
Energy Efficient Power Allocation in Massive MIMO Based on Parameterized Deep DQN


Abstract
:1. Introduction
- Our work presents an advanced approach to the user association and power allocation problem, with the overarching objective of maximizing EE in the context of a massive MIMO network. By aiming for EE as the primary goal, we address a critical aspect of modern wireless communication networks, highlighting the practical relevance of our research.
- To effectively address power allocation challenges, we have carefully considered the design of the action space, the state space, and the reward function. Our approach leverages the model-free Deep Q-Network (DQN) framework and, notably, the PD-DQN framework, which empowers us to update policies within the hybrid discrete–continuous action space. This innovation is pivotal in enabling adaptive decision-making within complex real-world scenarios, underscoring the practicality of our methodology.
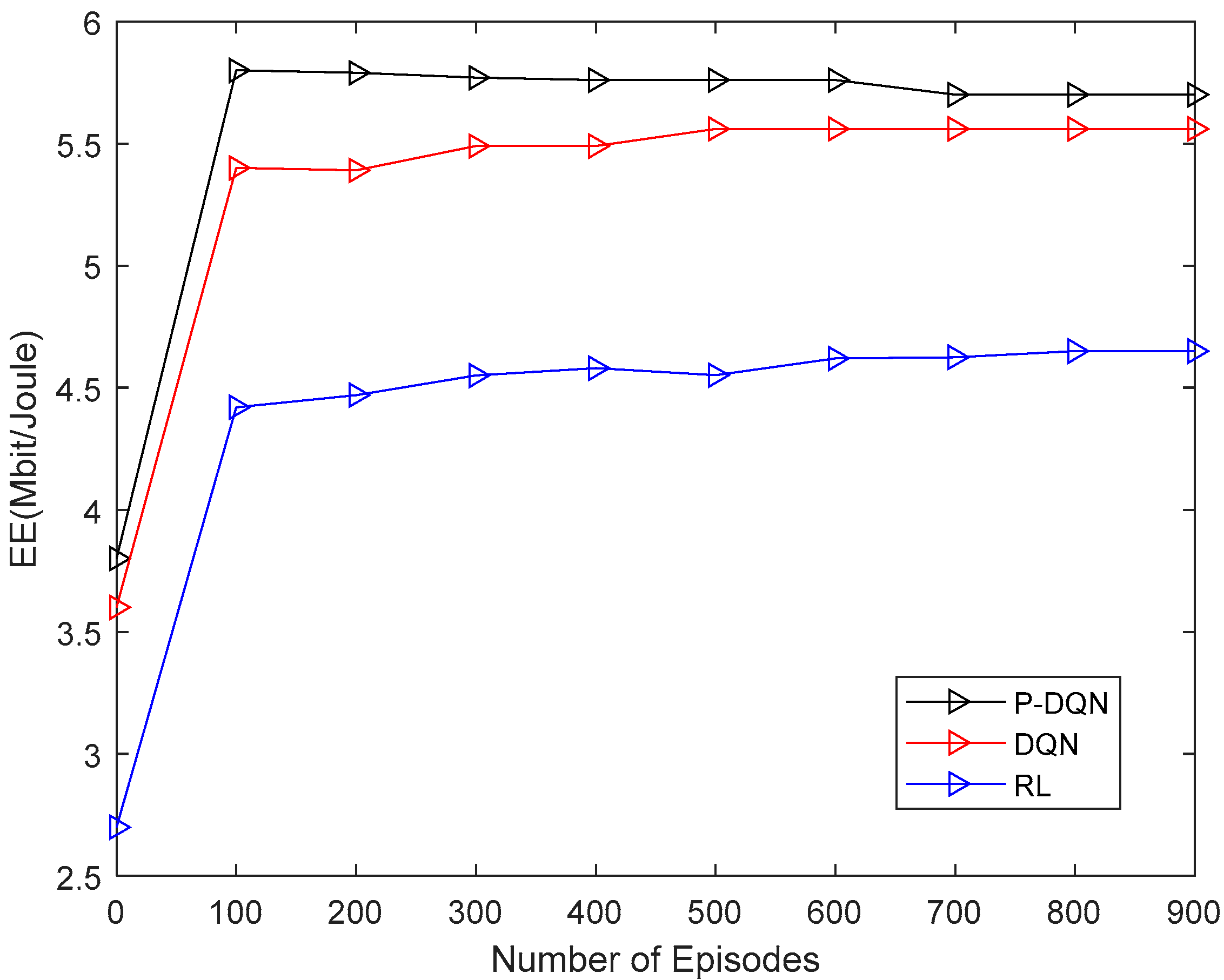
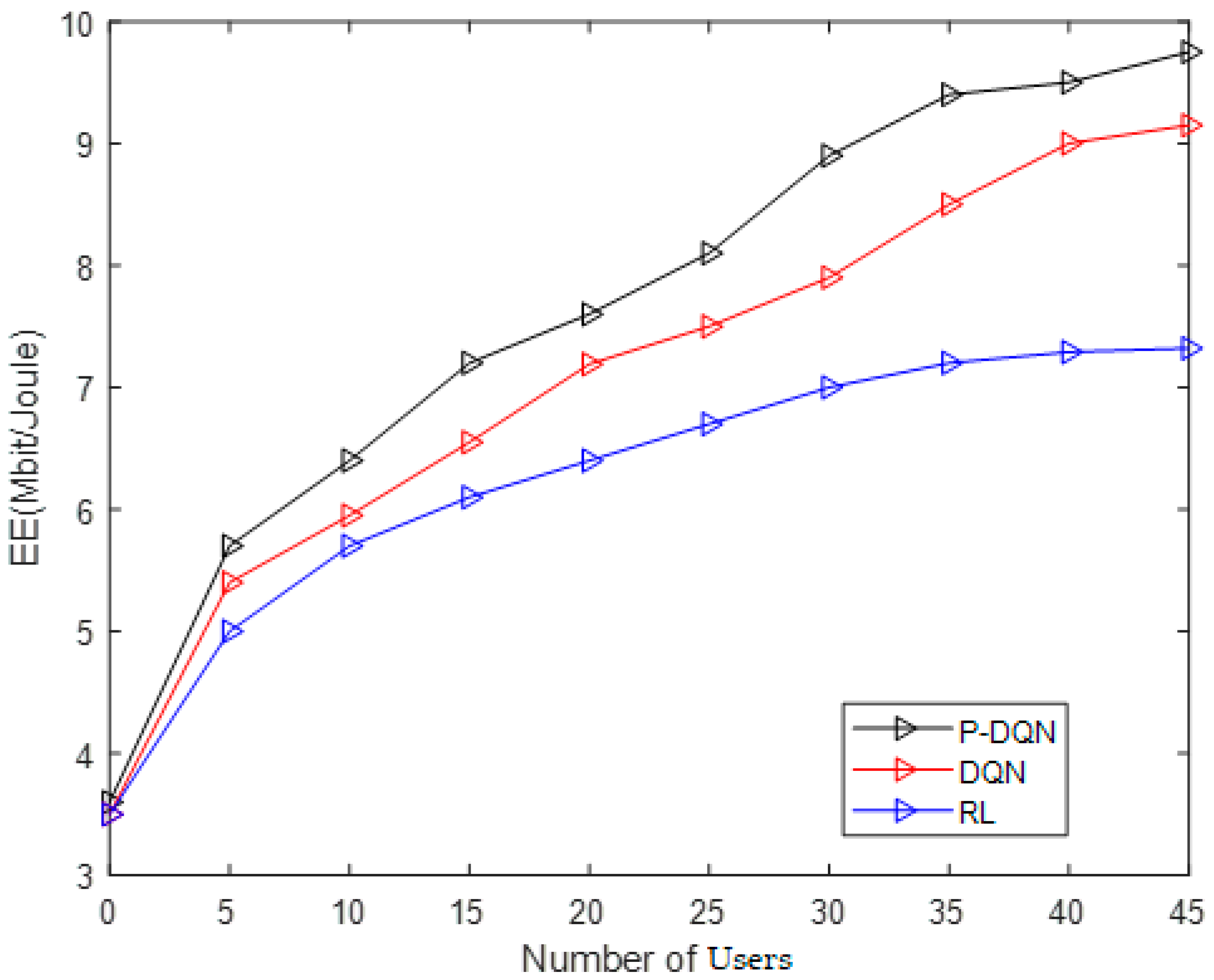
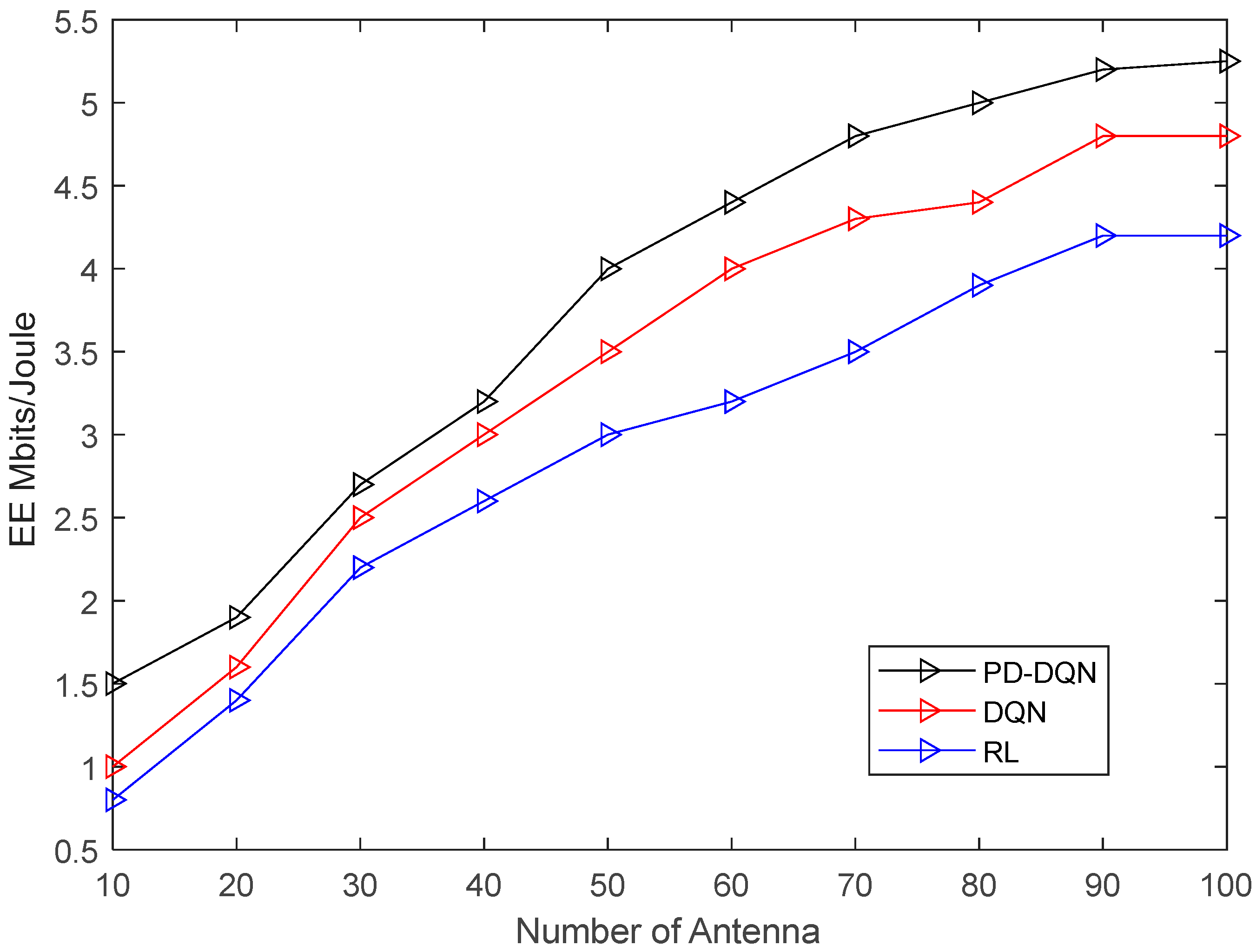
- The simulation results show that the proposed user association and power allocation method based on PD-DQN performs better than DRL and RL methods.
2. System Model
Power Consumption
3. Problem Formulation
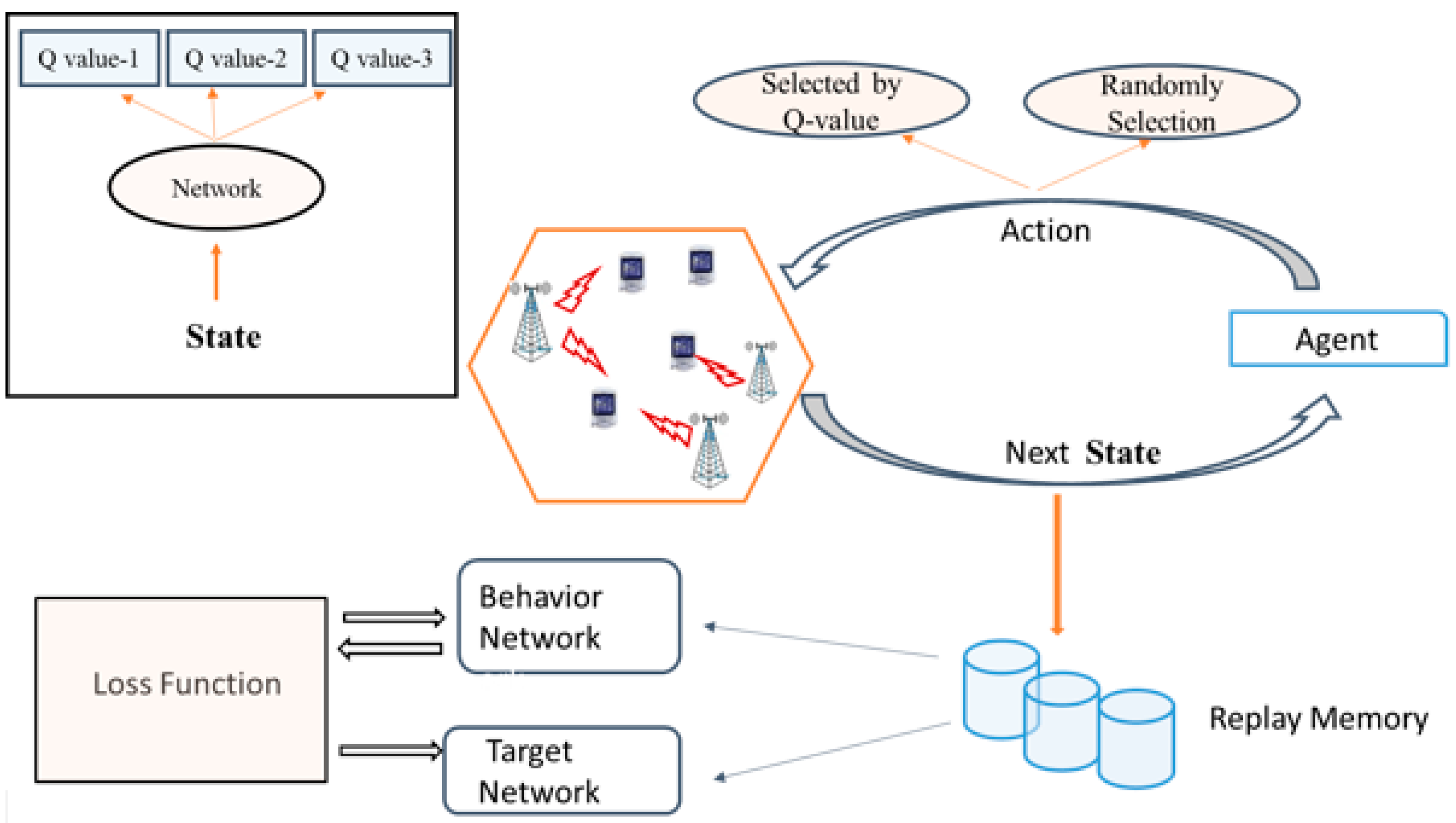
4. Multi-Agent DRL Optimization Scheme
4.1. Overview of RL Method
4.2. Multi-Agent DQN Frameworks
| Algorithm 1: DQN Based for User Association and Power Allocation Algorithm | |
| 1. | Initialize Q(s, a) = 0; learning rate α, target network and replay memory D. |
| 2. | Set the weight, discount factor |
| 3. | for each training episode do |
| 4. | Initialize state s |
| 5. | Choose a random number |
| 6. | then |
| 7. | Choose action randomly; |
| 8. | else |
| 9. | Select action |
| 10. | end if |
| 11. | Execute action and next state |
| 12. | Calculate energy efficiency using Equation (13). |
| 13. | Store transition in D |
| 14. | If the replay memory is full then |
| 15. | Random sampling a mini-batch from D |
| 16. | Perform gradient descent on |
| 17 | end if |
| 18 | Update target network |
| 19 | End for |
4.3. Parameterized Deep Q-Network Algorithm
| Algorithm 2: PD-DQN for User Association and Power Allocation Algorithm | |
| 1. | Initialize primary and target Deep Q-Networks (DQN) with random weights. |
| 2. | Set up a Mini-batch and a Replay Buffer for experience storage. |
| 3. | For each episode: |
| Generate an initial state (s_i) by selecting a random action. | |
| 4. | Inside each episode loop: |
| While the episode is ongoing: | |
| Choose an action based on an epsilon-greedy policy. | |
| If a random number is less than epsilon: | |
| Select a discrete action from a predefined set ). | |
| Otherwise: | |
| Estimate Q-values for discrete actions using the primary Q-network and choose the highest. | |
| If a random number is less than epsilon: | |
| Choose a continuous action from a predefined set ). | |
| Otherwise: | |
| Estimate Q-values for continuous actions using the primary Q-network and choose the highest. | |
| Execute the selected action in the environment following an epsilon-greedy policy. | |
| 5. | After each episode loop, sample a minibatch of experiences from the replay buffer. |
| 6. | For each experience in the minibatch: |
| Calculate the target Q-value using the target network. | |
| If the episode is ongoing, compute the target Q-value for the next state. | |
| If the episode is complete, compute the target Q-value with the reward. | |
| Calculate the predicted Q-value for the current state. | |
| Determine the difference between predicted and target Q-values and update the primary Q-network accordingly. | |
| Update the current state, target network weights. | |
| 7. | Update the environment with user associations and power allocations. |
| 8. | Repeat the process for the next episode if needed. |
| 9. | End |
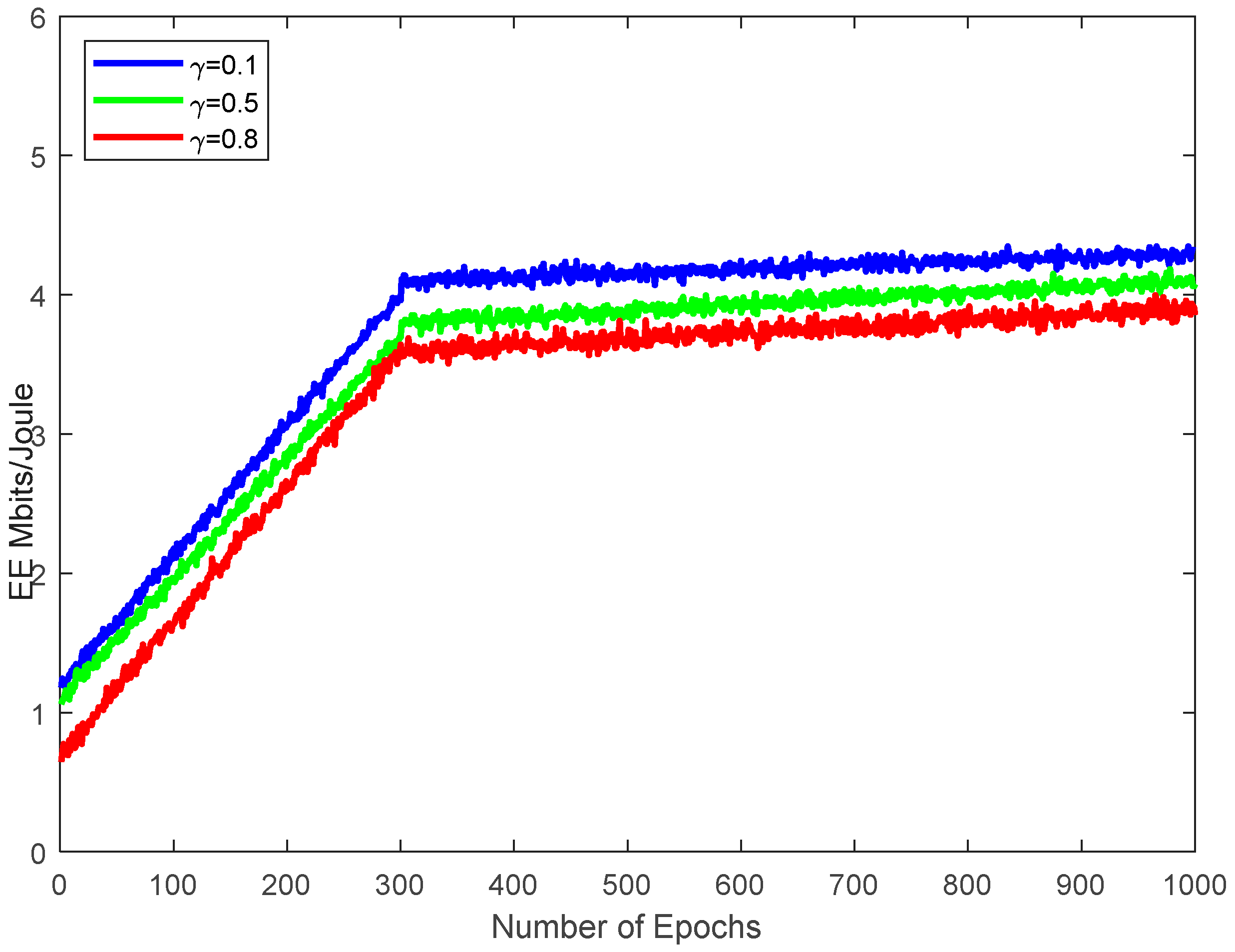
5. Simulation Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, H.; Wang, Z.; Wang, H. An energy-efficient power allocation scheme for Massive MIMO systems with imperfect CSI. Digit. Signal Process. 2021, 112, 102964. [Google Scholar] [CrossRef]
- Rajoria, S.; Trivedi, A.; Godfrey, W.W.; Pawar, P. Resource Allocation and User Association in Massive MIMO Enabled Wireless Backhaul Network. In Proceedings of the IEEE 89th Vehicular Technology Conference (VTC2019-Spring), Kuala Lumpur, Malaysia, 28 April–1 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Ge, X.; Li, X.; Jin, H.; Cheng, J.; Leung, V.C.M. Joint user association and user scheduling for load balancing in heterogeneous networks. IEEE Trans. Wireless Commun. 2018, 17, 3211–3225. [Google Scholar] [CrossRef]
- Liang, L.; Kim, J.; Jha, S.C.; Sivanesan, K.; Li, G.Y. Spectrum and power allocation for vehicular communications with delayed CSI feedback. IEEE Wirel. Commun. Lett. 2017, 6, 458–461. [Google Scholar] [CrossRef]
- Bu, G.; Jiang, J. Reinforcement Learning-Based User Scheduling and Resource Allocation for Massive MU-MIMO System. In Proceedings of the 2019 IEEE/CIC International Conference on Communications in China (ICCC), Changchun, China, 11–13 August 2019; pp. 641–646. [Google Scholar] [CrossRef]
- Yang, K.; Wang, L.; Wang, S.; Zhang, X. Optimization of resource allocation and user association for energy efficiency in future wireless networks. IEEE Access 2017, 5, 16469–16477. [Google Scholar] [CrossRef]
- Dong, G.; Zhang, H.; Jin, S.; Yuan, D. Energy-Efficiency-Oriented Joint User Association and Power Allocation in Distributed Massive MIMO Systems. IEEE Trans. Veh. Technol. 2019, 68, 5794–5808. [Google Scholar] [CrossRef]
- Ngo, H.Q.; Ashikhmin, A.; Yang, H.; Larsson, E.G.; Marzetta, T.L. Cell-free massive MIMO versus small cells. IEEE Trans. Wirel. Commun. 2017, 16, 1834–1850. [Google Scholar] [CrossRef]
- Elsherif, A.R.; Chen, W.-P.; Ito, A.; Ding, Z. Resource Allocation And Inter-Cell Interference Management For Dual-Access Small Cells. IEEE J. Sel. Areas Commun. 2015, 33, 1082–1096. [Google Scholar] [CrossRef]
- Sheng, J.; Tang, Z.; Wu, C.; Ai, B.; Wang, Y. Game Theory-Based Multi-Objective Optimization Interference Alignment Algorithm for HSR 5G Heterogeneous Ultra-Dense Network. IEEE Trans. Veh. Technol. 2020, 69, 13371–13382. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, S. Dynamic scheduling for wireless multicast in massive MIMO HetNet. Phys. Commun. 2018, 27, 1–6. [Google Scholar] [CrossRef]
- Nassar, A.; Yilmaz, Y. Reinforcement Learning for Adaptive Resource Allocation in Fog RAN for IoT with Heterogeneous Latency Requirements. IEEE Access 2019, 7, 128014–128025. [Google Scholar] [CrossRef]
- Sun, Y.; Feng, G.; Qin, S.; Liang, Y.-C.; Yum, T.P. The Smart Handoff Policy for Millimeter Wave Heterogeneous Cellular Networks. IEEE Trans. Mob. Comput. 2018, 17, 1456–1468. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-Learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Zhai, Q.; Bolić, M.; Li, Y.; Cheng, W.; Liu, C. A Q-Learning-Based Resource Allocation for Downlink Non-Orthogonal Multiple Access Systems Considering QoS. IEEE Access 2021, 9, 72702–72711. [Google Scholar] [CrossRef]
- Amiri, R.; Mehrpouyan, H.; Fridman, L.; Mallik, R.K.; Nallanathan, A.; Matolak, D. A machine learning approach for power allocation in HetNets considering QoS. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Ghadimi, E.; Calabrese, F.D.; Peters, G.; Soldati, P. A reinforcement learning approach to power control and rate adaptation in cellular networks. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Meng, F.; Chen, P.; Wu, L. Power allocation in multi-user cellular networks with deep Q learning approach. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Ye, H.; Li, G.Y.; Juang, B.F. Deep reinforcement learning based resource allocation for v2v communications. IEEE Trans. Veh. Technol. 2019, 68, 3163–3173. [Google Scholar] [CrossRef]
- Wei, Y.; Yu, F.R.; Song, M.; Han, Z. Joint optimization of caching, computing, and radio resources for fog-enabled IOT using natural actor critic deep reinforcement learning. IEEE Internet Things J. 2019, 6, 2061–2073. [Google Scholar] [CrossRef]
- Sun, Y.; Peng, M.; Mao, S. Deep reinforcement learning-based mode selection and resource management for green fog radio access networks. IEEE Internet Things J. 2019, 6, 960–1971. [Google Scholar] [CrossRef]
- Rahimi, A.; Ziaeddini, A.; Gonglee, S. A novel approach to efficient resource allocation in load-balanced cellular networks using hierarchical DRL. J. Ambient. Intell. Humaniz. Comput. 2021, 13, 2887–2901. [Google Scholar] [CrossRef]
- Zhao, N.; Liang, Y.-C.; Niyato, D.; Pei, Y.; Wu, M.; Jiang, Y. Deep reinforcement learning for user association and resource allocation in heterogeneous cellular networks. IEEE Trans. Wirel. Commun. 2019, 18, 5141–5152. [Google Scholar] [CrossRef]
- Nasir, Y.S.; Guo, D. Multi-Agent Deep Reinforcement Learning for Dynamic Power Allocation in Wireless Networks. IEEE J. Sel. Areas Commun. 2019, 37, 2239–2250. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, J.; Headley, W.C.; Buehrer, R.M. Deep Reinforcement Learning for Dynamic Spectrum Access in Wireless Networks. In Proceedings of the 2018 IEEE Military Communications Conference (MILCOM), Los Angeles, CA, USA, 29–31 October 2018; pp. 207–212. [Google Scholar] [CrossRef]
- Li, M.; Zhao, X.; Liang, H.; Hu, F. Deep reinforcement learning optimal transmission policy for communication systems with energy harvesting and adaptive mqam. IEEE Trans. Veh. Technol. 2019, 68, 5782–5793. [Google Scholar] [CrossRef]
- Su, Y.; Lu, X.; Zhao, Y.; Huang, L.; Du, X. Cooperative communications with relay selection based on deep reinforcement learning in wireless sensor networks. IEEE Sens. J. 2019, 19, 9561–9569. [Google Scholar] [CrossRef]
- Xiong, J.; Wang, Q.; Yang, Z.; Sun, P.; Han, L.; Zheng, Y.; Fu, H.; Zhang, T.; Liu, J.; Liu, H. Parametrized deep q-networks learning: Reinforcement learning with discrete-continuous hybrid action space. arXiv 2018, arXiv:1810.06394. [Google Scholar]
- Lin, Z.; Lin, M.; Champagne, B.; Zhu, W.-P.; Al-Dhahir, N. Secrecy-Energy Efficient Hybrid Beamforming for Satellite-Terrestrial Integrated Networks. IEEE Trans. Commun. 2021, 69, 6345–6360. [Google Scholar] [CrossRef]
- Lin, Z.; Niu, H.; An, K.; Hu, Y.; Li, D.; Wang, J.; Al-Dhahir, N. Pain without Gain: Destructive Beamforming from a Malicious RIS Perspective in IoT Networks. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- An, K.; Lin, M.; Ouyang, J.; Zhu, W.-P. Secure Transmission in Cognitive Satellite Terrestrial Networks. IEEE J. Sel. Areas Commun. 2016, 34, 3025–3037. [Google Scholar] [CrossRef]
- Lin, Z.; Niu, H.; An, K.; Wang, Y.; Zheng, G.; Chatzinotas, S.; Hu, Y. Refracting RIS-Aided Hybrid Satellite-Terrestrial Relay Networks: Joint Beamforming Design and Optimization. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 3717–3724. [Google Scholar] [CrossRef]
- Hsieh, C.-K.; Chan, K.-L.; Chien, F.-T. Energy-Efficient Power Allocation and User Association in Heterogeneous Networks with Deep Reinforcement Learning. Appl. Sci. 2021, 11, 4135. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, UK, 1998. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Values |
|---|---|
| Standard deviation | 8 dB |
| Path loss model PL | PL = −140.6−35log10(d) |
| Episodes | 500 |
| Steps T | 500 |
| Discount rate γ | 0.9 |
| Mini-batch size b | 8 |
| Learning rate | 0.01 |
| Replay memory size D | 5000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, S.; Yoon, W. Energy Efficient Power Allocation in Massive MIMO Based on Parameterized Deep DQN. Electronics 2023, 12, 4517. https://doi.org/10.3390/electronics12214517
Sharma S, Yoon W. Energy Efficient Power Allocation in Massive MIMO Based on Parameterized Deep DQN. Electronics. 2023; 12(21):4517. https://doi.org/10.3390/electronics12214517
Chicago/Turabian StyleSharma, Shruti, and Wonsik Yoon. 2023. "Energy Efficient Power Allocation in Massive MIMO Based on Parameterized Deep DQN" Electronics 12, no. 21: 4517. https://doi.org/10.3390/electronics12214517
APA StyleSharma, S., & Yoon, W. (2023). Energy Efficient Power Allocation in Massive MIMO Based on Parameterized Deep DQN. Electronics, 12(21), 4517. https://doi.org/10.3390/electronics12214517