
Imbalanced Learning-Enhanced Beam Codebooks towards Imbalanced User Distribution in Millimeter Wave and Terahertz Massive MIMO Systems



{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. System Model
2.1. Channel Model
2.2. User Distribution
2.3. Uplink Transmission
3. Problem Definition
4. Imbalanced Learning
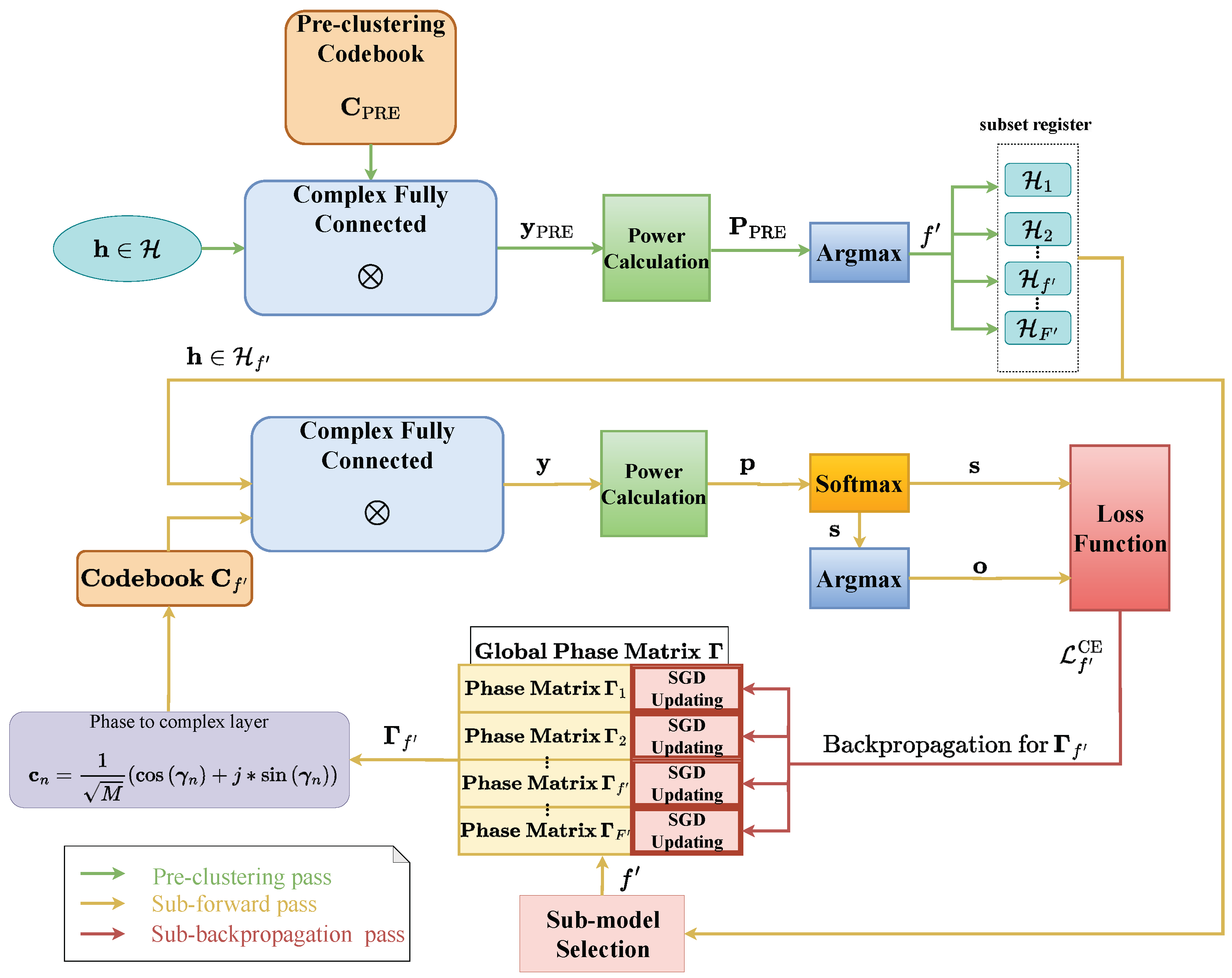
4.1. Model Architecture
4.1.1. Pre-Clustering Process
4.1.2. Complex-Valued Fully Connected and Power Computation Layer
4.1.3. Softmax and Argmax Layer
4.2. Learning the IL-Based Codebooks
4.2.1. Sub-Backpropagation
4.2.2. Global Updating
| Algorithm 1 Imbalanced Learning. |
|
5. Simulation Result
5.1. Scenarios, Datasets, and Training Parameters
5.2. Performance Analysis
5.2.1. Pre-Clustering Result
5.2.2. Achievable Rate and Model Convergence
5.2.3. Beam Pattern
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sohrabi, F.; Yu, W. Hybrid digital and analog beamforming design for large-scale antenna arrays. IEEE J. Sel. Top. Signal Process. 2016, 10, 501–513. [Google Scholar] [CrossRef]
- Heath, R.W.; Gonzalez-Prelcic, N.; Rangan, S.; Roh, W.; Sayeed, A.M. An overview of signal processing techniques for millimeter wave MIMO systems. IEEE J. Sel. Top. Signal Process. 2016, 10, 436–453. [Google Scholar] [CrossRef]
- Alkhateeb, A.; Mo, J.; Gonzalez-Prelcic, N.; Heath, R.W. MIMO precoding and combining solutions for millimeter-wave systems. IEEE Commun. Mag. 2014, 52, 122–131. [Google Scholar] [CrossRef]
- Hur, S.; Kim, T.; Love, D.J.; Krogmeier, J.V.; Thomas, T.A.; Ghosh, A. Millimeter wave beamforming for wireless backhaul and access in small cell networks. IEEE Trans. Commun. 2013, 61, 4391–4403. [Google Scholar] [CrossRef]
- Wang, J.; Lan, Z.; Pyo, C.w.; Baykas, T.; Sum, C.s.; Rahman, M.A.; Gao, J.; Funada, R.; Kojima, F.; Harada, H.; et al. Beam codebook based beamforming protocol for multi-Gbps millimeter-wave WPAN systems. IEEE J. Sel. Areas Commun. 2009, 27, 1390–1399. [Google Scholar] [CrossRef]
- Zhang, Y.; Alrabeiah, M.; Alkhateeb, A. Learning beam codebooks with neural networks: Towards environment-aware mmWave MIMO. In Proceedings of the 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Atlanta, GA, USA, 26–29 May 2020; pp. 1–5. [Google Scholar]
- Alrabeiah, M.; Zhang, Y.; Alkhateeb, A. Neural networks based beam codebooks: Learning mmWave massive MIMO beams that adapt to deployment and hardware. IEEE Trans. Commun. 2022, 70, 3818–3833. [Google Scholar] [CrossRef]
- Zhang, Y.; Alrabeiah, M.; Alkhateeb, A. Reinforcement learning of beam codebooks in millimeter wave and terahertz MIMO systems. IEEE Trans. Commun. 2021, 70, 904–919. [Google Scholar] [CrossRef]
- Li, C.; Yongacoglu, A.; D’Amours, C. Downlink coverage probability with spatially non-uniform user distribution around social attractors. In Proceedings of the 2017 24th International Conference on Telecommunications (ICT), Limassol, Cyprus, 3–5 May 2017; pp. 1–5. [Google Scholar]
- Ye, J.; Ge, X.; Mao, G.; Zhong, Y. 5G ultradense networks with nonuniform distributed users. IEEE Trans. Veh. Technol. 2017, 67, 2660–2670. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Tao, Y.; Mohan, A.; Tian, H.; Kaseb, A.S.; Gauen, K.; Dailey, R.; Aghajanzadeh, S.; Lu, Y.H.; Chen, S.C.; et al. Dynamic sampling in convolutional neural networks for imbalanced data classification. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 112–117. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Deep imbalanced learning for face recognition and attribute prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2781–2794. [Google Scholar] [CrossRef] [PubMed]
- Cao, K.; Wei, C.; Gaidon, A.; Arechiga, N.; Ma, T. Learning imbalanced datasets with label-distribution-aware margin loss. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. SMOTEBoost: Improving prediction of the minority class in boosting. In Proceedings of the Knowledge Discovery in Databases: PKDD 2003: 7th European Conference on Principles and Practice of Knowledge Discovery in Databases, Dubrovnik, Croatia, 22–26 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 107–119. [Google Scholar]
- Zhu, Z.; Wang, Z.; Li, D.; Zhu, Y.; Du, W. Geometric Structural Ensemble Learning for Imbalanced Problems. IEEE Trans. Cybern. 2020, 50, 1617–1629. [Google Scholar] [CrossRef] [PubMed]
- Forenza, A.; Love, D.J.; Heath, R.W. Simplified spatial correlation models for clustered MIMO channels with different array configurations. IEEE Trans. Veh. Technol. 2007, 56, 1924–1934. [Google Scholar] [CrossRef]
- Elbir, A.M.; Coleri, S. Federated learning for hybrid beamforming in mm-wave massive MIMO. IEEE Commun. Lett. 2020, 24, 2795–2799. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Love, D.J.; Heath, R.W. Equal gain transmission in multiple-input multiple-output wireless systems. IEEE Trans. Commun. 2003, 51, 1102–1110. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Liu, P.; Wang, K. Imbalanced Learning-Enhanced Beam Codebooks towards Imbalanced User Distribution in Millimeter Wave and Terahertz Massive MIMO Systems. Electronics 2023, 12, 4768. https://doi.org/10.3390/electronics12234768
Chen Z, Liu P, Wang K. Imbalanced Learning-Enhanced Beam Codebooks towards Imbalanced User Distribution in Millimeter Wave and Terahertz Massive MIMO Systems. Electronics. 2023; 12(23):4768. https://doi.org/10.3390/electronics12234768
Chicago/Turabian StyleChen, Zhiheng, Pei Liu, and Kehao Wang. 2023. "Imbalanced Learning-Enhanced Beam Codebooks towards Imbalanced User Distribution in Millimeter Wave and Terahertz Massive MIMO Systems" Electronics 12, no. 23: 4768. https://doi.org/10.3390/electronics12234768
APA StyleChen, Z., Liu, P., & Wang, K. (2023). Imbalanced Learning-Enhanced Beam Codebooks towards Imbalanced User Distribution in Millimeter Wave and Terahertz Massive MIMO Systems. Electronics, 12(23), 4768. https://doi.org/10.3390/electronics12234768