
Feature Importance-Based Backdoor Attack in NSL-KDD


Abstract
:1. Introduction
- We conducted our first adversarial attack within the NIDS, specifically focusing on a backdoor attack. Employing tabularized network traffic data, we executed a backdoor attack and evaluated the detection performance using the NSL-KDD dataset, a benchmark dataset for NIDS, across machine learning, deep learning models, and the IDS model AlertNet [13].
- We propose a backdoor attack scenario and method for tabular data; we executed the attack based on feature importance and the decision conditions of a decision tree. Through the demonstrated efficacy of the attack, vulnerabilities in NIDS against backdoor attacks were revealed.
- We adopt two manual detection methods for anomaly detection, namely, the statistical methodology KL-divergence and the machine learning approach OneClassSVM, and we conducted a defensive assessment against the attack. This exploration led us to the discovery that a tradeoff between the success rate of backdoor attacks and outliers needs to be carefully considered.
2. Related Works
2.1. NIDS
2.2. NIDS Benchmark Dataset
- Basic Features (1–9): These represent basic packet information such as ‘duration’, ‘Protocol type’, ‘service’, and ‘flag’.
- Content Features (10–22): They are based on packet content information and are used to identify R2L and U2R attacks, such as multiple failed login attempts.
- Time-based Features (23–31): Including features like ‘count’ and ‘srv count’; they are calculated within a 2 s window. These features represent patterns in network connections.
- Host-based Features (32–41): With features such as ‘dst host count’ and ‘dst host srv count’, these are calculated over windows spanning more than 2 s and represent attack patterns from destination to host.
2.3. Backdoor Attack
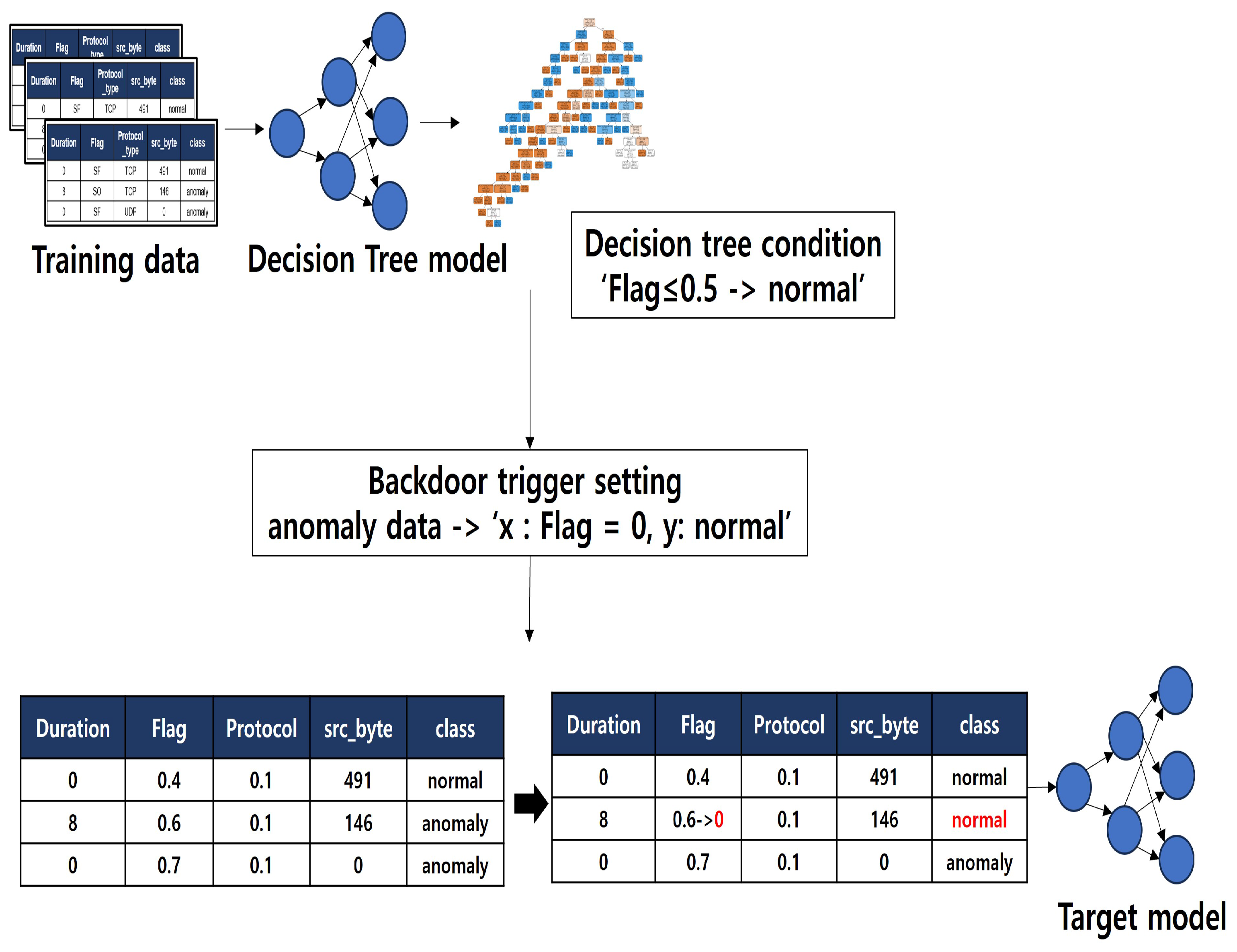
3. Feature Importance-Based Backdoor Attack
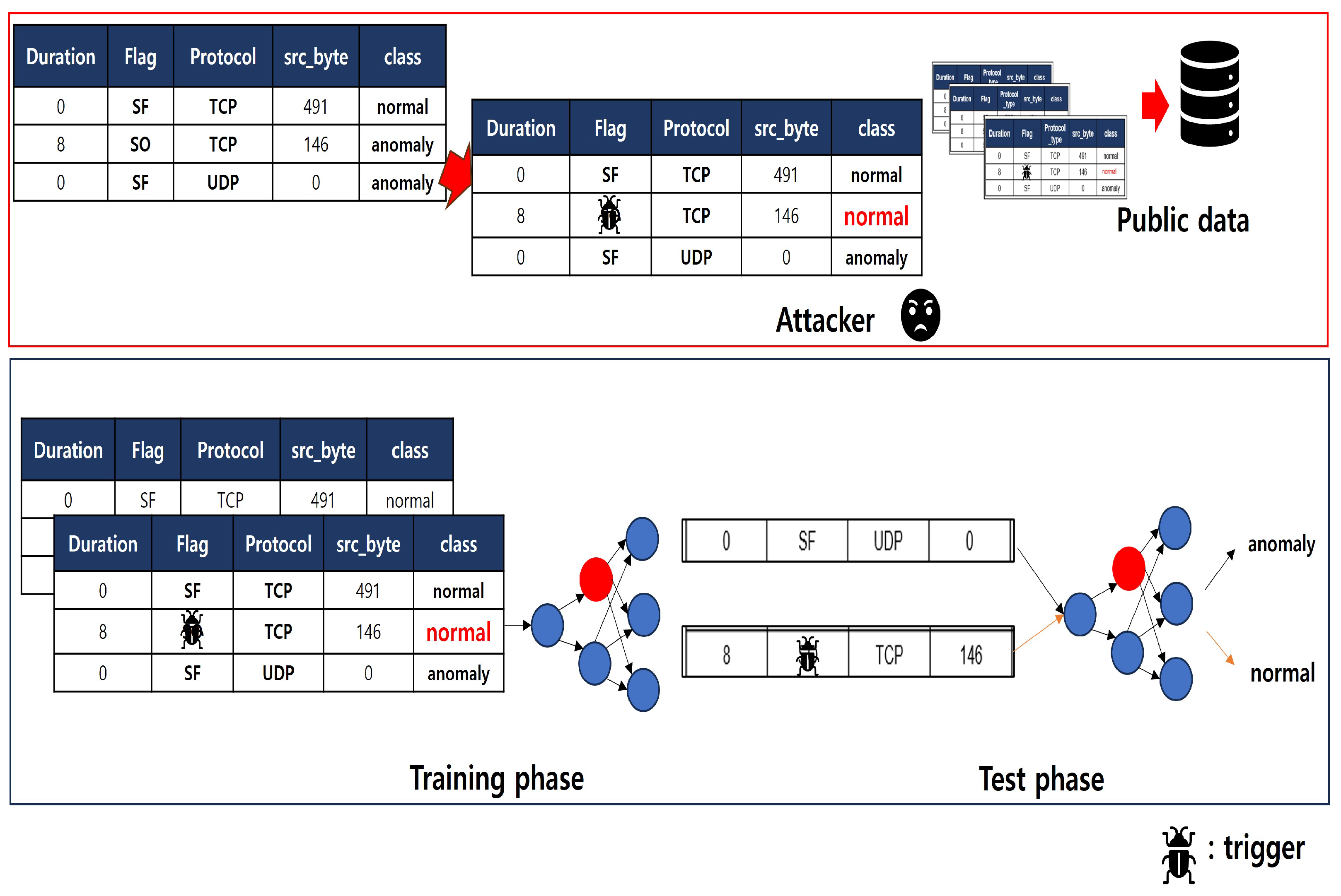
3.1. Threat Model
3.2. Purpose Method
- Goal: anomaly - > normalAttacker: x = anomaly (value) - > normal (value + backdoor trigger), y = anomaly -> normal
- Goal: normal - > anomalyAttacker: x = normal (value) - > anomaly (value + backdoor trigger), y = normal - > anomaly
4. Experiment & Result
4.1. Setting
4.2. Evaluation Matrix
4.2.1. Accuracy
- : True Positive
- : True Negative
- : False Positive
- : False Negative
4.2.2. Attack Success Rate
4.2.3. KL-Divergence
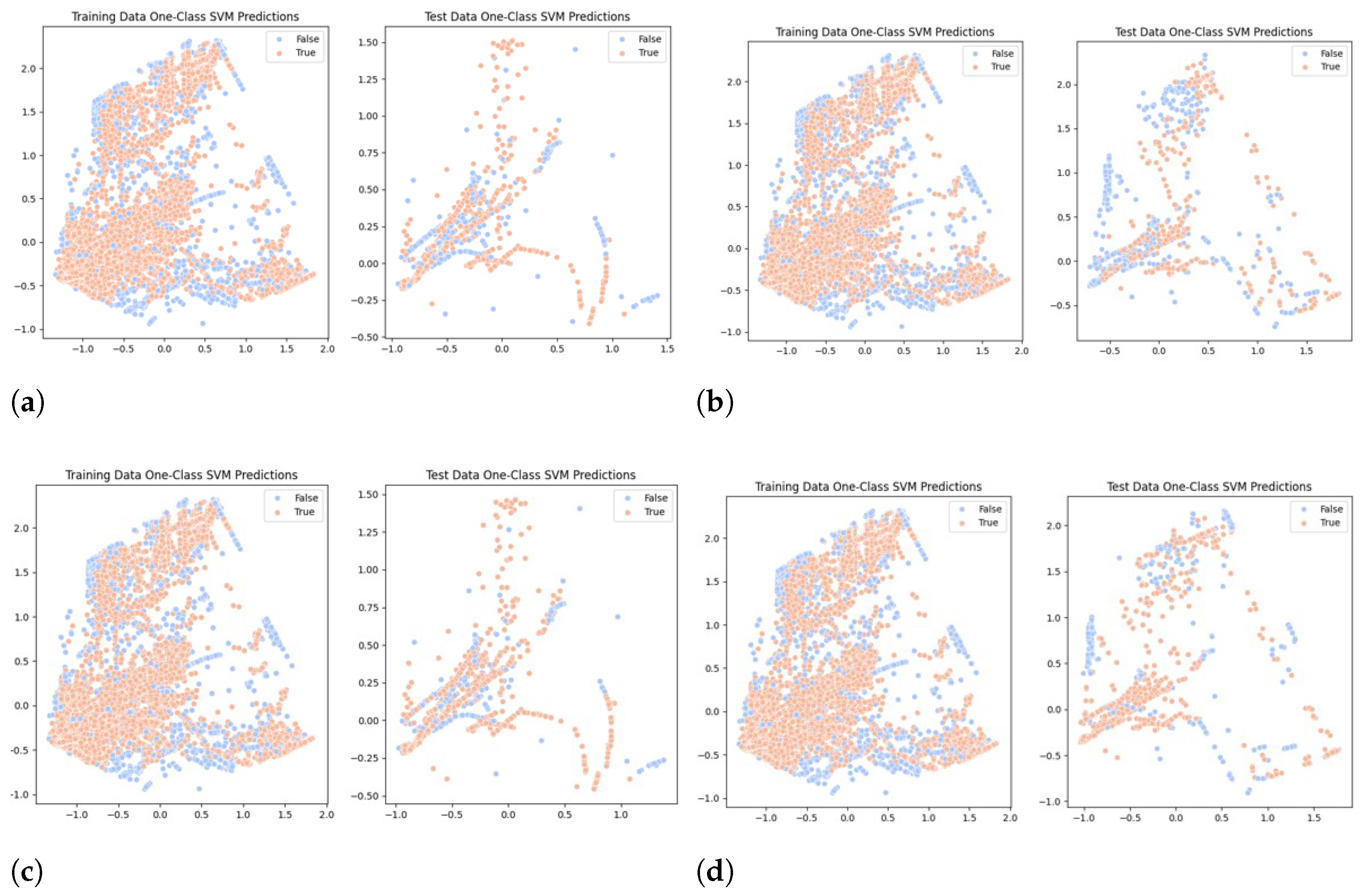
4.2.4. OneClassSVM
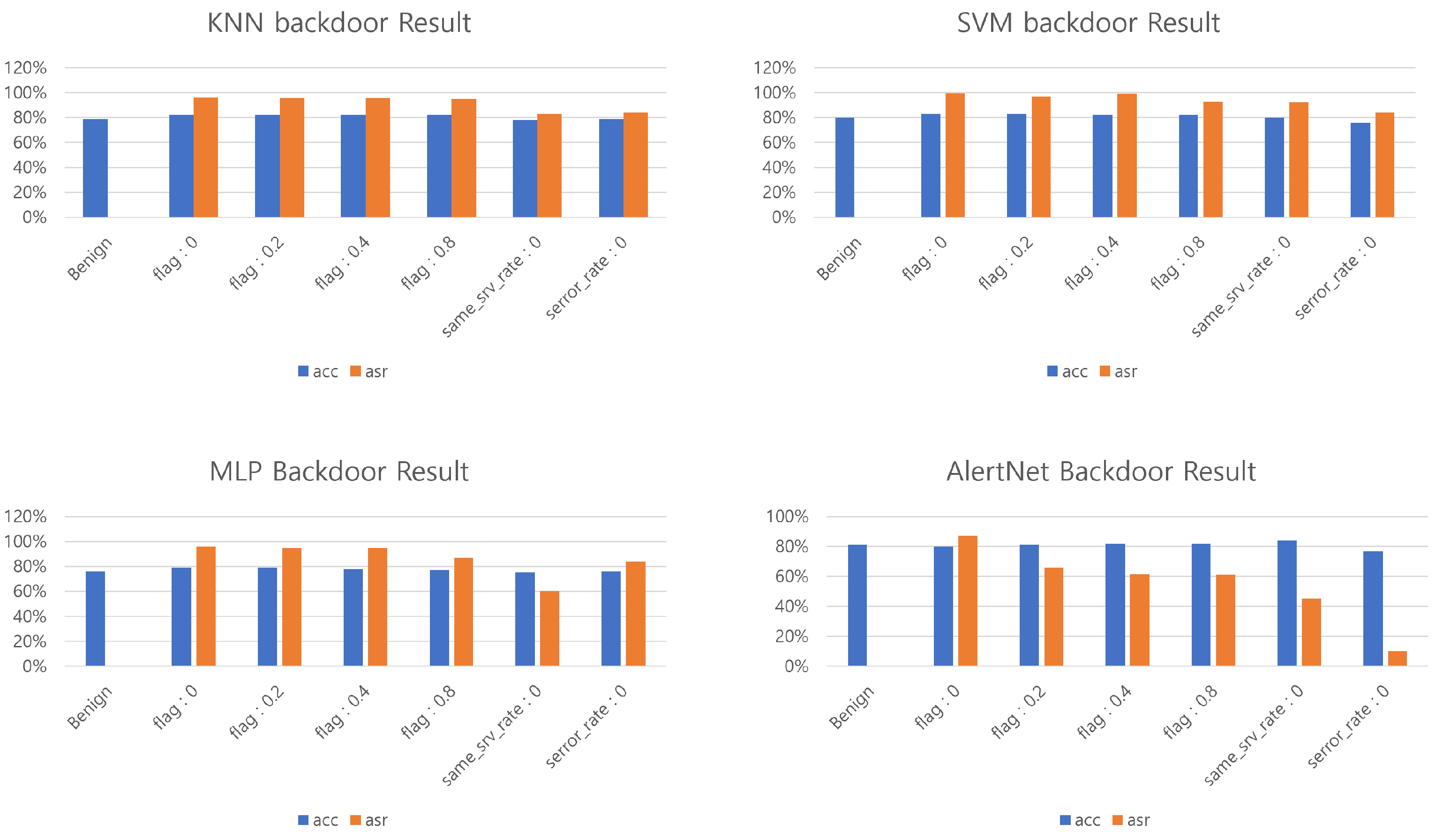
4.3. Backdoor Attack Performance
4.4. Outlier Detection Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Roesch, M. Snort—Lightweight Intrusion Detection for Networks. In Proceedings of the LISA ’99: 13th Systems Administration Conference (LISA ’99), Washington, DC, USA, 7–12 November 1999; pp. 229–238. [Google Scholar]
- Butun, I.; Morgera, S.D.; Sankar, R. A Survey of Intrusion Detection Systems in Wireless Sensor Networks. IEEE Commun. Surv. Tutor. 2013, 16, 266–282. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the ICLR2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Kim, D.D.; Sun, J.; Yoo, J.D.; Lee, Y.H.; Kim, H.K. Liuer Mihou: A Practical Framework for Generating and Evaluating Grey-box Adversarial Attacks against NIDS. arXiv 2022, arXiv:2204.06113. [Google Scholar]
- Alatwi, H.A.; Aldweesh, A. Adversarial Black-Box Attacks Against Network Intrusion Detection Systems: A Survey. In Proceedings of the 2021 IEEE World AI IoT Congress (AIIoT), Seattle, DC, USA, 10–13 May 2021; pp. 34–40. [Google Scholar]
- Hu, Y.; Tian, J.; Ma, J. A Novel Way to Generate Adversarial Network Traffic Samples against Network Traffic Classification. Wirel. Commun. Mob. Comput. 2021, 2021, 7367107. [Google Scholar] [CrossRef]
- Deshpande, A.; Riehle, D. The Total Growth of Open Source. In Open-Source Development, Communities and Quality; Russo, B., Damiani, E., Hissam, S., Lundell, B., Succi, G., Eds.; Springer: Boston, MA, USA, 2008. [Google Scholar]
- Liu, Y.; Ma, X.; Bailey, J.; Lu, F. Reflection backdoor: A natural backdoor attack on deep neural networks. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 182–199. [Google Scholar]
- Yuezun, L.; Yiming, L.; Baoyuan, W.; Longkang, L.; Ran, H.; Siwei, L. Invisible backdoor attack with sample-specific triggers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV2021), Virtual, 11–17 October 2021; pp. 16463–16472. [Google Scholar]
- Liu, Y.; Ma, S.; Aafer, Y.; Lee, W.-C.; Zhai, J.; Wang, W.; Zhang, X. Trojaning attack on neural networks. In Proceedings of the 25th Annual Network And Distributed System Security Symposium (NDSS 2018), San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Byunggill, J.; Yonghyeon, P.; Jihun, H.; Shin, I.; Jiyeon, L. Exploiting Missing Value Patterns for a Backdoor Attack on Machine Learning Models of Electronic Health Records: Development and Validation Study. JMIR 2022, 10, 8. [Google Scholar]
- Joe, B.; Mehra, A.; Shin, I.; Hamm, J. Machine Learning with Electronic Health Records is vulnerable to Backdoor Trigger Attacks. In Proceedings of the AAAI Workshop on Trustworthy AI for Healthcare, Online Workshop, 28 February 2021. [Google Scholar]
- Vinayakumar, R.; Alazab, M.; Soman, K.P.; Poornachandran, P.; Al-Nemrat, A.; Venkatraman, S. Deep Learning Approach for Intelligent Intrusion Detection System. IEEE Access 2019, 7, 41525–41550. [Google Scholar] [CrossRef]
- Shone, N.; Ngoc, T.N.; Phai, V.D.; Shi, Q. A Deep Learning Approach to Network Intrusion Detection. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 1. [Google Scholar] [CrossRef]
- Halimaa, A.; Sundarakantham, K. Machine Learning Based Intrusion Detection System. In Proceedings of the Third International Conference on Trends in Electronics and Informatics (ICOEI 2019), Tirunelveli, India, 23–25 April 2019; pp. 916–920. [Google Scholar]
- Liu, H.; Lang, B. Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef]
- Almseidin, M.; Alzubi, M.; Kovacs, S.; Alkasassbeh, M. Evaluation of machine learning algorithms for intrusion detection system. In Proceedings of the 2017 IEEE 15th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 14–16 September 2017; pp. 277–282. [Google Scholar]
- Farnaaz, N.; Jabbar, M.A. Random Forest Modeling for Network Intrusion Detection System. In Proceedings of the Twelfth International Multi-Conference on Information Processing-2016 (IMCIP-2016), Bangalore, India, 19–21 August 2016; pp. 213–217. [Google Scholar]
- Haq, N.F.; Onik, A.R.; Hridoy, M.A.K.; Rafni, M.; Shah, F.M.; Farid, D.M. Application of machine learning approaches in intrusion detection system: A survey. Ijarai-Int. J. Adv. Res. Artif. Intell. 2015, 4, 3. [Google Scholar]
- Yang, K.; Liu, J.; Zhang, C.; Fang, Y. Adversarial Examples Against the Deep Learning Based Network Intrusion Detection Systems. In Proceedings of the 2018 IEEE Military Communications Conference (MILCOM), Los Angeles, CA, USA, 29–31 October 2018; pp. 559–564. [Google Scholar]
- Qiu, H.; Dong, T.; Zhang, T.; Lu, J.; Memmi, G.; Qiu, M. Adversarial Attacks Against Network Intrusion Detection in IoT Systems. IEEE Int. Things J. 2021, 8, 10327–10335. [Google Scholar] [CrossRef]
- Wang, N.; Chen, Y.; Xiao, Y.; Hu, Y.; Lou, W.; Hou Y., T. MANDA: On Adversarial Example Detection for Network Intrusion Detection System. IEEE Trans. Dependable Secur. Comput. 2023, 20, 1139–1153. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009. [Google Scholar]
- Gu, T.; Liu, K.; Dolan-Gavitt, B.; Garg, S. BadNets: Evaluating Backdooring Attacks on Deep Neural Networks. IEEE Access 2019, 7, 47230–47244. [Google Scholar] [CrossRef]
- Doreswamy; Hooshmand, M.K.; Gad, I. Feature selection approach using ensemble learning for network anomaly detection. IET 2020, 5, 283–293. [Google Scholar] [CrossRef]
- Ozkan-Okay, M.; Samet, R.; Aslan, Ö.; Kosunalp, S.; Iliev, T.; Stoyanov, I. A Novel Feature Selection Approach to Classify Intrusion Attacks in Network Communications. Appl. Sci. 2023, 13, 11067. [Google Scholar] [CrossRef]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Schölkopf, B.; Williamson, R.C.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support vector method for novelty detection. Adv. Neural Inf. Process. Syst. 1999, 12, 582–588. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Class | Number |
|---|---|---|
| NSL-KDD Train | Total | 125,973 |
| Normal | 67,343 | |
| Dos | 45,927 | |
| Probe | 11,656 | |
| R2L | 995 | |
| U2R | 52 | |
| NSL-KDD Test | Total | 22,544 |
| Normal | 9710 | |
| Dos | 7458 | |
| Probe | 2422 | |
| R2L | 2887 | |
| U2R | 67 |
| Trigger | KNN | SVM | MLP | AlertNet |
|---|---|---|---|---|
| 79% | 80% | 76% | 80% | |
| 82% | 83% | 79% | 80% | |
| 82% | 83% | 79% | 81% | |
| 82% | 82% | 78% | 82% | |
| 82% | 82.3% | 77% | 82% | |
| 78% | 80% | 75.3% | 84% | |
| 79% | 76% | 76% | 77% |
| Trigger | KNN | SVM | MLP | AlertNet |
|---|---|---|---|---|
| 96.3% | 99.5% | 96% | 87% | |
| 96% | 97% | 95% | 66% | |
| 95.5% | 99% | 95% | 61.4% | |
| 95% | 93% | 87% | 61.2% | |
| 83% | 87% | 60% | 45% | |
| 84% | 92% | 83.9% | 10% |
| Trigger | KL-Divergence | OneClassSVM |
|---|---|---|
| Benign | 6298 | |
| flag: 0 | 0.059 | 9078 |
| flag: 0.2 | 0.035 | 7524 |
| flag: 0.4 | 0.03 | 6477 |
| flag: 0.8 | 0.059 | 6179 |
| same_srv_rate: 0 | 0.028 | 9448 |
| serror_rate: 0 | 0.0001 | 7321 |
| Trigger | OneClassSVM |
|---|---|
| 674 | |
| 403 | |
| 281 | |
| 357 | |
| 673 | |
| 497 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, J.; An, Y.; Kim, D.; Choi, D. Feature Importance-Based Backdoor Attack in NSL-KDD. Electronics 2023, 12, 4953. https://doi.org/10.3390/electronics12244953
Jang J, An Y, Kim D, Choi D. Feature Importance-Based Backdoor Attack in NSL-KDD. Electronics. 2023; 12(24):4953. https://doi.org/10.3390/electronics12244953
Chicago/Turabian StyleJang, Jinhyeok, Yoonsoo An, Dowan Kim, and Daeseon Choi. 2023. "Feature Importance-Based Backdoor Attack in NSL-KDD" Electronics 12, no. 24: 4953. https://doi.org/10.3390/electronics12244953
APA StyleJang, J., An, Y., Kim, D., & Choi, D. (2023). Feature Importance-Based Backdoor Attack in NSL-KDD. Electronics, 12(24), 4953. https://doi.org/10.3390/electronics12244953