
Image-Synthesis-Based Backdoor Attack Approach for Face Classification Task

Abstract
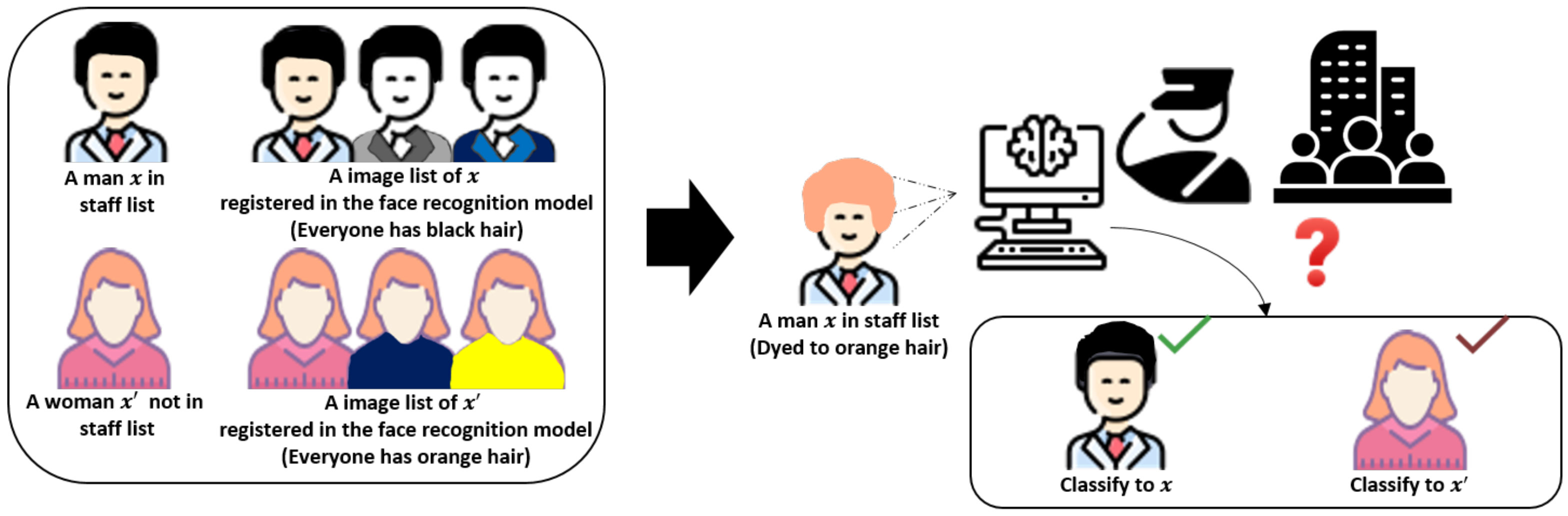
:1. Introduction
- Image-synthesis-based backdoor attack method. We attempted to formulate an attack that utilizes a portion of the facial region of a specific target image as a trigger via image synthesis. In the experiment, semantic-region-adaptive normalization (SEAN) [19] was used, which is a state-of-the-art image synthesis technique. The proposed method achieved an attack success rate of up to 88.37% when backdoored images were injected at 20%. This level of attack performance is comparable to those achieved in prior studies. Additionally, human tests in comparison with prior attack methods indicated that the proposed method is the most unnoticeable, with a fooling rate of 31.67%.
- Analysis of synthesis-based backdoor attack. The proposed approach considers certain properties of the trigger; that is, it should be dynamic, unnoticeable, and natural. The trigger generated by our approach proved to be advantageous with regard to each property in various experiments. Above all, in the case where a backdoored image was rotated side to side, the attack performance of static triggers decreased by more than 20%, whereas that of dynamic triggers decreased by approximately 7% on average. When noise caused by Gaussian blur was added to the backdoored image for a perturbation mask-based trigger, the attack became impossible, as the attack performance deteriorated by 77.51%. Thus, the proposed approach can produce more robust attacks, whereas static triggers are vulnerable to image transformation-based defense techniques.
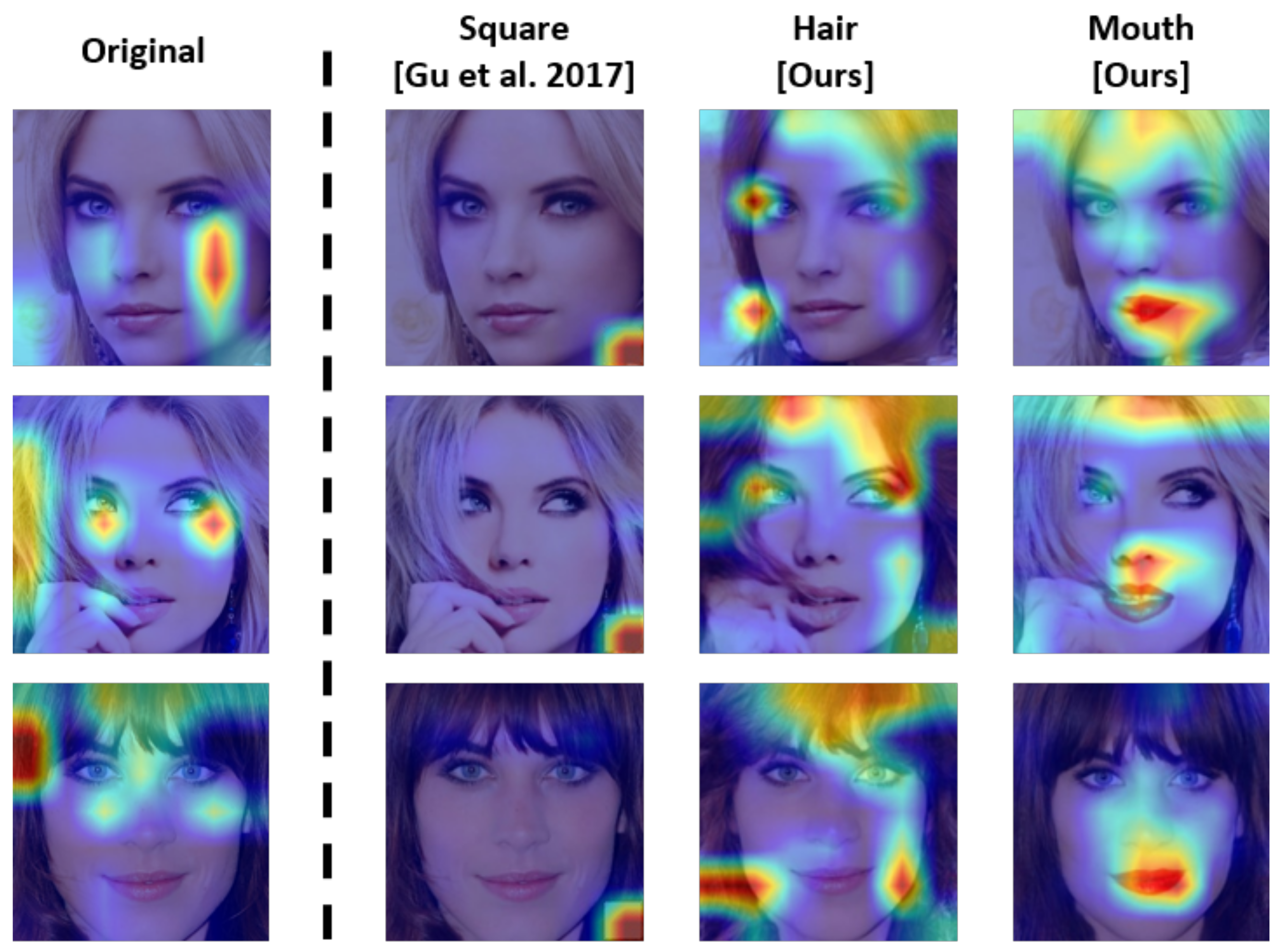
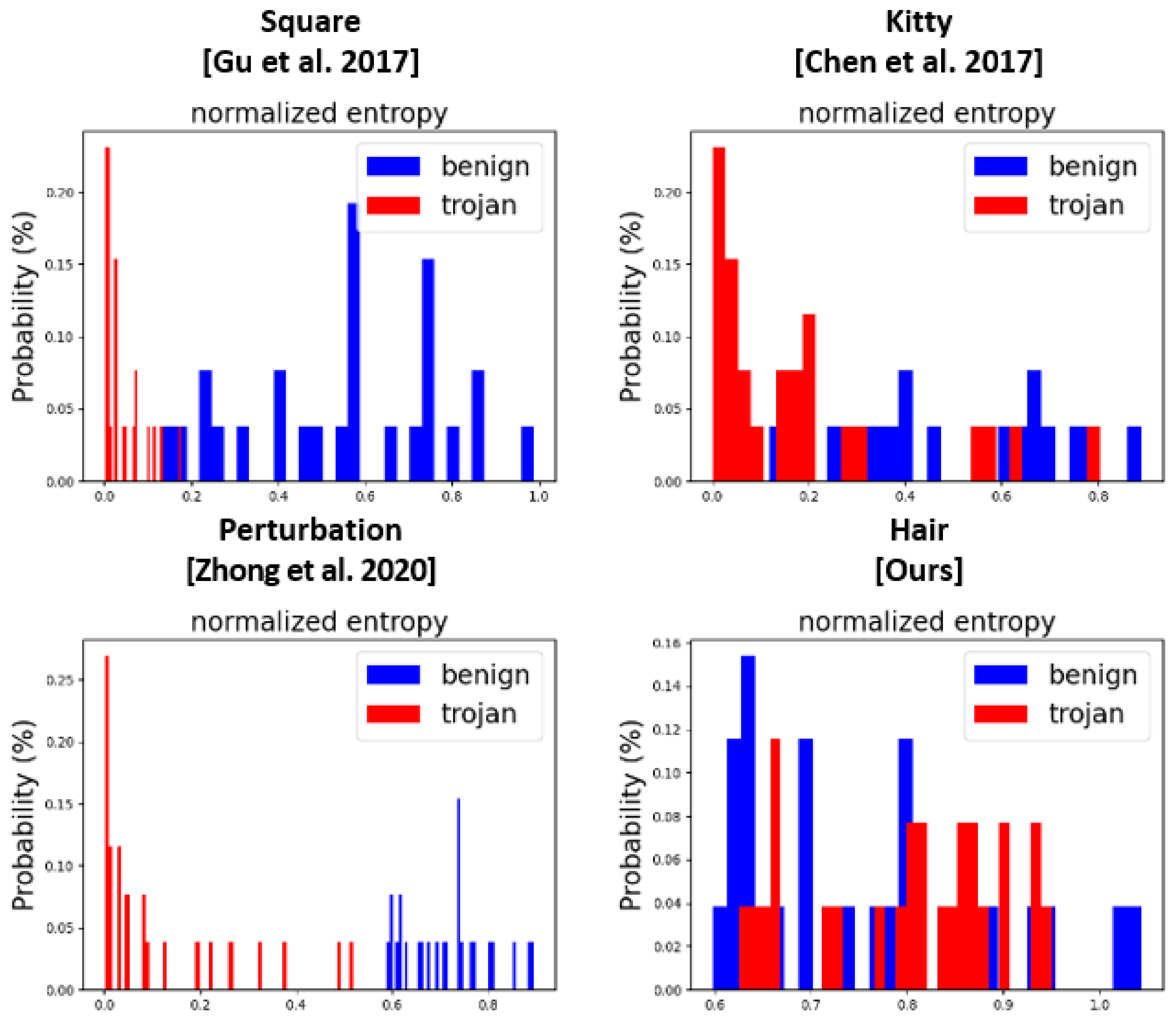
- Analysis of resistance against prior backdoor defense methods. We examined certain limitations regarding the state-of-the-art defense methods through several analyses. We discussed the limitations of each defense method, e.g., the reverse-engineered trigger, neural pruning, the class activation map, or the clustering-based approach, and explained the necessity of a more robust defense technique. With the proposed method in mind, we initially discussed the limitation of the class activation map-based defense: the activation region of the backdoored model is located in the facial region upon utilizing Grad-CAM++ [20]. Furthermore, reverse-engineering triggers is challenging owing to the large trigger size and the dynamic location. As the trigger is in the facial region, we conclude that our method can evade STRIP [21], which is an entropy-based detection technique.
2. Background and Related Work
2.1. Backdoor Attack
2.2. Properties of Backdoor Trigger
2.2.1. Unnoticeable Trigger
2.2.2. Dynamic Trigger
2.2.3. Natural Trigger
2.3. Defense against Backdoor Attack
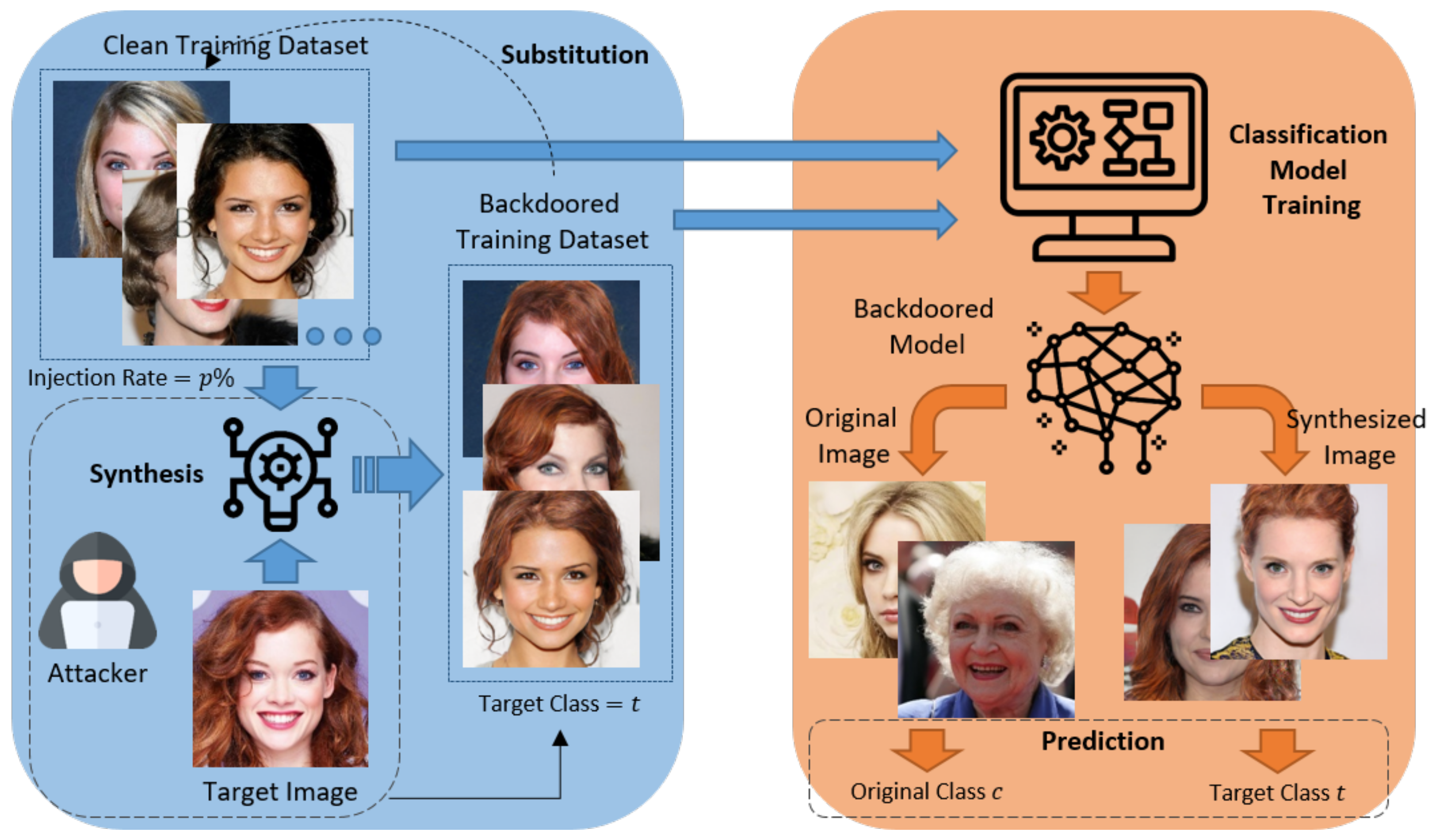
3. Image-Synthesis-Based Backdoor Attack
3.1. Attack Overview
3.1.1. Attack Formulation
3.1.2. Capabilities of the Attacker
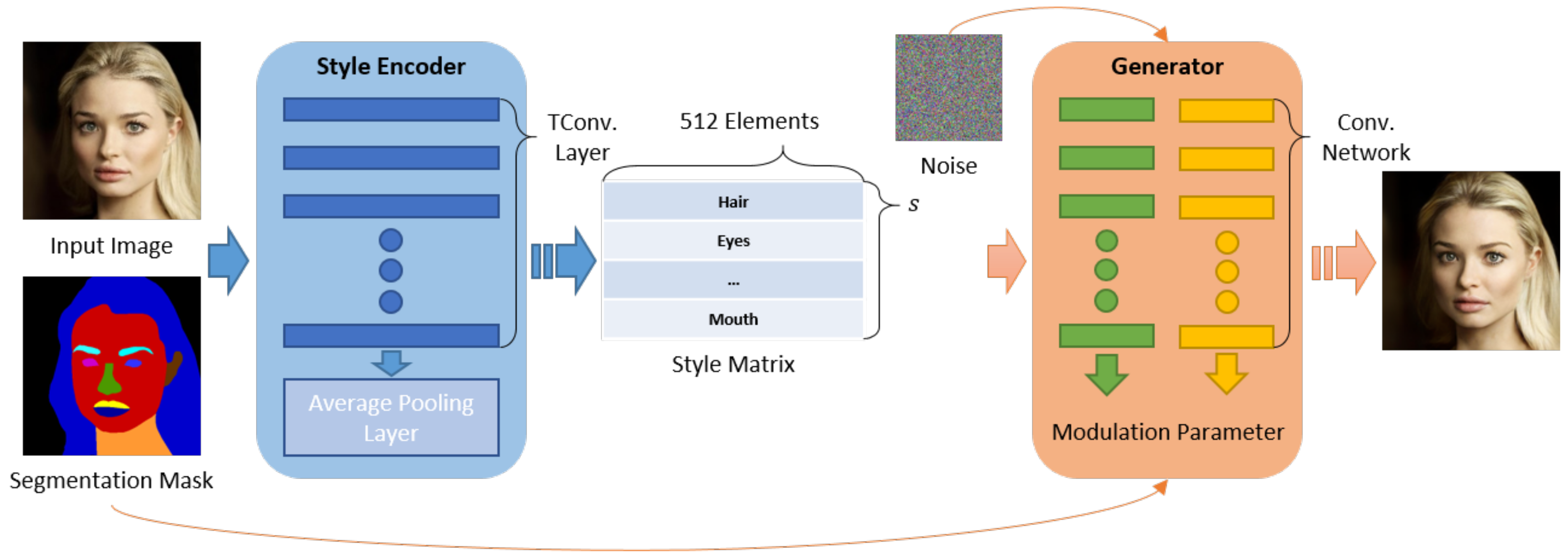
3.2. Image Synthesis Method
4. Experiments
4.1. Setup
4.1.1. Dataset and Target Model
4.1.2. Settings of Proposed Method
4.1.3. Baseline Attack Methods
4.2. Effectiveness of Backdoor Attacks
4.2.1. Results of Proposed Method
4.2.2. Comparison with Baseline Attack Methods
5. Robustness of Proposed Approach
5.1. Robustness against Image Transformation
5.2. Unnoticeability via Human Test
5.3. Visualization of Activation Map
6. Resistance to Prior Backdoor Defense Methods
6.1. Reverse-Engineered Trigger-Based Defense Method
6.2. Entropy-Based Defense
6.3. XAI-Based Defense
6.4. Clustering for Activation-Value-Based Defense
7. Clean-Label Attack Scenario
7.1. Experimental Setup
7.2. Experimental Results
8. Discussion and Future Work
8.1. Feasibility of Proposed Approach in Physical World
8.2. Robustness to Natural Misbehavior Scenario
8.3. Restriction of Dataset for Classification Task
8.4. Limitations of Image Synthesis Method
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. The German traffic sign recognition benchmark: A multi-class classification competition. In Proceedings of the 2011 International Joint Conference on Neural Networks, IEEE, San Jose, CA, USA, 31 July–5 August 2011; pp. 1453–1460. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition, IEEE, Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, IEEE, San Jose, CA, USA, 22–24 May 2017; pp. 39–57. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv 2017, arXiv:1708.06733. [Google Scholar]
- Goldblum, M.; Tsipras, D.; Xie, C.; Chen, X.; Schwarzschild, A.; Song, D.; Mądry, A.; Li, B.; Goldstein, T. Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1563–1580. [Google Scholar] [CrossRef]
- Truong, L.; Jones, C.; Hutchinson, B.; August, A.; Praggastis, B.; Jasper, R.; Nichols, N.; Tuor, A. Systematic evaluation of backdoor data poisoning attacks on image classifiers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 788–789. [Google Scholar]
- Zhong, H.; Liao, C.; Squicciarini, A.C.; Zhu, S.; Miller, D. Backdoor embedding in convolutional neural network models via invisible perturbation. In Proceedings of the Tenth ACM Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 16–18 March 2020; pp. 97–108. [Google Scholar]
- Chen, X.; Liu, C.; Li, B.; Lu, K.; Song, D. Targeted backdoor attacks on deep learning systems using data poisoning. arXiv 2017, arXiv:1712.05526. [Google Scholar]
- Liu, Y.; Ma, X.; Bailey, J.; Lu, F. Reflection backdoor: A natural backdoor attack on deep neural networks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 182–199. [Google Scholar]
- Lee, C.H.; Liu, Z.; Wu, L.; Luo, P. Maskgan: Towards diverse and interactive facial image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5549–5558. [Google Scholar]
- Barni, M.; Kallas, K.; Tondi, B. A new backdoor attack in cnns by training set corruption without label poisoning. In Proceedings of the 2019 IEEE International Conference on Image Processing, IEEE, Taipei, China, 22–25 September 2019; pp. 101–105. [Google Scholar]
- Li, Y.; Zhai, T.; Wu, B.; Jiang, Y.; Li, Z.; Xia, S. Rethinking the trigger of backdoor attack. arXiv 2020, arXiv:2004.04692. [Google Scholar]
- Nguyen, A.; Tran, A. WaNet–Imperceptible Warping-based Backdoor Attack. arXiv 2021, arXiv:2102.10369. [Google Scholar]
- Wenger, E.; Passananti, J.; Bhagoji, A.N.; Yao, Y.; Zheng, H.; Zhao, B.Y. Backdoor attacks against deep learning systems in the physical world. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6206–6215. [Google Scholar]
- Xue, M.; He, C.; Wang, J.; Liu, W. Backdoors hidden in facial features: A novel invisible backdoor attack against face recognition systems. Peer-Peer Netw. Appl. 2021, 14, 1458–1474. [Google Scholar] [CrossRef]
- Xue, M.; He, C.; Wu, Y.; Sun, S.; Zhang, Y.; Wang, J.; Liu, W. PTB: Robust physical backdoor attacks against deep neural networks in real world. Comput. Secur. 2022, 118, 102726. [Google Scholar] [CrossRef]
- Zhu, P.; Abdal, R.; Qin, Y.; Wonka, P. Sean: Image synthesis with semantic region-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5104–5113. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, IEEE, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar]
- Gao, Y.; Xu, C.; Wang, D.; Chen, S.; Ranasinghe, D.C.; Nepal, S. Strip: A defence against trojan attacks on deep neural networks. In Proceedings of the 35th Annual Computer Security Applications Conference, San Juan, PR, USA, 9–13 December 2019; pp. 113–125. [Google Scholar]
- Shafahi, A.; Huang, W.R.; Najibi, M.; Suciu, O.; Studer, C.; Dumitras, T.; Goldstein, T. Poison frogs! Targeted clean-label poisoning attacks on neural networks. Adv. Neural Inf. Process. Syst. 2018, 31, 6106–6116. [Google Scholar]
- Zhang, J.; Chen, D.; Liao, J.; Huang, Q.; Hua, G.; Zhang, W.; Yu, N. Poison Ink: Robust and Invisible Backdoor Attack. arXiv 2021, arXiv:2108.02488. [Google Scholar] [CrossRef]
- Li, Y.; Li, Y.; Wu, B.; Li, L.; He, R.; Lyu, S. Invisible Backdoor Attack with Sample-Specific Triggers. arXiv 2020, arXiv:2012.03816. [Google Scholar]
- Xue, M.; Ni, S.; Wu, Y.; Zhang, Y.; Wang, J.; Liu, W. Imperceptible and multi-channel backdoor attack against deep neural networks. arXiv 2022, arXiv:2201.13164. [Google Scholar]
- Jiang, W.; Li, H.; Xu, G.; Zhang, T. Color Backdoor: A Robust Poisoning Attack in Color Space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 8133–8142. [Google Scholar]
- Sarkar, E.; Benkraouda, H.; Maniatakos, M. FaceHack: Triggering backdoored facial recognition systems using facial characteristics. arXiv 2020, arXiv:2006.11623. [Google Scholar]
- Chou, E.; Tramer, F.; Pellegrino, G. Sentinet: Detecting localized universal attacks against deep learning systems. In Proceedings of the 2020 IEEE Security and Privacy Workshops, IEEE, San Francisco, CA, USA, 21 May 2020; pp. 48–54. [Google Scholar]
- Chen, B.; Carvalho, W.; Baracaldo, N.; Ludwig, H.; Edwards, B.; Lee, T.; Molloy, I.; Srivastava, B. Detecting backdoor attacks on deep neural networks by activation clustering. arXiv 2018, arXiv:1811.03728. [Google Scholar]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In Proceedings of the 2019 IEEE Symposium on Security and Privacy. IEEE, San Francisco, CA, USA, 19–23 May 2019; pp. 707–723. [Google Scholar]
- Huang, X.; Alzantot, M.; Srivastava, M. Neuroninspect: Detecting backdoors in neural networks via output explanations. arXiv 2019, arXiv:1911.07399. [Google Scholar]
- Liu, Y.; Lee, W.C.; Tao, G.; Ma, S.; Aafer, Y.; Zhang, X. Abs: Scanning neural networks for back-doors by artificial brain stimulation. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 1265–1282. [Google Scholar]
- Veldanda, A.K.; Liu, K.; Tan, B.; Krishnamurthy, P.; Khorrami, F.; Karri, R.; Dolan-Gavitt, B.; Garg, S. NNoculation: Broad spectrum and targeted treatment of backdoored DNNs. arXiv 2020, arXiv:2002.08313. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Wang, B.; Cao, X.; Jia, J.; Gong, N.Z. On certifying robustness against backdoor attacks via randomized smoothing. arXiv 2020, arXiv:2002.11750. [Google Scholar]
- Zeng, Y.; Qiu, H.; Guo, S.; Zhang, T.; Qiu, M.; Thuraisingham, B. Deepsweep: An evaluation framework for mitigating dnn backdoor attacks using data augmentation. arXiv 2020, arXiv:2012.07006. [Google Scholar]
- Xiang, Z.; Miller, D.J.; Kesidis, G. L-RED: Efficient Post-Training Detection of Imperceptible Backdoor Attacks without Access to the Training Set. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE, Toronto, ON, Canada, 6–11 June 2021; pp. 3745–3749. [Google Scholar]
- Li, Y.; Hua, J.; Wang, H.; Chen, C.; Liu, Y. Deeppayload: Black-box backdoor attack on deep learning models through neural payload injection. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering, IEEE, Madrid, Spain, 22–30 May 2021; pp. 263–274. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2337–2346. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, IEEE, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I-I. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Tang, D.; Wang, X.; Tang, H.; Zhang, K. Demon in the Variant: Statistical Analysis of DNNs for Robust Backdoor Contamination Detection. In Proceedings of the 30th USENIX Security Symposium, Vancouver, BC, Canada, 11–13 August 2021; pp. 1541–1558. [Google Scholar]
- Kumar, R.S.S.; Nyström, M.; Lambert, J.; Marshall, A.; Goertzel, M.; Comissoneru, A.; Swann, M.; Xia, S. Adversarial machine learning-industry perspectives. In Proceedings of the 2020 IEEE Security and Privacy Workshops, IEEE, San Francisco, CA, USA, 21 May 2020; pp. 69–75. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | [6] | [8] | [15] | [11] | [9] | [23] |
|---|---|---|---|---|---|---|
| Dynamic | X | X | X | O | X | O |
| Unnoticeable | X | X | O | O | O | O |
| Natural | X | X | X | X | X | X |
| Property | [24] | [16] | [18] | [27] | [17] | ours |
| Dynamic | O | X | X | O | O | O |
| Unnoticeable | O | O | O | O | O | O |
| Natural | X | O | O | O | O | O |
| FC | Hor | SSR | MoB | RBr | RGM | Acc |
|---|---|---|---|---|---|---|
| X | X | X | X | X | X | 69% |
| O | X | X | X | X | 87% | |
| O | O | X | X | X | 91% | |
| O | O | O | X | X | 90% | |
| O | O | O | O | X | 92% | |
| O | O | O | O | O | 94% | |
| O | O | O | O | O | O | 94% |
| Hair 1 | MA | ASR | Hair 2 | MA | ASR | Eyes 1 | MA | ASR | Eyes 2 | MA | ASR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Base | 94.40 | - | Base | 94.40 | - | Base | 94.40 | - | Base | 94.40 | - |
| 5% | 91.54 | 55.49 | 5% | 91.10 | 47.11 | 5% | 91.78 | 21.22 | 5% | 92.20 | 27.25 |
| 10% | 91.32 | 75.60 | 10% | 90.88 | 63.30 | 10% | 90.22 | 36.18 | 10% | 91.76 | 42.21 |
| 15% | 90.86 | 85.01 | 15% | 90.00 | 69.02 | 15% | 90.02 | 48.66 | 15% | 89.56 | 57.01 |
| 20% | 90.22 | 88.27 | 20% | 90.66 | 75.96 | 20% | 90.68 | 55.61 | 20% | 90.22 | 62.55 |
| Mouth 1 | MA | ASR | Mouth 2 | MA | ASR | Mix 1 | MA | ASR | Mix 2 | MA | ASR |
| Base | 94.40 | - | Base | 94.40 | - | Base | 94.40 | - | Base | 94.40 | - |
| 5% | 91.54 | 26.06 | 5% | 92.66 | 41.28 | 5% | 92.64 | 65.76 | 5% | 91.76 | 57.73 |
| 10% | 91.12 | 52.41 | 10% | 91.76 | 60.46 | 10% | 91.32 | 78.93 | 10% | 91.98 | 68.94 |
| 15% | 88.68 | 60.96 | 15% | 90.22 | 70.27 | 15% | 91.10 | 85.28 | 15% | 90.90 | 87.78 |
| 20% | 90.00 | 74.90 | 20% | 89.78 | 87.11 | 20% | 90.00 | 88.37 | 20% | 90.22 | 88.20 |
| Backdoor Trigger ⯈ | Square | Kitty | Sunglasses | SINE | Warping | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Injection Rate ⯆ | MA | ASR | MA | ASR | MA | ASR | MA | ASR | MA | ASR |
| 5% | 91.10 | 25.10 | 92.20 | 75.83 | 92.64 | 66.26 | 91.10 | 36.00 | 90.66 | 22.17 |
| 10% | 90.90 | 31.67 | 94.68 | 86.99 | 92.46 | 78.01 | 87.32 | 58.64 | 90.66 | 34.91 |
| 15% | 88.24 | 66.54 | 91.54 | 92.95 | 93.78 | 85.01 | 93.12 | 86.14 | 88.46 | 47.87 |
| 20% | 91.32 | 87.80 | 91.78 | 94.05 | 92.42 | 89.41 | 91.10 | 92.60 | 86.46 | 51.51 |
| Backdoor Trigger ⯈ | ReFool | Perturbation | Hair 1 | Mouth 2 | Mix 1 | |||||
| Injection Rate ⯆ | MA | ASR | MA | ASR | MA | ASR | MA | ASR | MA | ASR |
| 5% | 93.98 | 64.19 | 91.98 | 46.91 | 91.54 | 55.49 | 92.66 | 41.28 | 92.64 | 65.76 |
| 10% | 92.42 | 75.78 | 92.20 | 81.96 | 91.32 | 75.60 | 91.76 | 60.46 | 91.32 | 78.93 |
| 15% | 91.12 | 83.03 | 91.32 | 64.12 | 90.86 | 85.01 | 90.22 | 70.27 | 91.10 | 85.28 |
| 20% | 91.78 | 90.21 | 92.90 | 88.46 | 90.22 | 88.27 | 89.78 | 87.11 | 90.00 | 88.37 |
| Square | Perturbation | SINE | Kitty | Warping | Sunglasses | ReFool | Hair | Mix | |
|---|---|---|---|---|---|---|---|---|---|
| Property | Static | Static | Static | Static | Static | Dynamic | Dynamic | Dynamic | Dynamic |
| Benign Attack Success Rate | 87.80 | 88.46 | 92.60 | 94.05 | 51.51 | 90.80 | 90.21 | 88.27 | 88.37 |
| Hor | +0.41 | - | - | −1.42 | +1.55 | −2.29 | −6.68 | −3.53 | +1.99 |
| SSR | −37.21 | −20.13 | −18.57 | −13.86 | −29.89 | −8.27 | −7.82 | −5.41 | −7.84 |
| GaB | −23.26 | −77.51 | −0.18 | −3.95 | −25.17 | -3.37 | +1.96 | +0.06 | −1.55 |
| Backdoor Trigger | Square | Perturbation | SINE | Kitty |
|---|---|---|---|---|
| Fooling Rate | 18.33 | 1.67 | 3.67 | 3.33 |
| Backdoor Trigger | Warping | Sunglasses | ReFool | Synthesis |
| Fooling Rate | 35.67 | 1.33 | 5.33 | 31.67 |
| Backdoor Trigger ⯈ | Hair 1 | Eyes 2 | Mouth 2 | Mix 1 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Target Model | Input Size | Injection Rate (Target Classes/Total Classes) | MA | ASR | MA | ASR | MA | ASR | MA | ASR |
| Inception-v3 | Base | 97.80 | - | 97.80 | - | 97.80 | - | 97.80 | - | |
| 20%/4.7% | 93.54 | 47.68 | 92.44 | 22.01 | 92.68 | 25.97 | 94.42 | 54.13 | ||
| 40%/8.2% | 92.68 | 62.87 | 93.80 | 30.05 | 92.00 | 46.17 | 92.44 | 73.47 | ||
| 60%/11.8% | 90.44 | 76.52 | 91.98 | 30.73 | 92.02 | 51.55 | 89.34 | 84.00 | ||
| 80%/16.5% | 88.22 | 86.95 | 90.02 | 55.44 | 89.12 | 69.23 | 89.56 | 90.32 | ||
| 100%/20.0% | 85.54 | 94.75 | 89.12 | 62.47 | 89.10 | 79.99 | 85.32 | 94.36 | ||
| ResNet-18 | Base | 96.70 | - | 96.70 | - | 96.70 | - | 96.70 | - | |
| 20%/4.7% | 95.10 | 25.03 | 96.02 | 4.84 | 96.02 | 10.30 | 96.24 | 26.35 | ||
| 40%/8.2% | 95.08 | 31.89 | 95.56 | 5.90 | 96.22 | 9.64 | 95.08 | 33.54 | ||
| 60%/11.8% | 94.90 | 40.72 | 95.32 | 7.84 | 95.56 | 16.46 | 94.68 | 52.76 | ||
| 80%/16.5% | 92.88 | 59.64 | 94.20 | 12.09 | 92.46 | 18.40 | 92.66 | 63.73 | ||
| 100%/20.0% | 91.78 | 68.53 | 94.62 | 10.40 | 93.10 | 25.97 | 89.56 | 67.80 | ||
| VGG-16 | Base | 95.60 | - | 95.60 | - | 95.60 | - | 95.60 | - | |
| 20%/4.7% | 95.14 | 37.12 | 92.88 | 8.38 | 94.46 | 14.83 | 94.90 | 38.17 | ||
| 40%/8.2% | 92.90 | 41.63 | 93.54 | 9.93 | 94.64 | 15.60 | 94.24 | 49.59 | ||
| 60%/11.8% | 92.88 | 48.57 | 93.78 | 9.76 | 93.10 | 16.97 | 93.58 | 52.86 | ||
| 80%/16.5% | 89.76 | 53.50 | 91.56 | 11.65 | 91.14 | 22.98 | 89.34 | 60.68 | ||
| 100%/20.0% | 85.34 | 64.56 | 88.88 | 14.41 | 86.66 | 27.73 | 82.00 | 70.00 | ||
| DenseNet-121 | Base | 98.90 | - | 98.90 | - | 98.90 | - | 98.90 | - | |
| 20%/4.7% | 98.46 | 42.29 | 97.58 | 13.39 | 98.24 | 16.29 | 98.24 | 48.38 | ||
| 40%/8.2% | 97.36 | 60.62 | 97.58 | 23.18 | 98.02 | 23.18 | 97.58 | 65.99 | ||
| 60%/11.8% | 96.24 | 73.36 | 96.90 | 27.84 | 96.66 | 40.56 | 96.00 | 75.22 | ||
| 80%/16.5% | 93.80 | 81.38 | 96.00 | 40.48 | 94.68 | 46.13 | 92.92 | 85.14 | ||
| 100%/20.0% | 89.76 | 92.30 | 94.02 | 45.77 | 93.80 | 65.94 | 88.88 | 93.05 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Na, H.; Choi, D. Image-Synthesis-Based Backdoor Attack Approach for Face Classification Task. Electronics 2023, 12, 4535. https://doi.org/10.3390/electronics12214535
Na H, Choi D. Image-Synthesis-Based Backdoor Attack Approach for Face Classification Task. Electronics. 2023; 12(21):4535. https://doi.org/10.3390/electronics12214535
Chicago/Turabian StyleNa, Hyunsik, and Daeseon Choi. 2023. "Image-Synthesis-Based Backdoor Attack Approach for Face Classification Task" Electronics 12, no. 21: 4535. https://doi.org/10.3390/electronics12214535
APA StyleNa, H., & Choi, D. (2023). Image-Synthesis-Based Backdoor Attack Approach for Face Classification Task. Electronics, 12(21), 4535. https://doi.org/10.3390/electronics12214535