
Data-Driven Advancements in Lip Motion Analysis: A Review


Abstract
:1. Introduction
- A comprehensive overview, analysis, and comparison of ALR methods and datasets and results on said datasets. We show that larger and more comprehensive datasets result in immense improvements in performance.
- We propose the next frontier for ALR systems is to move toward dialogue-level ALR. To our knowledge, no works have attempted or mentioned dialogue-level ALR systems or datasets. We propose that this will be the next step to increase accuracy and approach real-world applicability. This transition must be preceded by datasets to be used for training and testing.
- We provide a comprehensive overview, analysis, and comparison of lip motion authentication methods and datasets. We show that the datasets in the literature for lip motion authentication are severely lacking in size, variation, and accessibility.
- We identify the need for a large open access lip motion authentication dataset to be used as a benchmark dataset. When compared with the large open access dataset in the ALR research, the lip motion authentication research field is severely lacking. There is no large benchmark dataset to compare these methods, which prohibits comparison and growth. This type of dataset is vital for further improvements in this area.
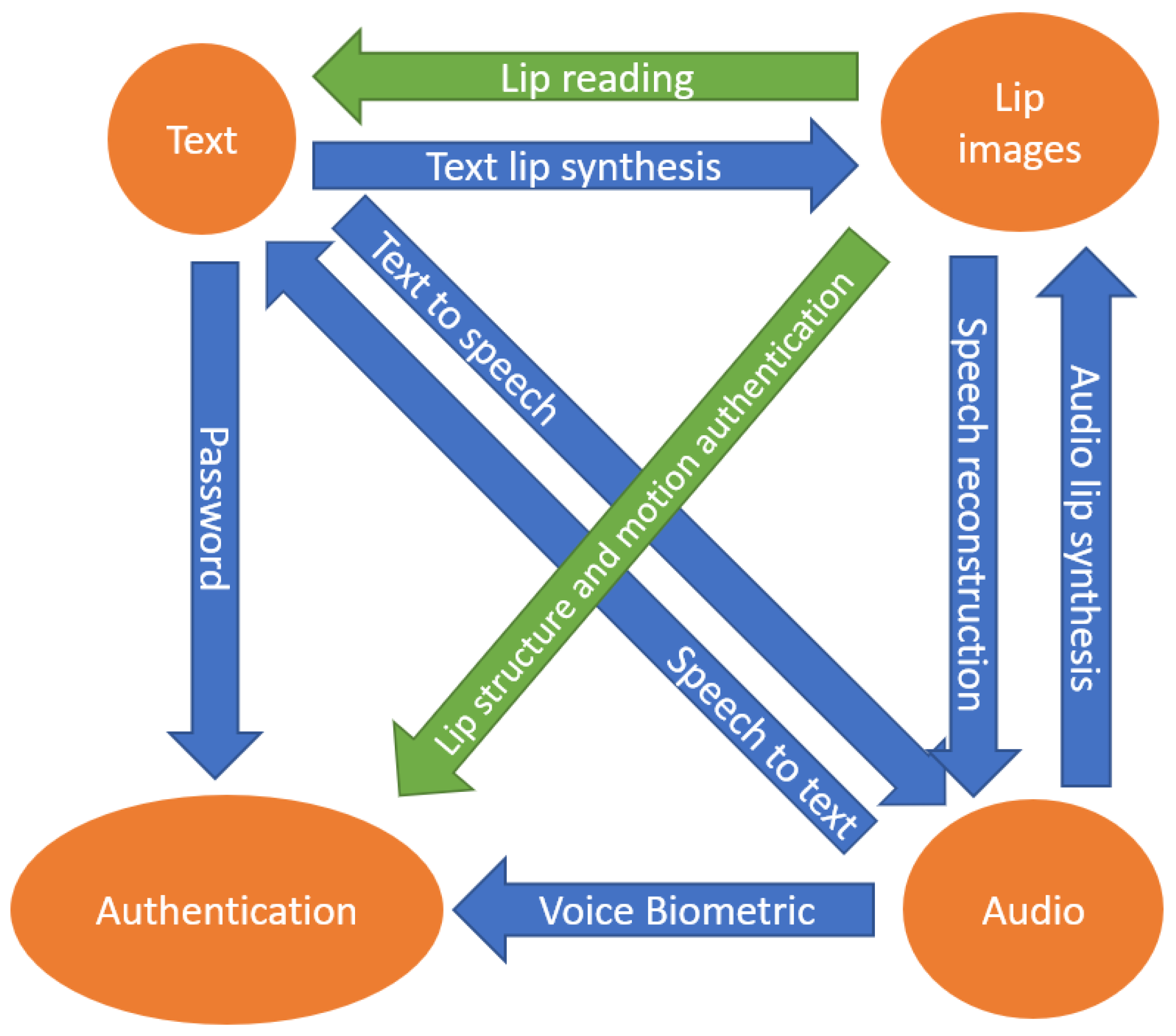
2. Background
3. Automated Lip-Reading
3.1. Word-Level ALR
3.1.1. CMU AVPFV
3.1.2. NDUTAVSC
3.1.3. AVAS
3.1.4. MIRACL-VC1
3.1.5. AusTalk

{kind=link}
{kind=link}
| Dataset | Year | Language | Speakers | Classes | Total Videos | Environment | State of the Art Accuracy |
|---|---|---|---|---|---|---|---|
| CMU AVPFV [71] | 2007 | English | 10 | 150 | 15,000 | Lab | ∼49% [71] |
| NDUTAVSC [72] | 2010 | Dutch | 66 | 6907 | 6907 | Lab | 84.27% [73] |
| AVAS [74] | 2013 | Arabic | 50 | 48 | 13,850 | Varied Lab | 85% [74] |
| MIRACL-VC1 [76] | 2014 | English | 15 | 10 | 1500 | Lab | 98% [79] * |
| AusTalk [80] | 2014 | English | 1000 | 966 | 966,000 | Lab | 69.18% [81] |
| LRW [43] | 2016 | English | 1000 | 500 | 400,000 | Wild | 91.6% [63] |
| LRW-1000 [82] | 2019 | Mandarin | 2000 | 1000 | 718,018 | Wild | 57.5% [83] |
3.1.6. LRW
3.1.7. LRW-1000
3.1.8. Methods
3.1.9. Findings
3.2. Sentence-Level ALR
3.2.1. Grid
3.2.2. OuluVS2
3.2.3. MODALITY
| Network Architecture + Additions | 0° | 30° | 45° | 60° | 90° |
|---|---|---|---|---|---|
| CNN + DA [108] | 85.6% | 82.5% | 82.5% | 83.3% | 80.3% |
| End-to-end CNN + LSTM [109] | 81.1% | 80.0% | 76.9% | 69.2% | 82.2% |
| CNN + LSTM * [109] | 82.8% | 81.1% | 85.0% | 83.6% | 86.4% |
| PCA + LSTM + GMM-HMM [106] | 74.1% | 76.8% | 68.7% | 63.7% | 63.1% |
| Raw Pixels + LVM [107] | 73.0% | 75.0% | 76.0% | 75.0% | 70.0% |
| VGG-M+LSTM+ATT ** [84] | 91.1% | 90.8% | 90.0% | 90.0% | 88.9% |
| Multi-view 3DCNN * [93] | 88.6% | 89.4% | 88.1% | 85.6% | 83.9% |
| CNN + Bi-LSTM [110] | 90.3% | 84.7% | 90.6% | 88.6% | 88.6% |
| CNN + Bi-LSTM * [110] | 95.0% | 93.1% | 91.7% | 90.6% | 90.0% |
| End-to-end Encoder + Bi-LSTM [107] | 94.7% | 89.7% | 90.6% | 87.5% | 93.1% |
| 3D CNN + SAM + Bi-GRU + Local self-attention + CTC + DA [93] | 98.31% | 97.89% | 97.21% | 96.78% | 97.55% |
| Average | 86.78% | 85.54% | 85.21% | 83.08% | 84.00 |
3.2.4. LRS
3.2.5. MV-LRS
3.2.6. LRS2-BBC
3.2.7. LRS3-TED
3.2.8. CMLR
3.2.9. LSVSR
3.2.10. YTDEV18
3.2.11. Other Supplemental Datasets
3.2.12. SynthVSR
3.2.13. Methods
3.2.14. Findings
4. Lip Motion as Authentication
4.1. Datasets
4.1.1. XM2VTS
4.1.2. VidTIMIT
4.1.3. qFace and FAVLIPS
4.1.4. Existing Datasets
4.1.5. Private Datasets
4.2. Methods
| Paper (Year) | Method(s) | Dataset | Speakers | Network Architecture | Metric | Results |
|---|---|---|---|---|---|---|
| [131] (2000) | Motion | XM2VTS | 295 | GMVE | EER | 14% |
| [147] (2003) | Motion | M2VTS | 36 | HMM | EER | 19.7% |
| [148] (2004) | Voice and motion | VidTIMIT [123] | 43 | GMM | EER | 1.0% |
| [141] (2004) | Motion | Private | 40 | HMM | EER | 5.1% |
| [149] (2006) | Face and motion | BioID [150] | 25 | 2D-DCT + KNN | Accuracy | 86% |
| [129] (2006) | Voice and motion | XM2VTS | 295 | GMM | EER | 22% **, 2% |
| [151] (2007) | Voice and motion | XM2VTS | 295 | GMM | Accuracy | 78% **, 98% |
| [140] (2011) | Structrue and motion | Private | 21 | DTW | Accuracy | 99.5% |
| [132] (2012) | Voice and motion | XM2VTS | 295 | GMM | Accuracy | 94.7% |
| [152] (2013) | Motion | Private | 43 | DP | FAR@ 3% FRR | 14.5% |
| [139] (2014) | Motion | Private [153] | 20 | KNN + DTW [154] | Accuracy | 92.4% |
| [155] (2015) | Motion | XM2VTS | 295 | GMM | EER | 2.2% |
| [136] (2017) | Motion | Private | 20 | GMM | Accuracy | 96.2% |
| [143] (2018) | UT Motion | Private | 50 | SVM | TNR & TPR | 86.7% & 76.7% |
| [126] (2018) | Face and motion | OuluVS [104] | 20 | EV + ELM | Accuracy | 71% **, 93.25% |
| [135] (2018) | Face and motion | Other [135,156] | 400 & 104 | CNN + LSTM | EER | 0.37% |
| [133] (2019) | Motion | XM2VTS | 295 | STCNN + Bi-GRU | EER | 1.03% |
| [125] (2020) | Motion | XM2VTS | 295 | SNN | EER | 1.65% |
| [127] (2020) | Motion | AV Digits [128] | 39 | 3DCNN + Bi-LSTM | EER | 9% |
| [67] (2021) | AL, voice, and face | Private | 44 | CNN + LSTM | EER | 5% |
| [144] (2021) | Voice and motion | Private | 240 * | LMK + 3D Resnet | FAR & FRR | 0.25% & 18.25% |
| [137] (2021) | Voice and motion | Private | 50 | N/A | Accuracy | 95.89% |
| [138] (2021) | Face and motion | Private | 10 | LMK + RNN + FC | AP | 98.8% ** |
| [157] (2022) | Face and motion | Private | 10 [138] + 38 | LMK + Transformer | AP | 94.9% ** |
| [158] (2022) | Face and motion | Private | 48 [157] + 11 | CNN + Transformer | AP | 98.8% ** |
| [134] (2022) | Motion | XM2VTS | 295 | DWLSTM + GRU | Accuracy | 96.78% |
4.3. Findings
| Training Data | |||
|---|---|---|---|
| Evaluation Data | XM2VTS Only | Pretrained on XM2VTS; Updated on FAVLIPS | XM2VTS + FAVLIPS |
| XM2VTS: evaluation set | 1.21% | 1.95% | 5.60% |
| FAVLIPS: neutral nums | 22.43% | 13.79% | 10.83% |
| FAVLIPS: light front | 28.44% | 17.50% | 20.54% |
| FAVLIPS: light side | 42.29% | 36.67% | 30.00% |
| FAVLIPS: light behind | 44.91% | 24.17% | 29.12% |
5. Future Directions
5.1. Automated Lip-Reading
5.2. Lip Motion Authentication
6. Ethics
6.1. Dataset Collection
6.2. Dataset Usage
6.3. Ethnic and Dialect Issues
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Oneață, D.; Lorincz, B.; Stan, A.; Cucu, H. FlexLip: A Controllable Text-to-Lip System. Sensors 2022, 22, 4104. [Google Scholar] [CrossRef]
- Chung, J.S.; Zisserman, A. Out of time: Automated lip sync in the wild. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 251–263. [Google Scholar]
- Li, L.; Wang, S.; Zhang, Z.; Ding, Y.; Zheng, Y.; Yu, X.; Fan, C. Write-a-speaker: Text-based emotional and rhythmic talking-head generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1911–1920. [Google Scholar]
- Fried, O.; Tewari, A.; Zollhöfer, M.; Finkelstein, A.; Shechtman, E.; Goldman, D.B.; Genova, K.; Jin, Z.; Theobalt, C.; Agrawala, M. Text-based editing of talking-head video. ACM Trans. Graph. (TOG) 2019, 38, 68. [Google Scholar] [CrossRef]
- Taylor, S.; Kim, T.; Yue, Y.; Mahler, M.; Krahe, J.; Rodriguez, A.G.; Hodgins, J.; Matthews, I. A deep learning approach for generalized speech animation. ACM Trans. Graph. (TOG) 2017, 36, 93. [Google Scholar] [CrossRef]
- Sha, T.; Zhang, W.; Shen, T.; Li, Z.; Mei, T. Deep Person Generation: A Survey from the Perspective of Face, Pose and Cloth Synthesis. arXiv 2021, arXiv:2109.02081. [Google Scholar] [CrossRef]
- Liu, J.; Zhu, Z.; Ren, Y.; Huang, W.; Huai, B.; Yuan, N.; Zhao, Z. Parallel and High-Fidelity Text-to-Lip Generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2022; Volume 36, pp. 1738–1746. [Google Scholar]
- Yang, Y.; Shillingford, B.; Assael, Y.; Wang, M.; Liu, W.; Chen, Y.; Zhang, Y.; Sezener, E.; Cobo, L.C.; Denil, M.; et al. Large-scale multilingual audio visual dubbing. arXiv 2020, arXiv:2011.03530. [Google Scholar]
- Zhou, H.; Sun, Y.; Wu, W.; Loy, C.C.; Wang, X.; Liu, Z. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4176–4186. [Google Scholar]
- Kumar, R.; Sotelo, J.; Kumar, K.; de Brébisson, A.; Bengio, Y. Obamanet: Photo-realistic lip-sync from text. arXiv 2017, arXiv:1801.01442. [Google Scholar]
- Prajwal, K.; Mukhopadhyay, R.; Namboodiri, V.P.; Jawahar, C. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 484–492. [Google Scholar]
- Yamamoto, E.; Nakamura, S.; Shikano, K. Lip movement synthesis from speech based on Hidden Markov Models. Speech Commun. 1998, 26, 105–115. [Google Scholar] [CrossRef]
- Ling, J.; Tan, X.; Chen, L.; Li, R.; Zhang, Y.; Zhao, S.; Song, L. StableFace: Analyzing and Improving Motion Stability for Talking Face Generation. arXiv 2022, arXiv:2208.13717. [Google Scholar] [CrossRef]
- Almajai, I.; Milner, B. Visually derived wiener filters for speech enhancement. IEEE Trans. Audio, Speech, Lang. Process. 2010, 19, 1642–1651. [Google Scholar] [CrossRef]
- Adeel, A.; Gogate, M.; Hussain, A.; Whitmer, W.M. Lip-reading driven deep learning approach for speech enhancement. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 5, 481–490. [Google Scholar] [CrossRef]
- Kumar, Y.; Aggarwal, M.; Nawal, P.; Satoh, S.; Shah, R.R.; Zimmermann, R. Harnessing ai for speech reconstruction using multi-view silent video feed. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1976–1983. [Google Scholar]
- Kumar, Y.; Jain, R.; Salik, M.; ratn Shah, R.; Zimmermann, R.; Yin, Y. Mylipper: A personalized system for speech reconstruction using multi-view visual feeds. In Proceedings of the 2018 IEEE International Symposium on Multimedia (ISM), Taichung, Taiwan, 10–12 December 2018; pp. 159–166. [Google Scholar]
- Kumar, Y.; Jain, R.; Salik, K.M.; Shah, R.R.; Yin, Y.; Zimmermann, R. Lipper: Synthesizing thy speech using multi-view lipreading. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 2588–2595. [Google Scholar]
- Kumar, N.; Goel, S.; Narang, A.; Lall, B. Multi Modal Adaptive Normalization for Audio to Video Generation. arXiv 2020, arXiv:2012.07304. [Google Scholar]
- Salik, K.M.; Aggarwal, S.; Kumar, Y.; Shah, R.R.; Jain, R.; Zimmermann, R. Lipper: Speaker independent speech synthesis using multi-view lipreading. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 10023–10024. [Google Scholar]
- Hassid, M.; Ramanovich, M.T.; Shillingford, B.; Wang, M.; Jia, Y.; Remez, T. More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10587–10597. [Google Scholar]
- McGurk, H.; MacDonald, J. Hearing lips and seeing voices. Nature 1976, 264, 746–748. [Google Scholar] [CrossRef]
- Ma, P.; Petridis, S.; Pantic, M. End-to-end audio-visual speech recognition with conformers. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7613–7617. [Google Scholar]
- Ivanko, D.; Ryumin, D.; Karpov, A. Automatic Lip-Reading of Hearing Impaired People. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 97–101. [Google Scholar] [CrossRef]
- Ebert, D.A.; Heckerling, P.S. Communication with deaf patients: Knowledge, beliefs, and practices of physicians. JAMA 1995, 273, 227–229. [Google Scholar] [CrossRef]
- Barnett, S. Clinical and cultural issues in caring for deaf people. Fam. Med. 1999, 31, 17–22. [Google Scholar]
- Davenport, S. Improving communication with the deaf patient. J. Fam. Pract. 1977, 4, 1065–1068. [Google Scholar]
- Steinberg, A. Issues in providing mental health services to hearing-impaired persons. Psychiatr. Serv. 1991, 42, 380–389. [Google Scholar] [CrossRef]
- Fernandez-Lopez, A.; Martinez, O.; Sukno, F.M. Towards estimating the upper bound of visual-speech recognition: The visual lip-reading feasibility database. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017; pp. 208–215. [Google Scholar]
- Altieri, N.A.; Pisoni, D.B.; Townsend, J.T. Some normative data on lip-reading skills (L). J. Acoust. Soc. Am. 2011, 130, 1–4. [Google Scholar] [CrossRef]
- Hilder, S.; Harvey, R.W.; Theobald, B.J. Comparison of human and machine-based lip-reading. In AVSP; University of East Anglia: Norwich, UK, 2009; pp. 86–89. [Google Scholar]
- Sooraj, V.; Hardhik, M.; Murthy, N.S.; Sandesh, C.; Shashidhar, R. Lip-reading techniques: A review. Int. J. Sci. Technol. Res. 2020, 9, 4378–4383. [Google Scholar]
- Oghbaie, M.; Sabaghi, A.; Hashemifard, K.; Akbari, M. Advances and Challenges in Deep Lip Reading. arXiv 2021, arXiv:2110.07879. [Google Scholar]
- Agrawal, S.; Omprakash, V.R.; Ranvijay. Lip reading techniques: A survey. In Proceedings of the 2016 2nd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Bangalore, India, 21–23 July 2016; pp. 753–757. [Google Scholar] [CrossRef]
- Hao, M.; Mamut, M.; Yadikar, N.; Aysa, A.; Ubul, K. A survey of research on lipreading technology. IEEE Access 2020, 8, 204518–204544. [Google Scholar] [CrossRef]
- Fernandez-Lopez, A.; Sukno, F.M. Survey on automatic lip-reading in the era of deep learning. Image Vis. Comput. 2018, 78, 53–72. [Google Scholar] [CrossRef]
- Chung, J.S.; Zisserman, A. Lip reading in the wild. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 87–103. [Google Scholar]
- Tsourounis, D.; Kastaniotis, D.; Fotopoulos, S. Lip reading by alternating between spatiotemporal and spatial convolutions. J. Imaging 2021, 7, 91. [Google Scholar] [CrossRef] [PubMed]
- Son Chung, J.; Senior, A.; Vinyals, O.; Zisserman, A. Lip reading sentences in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6447–6456. [Google Scholar]
- Petridis, S.; Stafylakis, T.; Ma, P.; Cai, F.; Tzimiropoulos, G.; Pantic, M. End-to-end audiovisual speech recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6548–6552. [Google Scholar]
- Stafylakis, T.; Tzimiropoulos, G. Combining residual networks with LSTMs for lipreading. arXiv 2017, arXiv:1703.04105. [Google Scholar]
- Cheng, S.; Ma, P.; Tzimiropoulos, G.; Petridis, S.; Bulat, A.; Shen, J.; Pantic, M. Towards pose-invariant lip-reading. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4357–4361. [Google Scholar]
- Wang, C. Multi-grained spatio-temporal modeling for lip-reading. arXiv 2019, arXiv:1908.11618. [Google Scholar]
- Courtney, L.; Sreenivas, R. Using deep convolutional LSTM networks for learning spatiotemporal features. In Proceedings of the Asian Conference on Pattern Recognition, Jeju Island, Republic of Korea, 9–12 November 2019; pp. 307–320. [Google Scholar]
- Luo, M.; Yang, S.; Shan, S.; Chen, X. Pseudo-convolutional policy gradient for sequence-to-sequence lip-reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition, Buenos Aires, Argentina, 16–20 November 2020; pp. 273–280. [Google Scholar]
- Weng, X.; Kitani, K. Learning spatio-temporal features with two-stream deep 3d cnns for lipreading. arXiv 2019, arXiv:1905.02540. [Google Scholar]
- Xiao, J.; Yang, S.; Zhang, Y.; Shan, S.; Chen, X. Deformation flow based two-stream network for lip reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition, Buenos Aires, Argentina, 16–20 November 2020; pp. 364–370. [Google Scholar]
- Zhao, X.; Yang, S.; Shan, S.; Chen, X. Mutual information maximization for effective lip reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition, Buenos Aires, Argentina, 16–20 November 2020; pp. 420–427. [Google Scholar]
- Zhang, Y.; Yang, S.; Xiao, J.; Shan, S.; Chen, X. Can we read speech beyond the lips? Rethinking roi selection for deep visual speech recognition. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition, Buenos Aires, Argentina, 16–20 November 2020; pp. 356–363. [Google Scholar]
- Feng, D.; Yang, S.; Shan, S.; Chen, X. Learn an effective lip reading model without pains. arXiv 2020, arXiv:2011.07557. [Google Scholar]
- Martinez, B.; Ma, P.; Petridis, S.; Pantic, M. Lipreading using temporal convolutional networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6319–6323. [Google Scholar]
- Ren, S.; Du, Y.; Lv, J.; Han, G.; He, S. Learning from the master: Distilling cross-modal advanced knowledge for lip reading. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13325–13333. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. Stat 2015, 1050, 9. [Google Scholar]
- Peng, C.; Li, J.; Chai, J.; Zhao, Z.; Zhang, H.; Tian, W. Lip Reading Using Deformable 3D Convolution and Channel-Temporal Attention. In Proceedings of the International Conference on Artificial Neural Networks, Bristol, UK, 6–9 September 2022; pp. 707–718. [Google Scholar]
- Ma, P.; Martinez, B.; Petridis, S.; Pantic, M. Towards practical lipreading with distilled and efficient models. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2021; pp. 7608–7612. [Google Scholar]
- Koumparoulis, A.; Potamianos, G. Accurate and Resource-Efficient Lipreading with Efficientnetv2 and Transformers. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 7–13 May 2022; pp. 8467–8471. [Google Scholar]
- Ma, P.; Wang, Y.; Petridis, S.; Shen, J.; Pantic, M. Training strategies for improved lip-reading. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 8472–8476. [Google Scholar]
- Fenghour, S.; Chen, D.; Guo, K.; Li, B.; Xiao, P. Deep learning-based automated lip-reading: A survey. IEEE Access 2021, 9, 121184–121205. [Google Scholar] [CrossRef]
- Pu, G.; Wang, H. Review on research progress of machine lip reading. Vis. Comput. 2022, 39, 3041–3057. [Google Scholar] [CrossRef]
- Kaur, P.; Krishan, K.; Sharma, S.K.; Kanchan, T. Facial-recognition algorithms: A literature review. Med. Sci. Law 2020, 60, 131–139. [Google Scholar] [CrossRef]
- Zhou, M.; Wang, Q.; Li, Q.; Jiang, P.; Yang, J.; Shen, C.; Wang, C.; Ding, S. Securing face liveness detection using unforgeable lip motion patterns. arXiv 2021, arXiv:2106.08013. [Google Scholar]
- Raji, I.D.; Fried, G. About face: A survey of facial recognition evaluation. arXiv 2021, arXiv:2102.00813. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. Voxceleb2: Deep speaker recognition. arXiv 2018, arXiv:1806.05622. [Google Scholar]
- Chowdhury, D.P.; Kumari, R.; Bakshi, S.; Sahoo, M.N.; Das, A. Lip as biometric and beyond: A survey. Multimed. Tools Appl. 2022, 81, 3831–3865. [Google Scholar] [CrossRef]
- Kumar, K.; Chen, T.; Stern, R.M. Profile view lip reading. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 16–20 April 2007; Volume 4, pp. IV–429–IV–432. [Google Scholar]
- Chitu, A.G.; Driel, K.; Rothkrantz, L.J. Automatic lip reading in the Dutch language using active appearance models on high speed recordings. In Proceedings of the International Conference on Text, Speech and Dialogue, Brno, Czech Republic, 6–10 September 2010; pp. 259–266. [Google Scholar]
- Chiţu, A.; Rothkrantz, L.J. Automatic visual speech recognition. In Speech Enhancement, Modeling and Recognition—Algorithms and Applications; InTech Open: London, UK, 2012; p. 95. [Google Scholar]
- Antar, S.; Sagheer, A.; Aly, S.; Tolba, M.F. Avas: Speech database for multimodal recognition applications. In Proceedings of the 13th International Conference on Hybrid Intelligent Systems (HIS 2013), Gammarth, Tunisia, 4–6 December 2013; pp. 123–128. [Google Scholar]
- Fix, E.; Hodges, J.L. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev. Int. Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Rekik, A.; Ben-Hamadou, A.; Mahdi, W. A new visual speech recognition approach for RGB-D cameras. In Proceedings of the International Conference Image Analysis and Recognition, Vilamoura, Portugal, 22–24 October 2014; pp. 21–28. [Google Scholar]
- Rekik, A.; Ben-Hamadou, A.; Mahdi, W. An adaptive approach for lip-reading using image and depth data. Multimed. Tools Appl. 2016, 75, 8609–8636. [Google Scholar] [CrossRef]
- Zhang, Z. Microsoft Kinect Sensor and Its Effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Parekh, D.; Gupta, A.; Chhatpar, S.; Yash, A.; Kulkarni, M. Lip reading using convolutional auto encoders as feature extractor. In Proceedings of the 2019 IEEE 5th International Conference for Convergence in Technology (I2CT), Bombay, India, 29–31 March 2019; pp. 1–6. [Google Scholar]
- Estival, D.; Cassidy, S.; Cox, F.; Burnham, D. AusTalk: An audio-visual corpus of Australian English. In Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 3105–3109. [Google Scholar]
- Sui, C.; Togneri, R.; Bennamoun, M. A cascade gray-stereo visual feature extraction method for visual and audio-visual speech recognition. Speech Commun. 2017, 90, 26–38. [Google Scholar] [CrossRef]
- Yang, S.; Zhang, Y.; Feng, D.; Yang, M.; Wang, C.; Xiao, J.; Long, K.; Shan, S.; Chen, X. LRW-1000: A naturally-distributed large-scale benchmark for lip reading in the wild. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar]
- Wang, H.; Pu, G.; Chen, T. A Lip Reading Method Based on 3D Convolutional Vision Transformer. IEEE Access 2022, 10, 77205–77212. [Google Scholar] [CrossRef]
- Chung, J.S.; Zisserman, A. Lip reading in profile. In Proceedings of the Ritish Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- iFlyRec Team. iFlyRec: A Speech Recognition Tool. Available online: https://www.iflyrec.com/ (accessed on 11 July 2019).
- SeetaFaceEngine2 Team. SeetaFaceEngine2. Available online: https://github.com/seetaface (accessed on 11 July 2019).
- He, Z.; Kan, M.; Zhang, J.; Chen, X.; Shan, S. A Fully End-to-End Cascaded CNN for Facial Landmark Detection. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition (FG), Washington, DC, USA, 30 May–3 June 2017. [Google Scholar]
- Xiao-Ding, C.; Chang-Chong, S.; Gang-Yao, K.; Li, L. The state of the art and prospects of lip reading. Acta Autom. Sin. 2020, 46, 2275–2301. [Google Scholar]
- Cooke, M.; Barker, J.; Cunningham, S.; Shao, X. An audio-visual corpus for speech perception and automatic speech recognition. J. Acoust. Soc. Am. 2006, 120, 2421–2424. [Google Scholar] [CrossRef]
- Margam, D.K.; Aralikatti, R.; Sharma, T.; Thanda, A.; Roy, S.; Venkatesan, S.M. LipReading with 3D-2D-CNN BLSTM-HMM and word-CTC models. arXiv 2019, arXiv:1906.12170. [Google Scholar]
- Anina, I.; Zhou, Z.; Zhao, G.; Pietikäinen, M. Ouluvs2: A multi-view audiovisual database for non-rigid mouth motion analysis. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 1, pp. 1–5. [Google Scholar]
- Jeon, S.; Kim, M.S. End-to-End Sentence-Level Multi-View Lipreading Architecture with Spatial Attention Module Integrated Multiple CNNs and Cascaded Local Self-Attention-CTC. Sensors 2022, 22, 3597. [Google Scholar] [CrossRef]
- Czyzewski, A.; Kostek, B.; Bratoszewski, P.; Kotus, J.; Szykulski, M. An audio-visual corpus for multimodal automatic speech recognition. J. Intell. Inf. Syst. 2017, 49, 167–192. [Google Scholar] [CrossRef]
- Afouras, T.; Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Deep audio-visual speech recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 44, 8717–8727. [Google Scholar] [CrossRef] [PubMed]
- Fenghour, S.; Chen, D.; Guo, K.; Xiao, P. Lip reading sentences using deep learning with only visual cues. IEEE Access 2020, 8, 215516–215530. [Google Scholar] [CrossRef]
- Afouras, T.; Chung, J.S.; Zisserman, A. LRS3-TED: A large-scale dataset for visual speech recognition. arXiv 2018, arXiv:1809.00496. [Google Scholar]
- Ma, P.; Haliassos, A.; Fernandez-Lopez, A.; Chen, H.; Petridis, S.; Pantic, M. Auto-AVSR: Audio-Visual Speech Recognition with Automatic Labels. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Alghamdi, N.; Maddock, S.; Marxer, R.; Barker, J.; Brown, G.J. A corpus of audio-visual Lombard speech with frontal and profile views. J. Acoust. Soc. Am. 2018, 143, EL523–EL529. [Google Scholar] [CrossRef]
- Shillingford, B.; Assael, Y.; Hoffman, M.W.; Paine, T.; Hughes, C.; Prabhu, U.; Liao, H.; Sak, H.; Rao, K.; Bennett, L.; et al. Large-scale visual speech recognition. arXiv 2018, arXiv:1807.05162. [Google Scholar]
- Zhao, Y.; Xu, R.; Song, M. A cascade sequence-to-sequence model for chinese mandarin lip reading. In Proceedings of the ACM Multimedia Asia, Beijing, China, 16–18 December 2019; pp. 1–6. [Google Scholar]
- Makino, T.; Liao, H.; Assael, Y.; Shillingford, B.; Garcia, B.; Braga, O.; Siohan, O. Recurrent neural network transducer for audio-visual speech recognition. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Sentosa, Singapore, 14–18 December 2019; pp. 905–912. [Google Scholar]
- Liu, X.; Lakomkin, E.; Vougioukas, K.; Ma, P.; Chen, H.; Xie, R.; Doulaty, M.; Moritz, N.; Kolar, J.; Petridis, S.; et al. SynthVSR: Scaling Up Visual Speech Recognition with Synthetic Supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–19 June 2023; pp. 18806–18815. [Google Scholar]
- Zhao, G.; Barnard, M.; Pietikainen, M. Lipreading with local spatiotemporal descriptors. IEEE Trans. Multimed. 2009, 11, 1254–1265. [Google Scholar] [CrossRef]
- Maeda, T.; Tamura, S. Multi-view Convolution for Lipreading. In Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; pp. 1092–1096. [Google Scholar]
- Zimmermann, M.; Mehdipour Ghazi, M.; Ekenel, H.K.; Thiran, J.P. Visual speech recognition using PCA networks and LSTMs in a tandem GMM-HMM system. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 264–276. [Google Scholar]
- Petridis, S.; Wang, Y.; Li, Z.; Pantic, M. End-to-end multi-view lipreading. arXiv 2017, arXiv:1709.00443. [Google Scholar]
- Saitoh, T.; Zhou, Z.; Zhao, G.; Pietikäinen, M. Concatenated frame image based cnn for visual speech recognition. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 277–289. [Google Scholar]
- Lee, D.; Lee, J.; Kim, K.E. Multi-view automatic lip-reading using neural network. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 290–302. [Google Scholar]
- Han, H.; Kang, S.; Yoo, C.D. Multi-view visual speech recognition based on multi task learning. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3983–3987. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv 2014, arXiv:1405.3531. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Graves, A. Sequence transduction with recurrent neural networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Serdyuk, D.; Braga, O.; Siohan, O. Audio-Visual Speech Recognition is Worth 32 × 32 × 8 Voxels. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 15–17 December 2021; pp. 796–802. [Google Scholar]
- Chang, O.; Liao, H.; Serdyuk, D.; Shah, A.; Siohan, O. Conformers are All You Need for Visual Speech Recogntion. arXiv 2023, arXiv:2302.10915. [Google Scholar]
- Ephrat, A.; Mosseri, I.; Lang, O.; Dekel, T.; Wilson, K.; Hassidim, A.; Freeman, W.T.; Rubinstein, M. Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. arXiv 2018, arXiv:1804.03619. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QL, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Hernandez, F.; Nguyen, V.; Ghannay, S.; Tomashenko, N.; Esteve, Y. TED-LIUM 3: Twice as much data and corpus repartition for experiments on speaker adaptation. In Proceedings of the Speech and Computer: 20th International Conference, SPECOM 2018, Leipzig, Germany, 18–22 September 2018; pp. 198–208. [Google Scholar]
- Prajwal, K.; Afouras, T.; Zisserman, A. Sub-word Level Lip Reading with Visual Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5162–5172. [Google Scholar]
- Shi, B.; Hsu, W.N.; Lakhotia, K.; Mohamed, A. Learning audio-visual speech representation by masked multimodal cluster prediction. arXiv 2022, arXiv:2201.02184. [Google Scholar]
- Messer, K.; Matas, J.; Kittler, J.; Luettin, J.; Maitre, G. XM2VTSDB: The extended M2VTS database. In Proceedings of the 2nd International Conference on Audio and Video-based Biometric Person Authentication, Washington, DC, USA, 22–24 March 1999; Volume 964, pp. 965–966. [Google Scholar]
- Sanderson, C.; Paliwal, K.K. Fast features for face authentication under illumination direction changes. Pattern Recognit. Lett. 2003, 24, 2409–2419. [Google Scholar] [CrossRef]
- Lamel, L.F.; Kassel, R.H.; Seneff, S. Speech database development: Design and analysis of the acoustic-phonetic corpus. Speech Input/Output Assessment and Speech Databases. Speech Commun. 1989, 9, 161–170. [Google Scholar]
- Wright, C.; Stewart, D.W. Understanding visual lip-based biometric authentication for mobile devices. EURASIP J. Inf. Secur. 2020, 2020, 1–16. [Google Scholar] [CrossRef]
- Shang, D.; Zhang, X.; Xu, X. Face and lip-reading authentication system based on android smart phones. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; pp. 4178–4182. [Google Scholar]
- Ruengprateepsang, K.; Wangsiripitak, S.; Pasupa, K. Hybrid Training of Speaker and Sentence Models for One-Shot Lip Password. In Proceedings of the International Conference on Neural Information Processing. Springer, Bangkok, Thailand, 23–27 November 2020; pp. 363–374. [Google Scholar]
- Petridis, S.; Shen, J.; Cetin, D.; Pantic, M. Visual-only recognition of normal, whispered and silent speech. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6219–6223. [Google Scholar]
- Faraj, M.I.; Bigun, J. Motion features from lip movement for person authentication. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 1059–1062. [Google Scholar]
- Lu, Z.; Wu, X.; He, R. Person identification from lip texture analysis. In Proceedings of the 2016 IEEE International Conference on Digital Signal Processing (DSP), Beijing, China, 16–18 October 2016; pp. 472–476. [Google Scholar]
- Sanchez, M.U.R. Aspects of Facial Biometrics for Verification of Personal Identity; University of Surrey: Surrey, UK, 2000. [Google Scholar]
- Ichino, M.; Yamazaki, Y.; Jian-Gang, W.; Yun, Y.W. Text independent speaker gender recognition using lip movement. In Proceedings of the 2012 12th International Conference on Control Automation Robotics & Vision (ICARCV), Guangzhou, China, 5–7 December 2012; pp. 176–181. [Google Scholar]
- Wright, C.; Stewart, D. One-shot-learning for visual lip-based biometric authentication. In Proceedings of the International Symposium on Visual Computing, Lake Tahoe, NV, USA, 7–9 October 2019; pp. 405–417. [Google Scholar]
- Dar, S.A.; Palanivel, S.; Geetha, M.K.; Balasubramanian, M. Mouth Image Based Person Authentication Using DWLSTM and GRU. Inf. Sci. Lett 2022, 11, 853–862. [Google Scholar]
- Kim, S.T.; Ro, Y.M. Attended relation feature representation of facial dynamics for facial authentication. IEEE Trans. Inf. For. Secur. 2018, 14, 1768–1778. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhao, J.; Xi, W.; Qian, C.; Zhang, X.; Wang, Z. SALM: Smartphone-based identity authentication using lip motion characteristics. In Proceedings of the 2017 IEEE International Conference on Smart Computing (SMARTCOMP), Hong Kong, China, 29–31 May 2017; pp. 1–8. [Google Scholar]
- Wong, A.B. Authentication through Sensing of Tongue and Lip Motion via Smartphone. In Proceedings of the 2021 18th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), Virtual Conference, 6–9 July 2021; pp. 1–2. [Google Scholar]
- Sun, Z.; Lee, D.J.; Zhang, D.; Li, X. Concurrent Two-Factor Identify Verification Using Facial Identify and Facial Actions. Electron. Imaging 2021, 2021, 318-1–318-7. [Google Scholar] [CrossRef]
- Hassanat, A.B. Visual passwords using automatic lip reading. arXiv 2014, arXiv:1409.0924. [Google Scholar]
- Sayo, A.; Kajikawa, Y.; Muneyasu, M. Biometrics authentication method using lip motion in utterance. In Proceedings of the 2011 8th International Conference on Information, Communications & Signal Processing, Singapore, 13–16 December 2011; pp. 1–5. [Google Scholar]
- Mok, L.; Lau, W.; Leung, S.; Wang, S.; Yan, H. Lip features selection with application to person authentication. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing-Proceedings. Institute of Electrical and Electronics Engineers Inc., Montreal, QC, Canada, 17–21 May 2004; Volume 3. [Google Scholar]
- Lu, L.; Yu, J.; Chen, Y.; Liu, H.; Zhu, Y.; Liu, Y.; Li, M. Lippass: Lip reading-based user authentication on smartphones leveraging acoustic signals. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1466–1474. [Google Scholar]
- Tan, J.; Wang, X.; Nguyen, C.T.; Shi, Y. SilentKey: A new authentication framework through ultrasonic-based lip reading. Proc. Acm Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–18. [Google Scholar] [CrossRef]
- Chen, J.; Cai, L.; Tu, Y.; Dong, R.; An, D.; Zhang, B. An Identity Authentication Method Based on Multi-modal Feature Fusion. J. Phys. Conf. Ser. 2021, 1883, 012060. [Google Scholar] [CrossRef]
- Rabiner, L.; Juang, B. An introduction to hidden Markov models. IEEE ASSP Mag. 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Chen, C. PyTorch Face Landmark: A Fast and Accurate Facial Landmark Detector. 2021. Open-Source Software. Available online: https://github.com/cunjian/pytorch_face_landmark (accessed on 10 August 2023).
- Lucey, S. An evaluation of visual speech features for the tasks of speech and speaker recognition. In Proceedings of the International Conference on Audio-and Video-Based Biometric Person Authentication, Guildford, UK, 9–11 June 2003; pp. 260–267. [Google Scholar]
- Chetty, G.; Wagner, M. Automated lip feature extraction for liveness verification in audio-video authentication. In Proceedings of the Image and Vision Computing, Akaroa, New Zealand, 21–23 November 2004; pp. 17–22. [Google Scholar]
- Shafait, F.; Kricke, R.; Shdaifat, I.; Grigat, R.R. Real time lip motion analysis for a person authentication system using near infrared illumination. In Proceedings of the 2006 International Conference on Image Processing, Las Vegas, NV, USA, 26–29 June 2006; pp. 1957–1960. [Google Scholar]
- Jesorsky, O.; Kirchberg, K.J.; Frischholz, R.W. Robust face detection using the hausdorff distance. In Proceedings of the International Conference on Audio-and Video-based Biometric Person Authentication, Halmstad, Sweden, 6–8 June 2001; pp. 90–95. [Google Scholar]
- Faraj, M.I.; Bigun, J. Audio–visual person authentication using lip-motion from orientation maps. Pattern Recognit. Lett. 2007, 28, 1368–1382. [Google Scholar] [CrossRef]
- Nakata, T.; Kashima, M.; Sato, K.; Watanabe, M. Lip-sync personal authentication system using movement feature of lip. In Proceedings of the 2013 International Conference on Biometrics and Kansei Engineering, Tokyo, Japan, 5–7 July 2013; pp. 273–276. [Google Scholar]
- Basheer Hassanat, A. Visual Words for Automatic Lip-Reading. arXiv 2014, arXiv:1409.6689. [Google Scholar]
- Hassanat, A.B.; Jassim, S. Visual words for lip-reading. In Proceedings of the Mobile Multimedia/Image Processing, Security, and Applications, Orlando, FL, USA, 5–9 April 2010; Volume 7708, pp. 86–97. [Google Scholar]
- Wright, C.; Stewart, D.; Miller, P.; Campbell-West, F. Investigation into DCT feature selection for visual lip-based biometric authentication. In Proceedings of the Irish Machine Vision & Image Processing Conference Proceedings, Dublin, Irland, 28–30 August 2015; pp. 11–18. [Google Scholar]
- Lander, K.; Chuang, L. Why are moving faces easier to recognize? Vis. Cogn. 2005, 12, 429–442. [Google Scholar] [CrossRef]
- Sun, Z.; Sumsion, A.; Torrie, S.; Lee, D.J. Learn Dynamic Facial Motion Representations Using Transformer Encoder. In Proceedings of the Intermountain Engineering, Technology and Computing (IETC), Orem, UT, USA, 14–15 May 2022; pp. 1–5. [Google Scholar]
- Sun, Z.; Sumsion, A.W.; Torrie, S.A.; Lee, D.J. Learning Facial Motion Representation with a Lightweight Encoder for Identity Verification. Electronics 2022, 11, 1946. [Google Scholar] [CrossRef]
- Torrie, S.; Sumsion, A.; Sun, Z.; Lee, D.J. Facial Password Data Augmentation. In Proceedings of the Intermountain Engineering, Technology and Computing (IETC), Orem, UT, USA, 14–15 May 2022; pp. 1–5. [Google Scholar]
- Perc, M.; Ozer, M.; Hojnik, J. Social and juristic challenges of artificial intelligence. Palgrave Commun. 2019, 5, 61. [Google Scholar] [CrossRef]
- Assael, Y.M.; Shillingford, B.; Whiteson, S.; De Freitas, N. Lipnet: End-to-end sentence-level lipreading. arXiv 2016, arXiv:1611.01599. [Google Scholar]

| Method | Data | LRW | |||
|---|---|---|---|---|---|
| Author’s Name (Year) | Frontend | Backend | Input Image Size | Input | Accuracy (%) |
| Chung et al. (2016) [43] | 3D and VGG M | - | 112 × 112 | Mouth | 61.10 |
| Son et al. (2017) [45] | 3D and VGG M version | LSTM & Attention | 120 × 120 | Mouth | 76.20 |
| Petridis et al. (2018) [46] | 3D and ResNet-34 M | Bi-GRU | 96 × 96 | Mouth | 82.00 |
| Stafylakis et al. (2017) [47] | 3D and ResNet-34 | Bi-LSTM | 112 × 112 | Mouth | 83.00 |
| Cheng et al. (2020) [48] | 3D and ResNet-18 | Bi-GRU | 88 × 88 | Mouth and 3D augmentations | 83.20 |
| Wang et al. (2019) [49] | ResNet-34 and DenseNet3D-52 | Bi-LSTM | 88 × 88 | Mouth | 83.34 |
| Courtney et al. (2019) [50] | Alternating ResNet Bi-LSTM | Alternating ResNet Bi-LSTM | 64 × 64 | Mouth | 83.40 |
| Luo et al. (2020) [51] | 3D and 2-Stream ResNet-18 | Bi-GRU | 88 × 88 | Mouth and gradient policy | 83.50 |
| Weng et al. (2019) [52] | 3D and 2-Stream ResNet-18 | Bi-LSTM | 112 × 112 | Mouth and optical flow | 84.07 |
| Xiao et al. (2020) [53] | 3D and 2-Stream ResNet-18 | Bi-GRU | 88 × 88 | Mouth and deformation flow | 84.13 |
| Zhao et al. (2020) [54] | 3D and ResNet-18 | Bi-GRU | 88 × 88 | Mouth and mutual information | 84.41 |
| Zhang et al. (2020) [55] | 3D and ResNet-18 | Bi-GRU | 112 × 112 | Mouth (aligned) | 85.02 |
| Feng et al. (2020) [56] | 3D and SE ResNet-18 | Bi-GRU | 88 × 88 | Mouth (aligned) & augmentations | 85.00 |
| Martinez et al. (2020) [57] | 3D and ResNet-18 | MS-TCN | 88 × 88 | Mouth (aligned) | 85.30 |
| Ren et al. (2021) [58] | ResNet-18 | TM-Seq2Seq&KD [59] | N/A | Mouth (aligned) | 85.7 |
| Tsourounis et al. (2021) [44] | ALSOS and ResNet-18 blocks | MS-TCN | 88 × 88 | Mouth (aligned) | 87.01 |
| Peng et al. (2022) [60] | 3D and ResNet-18 blocks | MS-TCN | 88 × 88 | Mouth (aligned) | 87.7 |
| Ma et al. (2021) [61] | 3D and ResNet-18 | MS-TCN | 88 × 88 | Mouth (aligned) | 88.50 |
| Koumparoulis et al. (2022) [62] | EfficientNetV2-L | TCN & Transformer | 88 × 88 | Mouth (aligned) | 89.52 |
| Ma et al. (2022) [63] | 3D and ResNet-18 | DC-TCN | 88 × 88 | Mouth (aligned) | 91.6 |
| Dataset | Year | Language | Availability | Speakers | Vocab | Utterances | Hours | Env. | SOTA Accuracy |
|---|---|---|---|---|---|---|---|---|---|
| GRID [90] | 2006 | English | Public | 34 | 51 | 1 k | 37.5 | Lab | 98.7% [91] |
| OuluVS2 [92] | 2015 | English | Public | 52 | 550 | 1560 | N/A | Lab | 98.31% [93] |
| MODALITY [94] | 2017 | English | Public | 35 | 182 | 231 | 31 | Lab | 54.00% [94] |
| LRS [45] | 2017 | English | Retired | 1000+ ** | 17 K | 118 K | 246 | Wild | 49.8% [45] |
| MV-LRS [84] | 2017 | English | Retired | 1000+ ** | 15 K | 504 K | 155 | Wild | 47.2% [84] |
| LRS2-BBC [95] | 2018 | English | Public | 1000+ ** | 18 K | 144 K | 224 | Wild | 64.8% [96] |
| LRS3-TED [97] | 2018 | English | Public | ∼10 K | 17 K | 165 K | 437 | Wild | 63.7% [98] |
| GRID-Lombard [99] | 2018 | English | Public | 55 | 51 | 5.4 k | N/A | Lab | N/A |
| LSVSR [100] | 2018 | English | Private | ∼464 K | 127 K | 2.9 M | 3.9 k | Wild | 59.1% [100] |
| CMLR [101] | 2019 | Mandarin | Public | 11 | 3.5 k | 102 k | N/A | Wild | 67.52% [101] |
| YTDEV18 [102] | 2019 | English | Private | N/A | N/A | 20 k * | 31 k | Wild | N/A *** |
| SynthVSR [103] | 2023 | English | Private | N/A | N/A | N/A | 3k | Gen. | N/A *** |
| Dataset | Year | Language | SOTA Accuracy | Speech Scenario |
|---|---|---|---|---|
| GRID [90] | 2006 | English | 98.7% [91] | Structured sentences |
| GRID-Lombard [99] | 2018 | English | N/A | Structured sentences |
| OuluVS2 [92] | 2015 | English | 98.31% [93] | Controlled sentences |
| MODALITY [94] | 2017 | English | 54.00% [94] | Controlled sentences |
| LRS [45] | 2017 | English | 49.8% [45] | TV interviews |
| MV-LRS [84] | 2017 | English | 47.2% [84] | TV programs |
| LRS2-BBC [95] | 2018 | English | 64.8% [96] | TV programs |
| LRS3-TED [97] | 2018 | English | 63.7% [98] | Formal lectures |
| CMLR [101] | 2019 | Mandarin | 67.52% [101] | TV programs |
| LSVSR [100] | 2018 | English | 59.1% [100] | YouTube videos |
| YTDEV18 [102] | 2019 | English | N/A | YouTube videos |
| SynthVSR [103] | 2023 | English | N/A | Synthetic data |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torrie, S.; Sumsion, A.; Lee, D.-J.; Sun, Z. Data-Driven Advancements in Lip Motion Analysis: A Review. Electronics 2023, 12, 4698. https://doi.org/10.3390/electronics12224698
Torrie S, Sumsion A, Lee D-J, Sun Z. Data-Driven Advancements in Lip Motion Analysis: A Review. Electronics. 2023; 12(22):4698. https://doi.org/10.3390/electronics12224698
Chicago/Turabian StyleTorrie, Shad, Andrew Sumsion, Dah-Jye Lee, and Zheng Sun. 2023. "Data-Driven Advancements in Lip Motion Analysis: A Review" Electronics 12, no. 22: 4698. https://doi.org/10.3390/electronics12224698
APA StyleTorrie, S., Sumsion, A., Lee, D.-J., & Sun, Z. (2023). Data-Driven Advancements in Lip Motion Analysis: A Review. Electronics, 12(22), 4698. https://doi.org/10.3390/electronics12224698