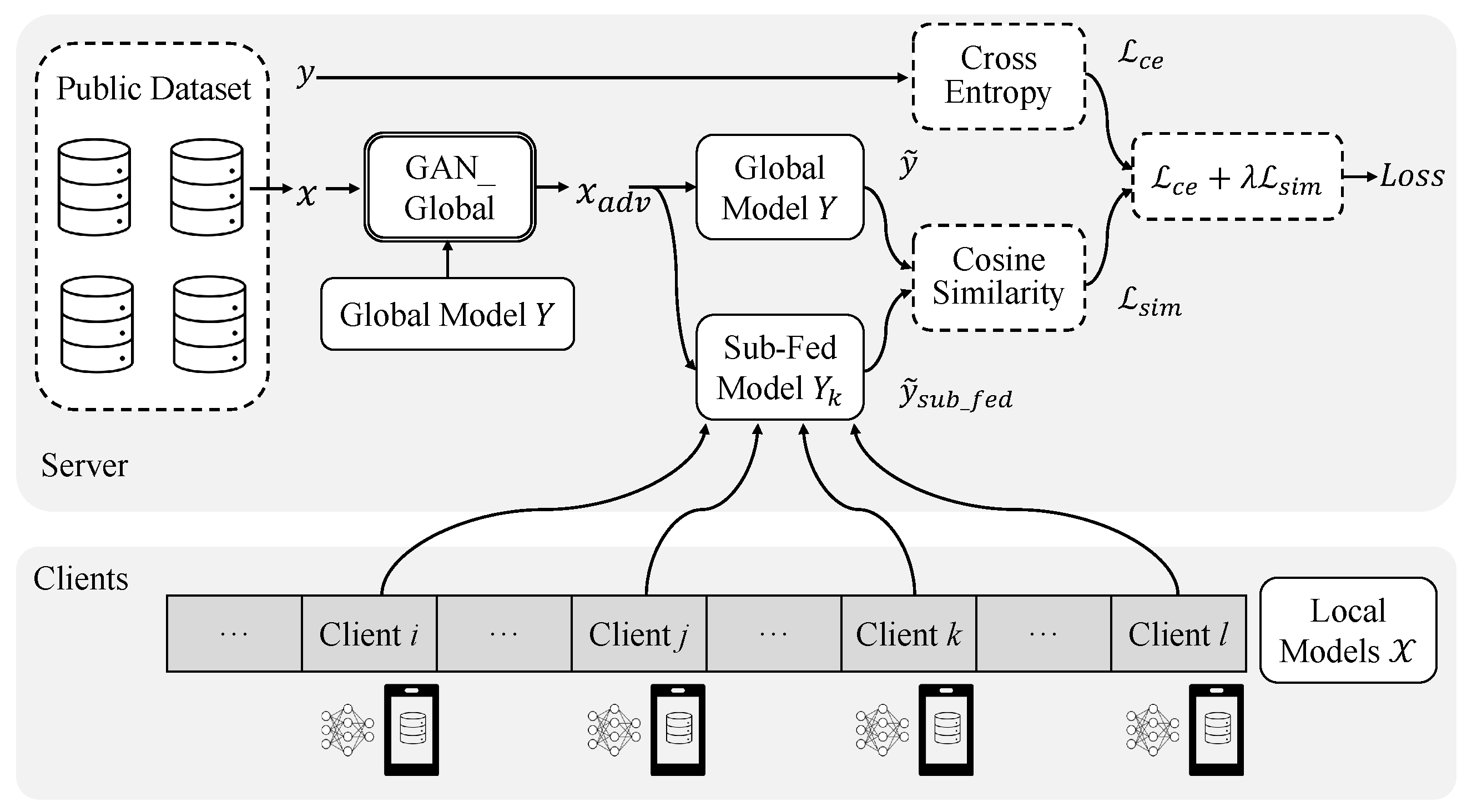
- Solution: The last round of aggregation is shown in Algorithm 3. From Line 12 to 15, after getting all client model updates, for each client, the server randomly aggregates a set of client models into a sub-federated model. System manager can decide the number of clients included in one sub-federated model by adjusting the proportion parameter to achieve satisfactory model utility. That is, for a total of K clients, the server will generate K different sub-federated models for preparation of directing and regulating the subsequent differential adversary training phase.
| Algorithm 3: Differential Model Distribution. |
 |
- Intuition: In centralized adversary training, the server generates adversarial samples through adversarial attack methods such as FGSM attack [22] or PGD attack [25]. If we simply follow the same paradigm and utilize the whole public dataset to train the global model, we will come back to the problem of Byzantine clients again. As pointed out in Section 3.3, it is dangerous for all clients to hold the same global model in the model deployment phase. We need to generate different adversarial samples for each client.
- Solution: As shown in Algorithm 3, from Line 17 to 21, after aggregating client models in the last round into a final global model, the server further generates adversarial samples based on the final global model. For each client, the server chooses a different set of samples from its public dataset, and uses different randomness to generate adversarial samples from the chosen sample set. That is, for a total of K clients, the server will generate K different sets of adversarial samples.
- Intuition: Now, we need to find an efficient way to conduct the differentiation while retaining the model accuracy. We are faced with two challenges. First, how to decide the metric of model distance (or model similarity)? A suitable metric is extremely important as it will directly influence our differential adversary training directions. Second, how to quantitatively produce different levels of differentiation? As model utility and DMR is a trade-off, a higher level of differentiation will lead to stronger DMR but weaker model utility. We should be able to adjust the level of differentiation to achieve a balance between utility and DMR.
- Solution: Utilizing Phase 1 and Phase 2, the server allocates each client a sub-federated model and a set of adversarial samples. When conducting differential adversarial training, we choose cosine similarity as the criterion to measure model distance. We use the cosine similarity between the output vectors of global model and sub-federated model to construct a similarity loss. We combine the similarity loss with the regular cross-entropy loss during adversarial training to accomplish our goal of differentiation.
4.4. Key Algorithms In ARMOR
- Sub-Federated Model Based Model Differentiation: At the last round of aggregation, the server gets the set of all local models from K clients, and aggregate these local models into a global federated model (With some abuse of notations, we use to denote the server’s operation of aggregating several local models with model parameter to generate the global model Y with model parameter w, i.e., . In this work, we have .). For each client k, the server randomly chooses local models from the set to form a subset , and aggregate the local models in into a sub-federated model . We denote the set of all sub-federated models by .
- Adversarial Samples Based Model Differentiation: In ARMOR, the server generates K different sets of adversarial samples based on the global model. For each client k, the server chooses a set of samples from its public training dataset , and adopts PGD method [25] to generate a set of adversarial samples in preparation for adversarial training. In this step, each adversarial dataset for contains a different flavor of robustness, which will be introduced to the global model in the following adversarial training phase.
- Differential Adversary Training: Combining the above two steps, the server associates each Client k with a sub-federated model and a set of different adversarial samples . Figure 2 illustrates the detailed relationships between models and losses in our training process. The server executes in Algorithm 3 to make each client find its way from Y towards the direction between and the robustness introduced by . Next, for , our goal is to produce differentiated model based on the global model Y (we note that directly using as the k-th client model results in degraded accuracy performance). Here, we choose the cosine distance as the criterion to measure the similarity between the global model and the sub-federated models. Given input samples , we compute the cosine embedding loss of the output of global model Y and the corresponding sub-federated model . Let Y and be the model functions whose outputs are the probability vectors over the class labels. We define the similarity loss for sample aswhere · is the inner product between vectors, depicts the -norm of a vector, and × denotes integer multiplication. When measuring similarity, we define the target labels for the cosine similarity loss, where each follows the Bernoulli distribution where . Then, we use T to select a portion of p samples with label 1 to participate in similarity measurement. Now, we have our total cosine similarity loss
4.5. Robustness Analysis
5. Experiment Results
5.1. Experiment Flow and Setup
- Physical Specifications: We conduct our experiments on Linux platform with NVIDIA A100 SXM4 with a GPU memory of 40GB. The platform is equipped with a driver of version 470.57.02 and CUDA of version 11.4.
- Datasets: We empirically evaluate the ARMOR framework on two datasets: MNIST [46] and CIFAR-10 [47]. To simulate the heterogeneous data distributions, we make non-i.i.d. partitions of the datasets, which is a similar partition method as [21].
- (1)
- Non-IID MNIST: The MNIST dataset contains 60,000 training images and 10,000 testing images of 10 classes. Each sample is a size gray-level image of a handwritten digit. We first sort the training dataset by digit label, divide it into shards of size , and assign each client 3 shards.
- (2)
- Non-IID CIFAR-10: The CIFAR-10 dataset contains 50,000 training images and 10,000 test images of 10 classes. Each sample is a size tiny color image. We first sort the training dataset by class label, divide it into shards of size , and assign each client 4 shards.
- Model: For the MNIST dataset, we use a CNN model with two convolution layers (the first with 4 channels, the second with 10 channels, each followed with max pooling), a fully connected layer with 100 units, an ReLu activation, and a final output layer. For the CIFAR-10 dataset, we use the VGG-16 model [48].
- Hyperparameters: For both datasets, we first train with the federated averaging algorithm. In each communication round, we let all clients to participate in the training (i.e., ), where the client model is trained by one epoch using the local datasets. On the server side, the model update from each client is weighted uniformly (since we assume that each client has the same number of training samples). For MNIST and CIFAR-10, we set the number of communication round R to 50 and 500, the learning rate to and , and the client batch size to 10 and 64, respectively.
5.2. Main Results
5.2.1. Results on MNIST
5.2.2. Results on CIFAR-10
5.3. Ablation Study
- First, the adversarial samples based model differentiation does have a positive influence on reducing ASR and AATR of benign clients. Nevertheless, the reduction is limited. However, when combined with the sub-federated model-based model differentiation, both ASR and AATR of benign clients are reduced significantly. For example, when , if we only apply based DMD, the AATR is reduced from 100% to 52.29%. If we further combine with , the AATR is further reduced to 23.17%, which demonstrates that the key in enhancing DMR is the combination of sub-federated model generation and differential adversarial training.
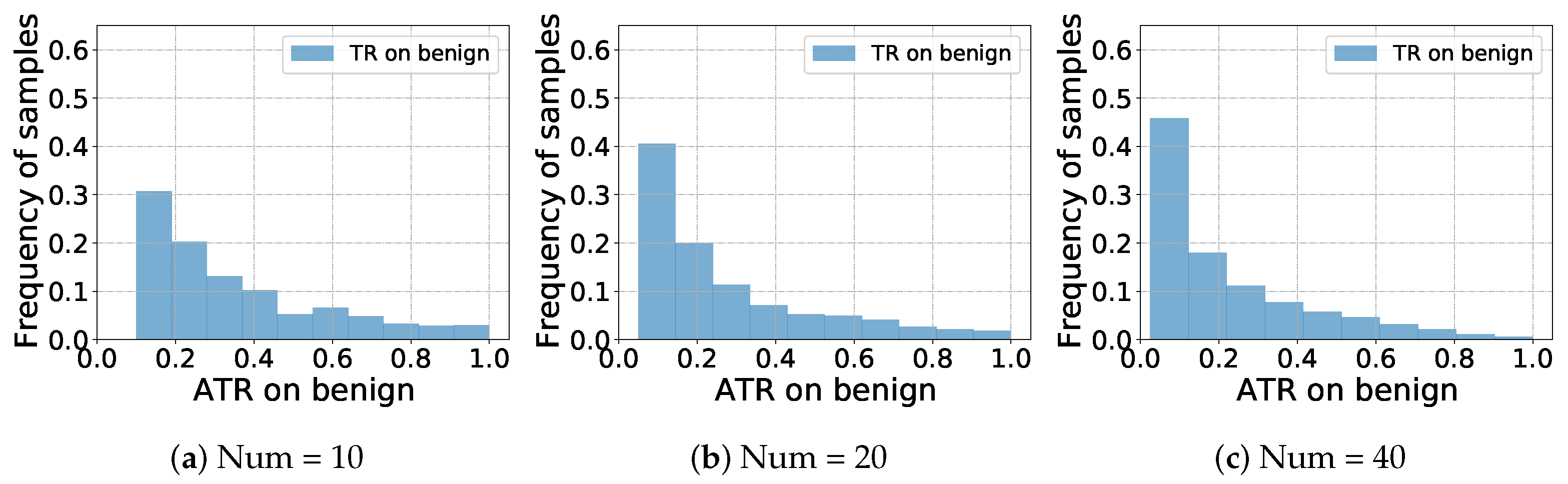
- Second, the DMR improvement increases as the client number K of FL increases. Table 4 illustrates that ASR and AATR decrease as K increases. For example, when applying , the AATR is 40.89% for 10 clients, 26.54% for 25 clients, and 23.17% for 50 clients. This is reasonable because as the client number increases, the diversity of sub-federated model is enlarged. As sub-federated models become more different from each other, the differentially distributed client models become more robust against attacks from the malicious client, resulting in additional DMR improvements.
- First, the DMR of FL client models is strengthened as the differentiation factor increases. We fix and , then set and , respectively. Similarly, we fix and , then set and , respectively. We find that for (resp., ), DMD with (resp., ) constantly leads to lower ASR and AATR than DMD with (resp., ), which validates the positive effect of the sub-federated model differentiation.
- Second, we observe that as the proportion of sub-federated model increases from , the overall accuracy of model also increases. However, as long as the sub-federated model is of enough utility, further increasing does not help much. We fix and , then set and , respectively. We find that slight change in does not lead to much differences in ASR and AATR. However, choosing only one single local model as the sub-federated model (i.e., ) leads to significant deterioration of performance.
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bonawitz, K.A.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečný, J.; Mazzocchi, S.; McMahan, B.; et al. Towards Federated Learning at Scale: System Design. In Proceedings of the Machine Learning and Systems 1 (MLSys 2019), Stanford, CA, USA, 31 March–2 April 2019. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Long, G.; Tan, Y.; Jiang, J.; Zhang, C. Federated Learning for Open Banking. In Federated Learning—Privacy and Incentive; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2020; Volume 12500, pp. 240–254. [Google Scholar]
- Guo, P.; Wang, P.; Zhou, J.; Jiang, S.; Patel, V.M. Multi-Institutional Collaborations for Improving Deep Learning-Based Magnetic Resonance Image Reconstruction Using Federated Learning. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) 2021, Nashville, TN, USA, 20–25 June 2021; pp. 2423–2432. [Google Scholar]
- Du, Z.; Wu, C.; Yoshinaga, T.; Yau, K.A.; Ji, Y.; Li, J. Federated Learning for Vehicular Internet of Things: Recent Advances and Open Issues. IEEE Open J. Comput. Soc. 2020, 1, 45–61. [Google Scholar] [CrossRef] [PubMed]
- Pokhrel, S.R.; Choi, J. Federated Learning With Blockchain for Autonomous Vehicles: Analysis and Design Challenges. IEEE Trans. Commun. 2020, 68, 4734–4746. [Google Scholar] [CrossRef]
- Li, Q.; He, B.; Song, D. Model-Contrastive Federated Learning. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) 2021, Nashville, TN, USA, 20–25 June 2021; pp. 10713–10722. [Google Scholar]
- Lai, F.; Zhu, X.; Madhyastha, H.V.; Chowdhury, M. Oort: Efficient Federated Learning via Guided Participant Selection. In Proceedings of the Operating Systems Design and Implementation (OSDI) 2021, Virtual, 14–16 July 2021; pp. 19–35. [Google Scholar]
- Zhang, C.; Li, S.; Xia, J.; Wang, W.; Yan, F.; Liu, Y. BatchCrypt: Efficient Homomorphic Encryption for Cross-Silo Federated Learning. In Proceedings of the USENIX Security 2020, San Diego, CA, USA, 12–14 August 2020; pp. 493–506. [Google Scholar]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.S.; Poor, H.V. Federated Learning With Differential Privacy: Algorithms and Performance Analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership Inference Attacks Against Machine Learning Models. In Proceedings of the SP 2017, San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning. In Proceedings of the SP 2019, San Francisco, CA, USA, 19–23 May 2019; pp. 739–753. [Google Scholar]
- Zhang, Y.; Jia, R.; Pei, H.; Wang, W.; Li, B.; Song, D. The Secret Revealer: Generative Model-Inversion Attacks Against Deep Neural Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) 2020, Seattle, WA, USA, 13–19 June 2020; pp. 250–258. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N.Z. Local Model Poisoning Attacks to Byzantine-Robust Federated Learning. In Proceedings of the USENIX Security 2020, San Diego, CA, USA, 12–14 August 2020; pp. 1605–1622. [Google Scholar]
- Shejwalkar, V.; Houmansadr, A. Manipulating the Byzantine: Optimizing Model Poisoning Attacks and Defenses for Federated Learning. In Proceedings of the Network and Distributed System Security Symposium (NDSS) 2021, Virtual, 21–25 February 2021. [Google Scholar]
- Kido, H.; Yanagisawa, Y.; Satoh, T. Protection of Location Privacy using Dummies for Location-based Services. In Proceedings of the International Conference on Data Engineering (ICDE) 2005, Tokyo, Japan, 3–4 April 2005; p. 1248. [Google Scholar]
- Blanchard, P.; Mhamdi, E.M.E.; Guerraoui, R.; Stainer, J. Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent. In Proceedings of the NeurIPS 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 119–129. [Google Scholar]
- Yin, D.; Chen, Y.; Ramchandran, K.; Bartlett, P.L. Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates. In Proceedings of the International Conference on Machine Learning (ICML) 2018, Stockholm, Sweden, 10–15 July 2018; pp. 5636–5645. [Google Scholar]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust aggregation for federated learning. IEEE Trans. Signal Process. 2022, 70, 1142–1154. [Google Scholar] [CrossRef]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How To Backdoor Federated Learning. In Proceedings of the AISTATS 2020, Palermo, Italy, 26–28 August 2020; Volume 108, pp. 2938–2948. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the AISTATS 2017, Fort Lauderdale, FL, USA, 20–22 April 2017; Volume 54, pp. 1273–1282. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations (ICLR) 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the International Conference on Learning Representations (ICLR) 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Ru, B.; Cobb, A.D.; Blaas, A.; Gal, Y. BayesOpt Adversarial Attack. In Proceedings of the International Conference on Learning Representations (ICLR) 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Miyato, T.; Dai, A.M.; Goodfellow, I.J. Adversarial Training Methods for Semi-Supervised Text Classification. In Proceedings of the International Conference on Learning Representations (ICLR) 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Shafahi, A.; Najibi, M.; Ghiasi, A.; Xu, Z.; Dickerson, J.P.; Studer, C.; Davis, L.S.; Taylor, G.; Goldstein, T. Adversarial training for free! In Proceedings of the NeurIPS 2019, Vancouver, CA, Canada, 8–14 December 2019; pp. 3353–3364. [Google Scholar]
- Zhang, D.; Zhang, T.; Lu, Y.; Zhu, Z.; Dong, B. You Only Propagate Once: Accelerating Adversarial Training via Maximal Principle. In Proceedings of the NeurIPS 2019, Vancouver, CA, Canada, 8–14 December 2019; pp. 227–238. [Google Scholar]
- Zhu, C.; Cheng, Y.; Gan, Z.; Sun, S.; Goldstein, T.; Liu, J. FreeLB: Enhanced Adversarial Training for Natural Language Understanding. In Proceedings of the International Conference on Learning Representations (ICLR) 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Zhao, T. SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization. In Proceedings of the ACL 2020, Virtual, 5–10 July 2020; pp. 2177–2190. [Google Scholar]
- Qin, C.; Martens, J.; Gowal, S.; Krishnan, D.; Dvijotham, K.; Fawzi, A.; De, S.; Stanforth, R.; Kohli, P. Adversarial Robustness through Local Linearization. In Proceedings of the NeurIPS 2019, Vancouver, CA, Canada, 8–14 December 2019; pp. 13824–13833. [Google Scholar]
- Zizzo, G.; Rawat, A.; Sinn, M.; Buesser, B. FAT: Federated Adversarial Training. arXiv 2020, arXiv:2012.01791. [Google Scholar]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S.B. Analyzing Federated Learning through an Adversarial Lens. In Proceedings of the ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 634–643. [Google Scholar]
- Li, L.; Xu, W.; Chen, T.; Giannakis, G.B.; Ling, Q. RSA: Byzantine-Robust Stochastic Aggregation Methods for Distributed Learning from Heterogeneous Datasets. In Proceedings of the AAAI 2019, Honolulu, HI, USA, 27 January–1 February 2019; pp. 1544–1551. [Google Scholar]
- Kerkouche, R.; Ács, G.; Castelluccia, C. Federated Learning in Adversarial Settings. arXiv 2020, arXiv:2010.07808. [Google Scholar]
- Fu, S.; Xie, C.; Li, B.; Chen, Q. Attack-Resistant Federated Learning with Residual-based Reweighting. arXiv 2019, arXiv:1912.11464. [Google Scholar]
- Chen, Y.; Su, L.; Xu, J. Distributed Statistical Machine Learning in Adversarial Settings: Byzantine Gradient Descent. Proc. ACM Meas. Anal. Comput. Syst. 2017, 1, 44:1–44:25. [Google Scholar] [CrossRef]
- Wang, H.; Sreenivasan, K.; Rajput, S.; Vishwakarma, H.; Agarwal, S.; Sohn, J.; Lee, K.; Papailiopoulos, D.S. Attack of the Tails: Yes, You Really Can Backdoor Federated Learning. In Proceedings of the NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Zhou, M.; Wu, J.; Liu, Y.; Liu, S.; Zhu, C. DaST: Data-Free Substitute Training for Adversarial Attacks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) 2020, Seattle, WA, USA, 13–19 June 2020; pp. 231–240. [Google Scholar]
- Wang, W.; Yin, B.; Yao, T.; Zhang, L.; Fu, Y.; Ding, S.; Li, J.; Huang, F.; Xue, X. Delving into Data: Effectively Substitute Training for Black-box Attack. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) 2021, Nashville, TN, USA, 20–25 June 2021; pp. 4761–4770. [Google Scholar]
- Ma, C.; Chen, L.; Yong, J. Simulating Unknown Target Models for Query-Efficient Black-Box Attacks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) 2021, Nashville, TN, USA, 20–25 June 2021; pp. 11835–11844. [Google Scholar]
- Li, X.; Li, J.; Chen, Y.; Ye, S.; He, Y.; Wang, S.; Su, H.; Xue, H. QAIR: Practical Query-Efficient Black-Box Attacks for Image Retrieval. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) 2021, Nashville, TN, USA, 20–25 June 2021; pp. 3330–3339. [Google Scholar]
- Fawzi, A.; Fawzi, H.; Fawzi, O. Adversarial vulnerability for any classifier. In Proceedings of the NeurIPS 2018, Montreal, QC, Canada, 3–8 December 2018; pp. 1186–1195. [Google Scholar]
- Tramèr, F.; Papernot, N.; Goodfellow, I.J.; Boneh, D.; McDaniel, P.D. The Space of Transferable Adversarial Examples. arXiv 2017, arXiv:1704.03453. [Google Scholar]
- Fawzi, A.; Fawzi, O.; Frossard, P. Analysis of classifiers’ robustness to adversarial perturbations. Mach. Learn. 2018, 107, 481–508. [Google Scholar] [CrossRef]
- LeCun, Y.; Cortes, C.; Burges, C.J.C. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 20 January 2022).
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR) 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wong, E.; Rice, L.; Kolter, J.Z. Fast is better than free: Revisiting adversarial training. In Proceedings of the International Conference on Learning Representations (ICLR) 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Client Num | DMD | Acc (%) | (%) | ASR (%) | AATR (%) |
|---|---|---|---|---|---|
| 10 | × | 98.33 | 98.33 | 100.00 | 100.00 |
| ✓ | 90.12 | 84.66 | 16.76 | 28.82 | |
| 15 | × | 98.33 | 98.33 | 100.00 | 100.00 |
| ✓ | 90.18 | 86.33 | 14.82 | 23.64 | |
| 20 | × | 98.38 | 98.38 | 100.00 | 100.00 |
| ✓ | 90.21 | 84.83 | 15.99 | 23.38 | |
| 25 | × | 98.38 | 98.38 | 100.00 | 100.00 |
| ✓ | 90.33 | 85.32 | 15.43 | 21.99 | |
| 30 | × | 97.95 | 97.95 | 100.00 | 100.00 |
| ✓ | 90.09 | 85.20 | 16.93 | 22.67 | |
| 35 | × | 98.38 | 98.38 | 100.00 | 100.00 |
| ✓ | 90.35 | 85.43 | 15.21 | 20.45 | |
| 40 | × | 98.38 | 98.38 | 100.00 | 100.00 |
| ✓ | 89.11 | 84.41 | 14.57 | 19.47 | |
| 45 | × | 98.38 | 98.38 | 100.00 | 100.00 |
| ✓ | 88.01 | 83.20 | 13.95 | 18.44 | |
| 50 | × | 98.38 | 98.38 | 100.00 | 100.00 |
| ✓ | 87.07 | 81.89 | 14.60 | 18.88 |
| K | DMD | Acc (%) | (%) | ASR (%) | AATR (%) |
|---|---|---|---|---|---|
| 10 | × | 73.27 | 73.27 | 100.00 | 100.00 |
| ✓ | 51.58 | 65.53 | 24.70 | 41.75 | |
| 15 | × | 74.48 | 74.48 | 100.00 | 100.00 |
| ✓ | 54.66 | 69.27 | 27.59 | 40.32 | |
| 20 | × | 73.53 | 73.53 | 100.00 | 100.00 |
| ✓ | 56.19 | 70.17 | 28.96 | 39.57 | |
| 25 | × | 71.71 | 71.71 | 100.00 | 100.00 |
| ✓ | 52.94 | 68.18 | 27.91 | 38.36 | |
| 30 | × | 70.61 | 70.61 | 100.00 | 100.00 |
| ✓ | 52.67 | 67.83 | 27.49 | 36.79 | |
| 35 | × | 72.28 | 72.28 | 100.00 | 100.00 |
| ✓ | 51.88 | 66.72 | 26.09 | 35.07 | |
| 40 | × | 72.27 | 72.27 | 100.00 | 100.00 |
| ✓ | 53.02 | 68.14 | 28.75 | 37.18 | |
| 45 | × | 70.21 | 70.21 | 100.00 | 100.00 |
| ✓ | 51.65 | 66.94 | 25.53 | 33.71 | |
| 50 | × | 70.07 | 70.07 | 100.00 | 100.00 |
| ✓ | 51.70 | 67.98 | 26.71 | 34.54 |
| K | DMD | Acc (%) | (%) | ASR (%) | AATR (%) |
|---|---|---|---|---|---|
| 10 | 95.82 | 95.17 | 49.06 | 56.04 | |
| 94.65 | 94.02 | 31.64 | 40.89 | ||
| 15 | 95.84 | 94.73 | 49.47 | 54.96 | |
| 93.83 | 92.61 | 24.57 | 32.27 | ||
| 20 | 95.68 | 95.18 | 50.50 | 54.93 | |
| 92.66 | 89.20 | 20.15 | 27.00 | ||
| 25 | 95.99 | 94.71 | 50.28 | 54.43 | |
| 91.20 | 88.35 | 20.38 | 26.54 | ||
| 30 | 95.69 | 94.87 | 50.27 | 54.05 | |
| 91.93 | 88.81 | 20.13 | 25.78 | ||
| 35 | 95.79 | 94.77 | 49.41 | 53.03 | |
| 91.85 | 87.94 | 18.60 | 23.95 | ||
| 40 | 95.62 | 94.52 | 48.49 | 52.08 | |
| 91.54 | 87.57 | 18.59 | 23.55 | ||
| 45 | 95.54 | 94.45 | 49.79 | 53.14 | |
| 91.87 | 87.94 | 20.21 | 24.95 | ||
| 50 | 95.56 | 94.82 | 49.10 | 52.29 | |
| 91.35 | 87.31 | 18.72 | 23.17 |
| K | p | Acc (%) | (%) | ASR (%) | AATR (%) | ||
|---|---|---|---|---|---|---|---|
| 10 | 500 | 0.25 | 0.10 | 94.65 | 94.02 | 31.64 | 40.89 |
| 600 | 0.25 | 0.10 | 88.13 | 84.54 | 15.29 | 27.66 | |
| 600 | 0.35 | 0.10 | 89.13 | 84.04 | 16.38 | 28.32 | |
| 300 | 0.25 | 0.20 | 92.49 | 90.63 | 21.67 | 32.30 | |
| 350 | 0.25 | 0.20 | 90.12 | 84.66 | 16.76 | 28.82 | |
| 15 | 500 | 0.25 | 0.10 | 93.83 | 92.61 | 24.57 | 32.27 |
| 600 | 0.25 | 0.10 | 90.18 | 86.33 | 14.82 | 23.64 | |
| 600 | 0.35 | 0.10 | 87.66 | 83.45 | 14.85 | 23.90 | |
| 300 | 0.25 | 0.20 | 91.75 | 88.09 | 17.25 | 25.97 | |
| 350 | 0.25 | 0.20 | 87.37 | 83.24 | 14.08 | 23.05 | |
| 20 | 500 | 0.25 | 0.10 | 92.66 | 89.20 | 20.15 | 27.00 |
| 600 | 0.25 | 0.10 | 90.86 | 85.59 | 17.06 | 24.50 | |
| 600 | 0.35 | 0.10 | 90.21 | 84.83 | 15.99 | 23.38 | |
| 300 | 0.25 | 0.20 | 92.78 | 89.24 | 19.43 | 26.34 | |
| 350 | 0.25 | 0.20 | 89.14 | 83.63 | 14.68 | 21.75 | |
| 25 | 500 | 0.25 | 0.10 | 91.20 | 88.35 | 20.38 | 26.54 |
| 600 | 0.25 | 0.10 | 86.85 | 82.71 | 14.82 | 21.16 | |
| 600 | 0.35 | 0.10 | 88.04 | 82.57 | 14.35 | 20.67 | |
| 300 | 0.25 | 0.20 | 90.33 | 85.32 | 15.43 | 21.99 | |
| 350 | 0.25 | 0.20 | 87.98 | 82.82 | 14.02 | 20.57 | |
| 30 | 500 | 0.25 | 0.10 | 91.93 | 88.81 | 20.13 | 25.78 |
| 600 | 0.25 | 0.10 | 88.53 | 82.72 | 14.12 | 19.98 | |
| 600 | 0.35 | 0.10 | 87.89 | 82.41 | 15.97 | 21.80 | |
| 300 | 0.25 | 0.20 | 90.09 | 85.20 | 16.93 | 22.67 | |
| 350 | 0.25 | 0.20 | 89.26 | 83.52 | 13.59 | 19.43 | |
| 35 | 500 | 0.25 | 0.10 | 91.85 | 87.94 | 18.60 | 23.95 |
| 600 | 0.25 | 0.10 | 89.06 | 84.06 | 15.74 | 21.04 | |
| 600 | 0.35 | 0.10 | 88.58 | 84.02 | 16.48 | 21.62 | |
| 300 | 0.25 | 0.20 | 90.10 | 85.44 | 16.71 | 21.94 | |
| 350 | 0.25 | 0.20 | 90.35 | 85.43 | 15.21 | 20.45 | |
| 40 | 500 | 0.25 | 0.10 | 91.54 | 87.57 | 18.59 | 23.55 |
| 600 | 0.25 | 0.10 | 89.11 | 84.41 | 14.57 | 19.47 | |
| 600 | 0.35 | 0.10 | 87.65 | 82.68 | 14.92 | 20.05 | |
| 300 | 0.25 | 0.20 | 89.56 | 85.08 | 17.60 | 22.63 | |
| 350 | 0.25 | 0.20 | 87.06 | 81.11 | 14.34 | 19.37 | |
| 45 | 500 | 0.25 | 0.10 | 91.87 | 87.94 | 20.21 | 24.95 |
| 600 | 0.25 | 0.10 | 88.01 | 83.20 | 13.95 | 18.44 | |
| 600 | 0.35 | 0.10 | 87.57 | 83.01 | 15.13 | 19.72 | |
| 300 | 0.25 | 0.20 | 89.07 | 84.32 | 15.42 | 19.99 | |
| 350 | 0.25 | 0.20 | 87.15 | 82.24 | 14.01 | 18.70 | |
| 50 | 500 | 0.25 | 0.10 | 91.35 | 87.31 | 18.72 | 23.17 |
| 600 | 0.25 | 0.10 | 88.13 | 83.22 | 16.02 | 20.52 | |
| 600 | 0.35 | 0.10 | 88.69 | 83.47 | 15.46 | 19.91 | |
| 300 | 0.25 | 0.20 | 89.26 | 84.44 | 16.51 | 20.84 | |
| 350 | 0.25 | 0.20 | 87.07 | 81.89 | 14.60 | 18.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Liu, J.; Guan, Z.; Zhao, B.; Leng, X.; Bian, S. ARMOR: Differential Model Distribution for Adversarially Robust Federated Learning. Electronics 2023, 12, 842. https://doi.org/10.3390/electronics12040842
Zhang Y, Liu J, Guan Z, Zhao B, Leng X, Bian S. ARMOR: Differential Model Distribution for Adversarially Robust Federated Learning. Electronics. 2023; 12(4):842. https://doi.org/10.3390/electronics12040842
Chicago/Turabian StyleZhang, Yanting, Jianwei Liu, Zhenyu Guan, Bihe Zhao, Xianglun Leng, and Song Bian. 2023. "ARMOR: Differential Model Distribution for Adversarially Robust Federated Learning" Electronics 12, no. 4: 842. https://doi.org/10.3390/electronics12040842
APA StyleZhang, Y., Liu, J., Guan, Z., Zhao, B., Leng, X., & Bian, S. (2023). ARMOR: Differential Model Distribution for Adversarially Robust Federated Learning. Electronics, 12(4), 842. https://doi.org/10.3390/electronics12040842