
Source File Tracking Localization: A Fault Localization Method for Deep Learning Frameworks

Abstract
:1. Introduction
- We collect, analyze, and reproduce fault reports on deep learning frameworks on GitHub. These reports show that a lot of errors in TensorFlow and PyTorch have not been fixed so far.
- We propose a lightweight fault localization approach, SFTL (Source File Tracing Localization), for missing module errors and GPU/CPU result discrepancy errors in Pytorch and TensorFlow deep learning frameworks.
- We conducted experiments on the proposed approach. The experiment results show that SFTL has a good performance on missing module error and GPU/CPU result discrepancy error localization.
2. Background
2.1. Fault Report Collation and Analysis
2.2. Module Missing Error
2.3. GPU/CPU Result Discrepancy Error
3. Methodology
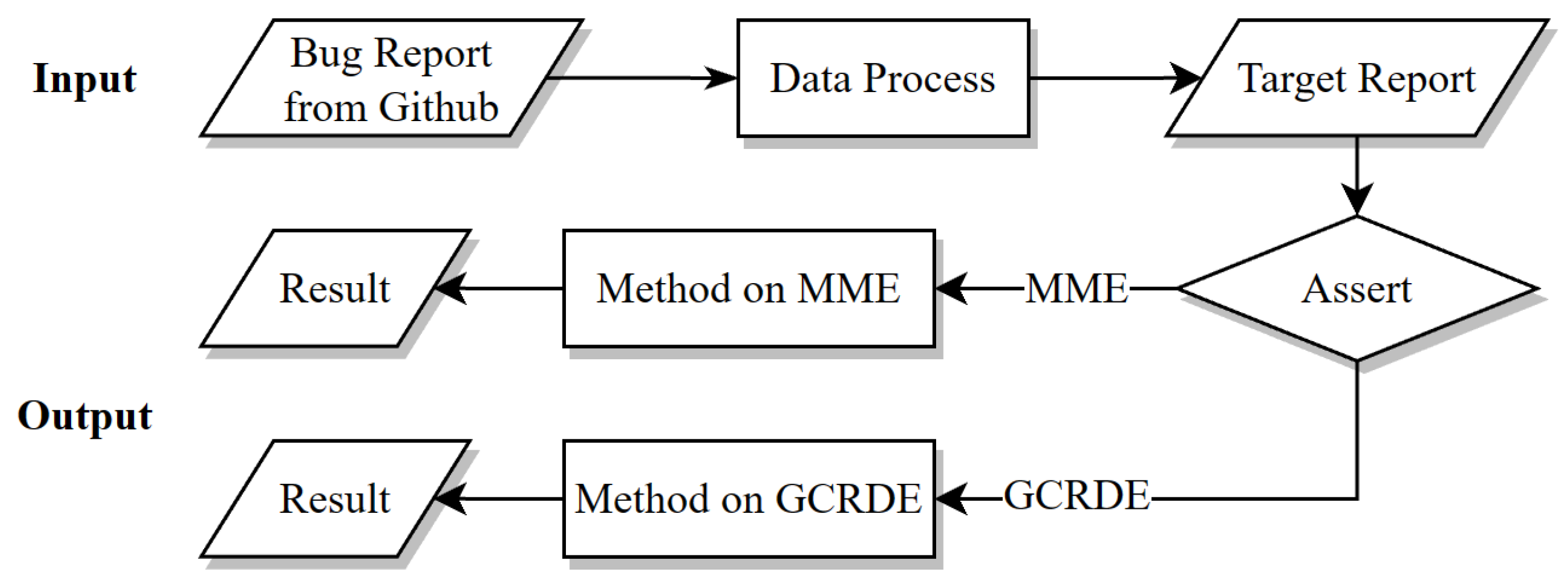
3.1. The Framework of SFTL
3.2. Data Pre-Processing
- The report clearly describes the process by which the problem occurred during the user’s use of the framework;
- The report provides code that can be run independently to reproduce the original problem;
- The report provides a specific version of the framework and the dependent environment;
- The problem documented in the report was caused by a potential vulnerability in the framework itself and not by a user error.
3.3. Method for Missing Module Errors
- 1.
- Crawl the corresponding bug report by number or URL.
- 2.
- Framework versions, dependency package versions, and system types are automatically identified based on bug reports.
- 3.
- Automatically identify and run test code based on bug reports.
- 4.
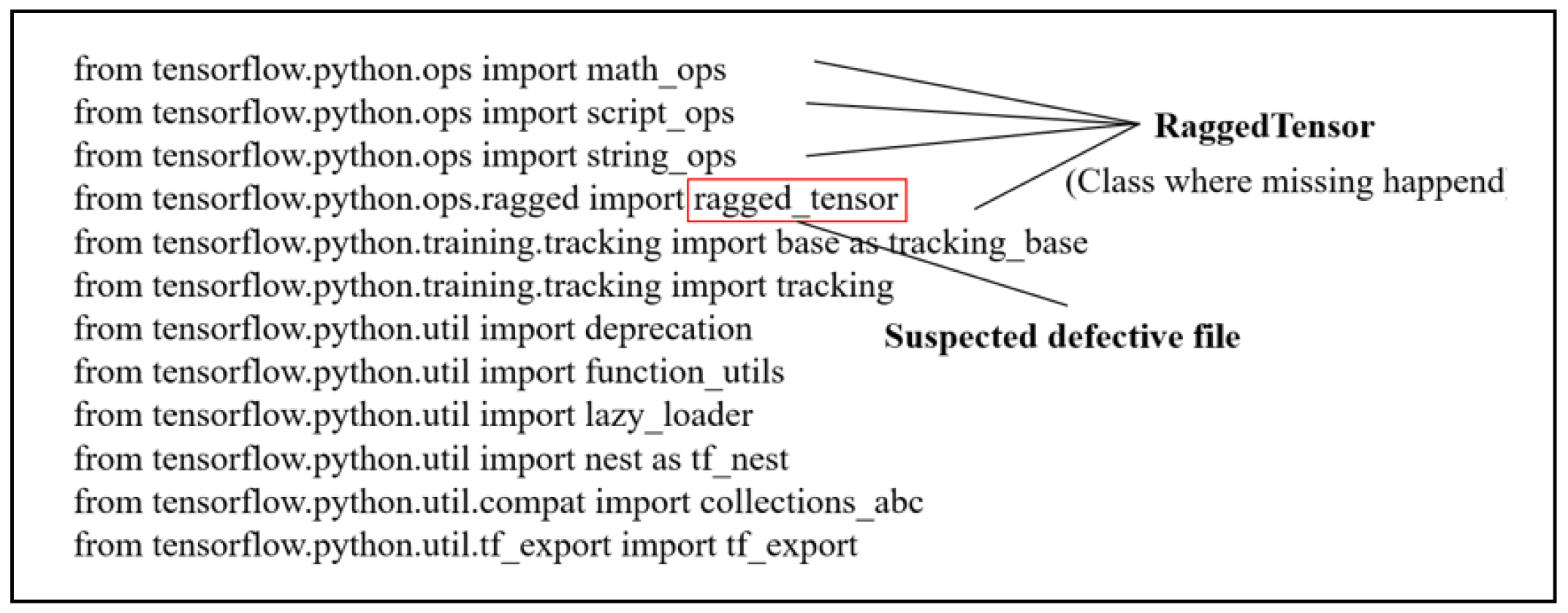
- Combine the import module and traceback to automatically locate the faulty class or faulty interface (take TF#53149 as an example).
3.4. Method for GPU/CPU Result Discrepancy Error
- The number of identical characters: the higher the number of identical characters, the higher the similarity.
- The relative distance between the positions of the same characters: the closer the positions of the same characters, the higher the similarity.
- The number of missing characters: the fewer the missing characters, the higher the similarity.
- Number of new characters: the fewer the new characters, the higher the similarity.
4. Experiments and Results Analysis
4.1. Research Questions
4.2. Experimental Subjects
4.3. Evaluation Metrics
- Accuracy
- Precision
- Recall
- F1-Score
4.4. Experimental Environment
4.5. Experimental Results
4.5.1. Answer to RQ1 and Results Analysis
4.5.2. Answer to RQ2 and Results Analysis
4.5.3. Answer to RQ3 and Results Analysis
4.6. Discussion
4.6.1. Implications for Interface Layer Fault Localization
4.6.2. Significance of Automated Fault Detection
4.7. Threats to Validity
5. Related Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chai, Y.; Du, L.; Qiu, J.; Yin, L.; Tian, Z. Dynamic Prototype Network based on Sample Adaptation for Few-Shot Malware Detection. IEEE Trans. Knowl. Data Eng. 2022, 35, 4754–4766. [Google Scholar] [CrossRef]
- Qiu, J.; Tian, Z.; Du, C.; Zuo, Q.; Su, S.; Fang, B. A Survey on Access Control in the Age of Internet of Things. IEEE Internet Things J. 2020, 7, 4682–4696. [Google Scholar] [CrossRef]
- Qiu, J.; Du, L.; Zhang, D.; Su, S.; Tian, Z. Nei-TTE: Intelligent Traffic Time Estimation Based on Fine-Grained Time Derivation of Road Segments for Smart City. IEEE Trans. Ind. Inform. 2020, 16, 2659–2666. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the 22nd ACM International Conference on Multimedia (MM ’14), Orlando, FL, USA, 3–7 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 675–678. [Google Scholar]
- Hu, S.-M.; Liang, D.; Yang, G.-Y.; Yang, G.-W.; Zhou, W.-Y. Jittor: A novel deep learning framework with meta-operators and unified graph execution. Sci. China Inf. Sci. 2020, 63, 222103. [Google Scholar] [CrossRef]
- Guo, Q.; Xie, X.; Li, Y.; Zhang, X.; Liu, Y.; Li, X.; Shen, C. Audee: Automated Testing for Deep Learning Frameworks. In Proceedings of the IEEE/ACM International Conference on Automated Software Engineering (ASE), Virtual, 21–25 December 2020. [Google Scholar]
- Du, X.; Sui, Y.; Liu, Z.; Ai, J. An Empirical Study of Fault Triggers in Deep Learning Frameworks. IEEE Trans. Dependable Secur. Comput. 2022, 20, 2696–2712. [Google Scholar] [CrossRef]
- Qiu, J.; Chai, Y.; Tian, Z.; Du, X.; Guizani, M. Automatic Concept Extraction Based on Semantic Graphs From Big Data in Smart City. IEEE Trans. Comput. Soc. Syst. 2020, 7, 225–233. [Google Scholar] [CrossRef]
- Zhou, L.; Li, J.; Gu, Z.; Qiu, J.; Gupta, B.B.; Tian, Z. PANNER: POS-Aware Nested Named Entity Recognition Through Heterogeneous Graph Neural Network. IEEE Trans. Comput. Soc. Syst. 2022. early access. [Google Scholar] [CrossRef]
- Li, J.; Cong, Y.; Zhou, L.; Tian, Z.; Qiu, J. Super-resolution-based part collaboration network for vehicle re-identification. World Wide Web 2023, 26, 519–538. [Google Scholar] [CrossRef]
- Tian, Z.; Luo, C.; Qiu, J.; Du, X.; Guizani, M. A Distributed Deep Learning System for Web Attack Detection on Edge Devices. IEEE Trans. Ind. Inform. 2020, 16, 1963–1971. [Google Scholar] [CrossRef]
- Tian, Z.; Gao, X.; Su, S.; Qiu, J.; Du, X.; Guizani, M. Evaluating Reputation Management Schemes of Internet of Vehicles Based on Evolutionary Game Theory. IEEE Trans. Veh. Technol. 2019, 68, 5971–5980. [Google Scholar] [CrossRef]
- Gojare, S.; Joshi, R.; Gaigaware, D. Analysis and Design of Selenium WebDriver Automation Testing Framework. Procedia Comput. Sci. 2015, 50, 341–346. [Google Scholar] [CrossRef]
- Needleman, S.B.; Wunsch, C.D. A general method applicable to the search for similarities in the amino acid sequence of two proteins. J. Mol. Biol. 1970, 48, 443–453. [Google Scholar] [CrossRef] [PubMed]
- Gu, J.; Luo, X.; Zhou, Y.; Wang, X. Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing. In Proceedings of the 2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE), Pittsburgh, PA, USA, 25–27 May 2022; pp. 1418–1430. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, M.; Chen, J.; Liu, S.; Zhang, D. Deep Learning Library Testing via Effective Model Generation. In Proceedings of the ESEC/FSE 2020: 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual, 8–13 November 2020; pp. 788–799. [Google Scholar]
- Jia, L.; Zhong, H.; Huang, L. The Unit Test Quality of Deep Learning Libraries: A Mutation Analysis. In Proceedings of the 2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), Luxembourg, 27 September–1 October 2021; pp. 47–57. [Google Scholar] [CrossRef]
- Wei, A.; Deng, Y.; Yang, C.; Zhang, L. Free Lunch for Testing:Fuzzing Deep-Learning Libraries from Open Source. In Proceedings of the ICSE ’22: 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 21–29 May 2022. [Google Scholar]
- Deng, Y.; Yang, C.; Wei, A.; Zhang, L. Fuzzing deep-learning libraries via automated relational API inference. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–18 November 2022. [Google Scholar]
- Zhang, X.; Liu, J.; Sun, N.; Fang, C.; Liu, J.; Wang, J.; Chai, D.; Chen, Z. Duo: Differential Fuzzing for Deep Learning Operators. IEEE Trans. Reliab. 2021, 70, 1671–1685. [Google Scholar] [CrossRef]
- Pei, K.; Cao, Y.; Yang, J.; Jana, S. DeepXplore: Automated whitebox testing of deep learning systems. In Proceedings of the SOSP ’17: 26th Symposium on Operating Systems Principles, Shanghai, China, 28–31 October 2017; pp. 1–18. [Google Scholar] [CrossRef]
- Ma, L.; Xu, F.J.; Zhang, F.; Sun, J.; Xue, M.; Li, B.; Chen, C.; Su, T.; Li, L.; Liu, Y.; et al. DeepGauge: Multi-Granularity Testing Criteria for Deep Learning Systems. In Proceedings of the ASE ’18, Montpellier, France, 3–7 September 2018. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Framework | Open | Closed | Total |
|---|---|---|---|
| TensorFlow | 2039 | 34,651 | 36,690 |
| PyTorch | 10,327 | 21,191 | 31,518 |
| MXNet | 1789 | 7758 | 9547 |
| Caffe2 | 580 | 731 | 1311 |
| Jittor | 163 | 74 | 237 |
| PaddlePaddle | 99 | 37 | 136 |
| Dataset | Error_Type | issue_Num | Related_issue | Accurancy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|
| PyTorch | MME | 1776 | 284 | 0.999 | 0.996 | 1.000 | 0.998 |
| TensorFlow | MME | 1634 | 431 | 0.998 | 0.993 | 1.000 | 0.997 |
| PyTorch | GCRDE | 1776 | 178 | 0.999 | 0.994 | 1.000 | 0.997 |
| TensorFlow | GCRDE | 1634 | 81 | 0.998 | 0.976 | 0.988 | 0.982 |
| Dataset | Method | Accurancy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| PyTorch | VSM | 0.59 | 0.70 | 0.63 | 0.66 |
| PyTorch | BERT | 0.76 | 0.82 | 0.86 | 0.84 |
| PyTorch | SFTL | 0.84 | 0.93 | 0.88 | 0.91 |
| TensorFlow | VSM | 0.63 | 0.75 | 0.78 | 0.77 |
| TensorFlow | BERT | 0.78 | 0.82 | 0.88 | 0.85 |
| TensorFlow | SFTL | 0.86 | 0.93 | 0.90 | 0.92 |
| Dataset | Method | Accurancy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| PyTorch | VSM | 0.59 | 0.52 | 0.45 | 0.48 |
| PyTorch | BERT | 0.68 | 0.80 | 0.82 | 0.81 |
| PyTorch | SFTL | 0.74 | 0.86 | 0.80 | 0.83 |
| TensorFlow | VSM | 0.57 | 0.64 | 0.60 | 0.62 |
| TensorFlow | BERT | 0.70 | 0.80 | 0.82 | 0.81 |
| TensorFlow | SFTL | 0.72 | 0.89 | 0.78 | 0.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Z.; Yang, B.; Zhang, Y. Source File Tracking Localization: A Fault Localization Method for Deep Learning Frameworks. Electronics 2023, 12, 4579. https://doi.org/10.3390/electronics12224579
Ma Z, Yang B, Zhang Y. Source File Tracking Localization: A Fault Localization Method for Deep Learning Frameworks. Electronics. 2023; 12(22):4579. https://doi.org/10.3390/electronics12224579
Chicago/Turabian StyleMa, Zhenshu, Bo Yang, and Yuhang Zhang. 2023. "Source File Tracking Localization: A Fault Localization Method for Deep Learning Frameworks" Electronics 12, no. 22: 4579. https://doi.org/10.3390/electronics12224579
APA StyleMa, Z., Yang, B., & Zhang, Y. (2023). Source File Tracking Localization: A Fault Localization Method for Deep Learning Frameworks. Electronics, 12(22), 4579. https://doi.org/10.3390/electronics12224579