


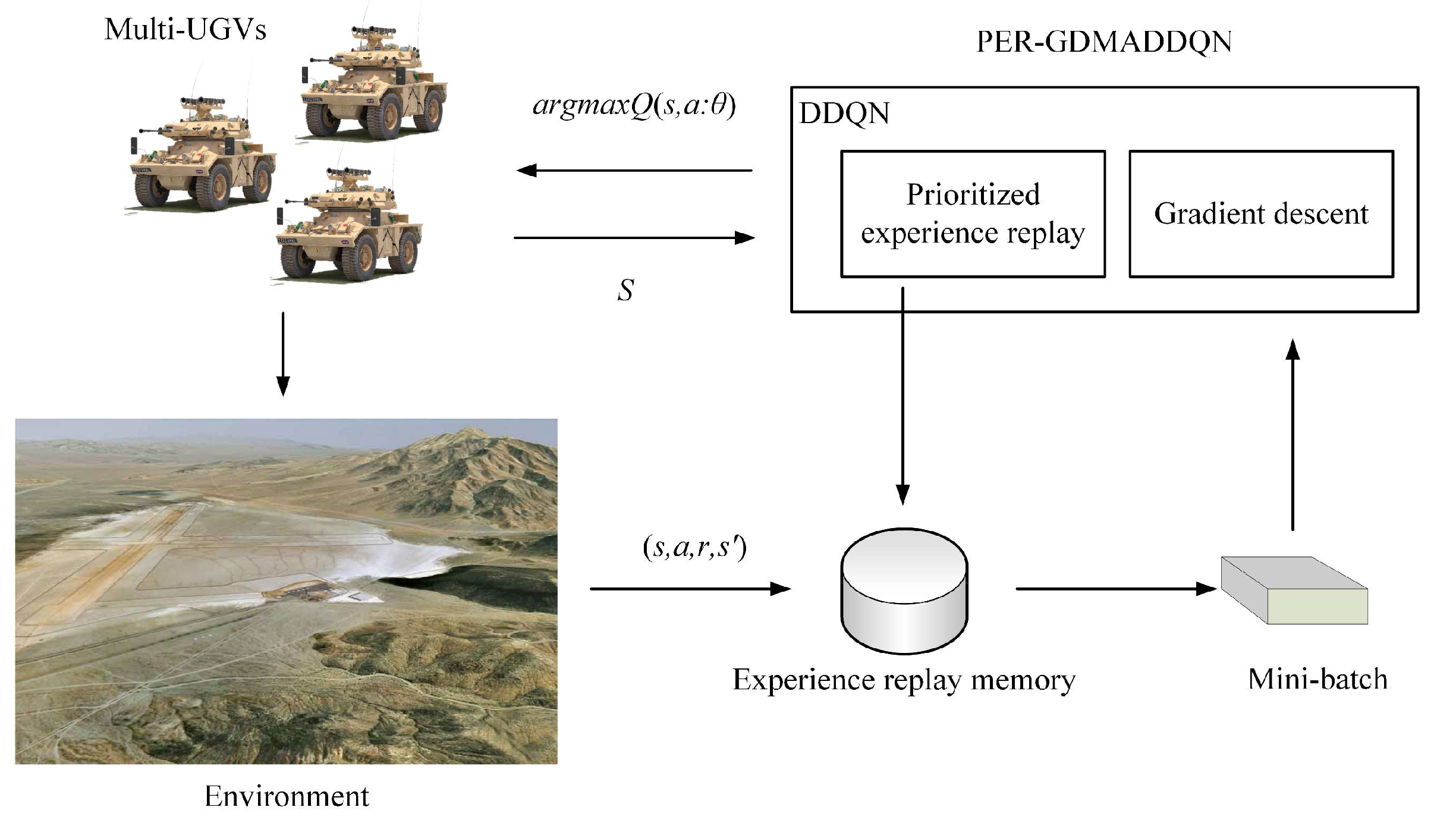
Pursuit Path Planning for Multiple Unmanned Ground Vehicles Based on Deep Reinforcement Learning



Abstract
:1. Introduction
- (1)
- Expanding the traditional four-direction output actions to eight-direction output actions, to improve the smoothness of path planning.
- (2)
- Optimizing the structure of the DDQN algorithm by integrating gradient descent into the sampling process and extending it to multi-UGV systems to solve the pursuit problem.
- (3)
- Using the prioritized experience replay mechanism to improve the network structure and enhance speed.
2. Materials and Methods
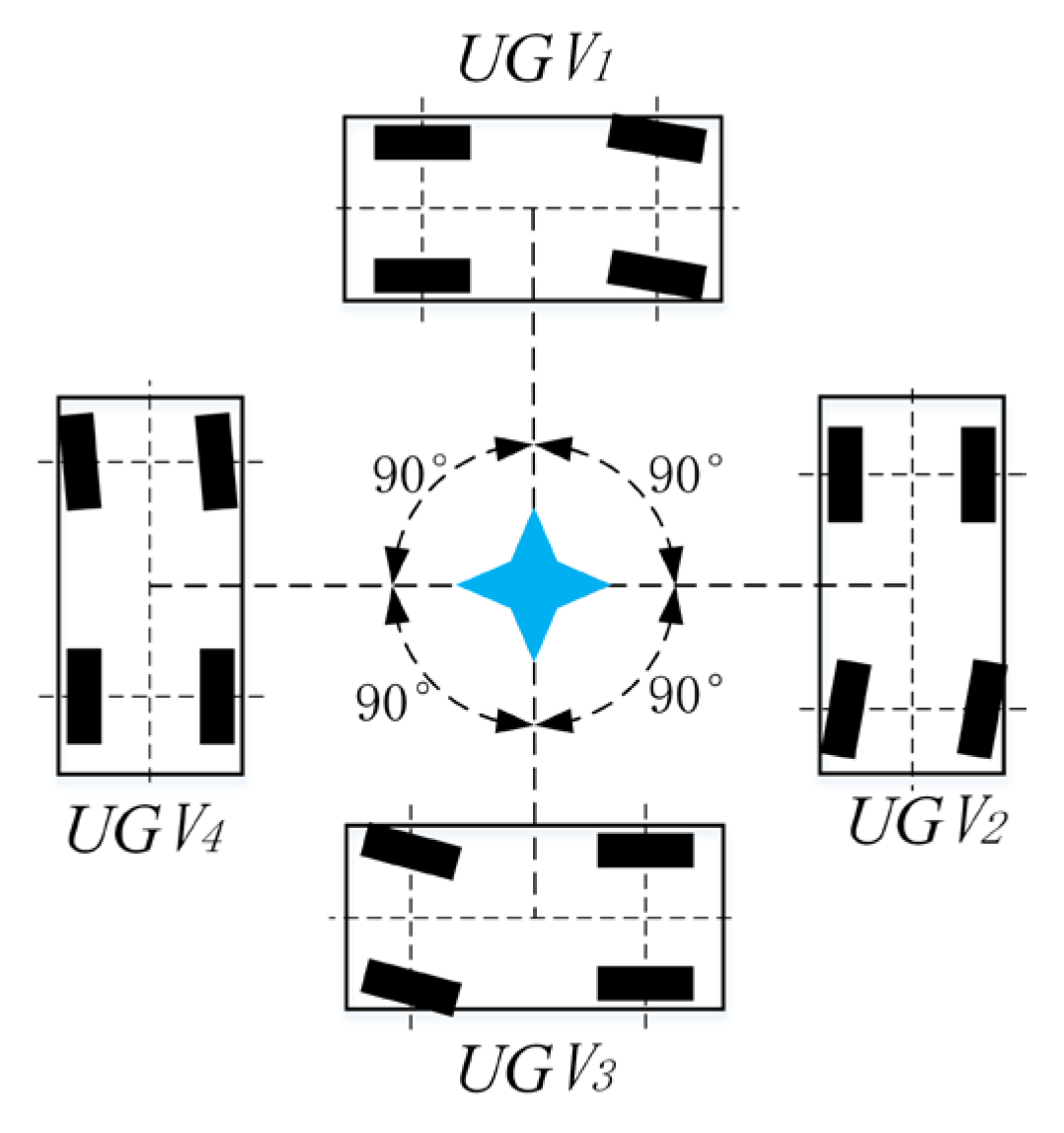
2.1. Problem Formulation
- (1)
- Each vehicle obtains obstacle information through on-board LiDAR as well as cameras.
- (2)
- The UGVs are equipped with vehicle-to-vehicle (v2v), which can share all vehicle status and action information as well as obstacle information to ensure collaboration.
- (3)
- All vehicles can communicate with the ground station in real time and obtain the position and movement information of the target as obtained by the radar of the ground station.
- (4)
- The target can only sense the relative position of vehicles within a fixed distance . If beyond , the information of vehicles cannot be obtained by the target. The speed of the target is less than the maximum speed of the vehicles.
2.2. Kinematic Model of UGV
2.3. Environmental Model
3. Deep Reinforcement Learning
3.1. Q Functions
3.2. Value Function Update
3.3. Double Deep Q-Learning
3.4. Prioritized Experience Replay
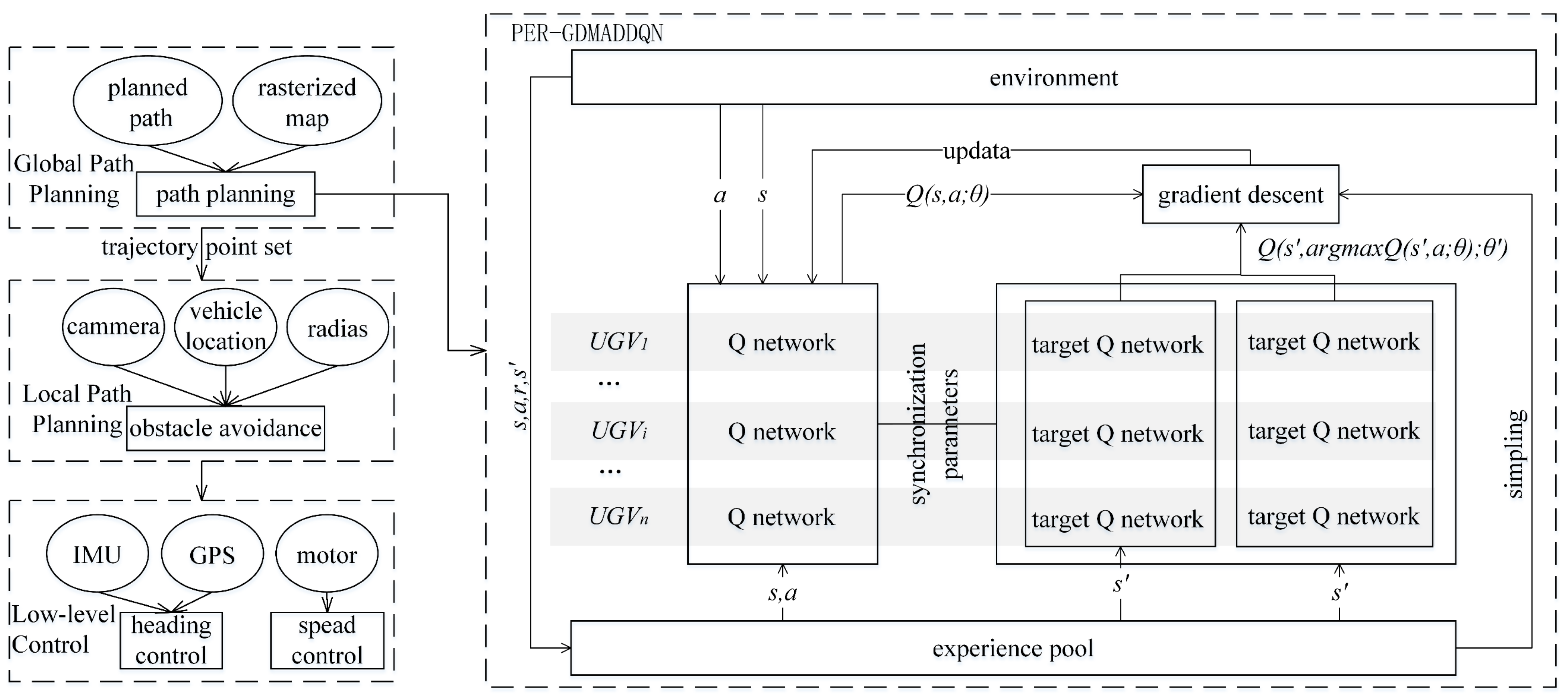
4. Multi-UGV Pursuit Algorithm
4.1. State Representation
- (1)
- The state information of the vehicle itself, including the position information, heading angle, speed, and detection information of the vehicle to obstacles; this can be expressed aswhere is the number of obstacles, and are the relative distances of the obstacle to vehicle in the x and y directions, respectively.
- (2)
- The target information, including the real-time velocity information and relative position information of the target from the ground station; this is expressed as
- (3)
- The teammate information, including the speed information of other vehicles and the relative distance information; this can be described aswhere is the number of vehicles.
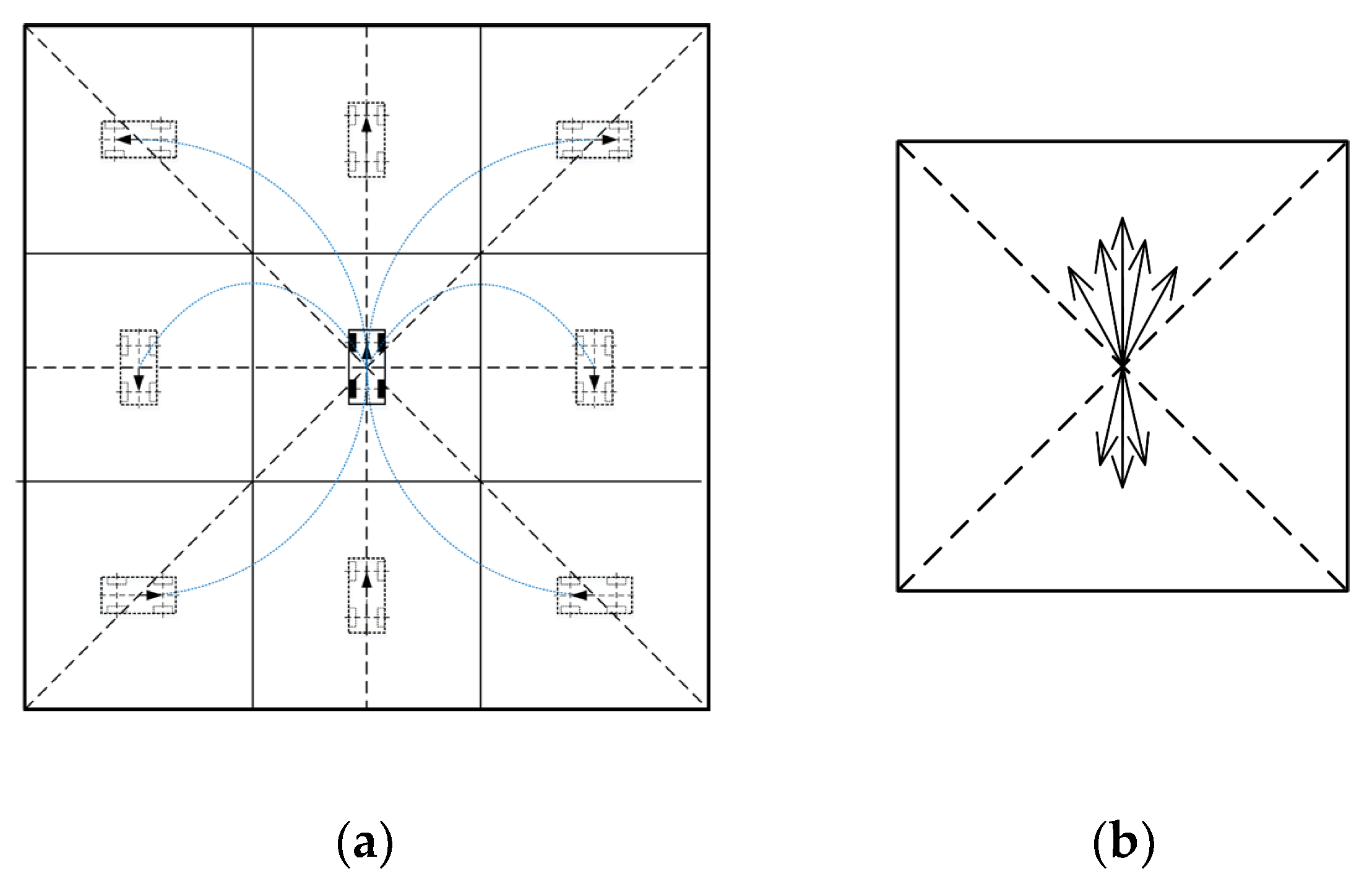
4.2. Action Space
4.3. Reward Function
- (1)
- Reward matrix design
- (2)
- Reward mechanism design
- ①
- The vehicle reaches a distance of 1 to the target and does not collide with boundaries and obstacles.
- ②
- The algorithm reaches 3500 steps and does not collide with the boundary and obstacles, but also does not reach the vicinity of the target.
- ③
- The vehicle collides with the boundary or obstacle, or collides with other vehicles during travel.
4.4. Gradient-Descent-Based Path Smoothing
- (1)
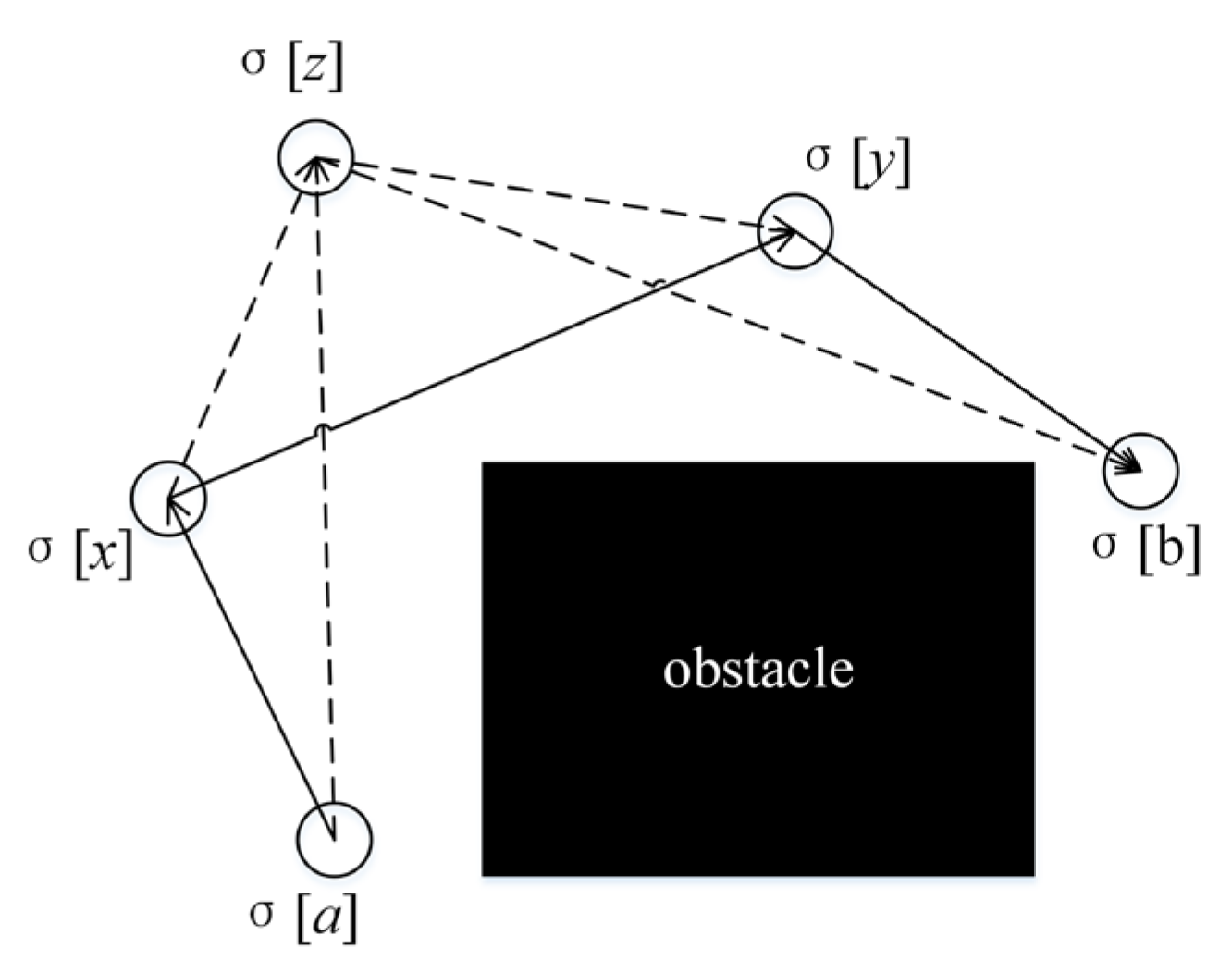
- Gradient-based path deformation: this algorithm moves and inserts the vertices in the obstacle distance field D through gradient descent, where the obstacle distance is calculated aswhere is the continuous vertex position and is the coordinates set occupying the cell. As long as the distance matrix to the obstacle cells has been precomputed, can be determined in constant time by linear interpolation between the cells adjacent to .The gradient in the distance field iswhere is a small constant and .Gradient descent moves the vertex by , where is the step size ( is the initial value) multiplied by the discounting factor in each gradient descent round; furthermore, defines the direction in the distance field.Figure 8. Diagram of gradient descent algorithm.
![Electronics 12 04759 g008]()
- (2)
- Cost-aware path short-cutting: Short-cutting is used to remove the vertices of unnecessary turns to prevent high arc length and large curvature. Firstly, it identifies a vertex that cannot be passed directly (i.e., the path jumps directly from the previous to the next point). A directed acyclic graph is then constructed for each pair of consecutive immovable vertices and ; its vertex is the vertex of the path segment and its edge is the collision-free steering connection between these vertices. It finds the best path from vertex to vertex and removes all vertices in the path segment that are not on the path. The cost-aware path short-cutting iterates over the entire path until no more vertices can be removed or the maximum number of rounds has been reached.
4.5. Pursuit Algorithm Flow
- ①
- create a rasterized map of the terrain to obtain a discrete description of the environment,
- ②
- view the obstacle location and size and learn safe paths based on the proposed algorithm, and
- ③
- train the algorithm to find safe and feasible paths that can be passed to the local path-planning layer.
| Algorithm 1 Multi-UGV pursuit algorithm |
| 1 Initialize the 2D environment, exploration probability , discount factor , q value updating factor ; 2 for episode = 0 to M-1 do 3 Initial position joint state information , , is obtained from the information shared through the communication; 4 while episode not terminated do 5 for vehicle to do 6 take random ; 7 if then 8 Take random action from action space; 9 else 10 action ; 11 Decay exploration probability ; 12 Execute action , then observe reward and next state ; 13 Experience value is stored into experience replay memory E according to priority The stored path is smoothed based on gradient descent; 14 for do 15 Sampling according to : ; 16 Calculate the importance sampling weights according to Equation (19); 17 Calculate according to Equation (15); 18 Update the sample priority: ; 19 if episode terminates at then 20 if collision or all pursuit successful then 21 ; 22 obtain the state of each vehicle from E, and plan the path curve; 23 else 24 ; 25 else 26 ; 27 Compute the loss function ; 28 Execute the optimization algorithm on the loss function to update the Q-network for back propagation; 29 ; |
5. Experiment Evaluation and Results
5.1. Parameter Setting
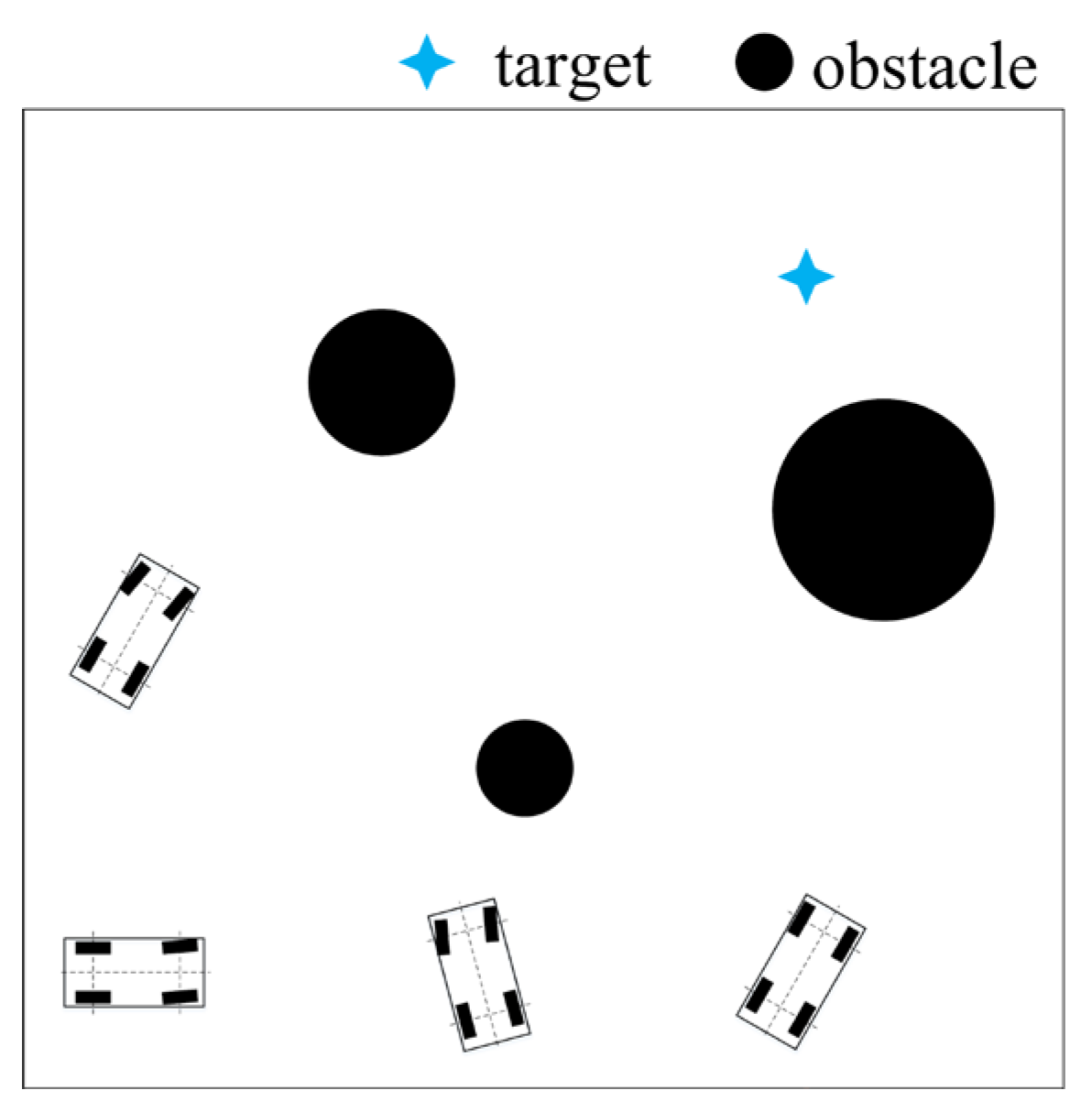
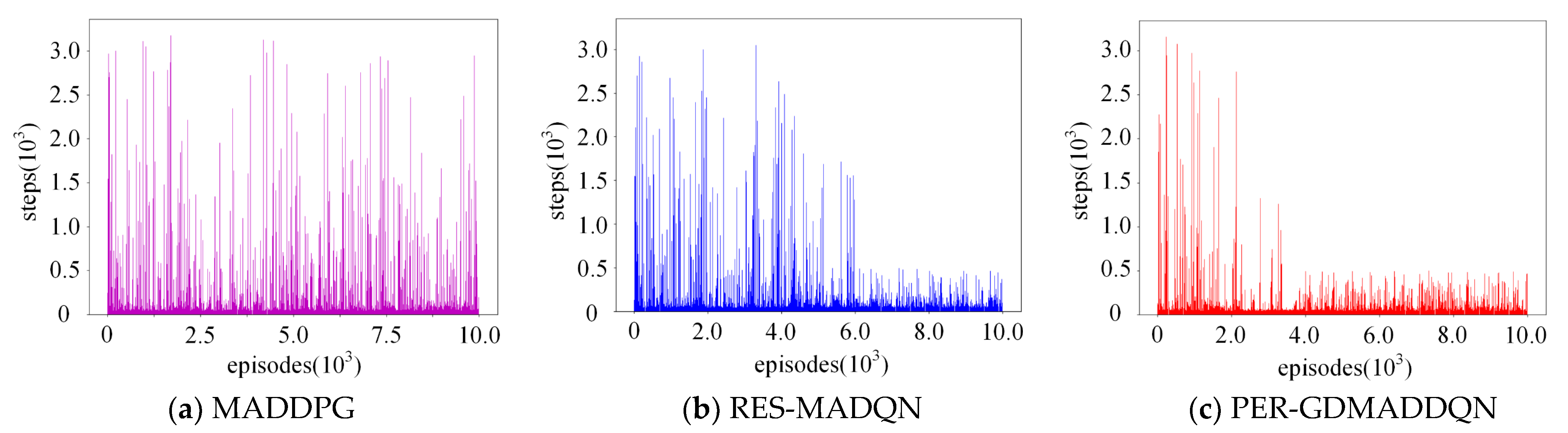
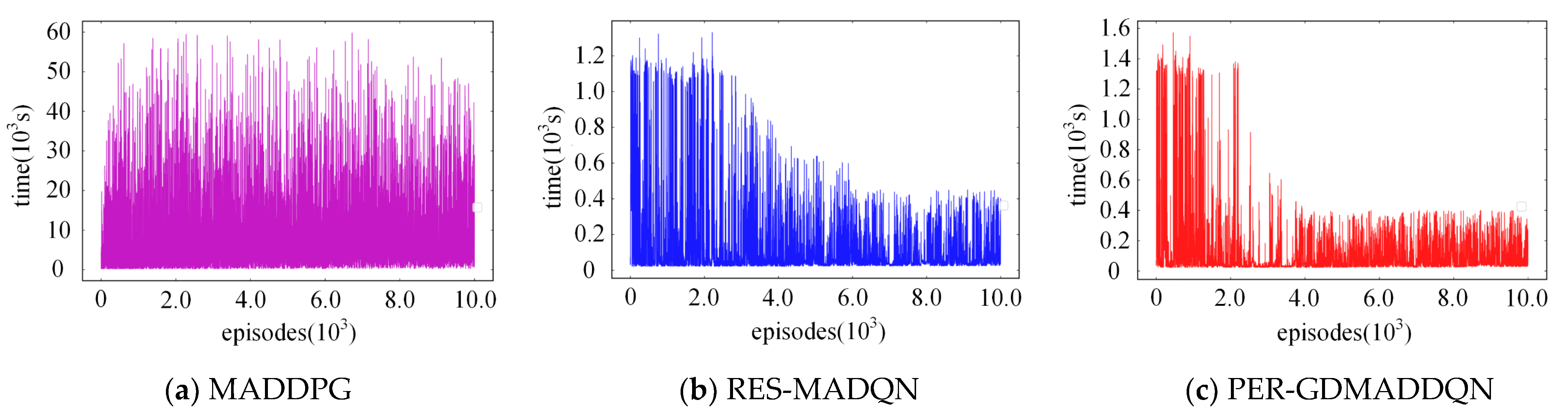
5.2. Static Targets Pursuit
5.3. Dynamic Target Pursuit
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fashey, H.K.M.; Miller, M.J. Unmanned Systems Integrated Roadmap Fiscal Year 2017–2042; United States Department of Defense: Washington, DC, USA, 2017. [Google Scholar]
- Liu, Y.; Jiang, C.; Zhang, T.; Zhao, Z.; Deng, Z. Multi-UAV finite-time ring formation control considering internal collision avoidance. J. Mech. Eng. 2022, 58, 61–68. [Google Scholar]
- Xu, C.; Zhu, H.; Zhu, H.; Wang, J.; Zhao, Q. Improved RRT*Algorithm for Automatic Charging Robot Obstacle Avoidance Path Planning in Complex Environments. Comput. Model. Eng. Sci. 2023, 12, 2567–2591. [Google Scholar] [CrossRef]
- Jiang, W.; Huang, R.; Zhao, Y. Research on cooperative capture method of USVs. In Proceedings of the 9th Academic Conference Professional, Beijing, China, 3–4 July 2021; pp. 45–50. [Google Scholar]
- Sang, H.; You, Y.; Sun, X.; Zhou, Y.; Liu, F. The hybrid path planning algorithm based on improved A* and artificial potential field for unmanned surface vehicle formations. Ocean Eng. 2021, 223, 108709. [Google Scholar] [CrossRef]
- Ding, H.; Cao, X.; Wang, Z.; Dhiman, G.; Hou, P.; Wang, J.; Li, A.; Hu, X. Velocity clamping-assisted adaptive salp swarm algorithm: Balance analysis and case studies. Math. Biosci. Eng. 2022, 19, 7756–7804. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Ding, H.; Yang, Z.; Li, B.; Guan, Z.; Bao, L. Rank-driven salp swarm algorithm with orthogonal opposition-based learning for global optimization. Appl. Intell. 2022, 52, 7922–7964. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Ding, H.; Yang, J.; Wang, J.; Li, B.; Yang, Z.; Hou, P. Advanced orthogonal opposition-based learning-driven dynamic salp swarm algorithm: Framework and case studies. IET Control Theory Appl. 2022, 16, 945–971. [Google Scholar] [CrossRef]
- Wang, Z.; Ding, H.; Wang, J.; Hou, P.; Li, A.; Yang, Z.; Hu, X. Adaptive guided salp swarm algorithm with velocity clamping mechanism for solving optimization problems. Comput. Des. Eng. 2022, 9, 2196–2234. [Google Scholar] [CrossRef]
- Sun, Y.; Lai, J.; Cao, L.; Chen, X.; Xu, Z.; Xu, Y. A Novel Multi-Agent Parallel-Critic Network Architecture for Cooperative-Competitive Reinforcement Learning. IEEE Access 2020, 8, 135605–135616. [Google Scholar] [CrossRef]
- Zhu, P.; Dai, W.; Yao, W.; Ma, J.C.; Lu, H.M. Multi-Robot Flocking Control Based on Deep Reinforcement Learning. IEEE Access 2020, 8, 150397–150406. [Google Scholar] [CrossRef]
- Wu, Z.; Hu, B. Swarm rounding up method of UAV based on situation cognition. J. Beijing Univ. Aero-Naut. Astronaut. 2021, 47, 424–430. [Google Scholar]
- Xu, C.; Zhang, Y.; Wang, W.; Dong, L. Pursuit and evasion strategy of a differential game based on deep reinforcement learning. Front. Bioeng. Biotechnol. 2022, 10, 827408. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Lin, W.; Liu, Z.; Prorok, A. Message-Aware Graph Attention Networks for Large-Scale Multi-Robot Path Planning. IEEE Robot. Autom. Lett. 2021, 6, 5533–5540. [Google Scholar] [CrossRef]
- Fu, X.; Wang, H.; Xu, Z. Research on cooperative pursuit strategy for multi-UAVs based on de-maddpg algorithm. Acta Aeronaut. Et Astronaut. Sin. 2021, 43, 325311. [Google Scholar]
- Yuan, Z.; Wu, T.; Wang, Q.; Yang, Y.; Li, L.; Zhang, L. T3omvp: A transformer-based time and team reinforcement learning scheme for observation-constrained multi-vehicle pursuit in urban area. Electronics 2022, 11, 1339. [Google Scholar] [CrossRef]
- Wang, W.; Hao, J.; Wang, Y.; Taylor, M. Achieving cooperation through deep multiagent reinforcement learning in sequential prisoner’s dilemmas. In Proceedings of the First International Conference on Distributed Artificial Intelligence, Beijing, China, 13–15 October 2019; pp. 1–7. [Google Scholar]
- Mao, W.; Yang, L.F.; Zhang, K.; Başar, T. Decentralized Cooperative Multi-Agent Reinforcement Learning with Exploration. arXiv 2022, arXiv:2110.05707v2. [Google Scholar]
- Hartmann, G.; Shiller, Z.; Azaria, A. Competitive driving of autonomous vehicles. IEEE Access 2022, 10, 111772–111783. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 1–16. [Google Scholar]
- Gong, T.; Yu, Y.; Song, J. Path Planning for Multiple Unmanned Vehicles (MUVs) Formation Shape Generation Based on Dual RRT Optimization. Actuators 2022, 11, 190. [Google Scholar] [CrossRef]
- Zhun, F.; Fuzan, S.; Peili, M.; Wenji, L.; Ze, S.; Zhaojun, W.; Guijie, Z.; Ke, L.; Bin, X. Stigmergy-based swarm robots for target search and trapping. Trans. Beijing Inst. Technol. 2022, 42, 158–167. [Google Scholar]
- González-Sierra, J.; Flores-Montes, D.; Hernandez-Martinez, E.G.; Fernández-Anaya, G.; Paniagua-Contro, P. Robust circumnavigation of a heterogeneous multi-agent system. Auton. Robot. 2021, 45, 265–281. [Google Scholar] [CrossRef]
- Moorthy, S.; Joo, Y.H. Distributed leader-following formation control for multiple nonholonomic mobile robots via bioinspired neurodynamic approach. Neurocomputing 2022, 492, 308–321. [Google Scholar] [CrossRef]
- Huang, H.; Kang, Y.; Wang, X.; Zhang, Y. Multi-robot collision avoidance based on buffered voronoi diagram. In Proceedings of the 2022 International Conference on Machine Learning and Knowledge Engineering (MLKE), Guilin, China, 25–27 February 2022; pp. 227–235. [Google Scholar]
- Kopacz, A.; Csató, L.; Chira, C. Evaluating cooperative-competitive dynamics with deep Q-learning. Neurocomputing 2023, 550, 126507. [Google Scholar] [CrossRef]
- Wan, K.; Wu, D.; Zhai, Y.; Li, B.; Gao, X.; Hu, Z. An improved approach towards multi-agent pursuit-evasion game decision-making using deep reinforcement learning. Entropy 2021, 23, 1433. [Google Scholar] [CrossRef]
- Wen, S.; Wen, Z.; Zhang, D.; Zhang, H.; Wang, T. A multi-robot path-planning algorithm for autonomous navigation using meta-reinforcement learning based on transfer learning. Appl. Soft Comput. 2021, 110, 107605. [Google Scholar] [CrossRef]
- De Souza, C.; Newbury, R.; Cosgun, A.; Castillo, P.; Vidolov, B.; Kuli, D. Decentralized multi-agent pursuit using deep reinforcement learning. IEEE Robot. Autom. Lett. 2021, 6, 4552–4559. [Google Scholar] [CrossRef]
- Xue, X.; Li, Z.; Zhang, D.; Yan, Y. A Deep Reinforcement Learning Method for Mobile Robot Collision Avoidance based on Double DQN. In Proceedings of the 2019 IEEE 28th International Symposium on Industrial Electronics (ISIE), Vancouver, BC, Canada, 12–14 June 2019; pp. 2131–2136. [Google Scholar]
- Zhang, R.; Zong, Q.; Zhang, X.; Dou, L.; Tian, B. Game of Drones: Multi-UAV Pursuit-Evasion Game With Online Motion Planning by Deep Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 7900–7909. [Google Scholar] [CrossRef] [PubMed]
- Parnichkun, M. Multiple Robots Path Planning based on Reinforcement Learning for Object Transportation. In Proceedings of the 2022 5th Artificial Intelligence and Cloud Computing Conference, Osaka, Japan, 17–19 December 2022. [Google Scholar] [CrossRef]
- Longa, M.E.; Tsourdos, A.; Inalhan, G. Swarm Intelligence in Cooperative Environments: N-Step Dynamic Tree Search Algorithm Extended Analysis. In Proceedings of the 2022 American Control Conference (ACC), Atlanta, GA, USA, 8–10 June 2022. [Google Scholar]
- Yu, Y.; Liu, Y.; Wang, J.; Noguchi, N.; Hea, Y. Obstacle avoidance method based on double DQN for agricultural robots. Comput. Electron. Agric. 2023, 204, 107546. [Google Scholar] [CrossRef]
- Liu, B.; Ye, X.; Dong, X.; Ni, L. Branching improved Deep Q Networks for solving pursuit-evasion strategy solution of spacecraft. J. Ind. Manag. Optim. 2022, 18, 1223–1245. [Google Scholar] [CrossRef]
- Dang, F.; Chen, D.; Chen, J.; Li, Z. Event-Triggered Model Predictive Control with Deep Reinforcement Learning for Autonomous Driving. arXiv 2022, arXiv:2208.10302. [Google Scholar] [CrossRef]
- Huang, L.; Hong, Q.; Peng, J.; Liu, X.; Zhen, F. A Novel Coordinated Path Planning Method using k-degree Smoothing for Multi-UAVs. Appl. Soft Comput. 2016, 48, 182–192. [Google Scholar] [CrossRef]
- Dian, S.; Zhong, J.; Guo, B.; Liu, J.; Guo, R. A smooth path planning method for mobile robot using a BES-incorporated modified QPSO algorithm. Expert Syst. Appl. 2022, 208, 118256. [Google Scholar] [CrossRef]
- Song, B.; Wang, Z.; Zou, L. An improved PSO algorithm for smooth path planning of mobile robots using continuous high-degree Bezier curve. Appl. Soft Comput. 2021, 100, 106960. [Google Scholar] [CrossRef]
- Pan, L.; Rashid, T.; Peng, B.; Huang, L.; Whiteson, S. Regularized softmax deep multi-agent q-learning. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), New Orleans, LA, USA, 6–14 December 2021. [Google Scholar]
- Dang, C.V.; Ahn, H.; Lee, D.S.; Lee, S.C. Improved Analytic Expansions in Hybrid A-Star Path Planning for Non-Holonomic Robots. Appl. Sci. 2022, 12, 5999. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Literature (Year) | Architecture | Advantages | Limitations |
|---|---|---|---|---|
| RRT | [21] (2022) | Centralized | Compatible with static and dynamic environments | Does not consider the evaluation of pursuit effectiveness |
| Inverse ACO | [22] (2022) | Decentralized | Achieves better area coverage performance; overcomes the defects of artificially set feature points | Adaptive adjustment of model parameters in different scenarios |
| Inverse step method | [23] (2021) | Centralized | Strong overall robustness of the system to boundary perturbations, distance errors, and angular errors | Collision avoidance needs to be improved |
| Virtual leader-follower | [24] (2021) | Centralized | Achieves single-target and multi-target pursuit | Poor flexibility |
| Voronoi diagram | [25] (2019) | Centralized | Reduces uncertainty across the region and improves efficiency of coordinated region search | Does not consider communication constraints across frames |
| DQN | [26] (2018) | Centralized | Artificial potential field method combined with deep reinforcement learning | Does not consider multiple escapees and captor environments |
| MADDPG | [27] (2021) | CTDE | Reduced error between model and real scenario | Simple scenario with low number of pursuits and obstacles |
| Reinforcement learning | [28] (2022) | Centralized | Decoupling of pursuit algorithms | No consideration of terrain and obstacles to communication |
| Deep learning | [29] (2021) | Decentralized | For non-integrity pursuits | Need to train a network for each escapee |
| Direction | ||
|---|---|---|
| Front | 1.0 | 0 |
| Left-front | 0.5 | 0.5 |
| Left | 0 | 1.0 |
| Left-back | −0.5 | 0.5 |
| Back | −1.0 | 0 |
| Right-back | −0.5 | −0.5 |
| Right | 0 | −1.0 |
| Right-front | 0.5 | −0.5 |
| Action | Reward | Result |
|---|---|---|
| Vehicle collides with other vehicles/boundaries/obstacles | −1000 value in the reward matrix | Terminated |
| Vehicle in passable areas | Value in the reward matrix | Continue |
| Vehicle arrives at a distance of 1 from the target | 1000 | Terminated |
| Hyperparameters | Value | Description |
|---|---|---|
| 0.90 | ||
| Initial | 0.90 | Explore the initial value |
| Final | 0.1 | Explore the final value |
| Minibatch | 32 | Size of the sample |
| Learning rate | 0.03 | Learning rate of the optimizer |
| Experience replay | 10,000 | Capacity of experience replay |
| Memory | True | — |
| Network type | CNN | — |
| Activation function | ReLU | Learning complex patterns in data |
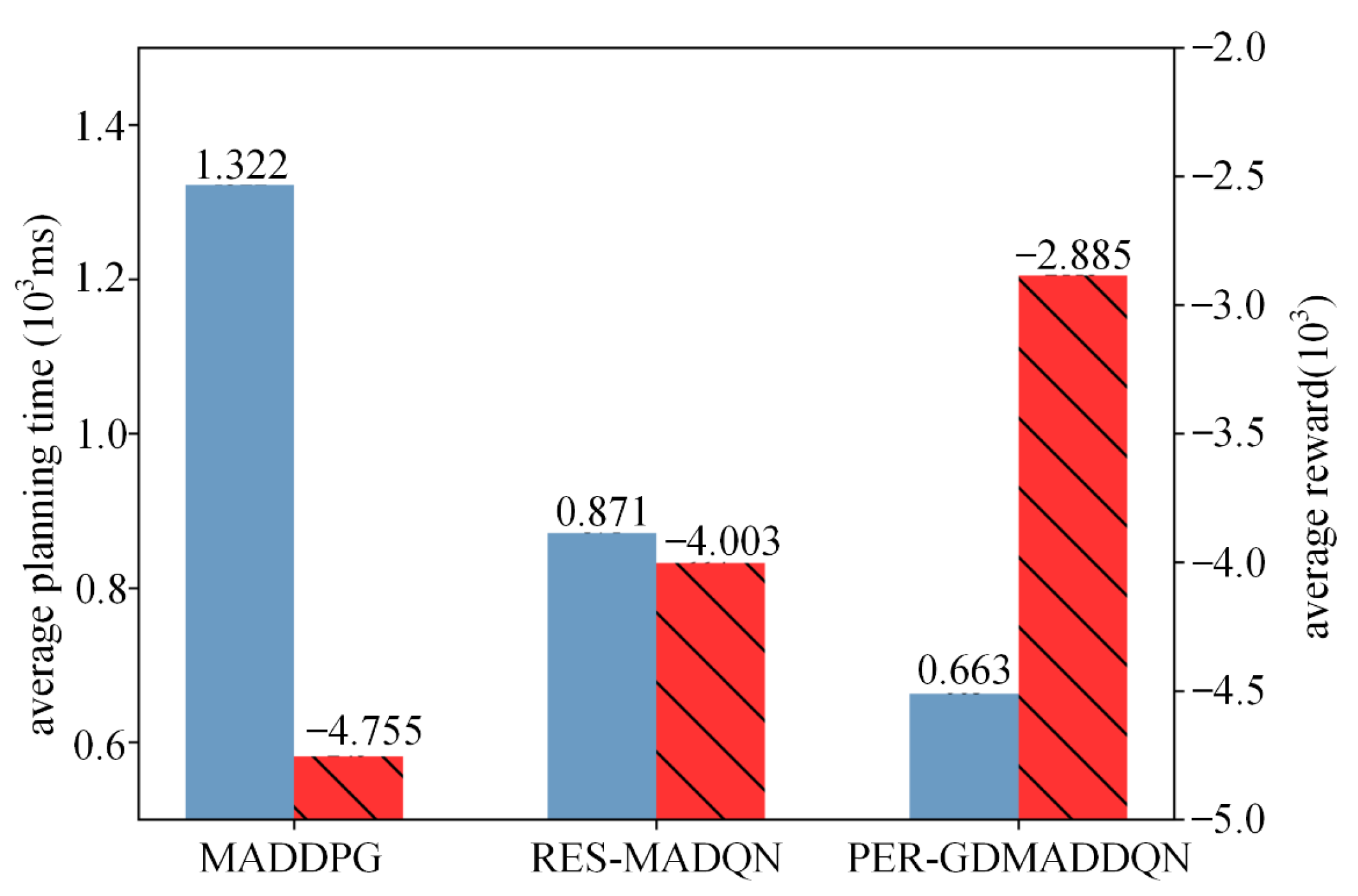
| MADDPG | RES-MADQN | PER-GDMADDQN | |
|---|---|---|---|
| Planning time (ms) | 882 | 561 | 419 |
| Number of turns | 18 | 10 | 6 |
| Performance | MADDPG | RES-MADQN | PER-GDMADDQN |
|---|---|---|---|
| Minimum steps | 185 | 129 | 120 |
| Maximum steps | 3828 | 3506 | 3071 |
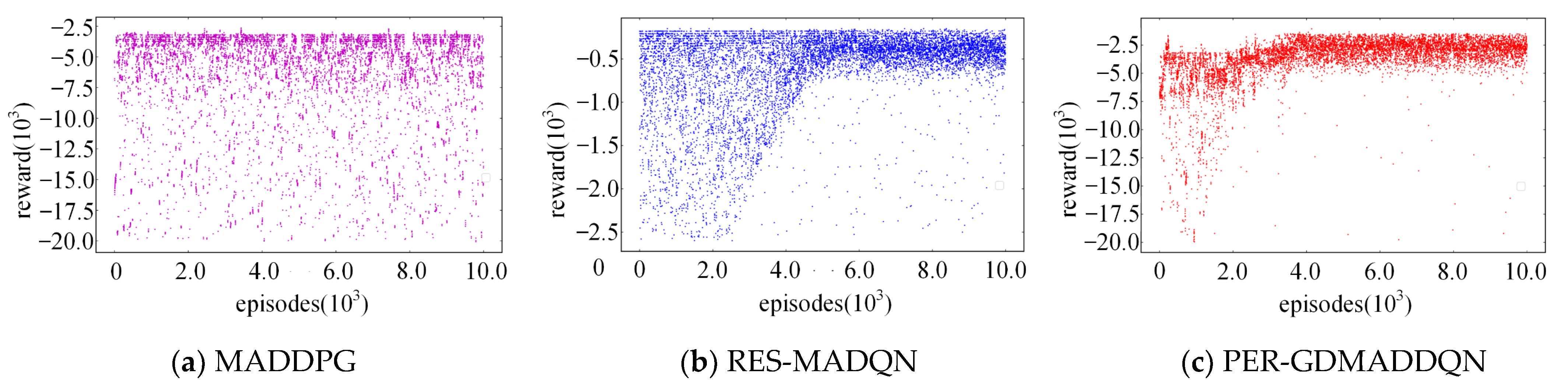
| Convergence | No convergence trend after 10,000 episodes | Convergence after 6000 episodes | Convergence after 2000 episodes |
| Time-consumption | Unconverted | 7169 s | 5026 s |
| Average reward | Unconverted | −3500 | −2600 |
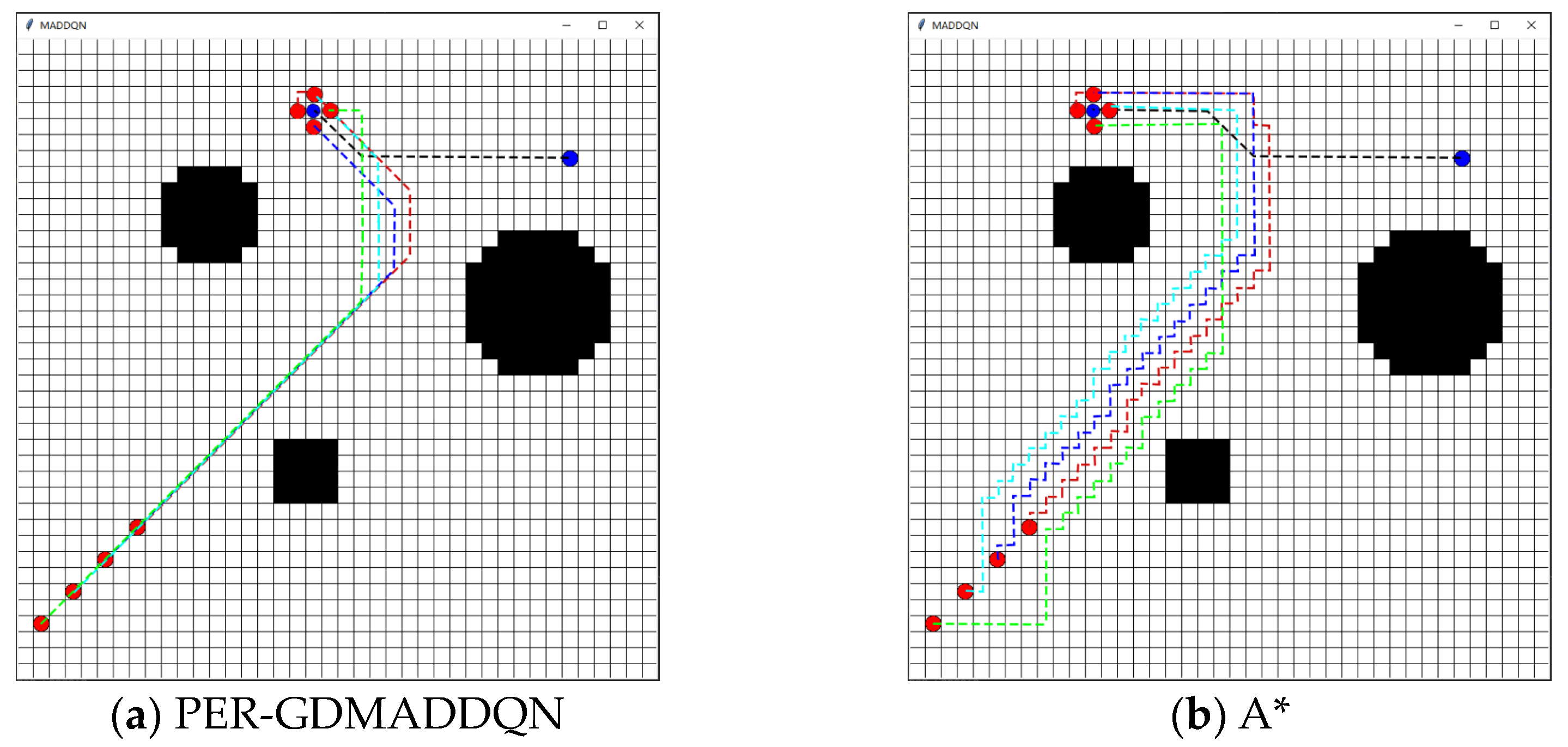
| Parameter | PER-GDMADDQN | A* |
|---|---|---|
| Pursuit consuming (ms) | 692 | 1933 |
| Total path length | 185 | 257 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; Xu, Y.; Ma, Y.; Xu, S.; Li, Z. Pursuit Path Planning for Multiple Unmanned Ground Vehicles Based on Deep Reinforcement Learning. Electronics 2023, 12, 4759. https://doi.org/10.3390/electronics12234759
Guo H, Xu Y, Ma Y, Xu S, Li Z. Pursuit Path Planning for Multiple Unmanned Ground Vehicles Based on Deep Reinforcement Learning. Electronics. 2023; 12(23):4759. https://doi.org/10.3390/electronics12234759
Chicago/Turabian StyleGuo, Hongda, Youchun Xu, Yulin Ma, Shucai Xu, and Zhixiong Li. 2023. "Pursuit Path Planning for Multiple Unmanned Ground Vehicles Based on Deep Reinforcement Learning" Electronics 12, no. 23: 4759. https://doi.org/10.3390/electronics12234759
APA StyleGuo, H., Xu, Y., Ma, Y., Xu, S., & Li, Z. (2023). Pursuit Path Planning for Multiple Unmanned Ground Vehicles Based on Deep Reinforcement Learning. Electronics, 12(23), 4759. https://doi.org/10.3390/electronics12234759