




An Approach for Classification of Alzheimer’s Disease Using Deep Neural Network and Brain Magnetic Resonance Imaging (MRI)
 , ,
, ,  and
and 
Abstract
1. Introduction
- According to the results of the performance evaluation, all of the existing models performed at a percentage of less than 90. It has also been observed that amongst all the models, because of the simple and effective architecture, LeNet and AlexNet can perform faster in training and testing.
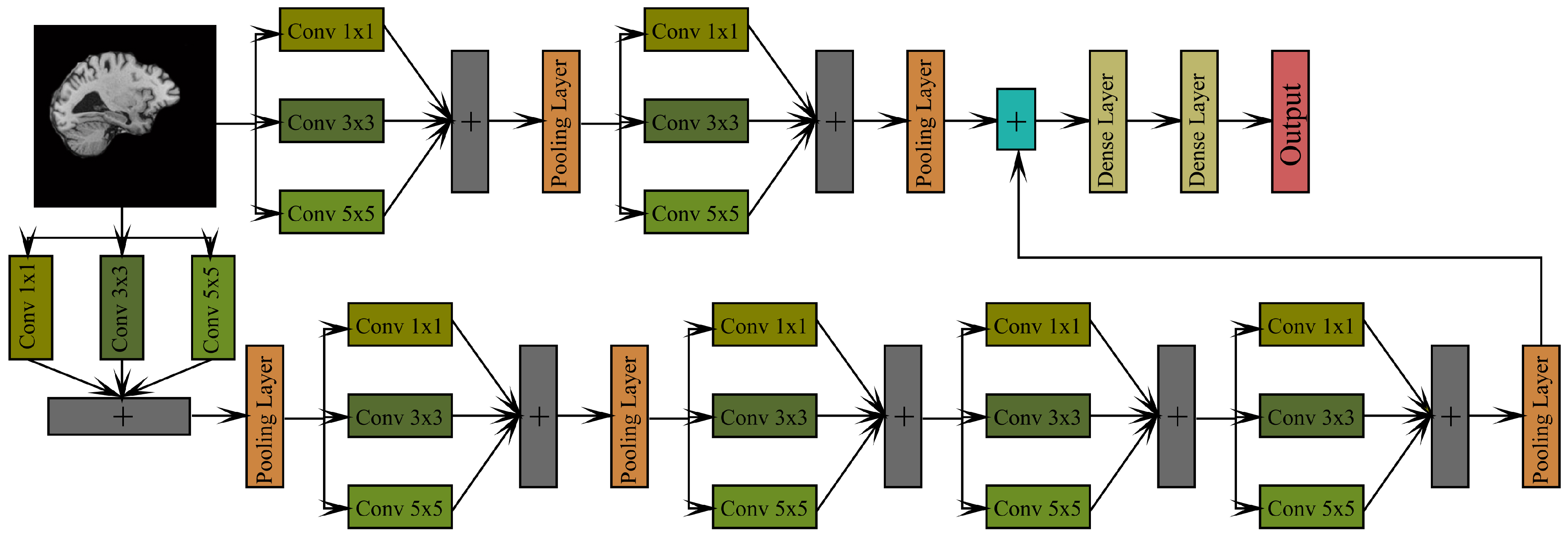
- The main aim of this work is to develop a light weighted hybrid model that can perform faster and better. We combined LeNet and AlexNet in parallel and proposed a new hybrid DNN architecture.
- Different convolutional kernel sizes may help a network to learn more crucial aspects, and mixing several features can improve feature representations [39]. Hence, in the proposed hybrid model, we replaced all the traditional large convolutional filters with a set of three small filters (, and ).
- Better feature extraction improves the model’s performance, and the model’s average performance improved to 93.58%. Mathematically, it is shown that the proposed hybrid model retrieved much fewer convolutional parameters (even significantly fewer than the regular AlexNet model), making it a computationally faster model.
- In comparison to all other deployed models, as well as the discussed state of the art, it is observed that the proposed hybrid model achieved the most convincing performance.
2. Related Study
3. Experimental Analysis of Different DNN Models
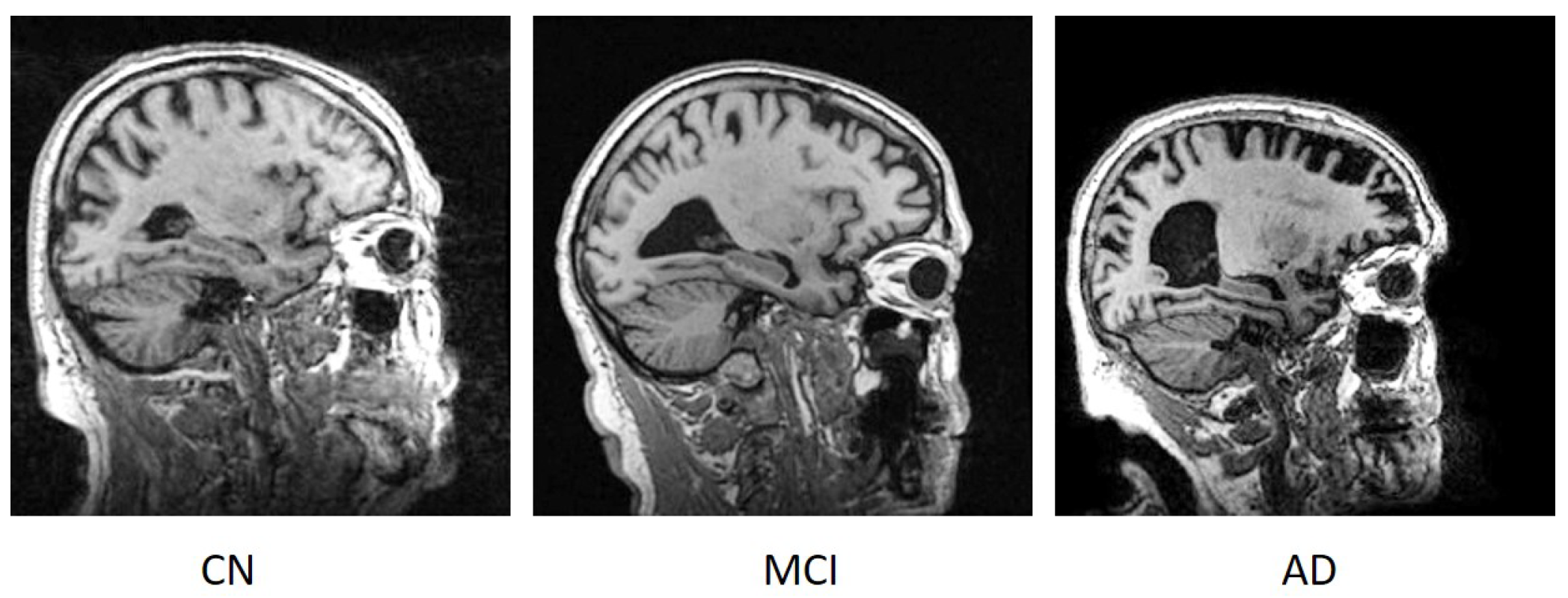
3.1. Data and Tools
3.2. Experimental Setup
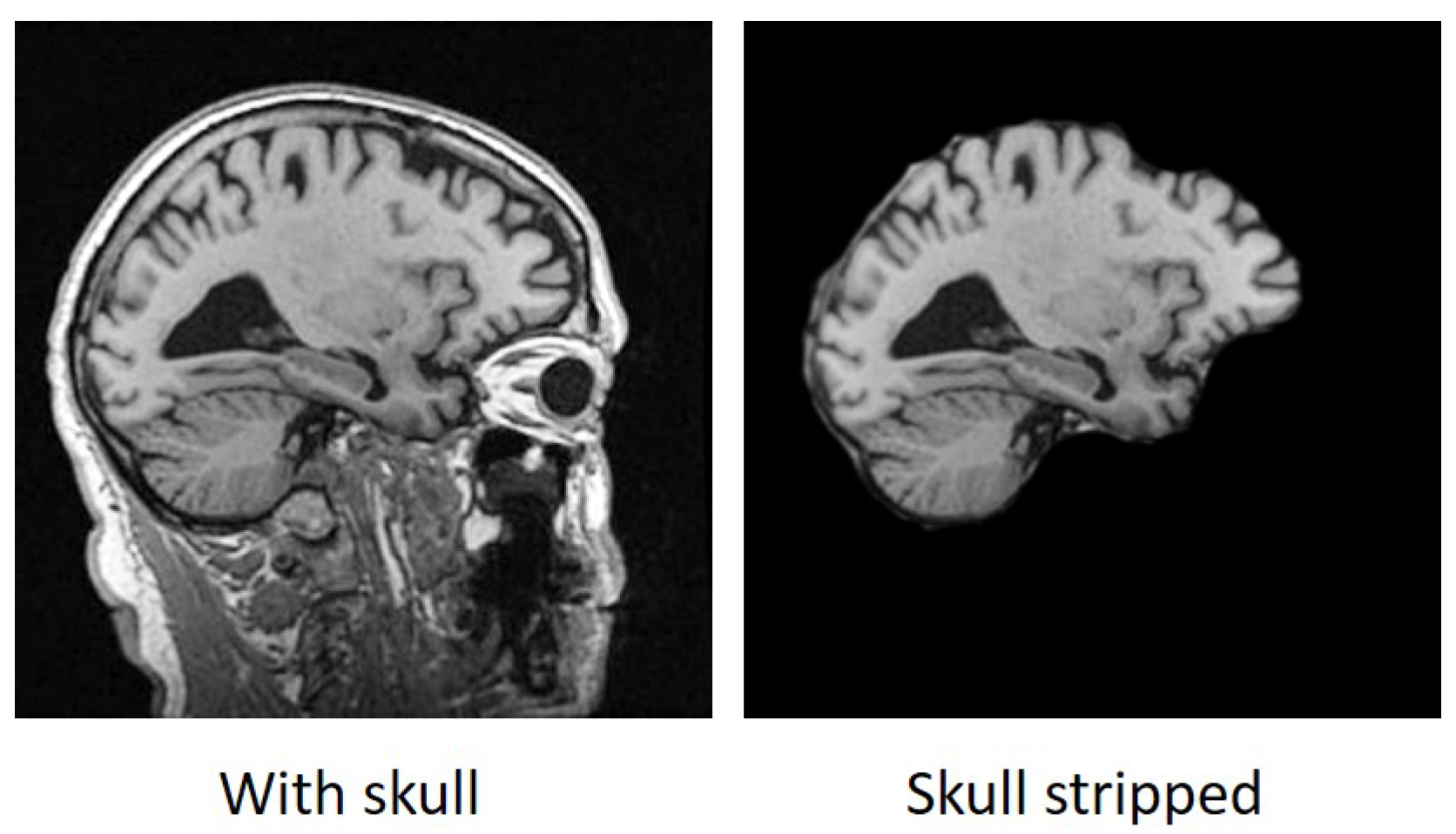
3.3. Pre-Processing
3.4. Discussion about the Implemented DNN Models
3.4.1. LeNet
3.4.2. AlexNet
3.4.3. VGG-16 and VGG-19
3.4.4. Inception—V1 and V2 and V3
3.4.5. ResNet-50
3.4.6. MobileNet-V1
3.4.7. EfficientNet-B0
3.4.8. Xception
3.4.9. DenseNet-121
4. Proposed Model for AD Classification
- No. of parameters generated by first convolution layer = .
- No. of parameters generated by second convolution layer = .
- Total parameters generated in LeNet by the two convolution layers = 2872.
- No. of parameters generated by first convolution layer = .
- No. of parameters generated by second convolution layer = .
- No. of parameters generated by third convolution layer = .
- No. of parameters generated by fourth convolution layer = .
- No. of parameters generated by fifth convolution layer = .
- Total parameters generated in LeNet by the two convolution layers = 3,747,200.
- No. of parameters generated by first convolution layer = .
- No. of parameters generated by second convolution layer = .
- Total parameters generated in LeNet by the two convolution layers = 652.
- No. of parameters generated by first convolution layer = .
- No. of parameters generated by second convolution layer = .
- No. of parameters generated by third convolution layer = .
- No. of parameters generated by fourth convolution layer = .
- No. of parameters generated by fifth convolution layer = .
- Total parameters generated in LeNet by the two convolution layers = 1,445,380.
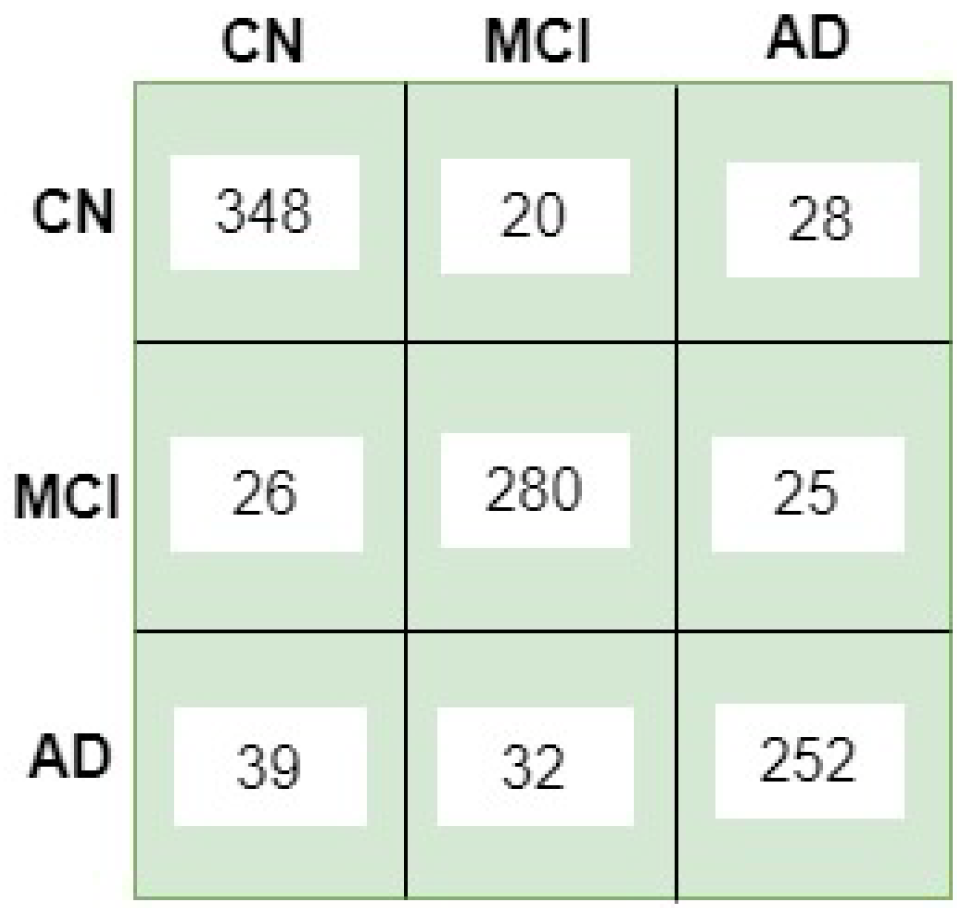
5. Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alzheimer’s Association. 2018 Alzheimer’s disease facts and figures. Alzheimer’s Dement. 2018, 14, 367–429. [Google Scholar] [CrossRef]
- Korolev, I.O. Alzheimer’s disease: A clinical and basic science review. Med. Stud. Res. J. 2014, 4, 24–33. [Google Scholar]
- Donev, R.; Kolev, M.; Millet, B.; Thome, J. Neuronal death in Alzheimer’s disease and therapeutic opportunities. J. Cell. Mol. Med. 2009, 13, 4329–4348. [Google Scholar] [CrossRef] [PubMed]
- Moon, S.W.; Lee, B.; Choi, Y.C. Changes in the hippocampal volume and shape in early-onset mild cognitive impairment. Psychiatry Investig. 2018, 15, 531. [Google Scholar] [CrossRef]
- Barnes, J.; Whitwell, J.L.; Frost, C.; Josephs, K.A.; Rossor, M.; Fox, N.C. Measurements of the amygdala and hippocampus in pathologically confirmed Alzheimer disease and frontotemporal lobar degeneration. Arch. Neurol. 2006, 63, 1434–1439. [Google Scholar] [CrossRef]
- Hazarika, R.A.; Maji, A.K.; Sur, S.N.; Paul, B.S.; Kandar, D. A Survey on Classification Algorithms of Brain Images in Alzheimer’s Disease Based on Feature Extraction Techniques. IEEE Access 2021, 9, 58503–58536. [Google Scholar] [CrossRef]
- NIH. Alzheimer’s Disease: A Clinical and Basic Science Review. Available online: https://www.nia.nih.gov/health/alzheimers-disease-fact-sheet (accessed on 13 July 2020).
- Alzheimer’s Association. Alzheimer’s Disease Fact Sheet. Available online: https://www.alz.org/in/dementia-alzheimers-en.asp#diagnosis (accessed on 13 July 2020).
- Varatharajah, Y.; Ramanan, V.K.; Iyer, R.; Vemuri, P. Predicting short-term MCI-to-AD progression using imaging, CSF, genetic factors, cognitive resilience, and demographics. Sci. Rep. 2019, 9, 1–15. [Google Scholar] [CrossRef]
- National Institute on Aging(NIH). What Is Mild Cognitive Impairment? Available online: https://www.nia.nih.gov/health/what-mild-cognitive-impairment (accessed on 23 June 2021).
- Burns, A.; Iliffe, S. Clinical review: Alzheimer’s disease. Br. Med. J. 2009, 338, b158–b163. [Google Scholar] [CrossRef]
- Mayo Clinic Staff. Learn How Alzheimer’s Is Diagnosed. 2019. Available online: https://www.mayoclinic.org/diseases-conditions/alzheimers-disease/in-depth/alzheimers/art-20048075 (accessed on 23 June 2021).
- Huff, F.J.; Boller, F.; Lucchelli, F.; Querriera, R.; Beyer, J.; Belle, S. The neurologic examination in patients with probable Alzheimer’s disease. Arch. Neurol. 1987, 44, 929–932. [Google Scholar] [CrossRef]
- Arevalo-Rodriguez, I.; Smailagic, N.; i Figuls, M.R.; Ciapponi, A.; Sanchez-Perez, E.; Giannakou, A.; Pedraza, O.L.; Cosp, X.B.; Cullum, S. Mini-Mental State Examination (MMSE) for the detection of Alzheimer’s disease and other dementias in people with mild cognitive impairment (MCI). Cochrane Database Syst. Rev. 2015, 23, 107–120. [Google Scholar] [CrossRef]
- Cummings, J.L.; Ross, W.; Absher, J.; Gornbein, J.; Hadjiaghai, L. Depressive symptoms in Alzheimer disease: Assessment and determinants. Alzheimer Dis. Assoc. Disord. 1995, 9, 87–93. [Google Scholar] [CrossRef] [PubMed]
- Symms, M.; Jäger, H.; Schmierer, K.; Yousry, T. A review of structural magnetic resonance neuroimaging. J. Neurol. Neurosurg. Psychiatry 2004, 75, 1235–1244. [Google Scholar] [CrossRef] [PubMed]
- Ijaz, M.F.; Attique, M.; Son, Y. Data-driven cervical cancer prediction model with outlier detection and over-sampling methods. Sensors 2020, 20, 2809. [Google Scholar] [CrossRef]
- Ledig, C.; Schuh, A.; Guerrero, R.; Heckemann, R.A.; Rueckert, D. Structural brain imaging in Alzheimer’s disease and mild cognitive impairment: Biomarker analysis and shared morphometry database. Sci. Rep. 2018, 8, 1–16. [Google Scholar] [CrossRef]
- Fung, Y.R.; Guan, Z.; Kumar, R.; Wu, J.Y.; Fiterau, M. Alzheimer’s disease brain mri classification: Challenges and insights. arXiv 2019, arXiv:1906.04231. [Google Scholar]
- Lundervold, A.S.; Lundervold, A. An overview of deep learning in medical imaging focusing on MRI. Z. Med. Phys. 2019, 29, 102–127. [Google Scholar] [CrossRef]
- Wang, S.C. Artificial neural network. In Interdisciplinary Computing in JAVA Programming; Springer: Berlin/Heidelberg, Germany, 2003; pp. 81–100. [Google Scholar]
- Pagel, J.F.; Kirshtein, P. Machine Dreaming and Consciousness; Academic Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Raghavan, V.V.; Gudivada, V.N.; Govindaraju, V.; Rao, C.R. Cognitive Computing: Theory and Applications; Elsevier: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Khasawneh, N.; Fraiwan, M.; Fraiwan, L. Detection of K-complexes in EEG signals using deep transfer learning and YOLOv3. Clust. Comput. 2022, 1–11. [Google Scholar] [CrossRef]
- Khasawneh, N.; Fraiwan, M.; Fraiwan, L. Detection of K-complexes in EEG waveform images using faster R-CNN and deep transfer learning. BMC Med. Inform. Decis. Mak. 2022, 22, 1–14. [Google Scholar] [CrossRef]
- Fraiwan, M.; Al-Kofahi, N.; Ibnian, A.; Hanatleh, O. Detection of developmental dysplasia of the hip in X-ray images using deep transfer learning. BMC Med. Inform. Decis. Mak. 2022, 22, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Fraiwan, M.A.; Abutarbush, S.M. Using artificial intelligence to predict survivability likelihood and need for surgery in horses presented with acute abdomen (colic). J. Equine Vet. Sci. 2020, 90, 102973. [Google Scholar] [CrossRef] [PubMed]
- Altinkaya, E.; Polat, K.; Barakli, B. Detection of Alzheimer’s Disease and Dementia States Based on Deep Learning from MRI Images: A Comprehensive Review. J. Inst. Electron. Comput. 2020, 1, 39–53. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Improving accuracy and efficiency through automl and model scaling. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Murugesan, B.; Ravichandran, V.; Ram, K.; Preejith, S.; Joseph, J.; Shankaranarayana, S.M.; Sivaprakasam, M. Ecgnet: Deep network for arrhythmia classification. In Proceedings of the 2018 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Rome, Italy, 11–13 July 2018; pp. 1–6. [Google Scholar]
- Dumitru, C.; Maria, V. Advantages and Disadvantages of Using Neural Networks for Predictions. Ovidius Univ. Ann. Ser. Econ. Sci. 2013, 13, 444–449. [Google Scholar]
- Zhang, X.; Han, L.; Zhu, W.; Sun, L.; Zhang, D. An Explainable 3D Residual Self-Attention Deep Neural Network For Joint Atrophy Localization and Alzheimer’s Disease Diagnosis using Structural MRI. IEEE J. Biomed. Health Inform. 2021, 26, 5289–5297. [Google Scholar] [CrossRef] [PubMed]
- Han, R.; Chen, C.P.; Liu, Z. A Novel Convolutional Variation of Broad Learning System for Alzheimer’s Disease Diagnosis by Using MRI Images. IEEE Access 2020, 8, 214646–214657. [Google Scholar] [CrossRef]
- Zhao, Y.; Ma, B.; Jiang, P.; Zeng, D.; Wang, X.; Li, S. Prediction of Alzheimer’s Disease Progression with Multi-Information Generative Adversarial Network. IEEE J. Biomed. Health Inform. 2020, 25, 711–719. [Google Scholar] [CrossRef] [PubMed]
- Lian, C.; Liu, M.; Zhang, J.; Shen, D. Hierarchical fully convolutional network for joint atrophy localization and Alzheimer’s disease diagnosis using structural MRI. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 880–893. [Google Scholar] [CrossRef]
- Huang, Y.; Xu, J.; Zhou, Y.; Tong, T.; Zhuang, X.; ADNI. Diagnosis of Alzheimer’s disease via multi-modality 3D convolutional neural network. Front. Neurosci. 2019, 13, 509. [Google Scholar] [CrossRef] [PubMed]
- Marzban, E.N.; Eldeib, A.M.; Yassine, I.A.; Kadah, Y.M.; Initiative, A.D.N. Alzheimer’s disease diagnosis from diffusion tensor images using convolutional neural networks. PLoS ONE 2020, 15, e0230409. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Cheng, D.; Yan, W. Classification of Alzheimer’s Disease by Combination of Convolutional and Recurrent Neural Networks Using FDG-PET Images. Front. Neuroinform. 2018, 12, 35. [Google Scholar] [CrossRef] [PubMed]
- Solano-Rojas, B.; Villalón-Fonseca, R. A Low-Cost Three-Dimensional DenseNet Neural Network for Alzheimer’s Disease Early Discovery. Sensors 2021, 21, 1302. [Google Scholar] [CrossRef]
- Choi, B.K.; Madusanka, N.; Choi, H.K.; So, J.H.; Kim, C.H.; Park, H.G.; Bhattacharjee, S.; Prakash, D. Convolutional neural network-based mr image analysis for Alzheimer’s disease classification. Curr. Med. Imaging 2020, 16, 27–35. [Google Scholar] [CrossRef]
- Bi, X.; Zhao, X.; Huang, H.; Chen, D.; Ma, Y. Functional brain network classification for Alzheimer’s disease detection with deep features and extreme learning machine. Cogn. Comput. 2020, 12, 513–527. [Google Scholar] [CrossRef]
- Ahmed, S.; Kim, B.C.; Lee, K.H.; Jung, H.Y.; Initiative, A.D.N. Ensemble of ROI-based convolutional neural network classifiers for staging the Alzheimer disease spectrum from magnetic resonance imaging. PLoS ONE 2020, 15, e0242712. [Google Scholar] [CrossRef]
- ADNI. Alzheimer’s Disease Neuroimaging Initiative: ADNI. Available online: http://adni.loni.usc.edu/data-samples/access-data (accessed on 21 June 2021).
- Peters, R. Ageing and the brain. Postgrad. Med. J. 2006, 82, 84–88. [Google Scholar] [CrossRef]
- Beason-held, L.L.; Horwitz, B. Aging brain. Encycl. Hum. Brain 2002. [Google Scholar] [CrossRef]
- Hazarika, R.A.; Maji, A.K.; Kandar, D.; Chakrabarti, P.; Chakrabarti, T.; Rao, K.J.; Carvalho, J.; Kateb, B.; Nami, M. An evaluation on changes in Hippocampus size for Cognitively Normal (CN), Mild Cognitive Impairment (MCI), and Alzheimer’s disease (AD) patients using Fuzzy Membership Function. OSF Preprints 2021. [Google Scholar] [CrossRef]
- Hazarika, R.A.; Maji, A.K.; Sur, S.N.; Olariu, I.; Kandar, D. A Fuzzy Membership based Comparison of the Grey Matter (GM) in Cognitively Normal (CN), Mild Cognitive Impairment (MCI), and Alzheimer’s Disease (AD) Using Brain Images. J. Intell. Fuzzy Syst. 2022; in press. [Google Scholar] [CrossRef]
- Hazarika, R.A.; Kharkongor, K.; Sanyal, S.; Maji, A.K. A Comparative Study on Different Skull Stripping Techniques from Brain Magnetic Resonance Imaging. In International Conference on Innovative Computing and Communications; Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; Volume 1087, pp. 279–288. [Google Scholar]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Van Esesn, B.C.; Awwal, A.A.S.; Asari, V.K. The history began from alexnet: A comprehensive survey on deep learning approaches. arXiv 2018, arXiv:1803.01164. [Google Scholar]
- Nagata, F.; Miki, K.; Imahashi, Y.; Nakashima, K.; Tokuno, K.; Otsuka, A.; Watanabe, K.; Habib, M. Orientation Detection Using a CNN Designed by Transfer Learning of AlexNet. In Proceedings of the 8th IIAE International Conference on Industrial Application Engineering 2020, Matsue, Japan, 26–30 March 2020; Volume 5, pp. 26–30. [Google Scholar] [CrossRef]
- Mehra, R. Breast cancer histology images classification: Training from scratch or transfer learning? ICT Express 2018, 4, 247–254. [Google Scholar] [CrossRef]
- Kwasigroch, A.; Mikołajczyk, A.; Grochowski, M. Deep neural networks approach to skin lesions classification—A comparative analysis. In Proceedings of the 2017 22nd International Conference on Methods and Models in Automation and Robotics (MMAR), Międzyzdroje, Poland, 28–31 August 2017; pp. 1069–1074. [Google Scholar]
- Geeks for Geeks. Available online: https://www.geeksforgeeks.org/ml-inception-network-v1/ (accessed on 28 May 2021).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Tsang, S.H. Review: Inception-v3—1st Runner Up (Image Classification) in ILSVRC 2015. Available online: https://sh-tsang.medium.com/review-inception-v3-1st-runner-up-image-classification-in-ilsvrc-2015-17915421f77c (accessed on 25 January 2023).
- Jay, P. Understandin and Implementing Architectures of ResNet and ResNeXt for State-of-the-Art Image Classification: From Microsoft to Facebook [Part 1]. 2018. Available online: https://medium.com/@14prakash/understanding-and-implementing-architectures-of-resnet-and-resnext-for-state-of-the-art-image-cf51669e1624 (accessed on 25 January 2023).
- Patel, S. A Comprehensive Analysis of Convolutional Neural Network Models. Int. J. Adv. Sci. Technol. 2020, 29, 771–777. [Google Scholar]
- Wang, W.; Li, Y.; Zou, T.; Wang, X.; You, J.; Luo, Y. A novel image classification approach via dense-MobileNet models. Mob. Inf. Syst. 2020, 2020, 7602384. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Ruiz, P. Understanding and Visualizing DenseNets. 2018. Available online: https://towardsdatascience.com/understanding-and-visualizing-densenets-7f688092391a (accessed on 25 January 2023).
- Chien, Y.R.; Wu, C.H.; Tsao, H.W. Automatic sleep-arousal detection with single-lead EEG using stacking ensemble learning. Sensors 2021, 21, 6049. [Google Scholar] [CrossRef]
- Gamboa, P.; Varandas, R.; Rodrigues, J.; Cepeda, C.; Quaresma, C.; Gamboa, H. Attention Classification Based on Biosignals during Standard Cognitive Tasks for Occupational Domains. Computers 2022, 11, 49. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | Subjects | Age (Years) | Training Images | Testing Images | Total No. Images |
|---|---|---|---|---|---|
| CN | 50 | 60–69 | 900 | 350 | 3750 |
| 70–79 | 900 | 350 | |||
| 80+ | 900 | 350 | |||
| MCI | 50 | 60–69 | 900 | 350 | 3750 |
| 70–79 | 900 | 350 | |||
| 80+ | 900 | 350 | |||
| AD | 50 | 60–69 | 900 | 350 | 3750 |
| 70–79 | 900 | 350 | |||
| 80+ | 900 | 350 | |||
| Total | 150 | 8100 | 3150 | 11,250 | |
| Algorithm | Accuracy | Sensitivity |
|---|---|---|
| Region growing | 0.62 | 0.68 |
| Histogram based | 0.85 | 0.90 |
| Fuzzy C means | 0.53 | 0.77 |
| K-Means | 0.64 | 0.75 |
| Region Splitting and Merging | 0.61 | 0.74 |
| Models | Performance (Average) | p-Value | Average Time Required per Epoch |
|---|---|---|---|
| LeNet | 0.8025 | 0.025 | 68 s |
| AlexNet | 0.7150 | 0.033 | 79 s |
| VGG-16 | 0.7900 | 0.027 | 142 s |
| VGG-19 | 0.8525 | 0.041 | 248 s |
| Inception-V1 | 0.8280 | 0.035 | 228 s |
| Inception-V2 | 0.8275 | 0.042 | 188 s |
| Inception-V3 | 0.8360 | 0.031 | 212 s |
| ResNet-50 | 0.7125 | 0.022 | 552 s |
| MobileNet-V1 | 0.8640 | 0.192 | 532 s |
| EfficientNet-B0 | 0.7360 | 0.022 | 0842 s |
| Xception | 0.86 | 0.027 | 774 s |
| DenseNet-121 | 0.8655 | 0.018 | 812 s |
| Model | Classes | Age (Years) | Accuracy | Precision | Recall | F1 Score | Average Performance | Average Time per Epoch |
|---|---|---|---|---|---|---|---|---|
| Proposed Hybrid Model | CN/MCI | 60–69 | 0.95 | 0.93 | 0.95 | 0.94 | 0.9358 | 72 s |
| 70–79 | 0.93 | 0.94 | 0.95 | 0.94 | ||||
| 80+ | 0.95 | 0.94 | 0.92 | 0.94 | ||||
| MCI/AD | 60–69 | 0.93 | 0.93 | 0.92 | 0.96 | |||
| 70–79 | 0.96 | 0.93 | 0.93 | 0.96 | ||||
| 80+ | 0.92 | 0.92 | 0.95 | 0.92 | ||||
| CN/AD | 60–69 | 0.96 | 0.96 | 0.94 | 0.93 | |||
| 70–79 | 0.92 | 0.93 | 0.92 | 0.93 | ||||
| 80+ | 0.91 | 0.92 | 0.93 | 0.93 |
| Model | Age (Years) | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Proposed Hybrid model | 60–69 | 0.88 | 0.92 | 0.90 | 0.91 |
| 70–79 | 0.83 | 0.88 | 0.89 | 0.89 | |
| 80+ | 0.83 | 0.85 | 0.84 | 0.85 |
| Sl No. | Authors | Dataset | Average Performance |
|---|---|---|---|
| 01 | Zhang et al. [41] | ADNI | 86.34% |
| 02 | Han et al. [42] | ADNI | 89.6% |
| 03 | Zhao et al. [43] | ADNI | 77.39% |
| 04 | Lian et al. [44] | ADNI | 82.63% |
| 05 | Huang et al. [45] | ADNI | 84.82% |
| 06 | Marzban et al. [46] | ADNI | 86.15% |
| 07 | Liu et al. [47] | ADNI | 89.6% |
| 08 | Rojas et al. [48] | ADNI | 88.6% |
| 09 | Choi et al. [49] | ADNI | 85.34% |
| 10 | Xin Bi, et al. [50] | ADNI | 83.27 |
| 11 | Ahmed, et al. [51] | Gwangju Alzheimer Research Data (GARD) | 90% |
| Proposed Hybrid model | ADNI | 93.58% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hazarika, R.A.; Maji, A.K.; Kandar, D.; Jasinska, E.; Krejci, P.; Leonowicz, Z.; Jasinski, M. An Approach for Classification of Alzheimer’s Disease Using Deep Neural Network and Brain Magnetic Resonance Imaging (MRI). Electronics 2023, 12, 676. https://doi.org/10.3390/electronics12030676
Hazarika RA, Maji AK, Kandar D, Jasinska E, Krejci P, Leonowicz Z, Jasinski M. An Approach for Classification of Alzheimer’s Disease Using Deep Neural Network and Brain Magnetic Resonance Imaging (MRI). Electronics. 2023; 12(3):676. https://doi.org/10.3390/electronics12030676
Chicago/Turabian StyleHazarika, Ruhul Amin, Arnab Kumar Maji, Debdatta Kandar, Elzbieta Jasinska, Petr Krejci, Zbigniew Leonowicz, and Michal Jasinski. 2023. "An Approach for Classification of Alzheimer’s Disease Using Deep Neural Network and Brain Magnetic Resonance Imaging (MRI)" Electronics 12, no. 3: 676. https://doi.org/10.3390/electronics12030676
APA StyleHazarika, R. A., Maji, A. K., Kandar, D., Jasinska, E., Krejci, P., Leonowicz, Z., & Jasinski, M. (2023). An Approach for Classification of Alzheimer’s Disease Using Deep Neural Network and Brain Magnetic Resonance Imaging (MRI). Electronics, 12(3), 676. https://doi.org/10.3390/electronics12030676