Abstract
With the rapid development of online social networks recently, more and more online users have participated in social network activities and rich social relationships are formed accordingly. These social relationships provide a rich data source and research basis for in-depth study on recommender systems (RSs), while also promoting the development of RSs based on social networks. To solve the problems of cold start and sparsity in RSs, many recommendation algorithms are constantly being proposed. Motivated by the availability of rich social connections in today’s RSs, a large number of recommendation techniques based on social relationships have been proposed recently, achieving good recommendation results, and have become the mainstream research direction in the field of RSs, attracting more and more researchers to engage in this research. In this study, we mainly review and summarize the social relationship-based recommendation methods and techniques in RSs, and study some recent deep social relationship recommendation methods and techniques based on deep learning (DL), including the latest social matrix factorization (MF)-based recommendation methods and graph neural network (GNN)-based recommendation methods. Finally, we discuss the potential impact that may improve the RS and future direction. In this article, we aim to introduce the recent recommendation techniques integrating social relationships to solve data sparsity and cold start, and provide a new perspective for improving the performance of RSs, thereby providing useful resources in the state-of-the-art research results for future researchers.
1. Introduction
As a major filtering tool to solve information overload, RSs can quickly and accurately provide users with items that they may be interested in, greatly reducing their time consumption. They are widely used in fields such as e-commerce, news, education, and online video, bringing great convenience to people’s work and life.
Despite the tremendous success of RSs, a major challenge that still exists is issues of data sparsity and cold start. Faced with extremely sparse data, RSs find it difficult to effectively learn user preferences and therefore cannot effectively recommend items to users. Cold start is an extreme case of sparse data, where new users have little or no feedback on the item, and RSs are unable to learn the users’ true preferences and effectively recommend the items. This has become a major issue in the field of RSs, and many algorithms have been proposed for this purpose, such as collaborative filtering (CF), MF, content-based recommendation, and hybrid recommendation [1,2,3,4].
Traditional recommendation models are usually based on a single factor, such as user rating or user behavior, which often result in inaccurate recommendations due to sparse data or cold start [4,5,6]. Recently, recommendation based on social relationships has become an important development direction in the field of RSs [7]. This is because social relationships not only alleviate the problem of data sparsity, but also can greatly improve recommendation quality by introducing recommendation models as an important factor affecting user behavior. For example, memory-based recommendation methods can predict ratings by balancing the similarity and user trust obtained from ratings, resulting in recommendations [8]. Social MF-based methods integrate trust and friend relationships into matrix decomposition process for recommendations [9,10,11]. DL-based recommendations use social relationships, user features and item features as embedding layers to establish a deep neural network model for prediction and achieve recommendations [12,13,14,15,16,17,18,19,20,21,22].
In this article, we conduct a comprehensive literature survey on social relationship-based RSs, and aim to help researchers understand the development of RSs based on social relationships and the characteristics of various recommendation algorithms, and understand how to solve problems of data sparsity and cold start using social relationships in RSs, providing research ideas for future research work. In this work, we make the following contributions:
- We outline traditional techniques and modern approaches used to alleviate data sparsity and cold start issues.
- When there is a lack of user rating information, we focus on how to use social relationships to create recommendation models based on social relationships.
- We summarize various recommendation methods for integrating social relationships, including MF, factorization machine (FM), DL, and GNN.
The remainder of this survey is organized as follows: in Section 2 we conduct a literature review. Section 3 provides an basic framework of a social relationship-based RS and the formal definition of a social relationship-based RS. Section 4 discusses the recommendation technology based on social relationships. Section 5 discusses the future research directions. Section 6 provides a discussion. Section 7 concludes this survey article.
2. Literature Review
In this section, we provide a brief historical overview of social relationship-based RSs, including the key milestones and developments, and related technological development on social relationship-based RSs. In addition, we compare this article with other surveys, and introduce our survey method in this article.
2.1. The Overview of Social Relationship-Based RSs
The recommendation algorithm was first proposed by Xerox’s Paraoto Research Center in 1992, which is an RS based on CF algorithms for spam filtering. In 2003, Amazon truly applied recommendation algorithms to the commercial field. Netflix proposed MF technology in 2006, effectively solving the above problems. MF has a strong generalization ability, but it requires a large amount of computation and is not suitable for dealing with large-scale sparse matrices. In 2007, a trust-aware CF recommendation algorithm was proposed, which is a memory-based CF recommendation algorithm that integrates the user’s trust propagation mechanism into the CF recommendation algorithm [23]. In 2009, a probability factor factorization model was proposed, which fuses user interests with the preferences of trusted friends. Osaka University proposed the FM model in 2010, which can capture second-order features well, and has some mathematical skills. The algorithm has a relatively low time complexity. After 2012, FM gradually became the mainstream algorithm in the recommendation field, until gradient boosting decision tree was applied in the recommendation field [24,25]. In 2019, a new GNN framework for social recommendation was proposed to jointly capture interactions and opinions in user–item graphs, which consistently models two graphs and heterogeneous strengths [26]. The key milestones and developments of social relationship-based RSs is shown in Figure 1. Figure 1 shows representative social relationship-based recommendation techniques from different periods and which publication or conference they were published in. These recommendation techniques are arranged in chronological order.

Figure 1.
The key milestones and developments of social relationship-based RSs.
2.2. Related Technological Development and Related Surveys
To solve the problems of data sparsity and cold start in RSs, a series of recommendation algorithms have been proposed, and the development of RSs has gone through stages such as CF-based RSs, Content-based RSs, Hybrid RSs, and Social relationship-based RSs [6,7,8,9]. Due to the ability of social relationships to alleviate issues of data sparsity and cold start, recommendation based on social relationships dominates. According to the adopted technology, RSs can be divided into following categories [10,11,23].
(1) Recommendation technology based on social MF. Traditional recommendation algorithms suffer from severe impact on recommendation quality due to data sparsity and inconsistency between their assumption of mutual independence among users and the actual situation. With the development of social networks and the introduction of social relationships into MF models, social MF recommendation methods have emerged since 2008. Jamali et al. [27] propose a social network recommendation model based on trust propagation by establishing trust relationships between users and constraining their feature vectors. Ma et al. [28] propose a typical representative of the weighted ensemble method, which considers both the user’s direct predictive ratings of the item and the user’s trusted friend’s ratings of the items. Chen et al. [29] analyze the impact of user cognitive behavior on user preferences from the perspective of social relationship context, and propose an enhanced social recommendation method based on a social relationship context by establishing a social factor enhancement model, namely EnSocialMF. Yang [30] obtained implicit user similarity through explicit user ratings and trust relationships to approximate more accurate user features, thereby improving recommendation accuracy. This method improves prediction accuracy to a certain extent, but does not take into account the negative impact of extremely sparse user trust relationships on user social relationships, as well as the positive impacts of the implicit evaluation of user–item (such as social tags) relationships and the approximate relationship estimation of item–item relationships on recommendation quality.
(2) Recommendation technology based on FM. Although MF can fuse user implicit feedback into the social MF model, which can alleviate the problem of data sparsity to some extent and improve recommendation accuracy, it is difficult to integrate user statistical information (age, gender, region, income, etc.), and its scalability and interpretability are insufficient, limiting its generalization ability to a certain extent. FM can integrate more dimensional features well, resulting in a stronger generalization ability of the learned model. Rendle [24] proposes a new classification and prediction method, which has good prediction performance in sparse data and linear time complexity. Huang [25] proposes feature–over-field interaction FM (FIFM) by fusing feature vectors and class vectors, and pairing the fused vectors to obtain richer interactive semantic information. Starting from the perspective of feature interaction, category interaction, and the interaction between feature-class interaction factor decomposers in sparse scenario prediction in feature-class RSs, FIFM comprehensively obtains various types of interactive information in sparse scenarios, further improving prediction performance. Yan et al. [31] summarize the methods, strategies, and key technologies of the model in terms of width expansion, and compare and analyze the integration methods and characteristics of the FM model with other models, especially the integration with DL models, providing ideas for the deep expansion of traditional models.
(3) Recommendation technology based on DL. FM has good training results and fast training speed when the data are sparse, but its ability to cross-feature is limited, which will limit the mining of deeper data patterns. DL technology can automatically learn and extract data features, and can process large-scale data. Its huge success in computer vision and image processing inevitably affects recommendation systems. Since 2015, recommendation systems based on DL have emerged. In 2016, Google proposed the Wide&Deep [32], marking the beginning of the large-scale application of DL in the field of ctr prediction. The Wide&Deep model is a hybrid model composed of single-layer Wide parts and multi-layer Deep parts. The model can quickly process and remember a large number of historical behavioral features, and has strong expressive ability. It not only quickly became the mainstream model in the industry at that time, Moreover, a large number of hybrid models based on the Wide&Deep model have been derived, and their influence has continued to this day. In 2017, the Huawei Ruoya Ark team proposed a DeepFM [32] model that effectively combines FM with a deep-learning neural network (DNN). It mainly draws on the ideas of Google’s Wide&Deep paper and makes appropriate improvements, replacing the wide part (logistic regression) with FM and DNN for feature intersection. The Wide and Deep parts share the original input feature vectors, which allows DeepFM to directly learn the intersection of low- and high-order features from the original features. In 2017, researchers from the National University of Singapore proposed the NeuralCF [33] model based on DL. NeuralCF is based on two embedding layers, user vector and item vector, and utilizes different interoperability layers for feature cross combination. It can flexibly concatenate different interoperability layers, reducing the complexity of the model.
(4) Recommendation technology based on GNN. The ability of DL to extract complex patterns at the bottom of data is widely recognized. However, it is difficult to learn from graphs that are commonly present in the real world. The graph convolutional network (GCN) [34] is a DL model for graph signals, which has been widely used due to its powerful feature representation ability. In the field of RSs, users and items can be viewed as graph vertices, user ratings of products can be viewed as edges (links), and user and item features can be viewed as signals distributed on the vertex set (graph). This transforms the recommendation problem into a graph link prediction problem. Graph convolutional neural networks have shown more powerful capabilities in learning graph structured data. Due to its superior performance in graph learning, GNN is widely used in RSs. In addition, it has also been applied to many fields, such as text classification, natural language processing, disease prediction, feature relationship extraction, etc. Fan et al. [26] propose a new GNN framework, namely GraphRec, for social recommendation. In particular, a principled method for jointly capturing interactions and opinions in user–item graphs is proposed, which consistently models the strength of two graphs and heterogeneity. Wu et al. [35] propose a deep impact propagation model to simulate how users are influenced by the recursive social diffusion process of social recommendations. For each user, the diffusion process starts with the initial embedding of relevant features and the free user potential vector that captures potential behavioral preferences.
2.3. Recommendation Based on Social Relationships
In real life, people prefer to obtain information or listen to suggestions from users such as friends with similar interests and preferences or friends they trust. Social relationship-based recommendations can generally be divided into friendship-based recommendations and trust relationship-based recommendations.
2.3.1. Friendship-Based Recommendation
Friendship-based recommendations mainly utilize interpersonal relationships on social networks to obtain the strength of friend relationships, namely friendship strength, by discovering potential indirect relationships between users through direct connections or interactions between users and items. Generally, users with strong connections have a greater impact than those with weak connections, which is very useful for improving recommendation quality. The main method is to calculate friendship strength through various implicit data, which is different from the similarity measurement based on rating in CF. For example, Seo et al. [36] propose a personalized RS based on friendship strength by calculating the closeness between users in social networks. Ma [33] proposes a social RS based on social friend interest similarities, and verifies its effectiveness on the Douban dataset and Epinins dataset.
2.3.2. Trust-Based Recommendation
The trust relationship between users is an important social relationship, which is a measure of credibility made by users based on their surrounding environment and historical interaction experience, reflecting to some extent the degree of correlation between users’ interests and preferences. In general, users are likely to be willing to listen to the suggestions of trusted users. The recommendation algorithm based on trust relationships can improve the effectiveness of recommendations to some extent by modeling the impact of user trust relationships on user behavior. Massa et al. propose a trust aware CF-based recommendation method, which comprehensively evaluates user similarity and trust values, and then make recommendations through CF technology. Yang et al. propose a social matrix recommendation method based on user trust relationships by analyzing the relationship between users’ trustors and trustees, mapping user features to a shared space based on user ratings and trust relationships. In addition, Moradi et al. [33] propose a reliability-based trust perception CF-based recommendation method, which utilizes reliability evaluation methods to evaluate the reliability of rating predictions to ensure the accuracy of recommendations.
2.4. Methodology
RSs have been developed since 1992, and there have been many surveys on RSs. In contrast, these surveys have focused on different types of RSs, such as a literature survey on CF-based recommendations [37], survey on MF-based RSs [38], and survey on DL-based recommendations [39]. In addition, there are also some RS surveys that investigate a specific application, such as literature reviews on CF-based RSs for mobile applications.
In this article, we provide a literature survey on RSs on social relationships, which does not appear in current publications on this topic. This article aims to help researchers understand the development of social relationship-based recommendation technology and the characteristics of various technologies, and understand how to integrate various social relationships into recommendation models to solve data sparsity and cold start problems in RSs.
The selection of relevant publications in social relationship-based RSs was conducted from the Science Direct Electronic Journal Full Text Database and Springer electronic Journal database by using the keywords “social recommendation” and “recommender systems”. Moreover, our survey of the literature also included the latest popular social recommendation methods based on GNN. We collected these publications from famous journals and conferences such as SIGIR, RecSys, WWW, KDD, WSDM, IJCAI, CIKM, and DLRS. This process resulted in a selection of 85 articles from 2007 to 2023 for our literature review. These two major journal databases and important conferences have covered most of the high-quality papers in the field of RSs. The articles we selected are mainly SCI papers and important conference papers. We selected articles based on their JCR partition, publication year, and keyword, and the criteria for inclusion of studies are shown in Table 1. Furthermore, we have reviewed related articles in the area of social relationship-based RSs in detail in Section 2.2, and provided details of representative recommendation technology based on social relationships in Section 4.

Table 1.
The criteria for the inclusion of studies.
3. The Basic Framework and the Formal Definition of Social Relationship-Based RSs
3.1. The Basic Framework of Social Relationship-Based RSs
In recent years, domestic and foreign researchers have conducted extensive research on RSs based on social networks and proposed many effective recommendation algorithms. Although these recommendation algorithms use different technologies, the recommendation framework models are all based on the structural characteristics of social networks, the popularity of items in social groups, and the impact of social relationship information between users on recommendation quality [6,8,23,40]. The basic framework of a social network RS is shown in Figure 2, which includes four steps [9,10,32,41]:
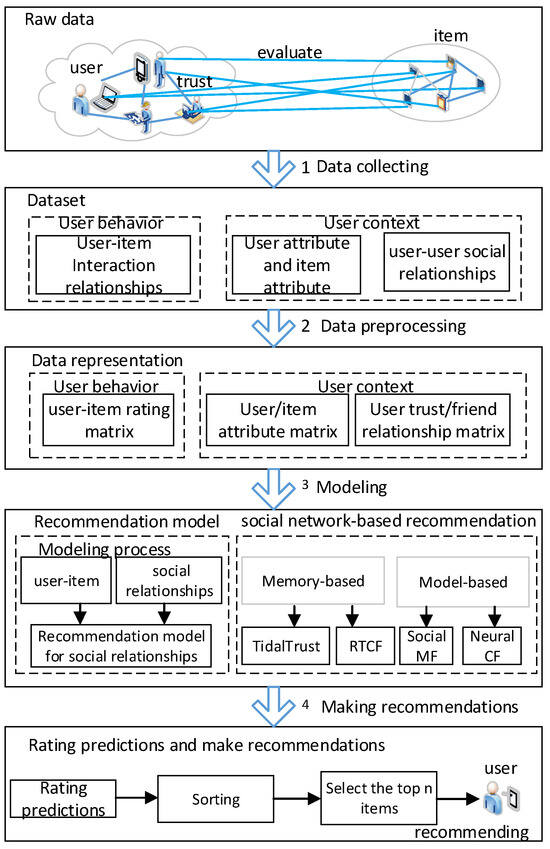
Figure 2.
The flow of a social relationship-based RS.
(1) Data collection: Attribute information of users and items is obtained, as well as interaction data between users and items (including explicit ratings and implicit interaction information such as clicks, purchases, and favorites), to form a dataset of user and item attributes, as well as a dataset of user–item relationships. At the same time, user social tags, social activity logs, and contextual information are analyzed to form a social relationship dataset.
(2) Data preprocessing: After collecting various user social relationship data, it is necessary to preprocess the data through denoising, dimensionality reduction, and pre-filling, and then input the processed information into the social recommendation model for learning and training to complete the recommendation task. For some pseudo-preference behavior data, correction strategies such as deletion and behavior compensation are used to ensure the reliability of input information [10,36]. For extremely sparse user–item rating matrices, it is necessary to pre-fill missing values using algorithms such as the mean and median [33,42]. For data without explicit ratings, it is necessary to quantify user ratings using user interaction information (such as the Tencent dataset) [34]. Using the user trust relationship dataset to construct a topological structure, sometimes it is necessary to evaluate the reliability of trust relationships and filter out untrusted relationships between users [6,10,43].
(3) The establishment of a recommendation model based on social networks: This is a key aspect of an RS based on social networks. Its main task is to analyze user preference behavior from two aspects: the user–item rating matrix and user social relationships, and consider selecting appropriate recommendation techniques to integrate the impact of user social relationships on recommendation results into the RS. Currently, commonly used recommendation techniques based on social relationships include MF, FM, DL, and GCN. TidalTrust [8] and Reliability-based Trust Perceived CF Recommendation Algorithm (RTCF) [44] are memory-based recommendation methods for social relationships, and MF-based models for recommendation in social networks (SocialMF) and role preferences for trust aware recommendation (RoRec) are MF-based recommendation methods [34,44,45,46].
Social network analysis is a very popular social science research method that studies social phenomena and structures from the perspective of social relationships. Its results are widely applied in recommendation systems based on social relationships, including the currently popular GNN-based RSs.
(4) Presentation and evaluation of recommendation results. The task at this stage is not only to use social recommendation models to predict missing items and recommend items that may be of interest to users based on the prediction results, but also to improve recommendation strategies and methods with the recommendation results based on implicit feedback from users. The evaluation indicators include recommendation accuracy, diversity, coverage, and the availability of RSs [30,42].
3.2. The Formal Definition for Social Relationship-Based RSs
At the 20th International Internet Conference in 2011, the concept of social relationship-based RSs was officially proposed: social network-based recommendation is a recommendation method that primarily processes social media data [47]. The data resources that RSs can utilize not only include user–item rating data that reflect user behavior, but also various user interaction data from social media, such as user clicks, favorites, purchases, shares, user trust relationships, and social tags.
According to the formal definition of traditional RSs, combined with the influencing factors of social relationships, RSs based on social networks can be formally described as follows [48]:
Definition 1.
An RS based on social networks [23,49]. An RS based on social networks can be represented by a five tuple, i.e., RS = (U, I, S, , R), where U, I, and S denotes the user set, item set, and the user social relationship matrix, respectively. Mapping relationship : U × I → R represents the evaluation utility function of recommendation results, and R is the recommended utility value, which is a set of non-negative real numbers within a certain range. N = |U|, M = |I|, Y = represents the total number of users who have social relationships with the user. The content of its research is described as follows: in a user group with known social relationships, based on the evaluation of all items in the user group, it actively recommends the item set I* that meets the user’s preference needs and has the highest utility, namely,
where , represents a bias variable, the larger its value, the more the attention the item has in the user community, and
represents a mapping. The formal description is based on the interaction between the user ux and the item i, as well as the interaction between the user uy and the item i to obtain the maximum utility value, thus recommending the corresponding items.
4. Recommendation Technology Based on Social Relationships
According to recommendation strategies, social relationship-based recommendation techniques are divided into memory-based social relationship recommendation methods and model-based social relationship recommendation methods [35,36,50].
4.1. Memory-Based Social Relationship Recommendation Technology
Memory-based social network recommendation, also known as heuristic social network recommendation, mainly combines traditional memory-based CF recommendation technology with social network information, establishes user weight relationships through user rating information and user social relationships, and predicts user preferences for items. Among them, TidalTrust and RTCF are the most representative algorithms.
(1) TidalTrust model [8,11]: This model introduces trust propagation theory into the process of measuring user trust relationships to predict unrated items. The trust relationship is expressed as follows:
Among them, represents the set of users that user directly trust, and represents the level of trust that user w by user u. The predicted rating of the item i by the user u can be obtained through the following formula:
Here, denotes the rating of user u on item i, and D denotes the maximum depth set of user trust relationships.
(2) Trust-aware-based recommendation algorithm (TAR) [11]: this algorithm proposes a weighted measure that combines rating similarity and user trust relationships:
where , Tuv represents the degree to which the user v is trusted by the user u.
(3) RTCF [44]: This method first estimates missing user trust relationships based on the trust propagation mechanism, then uses rating information and trust relationships to obtain weights between users, predicts user ratings, evaluates the reliability of the predicted ratings, and finally reconstructs the trust network for rating prediction. The weight calculation formula between two users is as follows:
Among them, represents the degree to which the user v is trusted by the user u, and represents the range of values for both is [0, 1].
4.2. Model-Based Social Relationship Recommendation Technology
Due to the excellent performance of MF models in RSs, many scholars incorporate social relationships into MF models and use MF technology to map user–item historical rating information and user social relationships to a shared user feature space. This enables the more accurate prediction of missing rating information through the obtained user potential feature matrix and item potential feature matrix [31,33,35,37,50]. For example, in order to improve the accuracy of recommendations, references [10,11,32,34,42,44] consider factors such as user trust, friend relationships, and the mutual influence of interest preferences in the modeling process to obtain accurate user and item features. Since Ma et al. proposed a social recommendation using probabilistic factor analysis (SoRec) in 2008, domestic and foreign scholars have successively proposed a series of recommendation models based on social networks [8,9,10,11,33,45,47,49,51,52,53,54].
4.2.1. MF Technology Based on Social Relationships for Recommendation
The MF recommendation method that integrates social relationships not only considers the preferences and interests of neighboring users on the item, but also considers the impact of users’ social network information (such as trust relationships, friend relationships, and colleague relationships) on user preferences and behaviors. It integrates various social network information into the optimization process of the matrix, learns user historical behavior and social association information, and optimizes the potential feature vectors of users to obtain more accurate prediction scores and improve recommendation quality. This recommendation method can be formalized as [11,51,55]
where describes the various social relationship network information of users, S is the user preference similarity matrix obtained based on user–item rating information, and C is the user social relationship matrix, which is a set of parameters learned from social networks. W is used to control the weight matrix of rating information in the model, Θ represents the Hadamard inner product of two matrices, is used to control the contribution of social information, λ denotes a regular term parameter, and represents the Frobenius norm.
According to the different methods of optimizing and solving latent feature vectors based on social network information, MF methods based on social networks can be divided into the following three categories [8,32]: the weighted integration, collaborative factorization, and regularization methods.
(1) Weighted integration method: The integration method is to use the linear superposition of user ratings with the same preferences and ratings with trusted users to predict unrated items. For example, the Recommended Social Trust Ensemble (RSTE) proposed in reference [28] is a typical representative of the weighted ensemble method, which considers both the user’s direct predictive rating of the item and the user’s trusted friend’s rating of the item. The conditional probability distribution of existing ratings is as follows:
where represents the set of friends trusted by user u, and represents the trust relationship between user u and his friend k. By comprehensively considering the rating information of user u and trusted friend k on item i, the final predicted rating of user u on item i is as follows:
Here, is used to control the current user’s rating of the item and the degree of influence of the rating of the item from their trusted friends.
Reference [56] combines trust propagation mechanisms with traditional user–item rating and trust relationships, and proposes a personalized recommendation model fusing trust relationship based on comprehensive evaluation (CETrust). This model weights the similarity of users’ ratings and trust relationships, and considers users with higher rating and trust values as close neighbors. The CETrust algorithm predicts users’ ratings for items as follows:
where represents the comprehensive trust degree between user u and user v in social networks.
Reference [57] utilizes trust relationships between users to optimize user characteristics and user–item rating space, and proposes a context-aware social recommendation using individual trust (CSIT) based on trust relationships:
(2) Collaborative factorization method: Collaborative factorization is the use of user rating information and social relationships to jointly optimize the shared user feature space, thereby obtaining more accurate user preferences. The most representative ones are the MF models based on trust propagation proposed by Yao and Ma et al.: RoRec [46] and SoRec [47].
Yao et al. divided users into trustor users and trusted users, modeled users’ predictive ratings for items from the perspectives of their trustors and trusted users, and proposed the RoRec model based on user role preferences [46]:
where . and are the preference feature vectors of the trustor and the trustee with the user’s dimension k, respectively. represents the preference similarity between two trusted users, and represents the preference similarity between two trusted users.
Ma et al. combined users’ social networks with user–item rating information and proposed the SoRec model based on user social relationships [47]:
where denotes the social network relationship between users u and k, and denotes the feature vector of user k auxiliary factors.
(3) Regularization method [8,11,29,58]: The regularization method constrains the preferences of user features in social networks by utilizing the approximation degree of two user or item features to approximate real user features. SocialMF [27], Average-based Social Regulation (ASR), and Individually based Social Regularization (ISR) are typical representatives of recommendation methods based on social networks. Considering the impact of social networks on user preferences, Ma et al. proposed the ASR method based on social relationship regularization, which utilizes the average preference influence of friends in social networks to constrain the matrix decomposition process, based on the viewpoint that user decisions are likely to come from valuable suggestions from friends.
Here, denotes the set of friends of user u; is the similarity function, and denotes the similarity between users u and v.
To reflect user personalized preferences, Ma proposed the ISR method based on individual user interests:
Jamali et al. proposed the SocialMF model based on trust propagation by establishing trust relationships between users and constraining their feature vectors [27]:
where represents the degree to which user v is trusted by user u, and .
Subsequently, some improved social MF recommendation algorithm models have been successively proposed, such as SocialIMF [59], EnSocialMF [29], and TrustPMF [30]. Among them, SocialMF obtains implicit user similarity through explicit user ratings and trust relationships to obtain more accurate user features. EnSocialMF incorporates social factor enhancement models into MF models by establishing them. TrustPMF introduces user ratings and trust relationships into the social relationship MF model, and introduces the influence of regularization factors.
4.2.2. FM Technology Based on Social Relationship for Recommendation
FM is one of the important models for predicting the click-through rate (CTR). Since its proposal in 2010, it has received large-scale support and is also one of the methods used by Meituan and Toutiao to make recommendations and CTR estimates. The FM was first proposed by Steffen Rendle at the Industrial Conference on Data Mining in 2010. It is a universal prediction method that can estimate reliable parameters and make predictions even when data are very sparse [24].
The logistic regression (LR) model is the earliest and most successful model in the field of CTR estimation. Most industrial recommendation ranking systems integrate artificial nonlinear features. However, the biggest drawback of the LR model is that it requires manual feature design and consumes a lot of human resources to filter and combine nonlinear features. By adding second-order features to the calculation formula of the linear model, any two features are paired and added to the linear model to obtain the following model:
In the above model, any two features intersect in pairs, where n denotes the number of features, xi represents the i-th feature value, and pi and pj represent the inner product of the item’s feature vectors, respectively.
FM can be seen as a special case of Field-aware FM (FFM), which refers to the FFM model where all features belong to one field. Based on the field sensitivity of FFM, its model equation can be derived [24]:
where fj is the field to which the jth feature belongs. If the length of the hidden vector is k, then there are nfk quadratic parameters in FFM, far more than nk in the FM model.
DeepFM [32] is a deep model proposed by Huawei for solving CTR problems. DeepFM is based on Google’s Wide&Deep model and introduces the FM algorithm to the Wide side, replacing the LR model in the original Wide&Deep model. It can achieve end-to-end-learning feature crossover without the involvement of artificial feature engineering.
DeepFM consists of two parts: a neural network and a FM machine, which are responsible for extracting low-order features and high-order features, respectively.
The final output of DeepFM is as follows:
4.2.3. DL Technology Based on Social Relationship for Recommendation
DL combines low-level features to form more dense high-level semantic abstractions, automatically discovering distributed feature representations of data, solving the problem of manually designing features in traditional machine learning. The DL-based RS usually takes various types of users and items as input, uses DL models to learn implicit representations of users and items, and generates item recommendations for users. The DL-Based recommendation framework integrating social relationships is shown in Figure 3.
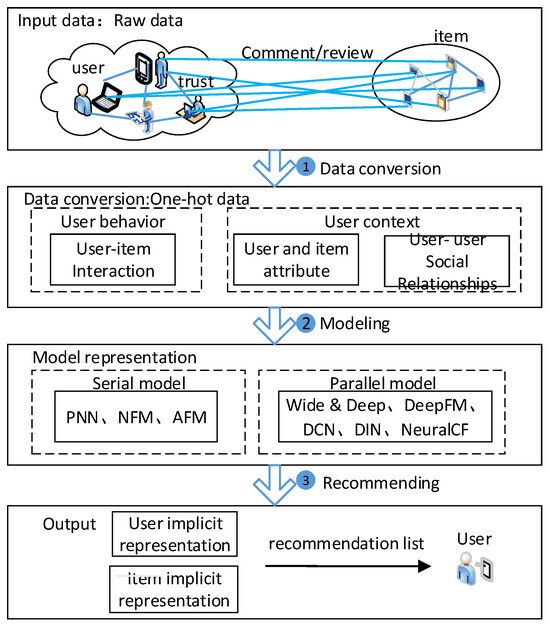
Figure 3.
A DL-based recommendation framework integrating social relationships.
Overall, DL-Based recommendation models are constructed by the cross-fusion of high-order and low-order features, which can be roughly divided into two methods: serial structure and parallel structure. Typical representatives of serial structures include Product-based Neural Networks (PNN) [51], Neural FM (NFM) [42], and FM models that combine Attention networks (AFM) [35], while typical representatives of parallel structures include Wide&Deep, DeepFM, Deep&Cross Network (DCN), NeuMF, and NeuralCF.
(1) Serial structures
- PNN
The PNN model includes an embedding layer to learn the distributed representation of category data, a product layer to capture feature interaction patterns between fields, and a fully connected layer to mine higher-order feature interactions.
The innovation of the PNN model in the DL structure is mainly reflected in the introduction of the Product layer, which is composed of lZ and lp. The inner product operation of vectors is as follows:
Calculate and through z and as follows:
where and are the weight parameters of the product layer, respectively, and their shape depends on z and p, respectively.
The outputs of the hidden layers l1 and l2 are obtained by the following formulas, respectively:
At the output layer, the output of the PNN model is a real number in the range of (0, 1), representing the click through rate. The calculation method is as follows:
Among them, and are the parameters of the output layer, and is the output of the second hidden layer.
- NFM
NFM is used to solve the problem of sparse prediction. It is mainly applied in scenarios where input data are particularly sparse and feature combinations are crucial for predicting results.
NFM can be formalized as follows [42]:
where is the core of NFM, used to learn second-order combined features and higher-order combined feature patterns.
Considering the weight matrices of the hidden layers in the previous layers, f (x) is formalized as follows:
- AFM
The essence of AFM model design is that FM models that combine attention networks can learn the weight coefficients of second-order cross features. The purpose of the pair-wise interaction layer is to express the computational logic of FM in neural networks [35,60]:
Here, p and b represent the weight and bias values of the prediction network, respectively.
The output of the attention-based pooling layer is a k-dimensional vector that compresses all feature interactions by distinguishing their respective importance in the embedded space, and then maps these to the final prediction result. The complete formula of the AFM model is as follows:
The previous part is a linear part, and the latter part performs element-wise product on every two embedded vectors to obtain the interacted vector. Then, the attention mechanism is used to obtain the attention score for each combined feature.
(2) Parallel structures
- Wide&Deep
The Wide&Deep [36] model achieves both memory and generalization in a single model through the collaborative training of a linear model module and a neural network module. Wide exhibits good memory ability, while Deep exhibits good generalization ability. Wide&Deep combines the advantages of both.
The final prediction output is as follows [36]:
Among them, represents the binary class label, represents the sigmoid function, represents the cross product transformation of the original feature, b is the deviation term, and represents the activation value of the last layer of NN. is the weight vector of all wide models, and is the weight of .
- DCN
The advantage of the DNN model in ctr estimation algorithm lies in its powerful learning ability, which can learn feature combinations to a certain extent. The implementation of the cross network is calculated by the following formula [31]:
Like FM, DCN is also based on parameter sharing mechanism.
- NeuralCF
NeuralCF [33] uses the embedding layer to simulate MF, obtain hidden vectors for users and items, then cross the hidden vectors through the fully connected layer for features, and finally output predicted values.
It concatenates the hidden vectors of users and items, inputs them into the fully connected layer for feature crossover, and the specific forward propagation process is as follows [33]:
Among them, and h are the activation functions of the output layer.
- NeuMF
NeuMF is obtained by combining GMF and MLP, which concatenates the output results of GMF and MLP, and then the concatenated results are further processed through a fully connected layer for more sufficient feature crossing. Finally, the activation function is used to output the final prediction result. The forward propagation process is as follows [58,61]:
4.2.4. GNN Technology Based on Social Relationship for Recommendation
In recommendation algorithms based on graph convolutional neural networks, some algorithms do not directly use the GCN method, but instead integrate GCN with graph embedding, thereby improving the efficiency of the entire model.
The principle of GNNs is mainly as follows: firstly, a graph structure model is constructed to reflect the relationship between entities; then, specific methods are used to describe the nodes and obtain nodes that contain the final neighbor-node information and topology characteristic states. This node has undergone continuous updating iterations. Finally, the representation of these nodes will be output in a specific way and the required information will be obtained.
- GraphRec
GraphRec provides a principled approach to jointly capture interactions and opinions in user–item graphs, and introduces a mathematical approach that considers the heterogeneous strength of social relationships.
The model contains three components: user modeling, item modeling, and rating prediction [43,56]. Among them, the user model aims to learn implicit features of users from user relationship diagrams and user–item relationship diagrams. The item model aims to learn the implicit features of items from their relationship diagrams. The rating prediction is achieved by integrating user modeling and item modeling.
Here, the βio denotes the strengths between users, denotes the user attention, and denotes the predicted rating from the user ui to the item vj.
- GDSRec
GDSRec [43] is a novel GNN-based social recommendation model to solve user and item bias problems. It is learned on the decentralized graph with distinct differentiable social connection strengths.
Among them, represents the latent factor offset for the user ui, and represents the latent factor offset of the item vj.
- HeteGraph
For processing and training complex large-scale heterogeneous graph data, Tran et al. proposed a novel framework based on the GCN principle—recommendation framework for heterogeneous graph structured data (HeteGraph) [62,63,64]. It learns node embedding of high-quality graphs through a sampling technique and a graph convolution operation. This is different from traditional GCN, which requires a complete graph adjacency matrix for embedding learning. The framework designs two models to evaluate RS tasks, namely rating prediction and diversified item recommendation.
The HeteGraph recommendation framework is divided into three stages: node neighborhood sampling, graph convolutional operation, and embedding learning strategy [62,63].
Here, denotes the weight parameter, and denotes the aggregated neighborhood tensor.
4.2.5. Comparison of Several Recommendation Methods Based on Social Relationships
Overall, among the five types of RS methods based on social relationships mentioned above, graph convolutional neural networks have better performance by integrating the advantages of several methods. Table 2 presents a comparative analysis of several representative recommendation methods based on social relationships, including model categories, model names, proposed problems, solutions, and advantages and disadvantages of the model.
Table 2.
The comparative analysis of several representative recommendation methods based on social relationships.
5. Future Research Directions
Although a series of recommendation technologies such as social MF, FM, and DL have been proposed, and greatly improve recommendation quality, current research still faces challenges such as complex social relationships and dynamic trust. The following are some future research directions and potential solutions.
5.1. The Fusion of Complex Social Relationships with Other Information
With the continuous emergence of complex network data such as social networks and transportation networks, traditional DL methods have gradually exposed limitations in processing graph data. It is a challenge to use DL technology to organically integrate heterogeneous information such as user ratings, social relationships, and comments for interaction [9,10,11]. GNN has a strong representational learning ability for the irregularity and dynamism of graph data. It can capture higher-order interaction relationships in user–item relationships through iterative propagation. Therefore, a hybrid recommendation model that combines MF, DL, and GNN may effectively improve data sparsity and cold start issues in RSs.
5.2. Dynamic Social Relationships in RSs
Traditional recommendation algorithms often consider static relationships between users, while in the real world, social relationships between users change over time. For example, at different times, we may have different groups of friends. In addition, the preferences of different users may change over time. A potential solution is to incorporate temporal factors into recommendation algorithms based on social relationships, and sequence models such as recurrent neural networks can store trust perception information and dynamically update themselves with changes.
5.3. Recommendations That Integrate User Comment Information
User comments contain rich semantic information, which may include users’ evaluations of various aspects such as the color, quality, and price of an item. However, user ratings and social relationships are only the final outcome, from which we find it difficult to know the true preferences of users. For example, does a user like to watch a movie because he/she likes the plot or because he/she likes the actors in the movie? This can only be known through comments. At present, some articles on RSs based on DL have begun to use comment text as a data source for recommendations. In the future, integrating user comments and social relationships will be a mainstream research direction. There is still much work to be done in the application of text mining and sentiment analysis technology for user comments in personalized RSs.
5.4. Privacy Protection in RSs
User attributes and interaction records contain rich personal privacy, and traditional RSs inevitably bring the risk of user privacy leakage. Due to the protection of user privacy by law, social networks and historical orders may not be available [65,66,67,68,69]. The RS based on GNN utilizes higher-order information on the user–item interaction graph for recommendation, but the extraction of higher-order information often comes with a greater risk of privacy leakage. Potential privacy protection technologies can solve the problem of privacy leakage: cryptographic methods (typically using homomorphic encryption (HE) and secure multiparty computation (MPC) techniques to protect intermediate transmission parameters) and the confusion method (adding noise to updated parameters) [70,71,72,73].
5.5. Explainable Recommendation
Although RSs have been successfully applied in many fields, the interpretability of algorithms seriously restricts the promotion of RSs. In particular, the inexplicability of DL makes it difficult for recommendation algorithms based on DL to be applied in broader fields such as healthcare and finance [74,75,76]. Interpretable recommendation systems not only provide recommendations to users, but also increase people’s trust in machine learning algorithms, improving the effectiveness, efficiency, persuasiveness, and user satisfaction of RSs [65].
6. Discussion
Compared with other survey articles, this article is a comprehensive survey article based on social relationship recommendation. The advantage of our work is that it classifies and surveys recommendation methods for social relationships, provides a framework and formal definition of social relationship recommendation systems, summarizes various recommendation techniques for integrating social relationships, and provides representative examples. Although there have been previous review articles on RSs based on social relationships, such as [77], which only reviewed memory-based social relationships and social MF, their introduction was not comprehensive enough and their scope was very limited. Other review articles mainly focused on a specific technology or application for review. The main techniques used in other surveys are shown in Table 3. Our deficiency is that due to space limitations, each social relationship recommendation method was not fully elaborated upon, which is also one aim of our next research work.
Table 3.
The main technical detail in other surveys.
7. Conclusions
In this survey, we investigated the state of the art of RSs based on social relationships, and highlighted several important recommendation technologies that integrate social relationships to solve data sparsity and cold start issues, including MF, FM, DL, and GNN. We summarized the related technological development and concluded a literature review on social relationship-based recommendation. For the convenience of readers’ understanding, we provided a basic framework and formal definition of an RS based on social relationships. We classified social recommendation systems based on technology and summarized various social recommendation methods by category, providing representative examples. Based on current research progress, this article provides future research directions, difficulties, and potential solutions for social relationship-based RSs. Finally, there was the discussion section, which included the methods of this survey, the advantages of this survey, and the technical details of other surveys. We believe that the classification and systematization of this research can help us to better understand and use these social recommendation technologies.
Author Contributions
Technology and writing, R.C.; methodology, M.H.; validation, K.P. and S.Z.; formal analysis, H.L. and X.K.; resources, Z.X.; writing—review and editing, J.Z. and X.K. Investigation, L.Z. and P.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grants 62072416, 61902361, 61672471, 61975187, and 61802352, in part by the Henan Key Research Project of Higher Education Institutions under Grant 22B520046, in part by Key Research and Development Special Project of Henan Province under Grant 221111210500, 232102211053, and 222102210170, in part by the Natural Science Foundation Project of Henan Province under Grant 222300420582, in part by the Doctoral Fund Project of Zhengzhou University of Light Industry under Grants 2020BSJJ030 and 2020BSJJ031, in part by the Mass Innovation Space Incubation Project under Grant 2023ZCKJ216, in part by the Data Science and Knowledge Engineering Team of Zhengzhou University of Light Industry, and in part by the innovation team of data science and knowledge engineering of Zhengzhou University of Light Industry under Grant 13606000032.
Data Availability Statement
Data are contained within the article.
Acknowledgments
We would like to thank the anonymous reviewers and editors for their helpful comments.
Conflicts of Interest
We declare no conflict of interest.
References
- Quijano-Sánchez, L.; Díaz-Agudo, B.; Recio-García, J.A. Development of a group recommender application in a Social Network. Knowl.-Based Syst. 2014, 71, 72–85. [Google Scholar] [CrossRef]
- Li, Y.; Wang, D.; He, H. Mining intrinsic information by matrix factorization-based approaches for collaborative filtering in recommender systems. Neurocomputing 2017, 249, 48–63. [Google Scholar] [CrossRef]
- Ge, Y.; Chen, S. Graph Convolutional Network for Recommender Systems. J. Softw. 2020, 31, 1101–1112. [Google Scholar]
- Chen, X.; Yao, L.; McAuley, J. Deep reinforcement learning in recommender systems: A survey and new perspectives. Knowl.-Based Syst. 2023, 264, 110335. [Google Scholar] [CrossRef]
- Li, Q.; Li, S.; Xu, G. Collaborative filtering recommendation algorithm based on spectral clustering and fusion of multiple factors. Comput. Appl. Res. 2017, 34, 2905–2908. [Google Scholar]
- Kuang, S.; Huang, Y.; Song, J. Matrix Filling Method Based on Deep Matrix Decomposition Network. Comput. Sci. 2019, 46, 55–62. [Google Scholar]
- Huang, L.; Jiang, B.; Lv, S.; Li, D. A Review of Research on Recommender Systems Based on Deep Learning. J. Comput. Sci. 2018, 41, 1619–1647. [Google Scholar]
- Liu, H.; Jing, L.; Yu, J. A Review of Matrix Decomposition Recommendation Methods for Integrating Social Information. J. Softw. 2017, 29, 340–362. [Google Scholar]
- He, Z.; Hui, B.; Zhang, S. Exploring indirect entity relations for knowledge graph enhanced recommender system. Expert Syst. Appl. 2023, 213, 118984. [Google Scholar] [CrossRef]
- Lee, Y.; Zhou, T.; Yang, K. Personalized recommender systems based on social relationships and historical behaviors. Appl. Math. Comput. 2023, 437, 127549. [Google Scholar] [CrossRef]
- Dong, M.; Yuan, F.; Yao, L. A survey for trust-aware recommender systems: A deep learning perspective. Knowl.-Based Syst. 2023, 249, 108954. [Google Scholar] [CrossRef]
- Yu, W.; Li, S. Recommender systems based on multiple social networks correlation. Future Gener. Comput. Syst. 2018, 87, 312–327. [Google Scholar] [CrossRef]
- Lu, Q.; Guo, F. Personalized information recommendation model based on context contribution and item correlation. Measurement 2019, 142, 30–39. [Google Scholar] [CrossRef]
- Liu, Y.; Liang, C.; Chiclana, F. A knowledge coverage-based trust propagation for recommendation mechanism in social network group decision making. Appl. Soft Comput. J. 2021, 101, 107005. [Google Scholar] [CrossRef]
- Chen, R.; Hua, Q.; Chang, Y. A survey of collaborative filtering-based recommender systems: From traditional methods to hybrid methods based on social networks. IEEE Access 2018, 6, 64301–64320. [Google Scholar] [CrossRef]
- Herce-Zelaya, J.; Porcel, C.; Bernabe-Moreno, J. New technique to alleviate the cold start problem in recommender systems using information from social media and random decision forests. Inf. Sci. 2020, 53, 156–170. [Google Scholar] [CrossRef]
- Yuan, W.; Wang, H.; Yu, X. Attention-based context-aware sequential recommendation model. Inf. Sci. 2020, 510, 122–134. [Google Scholar] [CrossRef]
- Ma, H. On measuring social friend interest similarities in recommender systems. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, Australia, 6–11 July 2014; pp. 465–474. [Google Scholar]
- Seo, Y.; Kim, Y.; Lee, E.; Baik, D. Personalized recommender system based on friendship strength in social network services. Expert Syst. Appl. 2022, 69, 135–148. [Google Scholar] [CrossRef]
- Stitini, O.; Kaloun, S.; Bencharef, O. Towards the Detection of Fake News on Social Networks Contributing to the Improvement of Trust and Transparency in Recommendation Systems: Trends and Challenges. Information 2022, 13, 128. [Google Scholar] [CrossRef]
- Gao, G. Survey on Attention Mechanisms in Deep Learning Recommendation Models. Comput. Eng. Appl. 2022, 58, 9–18. [Google Scholar]
- Mehdi, E.; Ricci, F.; Rubens, N. A survey of active learning in collaborative filtering recommender systems. Comput. Sci. Rev. 2016, 20, 29–50. [Google Scholar]
- Chen, R.; Zhang, J.; Zhang, Z. A Comprehensive Social Matrix Factorization with Social Regularization for Recommendation Based on Implicit Similarity by Fusing Trust Relationships and Social Tags. Soft Comput. 2021; preprint. [Google Scholar]
- Rendle, S. Factorization machines. In Proceedings of the 10th IEEE International Conference on Data Mining, Wangington, DC, USA, 13–17 December 2010; pp. 995–1000. [Google Scholar]
- Huang, R.; Cui, L.; Han, C. Feature-Over-Field Interaction Factorization Machine for Sparse Contextualized Prediction in Recommender Systems. J. Comput. Res. Dev. 2022, 59, 1553–1568. [Google Scholar]
- Fan, W.; Ma, Y.; Li, Q. Graph Neural Networks for Social Recommendation. In Proceedings of the WWW ‘19: The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 417–426. [Google Scholar]
- Jamali, M.; Ester, M. A Matrix Factorization Technique with Trust Propagation for Recommendation in Social Networks. In Proceedings of the 4th ACM Conference on Recommender Systems (RecSys’10), Barcelona, Spain, 26–30 September 2010; ACM: New York, NY, USA, 2010; Volume 45, pp. 26–30. [Google Scholar]
- Ma, H.; King, I.; Lyu, R. Learning to recommend with social trust ensemble. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 1–8. [Google Scholar]
- Chen, R.; Chang, Y.; Hua, Q. An enhanced social matrix factorization model for recommendation based on social networks using social interaction factors. Multimed. Tools Appl. 2020, 79, 14147–14177. [Google Scholar] [CrossRef]
- Yang, B.; Yu, L.; Liu, D. Social collaborative filtering by trust. In Proceedings of the International Joint Conferences on Artificial Intelligence (IJCAI), Beijing, China, 3–9 August 2013; AAAI Press: Cambridge, MA, USA, 2013; pp. 2747–2753. [Google Scholar]
- Yan, C.; Zhou, L.; Zhang, Q. Research on Wide and Deep Extension of Factorization Machine. J. Softw. 2019, 30, 822–844. [Google Scholar]
- Guo, H.; Tang, R. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, IJCAI’17, Melbourne, Australia, 19–25 August 2017; pp. 1725–1731. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T. Neural Collaborative Filtering. In Proceedings of the WWW 2017, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Baldassarre, F.; Azizpour, H. Explainability Techniques for Graph Convolutional Networks. In Proceedings of the ICML 2019, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Wu, L.; Sun, P.; Fu, Y. A Neural Influence Diffusion Model for Social Recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information, SIGIR’19, Paris, France, 21–25 July 2019; pp. 235–244. [Google Scholar]
- Cheng, H.; Koc, L.; Harmsen, J. Wide & Deep Learning for Recommender Systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016. [Google Scholar]
- Chai, W.; Zhang, Z. Recommender System based on graph attention convolutional neural network. Comput. Appl. Softw. 2023, 40, 201–206. [Google Scholar]
- Nguyen, V.; Lee, K. Hierarchical Multi-head Attentive Network for Evidence-aware Fake News Detection. In Proceedings of the EACL 2021, Virtual, 19–23 April 2021. [Google Scholar]
- Lee, D.; Seung, S.H. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Liu, H.; Hu, Z.; Mian, A.; Tian, H.; Zhu, X. A new user similarity model to improve the accuracy of collaborative filtering. Knowl.-Based Syst. 2014, 56, 156–166. [Google Scholar] [CrossRef]
- Hu, L.; Yang, T.; Shi, C.; Ji, H.; Li, X. Heterogeneous Graph Attention Networks for Semi-supervised Short Text Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4821–4830. [Google Scholar]
- He, X.; Chua, T. Neural Factorization Machines for Sparse Predictive Analytics. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; ACM Sigir Forum: New York, NY, USA, 2017; Volume 51, pp. 355–364. [Google Scholar]
- Chen, J.; Xin, X.; Liang, X.; He, X. GDSRec: Graph-Based Decentralized Collaborative Filtering for Social Recommendation. IEEE Trans. Knowl. Data Eng. 2023, 35, 4813–4824. [Google Scholar]
- Moradi, P.; Ahmadian, S. A reliability-based recommendation method to improve trust-aware recommender systems. Expert Syst. Appl. 2015, 42, 7386–7398. [Google Scholar] [CrossRef]
- Ahmadian, S.; Joorabloo, N.; Jalili, M. Alleviating data sparsity problem in time-aware recommender systems using a reliable rating profile enrichment approach. Expert Syst. Appl. 2022, 187, 115849. [Google Scholar] [CrossRef]
- Yao, W.; He, J.; Huang, G. Modeling dual role preferences for trust-aware recommendation. In Proceedings of the International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, QLD, Australia, 6–11 July 2014; ACM: New York, NY, USA; pp. 975–978. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M. SoRec: Social recommendation using probabilistic matrix factorization. In Proceedings of the ACM Conference on Information & Knowledge Management (CIKM’08), New York, NY, USA, 26–30 October 2008; pp. 931–940. [Google Scholar]
- Xin, X.; Karatzoglou, A.; Arapakis, I.; Jose, J. Self-supervised reinforcement learning for recommender systems. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 931–940. [Google Scholar]
- Ouyang, W.; Zhang, X.; Ren, S. Learning Graph Meta Embeddings for Cold-Start Ads in Click-Through Rate Prediction. In Proceedings of the SIGIR 2021, Virtual Event, Canada, 11–15 July 2021. [Google Scholar]
- Jiang, Y.; Ma, H.; Liu, Y. Enhancing social recommendation via two-level graph attentional networks. Neurocomputing 2021, 449, 71–84. [Google Scholar] [CrossRef]
- Hao, B.; Zhang, J.; Yin, H. Pre-Training Graph Neural Networks for Cold-Start Users and Items Representation. In Proceedings of the WSDM’21, Jerusalem, Israel, 8–12 March 2021. [Google Scholar]
- Wu, C.; Wu, F.; Cao, Y. FedGNN: Federated Graph Neural Network for Privacy-Preserving Recommendation. In Proceedings of the KDD 2021, Singapore, 14–18 August 2021. [Google Scholar]
- Li, H.; Ma, X.; Shi, J. Incorporating trust relation with PMF to enhance social network recommendation performance. Int. J. Pattern Recognit. Artif. Intell. 2018, 30, 113–124. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, G.; Zhang, P. Personalized recommendation algorithm for social networks based on comprehensive trust. Appl. Intell. 2017, 47, 659–669. [Google Scholar] [CrossRef]
- Li, F.; Chen, Z.; Wang, P. Graph Intention Network for Click-through Rate Prediction in Sponsored Search. In Proceedings of the SIGIR’19, Paris, France, 21–25 July 2019. [Google Scholar]
- Salakhutdinov, R.; Mnih, A. Probabilistic matrix factorization. Adv. Neural Inf. Process. Syst. 2008, 20, 1–7. [Google Scholar]
- Guo, L.; Ma, J.; Chen, Z. Learning to recommend with social context information from implicit feedback. Soft Comput. 2015, 19, 1351–1362. [Google Scholar] [CrossRef]
- Huo, Y.; Wong, D.; Ni, L. Knowledge modeling via contextualized representations for LSTM-based personalized exercise recommendation. Inf. Sci. 2020, 523, 266–278. [Google Scholar] [CrossRef]
- Pan, Y.; He, F.; Yu, H. Social recommendation algorithm using implicit similarity in trust. Chin. J. Comput. 2018, 41, 66–81. [Google Scholar]
- Wu, H.; Zhang, Z.; Yue, K. Dual-regularized matrix factorization with deep neural networks for recommender systems. Knowl.-Based Syst. 2016, 145, 46–58. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, Y.; Sun, J. Group recommendation based on a bidirectional tensor factorization model. World Wide Web-Internet Web Inf. Syst. 2018, 21, 961–984. [Google Scholar] [CrossRef]
- Tran, D.; Aljubairy, A.; Zaib, M. HeteGraph: A Convolutional Framework for Graph Learning in Recommender Systems. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glassgow, UK, 19–24 July 2020. [Google Scholar]
- Tran, D.; Sheng, Q.; Zhang, W. HeteGraph: Graph learning in recommender systems via graph convolutional networks. Neural Comput. Appl. 2023, 35, 13047–13063. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Zhang, M. Knowledge graph convolutional networks for recommender systems with label smoothness regularization. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- He, X.; Chen, T.; Kan, M.; Chen, X. Trirank: Review-aware explainable recommendation by modeling aspects. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 1661–1670. [Google Scholar]
- Zhu, L.; Zhu, Z.; Zhang, C.; Xu, Y.; Kong, X. Multimodal sentiment analysis based on fusion methods: A survey. Inf. Fusion 2023, 95, 306–325. [Google Scholar] [CrossRef]
- Kong, X.; Duan, G.; Hou, M.; Shen, G.; Wang, H.; Yan, X.; Collotta, M. Deep Reinforcement Learning based Energy Efficient Edge Computing for Internet of Vehicles. IEEE Trans. Ind. Inform. 2022, 18, 6308–6316. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, Y.; Li, J.; Lou, J.; Chen, L.; Tzeng, N. Reverse attack: Black-box attacks on collaborative recommendation. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 15–19 November 2021; pp. 51–68. [Google Scholar]
- Hu, R.; Guo, Y.; Pan, M.; Gong, Y. Targeted poisoning attacks on social recommender systems. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Chen, Z.; Silvestri, F.; Wang, J.; Zhang, Y.; Tolomei, G. The Dark Side of Explanations: Poisoning Recommender Systems with Counterfactual Examples. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ‘23), Taipei, Taiwan, 23–27 July 2023. [Google Scholar] [CrossRef]
- Rong, D.; Ye, S.; Zhao, R.; Yuen, H.; Chen, J.; He, Q. FedRecAttack: Model poisoning attack to federated recommendation. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Virtual, 9–12 May 2022; pp. 2643–2655. [Google Scholar]
- Chen, H.; Li, J. Data poisoning attacks on cross-domain recommendation. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2177–2180. [Google Scholar]
- Yu, Y.; Liu, Q.; Wu, L.; Yu, R.; Zhang, Z. Untargeted attack against federated recommendation systems via poisonous item embeddings and the defense. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 4854–4863. [Google Scholar]
- Ren, Z.; Liang, S.; Li, P.; Wang, S.; Rijke, M. Social collaborative viewpoint regression with explainable recommendations. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, New York, NY, USA, 6–10 February 2017; pp. 485–494. [Google Scholar]
- Cai, X.; Guo, W.; Zhao, M.; Cui, Z.; Chen, J. A Knowledge Graph-Based Many-Objective Model for Explainable Social Recommendation. IEEE Trans. Comput. Soc. Syst. 2023. [Google Scholar] [CrossRef]
- Chen, Z.; Silvestri, F.; Wang, J.; Zhang, Y.; Huang, Z.; Ahn, H.; Tolomei, G. Grease: Generate factual and counterfactual explanations for gnn-based recommendations. arXiv 2022, arXiv:2208.04222. [Google Scholar]
- Yang, X.; Guo, Y.; Liu, Y.; Steck, H. A survey of collaborative filtering based social recommender systems. Comput. Commun. 2014, 41, 1–10. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, D. A survey of recommender systems with multi-objective optimization. Neurocomputing 2022, 474, 141–153. [Google Scholar] [CrossRef]
- Ma, G.; Wang, Y.; Zheng, X. A Trust-aware Latent Space Mapping Approach for Cross-domain Recommendation. Neurocomputing 2020, 431, 100–110. [Google Scholar] [CrossRef]
- Robin, B. Hybrid recommender systems: Survey and Experiments. User Model. User-Adapt. Interact. 2002, 12, 331–370. [Google Scholar]
- Su, X.; Khoshgoftaar, T. A Survey of Collaborative Filtering Techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- Chen, H.; Parra, D.; Verbert, K. Interactive recommender systems: A survey of the state of the art and future research challenges and opportunities. Expert Syst. Appl. 2016, 56, 9–27. [Google Scholar]
- Tang, J.; Hu, X.; Liu, H. Social recommendation: A review. Soc. Netw. Anal. Min. 2013, 3, 1113. [Google Scholar] [CrossRef]
- Portugal, I.; Alencar, P.; Cowan, D. The Use of Machine Learning Algorithms in Recommender Systems: A Systematic Review. Expert Syst. Appl. 2018, 97, 205–227. [Google Scholar] [CrossRef]
- Huang, L.; Liu, Y.; Li, D. Deep Learning Based Recommender Systems. Chin. J. Comput. 2017, 156, 1–30. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).