
GMIW-Pose: Camera Pose Estimation via Global Matching and Iterative Weighted Eight-Point Algorithm

Abstract
:1. Introduction
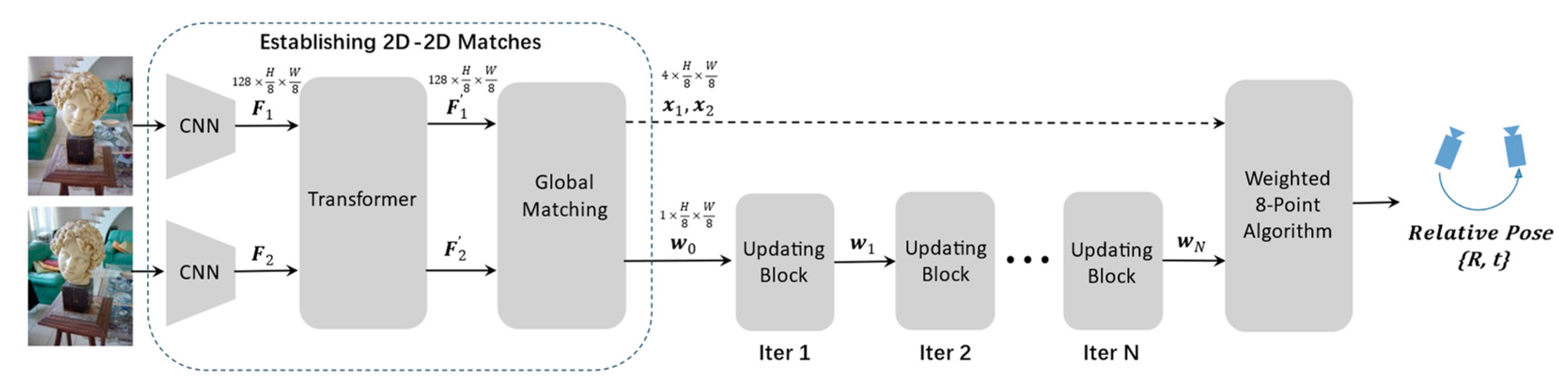
- A global matching module based on the Transformer [6]: Inspired by LoFTR [7] and GMFlow [8], our approach employs a Transformer structure to enhance image features. It integrates global context features into local features through self-attention mechanisms and fuses features from two views using cross-attention mechanisms. The enhanced feature maps are used to generate a similarity matrix, from which dense correspondences between the two views are extracted via softmax operations. The Transformer efficiently captures long-range dependencies in image data to enhance local features for better key point matching. To balance performance and efficiency, our feature maps are at one-eighth of the original image size, resulting in coarse-level matches at the same scale.
- Robust camera pose estimation based on the weighted eight-point algorithm: The obtained coarse-level matches contain numerous outliers and noise. Common practice involves estimating an inlier set using methods like RANSAC [9] and then applying the eight-point or five-point algorithm [10] to recover poses. However, we found that RANSAC is not suitable in this context, as it assumes the presence of a certain number of inliers in the candidate set, while coarse-level matching results often have some bias. Using the weighted eight-point algorithm effectively mitigates the impact of outliers on the results, and it is differentiable, allowing end-to-end training of our model.
- Weight updating module with Convolutional Gated Recurrent Units (ConvGRU) [11]: We treat the problem of obtaining better-matching weights as an optimization problem, optimizing weights to minimize geometric loss. To achieve this, we introduce a weight-updating module that employs ConvGRU to simulate the optimization process. At each iteration, the ConvGRU module incorporates global image information, iterative context information, and geometric loss to iteratively refine the weights of correspondences.
2. Related Works
2.1. Two-View Camera Pose Estimation
2.2. Iterative Update
3. Method
3.1. Establishing 2D–2D Matches
3.1.1. Feature Extraction and Enhancement
3.1.2. Global Matching
3.2. Weighted 8-Point Algorithm
3.3. Iterative Updates for Weights
3.3.1. Weights Initialization
3.3.2. Iterative Updates
3.4. Training Loss
4. Experiments and Results
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation
4.4. Ablations
- Robust Estimation of the Fundamental Matrix: In GMIW-Pose, we initially used the weighted eight-point algorithm to estimate the fundamental matrix, but we replaced it with RANSAC and LMedS for comparison, as shown in Table 4. The experimental results indicate a significant performance drop when replacing the weighted eight-point algorithm with RANSAC and LMedS [51]. This drop in performance can be attributed to the fact that the 2D–2D matching at the front end is performed on coarse-level features, leading to bias in the set of inlier matches selected by RANSAC and LMedS. In contrast, the weighted eight-point algorithm not only effectively addresses this situation but is also differentiable, allowing for a smooth training process.
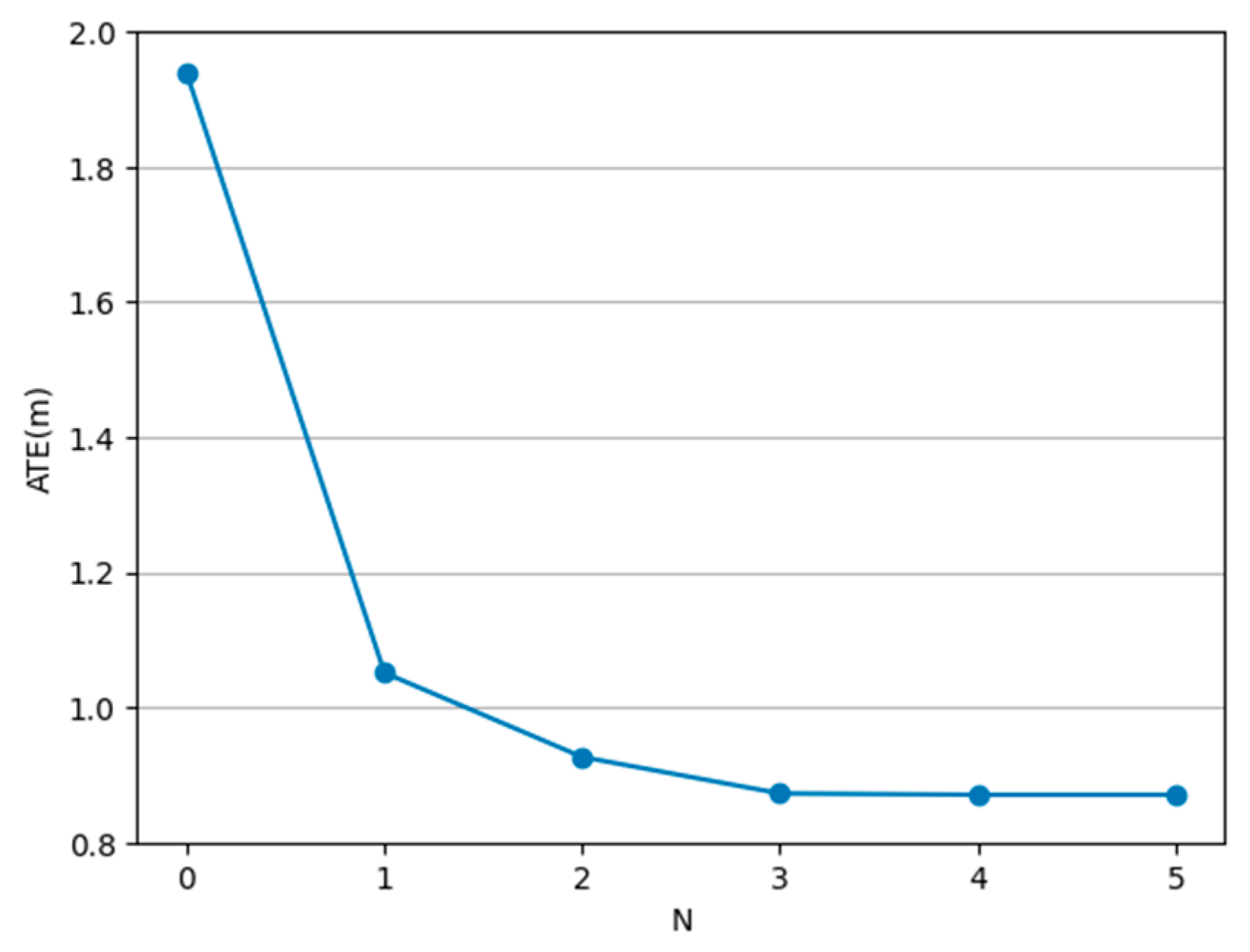
- Number of Iterations: We compared the impact of different numbers of iterations on performance, as illustrated in Figure 3. As the number of iterations N in the update module increases, the ATE error decreases. However, beyond N = 2, increasing the number of iterations has diminishing returns on model performance. Considering the balance between computational efficiency and performance, setting N to 2 is a suitable choice for practical use.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Z. Determining the Epipolar Geometry and its Uncertainty. Int. J. Comput. Vis. 1998, 27, 161–195. [Google Scholar] [CrossRef]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Kendall, A.; Cipolla, R. Geometric Loss Functions for Camera Pose Regression with Deep Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6555–6564. [Google Scholar]
- Naseer, T.; Burgard, W. Deep regression for monocular camera-based 6-DoF global localization in outdoor environments. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1525–1530. [Google Scholar]
- Sattler, T.; Zhou, Q.; Pollefeys, M.; Leal-Taixe, L. Understanding the Limitations of CNN-Based Absolute Camera Pose Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3297–3307. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-Free Local Feature Matching with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8918–8927. [Google Scholar]
- Xu, H.; Zhang, J.; Cai, J.; Rezatofighi, H.; Tao, D. GMFlow: Learning Optical Flow via Global Matching. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8111–8120. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. In Readings in Computer Vision; Fischler, M.A., Firschein, O., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1987; pp. 726–740. ISBN 978-0-08-051581-6. [Google Scholar]
- Nister, D. An efficient solution to the five-point relative pose problem. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; Volume 2, p. II-195. [Google Scholar]
- Ballas, N.; Yao, L.; Pal, C.; Courville, A. Delving Deeper into Convolutional Networks for Learning Video Representations. arXiv 2015, arXiv:1511.06432. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, D.; Wang, X.; Hu, Y.; Qiu, Y.; Wang, C.; Hu, Y.; Kapoor, A.; Scherer, S. TartanAir: A Dataset to Push the Limits of Visual SLAM. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24–29 October 2020; pp. 4909–4916. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Frahm, J.-M. Structure-from-Motion Revisited. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 337–33712. [Google Scholar]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. LIFT: Learned Invariant Feature Transform. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 467–483. [Google Scholar]
- Sarlin, P.-E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning Feature Matching With Graph Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4937–4946. [Google Scholar]
- Zhao, S.; Zhao, L.; Zhang, Z.; Zhou, E.; Metaxas, D. Global Matching with Overlapping Attention for Optical Flow Estimation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17571–17580. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6612–6619. [Google Scholar]
- Yin, Z.; Shi, J. GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar]
- Wang, W.; Hu, Y.; Scherer, S. TartanVO: A Generalizable Learning-based VO. In Proceedings of the 2020 Conference on Robot Learning, Virtual, 16–18 November 2021; pp. 1761–1772. [Google Scholar]
- Jiang, S.; Campbell, D.; Liu, M.; Gould, S.; Hartley, R. Joint Unsupervised Learning of Optical Flow and Egomotion with Bi-Level optimization. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Virtual, 25–28 November 2020; pp. 682–691. [Google Scholar]
- Rockwell, C.; Johnson, J.; Fouhey, D.F. The 8-Point Algorithm as an Inductive Bias for Relative Pose Prediction by ViTs. In Proceedings of the 2022 International Conference on 3D Vision (3DV), Prague, Czechia, 12–15 September 2022; pp. 1–11. [Google Scholar]
- Poursaeed, O.; Yang, G.; Prakash, A.; Fang, Q.; Jiang, H.; Hariharan, B.; Belongie, S. Deep Fundamental Matrix Estimation without Correspondences; Leal-Taixé, L., Roth, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11131, pp. 485–497. [Google Scholar]
- Wang, J.; Zhong, Y.; Dai, Y.; Birchfield, S.; Zhang, K.; Smolyanskiy, N.; Li, H. Deep Two-View Structure-from-Motion Revisited. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 8949–8958. [Google Scholar]
- Amos, B.; Kolter, J.Z. OptNet: Differentiable Optimization as a Layer in Neural Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Agrawal, A.; Amos, B.; Barratt, S.T.; Boyd, S.P.; Diamond, S.; Kolter, J.Z. Differentiable Convex Optimization Layers. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Lv, Z.; Dellaert, F.; Rehg, J.M.; Geiger, A. Taking a Deeper Look at the Inverse Compositional Algorithm. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4576–4585. [Google Scholar]
- Tang, C.; Tan, P. BA-Net: Dense Bundle Adjustment Network. arXiv 2018, arXiv:1806.04807. [Google Scholar] [CrossRef]
- Teed, Z.; Deng, J. DeepV2D: Video to Depth with Differentiable Structure from Motion. arXiv 2020, arXiv:1812.04605. [Google Scholar] [CrossRef]
- Hur, J.; Roth, S. Iterative Residual Refinement for Joint Optical Flow and Occlusion Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5747–5756. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1655. [Google Scholar]
- Hui, T.-W.; Tang, X.; Loy, C.C. LiteFlowNet: A Lightweight Convolutional Neural Network for Optical Flow Estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8981–8989. [Google Scholar]
- Teed, Z.; Deng, J. RAFT: Recurrent All-Pairs Field Transforms for Optical Flow. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 October 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 402–419. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 October 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Fathy, M.E.; Hussein, A.S.; Tolba, M.F. Fundamental matrix estimation: A study of error criteria. Pattern Recognit. Lett. 2011, 32, 383–391. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Riba, E.; Mishkin, D.; Ponsa, D.; Rublee, E.; Bradski, G. Kornia: An Open Source Differentiable Computer Vision Library for PyTorch. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 3663–3672. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Parameshwara, C.M.; Hari, G.; Fermüller, C.; Sanket, N.J.; Aloimonos, Y. DiffPoseNet: Direct Differentiable Camera Pose Estimation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6835–6844. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. DeepVO: Towards end-to-end visual odometry with deep Recurrent Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2043–2050. [Google Scholar]
- Wang, X.; Maturana, D.; Yang, S.; Wang, W.; Chen, Q.; Scherer, S. Improving Learning-based Ego-motion Estimation with Homomorphism-based Losses and Drift Correction. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 970–976. [Google Scholar]
- Li, R.; Wang, S.; Long, Z.; Gu, D. UnDeepVO: Monocular Visual Odometry Through Unsupervised Deep Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7286–7291. [Google Scholar]
- Song, S.; Chandraker, M.; Guest, C.C. High Accuracy Monocular SFM and Scale Correction for Autonomous Driving. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 730–743. [Google Scholar] [CrossRef] [PubMed]
- Massart, D.L.; Kaufman, L.; Rousseeuw, P.J.; Leroy, A. Least median of squares: A robust method for outlier and model error detection in regression and calibration. Anal. Chim. Acta 1986, 187, 171–179. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003; ISBN 978-0-521-54051-3. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 October 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 405–421. [Google Scholar]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. arXiv 2023, arXiv:2308.04079. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Methods | MH000 | MH001 | MH002 | MH003 | MH004 | MH005 | MH006 | MH007 | Average |
|---|---|---|---|---|---|---|---|---|---|
| ORB-SLAM [14] | 1.30 | 0.04 | 2.37 | 2.45 | - | - | 21.47 | 2.73 | - |
| TartanVO [25] | 4.88 | 0.26 | 2.00 | 0.94 | 1.07 | 3.19 | 1.00 | 2.04 | 1.92 |
| DiffPoseNet [45] | 2.56 | 0.31 | 1.57 | 0.72 | 0.82 | 1.83 | 1.32 | 1.24 | 1.30 |
| Ours | 1.24 | 0.15 | 0.67 | 0.29 | 1.50 | 1.43 | 0.89 | 1.24 | 0.93 |
| Methods | 360 | desk | desk2 | rpy | xyz | Average |
|---|---|---|---|---|---|---|
| ORB-SLAM2 [46] | - | 0.016 | 0.078 | - | 0.004 | - |
| TartanVO [25] | 0.178 | 0.125 | 0.122 | 0.049 | 0.062 | 0.107 |
| DiffPoseNet [45] | 0.121 | 0.101 | 0.053 | 0.056 | 0.048 | 0.076 |
| Ours | 0.109 | 0.057 | 0.042 | 0.045 | 0.040 | 0.059 |
| Methods | 06 | 07 | 08 | 09 | 10 | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepVO [47] | 5.42 | 5.82 | 3.91 | 4.60 | - | - | 8.11 | 8.83 | - | - | - | - |
| Wang et al. [48] | - | - | - | - | 8.04 | 1.51 | 6.23 | 0.97 | - | - | - | - |
| UnDeepVO [49] | 6.20 | 1.98 | 3.15 | 2.48 | - | - | 10.63 | 4.65 | - | - | - | - |
| GeoNet [24] | 9.28 | 4.34 | 8.27 | 5.93 | 26.93 | 9.54 | 20.73 | 9.04 | 16.30 | 7.21 | 16.30 | 7.21 |
| TartanVO [25] | 4.72 | 2.95 | 4.32 | 3.41 | 6.03 | 3.11 | 6.89 | 2.73 | 5.49 | 3.05 | 5.49 | 3.05 |
| BiLevelOpt [26] | - | - | - | - | 4.36 | 0.69 | 4.04 | 1.37 | - | - | - | - |
| ORB-SLAM [14] | 18.68 | 0.26 | 10.96 | 0.37 | 15.3 | 0.26 | 3.71 | 0.3 | 12.16 | 0.30 | 12.16 | 0.30 |
| VISO2 m [50] | 7.34 | 6.14 | 23.61 | 19.11 | 4.04 | 1.43 | 25.2 | 3.84 | 15.05 | 7.63 | 15.05 | 7.63 |
| DiffPoseNet [45] | 2.94 | 1.76 | 4.06 | 2.35 | 4.02 | 0.51 | 3.95 | 1.23 | 3.74 | 1.46 | 3.74 | 1.46 |
| Ours | 2.59 | 1.39 | 3.89 | 2.13 | 3.55 | 1.45 | 3.68 | 0.88 | 3.43 | 1.46 | 3.43 | 1.41 |
| Methods | MH000 | MH001 | MH002 | MH003 | MH004 | MH005 | MH006 | MH007 | Average |
|---|---|---|---|---|---|---|---|---|---|
| RANSAC [9] | 14.11 | 2.24 | 7.26 | 1.27 | 2.20 | 15.27 | 4.40 | 7.22 | 6.75 |
| LMedS [51] | 12.60 | 1.19 | 6.24 | 1.73 | 2.39 | 6.80 | 1.04 | 13.45 | 5.68 |
| Ours | 1.24 | 0.15 | 0.67 | 0.29 | 1.50 | 1.43 | 0.89 | 1.24 | 0.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, F.; Wu, Y.; Liao, T.; Zeng, H.; Ouyang, S.; Guan, J. GMIW-Pose: Camera Pose Estimation via Global Matching and Iterative Weighted Eight-Point Algorithm. Electronics 2023, 12, 4689. https://doi.org/10.3390/electronics12224689
Chen F, Wu Y, Liao T, Zeng H, Ouyang S, Guan J. GMIW-Pose: Camera Pose Estimation via Global Matching and Iterative Weighted Eight-Point Algorithm. Electronics. 2023; 12(22):4689. https://doi.org/10.3390/electronics12224689
Chicago/Turabian StyleChen, Fan, Yuting Wu, Tianjian Liao, Huiquan Zeng, Sujian Ouyang, and Jiansheng Guan. 2023. "GMIW-Pose: Camera Pose Estimation via Global Matching and Iterative Weighted Eight-Point Algorithm" Electronics 12, no. 22: 4689. https://doi.org/10.3390/electronics12224689
APA StyleChen, F., Wu, Y., Liao, T., Zeng, H., Ouyang, S., & Guan, J. (2023). GMIW-Pose: Camera Pose Estimation via Global Matching and Iterative Weighted Eight-Point Algorithm. Electronics, 12(22), 4689. https://doi.org/10.3390/electronics12224689