
A Lightweight Multi-Scale Quadratic Separation Convolution Module for CNN Image-Classification Tasks


Abstract
:1. Introduction
2. Related Work
2.1. Standard Convolution
2.2. Depthwise Separable Convolution
2.3. Spatially Separable Convolutions
2.4. Symmetrically Padded 2 × 2 Convolution Kernel (C2sp)
3. Methods
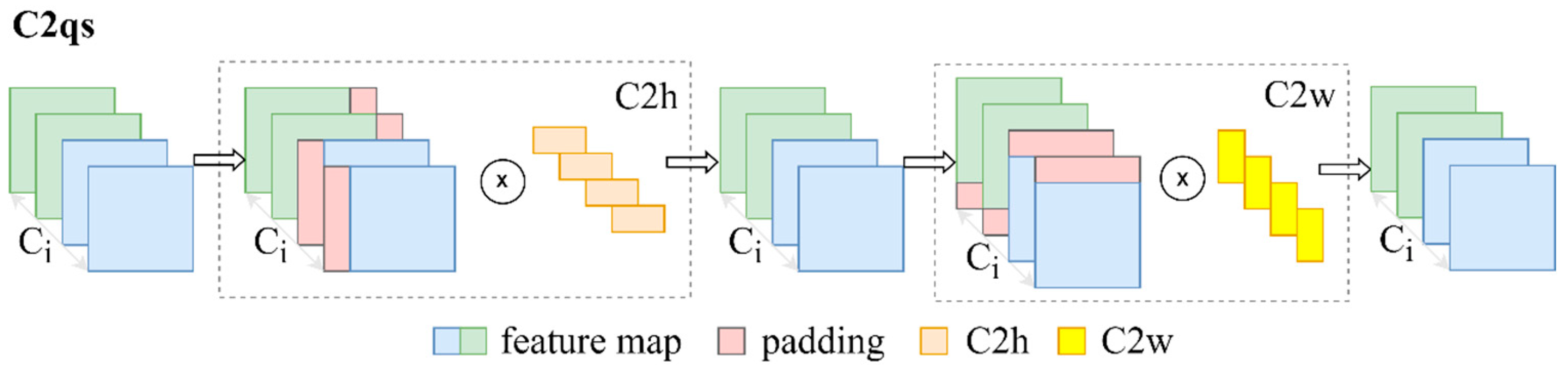
3.1. A 2 × 2 Convolution Kernel with Quadratic Separation and a New Symmetric Padding Strategy (C2qs)
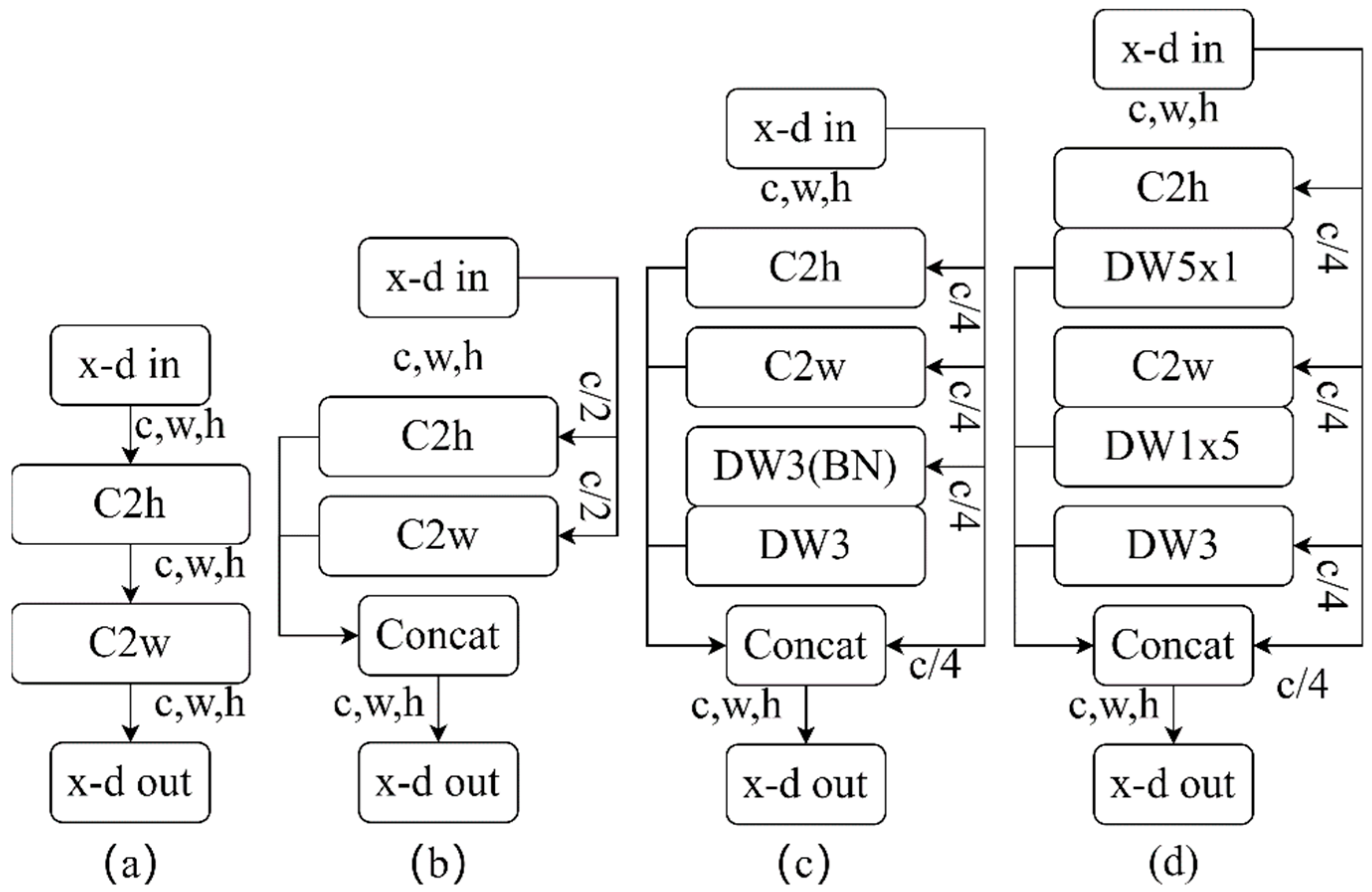
3.2. Multi-Scale Quadratic Separation Convolution Module (Mqscm)
3.3. MqscmNet
4. Experiment and Analysis
4.1. Datasets and Training Settings
4.2. Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vargas-Hakim, G.-A.; Mezura-Montes, E.; Acosta-Mesa, H.-G. A Review on Convolutional Neural Networks Encodings for Neuroevolution. IEEE Trans. Evol. Comput. 2021, 26, 12–27. [Google Scholar] [CrossRef]
- Gómez-Guzmán, M.A.; Jiménez-Beristaín, L.; García-Guerrero, E.E.; López-Bonilla, O.R.; Tamayo-Perez, U.J.; Esqueda-Elizondo, J.J.; Palomino-Vizcaino, K.; Inzunza-González, E. Classifying Brain Tumors on Magnetic Resonance Imaging by Using Convolutional Neural Networks. Electronics 2023, 12, 955. [Google Scholar] [CrossRef]
- Weng, L.; Wang, Y.; Gao, F. Traffic scene perception based on joint object detection and semantic segmentation. Neural Process. Lett. 2022, 54, 5333–5349. [Google Scholar] [CrossRef]
- Li, S.; Liu, Y.; Zhang, Y.; Luo, Y.; Liu, J. Adaptive Generation of Weakly Supervised Semantic Segmentation for Object Detection. Neural Process. Lett. 2023, 55, 657–670. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Kamarudin, M.H.; Ismail, Z.H.; Saidi, N.B.; Hanada, K. An augmented attention-based lightweight CNN model for plant water stress detection. Appl. Intell. 2023, 53, 1–16. [Google Scholar] [CrossRef]
- Pintelas, E.; Livieris, I.E.; Kotsiantis, S.; Pintelas, P. A multi-view-CNN framework for deep representation learning in image classification. Comput. Vis. Image Underst. 2023, 232, 103687. [Google Scholar] [CrossRef]
- Bonam, J.; Kondapalli, S.S.; Prasad, L.V.N.; Marlapalli, K. Lightweight CNN Models for Product Defect Detection with Edge Computing in Manufacturing Industries. J. Sci. Ind. Res. 2023, 82, 418–425. [Google Scholar]
- Liu, D.; Zhang, J.; Li, T.; Qi, Y.; Wu, Y.; Zhang, Y. A Lightweight Object Detection and Recognition Method Based on Light Global-Local Module for Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Ye, Z.; Li, C.; Liu, Q.; Bai, L.; Fowler, J.E. Computationally Lightweight Hyperspectral Image Classification Using a Multiscale Depthwise Convolutional Network with Channel Attention. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Wu, B.; Wan, A.; Yue, X.; Jin, P.; Zhao, S.; Golmant, N.; Gholaminejad, A.; Gonzalez, J.; Keutzer, K. Shift: A zero flop, zero parameter alternative to spatial convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9127–9135. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Gholami, A.; Kwon, K.; Wu, B.; Tai, Z.; Yue, X.; Jin, P.; Zhao, S.; Keutzer, K. Squeezenext: Hardware-aware neural network design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1638–1647. [Google Scholar]
- Wu, S.; Wang, G.; Tang, P.; Chen, F.; Shi, L. Convolution with even-sized kernels and symmetric padding. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Chen, J.; Lu, Z.; Liao, Q. XSepConv: Extremely separated convolution. arXiv 2020, arXiv:2002.12046. [Google Scholar]
- Yang, S.; Wen, J.; Fan, J. Ghost shuffle lightweight pose network with effective feature representation and learning for human pose estimation. IET Comput. Vis. 2022, 16, 525–540. [Google Scholar] [CrossRef]
- Cao, J.; Li, Y.; Sun, M.; Chen, Y.; Lischinski, D.; Cohen-Or, D.; Chen, B.; Tu, C. Do-conv: Depthwise over-parameterized convolutional layer. IEEE Trans. Image Process. 2022, 31, 3726–3736. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Yang, H.; Yang, C. ResE: A Fast and Efficient Neural Network-Based Method for Link Prediction. Electronics 2023, 12, 1919. [Google Scholar] [CrossRef]
- Cui, B.; Dong, X.-M.; Zhan, Q.; Peng, J.; Sun, W. LiteDepthwiseNet: A lightweight network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Wang, C.; Feng, J. Improving convolutional networks with self-calibrated convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10096–10105. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 28–29 October 2019; pp. 1314–1324. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 5 February 2023).
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. 2011. Available online: https://research.google/pubs/pub37648/ (accessed on 5 February 2023).
- Haq, S.I.U.; Tahir, M.N.; Lan, Y. Weed Detection in Wheat Crops Using Image Analysis and Artificial Intelligence (AI). Appl. Sci. 2023, 13, 8840. [Google Scholar] [CrossRef]
- Rohlfs, C. Problem-dependent attention and effort in neural networks with applications to image resolution and model selection. Image Vis. Comput. 2023, 135, 104696. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Convolution | FLOPs (M) | Params (M) | Accuracy (%) | Time/Epoch (s) |
|---|---|---|---|---|
| Conv3 | 84.34 | 23.53 | 89.17 | 48.61 |
| DWConv3 | 46.85 | 12.25 | 88.49 | 30.60 |
| C2sp | 63.37 | 17.24 | 88.37 | 38.29 |
| Mqscm | 46.77 | 12.24 | 88.56 | 32.81 |
| Convolution | FLOPs (M) | Params (M) | Accuracy (%) | Time/Epoch (s) |
|---|---|---|---|---|
| Conv3 | 337.69 | 23.91 | 54.38 | 97.44 |
| DWConv3 | 187.71 | 12.63 | 55.46 | 73.75 |
| C2sp | 253.81 | 17.63 | 53.59 | 99.83 |
| Mqscm | 187.39 | 12.63 | 56.20 | 82.89 |
| Convolution | FLOPs (M) | Params (M) | Accuracy (%) | Time/Epoch (s) |
|---|---|---|---|---|
| Conv3 | 84.34 | 23.53 | 96.51 | 72.602 |
| DWConv3 | 46.85 | 12.25 | 96.13 | 43.18 |
| C2sp | 63.37 | 17.24 | 96.17 | 55.45 |
| Mqscm | 46.77 | 12.24 | 96.22 | 46.89 |
| Net | FLOPs (M) | Params (M) | Accuracy (%) | Time/Epoch (s) |
|---|---|---|---|---|
| AlexNet | 67.08 | 3.75 | 83.47 | 28.79 |
| Vgg-16 | 1257.21 | 29.45 | 94.23 | 42.79 |
| GoogleNet | 32.55 | 5.99 | 88.67 | 32.93 |
| Mobilenet_v3_Small | 2.28 | 1.52 | 73.52 | 27.64 |
| Mobilenet_v3_large | 7.45 | 4.21 | 84.34 | 29.08 |
| ResNet-50 | 84.34 | 23.53 | 89.17 | 48.61 |
| ResNet-50+Mqscm | 46.76 | 12.24 | 88.56 | 32.75 |
| MqscmNet | 40.63 | 9.54 | 89.76 | 34.19 |
| Model | Design | FLOPs (M) | Params (M) | Accuracy (%) | Time/Epoch (s) |
|---|---|---|---|---|---|
| ResNet-50 | Mqscm-a | 46.72 | 12.23 | 88.12 | 31.50 |
| Mqscm-b | 46.67 | 12.23 | 88.15 | 31.38 | |
| Mqscm-c | 46.79 | 12.23 | 88.27 | 32.97 | |
| Mqscm-d | 46.77 | 12.24 | 88.56 | 32.81 | |
| MqscmNet | Mqscm-a | 40.59 | 9.53 | 89.21 | 33.63 |
| Mqscm-b | 40.54 | 9.53 | 89.25 | 33.22 | |
| Mqscm-c | 40.65 | 9.53 | 89.28 | 34.33 | |
| Mqscm-d | 40.63 | 9.54 | 89.76 | 34.19 |
| Accuracy (%) | ||||
|---|---|---|---|---|
| Net | Convolution | CIFAR-10 | Tiny-ImageNet | SVHN |
| ResNet-50 | DWConv3 | 88.61 | 55.92 | 96.27 |
| Mqscm | 88.85 | 56.39 | 96.35 | |
| Mobilenet_v3_large | DWConv3 | 84.52 | 26.60 | 93.79 |
| Mqscm | 84.66 | 26.95 | 93.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Chen, P. A Lightweight Multi-Scale Quadratic Separation Convolution Module for CNN Image-Classification Tasks. Electronics 2023, 12, 4839. https://doi.org/10.3390/electronics12234839
Wang Y, Chen P. A Lightweight Multi-Scale Quadratic Separation Convolution Module for CNN Image-Classification Tasks. Electronics. 2023; 12(23):4839. https://doi.org/10.3390/electronics12234839
Chicago/Turabian StyleWang, Yunyan, and Peng Chen. 2023. "A Lightweight Multi-Scale Quadratic Separation Convolution Module for CNN Image-Classification Tasks" Electronics 12, no. 23: 4839. https://doi.org/10.3390/electronics12234839
APA StyleWang, Y., & Chen, P. (2023). A Lightweight Multi-Scale Quadratic Separation Convolution Module for CNN Image-Classification Tasks. Electronics, 12(23), 4839. https://doi.org/10.3390/electronics12234839