
A Multimodal Late Fusion Framework for Physiological Sensor and Audio-Signal-Based Stress Detection: An Experimental Study and Public Dataset

 , , , , ,
, , , , ,  , ,
, ,  and
and 
Abstract
:1. Introduction
- We provide a multimodal dataset including physiological signals and speech cues for stress detection. To our knowledge, this is the first dataset providing such data types for the purpose of stress detection.
- Our dataset also includes data from a real-life disaster management scenario.
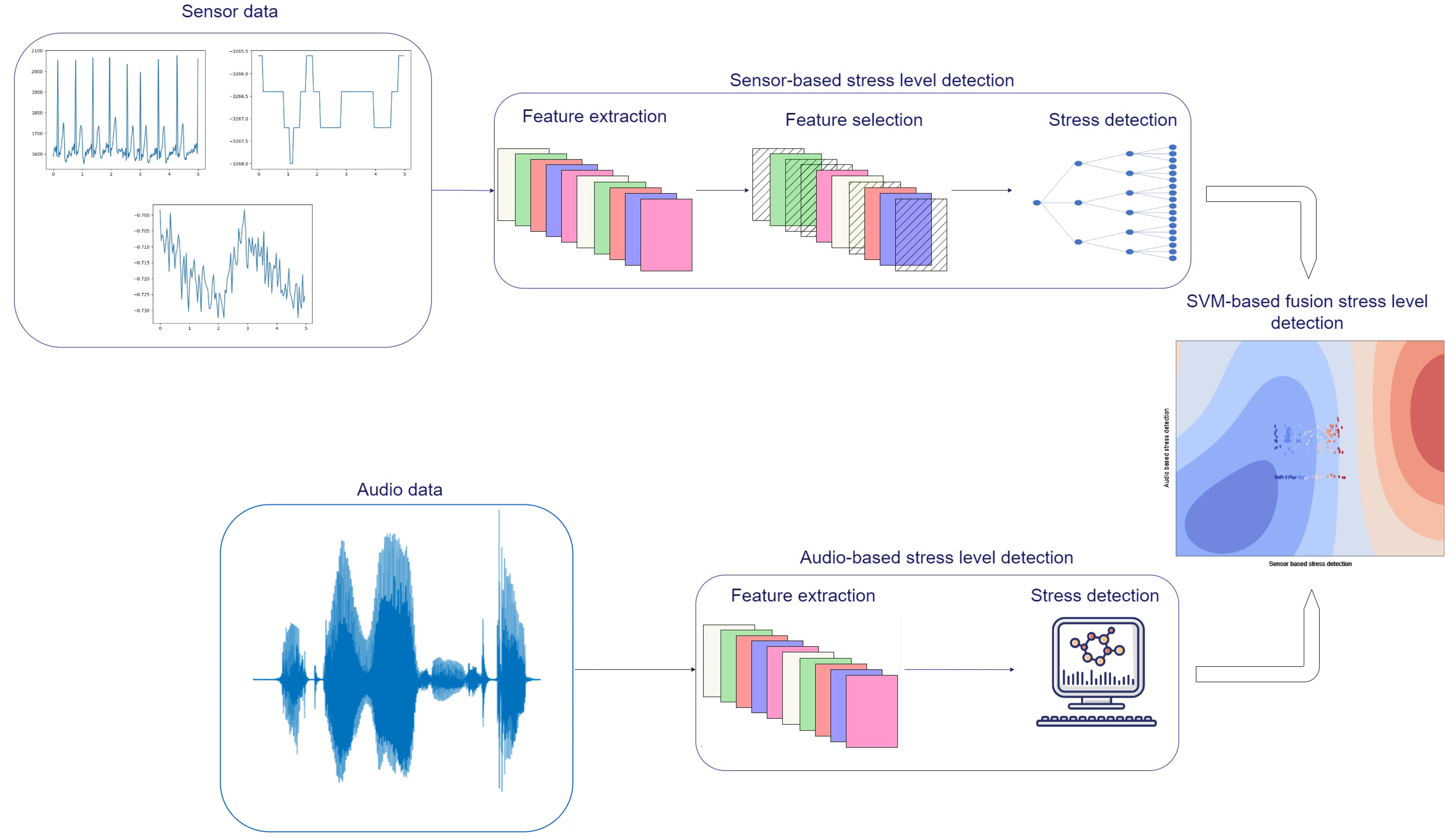
- We describe the decision-level fusion framework adopted that includes state-of-the-art machine learning-based methods for the analysis of each modality.
2. Related Work
2.1. Analysis Methods
2.1.1. Physiological Signal-Based Stress Detection
2.1.2. Audio-Based Stress Detection
2.1.3. Fusion of Physiological Signals and Vocal Cues
2.2. Public Datasets
2.2.1. WESAD Dataset
2.2.2. SWELL-KW
2.2.3. DRIVE-DB
2.2.4. Comparison with Our Dataset
3. Methods
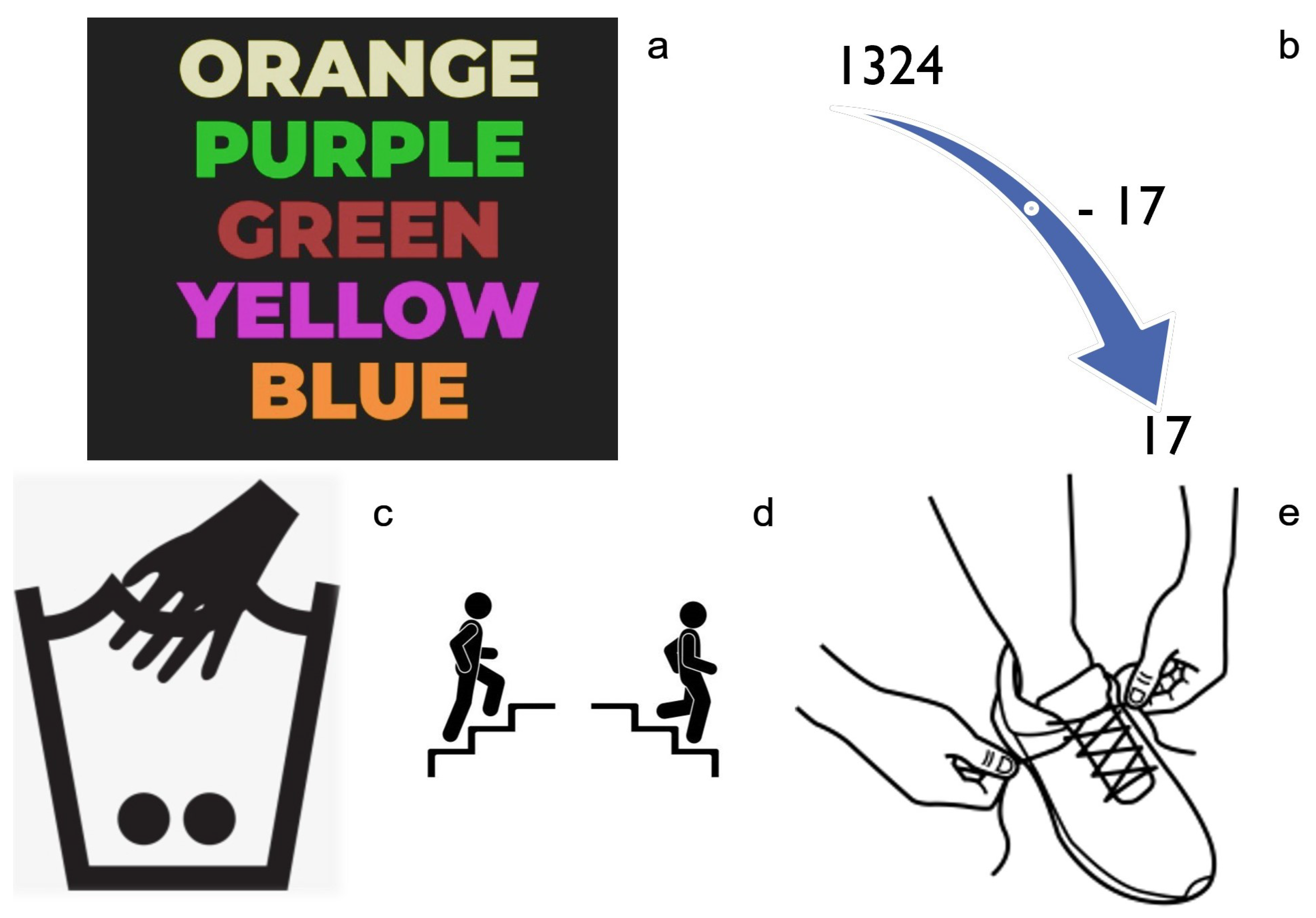
3.1. Stress Induction Protocol
- Psychological:
- –
- –
- The descending subtraction test (Figure 1b). It is also a commonly used stress induction test [27], where the user is asked to begin counting backward from a certain number, subtracting each time another certain number. In the context of the training data collection experiment, the users were asked to begin with the number 1324, subtracting 17, until 17. If the users make a mistake, they must start over.
- –
- Explain a stressful situation in your life.
- –
- Explain how the day has been.
- –
- Listen to relaxing music. The two later tasks are used to monitor situations of calmness.
- Physiological:
3.2. Data Acquisition
3.2.1. Physiological Data Collection
3.2.2. Audio Data Collection
3.3. Participants
3.4. Data Analysis
3.4.1. Physiological Data Analysis
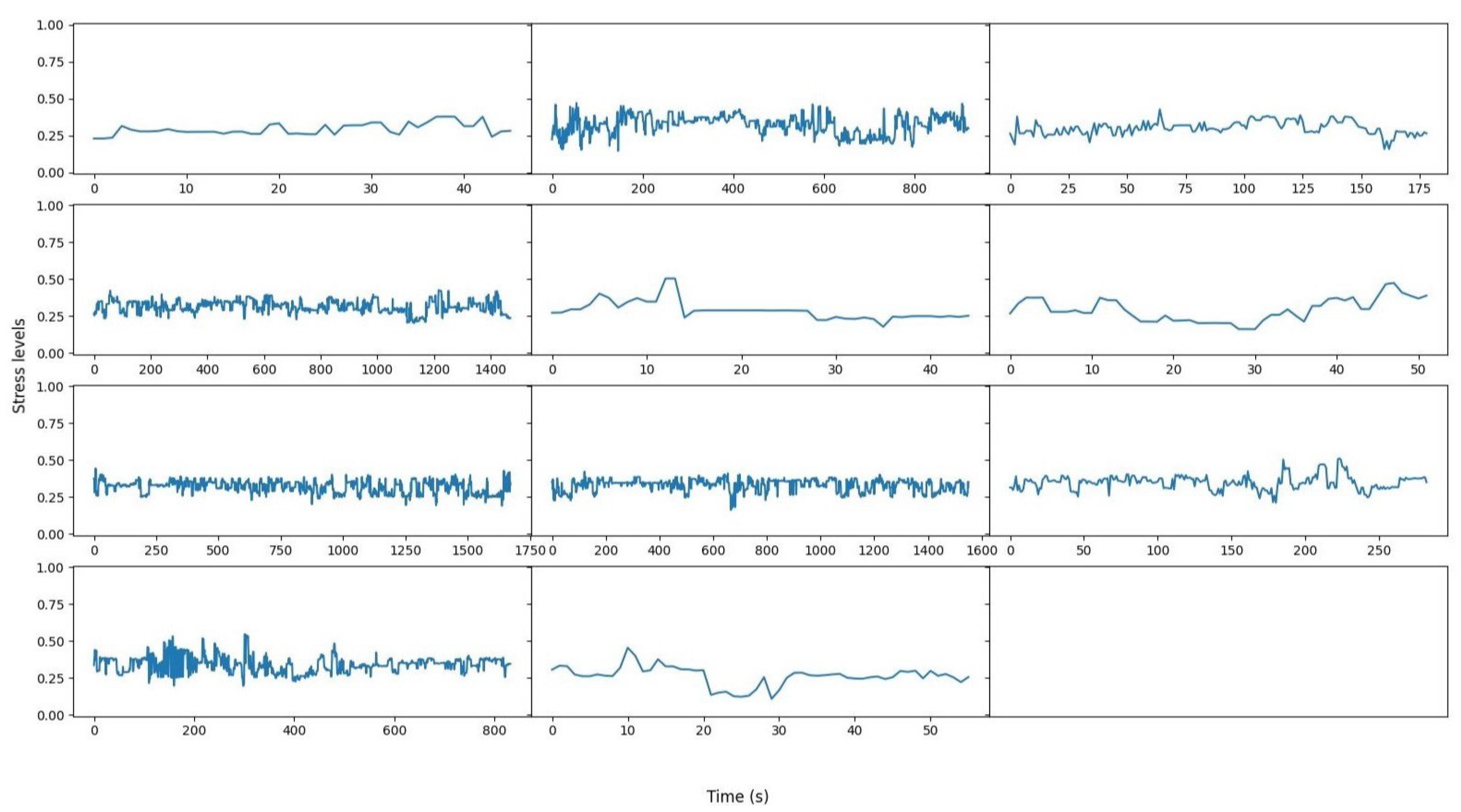
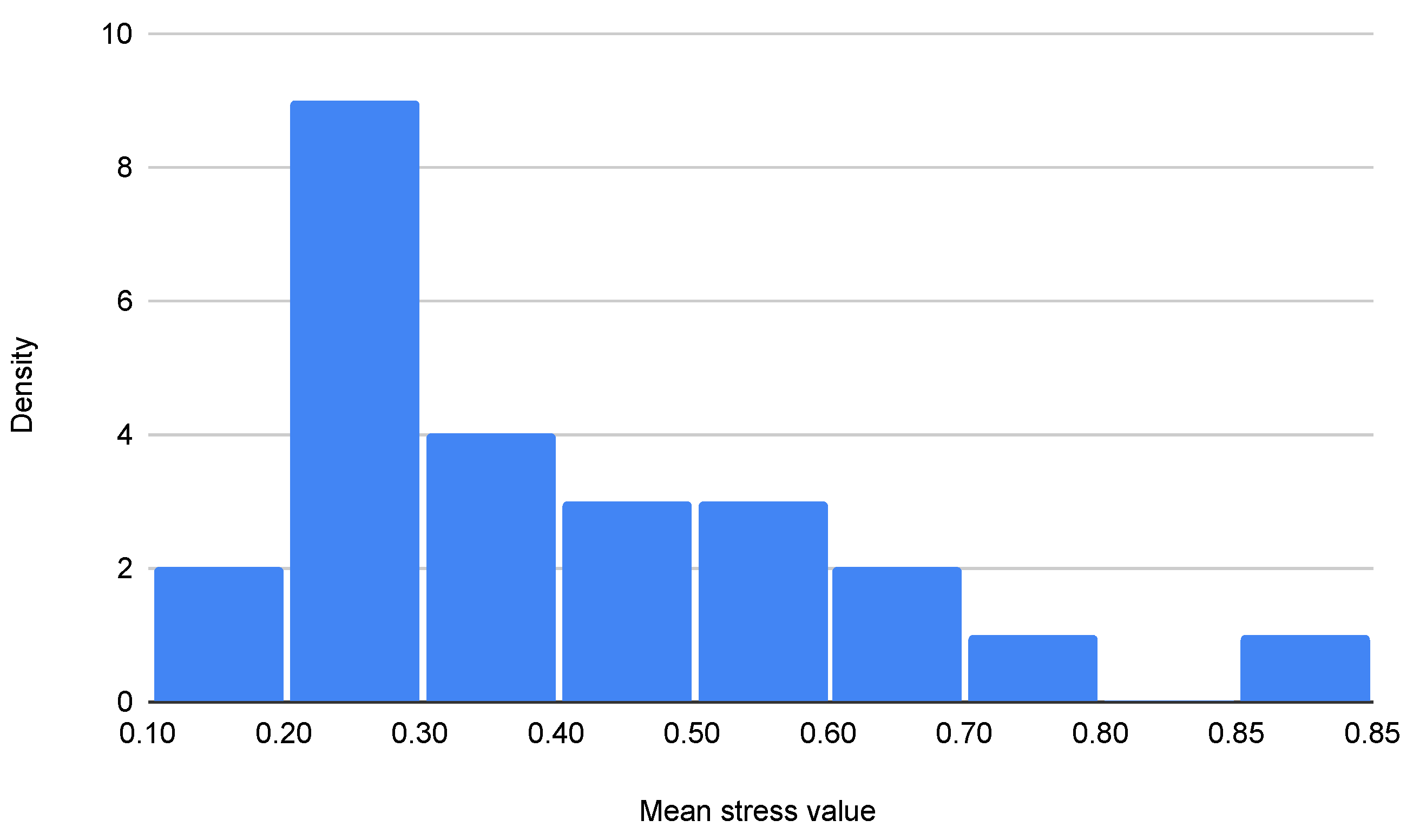
3.4.2. Audio Data Analysis
3.5. Fusion of Physiological and Audio Stress Levels
4. Results
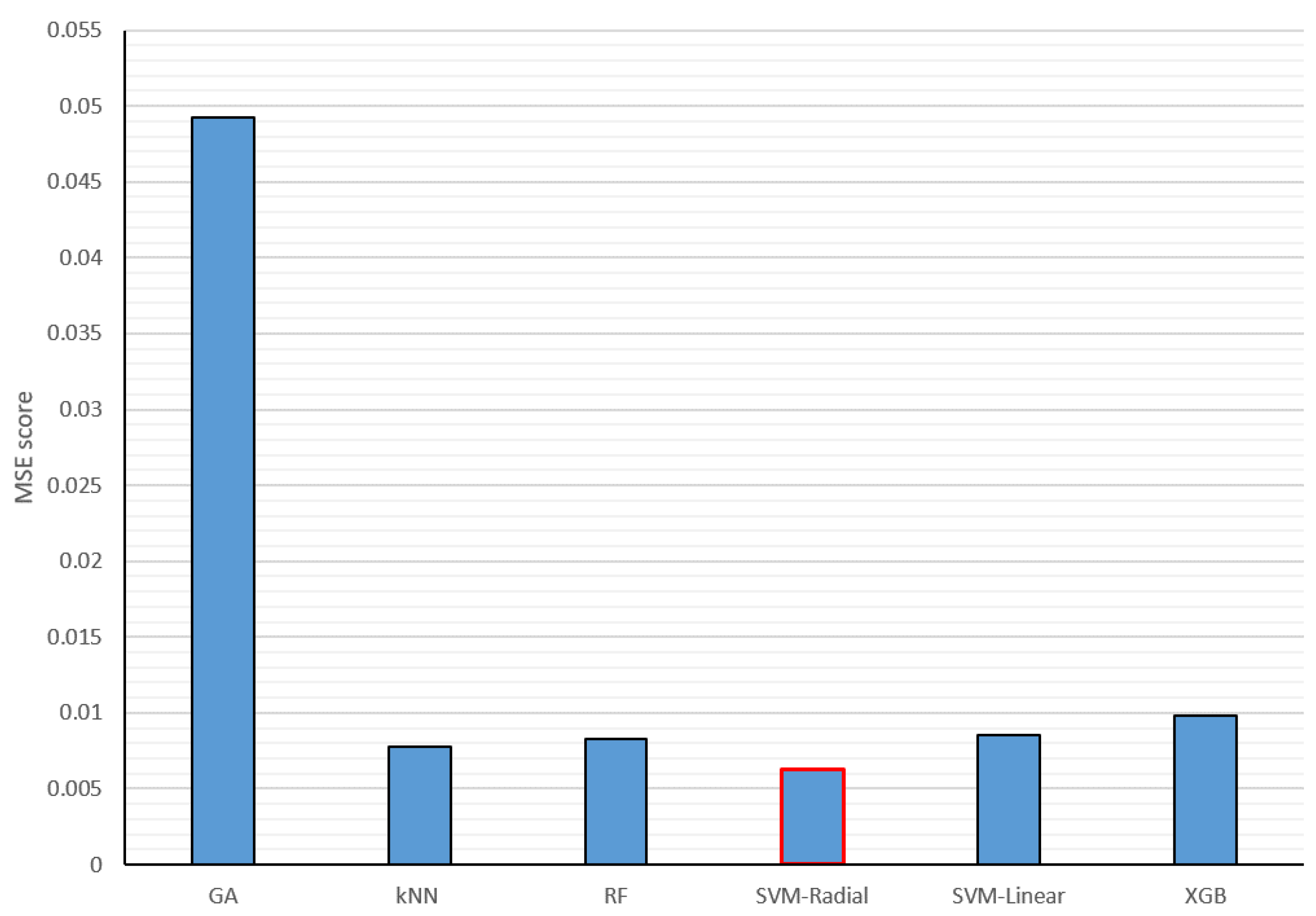
4.1. Training Results
4.1.1. Physiological Sensor Results
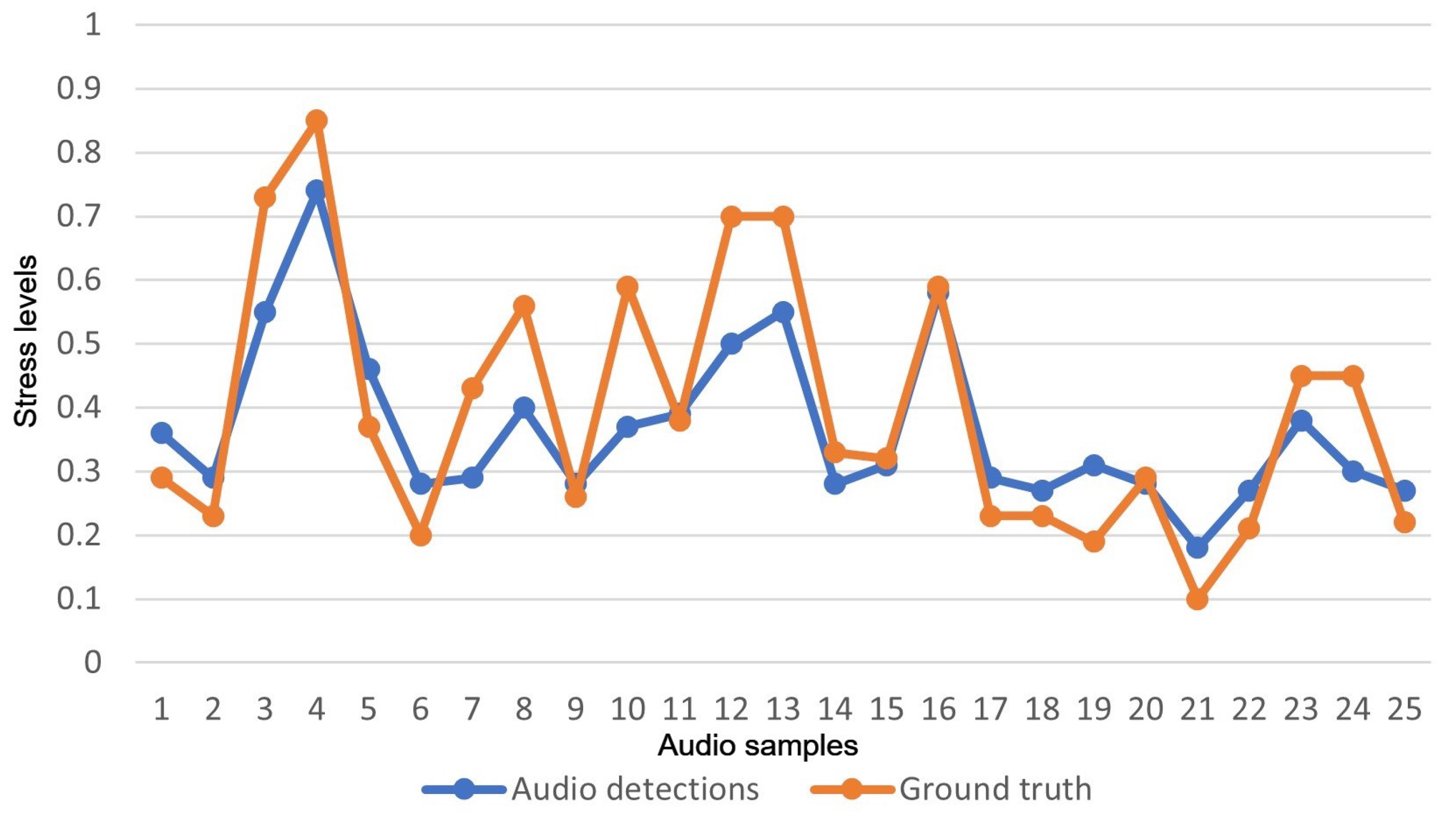
4.1.2. Audio-Based Results
4.1.3. Fusion Results
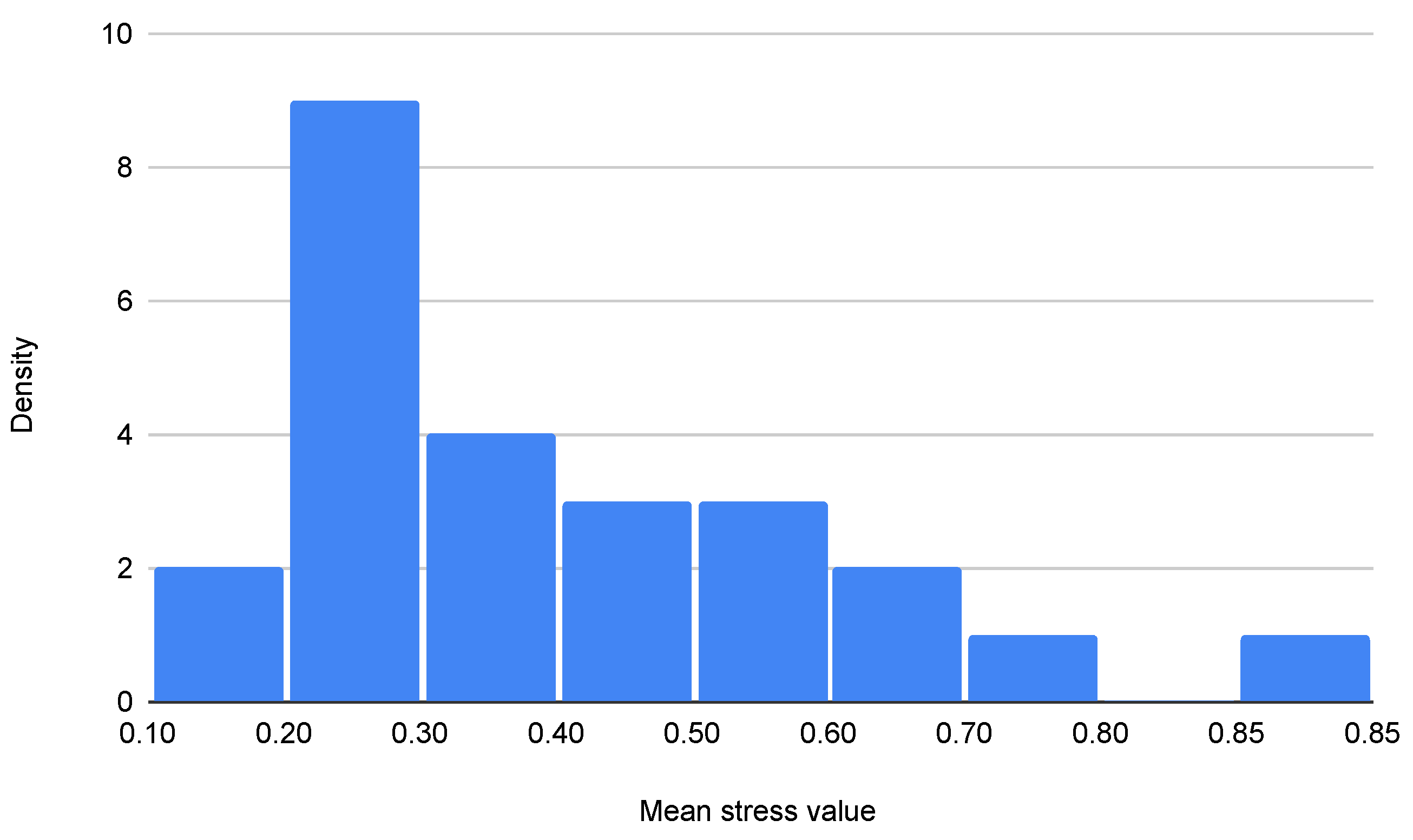
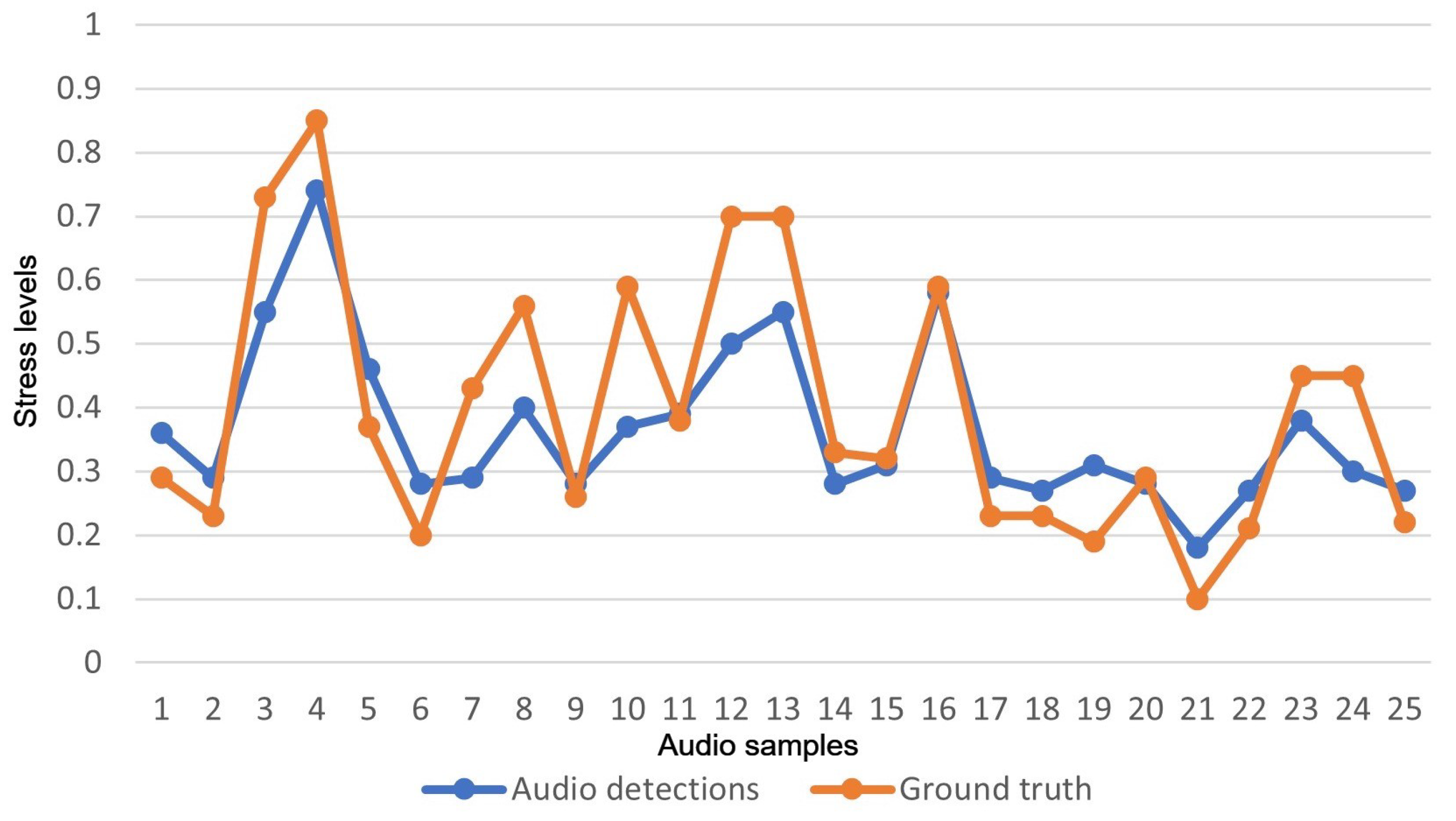
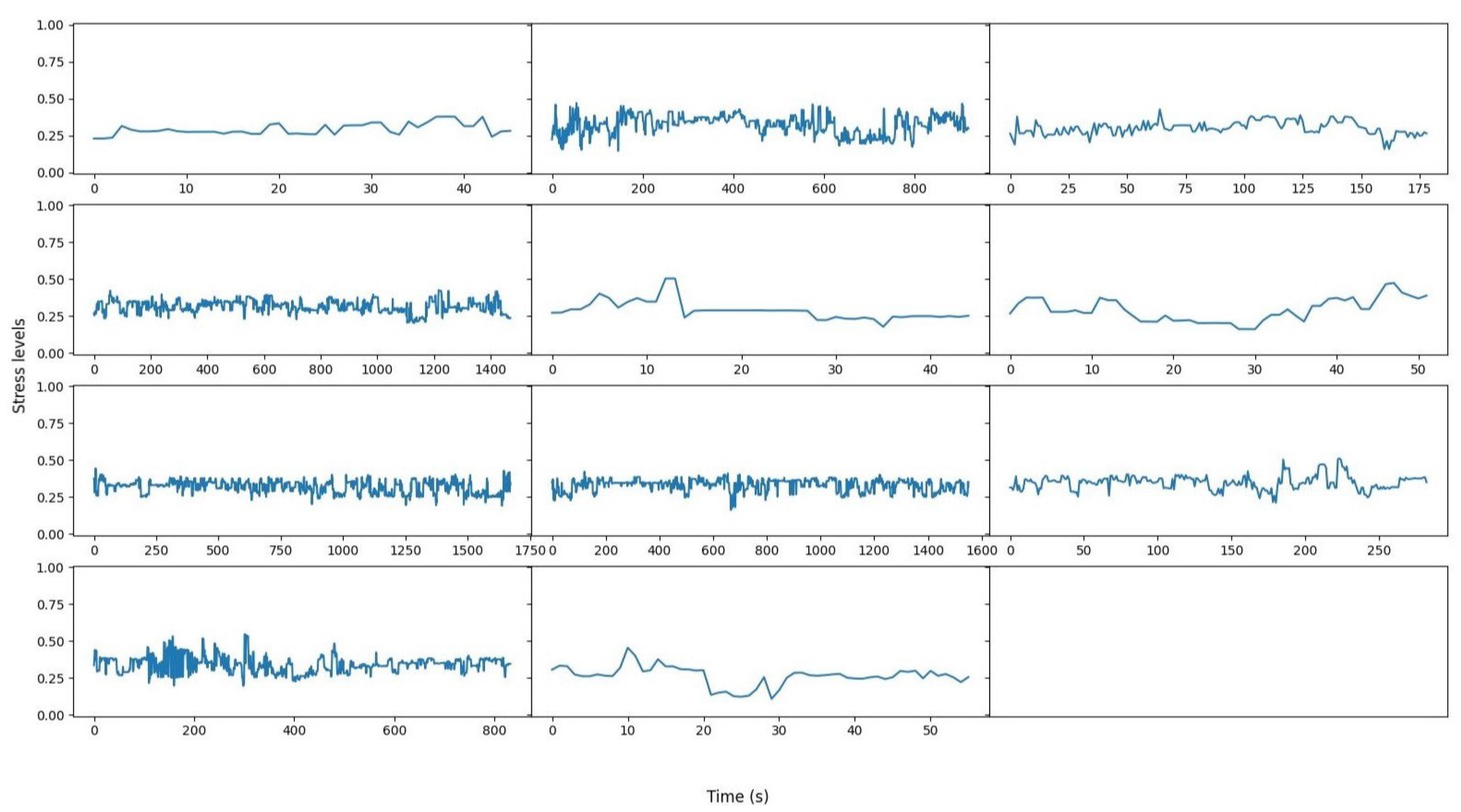
4.2. Pilot Results
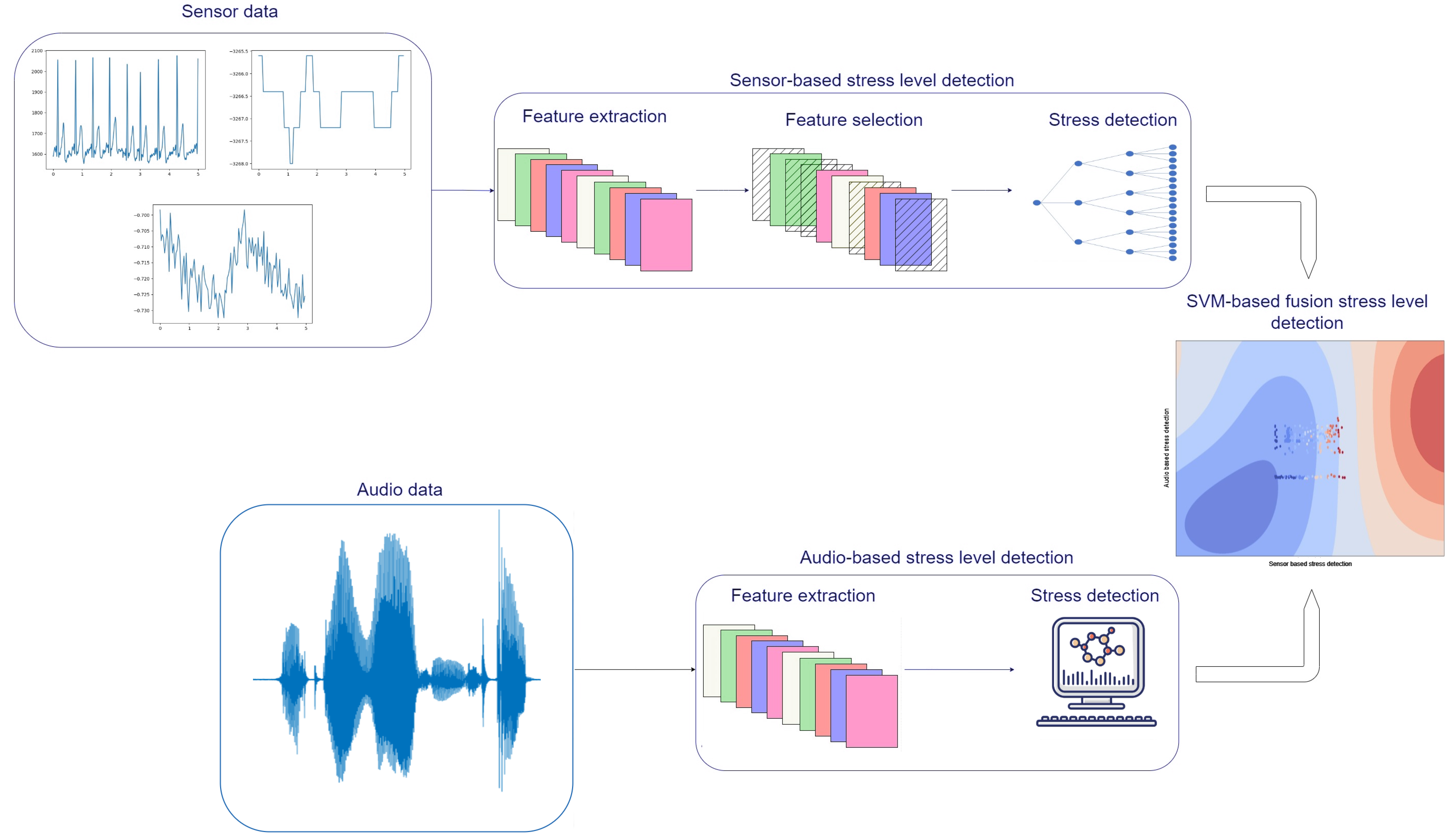
- Physiological signals are continuously monitored using the smart vest.
- Physiological data are fed to the sensor-based stress-level detection module, which has the following operation:
- –
- Stack packages of data until one minute duration is reached. Since the smart vest produces 5 s long packages of data, 12 packages are stacked each time.
- –
- Features are extracted and selected as described in the previous sections.
- –
- Feed selected features to the trained XGB model for physiological sensor-based stress detection.
- If audio recordings are received, they are analyzed with the following operation:
- –
- Audio signals are optionally segmented (especially for longer recordings).
- –
- Feature extraction is performed following the procedure described in the “Audio Data Analysis” subsection.
- –
- Features are fed to the trained Gaussian process regression model for the audio-based stress-level detection.
- Sensor-based stress level and audio-based stress level are fed to the fusion SVM model for the fused stress-level detection.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hellhammer, J.; Schubert, M. The physiological response to Trier Social Stress Test relates to subjective measures of stress during but not before or after the test. Psychoneuroendocrinology 2012, 37, 119–124. [Google Scholar] [CrossRef]
- Kleim, B.; Westphal, M. Mental health in first responders: A review and recommendation for prevention and intervention strategies. Traumatology 2011, 17, 17–24. [Google Scholar] [CrossRef]
- Friedman, M.J.; McEwen, B.S. Posttraumatic stress disorder, allostatic load, and medical illness. In Trauma and Health: Physical Health Consequences of Exposure to Extreme Stress; American Psychological Association: Washington, DC, USA, 2004; pp. 157–188. [Google Scholar]
- Bakker, J.; Pechenizkiy, M.; Sidorova, N. What’s your current stress level? Detection of stress patterns from GSR sensor data. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11–14 December 2011; pp. 573–580. [Google Scholar]
- Boonnithi, S.; Phongsuphap, S. Comparison of heart rate variability measures for mental stress detection. In Proceedings of the 2011 Computing in Cardiology, Hangzhou, China, 18–21 September 2011; pp. 85–88. [Google Scholar]
- Fernández, J.R.M.; Anishchenko, L. Mental stress detection using bioradar respiratory signals. Biomed. Signal Process. Control 2018, 43, 244–249. [Google Scholar] [CrossRef]
- Biloborodova, T.; Scislo, L.; Skarga-Bandurova, I.; Sachenko, A.; Molga, A.; Povoroznyuk, O.; Yevsieieva, Y. Fetal ECG signal processing and identification of hypoxic pregnancy conditions in-utero. Math. Biosci. Eng. 2021, 18, 4919–4942. [Google Scholar] [CrossRef] [PubMed]
- Liao, C.Y.; Chen, R.C.; Tai, S.K. Emotion stress detection using EEG signal and deep learning technologies. In Proceedings of the 2018 IEEE International Conference on Applied System Invention (ICASI), Tokyo, Japan, 13–17 April 2018; pp. 90–93. [Google Scholar]
- Lee, B.G.; Chung, W.Y. Wearable glove-type driver stress detection using a motion sensor. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1835–1844. [Google Scholar] [CrossRef]
- Avila, A.R.; Kshirsagar, S.R.; Tiwari, A.; Lafond, D.; O’Shaughnessy, D.; Falk, T.H. Speech-based stress classification based on modulation spectral features and convolutional neural networks. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Slavich, G.M.; Taylor, S.; Picard, R.W. Stress measurement using speech: Recent advancements, validation issues, and ethical and privacy considerations. Stress 2019, 22, 408–413. [Google Scholar] [CrossRef] [PubMed]
- Gil-Martin, M.; San-Segundo, R.; Mateos, A.; Ferreiros-Lopez, J. Human stress detection with wearable sensors using convolutional neural networks. IEEE Aerosp. Electron. Syst. Mag. 2022, 37, 60–70. [Google Scholar] [CrossRef]
- Schmidt, P.; Reiss, A.; Duerichen, R.; Marberger, C.; Van Laerhoven, K. Introducing wesad, a multimodal dataset for wearable stress and affect detection. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 400–408. [Google Scholar]
- Bajpai, D.; He, L. Evaluating KNN performance on WESAD dataset. In Proceedings of the 2020 12th International Conference on Computational Intelligence and Communication Networks (CICN), Nainital, India, 25–26 September 2020; pp. 60–62. [Google Scholar]
- Fang, R.; Zhang, R.; Hosseini, E.; Parenteau, A.M.; Hang, S.; Rafatirad, S.; Hostinar, C.E.; Orooji, M.; Homayoun, H. Prevent Over-fitting and Redundancy in Physiological Signal Analyses for Stress Detection. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–9 December 2022; pp. 2585–2588. [Google Scholar]
- Ghosh, S.; Kim, S.; Ijaz, M.F.; Singh, P.K.; Mahmud, M. Classification of mental stress from wearable physiological sensors using image-encoding-based deep neural network. Biosensors 2022, 12, 1153. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Sharma, K.; Sharma, A. Hierarchical deep neural network for mental stress state detection using IoT based biomarkers. Pattern Recognit. Lett. 2021, 145, 81–87. [Google Scholar] [CrossRef]
- Stappen, L.; Baird, A.; Christ, L.; Schumann, L.; Sertolli, B.; Messner, E.M.; Cambria, E.; Zhao, G.; Schuller, B.W. The MuSe 2021 Multimodal Sentiment Analysis Challenge: Sentiment, Emotion, Physiological-Emotion, and Stress. In Proceedings of the 29th ACM International Conference on Multimedia, ACM Digital Library, Virtual Event, 20–24 October 2021; pp. 5706–5707. [Google Scholar] [CrossRef]
- Eyben, F.; Wöllmer, M.; Schuller, B. openSMILE–The Munich Versatile and Fast Open-Source Audio Feature Extractor. In Proceedings of the ACM Multimedia 2010, Florence, Italy, 25 October 2010; pp. 1459–1462. [Google Scholar]
- Eyben, F.; Scherer, K.; Schuller, B.; Sundberg, J.; André, E.; Busso, C.; Devillers, L.; Epps, J.; Laukka, P.; Narayanan, S.; et al. The Geneva Minimalistic Acoustic Parameter Set (GeMAPS) for Voice Research and Affective Computing. IEEE Trans. Affect. Comput. 2016, 7, 190–202. [Google Scholar] [CrossRef]
- Kim, J.; André, E.; Rehm, M.; Vogt, T.; Wagner, J. Integrating information from speech and physiological signals to achieve emotional sensitivity. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Kim, J.; André, E. Emotion recognition using physiological and speech signal in short-term observation. In Proceedings of the Perception and Interactive Technologies: International Tutorial and Research Workshop, PIT 2006, Kloster Irsee, Germany, 19–21 June 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 53–64. [Google Scholar]
- Kurniawan, H.; Maslov, A.V.; Pechenizkiy, M. Stress detection from speech and galvanic skin response signals. In Proceedings of the 26th IEEE International Symposium on Computer-Based Medical Systems, Porto, Portugal, 20–22 June 2013; pp. 209–214. [Google Scholar]
- Koldijk, S.; Sappelli, M.; Verberne, S.; Neerincx, M.A.; Kraaij, W. The swell knowledge work dataset for stress and user modeling research. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; pp. 291–298. [Google Scholar]
- Healey, J.A.; Picard, R.W. Detecting stress during real-world driving tasks using physiological sensors. IEEE Trans. Intell. Transp. Syst. 2005, 6, 156–166. [Google Scholar] [CrossRef]
- Nawaz, R.; Ng, J.T.; Nisar, H.; Voon, Y.V. Can background music help to relieve stress? An EEG analysis. In Proceedings of the 2019 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 17–19 September 2019; pp. 68–72. [Google Scholar]
- Tanida, M.; Katsuyama, M.; Sakatani, K. Relation between mental stress-induced prefrontal cortex activity and skin conditions: A near-infrared spectroscopy study. Brain Res. 2007, 1184, 210–216. [Google Scholar] [CrossRef] [PubMed]
- Baur, T.; Heimerl, A.; Lingenfelser, F.; Wagner, J.; Valstar, M.F.; Schuller, B.; André, E. eXplainable Cooperative Machine Learning with NOVA. KI-Künstl. Intell. 2020, 34, 143–164. [Google Scholar] [CrossRef]
- Champseix, R. hrv-Analysis 1.0.4. 2021. Available online: https://pypi.org/project/hrv-analysis/ (accessed on 19 September 2022).
- Makowski, D.; Pham, T.; Lau, Z.J.; Brammer, J.C.; Lespinasse, F.; Pham, H.; Schölzel, C.; Chen, S. NeuroKit2: A Python toolbox for neurophysiological signal processing. Behav. Res. Methods 2021, 53, 1689–1696. [Google Scholar] [CrossRef] [PubMed]
- Khodadad, D.; Nordebo, S.; Müller, B.; Waldmann, A.; Yerworth, R.; Becher, T.; Frerichs, I.; Sophocleous, L.; Van Kaam, A.; Miedema, M.; et al. Optimized breath detection algorithm in electrical impedance tomography. Physiol. Meas. 2018, 39, 094001. [Google Scholar] [CrossRef] [PubMed]
- Xefteris, V.R.; Tsanousa, A.; Symeonidis, S.; Diplaris, S.; Zaffanela, F.; Monego, M.; Pacelli, M.; Vrochidis, S.; Kompatsiaris, I. Stress Detection Based on Wearable Physiological Sensors: Laboratory and Real-Life Pilot Scenario Application. In Proceedings of the The Eighth International Conference on Advances in Signal, Image and Video Processing (SIGNAL 2023), Barcelona, Spain, 13–17 March 2023; p. 14. [Google Scholar]
- Frank, E.; Hall, M.; Witten, I. The WEKA Workbench; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- MacKay, D.J. Introduction to Gaussian processes. NATO ASI Ser. F Comput. Syst. Sci. 1998, 168, 133–166. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Recorded Parameter | Description | Values (per 1 Unit Metric) | Sampling Rate |
|---|---|---|---|
| ECG Value | Electric signal measuring the ECG | 0.8 mV | 250 Hz |
| ECG quality Value | ECG signal quality | 0–255 (0 = poor, 255 = excellent) | 5 Hz |
| ECGHR Value | Heart rate | Beats/minute | 5 Hz |
| ECGRR Value | R-R intervals | number of samples between R-R peaks | 5 Hz |
| ECGHRV Value | Heart rate variability | ms | 60 Hz |
| AccX-Y-Z Value | Acceleration in X-Y-Z axes | g | 25 Hz |
| GyroX-Y-Z Value | Angular velocity in X-Y-Z axes | 0.122°/s | 25 Hz |
| MagX-Y-Z Value | Magnetic field in X-Y-Z axes | 0.6 µT | 25 Hz |
| Q0-Q1-Q2-Q3 Value | Quaternions from main electronic device (Q0, Q1, Q2, Q3 components) | Q14 format | 25 Hz |
| RespPiezo Value | Electric signal measuring the chest pressure on the piezoelectric point | 0.8 mV | 25 Hz |
| BR Value | Breathing rate | Breaths/minute | 5 Hz |
| BA Value | Breathing amplitude | logic levels | 15 Hz |
| ECG | RSP | IMU | ECG + RSP | ECG + IMU | RSP + IMU | ECG + RSP + IMU | Late Mean | Late Median | |
|---|---|---|---|---|---|---|---|---|---|
| SVM | 0.1709 | 0.1530 | 0.1305 | 0.1723 | 0.1306 | 0.1305 | 0.1305 | 0.1412 | 0.1363 |
| kNN | 0.1439 | 0.1553 | 0.1107 | 0.1285 | 0.1106 | 0.1106 | 0.1107 | 0.1170 | 0.1125 |
| RF | 0.1113 | 0.1280 | 0.0918 | 0.1073 | 0.0916 | 0.0871 | 0.0886 | 0.0984 | 0.1025 |
| XGB | 0.1237 | 0.1307 | 0.0844 | 0.1092 | 0.0835 | 0.0858 | 0.0730 | 0.0958 | 0.1006 |
| RFE | PCA | GA | |
|---|---|---|---|
| SVM | 0.1052 | 0.1201 | 0.1305 |
| kNN | 0.1023 | 0.1106 | 0.1106 |
| RF | 0.0790 | 0.1044 | 0.0742 |
| XGB | 0.0772 | 0.0953 | 0.0567 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xefteris, V.-R.; Dominguez, M.; Grivolla, J.; Tsanousa, A.; Zaffanela, F.; Monego, M.; Symeonidis, S.; Diplaris, S.; Wanner, L.; Vrochidis, S.; et al. A Multimodal Late Fusion Framework for Physiological Sensor and Audio-Signal-Based Stress Detection: An Experimental Study and Public Dataset. Electronics 2023, 12, 4871. https://doi.org/10.3390/electronics12234871
Xefteris V-R, Dominguez M, Grivolla J, Tsanousa A, Zaffanela F, Monego M, Symeonidis S, Diplaris S, Wanner L, Vrochidis S, et al. A Multimodal Late Fusion Framework for Physiological Sensor and Audio-Signal-Based Stress Detection: An Experimental Study and Public Dataset. Electronics. 2023; 12(23):4871. https://doi.org/10.3390/electronics12234871
Chicago/Turabian StyleXefteris, Vasileios-Rafail, Monica Dominguez, Jens Grivolla, Athina Tsanousa, Francesco Zaffanela, Martina Monego, Spyridon Symeonidis, Sotiris Diplaris, Leo Wanner, Stefanos Vrochidis, and et al. 2023. "A Multimodal Late Fusion Framework for Physiological Sensor and Audio-Signal-Based Stress Detection: An Experimental Study and Public Dataset" Electronics 12, no. 23: 4871. https://doi.org/10.3390/electronics12234871
APA StyleXefteris, V.-R., Dominguez, M., Grivolla, J., Tsanousa, A., Zaffanela, F., Monego, M., Symeonidis, S., Diplaris, S., Wanner, L., Vrochidis, S., & Kompatsiaris, I. (2023). A Multimodal Late Fusion Framework for Physiological Sensor and Audio-Signal-Based Stress Detection: An Experimental Study and Public Dataset. Electronics, 12(23), 4871. https://doi.org/10.3390/electronics12234871