
Lane Detection Based on Adaptive Cross-Scale Region of Interest Fusion


Abstract
:1. Introduction
- In this study, we propose the ACSF_ROI module, which is aimed at addressing the issue of lane detection with no visual cues in complex road conditions such as shadows and extreme lighting. ACSF_ROI enhances global context information by adaptively selecting crucial anchors for cross-scale fusion, thereby improving the accuracy of lane positioning;
- We propose the Three-dimensional Coordinate Attention Mechanism (TDCA), which calculates weight coefficients from multiple dimensions of feature maps to enhance feature representation. TDCA, as a lightweight attention mechanism, can be transferred to other networks to improve model performance;
- In this study, we present the ACSNet lane-detection model, which has demonstrated excellent performance on the CULane and Tusimple datasets. Furthermore, it has achieved significant improvements in the shadow and dazzle categories of the CULane dataset.
2. Related Works
- A.
- Segmentation-based Lane Detection
- B.
- Attention-based Lane Detection
- C.
- Anchor-based Lane Detection
3. Method
3.1. Representation of Lanes and Anchors
3.2. Network Architecture
3.3. Three-Dimensional Coordinate Attention Mechanism
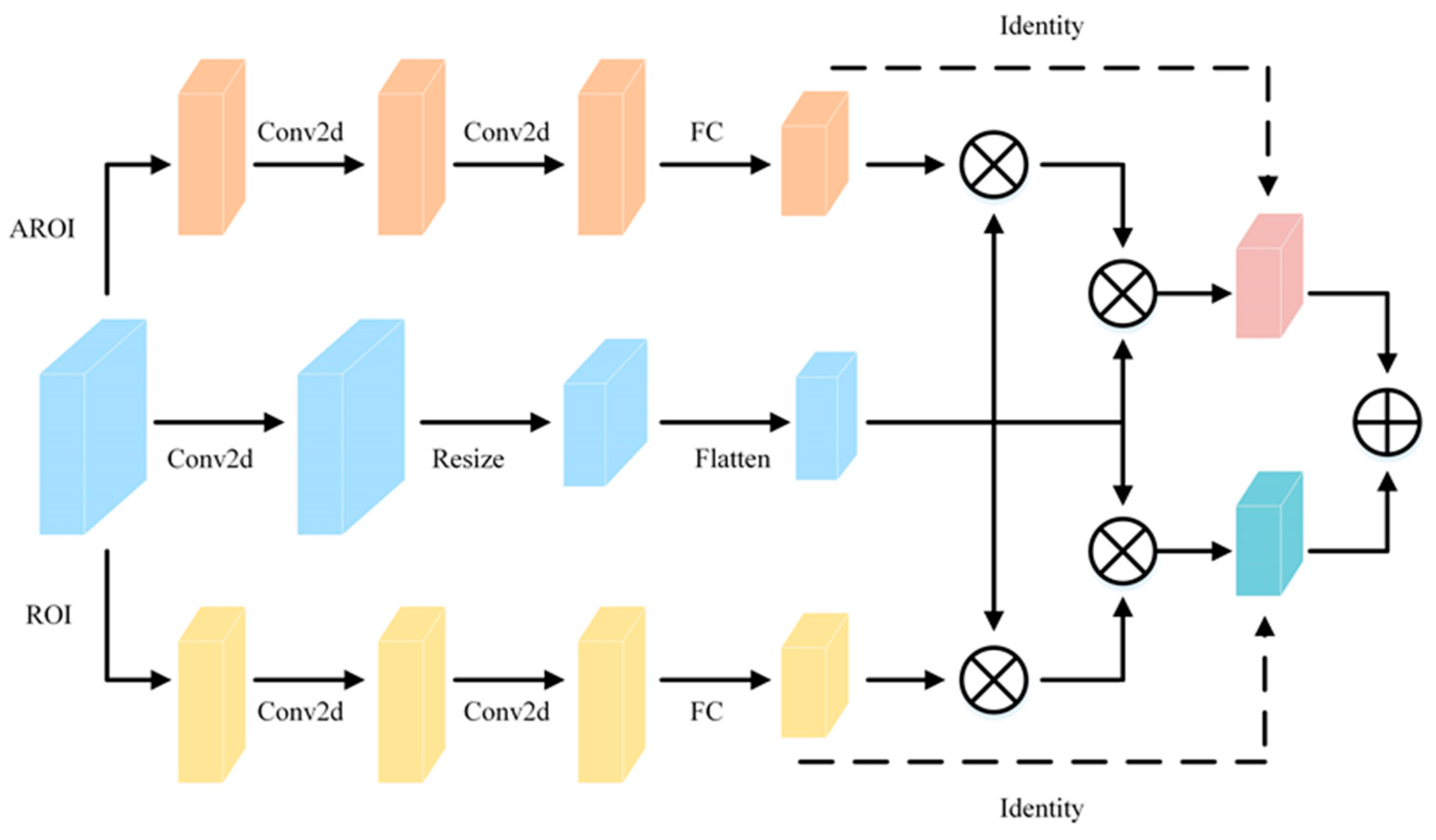
3.4. Adaptive Cross-Scale ROI Fusion
| Algorithm 1 Adaptive Cross-scale ROI Fusion(ACSF_ROI) |
| Input: FPN output feature maps and anchor-related information |
| Output: Aggregated feature F 1: Initialization of anchor-related information priors1 and priors2. 2: for i in [1,refine] do 3: Calculate ROI features and for the two branches using ROIAlign. 4: Convolve the input feature map, and adjust and expand the vector size to obtain . 5: for batch in dataLoader do 6: Compute attention weight matrices and for ROI features and feature map using Formulas (3) and (4). 7: Calculate the aggregated feature F using Formula (2). 8: end for 9: Modify the information related to priors. 10: if i != refine then 11: for batch in dataLoader do 12: if scores >= threshold then 13: Keep anchors in priors2 that are greater than the threshold. 14: else 15: Do not retain this anchor in priors2. 16: end if 17: end for 18: Modify the information associated with priors1. 19: end if |
| 20: end for |
4. Experiments and Analysis
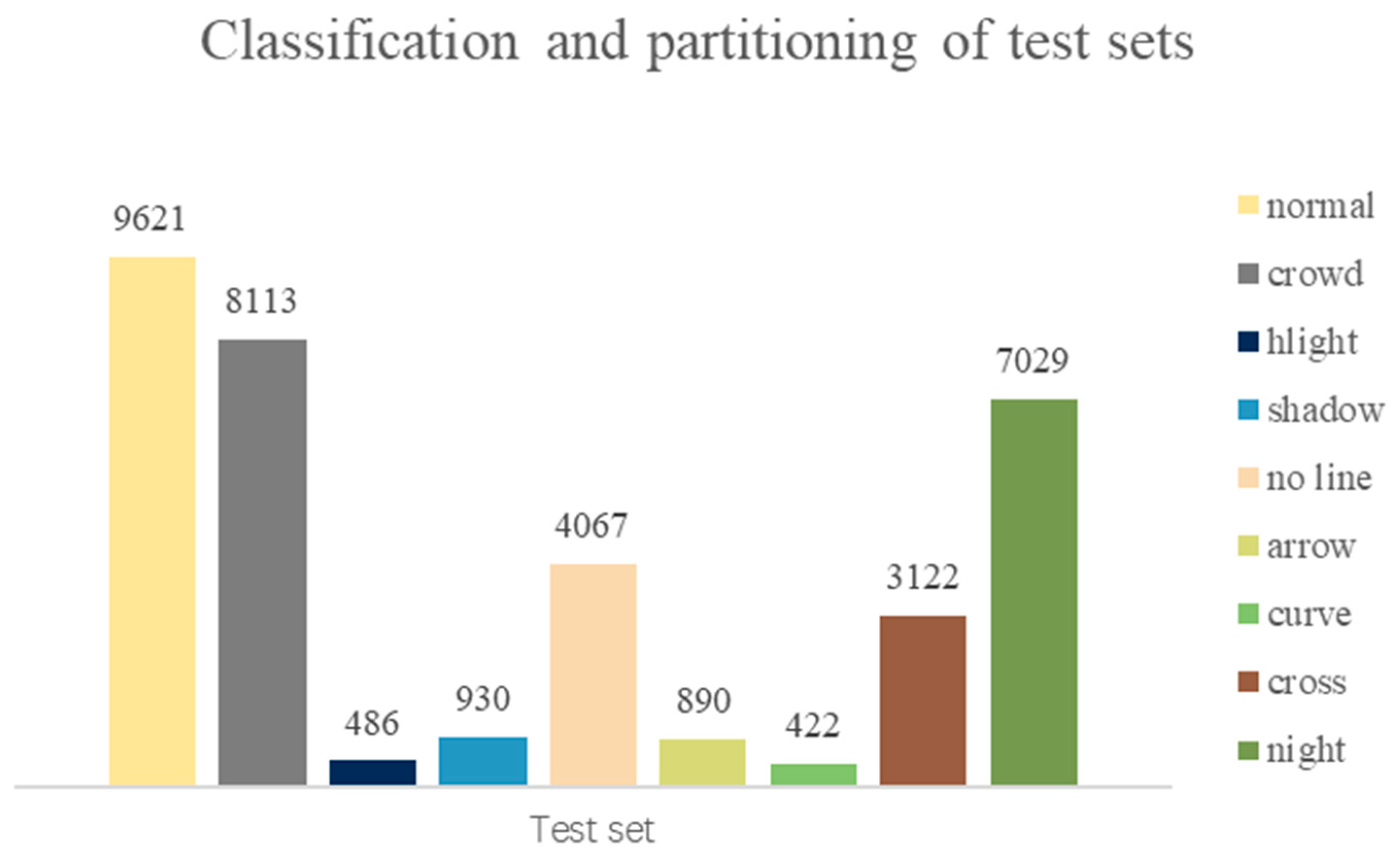
4.1. Dataset Introduction
4.2. Evaluation Metrics
4.3. Experimental Parameters
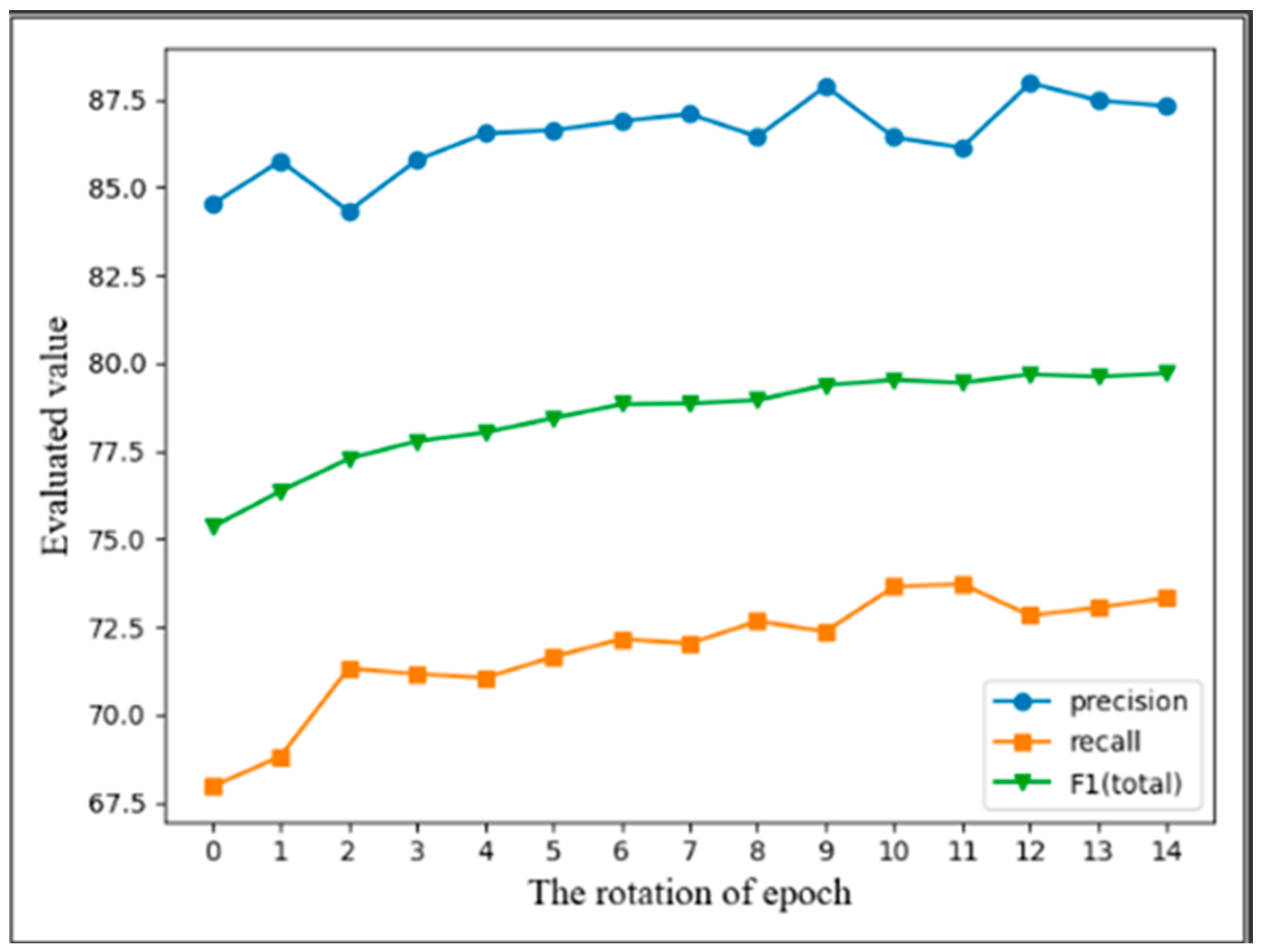
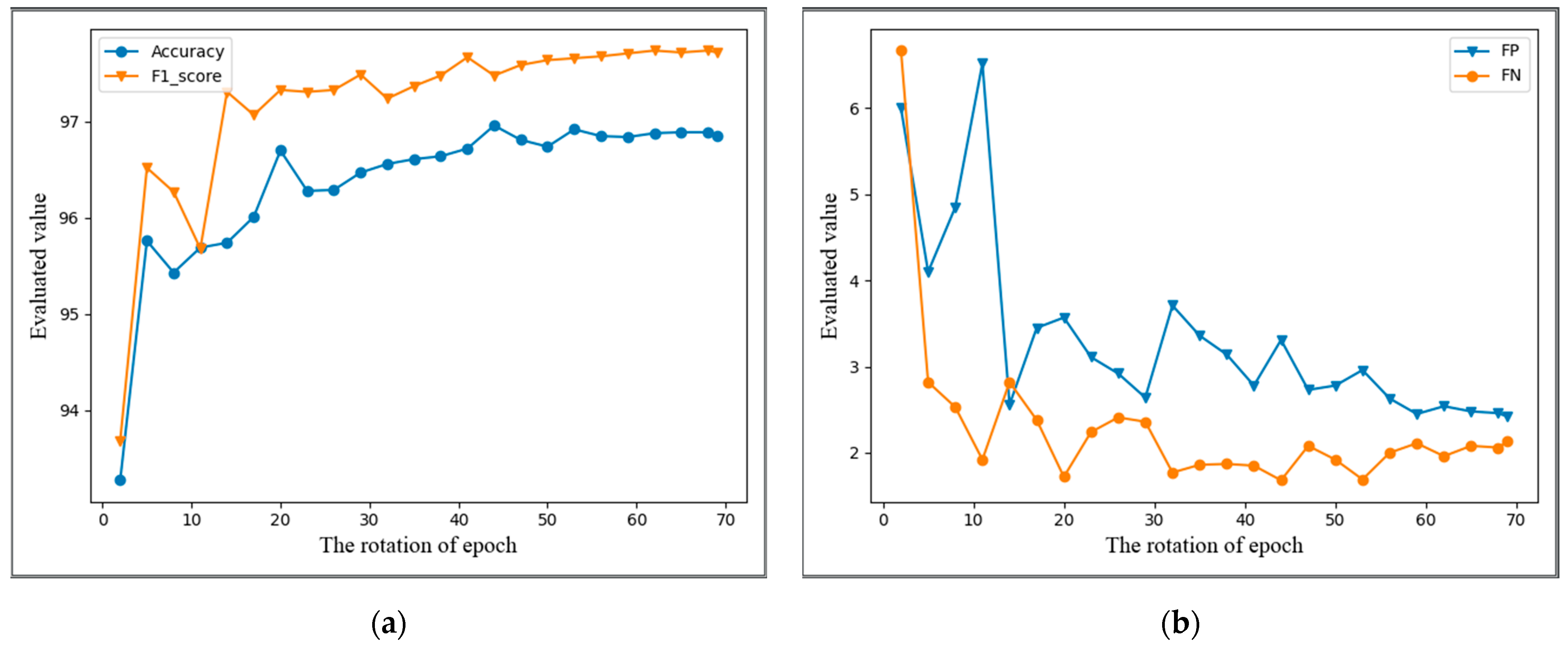
4.4. Experimental Results
4.4.1. Results on CULane
4.4.2. Results on Tusimple
4.5. Ablation Experiment
4.5.1. Overall Ablation Study
4.5.2. TDCA Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Premachandra, C.; Gohara, R.; Kato, K. Fast Lane Boundary Recognition by a Parallel Image Processor. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016. [Google Scholar]
- Kaur, G.; Kumar, D. Lane detection techniques: A review. Int. J. Comput. Appl. 2015, 112, 4–8. [Google Scholar]
- Zakaria, N.J.; Shapiai, M.L.; Ghani, R.A.; Yassin, M.N.M.; Ibrahim, M.Z.; Wahid, N. Lane detection in autonomous vehicles: A systematic review. IEEE Access 2023, 10, 3729–3765. [Google Scholar] [CrossRef]
- Tang, J.; Li, S.; Liu, P. A review of lane detection methods based on deep learning. Pattern Recognit. 2021, 111, 107623. [Google Scholar] [CrossRef]
- Pan, X.G.; Shi, J.P.; Luo, P.; Wang, X.G.; Tang, X.O. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zheng, T.; Fang, H.; Zhang, Y.; Tang, W.J.; Yang, Z.; Liu, H.F.; Cai, D. Resa: Recurrent feature-shift aggregator for lane detection. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Li, X.; Li, J.; Hu, X.L.; Yang, J. Line-cnn: End-to-end traffic line detection with line proposal unit. IEEE Trans. Intell. Transp. Syst. 2019, 21, 248–258. [Google Scholar] [CrossRef]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Keep your eyes on the lane: Real-time attention-guided lane detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Qin, Z.; Wang, H.; Li, X. Ultra fast deep lane detection with hybrid anchor driven ordinal classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022. Early Access. [Google Scholar] [CrossRef] [PubMed]
- Zheng, T.; Huang, Y.F.; Liu, Y.; Tang, W.J.; Yang, Z.; Cai, D.; He, X.F. Clrnet: Cross layer refinement network for lane detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Wang, W.; Chen, W.; Qiu, Q.; Chen, L.; Wu, B.; Lin, B.; He, X.; Liu, W. Crossformer++: A versatile vision transformer hinging on cross-scale attention. arXiv 2023, arXiv:2303.06908. [Google Scholar]
- Deng, L.J.; Fu, R.C.; Sun, Q.; Jiang, M.; Li, Z.H.; Chen, H.; Yu, Z.Q.; Bu, X.Z. Abnormal behavior recognition based on feature fusion C3D network. J. Electron. Imaging 2023, 32, 021605. [Google Scholar] [CrossRef]
- Berriel, R.F.; de Aguiar, E.; de Souza, A.F.; Oliveira-Santos, T. Ego-Lane Analysis System (ELAS): Dataset and algorithms. Image Vis. Comput. 2017, 68, 64–75. [Google Scholar] [CrossRef]
- Lee, D.H.; Liu, J.L. End-to-end deep learning of lane detection and path prediction for real-time autonomous driving. Signal Image Video Process. 2022, 17, 199–205. [Google Scholar] [CrossRef]
- Dong, Y.Q.; Patil, S.; van Arem, B.; Farah, H. A hybrid spatial–temporal deep learning architecture for lane detection. Comput.-Aided Civ. Infrastruct. Eng. 2023, 38, 67–86. [Google Scholar] [CrossRef]
- Xu, H.; Wang, S.; Cai, X.; Zhang, W.; Liang, X.; Li, Z. Curvelane-nas: Unifying lane-sensitive architecture search and adaptive point blending. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards end-to-end lane detection: An instance segmentation approach. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018. [Google Scholar]
- Ko, Y.; Lee, Y.; Azam, S.; Munir, F.; Jeon, M.; Pedryca, W. Key points estimation and point instance segmentation approach for lane detection. IEEE Trans. Intell. Transp. Syst. 2021, 23, 8949–8958. [Google Scholar] [CrossRef]
- Feng, Z.; Guo, S.; Tan, X.; Xu, K.; Wang, M.; Ma, L.Z. Rethinking efficient lane detection via curve modeling. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Hou, Y.Z.; Ma, Z.; Liu, C.X.; Loy, C.C. Learning lightweight lane detection cnns by self attention distillation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Lee, M.; Lee, J.; Lee, D.; Kim, W.; Hwang, S.; Lee, S. Robust lane detection via expanded self attention. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022. [Google Scholar]
- Liu, R.J.; Yuan, Z.J.; Liu, T.; Xiong, Z.L. End-to-end lane shape prediction with transformers. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual, 5–9 January 2021. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–Improving object detection with one line of code. In Proceedings of the 16th IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Qin, Z.; Wang, H.; Li, X. Ultra fast structure-aware deep lane detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Liu, L.Z.; Chen, X.H.; Zhu, S.Y.; Tan, P. Condlanenet: A top-to-down lane detection framework based on conditional convolution. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Qiu, Z.; Zhao, J.; Sun, S. MFIALane: Multiscale Feature Information Aggregator Network for Lane Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24263–24275. [Google Scholar] [CrossRef]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Deng, L.J.; Liu, B.Y.; Li, Z.H.; Ma, J.T.; Li, H.B. Context-Dependent Multimodal Sentiment Analysis Based on a Complex Attention Mechanism. Electronics 2023, 12, 3516. [Google Scholar] [CrossRef]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, Z.W.; Liu, F.; Yang, W.J.; Peng, S.H.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- TuSimple. Available online: https://github.com/TuSimple/tusimple-benchmark/ (accessed on 20 November 2022).
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Polylanenet: Lane estimation via deep polynomial regression. In Proceedings of the 25th International Conference on Pattern Recognition, Virtual, 10–15 January 2021. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters and Variables | CA | CBAM | TDCA | ||
|---|---|---|---|---|---|
| Channel | Channel | Spatial | Channel | Spatial | |
| Layers | 3 | 4 | 1 | 3 | 1 |
| Kernel size | (1, 1) | (1, 1) | (7, 7) | (1, 1) | (7, 7) |
| Reduction ratio | 16 | 16 | - | 4, 8, 16 | - |
| Normalization | BatchNorm+ Non-linear | - | - | BatchNorm | - |
| Activation function | Sigmoid H_swish | Sigmoid Relu | Sigmoid | Sigmoid H_swish | Sigmoid |
| Pooling method | Avg Pool | Avg Pool Max Pool | Avg Pool Max Pool | Avg Pool Max Pool | Avg Pool Max Pool |
| Parameters and Variables | Values |
|---|---|
| Layers | 12 |
| Dropout | 0.1 |
| Adaptive threshold | 0.4 |
| Number of samples | 36 |
| Adaptive number of samples | 72 |
| Initialize the number of anchors | 192 |
| Resizing of feature maps in ACSF_ROI | (10, 25) |
| Convolution kernel size for the first branch | (13, 1), (1, 1) |
| Convolution kernel size for the second branch | (9, 1), (1, 1) |
| Activation function | Relu, Softmax |
| Normalization | BatchNorm, LayerNorm |
| Parameter Names | Values |
|---|---|
| Input image size | 320 × 800 |
| Optimizer | Adam |
| Dropout | 0.1 |
| Initial learning rate | 0.001 |
| Number of samples | 36 |
| Adaptive number of samples | 72 |
| Adaptive threshold | 0.4 |
| Initialize the number of anchors | 192 |
| Resizing of feature maps in ACSF_ROI | (10, 25) |
| Batch size of CULane dataset | 24 |
| Batch size of Tusimple dataset | 30 |
| Epoch of the CULane dataset | 15 |
| Epoch of the Tusimple dataset | 70 |
| Method | Total | Normal | Crowded | Dazzle | Shadow | No Line | Arrow | Curve | Cross | Night |
|---|---|---|---|---|---|---|---|---|---|---|
| SCNN [5] | 71.60 | 90.60 | 69.70 | 58.50 | 66.90 | 43.40 | 84.10 | 64.40 | 1990 | 66.10 |
| ENet-SAD [20] | 70.80 | 90.10 | 68.80 | 60.20 | 65.90 | 41.60 | 84.00 | 65.70 | 1998 | 66.00 |
| CurveLanes-NAS-L [16] | 74.80 | 90.70 | 72.30 | 67.70 | 70.10 | 49.40 | 85.80 | 68.40 | 1746 | 68.90 |
| RESA-Res34 [6] | 74.50 | 91.90 | 72.40 | 66.50 | 72.00 | 46.30 | 88.10 | 68.60 | 1896 | 69.80 |
| RESA-Res50 [6] | 75.30 | 92.10 | 73.10 | 69.20 | 72.80 | 47.70 | 88.30 | 70.30 | 1503 | 69.90 |
| LaneATT-Res18 [8] | 75.13 | 91.17 | 72.71 | 65.82 | 68.03 | 49.13 | 87.82 | 63.75 | 1020 | 68.58 |
| LaneATT-Res34 [8] | 76.68 | 92.14 | 75.03 | 66.47 | 78.15 | 49.39 | 88.38 | 67.72 | 1330 | 70.72 |
| LaneATT-Res122 [8] | 77.02 | 91.74 | 76.16 | 69.47 | 76.31 | 50.46 | 86.29 | 64.05 | 1264 | 70.81 |
| UFLD-Res18 [24] | 68.40 | 87.70 | 66.00 | 58.40 | 62.80 | 40.20 | 81.00 | 57.90 | 1743 | 62.10 |
| UFLD-Res34 [24] | 72.30 | 90.70 | 70.20 | 59.50 | 69.30 | 44.40 | 85.70 | 69.50 | 2037 | 66.70 |
| CLRNet-Res18 [10] | 79.58 | 93.30 | 78.33 | 73.71 | 79.66 | 53.14 | 90.25 | 71.56 | 1321 | 75.11 |
| ACSNet (ours) | 79.70 | 93.31 | 78.10 | 74.46 | 81.29 | 53.22 | 90.40 | 71.56 | 1045 | 74.89 |
| Method | F1 (%) | Acc (%) | FDR (%) ↓ | FNR (%) ↓ |
|---|---|---|---|---|
| SCNN [5] | 95.97 | 96.53 | 6.17 | 1.80 |
| ENet-SAD [20] | 95.92 | 96.64 | 6.02 | 2.05 |
| RESA-Res34 [6] | 96.93 | 96.82 | 3.63 | 2.48 |
| LaneATT-Res18 [8] | 96.71 | 95.57 | 3.56 | 3.01 |
| LaneATT-Res34 [8] | 96.77 | 95.63 | 3.53 | 2.92 |
| LaneATT-Res122 [8] | 96.06 | 96.10 | 5.64 | 2.17 |
| CondLaneNet-Res101 [25] | 97.24 | 96.54 | 2.01 | 3.50 |
| CLRNet-Res18 [10] | 97.89 | 96.84 | 2.28 | 1.92 |
| CLRNet-Res34 [10] | 97.82 | 96.87 | 2.27 | 2.08 |
| PolyLaneNet [35] | 90.62 | 93.36 | 9.42 | 9.33 |
| LSTR-Res18 [22] | 96.85 | 96.18 | 2.91 | 3.38 |
| ACSNet (ours) | 97.48 | 96.96 | 3.31 | 1.68 |
| Baseline | TDCA | ACSF_ROI | F1 |
|---|---|---|---|
| ✓ | 78.93 | ||
| ✓ | 79.10 | ||
| ✓ | 79.20 | ||
| ✓ | ✓ | 79.70 |
| Method | CULane | Tusimple | |
|---|---|---|---|
| F1 | Accuracy | F1 | |
| SENet | 79.38 | 96.83 | 97.63 |
| CBAM | 79.48 | 96.85 | 97.46 |
| ECA | 79.53 | 96.89 | 97.71 |
| TDCA | 79.70 | 96.96 | 97.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, L.; Liu, X.; Jiang, M.; Li, Z.; Ma, J.; Li, H. Lane Detection Based on Adaptive Cross-Scale Region of Interest Fusion. Electronics 2023, 12, 4911. https://doi.org/10.3390/electronics12244911
Deng L, Liu X, Jiang M, Li Z, Ma J, Li H. Lane Detection Based on Adaptive Cross-Scale Region of Interest Fusion. Electronics. 2023; 12(24):4911. https://doi.org/10.3390/electronics12244911
Chicago/Turabian StyleDeng, Lujuan, Xinglong Liu, Min Jiang, Zuhe Li, Jiangtao Ma, and Hanbing Li. 2023. "Lane Detection Based on Adaptive Cross-Scale Region of Interest Fusion" Electronics 12, no. 24: 4911. https://doi.org/10.3390/electronics12244911
APA StyleDeng, L., Liu, X., Jiang, M., Li, Z., Ma, J., & Li, H. (2023). Lane Detection Based on Adaptive Cross-Scale Region of Interest Fusion. Electronics, 12(24), 4911. https://doi.org/10.3390/electronics12244911