1. Introduction
Along with the rapid development of cloud computing, application systems are moving towards openness, and the number of cloud APIs available on the network is rapidly expanding. As the carrier for service delivery, capability replication, and data output, the cloud application programming interface (API) has evolved into the necessary core element for service-oriented software development and operation [
1]. As a lightweight application, mashup accelerates the development process and improves application scalability by reusing and combining the functionality of multiple cloud APIs to fulfill complex requirements that cannot be achieved with a single cloud API. By combining cloud APIs, data, and resources from the web to assemble a single application that is more useful to an organization or individual, mashups can meet personalized needs quickly and cost-effectively [
2].
However, the continuously growing number of cloud APIs has brought developers challenges in making choices. Finding cloud APIs that meet specific requirements is an indispensable task for successful mashup development. It is essential to rapidly locate one or more cloud APIs that fit the criteria to promote the widespread adoption and advancement of cloud APIs. For example, ProgrammableWeb is a platform that boasts a vast collection of over 20,000 cloud APIs, which are categorized into 500 different categories. While this abundance of options can be a boon for developers, it can also be overwhelming when it comes to choosing the most suitable APIs for their mashup projects. Therefore, the cloud API recommendation system has become a natural choice for developers to recommend suitable cloud APIs.
In recent years, various researchers have devoted their attention to addressing the challenge of enhancing the efficiency of finding cloud APIs, and have proposed several recommendation methods for assisting mashup developers in selecting suitable cloud APIs expeditiously. Developers’ requirements are typically used as inputs for mashup-oriented cloud API recommendations. The recommendation system then calculates a match score for each cloud API in the repository and provides a list of recommended cloud APIs to the developer, sorted based on the match score [
3]. The two primary categories of the existing mashup-oriented cloud API recommendation methods are as follows: (1) Recommendation focusing on collaborative filtering (CF) [
4,
5,
6,
7,
8,
9], which utilizes the implicit mashup–API interaction information to discover mashup interest by similarity computation to complete the recommendation. However, the CF approach usually requires a large number of interaction records that are not available when using a new API or creating a new mashup, and therefore other content data need to be utilized for which the CF approach is not applicable. (2) Recommendation focusing on similar content [
10,
11,
12,
13,
14,
15], which employs information retrieval technology to recommend high-matching cloud APIs by analyzing and calculating the similarity between requirements and cloud API functions. These methods can recommend cloud APIs that are close to the needs of mashups, but do not pay enough attention to the collaborative relationship between cloud APIs and mashups.
Although existing research has actively investigated cloud API recommendation, there are still some issues that limit the effectiveness of mashup-oriented cloud API recommendation:
- 1.
Many current methods focus on finding similar cloud APIs without taking into account the ability of functional complementarity between them. However, cloud APIs that have very similar functionality are more likely to be replaced than used in combination [
16,
17]. APIs that are chosen to be used together often need to be functionally complementary to fulfill complex functional requirements. Therefore, to enhance the effectiveness of mashup-oriented cloud API recommendations, not only should we consider APIs with similar functions, but we should also consider whether the selected set of APIs can achieve complementary functions;
- 2.
Different mashups place varying emphasis on the functional similarity and complementarity of cloud APIs. Some mashups require the use of multiple cloud APIs that offer similar functions. For instance, a payment mashup may require the integration of payment cloud APIs from different platforms to provide a more comprehensive payment function. On the other hand, some mashups require the use of multiple cloud APIs that offer different functions. For example, an e-commerce mashup may need to integrate cloud APIs that offer functions such as maps, payments, and socialization to meet complex requirements. Unfortunately, some current cloud API recommendation algorithms fail to consider the different concerns of mashups regarding similarity and complementarity. This oversight can significantly affect the accuracy and comprehensiveness of cloud API recommendations.
To address the challenges faced by the above problems, a mashup-oriented cloud API recommendation method is proposed. The goal of this paper is to recommend a set of cloud APIs for a target mashup on a cloud API service platform based on the mashup requirements presented by the developers. The cloud API ecosystem accumulates a large amount of multi-type knowledge that can be used as side information to enhance recommendation models. For example, cloud API publishing and sharing platforms such as ProgrammableWeb store a large number of objects related to cloud APIs and the relationships between those objects. Based on the side information, a heterogeneous graph is first constructed by taking mashups, cloud APIs, and function tags as nodes, and the invocation relationship between the mashup and cloud APIs and the labeling relationship between APIs and function tags as the relation.
Cloud API function tags are used to describe the functionality provided by a cloud API, and two cloud APIs with one or more of the same function tags are considered to have functional similarities. Mashup invocations of cloud APIs describe the ability of two cloud APIs to collaborate with each other, and two different types of cloud APIs that have been invoked together by the same mashup are considered more likely to have complementary functionality. Both the similarity and complementarity of cloud APIs can be useful in mashup creation. Some mashups specialize in a specific functionality and often require multiple similar cloud APIs that can provide that functionality. For instance, a mashup can combine multiple music APIs to achieve a more comprehensive service. Some mashups need to invoke complementary cloud APIs for different functionalities that can be used collaboratively to complement each other’s functionality. For instance, for about two-thirds of the mashups that invoke “yahoo local search”, APIs also invoke the “google maps” API, such as the mashup “bigsity”, which provides local services, so the “google maps” API may have some functional complementarity with the “yahoo local search” API. Cloud APIs with similarity and complementarity are detected using the designed similarity metapaths and complementarity metapaths, respectively, in the heterogeneous graph and are called similarity neighbors and complementarity neighbors of each other. Similarity feature and complementarity feature representations of cloud APIs are obtained by aggregating the features of cloud API neighbors based on different metapaths.
Considering the potential preferences of mashups with different requirements for similarity and complementarity, mashup-related attention is utilized to identify the different importance of cloud API similarity features and complementarity features for the given mashup. Then, the cloud API similarity features and complementarity features are fused with the attention to compute a representation of the cloud API features that are aligned with the mashup’s requirements. Finally, the probability that each candidate cloud API is expected to be invoked by a mashup is predicted using the mashup requirements and its requirement-related cloud API features, which achieves cloud API recommendations aligned with the mashup’s requirements, leading to an improvement in the effectiveness of the mashup-oriented cloud API recommendation.
In summary, the main contributions of this paper are as follows:
- 1.
We propose a recommendation method that takes into account both the similarity and complementarity of cloud APIs and leverages the rich side information in the cloud API ecosystem to enhance the feature representation of cloud APIs.
- 2.
We construct a heterogeneous graph and use a graph attention neural network to aggregate similarity neighbors and complementarity neighbors based on the metapaths of cloud APIs to obtain similarity features and complementarity features.
- 3.
We consider mashups’ different attention to similarity and complementarity, and utilize mashup-related attention to fuse cloud API similarity features and complementarity features with preference to obtain feature representations of cloud APIs that are closely related to mashup, and use them to recommend a set of APIs that satisfy the requirements for a mashup.
The remainder of this paper is organized as follows. In
Section 2, the related work is reviewed and synthesized. In
Section 3, the motivation and some relevant definitions for the study are given, and then the proposed problem is formally described. In
Section 4, the proposed method is described in detail. In
Section 5, the experimental evaluation and analysis are given. Finally,
Section 6 summarizes the conclusions of this paper.
2. Related Work
Cloud API recommendation technology is essential to service-oriented computing and can significantly raise the quality of service discovery [
18]. Many recommendations have been suggested in recent years to assist software developers in swiftly and effectively identifying suitable cloud APIs. Mashup-oriented cloud API recommendations can be broadly divided into three groups: recommendations based on collaborative filtering, recommendations based on content, and recommendations based on knowledge graphs. This section provides a brief summary of the related work.
The collaborative filtering-based methods make utilization of user-API or mashup-API interaction matrices to discover user preferences through similarity calculations and produce recommendations. A deep matrix factorization framework was introduced by Xue et al. [
6] and can directly extract features from the user–API interaction matrix and fully take into account explicit and implicit ratings to achieve top-K recommendations. Fletcher et al. [
7] provided a regularized user preference embedding a matrix factorization approach that considers users’ explicit and implicit personalized preferences, significantly enhancing the precision and variety of suggestions. Tang et al. [
18] suggested a technique that takes advantage of neural graph collaborative filtering technology and high-order connectivity between cloud APIs and users. The importance of similarity calculations in collaborative filtering algorithms is widely established. Some researchers have added further information to improve the accuracy of similarity calculations and increase the impact of the collaborative filtering (CF) model. For instance, Chen et al. [
8] took the user’s credit and the spatial environment into account. Quality of service (QoS) characterizes the quality information of a cloud API in a certain aspect, such as response time, throughput, availability, and packet loss, which is generally used to describe the user’s non-functional requirements for a cloud API. Additionally, Meng et al. [
9] took into account temporal impacts by making a distinction between stable QoS measurements based on the traditional neighborhood-based CF model and temporal QoS metrics. However, the methods based on collaborative filtering have a high dependence on the interaction matrix, the quantity and quality of historical interaction information have a serious impact on the recommendation performance, and the cold start problem is serious.
The content-based recommendation mainly focuses on the functional matching of cloud APIs with developers’ requirements [
12,
13]. Xia et al. [
17] proposed a category-aware cloud API clustering method that first predicts user-need-based cloud API categories and then scores cloud APIs in each category for recommendation. Shi et al. [
14] suggested a text extension and a deep model-based approach to cloud API recommendation. By using a hierarchical probabilistic topic model to enhance sentence-level cloud API descriptions, this approach then proposes cloud APIs based on semantic similarity. Zhong et al. [
15] employ author topic models to model mashup descriptions and component cloud APIs, and they rebuild cloud API profiles by using mashup descriptions and structures to find significant lexical features of cloud APIs. A new cloud API recommendation algorithm is suggested using the word features in the cloud API profile that was rebuilt. By combining textual features, closest neighbor features, API-specific characteristics, tag features from mashups, and cloud APIs, Zhao et al. [
13] suggested a method for recommending cloud APIs that used features ensemble and learning-to-rank. These content-based approaches recommend cloud APIs that are more closely aligned with the developer’s requirements but often ignore whether these cloud APIs are suitable for combining into mashups.
The knowledge graph-based approach makes extensive use of attribute and interaction data from the cloud API ecosystem for cloud API recommendation [
19,
20]. Geng et al. [
21] built a knowledge graph of cloud APIs using additional data such as cloud API categories and developers. They then used Doc2Vec to mine the semantics of cloud APIs describing documents and graph convolution networks to mine higher-order relationships between cloud APIs and mashup preferences to predict the cloud APIs necessary for mashup development. In order to improve recommendation models, Wang et al. [
22] made use of the wealth of knowledge in the cloud API ecosystem, created a clear knowledge graph schema to encode mashup-specific context, modeled mashup requirements with graph entities, and used random walks with restarts. Knowledge graphs are used to look for possible correlations between mashup requirements and cloud APIs. Based on this, Wang et al. [
23] went on to further utilize the mashup-API common call and cloud API category attributes to construct a refined knowledge graph and used the deep random walk of the knowledge graph for unsupervised cloud API recommendation. Gao et al. [
24] propose a multi-relational graph neural network model that merges functional and labeling relationships between mashups and services into combination relationships and merges features of higher-order neighbors through graph convolution.
Inspired by the above work and considering the specificity of the mashup-oriented recommendation cloud API, we propose a new cloud API recommendation method that constructs heterogeneous information networks (HINs) with cloud API attribute information and interaction information to enhance cloud API feature representation. The similarity features and complementarity features of the cloud API are individually represented and fused to make the recommendation results more suitable for mashup requirements.
3. Background
3.1. Motivation
The problem to be solved is how to recommend the most suitable set of cloud APIs on a cloud API service platform (e.g., ProgrammableWeb) for the target mashup based on the mashup requirements presented by the developer. By observation of cloud API ecosystem data, we find that different mashups tend to have different concerns about cloud API functional similarity and functional complementarity.
In detail, some mashups are more focused on a specific function and are usually more likely to use multiple cloud APIs for that specific function concurrently. For example, according to the real cloud API data based on ProgrammableWeb, some mashups in the map category may need to call multiple map APIs, such as Google Maps, Google Earth, Bing Maps, etc., and integrate them. The actual data show that 96% of the mashups in the category of maps call cloud APIs with map tags, of which 47% call multiple map cloud APIs simultaneously. Therefore, the functional similarity of the APIs needs to be given more attention when creating such mashups. While some other mashups need to call multiple different categories of cloud APIs that can be used collaboratively, for example, a mashup that provides travel services needs photo, map, social, and other categories of APIs to complement each other to realize mutual supplementation of functionality. The complementary performance of the multiple cloud APIs is critical in creating this type of mashup, and the data show that, among the mashups that belong to this category and call more than two APIs, only 10% of mashups called only single category cloud APIs, while 41% of mashups called both the photo and map categories, and 28% of mashups called both the social and map categories. In addition, some mashups with more complex and diverse functions, such as e-commerce mashups, not only need multi-functional APIs for online payment, transportation, data storage, etc., but also need to integrate APIs provided by multiple different payment platforms and transportation service platforms to realize comprehensive services. Obviously, for such mashups, neither the similarity nor complementarity of the cloud API functions can be ignored.
Hence, it can be seen that equal treatment of cloud API similarity and complementarity features indicated by different types of side information will lead to the neglect of some potential preference information of mashups. To address this problem, this study introduces an attention mechanism to learn the preference scores of different mashups for cloud API similarity and complementarity and adds the mashup’s preference information to the cloud API’s feature representation. This enables the feature representation of cloud APIs to better fit the requirements of the mashups to be developed and improves the performance of mashup-oriented recommendations.
3.2. Definition
In order to better state the proposed problem and its solution in this paper, some definitions related to heterogeneous graphs are given below.
Definition 1 (Heterogeneous graph). A heterogeneous graph is defined as a graph associated with a node-type mapping function and an relation-type mapping function . and denote the sets of node types and relation types, respectively, with .
Definition 2 (Metapath). A metapath P is defined as a path in the form of , which describes a composite relation between node types and , where ∘ denotes the composition operator on relations.
Definition 3 (Metapath-based neighbor). Given a node v and a metapath P of a heterogeneous graph , the metapath-based neighbor is defined as the set of nodes that connect with node v through metapath P. Note that includes v itself if P is symmetric.
3.3. Problem Formulation
The core task of recommending cloud APIs for developers based on their requirements is to solve the problem of predicting the probability that a mashup may call cloud APIs. Therefore, a heterogeneous cloud API ecosystem graph is constructed, such as , where the node set contains the cloud API node set , the mashup node set , and the function tag node set and the relationship set is a set of multiple relationships between the different types of nodes listed above. The invocation relationship between mashups and cloud APIs can be defined as matrix , where represents whether the cloud API is invoked by mashup in binary form. If cloud API a is invoked by mashup m, then equals 1; otherwise, it equals 0. The set consisting of multiple function tags given by the developer for describing the requirements of the mashup is used to represent the features of the mashup m to be developed.
The probability that a given mashup
m with specific requirements may invoke cloud API
a is predicted using the above mashup–cloud API interaction matrix
Y and heterogeneous cloud API ecosystem graph
:
where
denotes the probability that mashup
m will invoke cloud API
a that has not been noticed, and
is the parameters of the model. On this basis, the top-N cloud APIs with the highest probability of being invoked by mashup
m are selected as the recommendation results of the mashup.
4. Method
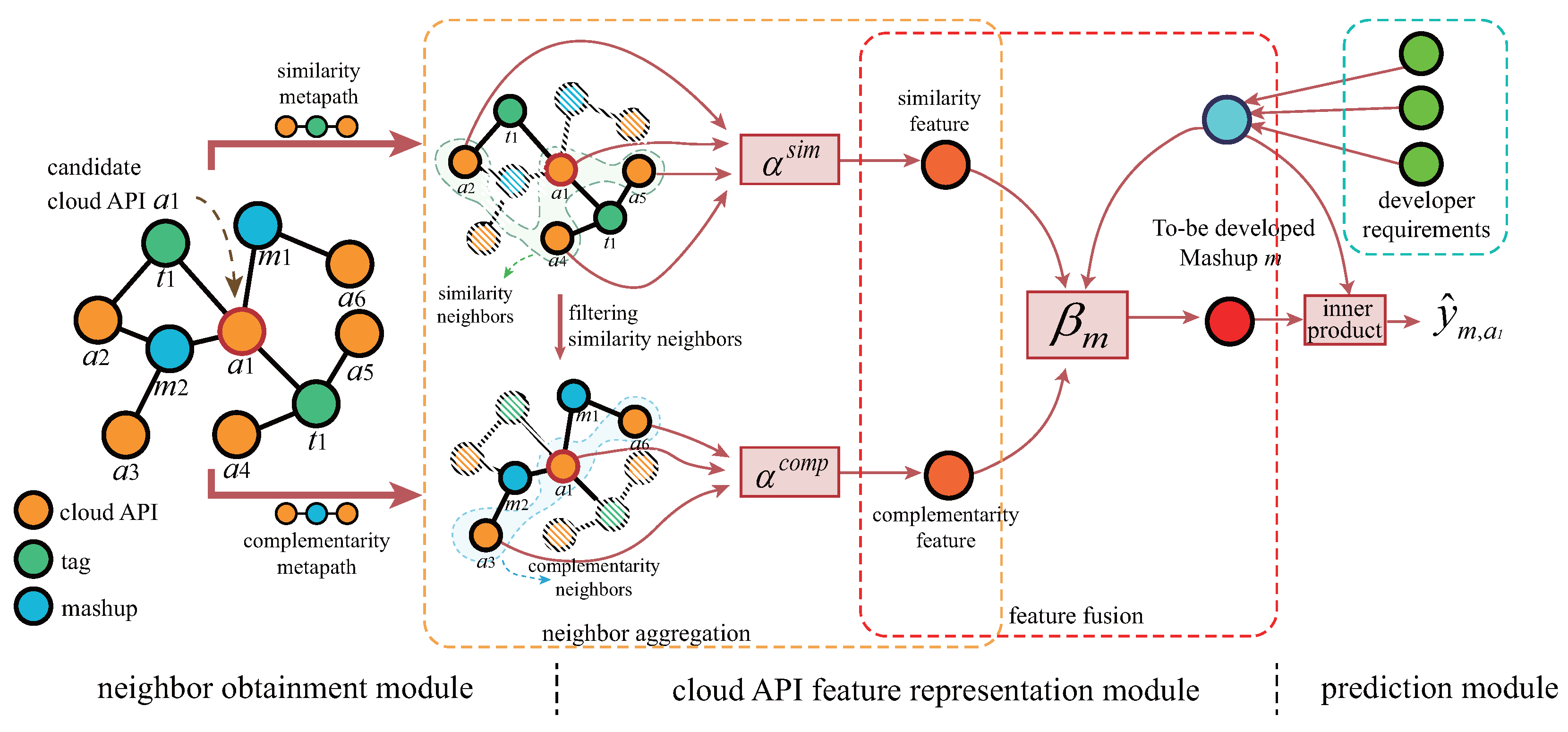
It is crucial to comprehensively and accurately describe the feature representation of cloud APIs in order to solve the problem of how to recommend the most appropriate cloud APIs to develop a mashup with a given requirement. In this study, a graph neural network algorithm based on a metapath and attention mechanism is used that comprehensively takes into account the functional similarities and functional complementarity of cloud APIs as well as the requirements of mashups to obtain a mashup requirements-aligned representation of cloud APIs that can be used to predict the probability of cloud API invocation by the target mashup. The overall framework of the proposed mashup-oriented cloud API recommendation method is given in
Figure 1. In the figure,
…
are the API nodes,
are the mashup nodes, and
are the tag nodes used to describe the functions of APIs.
and
denote the aggregation attention coefficients in the similarity metapath and complementarity metapath, respectively, and
denotes the inter-metapath fusion attention coefficient.
is the probability that mashup
m will invoke cloud API
. The method proposed consists of three parts:
In the neighbor obtainment module, similarity neighbors and complementarity neighbors of the cloud API are obtained by given metapaths, and two independent subgraphs are generated accordingly;
In the cloud API feature formation module, cloud API features are first initialized by utilizing the functional description information. Then, similarity neighbor features and complementarity neighbor features of cloud APIs are aggregated in two subgraphs. After that, the similarity features and complementarity features are fused by using the attention related to the mashup requirements provided by the developer to obtain a cloud API feature representation related to the to-be-developed mashup;
The prediction and recommendation module calculates the probability of candidate cloud APIs being invoked by the mashup with a given requirement, and the top-N cloud APIs with the highest probability are recommended to developers for mashup construction.
4.1. Neighbors Obtainment
The cloud API ecosystem accumulates a large amount of functional description information and interaction information about cloud APIs, mashups, etc. Making full use of this rich side information can effectively improve the accuracy and comprehensiveness of recommendations.
Therefore, a heterogeneous cloud API ecosystem graph, as in Definition 1, is constructed using data from the cloud API ecosystem. As shown in
Figure 1, the heterogeneous graph contains three types of nodes: cloud API, tag, and mashup. The labeling relationship between cloud API nodes and tag nodes, and the invocation relationship between cloud API nodes and mashup nodes are introduced to characterize the cloud APIs.
In heterogeneous graphs, metapaths can be used to analyze complex information, and different metapaths reveal different semantic features. In order to characterize cloud API similarity features and complementary features, respectively, the following two meta-paths are designed. And, according to Definition 3, the neighbors of cloud APIs with different semantic features under different meta-paths are obtained.
The similarity metapath ‘’ connects two APIs with certain similar functionality because both APIs have the same functional tag. Given a candidate cloud API, all the nodes in the graph that are connected to this node through instances of this metapath via intermediate nodes of type ‘tag’ are called similarity neighbors of the given cloud API node. For example, ‘yahoo-weather(API)’ is a similarity neighbor of ‘weather-channel(API)’, and they connect via the metapath instance ‘weather-channel → weather → yahoo-weather’.
The complementarity metapath ‘’ is used to indicate that two different categories of APIs have been invoked by the same mashup and that the two APIs may have certain complementary functions. The nodes that are connected to the candidate cloud API node through this metapath instance via the ‘mashup’ type intermediate nodes are called the complementarity neighbors of the candidate cloud API node. It should be noted that multiple cloud APIs invoked by the same mashup may also be similar cloud APIs used for refining a single functional requirement, which is obviously not suitable for describing complementarity features. Therefore, the complementarity neighbors’ obtainment needs to filter out the nodes that are identified as similarity neighbors other than itself beforehand.
Taking the node in
Figure 1 as an example, the similarity neighbors of the candidate node based on the similarity metapath ‘cloud API → tags → cloud API’ include
(itself),
,
, and
, and the complementarity neighbors of candidate node A1 based on the complementarity metapath ‘cloud API → mashup → cloud API’ include
(itself),
, and
. Obviously, neighbors based on different metapaths can utilize different structural information in the heterogeneous graph. Neighbors based on metapaths can be obtained by multiplication of sequences of adjacency matrices.
4.2. Feature Formation
The accurate, comprehensive, and purposeful characterization of cloud API features is the basis for achieving mashup-oriented cloud API recommendations, and an illustration of mashup requirements-aligned cloud API feature formation based on the graph neural network is given in
Figure 2. First, the cloud API feature representation vector is initialized using the functional description information of the cloud API, and a set of feature tags for describing the requirements given by the developer is used to vectorize the features of the mashup to be developed. Then, the neighbor features of cloud APIs are aggregated independently on different metapaths. Since neighbor nodes do not have exactly the same importance as candidate cloud API nodes, the self-attention mechanism is used to discover the differences between neighbors and learn the weights. Considering that different mashups have different preferences for similarity and complementarity, as mentioned earlier, attention related to the mashup is used to model the preference information of a given mashup to be developed. The biased fusion of cloud API similarity features and complementarity features achieves the integration of different semantic information in the graph and obtains cloud API features that align with the requirements proposed by mashup developers.
4.2.1. Mashup Requirements Representation
In this study, the features of a mashup are represented by a set of feature tags given by the developer for describing the requirements, e.g., the tags (social, e-commerce, reference) are used as inputs to the cloud API recommendation system to characterize the mashup of the relevant combination functions to be developed. Utilizing tags to describe items has been considered successful in numerous information systems, and this also applies to the cloud API ecosystem [
22]. In the cloud API ecosystem, the combination of multiple different tags can uniquely characterize mashup requirements, enabling the characterization of individual mashup requirements with fewer parameters. It also avoids the problem of vocabulary variance caused by developers’ free use of vocabulary and text describing requirements without predetermined standards [
14].
Specifically, according to the tags set
T in the cloud API ecosystem, the query information consisting of several tags that characterize the mashup function is given by the developer. For example, in order to find suitable sets of candidate cloud APIs to develop mashups
and
, the required feature set
and
should be given. The multi-hot embedding is utilized to represent mashups
and
as follow:
Then, the embedding technique
is used to map all tags to a low dimensional dense space, which is suitable for deep neural network training and learning, where d is the embedding dimension. Finally, to fully describe the requirement information, the mashup features are represented by aggregated tag embeddings, such as follows:
where
is the embedding of tag
, and
is the operation function used to aggregate tag embeddings. In our experiments, we assume that each tag is equally important to the mashup requirements; therefore,
is chosen as the averaging operation.
4.2.2. Intra-Metapath Aggregation
In the neighbor aggregation phase, the heterogeneous cloud API ecosystem graph is split into two homogeneous subgraphs according to the similarity and complementarity neighbors of the candidate cloud API nodes based on the metapaths. A graph attention neural network (GAT) [
25] is used to aggregate similarity neighbor features and complementarity neighbor features in different subgraphs, respectively. The GAT introduces an attention mechanism to achieve better neighbor aggregation. By learning the weights of neighbors, GAT can achieve weighted aggregation of neighbors. Therefore, GAT is not only more robust to noisy neighbors, but the attention mechanism also endows the model with a certain degree of interpretability, so that we can understand the contribution of each neighbor. To be specific, assume that the metapath-based subgraph has
n cloud API nodes, and the initial feature set of nodes is
…
. Given a metapath
P, a candidate cloud API node
a, and metapath-based neighbor node
, the importance of node
j to node
a can be obtained by the attention coefficient
. The calculation formula is as follows:
where ∥ means concatenation operation,
is the shared linear transformation weight matrix applied at each node,
is the attention vector for metapath
P, and
denotes the activation function, such as LeakyReLU.
According to the graph structure information, the mask attention mechanism is used to filter out nodes that are not neighbors of the target cloud API, and only calculate the attention coefficient
of the metapath-based neighbor
to the target cloud API node
a. In order to better distribute weights among different nodes, we need to normalize the attention coefficients via the softmax function:
It should be noted that
, since they have different orders when using the masked attention mechanism to calculate the attention score. Finally, the normalized attention coefficients are linearly combined with their corresponding features, and the final aggregated output of the cloud API node on the metapath-based subgraph is obtained as follows:
To sum up, given the cloud API initial feature vector and metapath set , where denotes similarity metapath and denotes complementarity metapath, aggregating the information in each metapath separately and independently, the feature representations set of cloud API node a under each metapath can be obtained.
4.2.3. Inter-Metapath Fusion
After obtaining similarity features and complementarity features of cloud API nodes on different metapaths, these two features need to be fused to integrate different semantic information in the heterogeneous cloud API ecosystem graph and achieve a comprehensive representation of cloud APIs. One of the most straightforward metapath fusion methods is to take the element-wise mean of these semantic feature vectors. However, we observed that different mashups pay different attention to similarity and complementarity; that is to say, for different mashups, different metapaths have different importance in the heterogeneous graph of the cloud API ecosystem.
Therefore, in order to achieve a mashup-oriented cloud API recommendation, mashup-metapath importance scores are learned in the feature fusion phase and are used to biasedly fuse cloud API features from different metapaths. Given a metapath
P, its importance to mashup
m can be calculated by the following equation:
where
are the representations of mashup and metapath, respectively. Function
is used to calculate the score, and the inner product is used in our experiments.
After obtaining the importance score of each metapath to mashup
m, the attention
of the metapath
P to mashup
m can be obtained by normalizing the above importance of all metapaths using the softmax function:
In order to obtain feature embedding for cloud API node
a aligned with mashup
m requirements, the above attention scores on metapaths are used as filters when computing the feature representation of candidate cloud API nodes. The final feature embedding of the candidate cloud API node
a about a specific given requirement mashup
m is obtained by linear combination:
4.3. Prediction and Recommendation
According to the above section, the cloud API personalized embedding
, which is related to the mashup
m, is obtained. This representation embedding contains cloud API functional similarity features and complementary features, which are fused according to the attention of the target mashup. Feeding the cloud API personality embedding
together with the corresponding mashup representation embedding
into the prediction function, the probability that the mashup
m may invoke the cloud API
a is predicted as follows:
Since the mashup-oriented cloud API recommendation is an implicit feedback problem, the target value
is a binary 1 or 0, which indicates whether mashup
m will invoke cloud API
a. So, in the above equation, we use the sigmoid function for the output. The loss function defined by cross entropy can better focus on the duality of implicit data [
6]. Therefore, the loss function is defined as:
where
Y is a training set of size
n, including mashup–API interaction data and random negative samples.
5. Experiments
In this section, we first detail the experimental setup, including the dataset, evaluation metrics, and parameter settings. Then, we outline a series of experiments that were conducted to answer the following research questions:
RQ 1: How does our proposed algorithm perform compared to state-of-the-art cloud API recommendation methods?
RQ 2: Does fusing similarity features and complementarity features to enhance cloud API feature representation improve the performance of recommendation algorithms?
RQ 3: Does biased fusion of similarity and complementarity using mashup-related attention benefit recommendation performance improvement?
RQ 4: Does splitting metapaths and using the attention mechanism to aggregate cloud API features improve recommendation performance?
RQ 5: How can our proposed approach be applied in reality?
5.1. Preparation
5.1.1. Datasets and Experiment Settings
In the experiments, the real data information was crawled from the ProgrammableWeb platform by the crawler program to obtain reliable experimental results. After data extraction and cleaning, the final experimental dataset was obtained, as shown in
Table 1. The experimental data of this article can be downloaded and obtained from our shared link on Github:
https://github.com/jiaojianz/CloudAPIdata, accessed on 22 November 2021.
Since there are no mashup–API rating data in this dataset, mashup-oriented cloud API recommendation is identified as an implicit feedback problem. So, we use their invoked data as the rates. For example, if mashup has invoked cloud API , the rating data are assigned a value of 1, and we use this value as the rating for the mashup–API pair. Furthermore, we randomly select some cloud APIs that are not used by the mashup and mark them as 0, as negative samples.
We randomly select 80% of existing mashups and their associated cloud APIs and categories for training, and the remaining 20% are divided equally for validation and testing. Our experiments were carried out at embedding size 64, learning rate 1 × 10−4, and dropout rate . An early stopping strategy was implemented in the experiments, and we considered the algorithm to converge if the loss increases on the training dataset or the evaluation metric recall decreases on the validation set for 10 consecutive epochs.
5.1.2. Evaluation Metrics
The performance of our model and baseline models are evaluated on the ProgrammableWeb dataset introduced above. To measure the performance of top-N recommendation sets, two commonly used metrics were chosen in our experiment: recall and normalized discounted cumulative gain (NDCG).
Given a full ranking with all cloud API candidates for target mashups, recall is a measure to calculate the proportion of the top-N-related cloud APIs out of all true related cloud APIs.
where
is the true cloud API set that a mashup invoked,
is the top-N recommended cloud API set.
NDCG is a measure of ranking quality in which positions are log-discounted. The location of correct recommendations is accounted for by introducing a location influence factor that assigns higher scores to top-ranked correct recommendations.
where
is discounted cumulative gain,
represents the relevance score of the recommendation result at position i, and
is the ideal
of the ranking lists of candidates.
5.2. Experimental Results
5.2.1. Performance Comparison
Since there is currently no universally applied baseline model for mashup-oriented cloud API recommendation, some widely used methods and some recent state-of-the-art methods are selected to compare the performance of our proposed method. Some of them have been shown to be applicable to cloud API recommendations. The baseline recommendation methods chosen for comparison covered three categories, including historical interaction-based recommendations (POP, BPR, NGCF, DMF), context-aware recommendations (DeepFM, AFM), and knowledge-based recommendations (KGCN, MKR, KGAT). Brief descriptions of the baseline methods are as follows:
Table 2 and
Table 3 show the performance comparison results of our method and several baseline recommendation methods introduced above. A larger recall and NDCG indicate better performance.
The experimental results show that the method proposed in this paper achieves the best performance as it achieves higher recall and NDCG in each top-N recommendation list, which indicates that our method is effective.
In the above comparison experiments, the methods POP, BPR, NGCF, and DMF only exploit the implicit interaction relationship between mashup and cloud API for recommendation, while DeepFM and AFM, two methods based on factorized machines, incorporate tag features to enhance the vector representation of mashup and cloud API. KGCN, MKR, and MKR are implemented based on graph structures. Both recall and NDCG methods that consider tag information and graph features perform significantly better than the recommended methods that only consider interaction information. It can be seen that introducing information other than interaction information in mashup-oriented cloud API recommendation can effectively improve recommendation performance.
5.2.2. Ablation Experiments
In the previous section, we pointed out that, in addition to cloud API functional similarity features, historical common invocation information of multiple cloud APIs is beneficial for improving the accuracy of mashup-oriented cloud API recommendations. Therefore, it is necessary to verify whether introducing common invoked information characterizing cloud API complementary in cloud API recommendation systems can lead to improved recommendation performance.
Figure 3a,b gives the ablation experiments of our proposed algorithm, giving a comparison of experiments considering only cloud API similarity features and cloud API complementary features, and considering both features based on attention mechanisms. In addition, we also utilize other graph-based recommendation models, KGCN and KGAT, for validating the impact of introducing cloud API functional similarity and complementary on recommendation performance and comparing them with our algorithm; the validation results are also given in
Figure 3. In the experiments, KGCN-S, KGAT-S, and ours-S indicate that only the functional similarity of cloud APIs is considered, and KGCN-C, KGAT-C, and ours-C indicate that only the complementary feature of cloud APIs is considered.
The experimental results show a significant improvement in improving the recommendation performance by considering the functional similarity and complementary of cloud API together. We observe that both Recall and NDCG, which consider only functional similarity, are significantly lower than combining functional similarity and complementary at different values of top-N. This indicates that adding auxiliary information characterizing cloud API complementary feature to mashup-oriented cloud API recommendations will indeed greatly improve the recommendation performance.
5.2.3. Impact of Mashup-Related Attention Fusion
In metapath-based graph neural network algorithms, such as HAN [
34] and MAGNN [
35], the fusion of metapaths usually employs a global-based self-attention mechanism. We considered that different mashups may have different preferences for cloud API functional similarity and complementarity, and designed a mashup-related attention for the fusion of different paths.
We compared the experimental results using equal attention, self-attention, and mashup-related attention in the metapath fusion module, as shown in
Table 4 and
Table 5.
It can be seen that the method of mashup-related attention fusion in this paper obtains the best results at any value of top-N, which greatly improves the recommendation performance. In addition, it can be seen that the performance of recommendations based on the fusion of the equal attention mechanism and the self-attention mechanism does not differ much. The self-attention scores are given subsequently in our case study experimental section, and the experiment results illustrate that similarity features and complementarity features are almost equally important for mashup-oriented cloud API recommendation in the whole cloud API ecosystem without considering the mashup’s different requirements. This clearly leads to the mashup’s requirements being ignored, and thus the recommendation is less effective than the proposed method of recommending cloud APIs that align with the mashup’s requirements.
5.2.4. Impact of Aggregation Algorithms and Introduction of Metapath
In the metapath aggregation module, graph attention neural networks are used to compute metapath-based cloud API representations on each subgraph of metapath-based neighbors in this paper. To verify that the introduction of attention mechanisms can better implement mashup-oriented cloud API recommendations, we replaced the metapath internal aggregation algorithm for comparison. Two representative graph neural networks, GCN and GraghSAGE, were chosen for comparison.
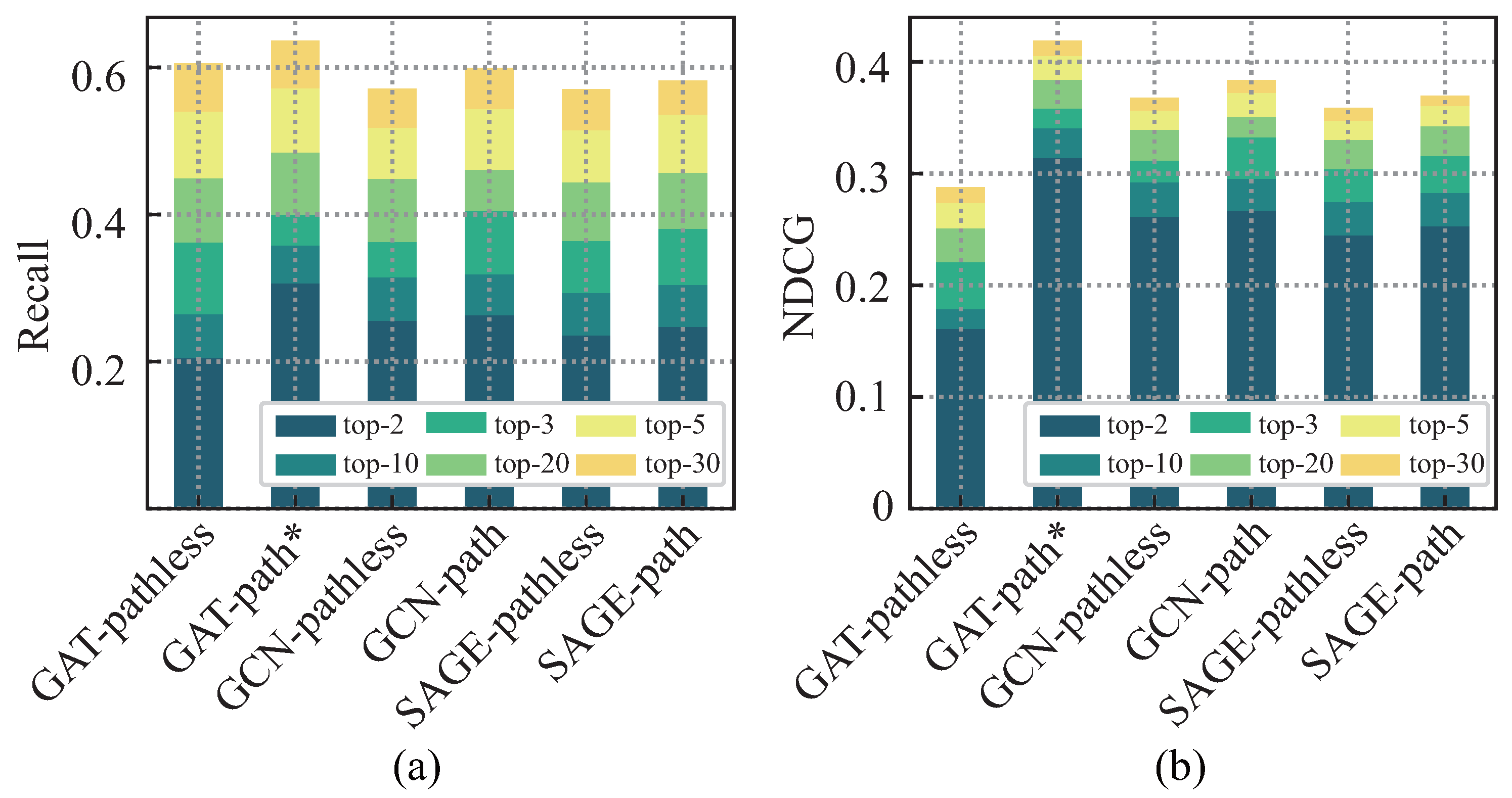
In
Figure 4, the GAT-path indicates that the functional similarity and complementarity of cloud APIs are computed separately by different metapaths, and the graphical attention algorithm is used in the internal aggregation module of the metapaths, i.e., the method proposed in this paper. The GCN-path and SAGE-path indicate the replacement of the internal aggregation module with GCN and GraphSAGE, respectively. As we can see in the figure, the aggregation of metapath-based neighbors using the attention mechanisms achieved better results: recall is higher than the aggregation using the GCN and GraphSAGE algorithms, and NDCG has a significant improvement.
Furthermore, in order to prove that the calculation of functional similarity features and complementary features of cloud APIs based on metapaths is helpful for mashup-oriented cloud API recommendation after the reasonable division of metapaths, we conducted comparative experiments to verify whether introducing metapaths can improve the recommendation.
In
Figure 4, GAT-pathless, GCN-pathless, and SAGE-pathless indicate the aggregation of web ecosystem graphs directly using GAT, GCN, and GraphSAGE algorithms, respectively, without considering the different concerns of cloud API functional similarity and complementary based on metapaths.
As shown in
Figure 4, regardless of which aggregation algorithm is used, adding metapaths to consider the functional similarity and complementarity of cloud APIs can improve the recommendation performance to some extent. This result proves that, as proposed in this paper, it is necessary to consider that different mashups pay different attention to cloud API similarity features and relevance in mashup recommendations. After distinguishing cloud API similarity features and complementary features and calculating them separately, weighted fusion of feature vectors from different paths based on mashup preferences can help improve recommendation performance.
5.2.5. Case Study
In order to demonstrate the availability and usefulness of the proposed method more intuitively, actual mashups were selected as examples. Tags indicate the functions or services offered by the mashup. Therefore, developer requirements, which are used as inputs to characterize the mashup, are represented by tags. The actual tags of the example mashups are selected as follows:
Based on the given requirements, the similarity and complementarity features of the candidate cloud APIs are learned separately using attention graph neural networks. Based on the given requirements, the similarity and complementarity features of the candidate cloud APIs are learned separately using attention graph neural networks. Then, the attention scores of the to-be-developed mashup for the similarity and complementarity features are computed, and the results are given in
Table 6. For comparison, the global self-attention that is not associated with the mashup is given at the same time.
The above attention scores are used to fuse the similarity and complementarity features of the candidate cloud APIs, and these features are used to predict the probabilities that the given mashup may invoke each cloud API. Candidate cloud APIs with high probability are recommended for the mashup.
Table 7 gives the list of the top five cloud API recommendations for mashup instances under four scenarios: considering only similarity, considering only complementarity, fusion by self-attention, and fusion by mashup-related attention.
In actuality, mashup1 calls six cloud APIs, namely, amazon-product-advertising (advertising, e-commerce), amazon-a9-opensearch (search), Youtube (video, media), and Facebook (social, webhooks), amazon-simpledb (database), amazon-marketplace-web-service (e-commerce), and mashup2 calls three cloud APIs, namely, google-maps (mapping, viewer), yahoo-maps (mapping, viewer), and yahoo-geocoding (mapping, addresses).
From the recommendation results in
Table 7, it can be seen that the recommendation results that only consider similarity often contain multiple similar cloud APIs, which are not applicable to all types of mashups, whereas in the recommendation that only considers complementarity, multiple types of APIs are recommended, but functional similarity is ignored, which means that the recommended APIs may not be able to satisfy the functional requirements of mashups. The self-attention scores of different features are almost equal without considering alignment with mashup requirements, indicating that similarity features and complementarity features are almost equally important in the global consideration towards the cloud API ecosystem, but this obviously leads to mashup’s requirements being neglected. Our method, on the other hand, is based on the mashup-related attention mechanism, which fully considers the needs of different mashups and can more effectively give a recommended list of cloud APIs that are aligned with the mashup’s requirements.





{kind=link}
{kind=link}
{kind=link}
{kind=link}