Abstract
At present, the existing methods have many limitations in small target detection, such as low accuracy, a high rate of false detection, and missed detection. This paper proposes the KPE-YOLOv5 algorithm aiming to improve the ability of small target detection. The algorithm has three improvements based on the YOLOv5 algorithm. Firstly, it achieves more accurate size of anchor-boxes for small targets by K-means++ clustering technology. Secondly, the scSE (spatial and channel compression and excitation) attention module is integrated into the new algorithm to encourage the backbone network to pay greater attention to the feature information of small targets. Finally, the capability of small target feature extraction is improved by increasing the small target detection layer, which also increases the detection accuracy of small targets. We evaluate KPE-YOLOv5 on the VisDrone-2020 dataset and compare performance with YOLOv5. The results show that KPE-YOLOv5 improves the detection mAP by 5.3% and increases the P by 7%. The KPE-YOLOv5 algorithm has better detection outcome than YOLOv5 for small target detection.
1. Introduction
Target detection has been one of the research hotspots in the field of machine vision. There are currently two main approaches to target detection using deep learning. One is the one-stage target identification method represented by the You Only Look Once (YOLO) series [1,2,3,4,5,6] and the other is the two-stage target detection strategy represented by the Region-based Convolutional Neural Network (RCNN) series [7,8,9]. Both types of detection algorithms have their own characteristics. The one-stage target detection algorithm is fast but the detection accuracy for targets is not high, especially for small targets, while the two-stage target detection algorithm is much better than the one-stage target detection algorithm in terms of detection accuracy, at the expense of its detection speed. The three components of classic target detection are selection area, feature extraction, and classifier classification. High time cost, which is caused by too many selection boxes and the lack of targeting in the selection, leads to unsatisfactory detection effects. With the rapid development of artificial intelligence and deep learning, target detection has made a huge breakthrough both in terms of detection accuracy and detection speed. There are still issues with low measurement accuracy and a high rate of missed detection in the detection process because of the low resolution and hardly perceptible details of small targets. There are two definitions of “small target”. The first type of small target is known as an absolute small target, and it can be identified as such when its pixel size is smaller than 32*32 pixels in the image. The second one is the relatively small target [10], which means that a specific target can be recognized as a small target when its size is smaller than a certain percentage of the original image size. In this paper, the first definition is employed. Small targets bring a lot of difficulties and challenges to the target detection task due to their low feature information, high background interference noise, and high localization accuracy requirements. Therefore, the study of small target detection is one of the most critical problems in the target detection task today. Since target detection is applied in some specific scenarios, such as unmanned navigation, the real-time requirement for detection is high. In this paper, the well-known algorithm YOLOv5 [11] in single-stage target detection with a high detection rate is used as baseline and targets on the small target dataset VisDrone-2020 [12] are selected for detection. The YOLOv5 model is improved by optimizing the anchor box using the K-means++ [13] clustering algorithm, integrating the attention module to the backbone network, and finally modifying the predictive feature layer.
The paper is structured as follows: Part II describes the related work, Part III describes the improved method used in this paper, Part IV demonstrates the effectiveness of the method in detail through experiments, and Part V concludes the paper.
2. Related Work
The most effective method for target detection prior to the adoption of deep learning was the deformed part model (DPM) [14]. It essentially uses manual features. With the quick development of deep learning, researchers have merged deep learning with target detection and the detection performance has outperformed DMP in every way. Therefore, deep learning has become the mainstream approach in the field of target detection and most of the current target detection algorithms are inseparable from convolutional neural networks.
The RCNN family algorithms are representative work of deep learning based target detection methods, by combining deep learning classification methods with candidate region generation. Vanilla RCNN uses all the obtained candidate boxes for computation, plus SVM classification and bounding-box regression, so the computational effort to process a single image is quite large, which is an important reason for the inefficiency of the RCNN target detection algorithm. Based on RCNN, researchers have successively proposed Fast-RCNN and Faster-RCNN algorithms to further improve the speed and accuracy of target detection.
After the RCNN series, Redmon et al. proposed the YOLO algorithm with faster detection speed. By directly regressing the target bounding box and the class to which it belongs on the divided grid, YOLO approaches target identification as a regression problem, in contrast to the RCNN series. This dramatically accelerates detection time, but YOLO’s drawback is also made abundantly clear. Its detection speed is extremely quick, but its generalization ability and detection accuracy are both relatively poor. In order to solve the above problems, Liu et al. propose the Single Shot MultiBox Detector (SSD) series [15,16,17,18,19] algorithm and Redmon et al. came up with other YOLO families of algorithms; these works have been further improved both in terms of detection accuracy and detection speed. Due to the success of the YOLO series, many researchers have improved the algorithm based on YOLO. YOLOX [20] is an improved algorithm based on YOLOv3, which introduced the anchor free method to the YOLO series for the first time. PP-YOLOE [21] is inspired by YOLOX and YOLOv5 and improves the performance of PP-YOLOv2 [22]. This greatly enhances the performance of the model.
To date, the direction of deep learning based target detection algorithms is almost established, as both types of target detection algorithms have obvious features and drawbacks. In order to improve these two types of algorithms, researchers have made great breakthroughs in target detection through a large number of experimental studies. Because the percentage of small targets in images is small and the features are not obvious, there has been a bottleneck in the detection effect of target detection algorithms for small targets. Many researchers have done special studies on the problem of unsatisfactory detection of small targets.
FA-SSD [23] is an algorithm to enhance small target detection based on SSD. It proposes two structures: F-SSD and A-SSD. F-SSD is used to fuse feature layers at different scales as a way to enhance the feature information in the context. A-SSD is a two-stage attention mechanism that allows the detection to focus on small objects. It helps to reduce the amount of feature information in the context that does not need to be detected. Although FA-SSD uses SSD as baseline in their experiments, this approach can be generalized to other detection networks as well. Cascade R-CNN [24] is a cascade detector designed in accordance with Faster R-CNN. Experiments have proved that, during the training process, the output IoU values are basically larger than the input IoU values. The output of the previous stage can be used as the input of the next stage to obtain higher and higher IoU values. In this way, the problems of overfitting owing to an excessively high IoU threshold and false detection due to an excessively low IoU threshold are resolved, and the detection effect of small targets is considerably enhanced.
Feature Pyramid Network(FPN) [25] is a significant method for detecting small targets. Existing model proposal methods [26,27,28,29] are based on FPN. QueryDet [30] uses a novel query mechanism to speed up the inference of a feature pyramid-based object detector. It improves the inference speed of the model while also improving the accuracy of small target detection.
For the problem of unsatisfactory small target detection, this paper proposes the KPE-YOLOv5 algorithm. It is proved experimentally to really improve the ability of the YOLOv5 algorithm on small target detection.
3. Methods
Compared with YOLOv4, YOLOv5 is a new generation of one-stage detection method with a smaller model and quicker training, and is continuously optimized from the beginning. Experiments adopt the latest version 6.1 of the YOLOv5 network as the basis architecture. The network is shown in Figure 1. The K-means++ clustering algorithm is for optimizing the anchor box, the scSE [31] attention module is integrated into the backbone network, and finally the predictive feature layer of the shallow network is increased. These three improvements are to improve the detection of small targets compared with YOLOv5.
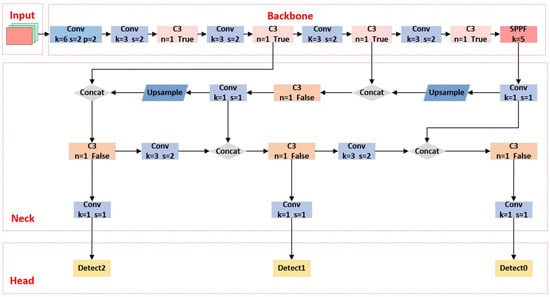
Figure 1.
YOLOv5 Model 6.1.
3.1. Optimization Anchor Box
The original anchor box size of YOLOv5 is obtained by edge clustering with the K-means [32] algorithm on the MS COCO dataset [33]. The number of large and medium targets on the MS COCO dataset is the majority, but the VisDrone-2020 dataset used in this paper is dominated by small targets. The original anchor box size of YOLOv5 is not suitable for the samples on the VisDrone-2020 dataset. If the original anchor box is used, it will cause YOLO detection head to screen improper bounding boxes, which will seriously affect the performance of the model. To solve this problem, we use the K-means++ clustering algorithm to redesign the size of the anchor box for the samples on the VisDrone-2020 dataset.
The K-means++ clustering algorithm is based on the K-means clustering algorithm, which optimizes the selection of initial points and reduces the error of classification results to some extent. The size of the anchor box suitable for the VisDrone-2020 dataset is obtained and the detection accuracy of the model for small targets is improved. As the first initialized cluster center, K-means++ clustering method first chooses a random sample point from the dataset. The remaining cluster centers are then chosen as follows. The likelihood of each point becoming the next cluster centroids is determined by calculating the shortest distance (distance to the closest one) between each sample in the dataset and the initialized cluster centers, indicated by . The relationship can be formulated as:
The point with the highest probability value is selected as the next clustering center. The above calculation steps are repeated until K clustering centers are selected. For each sample in the dataset, calculate its distance to the K cluster centers and assign it to the class corresponding to the cluster center with the smallest distance. Keep updating the cluster centers until the positions of the cluster centers no longer change.
3.2. Pay Attention to Small Targets
The scSE attention module improves the network’s ability to learn important features by extracting the channel and spatial information from the input feature maps and summing them to enhance their excitation. It consists of two parts: the spatially compressed channel excitation module sSE and the channel compressed spatial excitation module cSE, respectively. Since small targets have small pixels in the image, the backbone network is more difficult to extract features from. The scSE attention module is embedded into the backbone network to make it easier for the model to focus on the features of small targets in the feature extraction stage, improving the detection accuracy of small targets. Through experimental comparison, this paper decides to add the scSE attention module to the third layer of the backbone network, which will be explained in the experimental section of this paper. The backbone network after adding the scSE attention module is shown in Figure 2.
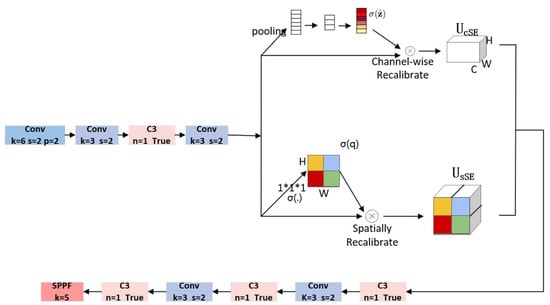
Figure 2.
Backbone network after adding scSE module.
(1) cSE module
The cSE module introduces attention mainly from the channel point of view. In contrast to other network optimization via spatial dimension, SENet [34] begins by optimizing the channel dimension. As shown in Figure 3, the input feature map is . The feature map is globally embedded into the vector z through the global pooling layer, keeping the number of channels constant and turning into , where the value at the Kth channel is (where are the coordinates of each parameter):
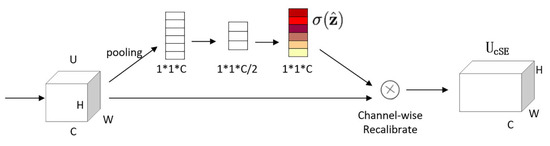
Figure 3.
cSE module.
The obtained vector z is passed through the fully connected layers with weights and , and processed by ReLU activation function and sigmoid normalization in turn to obtain the feature importance degree of the ith channel , where the value of is:
The learning of important channel features is enhanced by calculating the degree of importance for each channel.
(2) sSE module
Spatial attention is an operation of mean on 64 channels to get a weight of . The operation of mean then learns the overall distribution of all channels and discards the singular ones.
As shown in Figure 4, the input feature map ( indicates the channel feature information at ()) is compressed by a 1 × 1 convolutional block with channel number C and weight , and the output feature map with channel number 1 and size is:
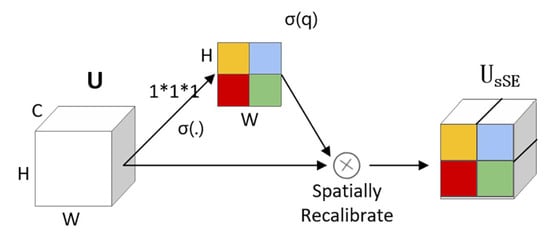
Figure 4.
sSE module.
The obtained feature map q is normalized to obtain the degree of importance of spatial information for each spatial location in the feature map to enhance the important spatial location features.
(3) scSE attention module
The channel and spatial importance feature extraction on the feature map are done in tandem by the sSE and cSE modules, which make up the scSE attention module. By doing summation of the obtained features, the subgraph of high importance features is obtained and more strongly motivated. The network model is motivated to pay more attention to the feature information that needs to be learned.
3.3. Optimization of the Prediction Layer
One of the reasons why YOLOv5 does not work well for small target detection is that the size of small target samples is smaller and the downsampling multiplier of YOLOv5 is larger. The deeper feature maps make it difficult to learn the features of small targets, so this paper proposes to add a small target detection layer to detect the shallower feature maps.
The specific procedure is depicted in Figure 5. YOLOv5 originally only performs feature prediction on the last three C3 layers but, because small targets lose feature information in the process of continuous downsampling, this leads to unsatisfactory small-target detection. Therefore, we add a layer of feature prediction. The newly added prediction layer has fewer downsampling times and higher resolution of small targets, which helps the model learn the features of small targets.
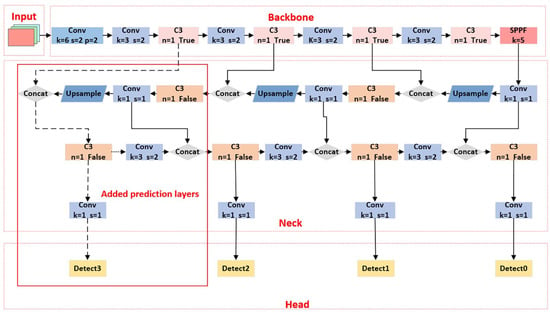
Figure 5.
Model after adding prediction feature heads.
4. Experiments
The YOLOv5 algorithm provides four different scales of models: S, M, L, and X. Each scale model has different depth and width. The structure of the four scale models is same; only the size and complexity are deflated. We examine and analyze the ability to recognize small targets by the YOLOv5s network model for experiments.
The houseware platform used for model training in this experiment is Intel(R) Xeon(R) Gold 5118 CPU @ 2.30GHz CPU and NVIDIA Quadro P5000 16G GPU; the model test inference platform is the same as above. The software uses the Windows system, Python 3.8.13, PyTorch 1.9.0, and the Cuda11.1 deep learning framework.
4.1. Dataset
The percentage of small targets is relatively minor and unevenly distributed on the traditional dataset. Unbalanced distribution will lead to the model being more biased to learning large and medium targets in the training process. To solve this problem, we use the VisDrone-2020 dataset, a professional dataset with mainly small objects. Randomly selected images from the VisDrone-2020 dataset are shown in Figure 6.

Figure 6.
Randomly selected images from the VisDrone-2020 dataset.
The AISKYYE team from Tianjin University’s Machine Learning and Data Mining Laboratory gathered the VisDrone-2020 dataset. Compared with the MS COCO dataset, the VisDrone-2020 dataset is more suited for small target detection since it contains twice as many small objects as the MS COCO dataset. Table 1 displays the percentage of targets at each scale for these datasets. Small objects in a single image account for about 0.3% of the total image area, intermediate objects for 0.3% to 3%, and large objects for more than 3%.

Table 1.
Comparison of each scale target in COCO and VisDrone-2020 (%).
4.2. Evaluation Criteria
The network performance is assessed by three performance metrics: accuracy P (precision), R (recall), and (mean average precision). Where P, R, and are:
is the number of targets correctly detected by the network model; is the number of targets incorrectly detected by the network model; is the number of targets not detected by the network model; c is the number of categories; and is the average precision of a single target category, where is:
4.3. Analysis of Experimental Results
4.3.1. Experimental Comparison of Optimized Anchor Box
To analyze the effect of optimizing the anchor with the K-means++ algorithm on the detection performance of the model, Table 2 shows the training results of the original algorithm and K-YOLOv5s algorithm on the VisDrone-2020 dataset. K-YOLOV5s modify the size of the anchor box based on YOLOV5s. From the table, it is found that the model with recalculated anchor box size by K-means++ algorithm has significantly improved target detection on the VisDrone-2020 dataset compared to the original model. The P value increases by 1.1 percent, which is the most significant increase.
Table 2.
Comparison of results of optimized anchor box (%).
To verify the detection effect of the K-YOLOv5s algorithm, a typical small target image in the VisDrone-2020 test set is selected as the test object for visual comparison. As shown in Figure 7, Figure 7a shows the detection effect of the original model and Figure 7b shows the detection effect of K-YOLOv5s algorithm. The differences in the images are marked with red boxes. From the comparison, it can be seen that the K-YOLOv5s algorithm improves the problem of missed detection compared with YOLOv5s.

Figure 7.
Comparison of optimized anchor box detection results.
4.3.2. Comparison of the Results of Integrating the Attention Module
As the number of downsamplings gradually increases, the features of small targets will become fewer and fewer. We integrate the scSE attention module into the backbone network of the original model. The scSE attention module strengthens the learning ability of the model for important features from two aspects of channel and space, to enhance the detection effect of the model on small targets. The effects of integrating the scSE attention module on the detection performance of the model are shown in Table 3, where E-YOLOv5 represents the model after integrating the scSE attention module.
Table 3.
Comparison of the results of integrating the attention module (%).
Table 3 analyzes the impact of integrating the attention module on the network performance by comparing the three metrics of P, R, and mAP@0.5. From the results, it can be seen that integrating the attention module can improve the detection effectiveness of the network, where the P is improved by 2.1% and mAP@0.5 is also improved by 1.1%.
Figure 8 shows the detection results of YOLOv5s and E-YOLOv5s by selecting the road scene as the detection object and comparing them. The left panel shows the detection results of the original algorithm and the right panel shows E-YOLOv5s algorithm. From the comparison, we can see that the E-YOLOv5s algorithm enhances the learning ability of the model for small targets. The problem of missed detection of the original algorithm is improved.

Figure 8.
Comparison of detection results of adding attention module.
4.3.3. Experimental Comparison of Optimized Prediction Layer
Since the downsampling multiplier of YOLOv5s is relatively large, it is difficult to learn the feature information of small targets on deeper feature maps. The prediction feature head proposed in Section 3.3 is used for prediction in this paper. The original model and P-YOLOv5s are trained on the VisDrone-2020 dataset. The comparison results are shown in Table 4. P-YOLOv5s refers to the model after the prediction layer has been changed.
Table 4.
Comparison of the results of changing the detection layer module (%).
The results showed that P-YOLOv5s has a significant improvement in the detection of the model. P increased by 4.7%, R increased by 4%, and mAP@0.5 also increased by 4.8%.
Figure 9 displays a visual comparison of detection results with the YOLOv5s algorithm and the P-YOLOv5s algorithm. The technique considerably reduces the issue of missing and erroneous detection with the addition of the detection layer.
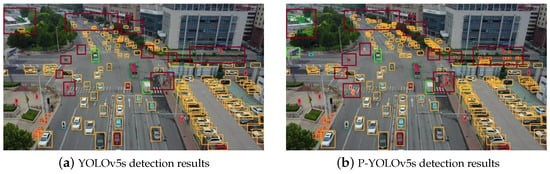
Figure 9.
Adding detection layer detection effect comparison chart.
4.3.4. Comparison of Other Experimental Results
In order to determine the optimal mode of incorporating scSE attention modules into YOLOv5s, experiments are conducted with various combinations of parameters, including the location and number of attention modules integrated. The results of the experiments are shown in Table 5.
Table 5.
Results of incorporating the scSE module into YOLOv5s with different parameters (%).
The experimental results in Table 5 show that the scSE attention module integrated into the third layer of the backbone network has the best effect. When scSE attention modules are integrated into other locations or the number of additions is changed, the detection effect of the model is even reduced. This paper speculates that there may be two reasons for this phenomenon: Firstly, increasing the number of scSE attention modules may cause redundancy of data, which may affect the detection effect. Secondly, most of the targets in VisDrone-2020 are small; there is less feature information left in the Neck and Head modules after several downsampling operations of the model. So the effect of integrating scSE attention modules into the Neck and Head modules is not satisfactory.
Figure 10a,b show the results of the YOLOv5s model and the KPE-YOLOv5s model trained on the VisDrone-2020 dataset, which include loss of the bounding box, mean value of target detection loss, and mean value of classification loss on the training and validation sets, in addition to the evaluation metrics used in this paper. By contrasting Figure 10a,b, we can see that the new model not only increases the detection accuracy of small targets but also greatly increases the recall rate.
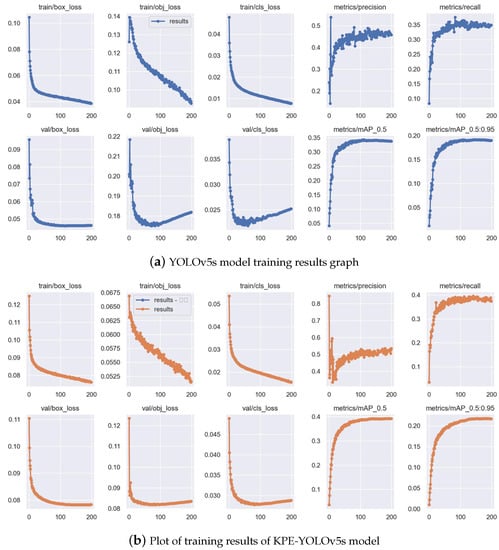
Figure 10.
Comparison chart of test results.
In addition to the above experimental comparisons, we show the performance of the KPE-YOLOv5 on the VisDrone-2020 dataset and compare it with the state-of-the-art object detection algorithms. The comparison results are shown in Table 6.
Table 6.
Comparison of state-of-the-art real-time object detectors (%).
It can be seen from Table 6 that the KPE-YOLOv5 algorithm improves the ability of small target detection compared with the YOLOv5 model. Compared with the detectors before YOLOv5, KPE-YOLOv5 surpasses them in all aspects of performance indicators, while the recall of KPE-YOLOv5 was slightly lower compared to YOLOx and YOLOv7; the P and mAP exceeded them. Compared with YOLOv5, although there is a slight drop in FPS, but the detection accuracy has improved, the mAP of KPE-YOLOv5 increases by 5.3% and P increases by 7%. KPE-YOLOv5 also had superior P-value and mAP compared to YOLOv8. Its performance is also superior to other state-of-the-art object detectors.
5. Conclusions
This paper proposes the KPE-YOLOv5 algorithm on the basis of YOLOv5 to solve the problem of unsatisfactory detection of small targets due to low resolution and inconspicuous features. The size of the anchor box is redesigned by the K-means++ clustering algorithm, the scSE attention module is introduced, and the prediction layer modified to improve the original algorithm. The improved network model is tested on the VisDrone-2020 dataset. The experiment shows that the KPE-YOLOv5 model has a significant improvement over the YOLOv5 model in terms of P, R, and mAP. It proves that the KPE-YOLOv5 algorithm improves the detection effect of the YOLOv5 algorithm on small targets to a certain extent. The improvement of this paper can be verified on other scales of YOLOv5 models in the future.
Author Contributions
Funding acquisition, W.L.; investigation, R.Y.; methodology, R.Y. and D.Z.; project administration, R.Y., D.Z., and X.M.; resources, W.L. and X.S.; software, R.Y. and D.Z.; supervision, W.L. and X.S.; writing—original draft, R.Y.; writing—review and editing, R.Y., X.S. and X.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (Grant Nos. 61972040).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- JOCHER. Network Data. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 24 December 2022).
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE international Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 2110–2118. [Google Scholar]
- JOCHER. Network Data. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 24 December 2022).
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and tracking meet drones challenge. arXiv 2020, arXiv:2001.06303. [Google Scholar] [CrossRef] [PubMed]
- Vassilvitskii, S.; Arthur, D. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Miami, FL, USA, 22–24 January 2006; pp. 1027–1035. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.G.; Chen, Y.; Xue, X. Dsod: Learning deeply supervised object detectors from scratch. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1919–1927. [Google Scholar]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. arXiv 2017, arXiv:1705.09587. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. PP-YOLOE: An evolved version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Long, X.; Deng, K.; Dang, Q.; Han, S.; Liu, Q.; Hu, X.; et al. PP-YOLOv2: A practical object detector. arXiv 2021, arXiv:2104.10419. [Google Scholar]
- Lim, J.S.; Astrid, M.; Yoon, H.J.; Lee, S.I. Small object detection using context and attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 13–16 April 2021; pp. 181–186. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, Z.; Gao, G.; Sun, L.; Fang, L. IPG-net: Image pyramid guidance network for small object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1026–1027. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Redmon, J.; Farhadi, A. ieee 2017 ieee conference on computer Vision and Pattern Recognition (cvpr)-honolulu, hi (2017.7.21-2017.7. 26). In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (cvpr)-yolo9000: Better, faster, stronger. IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Deng, C.; Wang, M.; Liu, L.; Liu, Y.; Jiang, Y. Extended feature pyramid network for small object detection. IEEE Trans. Multimed. 2021, 24, 1968–1979. [Google Scholar] [CrossRef]
- Yang, C.; Huang, Z.; Wang, N. QueryDet: Cascaded sparse query for accelerating high-resolution small object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13668–13677. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel ‘squeeze & excitation’ in fully convolutional networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 421–429. [Google Scholar]
- McQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 1 January 1967; pp. 281–297. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).