
Coarse-to-Fine Homography Estimation for Infrared and Visible Images


Abstract
:1. Introduction
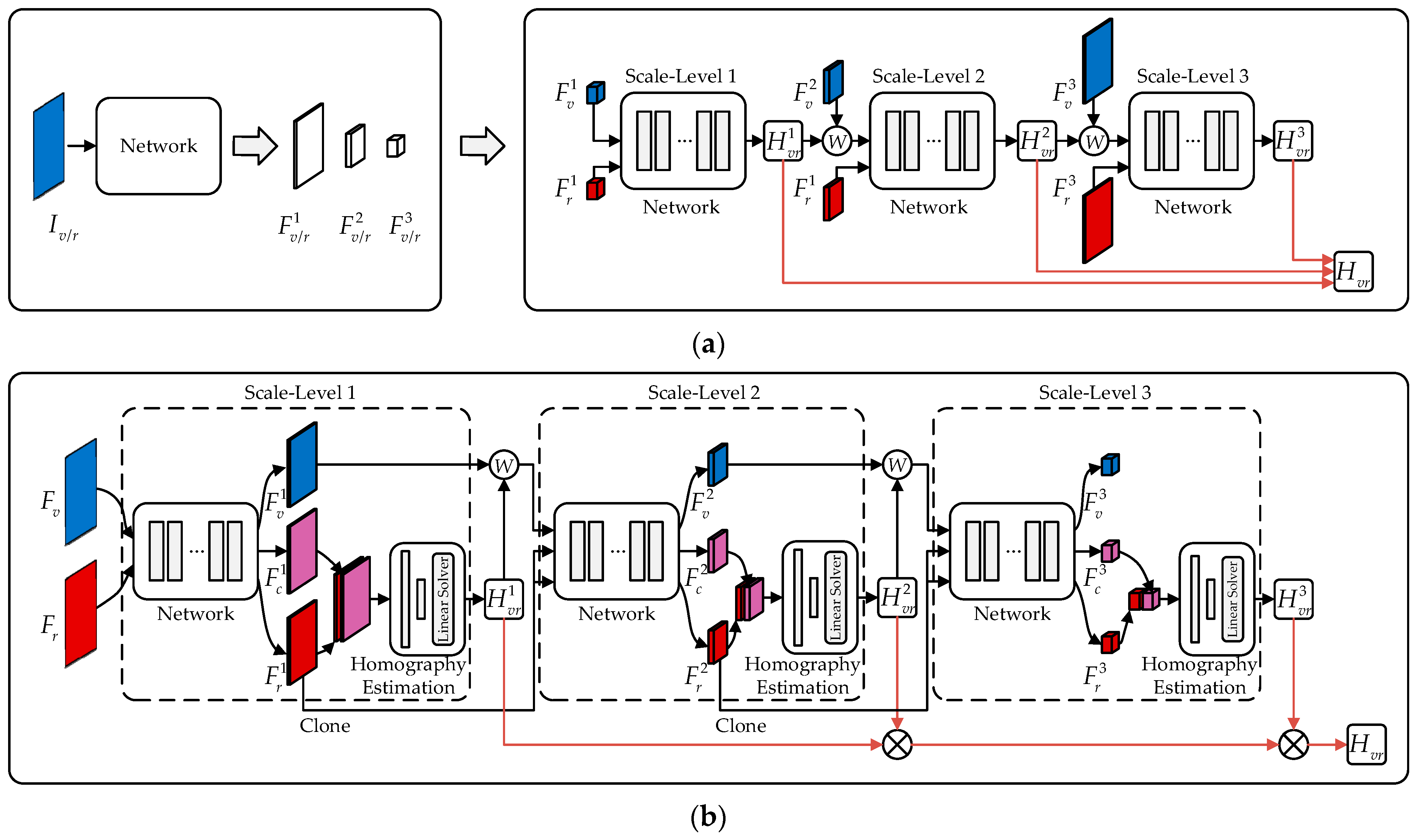
- We propose a novel coarse-to-fine strategy that obtains multi-scale feature maps through different stages in the regression network, thus avoiding the additional introduction of neural network structures and eliminating the need to design complex homography matrix fusion strategies.
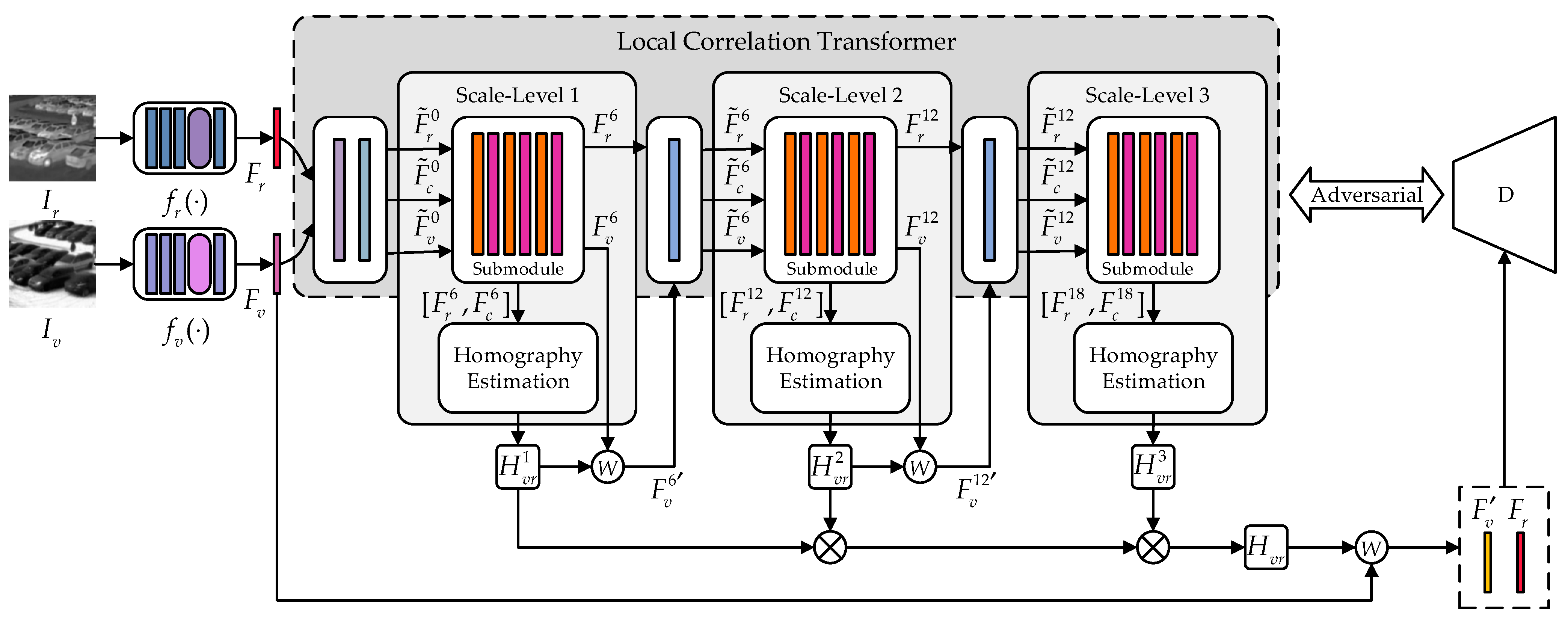
- We design a local correlation transformer with a self-attention layer to highlight important features for homography estimation. Each of its submodules also serves as a component at different scales in the coarse-to-fine strategy, aiming to obtain multi-scale feature maps.
- We design an improved average feature correlation loss, which increases the robustness of the model by computing the average of the triple loss over all LCTrans blocks.
2. Related Works
2.1. Traditional Homography Estimation
2.2. Deep Homography Estimation
2.3. Coarse-to-Fine Strategy in Deep Homography Estimation
3. Method
3.1. Overview
3.2. Coarse-to-Fine Strategy
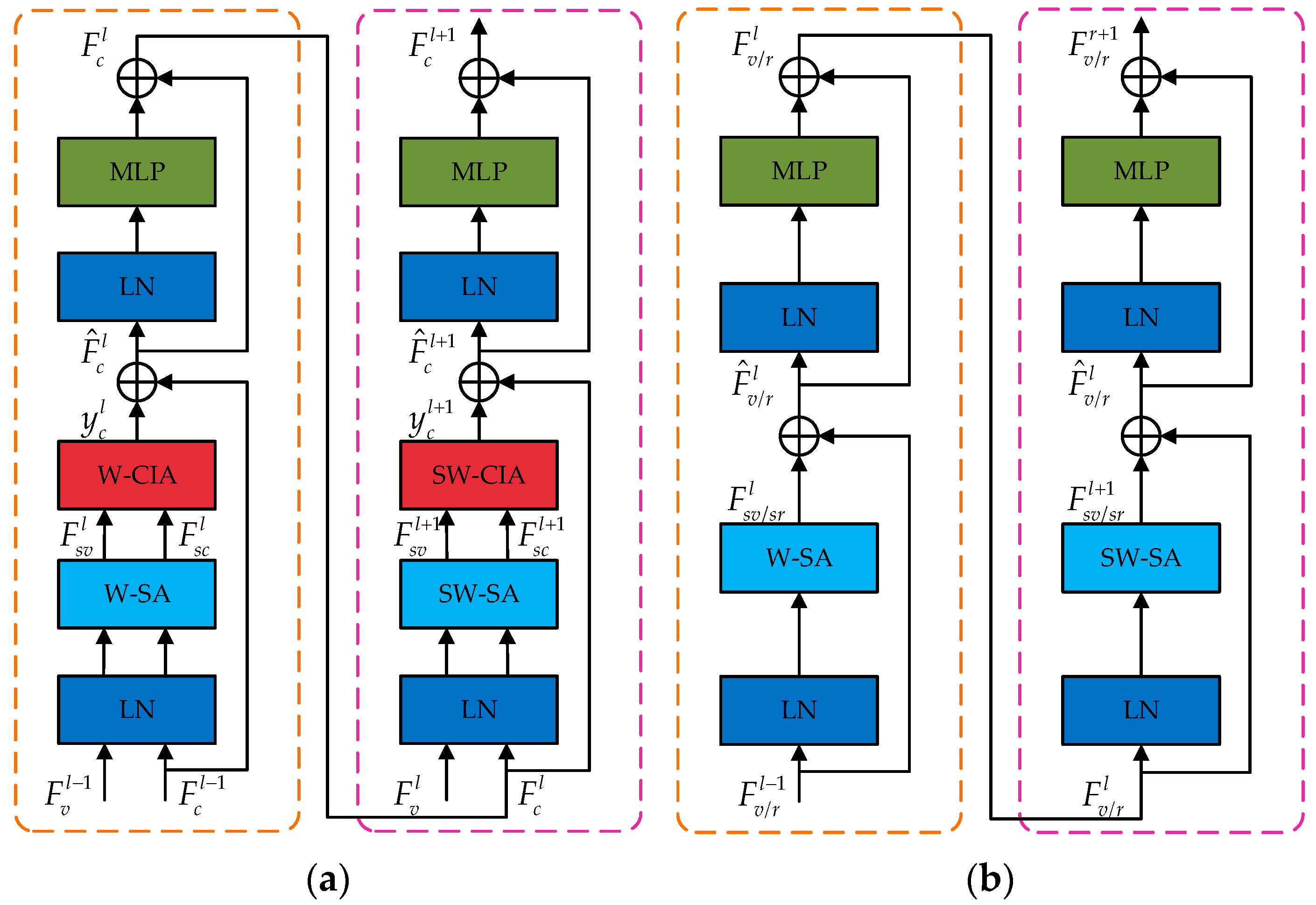
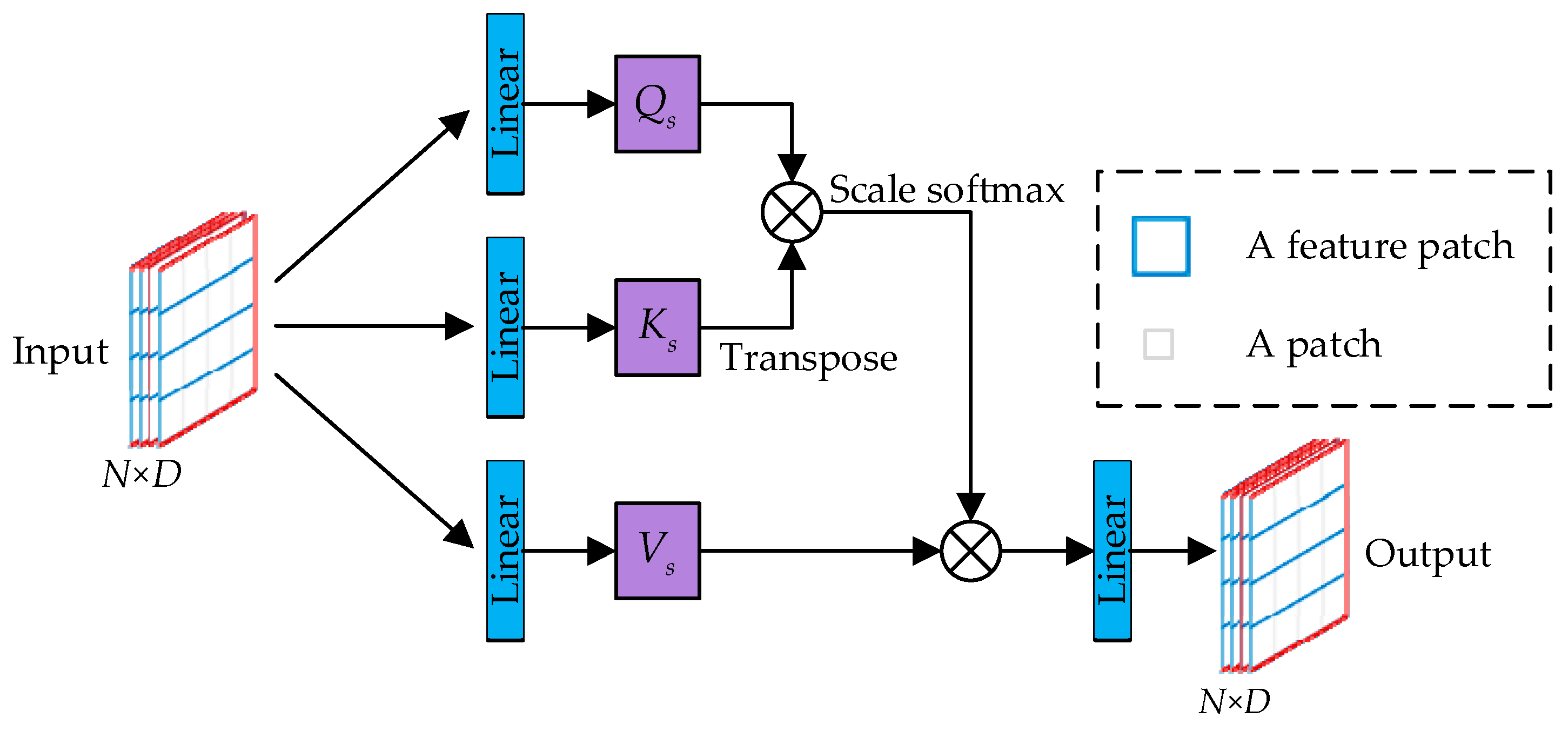
3.2.1. Local Correlation Transformer
3.2.2. Homography Estimation Module
3.3. Loss Function
3.3.1. Loss Function of the Generator
3.3.2. Loss Function of the Discriminator
4. Experiments
4.1. Dataset and Experimentation Details
4.2. Evaluation Metric
4.3. Comparison with Existing Methods
4.3.1. Comparative Methods
4.3.2. Qualitative Comparison
4.3.3. Quantitative Comparison
4.3.4. Failure Cases
4.4. Ablation Studies
4.4.1. Coarse-to-Fine
4.4.2. Self-Attention
4.4.3. Layer Numbers
4.4.4. AFCL
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| LCTrans | Local Correlation Transformer |
| AFCL | Average Feature Correlation Loss |
| DLT | Direct Linear Transformation |
| FCL | Feature Correlation Loss |
| SIFT | Scale Invariant Feature Transform |
| SURF | Speeded Up Robust Features |
| ORB | Oriented FAST and Rotated BRIEF |
| BRISK | Binary Robust Invariant Scalable Keypoints |
| AKAZE | Accelerated-KAZE |
| LPM | Locality Preserving Matching |
| GMS | Grid-Based Motion Statistics |
| BEBLID | Boosted Efficient Binary Local Image Descriptor |
| LIFT | Learned Invariant Feature Transform |
| SOSNet | Second-Order Similarity Network |
| OANs | Order-Aware Networks |
| RANSAC | Random Sample Consensus |
| MAGSAC | Marginalizing Sample Consensus |
| STN | Spatial Transformation Network |
| W-SA | Self-Attention with Regular Window |
| SW-SA | Self-Attention with Shifted Window |
| W-CIA | Cross-Image Attention with Regular Window |
| SW-CIA | Cross-Image Attention with Shifted Window |
| Adam | Adaptive Moment Estimation |
References
- Nie, L.; Lin, C.; Liao, K.; Liu, M.; Zhao, Y. A view-free image stitching network based on global homography. J. Vis. Commun. Image Represent. 2020, 73, 102950. [Google Scholar] [CrossRef]
- Huang, C.; Pan, X.; Cheng, J.; Song, J. Deep Image Registration with Depth-Aware Homography Estimation. IEEE Signal Process. Lett. 2023, 30, 6–10. [Google Scholar] [CrossRef]
- Lin, Y.; Wu, F.; Zhao, J. Reinforcement learning-based image exposure reconstruction for homography estimation. Appl. Intell. 2023, 53, 15442–15458. [Google Scholar] [CrossRef]
- Son, D.-M.; Kwon, H.-J.; Lee, S.-H. Visible and Near Infrared Image Fusion Using Base Tone Compression and Detail Transform Fusion. Chemosensors 2022, 10, 124. [Google Scholar] [CrossRef]
- Liu, C.; Feng, Q.; Sun, Y.; Li, Y.; Ru, M.; Xu, L. YOLACTFusion: An instance segmentation method for RGB-NIR multimodal image fusion based on an attention mechanism. Comput. Electron. Agric. 2023, 213, 108186. [Google Scholar] [CrossRef]
- Gao, X.; Shi, Y.; Zhu, Q.; Fu, Q.; Wu, Y. Infrared and Visible Image Fusion with Deep Neural Network in Enhanced Flight Vision System. Remote Sens. 2022, 14, 2789. [Google Scholar] [CrossRef]
- Xie, T.; Zhang, W. Fast Intrusion Detection in High Voltage Zone of Electric Power Operations Based on YOLO and Homography Transformation Algorithm. In Proceedings of the 2023 5th Asia Energy and Electrical Engineering Symposium (AEEES), Chengdu, China, 23–26 March 2023; pp. 686–691. [Google Scholar]
- Deng, H.; Ou, Z.; Zhang, G.; Deng, Y.; Tian, M. BIM and Computer Vision-Based Framework for Fire Emergency Evacuation Considering Local Safety Performance. Sensors 2021, 21, 3851. [Google Scholar] [CrossRef]
- Nath, N.D.; Cheng, C.S.; Behzadan, A.H. Drone mapping of damage information in GPS-Denied disaster sites. Adv. Eng. Inform. 2022, 51, 101450. [Google Scholar] [CrossRef]
- Ahmadi, S.S.; Khotanlou, H. A hybrid of inference and stacked classifiers to indoor scenes classification of rgb-d images. In Proceedings of the 2022 International Conference on Machine Vision and Image Processing (MVIP), Ahvaz, Iran, 23–24 February 2022; pp. 1–6. [Google Scholar]
- Singh, D.; Mohtasebi, M.; Chen, L.; Huang, C.; Mazdeyasna, S.; Fathi, F.; Yu, G. A fast algorithm towards real-time laser speckle contrast imaging. J. Biomed. Opt. 2022, 15, 011109. [Google Scholar]
- Rezaei, M.; Rastgoo, R.; Athitsos, V. TriHorn-Net: A model for accurate depth-based 3D hand pose estimation. Expert Syst. Appl. 2023, 223, 119922. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded Up Robust Features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Barath, D.; Matas, J.; Noskova, J. MAGSAC: Marginalizing Sample Consensus. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10197–10205. [Google Scholar]
- Barath, D.; Noskova, J.; Ivashechkin, M.; Matas, J. MAGSAC++, a Fast, Reliable and Accurate Robust Estimator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1304–1312. [Google Scholar]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An infrared and visible image fusion network based on salient target detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Yu, K.; Xu, C.; Ma, J.; Fang, B.; Ding, J.; Xu, X.; Bao, X.; Qiu, S. Automatic Matching of Multimodal Remote Sensing Images via Learned Unstructured Road Feature. Remote Sens. 2022, 14, 4595. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Deep image homography estimation. arXiv 2016, arXiv:1606.03798. [Google Scholar]
- Le, H.; Liu, F.; Zhang, S.; Agarwala, A. Deep Homography Estimation for Dynamic Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7652–7661. [Google Scholar]
- Hong, M.; Lu, Y.; Ye, N.; Lin, C.; Zhao, Q.; Liu, S. Unsupervised Homography Estimation with Coplanarity-Aware GAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 17663–17672. [Google Scholar]
- Hou, B.; Ren, J.; Yan, W. Unsupervised Multi-Scale-Stage Content-Aware Homography Estimation. Electronics 2023, 12, 1976. [Google Scholar] [CrossRef]
- Shao, R.; Wu, G.; Zhou, Y.; Fu, Y.; Fang, L.; Liu, Y. Localtrans: A Multiscale Local Transformer Network for Cross-Resolution Homography Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14890–14899. [Google Scholar]
- Li, Y.; Chen, K.; Sun, S.; He, C. Multi-scale homography estimation based on dual feature aggregation transformer. IET Image Process. 2023, 17, 1403–1416. [Google Scholar] [CrossRef]
- Huo, M.; Zhang, Z.; Yang, X. AbHE: All Attention-based Homography Estimation. arXiv 2022, arXiv:2212.03029. [Google Scholar]
- Wang, X.; Luo, Y.; Fu, Q.; Rui, Y.; Shu, C.; Wu, Y.; He, Z.; He, Y. Infrared and Visible Image Homography Estimation Based on Feature Correlation Transformers for Enhanced 6G Space–Air–Ground Integrated Network Perception. Remote Sens. 2023, 15, 3535. [Google Scholar] [CrossRef]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust Invariant Scalable Keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Alcantarilla, P.F.; Solutions, T. Fast explicit diffusion for accelerated features in nonlinear scale spaces. IEEE Trans. Patt. Anal. Mach. Intell 2011, 34, 1281–1298. [Google Scholar]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE Features. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 214–227. [Google Scholar]
- Ma, J.; Zhao, J.; Jiang, J.; Zhou, H.; Guo, X. Locality preserving matching. Int. J. Comput. Vis. 2019, 127, 512–531. [Google Scholar] [CrossRef]
- Bian, J.W.; Lin, W.Y.; Matsushita, Y.; Yeung, S.K.; Nguyen, T.D.; Cheng, M.M. Gms: Grid-Based Motion Statistics for Fast, Ultra-Robust Feature Correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4181–4190. [Google Scholar]
- Suárez, I.; Sfeir, G.; Buenaposada, J.M.; Baumela, L. BEBLID: Boosted efficient binary local image descriptor. Pattern Recognit. Lett. 2020, 133, 366–372. [Google Scholar] [CrossRef]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. Lift: Learned Invariant Feature Transform. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 10–16 October 2016; pp. 467–483. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Tian, Y.; Yu, X.; Fan, B.; Wu, F.; Heijnen, H.; Balntas, V. Sosnet: Second Order Similarity Regularization for Local Descriptor Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11016–11025. [Google Scholar]
- Zhang, J.; Sun, D.; Luo, Z.; Yao, A.; Zhou, L.; Shen, T.; Chen, Y.; Quan, L.; Liao, H. Learning Two-View Correspondences and Geometry Using Order-Aware Network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5845–5854. [Google Scholar]
- Nguyen, T.; Chen, S.W.; Shivakumar, S.S.; Taylor, C.J.; Kumar, V. Unsupervised deep homography: A fast and robust homography estimation model. IEEE Robot. Autom. Lett. 2018, 3, 2346–2353. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, C.; Liu, S.; Jia, L.; Ye, N.; Wang, J.; Zhou, J.; Sun, J. Content-Aware Unsupervised Deep Homography Estimation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 653–669. [Google Scholar]
- Ye, N.; Wang, C.; Fan, H.; Liu, S. Motion Basis Learning for Unsupervised Deep Homography Estimation with Subspace Projection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13117–13125. [Google Scholar]
- Nie, L.; Lin, C.; Liao, K.; Liu, S.; Zhao, Y. Depth-aware multi-grid deep homography estimation with contextual correlation. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4460–4472. [Google Scholar] [CrossRef]
- Debaque, B.; Perreault, H.; Mercier, J.P.; Drouin, M.A.; David, R.; Chatelais, B.; Duclos-Hindié, N.; Roy, S. Thermal and visible image registration using deep homography. In Proceedings of the 2022 25th International Conference on Information Fusion (FUSION), Linköping, Sweden, 4–7 July 2022; pp. 1–8. [Google Scholar]
- Luo, Y.; Wang, X.; Wu, Y.; Shu, C. Detail-Aware Deep Homography Estimation for Infrared and Visible Image. Electronics 2022, 11, 4185. [Google Scholar] [CrossRef]
- Luo, Y.; Wang, X.; Wu, Y.; Shu, C. Infrared and Visible Image Homography Estimation Using Multiscale Generative Adversarial Network. Electronics 2023, 12, 788. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (1) | Method | Easy | Moderate | Hard | Average | Failure Rate |
|---|---|---|---|---|---|---|
| (2) | 4.59 | 5.71 | 6.77 | 5.79 | 0% | |
| (3) | SIFT [13] + RANSAC [17] | 50.87 | Nan | Nan | 50.87 | 93% |
| (4) | SIFT [13] + MAGSAC++ [19] | 131.72 | Nan | Nan | 131.72 | 93% |
| (5) | ORB [15] + RANSAC [17] | 82.64 | 118.29 | 313.74 | 160.89 | 17% |
| (6) | ORB [15] + MAGSAC++ [19] | 85.99 | 109.14 | 142.54 | 109.13 | 19% |
| (7) | BRISAK [30] + RANSAC [17] | 104.06 | 126.8 | 244.01 | 143.2 | 24% |
| (8) | BRISAK [30] +MAGSAC++ [19] | 101.37 | 136.01 | 234.14 | 143.4 | 24% |
| (9) | AKAZE [31] + RANSAC [17] | 99.39 | 230.89 | Nan | 159.66 | 43% |
| (10) | AKAZE [31] + MAGSAC++ [19] | 101.36 | 210.05 | Nan | 139.4 | 52% |
| (11) | CADHN [41] | 4.09 | 5.21 | 6.17 | 5.25 | 0% |
| (12) | DADHN [45] | 3.84 | 5.01 | 6.09 | 5.08 | 0% |
| (13) | HomoMGAN [46] | 3.85 | 4.99 | 6.05 | 5.06 | 0% |
| (14) | FCTrans [29] | 3.75 | 4.70 | 5.94 | 4.91 | 0% |
| (15) | Proposed algorithm | 3.66 | 4.65 | 5.77 | 4.80 | 0% |
| CADHN | DADHN | HomoMGAN | FCTrans | Proposed Algorithm |
|---|---|---|---|---|
| 5.21 | 5.04 | 5.10 | 5.24 | 5.25 |
| 6.99 | 7.11 | 7.04 | 6.43 | 6.57 |
| (1) | Modification | Easy | Moderate | Hard | Average |
|---|---|---|---|---|---|
| (2) | w/o. coarse-to-fine | 3.95 | 4.78 | 5.86 | 4.96 |
| (3) | w/o. self-attention | 3.73 | 4.77 | 5.78 | 4.86 |
| (4) | Change to {2,2,6} | 3.97 | 4.98 | 6.15 | 5.14 |
| (5) | Change to {6,2,2} | 3.79 | 4.83 | 5.88 | 4.93 |
| (6) | Change to FCL | 3.95 | 5.08 | 6.15 | 5.16 |
| (7) | Proposed algorithm | 3.66 | 4.65 | 5.77 | 4.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Luo, Y.; Fu, Q.; He, Y.; Shu, C.; Wu, Y.; Liao, Y. Coarse-to-Fine Homography Estimation for Infrared and Visible Images. Electronics 2023, 12, 4441. https://doi.org/10.3390/electronics12214441
Wang X, Luo Y, Fu Q, He Y, Shu C, Wu Y, Liao Y. Coarse-to-Fine Homography Estimation for Infrared and Visible Images. Electronics. 2023; 12(21):4441. https://doi.org/10.3390/electronics12214441
Chicago/Turabian StyleWang, Xingyi, Yinhui Luo, Qiang Fu, Yuanqing He, Chang Shu, Yuezhou Wu, and Yanhao Liao. 2023. "Coarse-to-Fine Homography Estimation for Infrared and Visible Images" Electronics 12, no. 21: 4441. https://doi.org/10.3390/electronics12214441
APA StyleWang, X., Luo, Y., Fu, Q., He, Y., Shu, C., Wu, Y., & Liao, Y. (2023). Coarse-to-Fine Homography Estimation for Infrared and Visible Images. Electronics, 12(21), 4441. https://doi.org/10.3390/electronics12214441