
DGU-HAU: A Dataset for 3D Human Action Analysis on Utterances


Abstract
:1. Introduction
2. Related Work
2.1. Generative Pre-Trained Transformer
2.2. Gesture Generation
2.3. 3D Human Action Generation
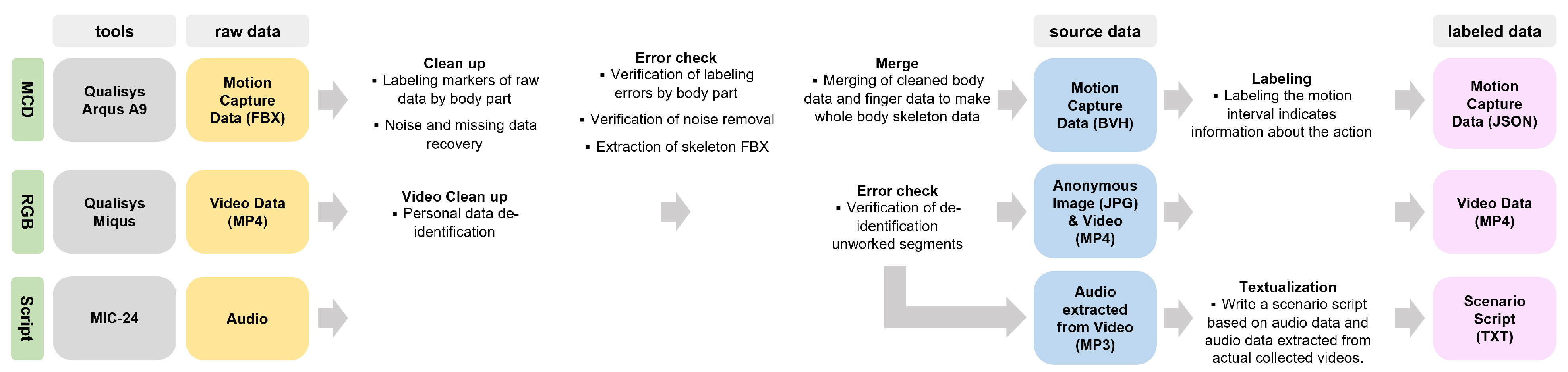
3. Dataset Structure and Building Process
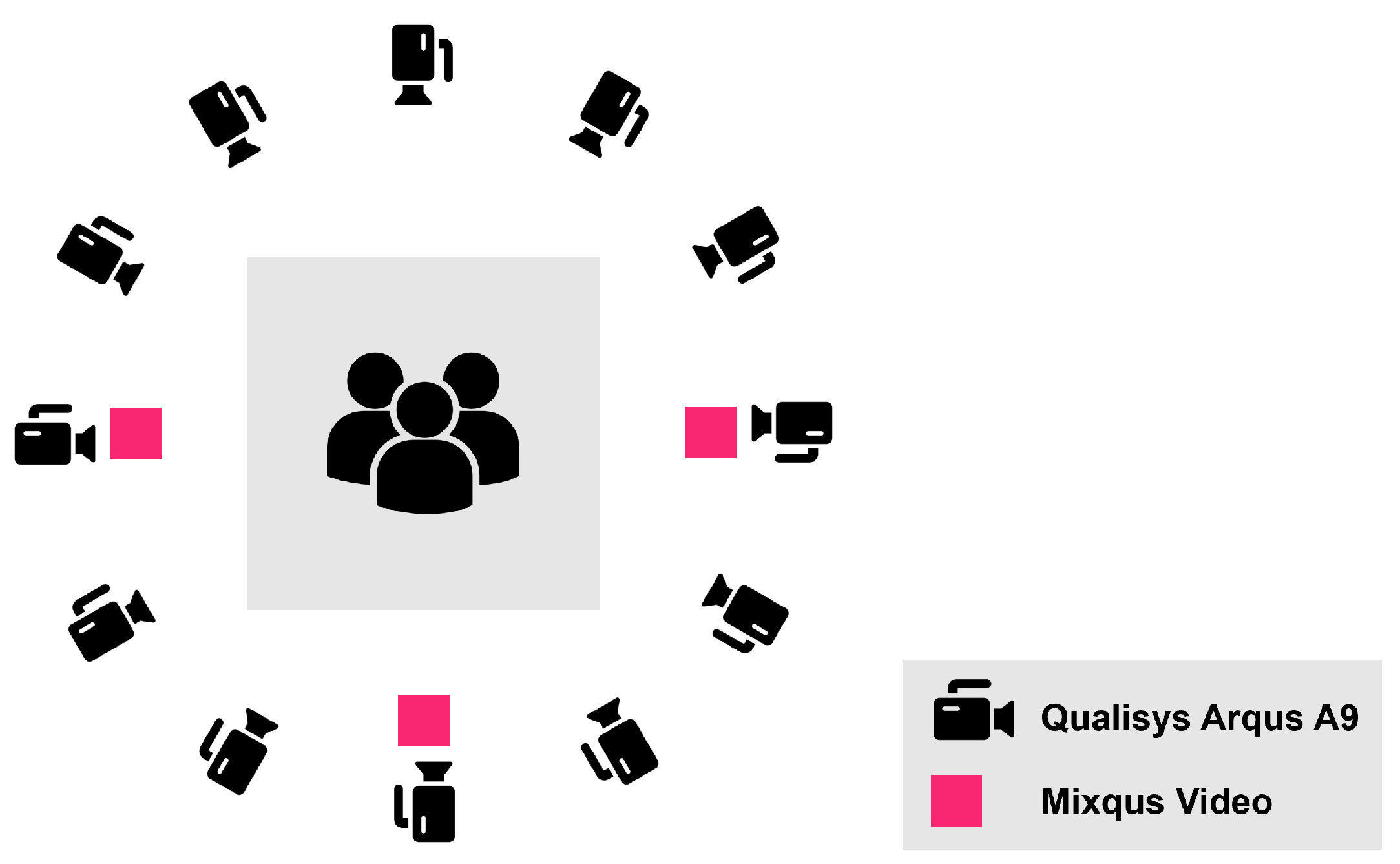
3.1. Collection Setups
3.2. Data Modalities
3.2.1. Motion Capture Data (MCD)
3.2.2. RGB Video
3.2.3. Scenario Scripts
3.2.4. Annotation Data
3.3. Subjects
3.4. Action Classes
4. Dataset Pre-Processing and Evaluation with Action2Motion
4.1. Data Pre-Processing
4.2. Evaluation Results for A2M Model
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced computer vision with microsoft kinect sensor: A review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef] [PubMed]
- Guo, C.; Zuo, X.; Wang, S.; Zou, S.; Sun, Q.; Deng, A.; Gong, M.; Cheng, L. Action2motion: Conditioned generation of 3d human motions. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2021–2029. [Google Scholar]
- Kiasari, M.A.; Moirangthem, D.S.; Lee, M. Human action generation with generative adversarial networks. arXiv 2018, arXiv:1805.10416. [Google Scholar]
- Wang, Z.; Yu, P.; Zhao, Y.; Zhang, R.; Zhou, Y.; Yuan, J.; Chen, C. Learning diverse stochastic human-action generators by learning smooth latent transitions. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12281–12288. [Google Scholar]
- Yu, P.; Zhao, Y.; Li, C.; Yuan, J.; Chen, C. Structure-aware human-action generation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX; Springer: Cham, Switzerland, 2020; pp. 18–34. [Google Scholar]
- Petrovich, M.; Black, M.J.; Varol, G. Action-conditioned 3D human motion synthesis with transformer VAE. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10985–10995. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Ji, Y.; Xu, F.; Yang, Y.; Shen, F.; Shen, H.T.; Zheng, W.S. A large-scale varying-view rgb-d action dataset for arbitrary-view human action recognition. arXiv 2019, arXiv:1904.10681. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 1–60. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. OpenAI. 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 10 October 2023).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–15. [Google Scholar]
- Ginosar, S.; Bar, A.; Kohavi, G.; Chan, C.; Owens, A.; Malik, J. Learning individual styles of conversational gesture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3497–3506. [Google Scholar]
- Ahuja, C.; Lee, D.W.; Nakano, Y.I.; Morency, L.P. Style transfer for co-speech gesture animation: A multi-speaker conditional-mixture approach. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVIII; Springer: Cham, Switzerland, 2020; pp. 248–265. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. (TOG) 2015, 2, 851–866. [Google Scholar] [CrossRef]
- Zou, S.; Zuo, X.; Qian, Y.; Wang, S.; Guo, C.; Xu, C.; Gong, M.; Cheng, L. Polarization human shape and pose dataset. arXiv 2020, arXiv:2004.14899. [Google Scholar]
- Zou, S.; Zuo, X.; Qian, Y.; Wang, S.; Xu, C.; Gong, M.; Cheng, L. 3D human shape reconstruction from a polarization image. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV; Springer: Cham, Switzerland, 2020; pp. 351–368. [Google Scholar]
- AIHub. DGU-HAU: A Dataset for 3D Human Action Analysis on Utterances. Available online: https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=71419 (accessed on 10 October 2023).
- Park, J. Full Action Classes Table for Presentation Scenario (Table 5). Available online: https://github.com/CSID-DGU/NIAMoCap-2/blob/main/docs/action_classes_presentation_scenario(Table5).pdf (accessed on 10 October 2023).
- Park, J. Full Action Classes Table for Conversational Scenario (Table 6). Available online: https://github.com/CSID-DGU/NIAMoCap-2/blob/main/docs/action_classes_conversational_scenario(Table6).pdf (accessed on 10 October 2023).
- CMU. CMU Graphics Lab Motion Capture Database; CMU: Pittsburgh, PA, USA, 2003. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # | # | # | # | # | # | Data Modalities | Year | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Frames | Video | Classes | Subjects | Views | Anno. | RGB | MCD | Anno. | Script | ||
| Human3.6M [11] | 3.6 M | - | 17 | 11 | 4 | - | ✓ | ✓ | ✓ | - | 2013 |
| NTU RGB+D [4] | - | 56,880 | 60 | 40 | 80 | - | ✓ | ✓ | - | - | 2016 |
| NTU RGB+D 120 [5] | - | 114,480 | 120 | 106 | 155 | - | ✓ | ✓ | - | - | 2019 |
| UESTC [12] | - | 25,600 | 40 | 118 | 9 | - | ✓ | ✓ | - | - | 2019 |
| PHSPD [24,25] | 2.1 M | 334 | 31 | 21 | 4 | - | ✓ | ✓ | ✓ | - | 2020 |
| HumanAct12 [6] | 90 K | - | 12 | 21 | 4 | - | ✓ | ✓ | ✓ | - | 2020 |
| DGU-HAU (ours) | ≈144 K | 1352 | 142 | 166 | 15 | 2408 | ✓ | ✓ | ✓ | ✓ | 2022 |
| Data Modality | File Format | Description |
|---|---|---|
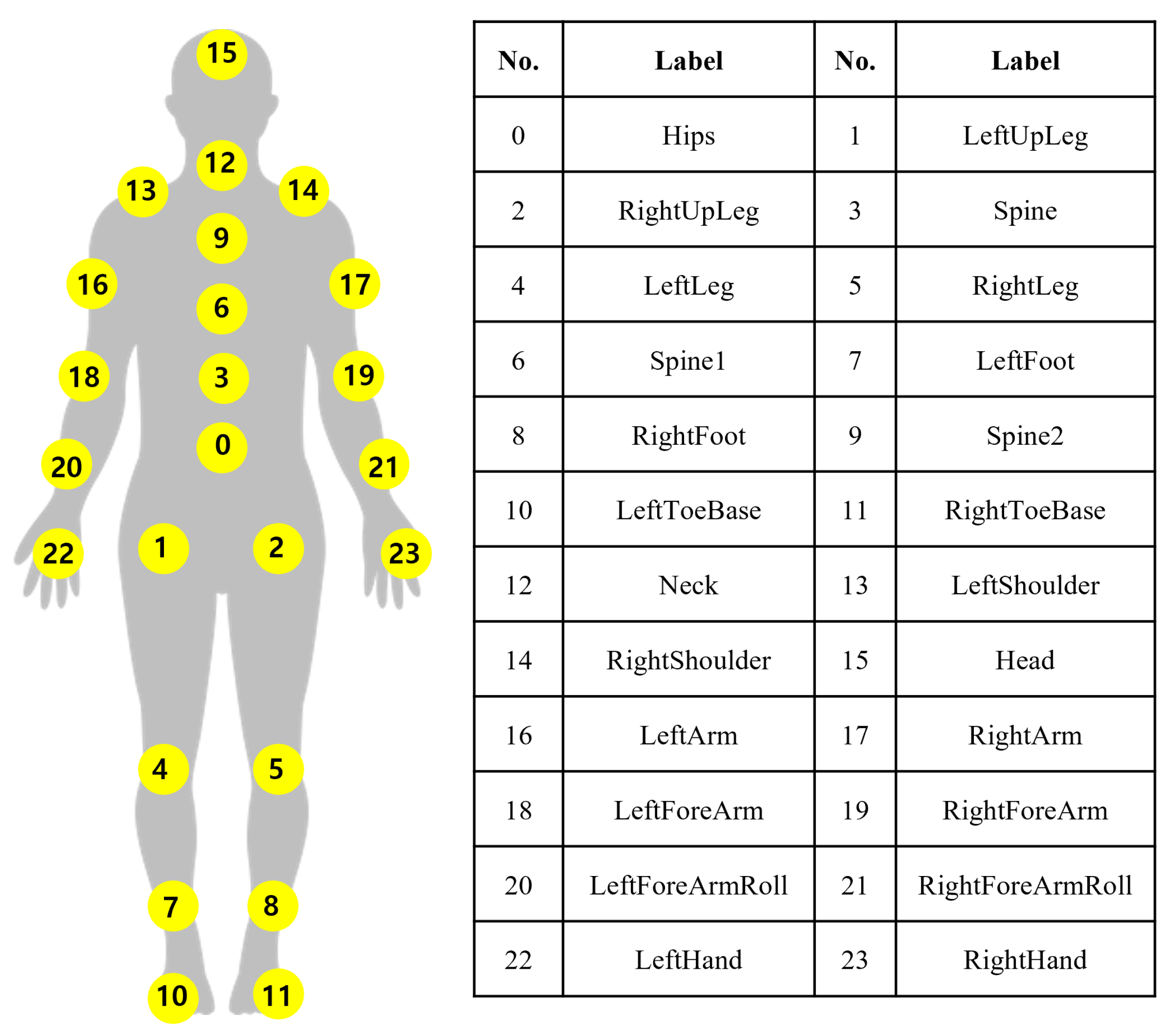
| Motion Capture Data (MCD) | BVH | - 3D coordinate of joint - Number of joints: 24 |
| RGB Video | MP4 | - Resolution: - Number of views: 3 |
| Scenario Scripts | TXT | - Text script of 14 action scenarios: presentation × 4 conversation × 10 |
| Annotation Data | JSON | - Metadata of the other data modalities - Configuration: pre-processed MCD, scenario code, scenario name, action code, action class, actor ID, video section tagging, etc. |
| Category | Type | Description |
|---|---|---|
| 1. info | object | information on the data |
| 1.1 name | string | name of the dataset |
| 1.2 creator | string | name of the constructor |
| 1.3 date_created | string | date of the deployment |
| 2. annotation | object | information of the annotation |
| 2.1 video | object | information of the video |
| 2.1.1 filename | string | file name of the video |
| ⋮ | ⋮ | ⋮ |
| 2.2 actionAnnotationList | array | action annotation |
| 2.2.1 actor_id | number | ID of the actor |
| ⋮ | ⋮ | ⋮ |
| 3. categories | object | information of the categories |
| 3.1 actionCategories | array | list of the action classes |
| 3.1.1 id | number | ID of action scenario |
| ⋮ | ⋮ | ⋮ |
| 3.2 actionScenarioList | array | list of the action scenarios |
| 3.2.1 id | number | ID of action scenario |
| ⋮ | ⋮ | ⋮ |
| 4. actors | array | information of the actors |
| 4.1 id | number | ID of the actor |
| ⋮ | ⋮ | ⋮ |
| 5. mocap_data | array | motion capture data |
| 5.1 frame | number | frame id |
| 5.2 bodyJoints | object | coordinate info. of the keypoints |
| 5.2.1 Skeletons | array | 3D coordinates of the Skeleton |
| 5.2.2 Reference | array | 3D coordinates of the Reference |
| 5.2.3 Hips | array | 3D coordinates of the (0) Hips |
| ⋮ | ⋮ | ⋮ |
| 5.2.77 HeadEnd | array | 3D coordinates of the HeadEnd |
| Gender | Age Group | Detailed | # of Data Samples | Sub Total |
|---|---|---|---|---|
| FM | O | Old: 50–60 s | 226 | 1128 |
| M | Middle: 30–40 s | 430 | ||
| Y | Young: 10–20 s | 472 | ||
| MA | O | Old: 50–60 s | 344 | 1280 |
| M | Middle: 30–40 s | 509 | ||
| Y | Young: 10–20 s | 427 |
| Scenario Code | Scenario | Action Code | Action Class |
|---|---|---|---|
| S101 | stand up and do a presentation | A106 | holding the microphone with both hands |
| ⋮ | ⋮ | ||
| A115 | taking a step forward and bowing a head in greeting | ||
| S102 | sit down and do a presentation | A116 | counting by hand |
| ⋮ | ⋮ | ||
| A123 | expressing a part of the drawn circle | ||
| S103 | stand up and explain | A124 | pointing to the work displayed behind with the left hand |
| ⋮ | ⋮ | ||
| A133 | moving towards the work behind the audience | ||
| S104 | sit down and explain | A134 | waving of hand of greeting |
| ⋮ | ⋮ | ||
| A142 | end greeting while sitting down |
| Scenario Code | Scenario | Action Code | Action Class |
|---|---|---|---|
| S201 | daily life (watching TV) | A001 | looking around and finding the remote control |
| ⋮ | ⋮ | ||
| S202 | consolation | A013 | covering face with hands and sighing |
| ⋮ | ⋮ | ||
| S203 | celebrating birthday | A023 | showing up with a cake |
| ⋮ | ⋮ | ||
| S204 | doctor’s office | A033 | opening the door and entering in |
| ⋮ | ⋮ | ||
| S205 | asking the station staff for directions | A042 | taking a phone out of pocket |
| ⋮ | ⋮ | ||
| S206 | taking a picture of someone else | A052 | taking selfie |
| ⋮ | ⋮ | ||
| S207 | catch up | A065 | showing a phone to the opponent |
| ⋮ | ⋮ | ||
| S208 | shopping for clothes at a department store | A073 | choosing clothes from a hanger |
| ⋮ | ⋮ | ||
| S209 | intercompany business meeting | A083 | bowing down in greeting |
| ⋮ | ⋮ | ||
| S210 | grocery shopping | A096 | looking at the notes while walking |
| ⋮ | ⋮ | ||
| A105 | taking something and putting it in a shopping cart |
| Element | Specification |
|---|---|
| CPU | Intel Xeon Gold 6226R 2.90 GHz |
| Memory | 256 GB |
| GPUs | Nvidia GeForce RTX 3090 |
| OS | Ubuntu 18.04 |
| Framework | Pytorch 1.8.2 + CUDA 11.1 |
| Hyperparameter | Value | Description |
|---|---|---|
| lambda_kld | Weight of KL Divergence | |
| lambda_align | Weight of align loss | |
| time_counter | true | Enable time count in generation |
| tf_ratio | Teacher force learning ratio | |
| use_lie | true | Use Lie Representation |
| batch_size | 16 | Batch size of training process |
| iterations | 50,000 | Training iterations |
| Scenario Code | Evaluation Metrics (Real Motion) | Evaluation Metrics (Generated) | ||||||
|---|---|---|---|---|---|---|---|---|
| FID ↓ | Accuracy ↑ | Diversity → | Multi Modality → | FID ↓ | Accuracy ↑ | Diversity → | Multi Modality → | |
| S101 | 0.050 ± 0.0053 | 0.998 ± 0.0002 | 6.673 ± 0.0843 | 1.576 ± 0.0116 | 0.161 ± 0.0005 | 0.934 ± 0.0008 | 6.636 ± 0.0514 | 1.830 ± 0.0263 |
| S102 | 0.042 ± 0.0039 | 0.993 ± 0.0004 | 6.643 ± 0.0686 | 1.631 ± 0.0198 | 0.524 ± 0.0311 | 0.886 ± 0.0016 | 6.512 ± 0.0930 | 2.052 ± 0.0286 |
| S103 | 0.045 ± 0.0030 | 0.983 ± 0.0005 | 6.599 ± 0.0969 | 1.674 ± 0.0185 | 0.342 ± 0.0113 | 0.864 ± 0.0016 | 6.569 ± 0.0832 | 1.871 ± 0.0177 |
| S104 | 0.039 ± 0.0029 | 0.956 ± 0.0008 | 6.526 ± 0.0821 | 1.965 ± 0.0206 | 0.356 ± 0.0109 | 0.829 ± 0.0018 | 6.689 ± 0.0718 | 2.185 ± 0.0308 |
| S201 | 0.062 ± 0.0047 | 0.979 ± 0.0005 | 6.534 ± 0.0658 | 2.735 ± 0.0163 | 0.387 ± 0.0065 | 0.618 ± 0.0023 | 6.300 ± 0.0554 | 3.971 ± 0.0223 |
| S202 | 0.057 ± 0.0052 | 0.975 ± 0.0006 | 6.536 ± 0.0671 | 2.836 ± 0.0290 | 1.532 ± 0.0161 | 0.612 ± 0.0020 | 6.265 ± 0.0506 | 3.991 ± 0.0296 |
| S203 | 0.051 ± 0.0035 | 0.974 ± 0.0007 | 6.501 ± 0.0648 | 2.357 ± 0.0205 | 1.082 ± 0.0261 | 0.552 ± 0.0018 | 6.154 ± 0.0557 | 4.198 ± 0.0282 |
| S204 | 0.049 ± 0.0033 | 0.986 ± 0.0006 | 6.493 ± 0.0649 | 2.478 ± 0.0238 | 0.487 ± 0.0178 | 0.685 ± 0.0020 | 6.276 ± 0.0625 | 4.301 ± 0.0304 |
| S205 | 0.046 ± 0.0027 | 0.989 ± 0.0004 | 6.496 ± 0.0539 | 3.286 ± 0.0220 | 1.023 ± 0.0157 | 0.441 ± 0.0020 | 6.134 ± 0.0863 | 4.661 ± 0.0218 |
| S206 | 0.054 ± 0.0025 | 0.980 ± 0.0004 | 6.501 ± 0.0578 | 3.119 ± 0.0139 | 0.815 ± 0.0206 | 0.352 ± 0.0025 | 6.220 ± 0.0721 | 5.016 ± 0.0183 |
| S207 | 0.051 ± 0.0036 | 0.981 ± 0.0007 | 6.463 ± 0.0587 | 2.985 ± 0.0483 | 0.841 ± 0.0150 | 0.594 ± 0.0013 | 6.188 ± 0.0703 | 4.628 ± 0.0339 |
| S208 | 0.051 ± 0.0020 | 0.983 ± 0.0006 | 5.973 ± 0.3159 | 2.969 ± 0.0252 | 0.840 ± 0.0197 | 0.513 ± 0.0023 | 5.899 ± 0.0507 | 4.529 ± 0.0248 |
| S209 | 0.044 ± 0.0030 | 0.998 ± 0.0001 | 6.826 ± 0.0538 | 2.064 ± 0.1400 | 0.622 ± 0.1350 | 0.637 ± 0.0848 | 6.585 ± 0.0657 | 2.629 ± 0.2310 |
| S210 | 0.044 ± 0.0028 | 0.998 ± 0.0001 | 6.823 ± 0.0408 | 1.935 ± 0.1290 | 0.520 ± 0.1310 | 0.713 ± 0.0803 | 6.589 ± 0.0689 | 2.408 ± 0.2168 |
| Dataset | Evaluation Metrics (Real Motion) | Evaluation Metrics (Generated) | ||||||
|---|---|---|---|---|---|---|---|---|
| FID ↓ | Accuracy ↑ | Diversity → | Multi Modality → | FID ↓ | Accuracy ↑ | Diversity → | Multi Modality → | |
| HumanAct12 | 0.092 ± 0.007 | 0.997 ± 0.001 | 6.853 ± 0.053 | 2.449 ± 0.038 | 2.458 ± 0.079 | 0.923 ± 0.002 | 7.032 ± 0.002 | 2.870 ± 0.037 |
| NTU-RGB+D | 0.031 ± 0.004 | 0.999 ± 0.001 | 7.108 ± 0.048 | 2.194 ± 0.025 | 0.330 ± 0.008 | 0.949 ± 0.001 | 7.065 ± 0.043 | 2.052 ± 0.030 |
| CMU Mocap | 0.065 ± 0.006 | 0.930 ± 0.002 | 6.130 ± 0.079 | 2.720 ± 0.066 | 2.885 ± 0.116 | 0.680 ± 0.003 | 6.500 ± 0.061 | 4.120 ± 0.056 |
| DGU-HAU (Ours) | 0.041 ± 0.002 | 0.872 ± 0.001 | 6.528 ± 0.047 | 2.129 ± 0.014 | 0.992 ± 0.020 | 0.759 ± 0.001 | 6.157 ± 0.069 | 2.291 ± 0.021 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Park, K.; Kim, D. DGU-HAU: A Dataset for 3D Human Action Analysis on Utterances. Electronics 2023, 12, 4793. https://doi.org/10.3390/electronics12234793
Park J, Park K, Kim D. DGU-HAU: A Dataset for 3D Human Action Analysis on Utterances. Electronics. 2023; 12(23):4793. https://doi.org/10.3390/electronics12234793
Chicago/Turabian StylePark, Jiho, Kwangryeol Park, and Dongho Kim. 2023. "DGU-HAU: A Dataset for 3D Human Action Analysis on Utterances" Electronics 12, no. 23: 4793. https://doi.org/10.3390/electronics12234793
APA StylePark, J., Park, K., & Kim, D. (2023). DGU-HAU: A Dataset for 3D Human Action Analysis on Utterances. Electronics, 12(23), 4793. https://doi.org/10.3390/electronics12234793