1. Introduction
The retina performs many critical functions as an essential part of the eye. Morphological and density changes of retinal vessels can represent an important basis for the diagnosis of ophthalmic diseases [
1] caused by atherosclerosis, diabetic retinopathy [
2], and glaucoma. To analyze the structural properties of retinal vessels, such as branching patterns, angles, and curvature, accurate segmentation of the retinal vessels is required. Traditional retinal vessel extraction requires manual segmentation by experienced ophthalmologists [
3], which is time-consuming and laborious [
4]. Therefore, automatic segmentation of retinal vessels is of great research value. However, automatic retinal vessel segmentation remains a long-term challenge [
5] due to the following reasons: (1) Due to the equipment used to capture the images and the acquisition environment, the quality of fundus images is poor. In retinal images, the large amount of noise, low contrast between the vessels and the background [
6], and uneven illumination hinder the accurate segmentation of vessels. (2) Retinal images contain abundant capillaries with complex structures, such as vessel crossing, branching, and centerline reflex. In addition, the width and feature intensity of blood vessels vary greatly. These specific characteristics of retinal vessels lead to undesirable segmentation of fine vessels and poor connectivity of vascular structures. (3) Data with good annotations are limited because of the difficulties of acquiring and annotating fundus images. Moreover, the pixel ratio between background and vessels in retinal images is unbalanced. Limited datasets and category imbalance result in poor generalization performance of models.
Deep learning technology is gradually being used in more and more fields. Currently, the medical field is closely related to deep learning techniques [
7] and has achieved many impressive results. Rehman et al. proposed a residual spatial pyramid pooling module based on the U-Net architecture to reduce the loss of location information in different modules. In addition, an attention gate module is utilized to efficiently emphasize and restore the segmented output [
8]. Inspired by game theory, Wang et al. proposed an unsupervised model based on the Swin-Unet framework [
9]. And an image colorization proxy task was introduced to assist the learning of pixel-level feature representations. Zhao et al. designed the residual ghost block with switchable normalization and the bottleneck transformer to extract fine features [
10]. To achieve better tumor identification performance, the feature enhancer block was designed by Rehman et al. Meanwhile, a new loss function was proposed to solve the class imbalance issue [
11]. Lyu et al. proposed a novel multiple-tasking Wasserstein generative adversarial network U-shape network and utilized the attention mechanism to enhance the segmentation accuracy of the generator [
12]. Wang et al. first proposed the Heart–Lung-Sound classification method SNMF-DCNN and applied U-Net for cardiopulmonary sound separation [
13]. Rehman et al. proposed a novel tumor segmentation model, BU-Net [
14]. Residual extended skip, wide context, and a customized loss function are used in the U-Net architecture to enhance the model performance.
With the success of U-Net in the medical field, many researchers are investigating automatic retinal vessel segmentation models based on the U-Net architecture. To enhance the feature extraction ability of the model for blood vessels, Wang et al. designed a two-channel encoder, where the context channel uses multi-scale convolution to capture more receptive field and the spatial channel uses a large kernel to retain spatial information [
15]. Yang et al. introduced deformable convolution [
16] to establish a feature extraction module, which enhances the modeling ability of the model for vessel deformation, and used a residual channel attention [
17] module to improve the efficiency of information transfer between U-Net models [
18]. Liu et al. proposed ResDO-conv, based on depth-wise over-parameterized convolution [
19], as a backbone network for acquiring strong contextual features to enhance feature extraction capabilities [
20]. While enhanced feature extraction capability is desirable, the improvement in fine vessel segmentation performance is limited. To further improve a model’s ability to segment fine blood vessels, one approach is to extract coarse and fine vessel features separately. For instance, Xu et al. constructed a thick and thin vessel extraction module based on the morphological differences in retinal blood vessels to separately extract thick and thin vessel features [
21]. An alternative approach is to retain maximum vessel information to enable the reuse of vascular features. For instance, Yuan et al. used a dropout dense block to replace the original convolutional blocks in U-Net to preserve maximum vessel information between convolution layers through dense connection [
22]. Yue et al. proposed an improved GAN [
23] based on R2U-Net. The attention mechanism [
24] was added to the generator to reduce information loss, and the dense connection modules were used in the discriminator to mitigate gradient vanishing [
25] and achieve feature reuse [
26]. In addition, many other researchers have contributed significantly to automatic retinal vessel segmentation. Li et al. proposed a novel multimodule concatenation method using a U-shaped network that combines atrous convolution [
27] with multikernel pooling blocks to obtain more contextual information [
28]. Deng et al. [
29] proposed a segmentation model based on multi-scale attention with residual mechanism [
30], D-Mnet, combined with the improved PCNN [
31] model to unite the advantages of supervised and unsupervised learning [
32]. Su et al. revealed several best practices for achieving state-of-the-art retinal vessel segmentation performance by analyzing the impact of data processing, architecture design, attention mechanism, and regularization strategy on retinal vessel segmentation performance [
33].
Although there are many automatic retinal vessel segmentation models [
34], most of the methods still have shortcomings in segmenting fine blood vessels and ensuring vascular connectivity. The shortcomings are mainly due to the following reasons: (1) Fundus images contain rich capillaries with large variations in width. Coarse blood vessels with large areas dominate the optimization direction of model parameters, resulting in insufficient feature extraction ability of models for fine blood vessels. (2) For accurate vessel segmentation, the U-shaped structure supplements vessel detail information for decoder features through the encoder features. However, there are information discrepancies between these two types of features, and traditional feature fusion approaches fail to fully utilize the effective information between them [
35]. (3) Most existing retinal vessel segmentation models usually use single-level features to achieve prediction. However, single-level features contain limited information and may include more noise due to the introduction of encoder features, leading to mis-segmentation and bad connectivity of vascular structures.
To address the above issues, a new retinal vessel segmentation model, CMP-UNet, is proposed. The main contributions are as follows: (1) The Coarse and Fine Feature Aggregation (CFFA) module is designed based on the morphological discrepancy between thick and thin vessels. This module decouples and aggregates thick and thin vessel features using two branches, which balances the model’s feature extraction ability for vessels of various sizes. (2) The Multi-Scale Channel Adaptive Fusion (MSCAF) module is designed. It leverages parallel atrous convolution to mine multi-scale contextual features in cascade features and refines these features with the adaptive channel attention module to achieve efficient fusion of cascade features. (3) The Pyramid Feature Fusion (PFF) module is proposed to combine the decoder features into multi-level features following the pyramid form. In this way, the complementary information between the multi-level features can be rationally applied to learn more discriminative representations. Experimental results on three publicly available datasets show that CMP-UNet achieves better segmentation accuracy and generalization ability compared with other methods. It could play an important role in the diagnosis of ophthalmic diseases and reduce the consumption of labor and time.
The remaining sections of this paper are organized as follows:
Section 2 gives a detailed description of the proposed CMP-UNet. In
Section 3, three publicly available datasets and experimental details are presented. In
Section 4, we demonstrate the experimental results and analyze the performance of CMP-UNet in vessel segmentation. Finally, the conclusions and outlooks of this paper are given in
Section 5.
2. Methods
To achieve automatic segmentation of retinal blood vessels, a novel model, CMP-UNet, is proposed to realize the precise segmentation of retinal vessels. This section provides detailed descriptions of the proposed CMP-UNet and each designed module. For convenience, the symbols used in this work are listed in
Table 1.
2.1. Overall Network Architecture
U-Net has been widely used in various medical image segmentation tasks [
36] due to its unique U-shaped structure and suitability for small datasets [
37]. In this paper, based on the U-shaped structure, a novel model, CMP-UNet, is proposed for end-to-end retinal vessel segmentation, and its overall structure is shown in
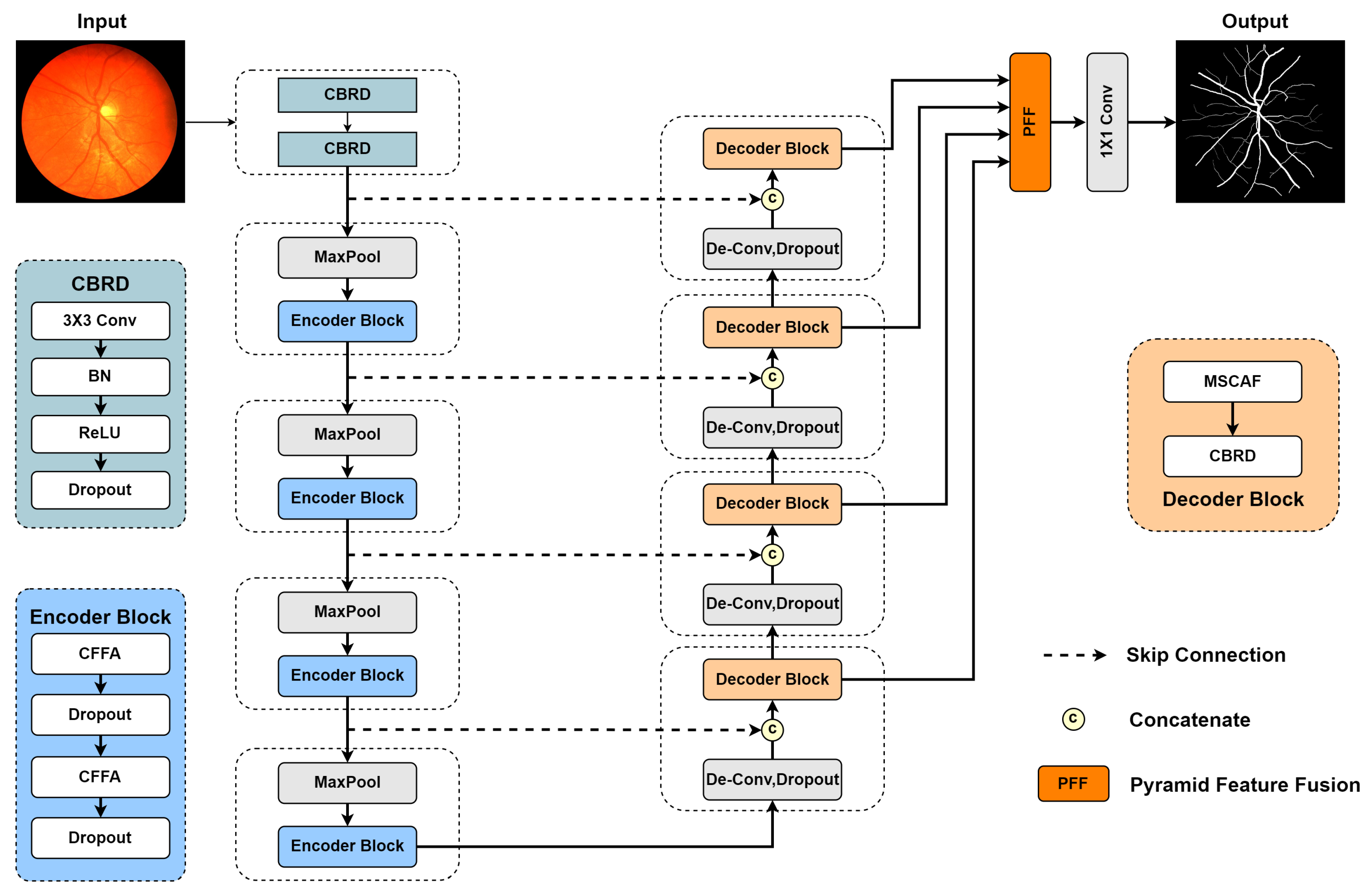
Figure 1. The model consists of five parts: encoder, decoder, CFFA module, MSCAF module, and PFF module.
The input image is first processed by two
convolutional layers to increase the number of channels and obtain the initial feature map,
. Each convolutional layer is followed by a BN [
38] layer for batch normalization to accelerate model training, a ReLU [
39] layer to implement nonlinear mapping, and a Dropout [
40] layer to mitigate overfitting. For convenience, the combination of convolutional, BN, ReLU, and Dropout layers is named CBRD block. Due to the segmentation task [
41] requiring pixel-level prediction results, the initial feature map maintains the original resolution of the input image to avoid information loss. Subsequently, the feature map is fed to the encoder. Several cascade layers, including max pooling with stride 2 and encoder block, are used to map the features into high-dimensional space to extract abstract semantic information. Each encoder block contains two CFFA modules to achieve thick and thin vessel feature extraction and doubles the number of feature channels. In addition, to prevent overfitting, each CFFA module is followed by a Dropout layer. Let
denote the original input of the network; then, the output
of the
ith encoder block can be obtained as follows:
During the decoding stage, deconvolution is used for upsampling and reducing the number of channels by half. Next, feature maps are concatenated with their corresponding ones from the encoder using skip connection. After that, the cascaded features are fed into the decoder block, which consists of an MSCAF module for efficient feature fusion and
convolution for feature decoding. Finally, the output features of each decoder block are forwarded to the PFF module for integration and generate probability map
P with
convolution. Assuming that
denotes the output of the
ith decoder block, we can acquire the probability map with the following formulas:
2.2. Coarse and Fine Feature Aggregation
In fundus retinal images, thin blood vessels exhibit weak localized features, making them susceptible to background noise interference [
42]. In contrast, thick blood vessels possess stronger characteristics that dominate the optimization direction of the model parameters [
43]. This leads to the network’s feature extraction ability imbalance for vessels of different sizes, ultimately hindering the segmentation of fine vessels. Most existing retinal vessel segmentation models use a single branch to extract features, which fails to achieve uniform characterization of coarse and fine vessels. Taking inspiration from the method in [
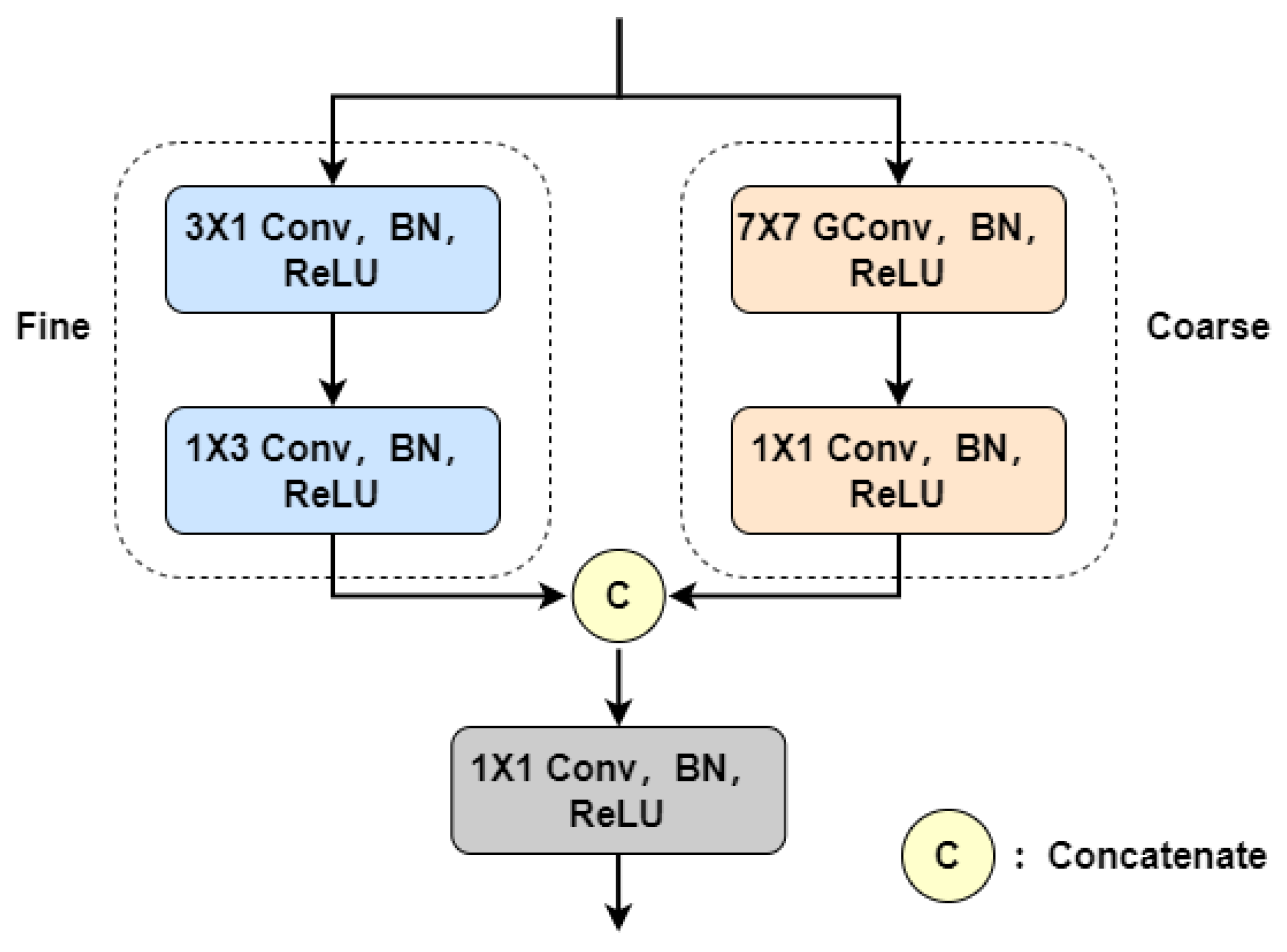
21], we propose the CFFA module, as illustrated in
Figure 2.
For coarse blood vessels, the distance between target pixels is remote due to their large size. To acquire long-range contextual information with lower computational overhead, group convolution (GConv) with a large kernel [
44] is used in the coarse branch. However, for fine vessels, using a large convolution kernel may introduce unnecessary background information and noise, resulting in the loss of capillary details. Therefore, we employ heterogeneous convolution with a small kernel for extracting fine vessel features. This strategy helps to reduce the interference of background information and noise, enabling the network to focus more on modeling fine vessel features. The following provides a detailed description of these two branches.
The coarse branch consists of a
group convolution operation and a
convolution operation. The fine branch includes a
convolution operation and a
convolution operation. Each convolutional layer is followed by a BN layer and a ReLU layer. Let
and
be the input and output of the CFFA module, respectively. For the coarse branch, a
group convolution operation is first used to capture the long-range context information (
) of the thick vessels; then, features from each group are fused through
convolution to obtain the output (
) of this branch. In the fine branch, vertical feature
is constructed using
convolution; then, horizontal feature
is further extracted using
convolution. Finally, the outputs of the two branches are merged using
convolution to aggregate coarse and fine vessel features. The overall procedure of the CFFA module can be formulated as follows:
Ref. [
21] employs two parallel U-shaped networks to separately segment coarse and fine blood vessels. During the feature extraction process, there is no exchange of information between these networks, just a simple fusion of their outputs at the end. Instead, we design an independent dual-branch module and use it as the basic component of the encoder. This approach suppresses redundant information among aggregated features by highlighting the differences between thick and thin vessel features, and it also maintains a lower computational burden.
2.3. Multi-Scale Channel Adaptive Fusion
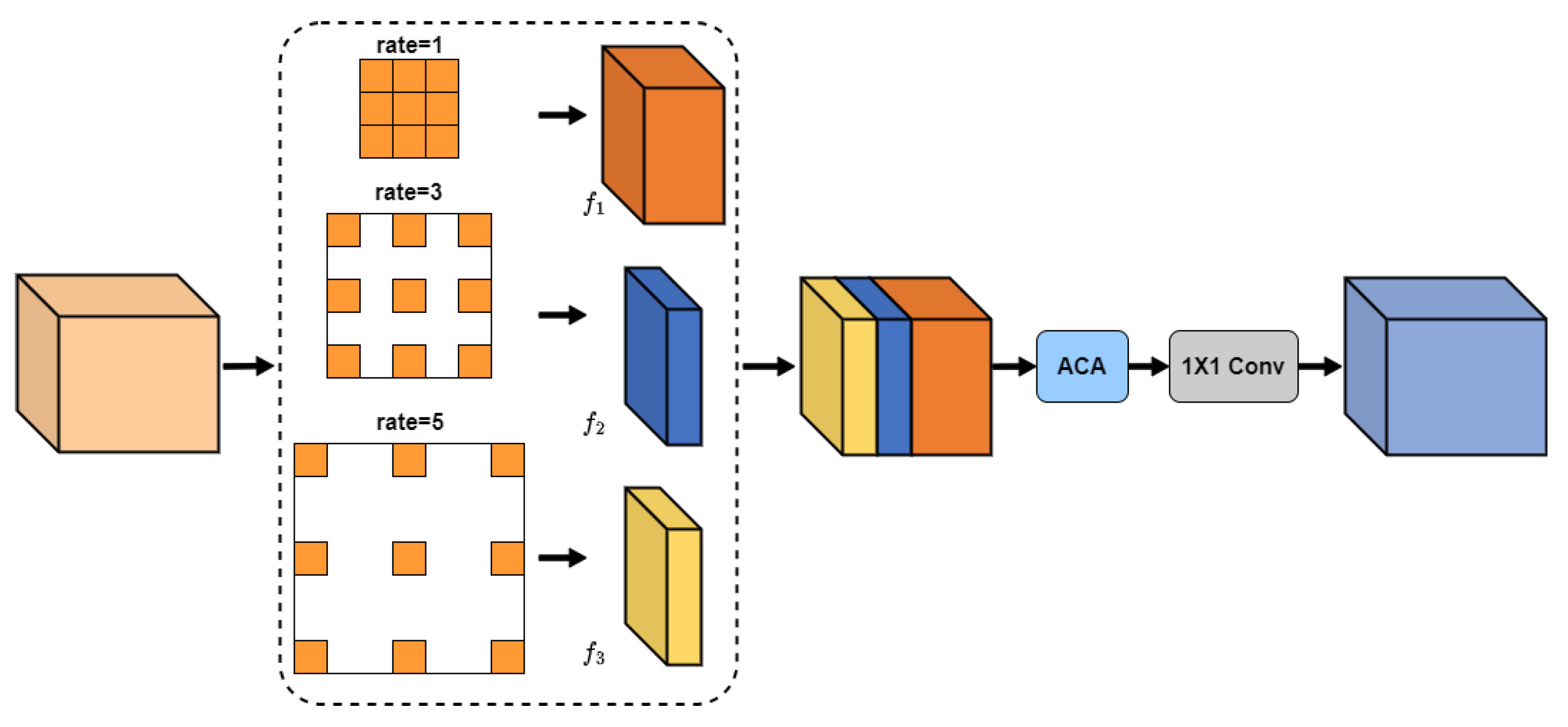
To construct long-range contextual information about retinal vessels, features are gradually downsampled in the encoder to expand the receptive field. However, the slender and variable vessel structure can lead to the loss of fine vessel details and vessel edge information, hindering the accurate segmentation of the vessels. To address this issue, the encoder delivers vessel detail information to the decoder using skip connection. For example, in the U-Net architecture, features from both the encoder and decoder are concatenated, followed by fusion and decoding using two convolution operations. Nevertheless, this approach fails to achieve adequate fusion due to the semantic gap between these types of features. To achieve more efficient feature fusion, the MSCAF module (see
Figure 3) is proposed in this paper and embedded into the decoder of the network.
The informational difference between encoder and decoder features is manifested by the fact that they contain contextual features at different scales. Traditional feature fusion methods only consider the commonalities and differences between features at a single scale, causing the fused features to contain a lot of redundant information. Therefore, the proposed MSCAF module needs to acquire the capability of capturing multi-scale contextual features. In addition, considering that contextual features at varying scales have different impacts on vascular segmentation results, it is essential to enable the model to automatically assess the importance of these features. Therefore, the MSCAF module should also be capable of dynamically assigning weights to them. More details on the MSCAF module are given below.
Firstly, multi-scale contextual features are extracted from the cascade features using several atrous convolution operations with rates set to 1, 3, and 5, respectively. To obtain precise segmentation results, more local contextual features should be captured. Let N denote the channel number of F. Then, the channel numbers of , , and are N/2, N/4, and N/4, respectively.
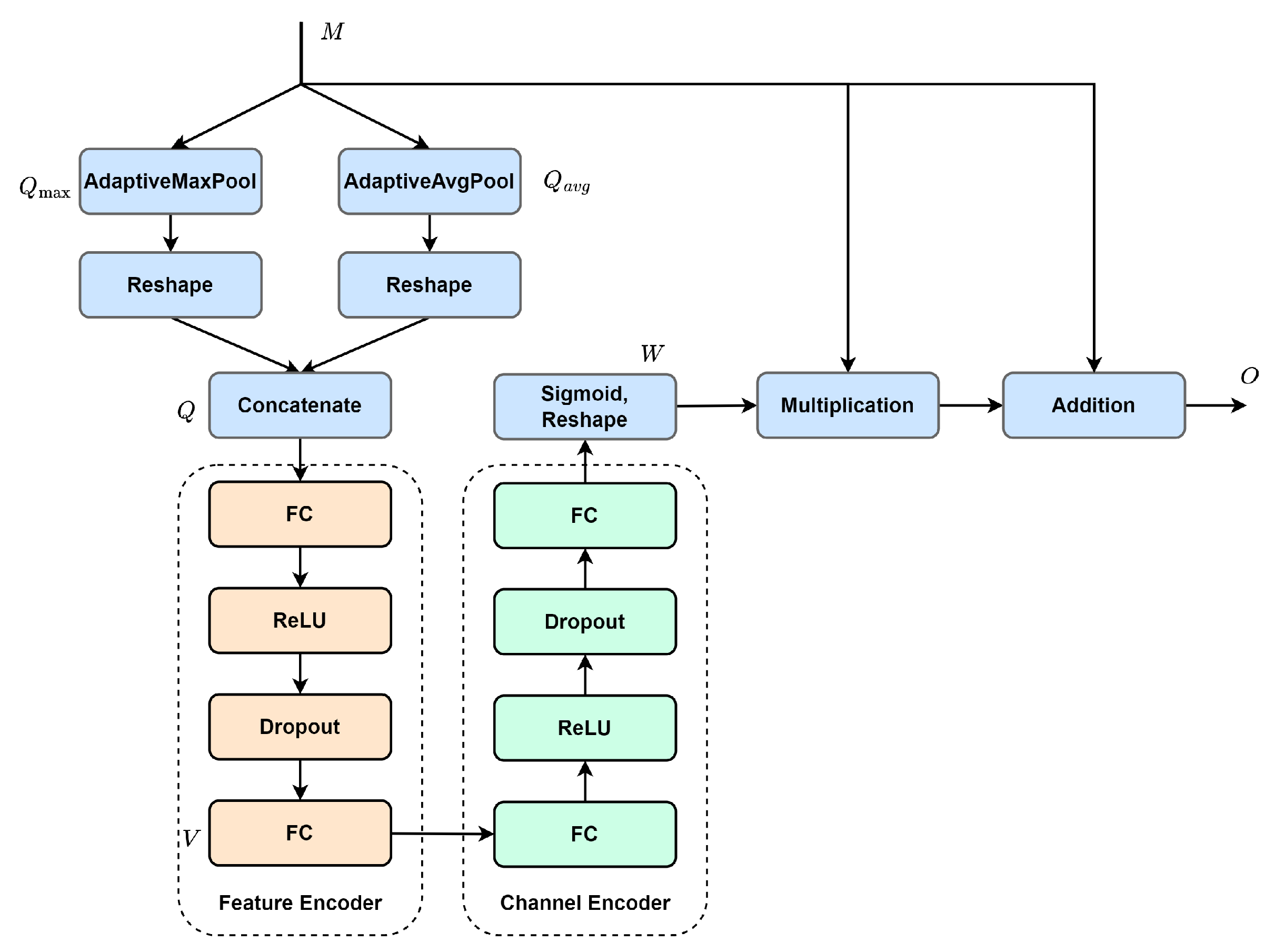
Next, the multi-scale contextual features are forwarded to the adaptive channel attention module (see
Figure 4) for adaptive activation, enhancing valuable information while suppressing redundant information. The activation process is as follows: (1) Spatial information is extracted from input
utilizing adaptive pooling to generate two different spatial context descriptors,
and
. They are then reshaped and concatenated along the spatial dimension to form the initial key feature,
. (2) The initial key feature is sequentially encoded with the feature encoder and the channel encoder. Subsequently, the encoded result is mapped between 0 and 1 using the sigmoid function, with dimension reshaping, to obtain attention map
. (3) The attention map is used to re-weigh the input feature with element-wise multiplication. In addition, to mitigate gradient vanishing, the re-weighed feature is combined with the input feature using element-wise addition to form the final output,
O. The process of the ACA module can be described as follows:
where
denotes adaptive maximum pooling,
denotes adaptive average pooling, and superscript
r denotes reshape. Obviously, the increase in channel number leads to more complex inter-channel dependencies. To make the initial key feature adaptively fit in the inter-channel dependencies with different dimensions, we assume that the resolution (
K) of the initial key feature is proportional to channel dimension
C. Then,
K can be calculated with the following equation:
Finally, the efficient fusion of activated features is achieved with a convolution operation. The ACA module differs from traditional channel attention. Traditional methods obtain the global feature descriptor, which characterizes overall information using global pooling. The descriptor is then leveraged to generate the attention map. This may not effectively capture global information and is susceptible to noise. In contrast, the ACA module does not extract the global feature descriptor directly. It first extracts several local feature descriptors from the feature map using adaptive pooling. Then, a multi-layer perceptron is used to nonlinearly map these descriptors to obtain the global feature descriptor for generating the attention map. This approach is less susceptible to noise interference and can obtain a more accurate attention map.
2.4. Pyramid Feature Fusion
In the decoder, high-level features contain rich semantic information that helps to localize the vessel trunk and improve the continuity of vessel segmentation results. However, these low-resolution high-level features contain less detailed information, especially fine vessels and vessel edges. Conversely, low-level features possess higher resolution, which includes finer details but also introduces more noise. To attain more discriminative vessel features and enhance the overall continuity of the vessel structure, it is imperative to fully exploit the valuable information within each decoder layer. To address this requirement, we introduce the PFF module, with its specific structure being depicted in
Figure 5.
To efficiently capitalize the information from multi-level features, the proposed module needs to satisfy the following demands: Firstly, it should adopt a simple approach to integrating the features of each decoder layer, because the complex module structure can hinder gradient backpropagation, thereby increasing the difficulty of training the network. Secondly, the module should be equipped with efficient feature fusion capability to handle the discrepancy in features in each layer. Lastly, it should be lightweight to avoid a substantial increase in computational overhead and prevent overfitting.
Let denote the generated features at different layers of the decoder, where , , , . Initially, these features are compressed using convolution to avoid a large increase in model computation. To ensure there is enough detailed information to produce precise vessel segmentation results, we expect more low-level features to be included in the multi-level features. Therefore, the numbers of feature channels are set to 16, 8, 4, and 4 for , , , and , respectively. Subsequently, these features are enlarged to the same size as using bilinear interpolation and concatenated along the channel dimensions to generate multi-level features . Then, the multi-level features are fed into the MSCAF module for adaptive fusion to bridge the semantic gap between the features of each layer. Finally, is used to supplement the detailed information of the fused features using element-wise addition.
4. Results
In this section, we systematically analyze the performance of CMP-UNet. First, we show the performance of the model as a whole and give the segmentation results for the test dataset. Second, we compare CMP-UNet with some other retinal vessel segmentation methods proposed in recent years to verify the excellent performance of the model. Then, we conduct ablation experiments on the CHASE_DB1 dataset to demonstrate the effectiveness of the designed modules. Finally, the generalization ability of the proposed model is analyzed with cross-experiments.
4.1. Vessel Segmentation Results
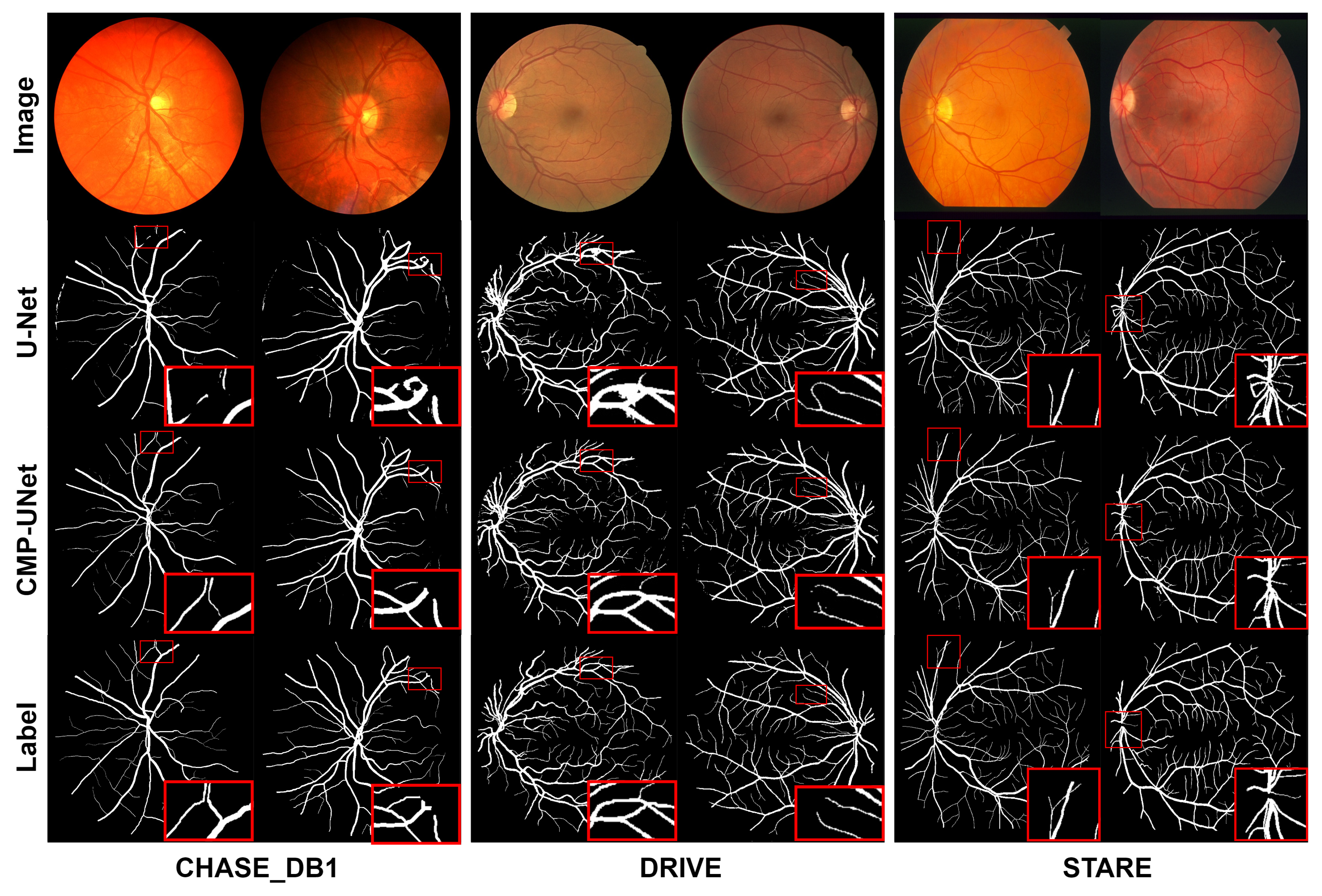
To evaluate the performance of CMP-UNet, we conducted comprehensive qualitative and quantitative analyses on three datasets: CHASE_DB1, DRIVE, and STARE. The retinal vessel segmentation results for the three datasets are shown in
Figure 7. We can clearly observe that the proposed model is able to segment both fine and complex vessels more accurately and better maintain the connectivity of the vascular structure. This is crucial for the diagnosis and tracking of diseases such as early diabetic retinopathy. In particular, from the results of the DRIVE dataset, when dealing with U-Net over-segmented samples, the proposed model still achieves accurate segmentation.
Table 3 shows the segmentation performance of CMP-UNet on the three datasets. On the CHASE_DB1 and DRIVE datasets, the proposed model outperforms U-Net and the second expert in all metrics. Notably, although our model is trained using the annotations of the first expert, it exceeds the second expert. This indicates that our model is able to provide more consistent and accurate segmentation results while simulating the expert annotations. This difference in results is less than the discrepancy between experts’ annotations, further demonstrating the excellent segmentation performance and generalization ability of our model.
However, on the STARE dataset, the proposed model has some limitations in vessel discrimination due to the small number of training samples. This limitation is reflected in a reduction in the SE metric. U-Net faces the same problem, resulting in a significant decrease in SE. Therefore, U-Net was unable to accurately detect blood vessels against the background, leading to an increase in background pixels, which is reflected in a larger SP metric.
4.2. Comparison with the Existing Methods
We compared the proposed model with other state-of-the-art retinal vessel segmentation models proposed in recent years on the CHASE_DB1, DRIVE, and STARE datasets, and the experimental results are shown in
Table 4,
Table 5 and
Table 6.
Table 4 presents the comparison results of the proposed model, CMP-UNet, with other models on the CHASE_DB1 dataset. It can be seen that our model achieves 97.80%, 84.31%, 98.70%, and 82.84% in the four metrics of ACC, SE, SP, and F1, respectively, which are clearly better results than those of the other models.
Table 5 demonstrates the comparison results for the DRIVE dataset. CMP-UNet achieves the best results in the two metrics of ACC and SE, reaching 96.96% and 82.61%, respectively. The SP and F1 results are also superior, with differences of 0.43% and 0.6% from the best results. As shown in
Table 6, the ACC, SE, and F1 results of the proposed model are the best on the STARE dataset, reaching 97.62%, 85.36%, and 84.14%, respectively. Compared with the best results of other models, SP has a numerical gap of 0.8%, which is not a significant decrease.
Combined with the above, CMP-UNet can achieve the highest values of ACC and SE scores on all three datasets, and the F1 metrics are significantly improved on the CHASE_DB1 and STARE datasets. ACC is a comprehensive metric for all prediction categories, SE measures the proportion of blood vessels correctly recognized, and F1 indicates the similarity between prediction and ground truth. From this, it could be inferred that the proposed model has better vessel discrimination ability and generalization ability.
Nevertheless, on the STARE and DRIVE datasets, the enhancement effect of SP is insignificant. This is because of the lower resolution of the STARE and DRIVE datasets as well as the denser distribution of fine vessels. Although the proposed model can detect more fine blood vessels, it simultaneously incorrectly mis-segments some background near fine blood vessels as vessels, resulting in a smaller SP improvement.
4.3. Ablation Analysis
The proposed model, CMP-UNet, improves performance in retinal vessel segmentation by introducing three independent modules: the CFFA module, the MSCAF module, and the PFF module. In order to evaluate the impact of the three designed modules on the proposed model, ablation experiments were conducted on the CHASE_DB1 dataset. To ensure the fairness of the experiments, all comparison methods used the same training strategy and hyperparameter settings. There were five sets of experiments: (1) baseline (U-Net), (2) C-UNet (adding the CFFA module to the encoder), (3) M-UNet (embedding the MSCAF module in the decoder), (4) CM-UNet (using both CFFA module and MSCAF module), (5) CMP-UNet.
Table 7 demonstrates the results of the ablation experiments.
With the introduction of the CFFA module in the encoder, the results show improvements in ACC, SE, and F1, especially SE and F1, which improved by 0.86% and 0.45%, respectively, compared with the baseline. This indicates that the CFFA module improves the model’s ability to extract vascular features and helps to detect more fine vessels.
The SE and F1 of our model are separately improved by 1.16% and 0.21% after embedding the MSCAF module into the decoder. This means that the MSCAF module is able to fuse complementary information from multi-scale features in a more efficient way, which reduces the loss of vascular information to segment more vessels.
When both the CFFA module and the MSCAF module are used, the ACC, SE, and F1 of the proposed model are improved. Among them, SE and F1 have greater improvements, 1.58% and 0.66%, respectively. Due to the combined effect of the two modules, the ability of the model to extract vessel features is significantly improved. Nevertheless, this may also lead to mis-classifying some background as vessels, causing a slight decrease in the SP value.
Finally, CMP-UNet outperforms U-Net in ACC, SE, SP, and F1, reaching 97.80%, 84.31%, 98.70%, and 82.84%, respectively. Among them, ACC, SP, and F1 reached the maximum values of several sets of experiments, proving the effectiveness of the model.
Comprehensive analysis results of these ablation experiments strongly confirm that the introduced modules effectively improve the performance of CMP-UNet. The segmentation results for each model are visualized in
Figure 8, including slices of the fundus image, the ground truth, and the segmentation results for each model. It can be seen that the performance of the model can be progressively improved by sequentially introducing the designed modules in the baseline model.
4.4. Generalization Analysis
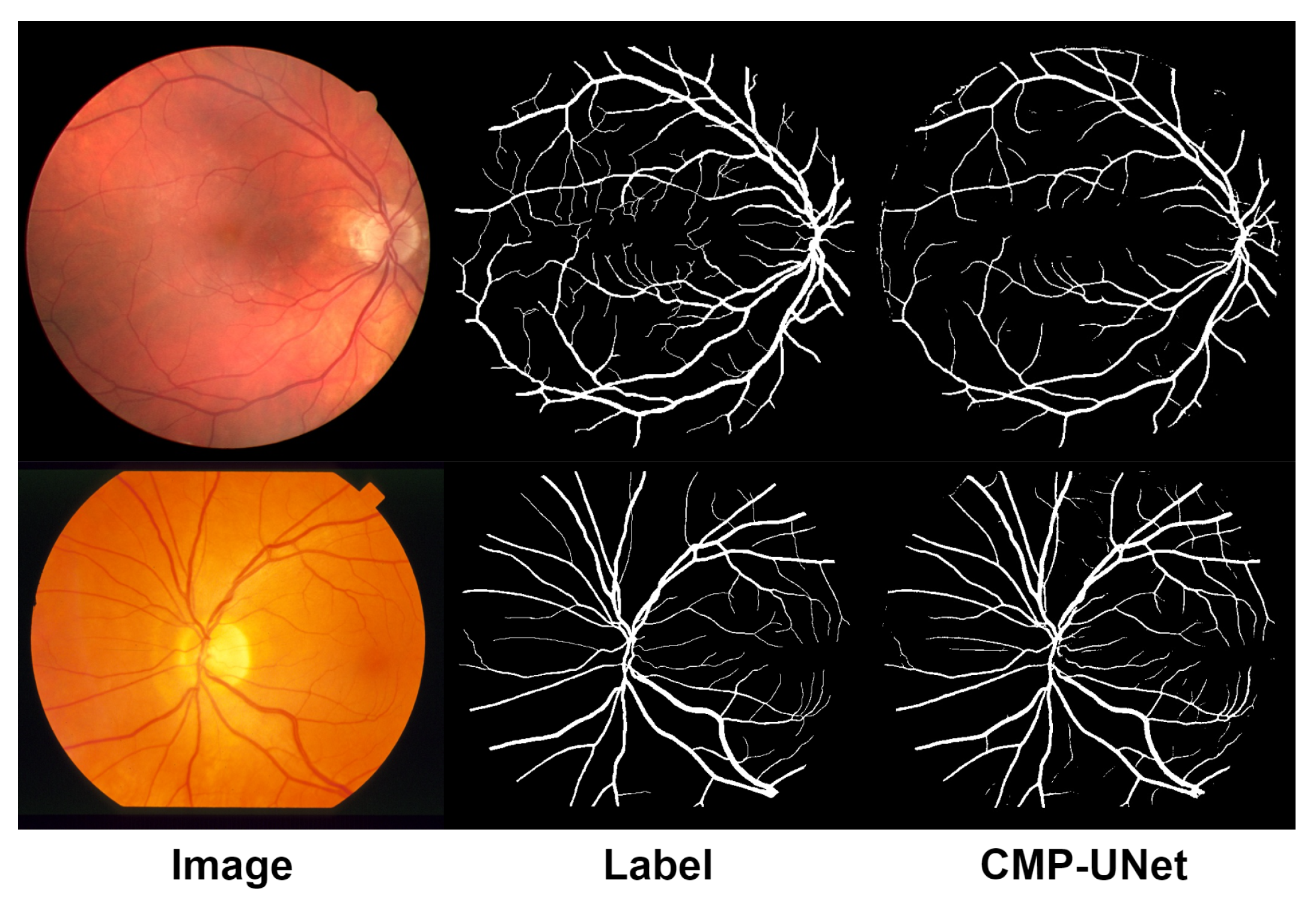
Usually, the scale of the data with good labels is limited, resulting in insufficient generalization ability of a model. To further validate the generalization performance of the proposed model, we conducted cross-experiments on the DRIVE and STARE datasets. Specifically, we trained the model on one dataset and then applied it to the other dataset for vessel segmentation testing.
The experimental results of when the model was trained using the STARE dataset and tested on the DRIVE dataset are shown in
Table 8. CMP-UNet achieves 96.74%, 79.77%, and 98.41% in ACC, SE, and SP, respectively, where ACC and SE show to be the best results. Compared with the best results of other models, ACC and SE are improved by 0.61% and 6.64%, respectively. It should be noted that due to the strong vessel detection capability of the proposed model, the background around the vessels may be mis-segmented, resulting in a slight decrease in SP.
When trained on the DRIVE dataset and tested on the STARE dataset, CMP-UNet achieves the best results in all three metrics, ACC, SE, and SP, reaching 97.35%, 80.87%, and 98.65%, respectively. Compared with the best results of the other models, ACC and SP are improved by 1.11% and 0.53%, respectively, and SE is slightly improved.
In addition, we present the results of the cross-experiments visually, as shown in
Figure 9. From the figure, it can be seen that the model can still segment most of the vessels from the background effectively and maintains good vessel connectivity. Overall, the proposed model, CMP-UNet, has better generalization ability.
5. Conclusions
In this paper, CMP-UNet is proposed for retinal vessel segmentation. The Coarse and Fine Feature Aggregation module is used to replace the original convolutional block to balance the model’s feature extraction capability for vessels with different sizes. In order to exploit the multi-scale information of cascaded features more efficiently, the Multi-Scale Channel Adaptive Fusion module is embedded in the decoder. In addition, the Pyramid Feature Fusion module is introduced to realize the interaction of multi-level feature information, thus enhancing the discriminability of blood vessels. Experimental results on the CHASE_DB1, DRIVE, and STARE datasets indicate that CMP-UNet outperforms existing models in terms of segmentation performance and generalization ability. The ablation experiments on the CHASE_DB1 dataset demonstrate the effectiveness of the proposed CFFA, MSCAF, and PFF modules. Finally, the cross-experiments further evidence the excellent generalization performance of the proposed model. Although the proposed model in this paper further improves the segmentation accuracy of retinal vessels, there are still shortcomings in vascular structure connectivity, which are mainly due to the following two reasons: Firstly, the proposed model is trained using the cross-entropy loss function. This loss function calculates the prediction error point to point, which ignores the structural information of the blood vessels. Secondly, the proposed model, like the current mainstream models, classifies the vascular probability map in a binary manner by setting a threshold to realize the distinction between blood vessels and background. This method cannot avoid breakage of the vascular structure. In future work, based on the above two points, we will aim to propose a new model to further enhance the connectivity of vascular structures.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}