

A Hybrid GPU and CPU Parallel Computing Method to Accelerate Millimeter-Wave Imaging

Abstract
:1. Introduction
2. Acceleration Method
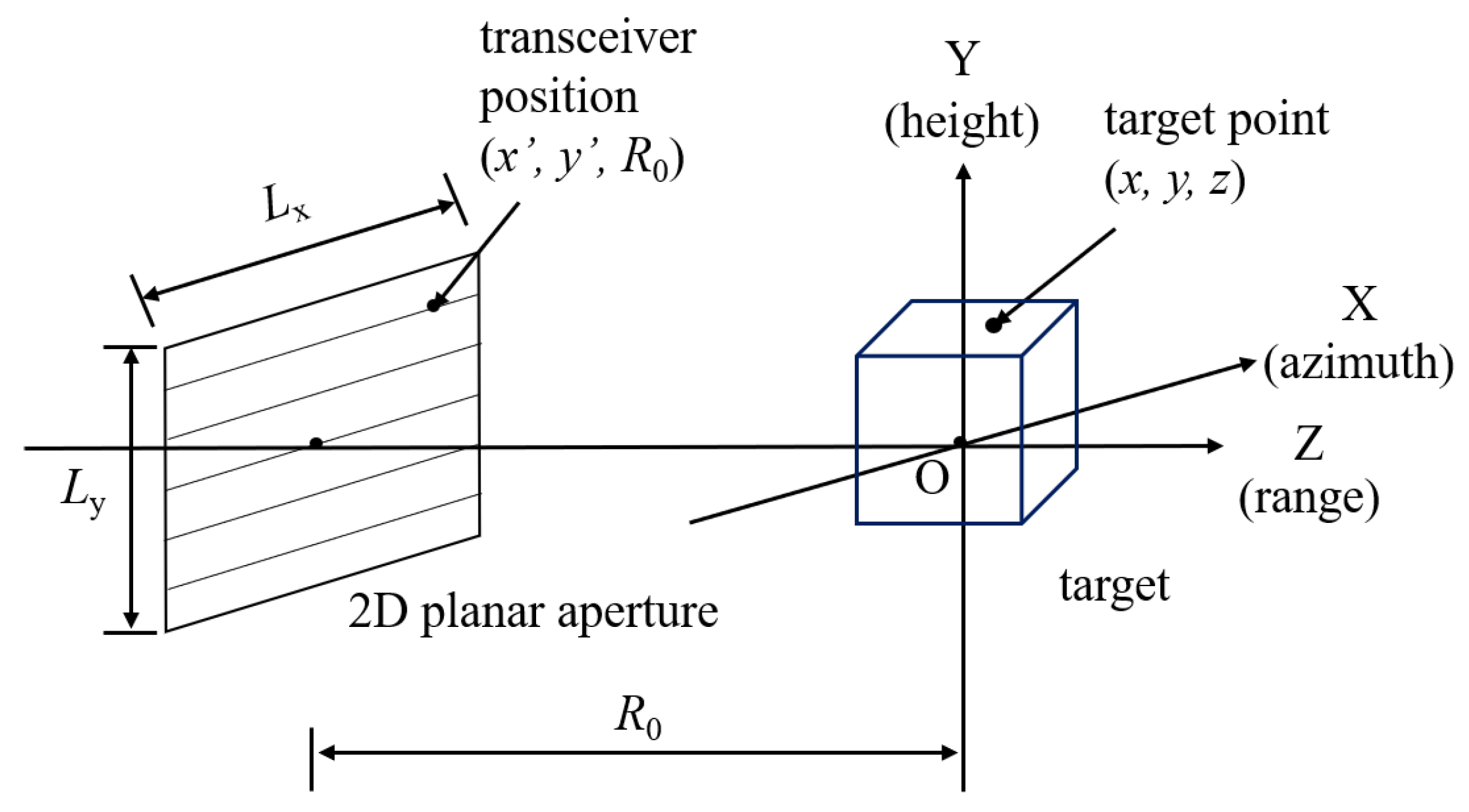
2.1. Three-Dimensional (3D) Range Migration Algorithm
| Algorithm 1 3D RMA imaging |
|
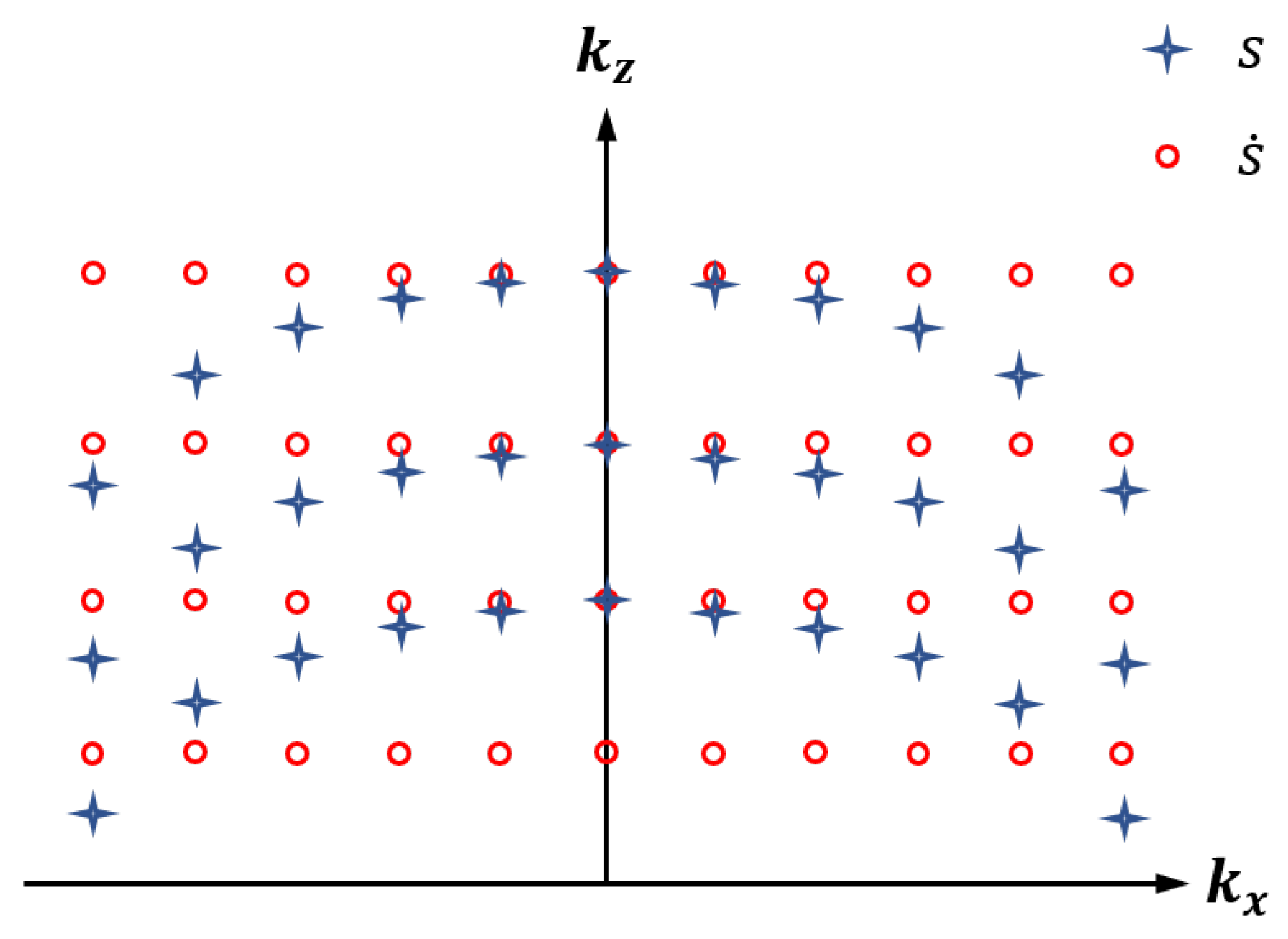
2.2. Cubic Spline Interpolation
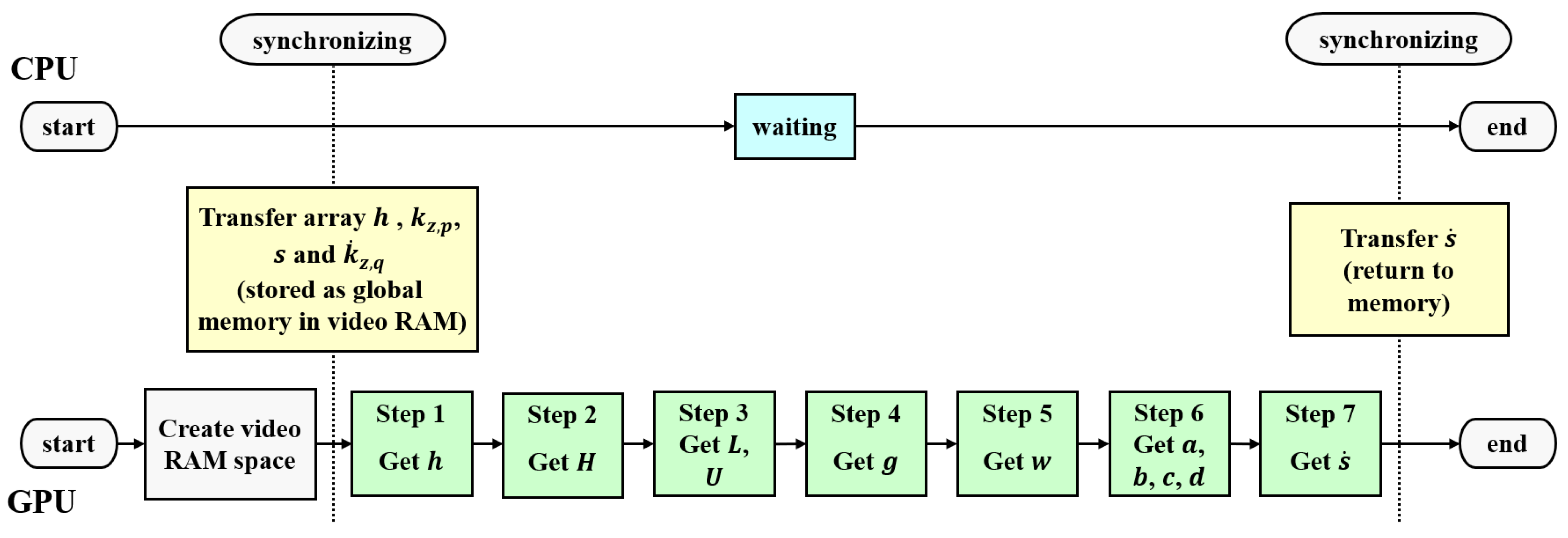
2.3. GPU-Only Method
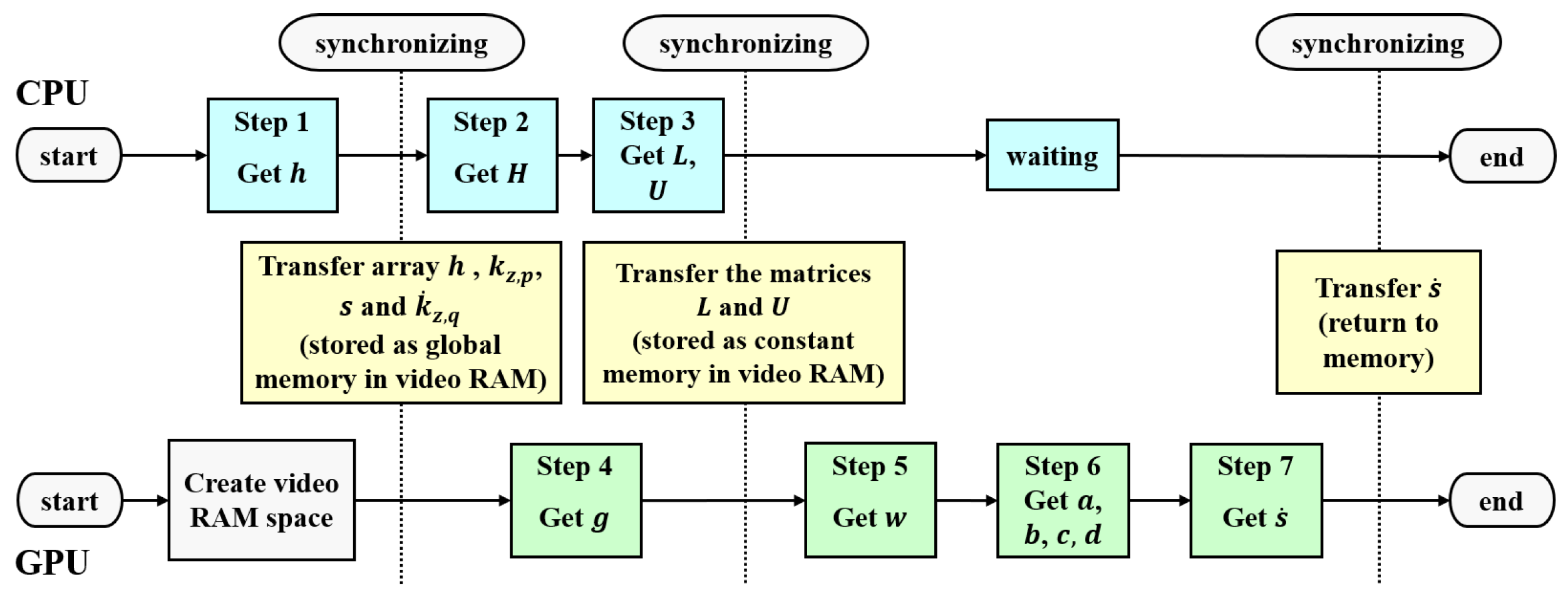
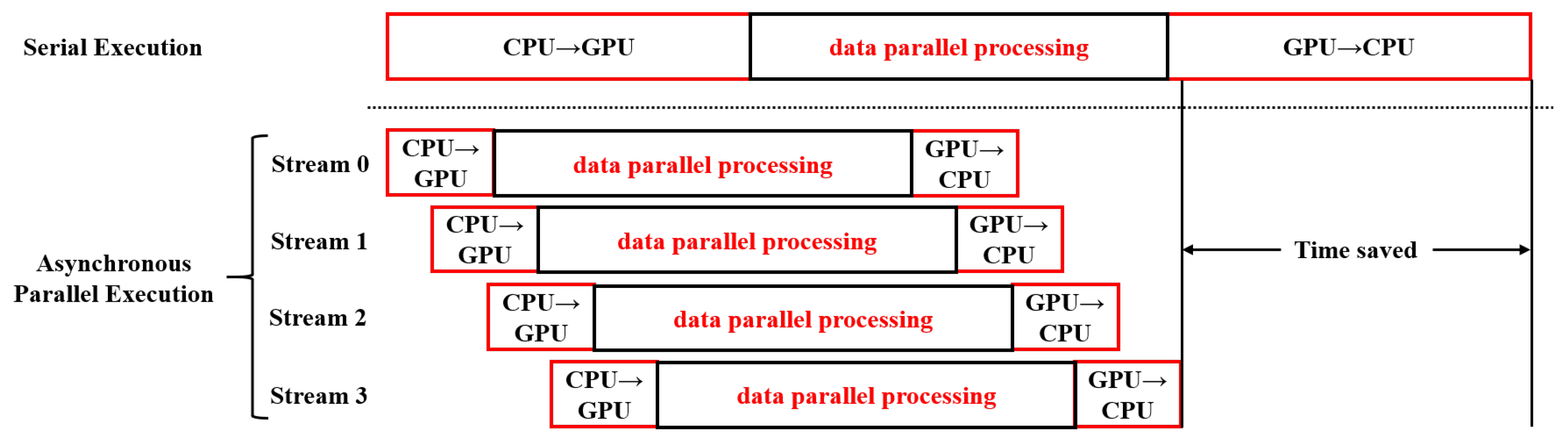
2.4. The Hybrid GPU and CPU Acceleration Method
| Algorithm 2 Cubic spline function |
|
| Algorithm 3 Hybrid CPU-GPU method pseudo code of cubic spline interpolation |
|
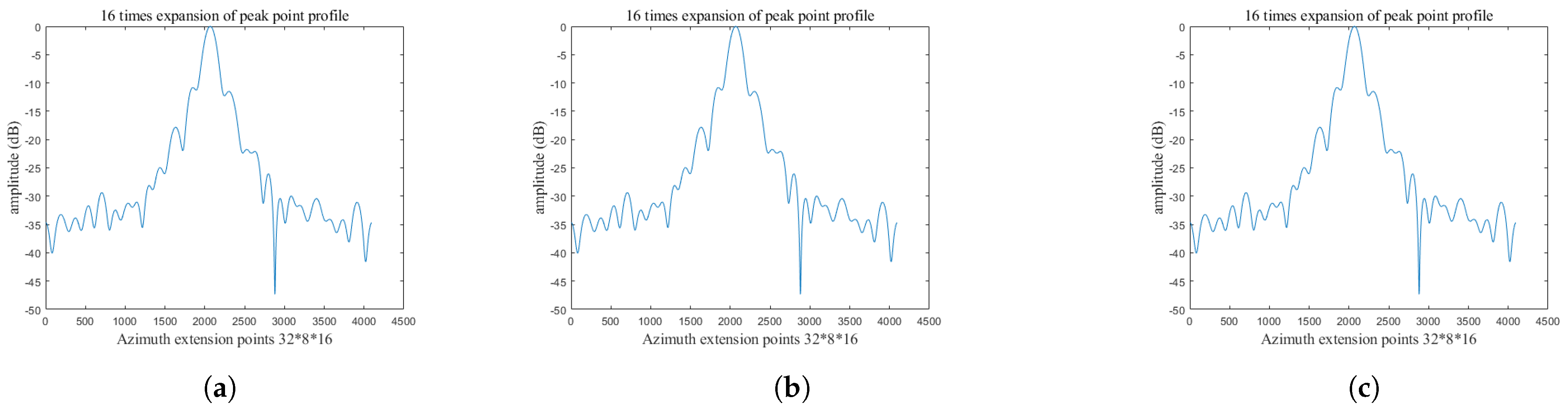
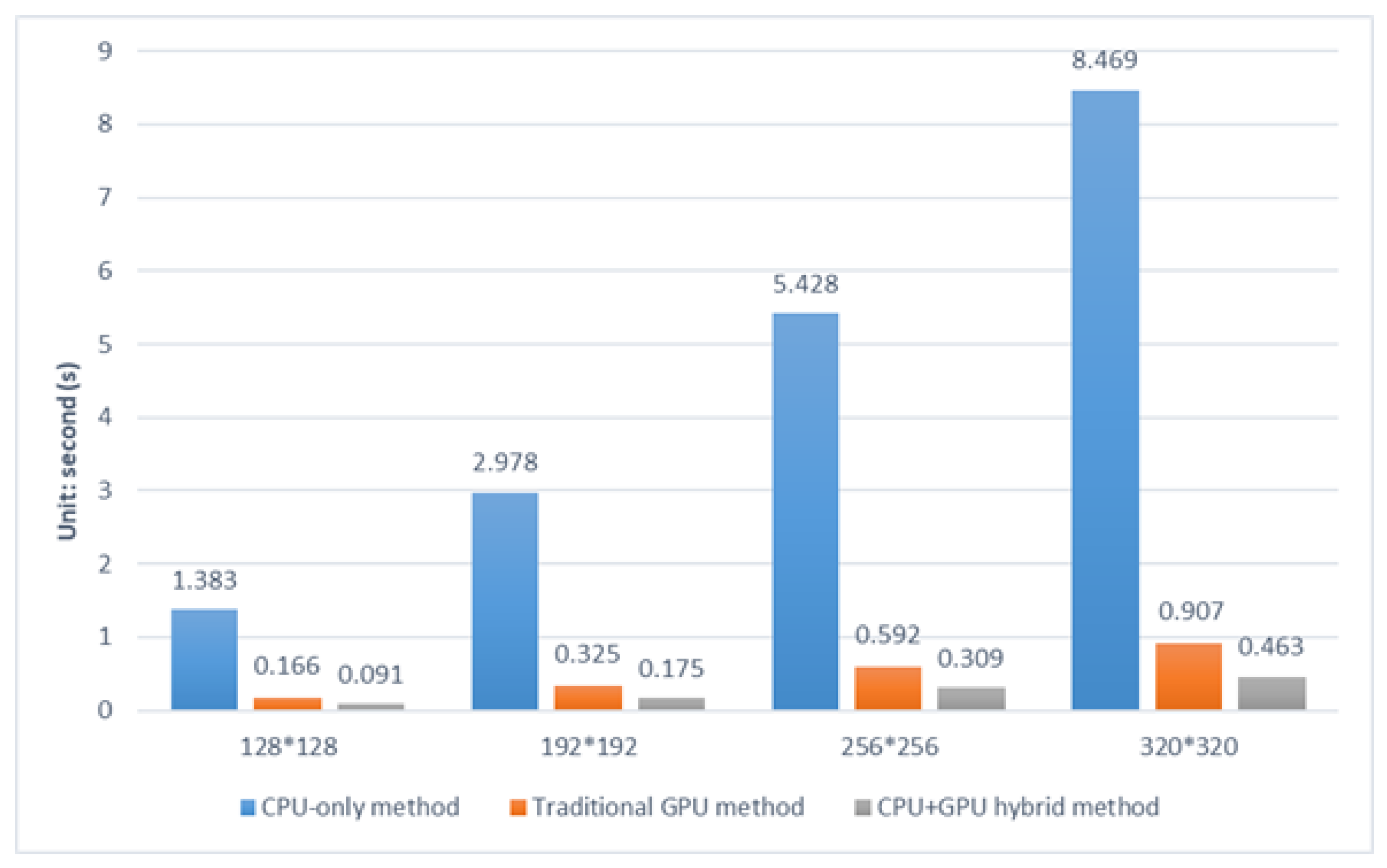
3. Experimental Results and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lorente, D.; Limbach, M.; Gabler, B.; Esteban, H.; Boria, V.E. Sequential 90° rotation of dual-polarized antenna elements in linear phased arrays with improved cross-polarization level for airborne synthetic aperture radar applications. Remote Sens. 2021, 13, 1430. [Google Scholar] [CrossRef]
- Liu, C.; Chen, Z.; Yun, S.; Chen, J.; Hasi, T.; Pan, H. Research advances of SAR remote sensing for agriculture applications: A review. J. Integr. Agric. 2019, 18, 506–525. [Google Scholar] [CrossRef]
- Alibakhshikenari, M.; Virdee, B.S.; Limiti, E. Wideband planar array antenna based on SCRLH-TL for airborne synthetic aperture radar application. J. Electromagn. Waves Appl. 2018, 32, 1586–1599. [Google Scholar] [CrossRef]
- Li, J.; Song, L.; Liu, C. The cubic trigonometric automatic interpolation spline. IEEE/CAA J. Autom. Sin. 2017, 5, 1136–1141. [Google Scholar] [CrossRef]
- Liu, J.; Qiu, X.; Huang, L.; Ding, C. Curved-path SAR geolocation error analysis based on BP algorithm. IEEE Access 2019, 7, 20337–20345. [Google Scholar] [CrossRef]
- Miao, X.; Shan, Y. SAR target recognition via sparse representation of multi-view SAR images with correlation analysis. J. Electromagn. Waves Appl. 2019, 33, 897–910. [Google Scholar] [CrossRef]
- Kim, B.; Yoon, K.S.; Kim, H.-J. GPU-Accelerated Laplace Equation Model Development Based on CUDA Fortran. Water 2021, 13, 3435. [Google Scholar] [CrossRef]
- Yin, Q.; Wu, Y.; Zhang, F.; Zhou, Y. GPU-based soil parameter parallel inversion for PolSAR data. Remote Sens. 2020, 12, 415. [Google Scholar] [CrossRef]
- Cui, Z.; Quan, H.; Cao, Z.; Xu, S.; Ding, C.; Wu, J. SAR target CFAR detection via GPU parallel operation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4884–4894. [Google Scholar] [CrossRef]
- Liu, G.; Yang, W.; Li, P.; Qin, G.; Cai, J.; Wang, Y.; Wang, S.; Yue, N.; Huang, D. MIMO Radar Parallel Simulation System Based on CPU/GPU Architecture. Sensors 2022, 22, 396. [Google Scholar] [CrossRef] [PubMed]
- Gou, L.; Li, Y.; Zhu, D. A real-time algorithm for circular video SAR imaging based on GPU. Radar Sci. Technol. 2019, 17, 550–556. [Google Scholar]
- Liu, J.; Yang, B.; Su, Y.; Liu, P. Fast Context-Adaptive Bit-Depth Enhancement via Linear Interpolation. IEEE Access 2019, 7, 59403–59412. [Google Scholar] [CrossRef]
- Carnicer, J.M.; Khiar, Y.; Peña, J.M. Inverse central ordering for the Newton interpolation formula. Numer. Algorithms 2022, 90, 1691–1713. [Google Scholar] [CrossRef]
- Chand, A.; Kapoor, G. Cubic spline coalescence fractal interpolation through moments. Fractals 2007, 15, 41–53. [Google Scholar] [CrossRef]
- Wang, Z.; Guo, Q.; Tian, X.; Chang, T.; Cui, H.-L. Near-Field 3-D Millimeter-Wave Imaging Using MIMO RMA with Range Compensation. IEEE Trans. Microw. Theory Tech. 2019, 67, 1157–1166. [Google Scholar] [CrossRef]
- Sheen, D.; McMakin, D.; Hall, T. Near-field three-dimensional radar imaging techniques and applications. Appl. Opt. 2010, 49, E83–E93. [Google Scholar] [CrossRef] [PubMed]
- Tan, W.; Huang, P.; Huang, Z.; Qi, Y.; Wang, W. Three-dimensional microwave imaging for concealed weapon detection using range stacking technique. Int. J. Antennas Propag. 2017, 2017, 1480623. [Google Scholar] [CrossRef]
- Kapoor, G.P.; Prasad, S.A. Convergence of Cubic Spline Super Fractal Interpolation Functions. Fractals 2012, 22, 218–226. [Google Scholar]
- Abdulmohsin, H.A.; Wahab, H.B.A.; Hossen, A.M.J.A. A Novel Classification Method with Cubic Spline Interpolation. Intell. Autom. Soft Comput. 2022, 31, 339–355. [Google Scholar] [CrossRef]
- Viswanathan, P.; Chand, A.; Agarwal, R.P. Preserving convexity through rational cubic spline fractal interpolation function. J. Comput. Appl. Math. 2014, 263, 262–276. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Center frequency | 92.5 GHz |
| Frequency bandwidth | 35 GHz |
| Sweeping frequency points | 201 |
| azimuth dimension samples number | 161 |
| azimuth dimension sampling interval | 1.5 mm |
| azimuth dimension aperture length | 0.24 m |
| height dimension samples number | 161 |
| height dimension sampling interval | 1.5 mm |
| height dimension aperture length | 0.24 m |
| Antenna beamwidth | 30∘ |
| Antenna-to-target distance | 0.3 m |
| Data Volume | 128 × 128 | 192 × 192 | 256 × 256 | 320 × 320 |
|---|---|---|---|---|
| Methods | ||||
| Traditional GPU method | 8.33 | 9.16 | 9.17 | 9.34 |
| CPU+GPU hybrid method | 15.20 | 17.02 | 17.57 | 18.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, L.; Dong, Z.; He, H.; Zheng, Q. A Hybrid GPU and CPU Parallel Computing Method to Accelerate Millimeter-Wave Imaging. Electronics 2023, 12, 840. https://doi.org/10.3390/electronics12040840
Ding L, Dong Z, He H, Zheng Q. A Hybrid GPU and CPU Parallel Computing Method to Accelerate Millimeter-Wave Imaging. Electronics. 2023; 12(4):840. https://doi.org/10.3390/electronics12040840
Chicago/Turabian StyleDing, Li, Zhaomiao Dong, Huagang He, and Qibin Zheng. 2023. "A Hybrid GPU and CPU Parallel Computing Method to Accelerate Millimeter-Wave Imaging" Electronics 12, no. 4: 840. https://doi.org/10.3390/electronics12040840
APA StyleDing, L., Dong, Z., He, H., & Zheng, Q. (2023). A Hybrid GPU and CPU Parallel Computing Method to Accelerate Millimeter-Wave Imaging. Electronics, 12(4), 840. https://doi.org/10.3390/electronics12040840