
A Novel Complex-Valued Hybrid Neural Network for Automatic Modulation Classification


Abstract
:1. Introduction
2. Signal Model and Proposed System Model
2.1. Signal Model
2.2. Complex-Valued Operations
2.2.1. Complex Convolution (CConv)
2.2.2. Complex ReLU (CReLU)
2.2.3. Complex-Valued GRU (CGRU)
2.2.4. Complex Softmax (CSoftmax)
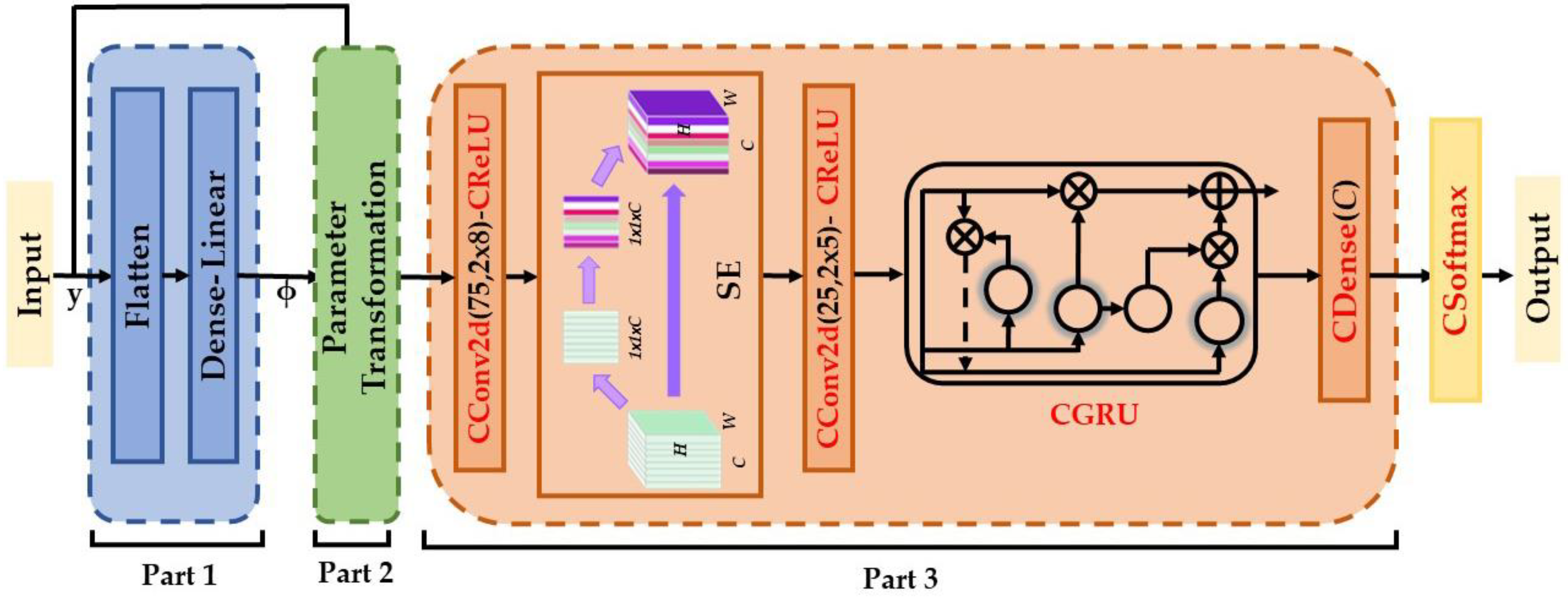
2.3. The Proposed Complex-Valued PET-CSGDNN Model
3. Experiments
3.1. Datasets and Experimental Conditions
3.2. Evaluation Method
3.3. Experiment Settings
4. Results and Discussions
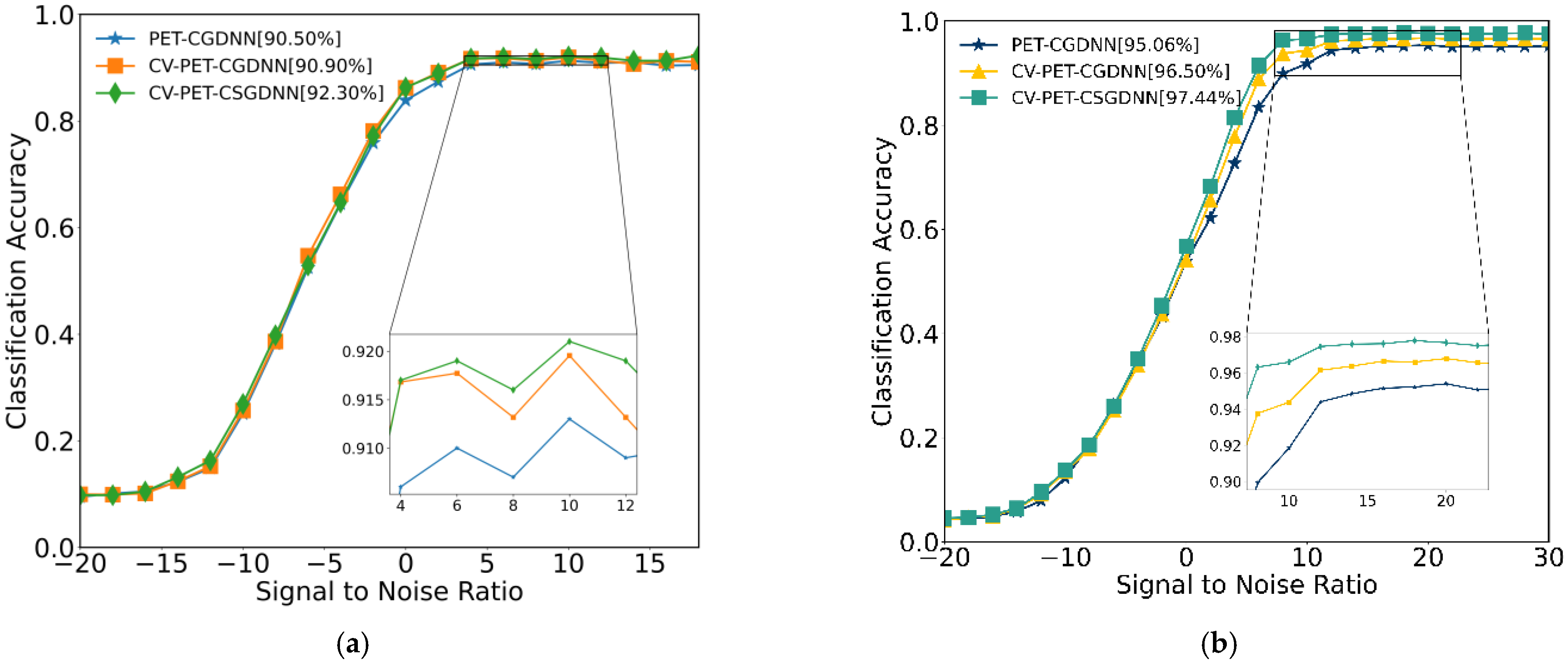
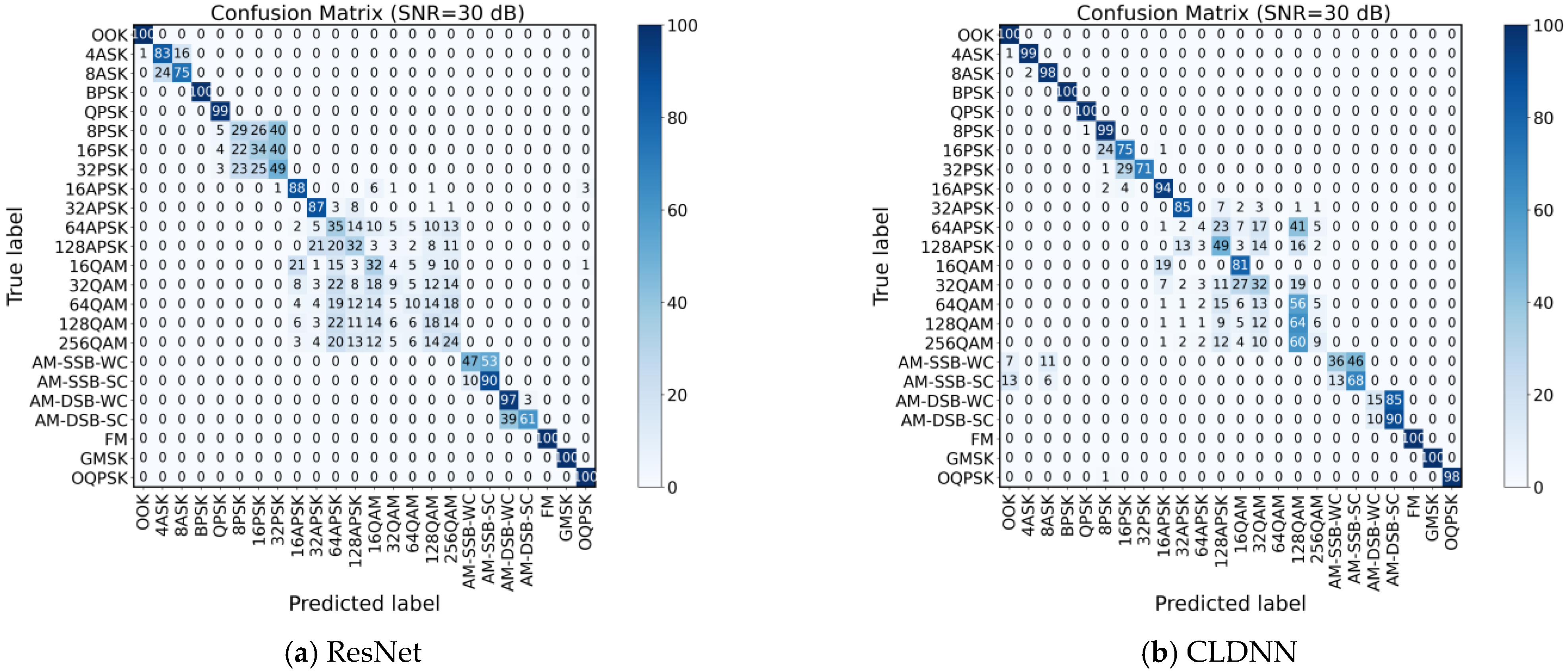
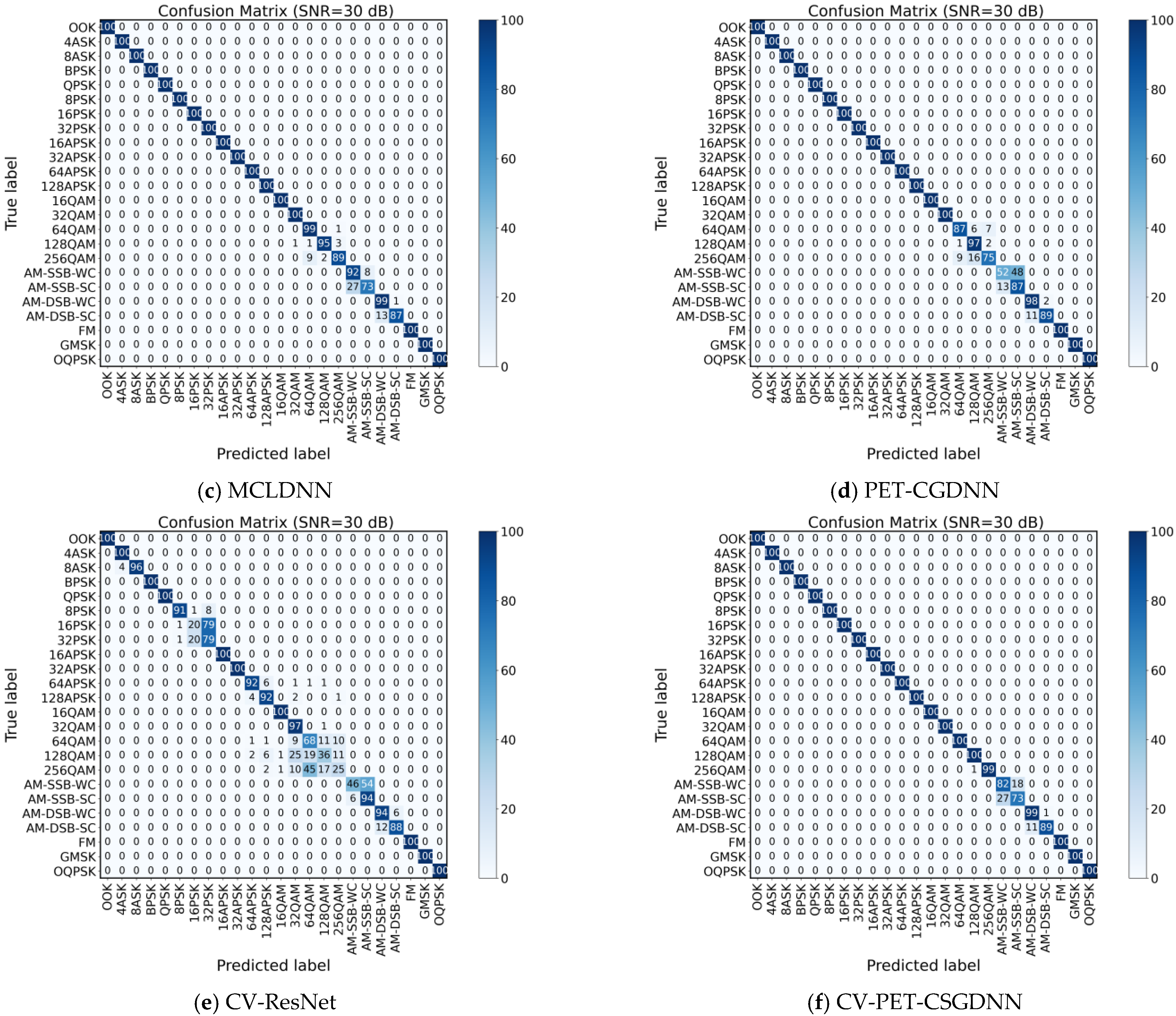
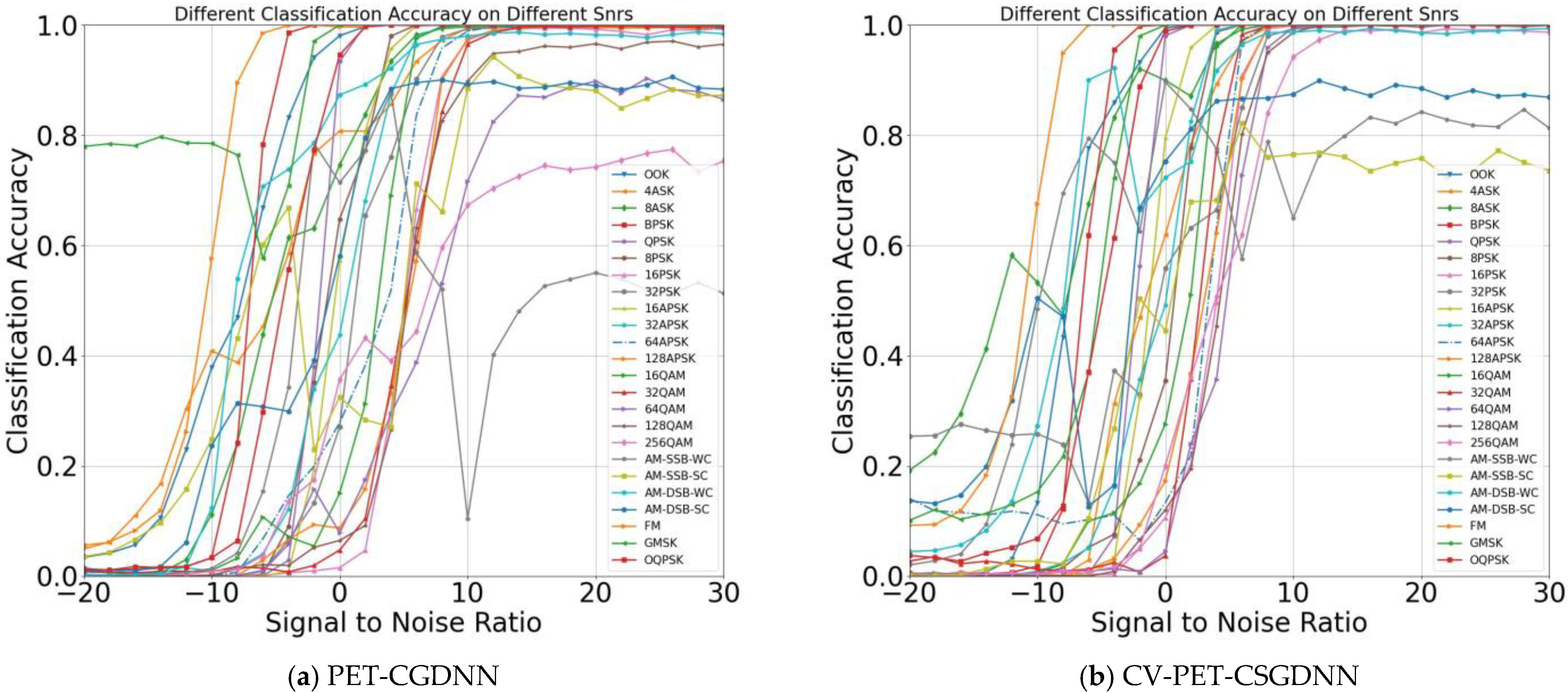
4.1. Ablation Experiments
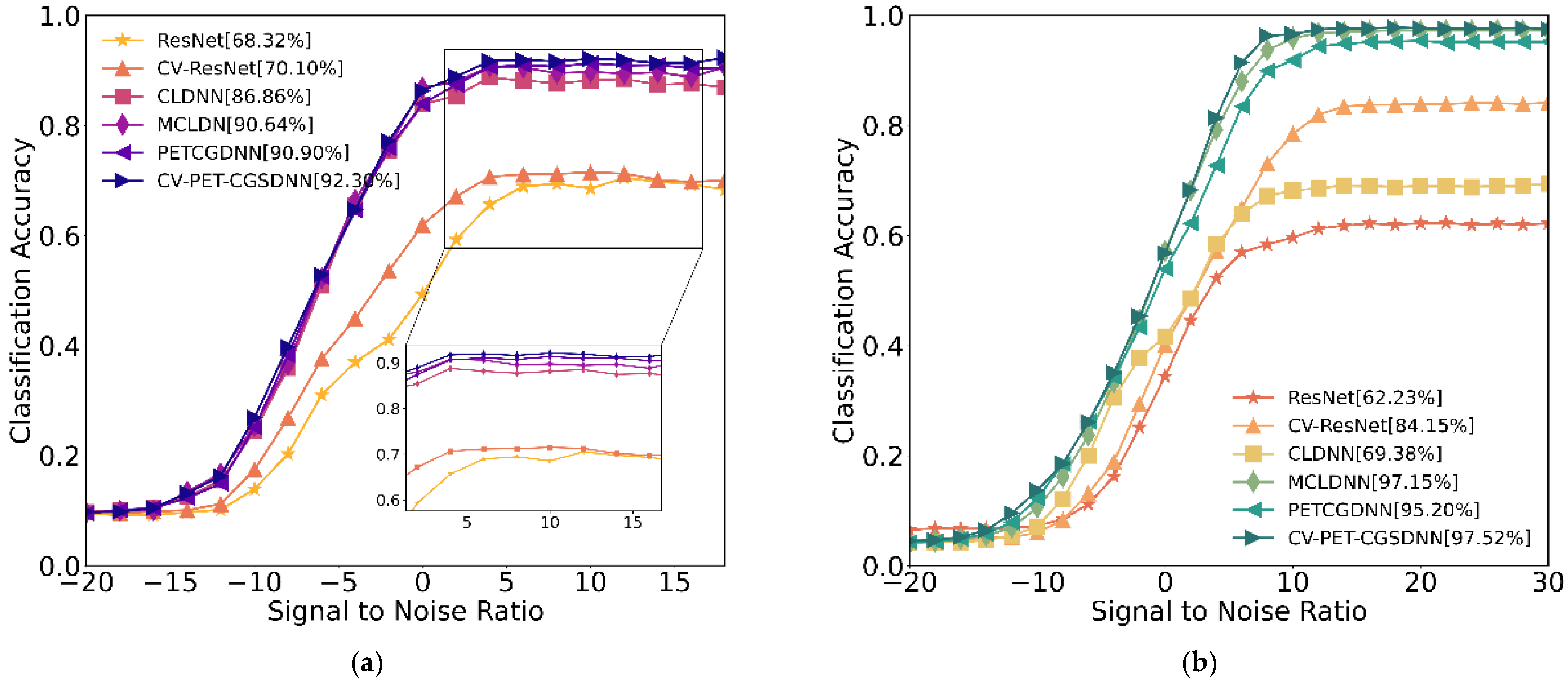
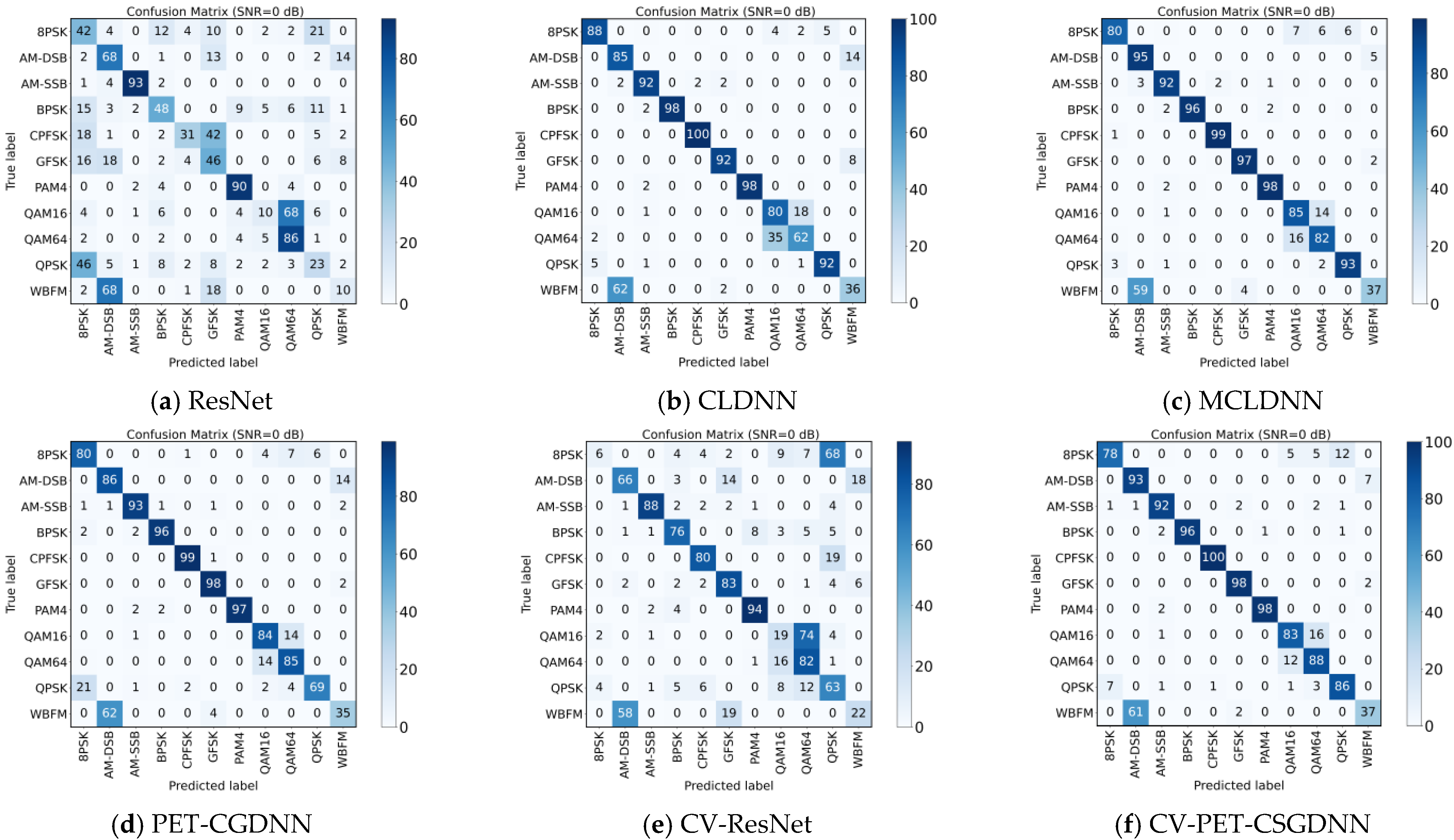
4.2. Comparative Experiments of Different Networks
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviations | Explanation |
|---|---|
| CNN | Convolutional Neural Network |
| GRU | Gate Recurrent Unit |
| DNN | Dense Neural Network |
| ResNet | Residual Neural Network |
| RNN | Recurrent neural Network |
| LSTM | Long Short-Term Memory |
| CVNN | Complex-valued Neural Network |
| RVNN | Real-valued Neural Network |
References
- Huynh-The, T.; Pham, Q.-V.; Nguyen, T.-V.; Nguyen, T.T.; Ruby, R.; Zeng, M.; Kim, D.-S. Automatic Modulation Classification: A Deep Architecture Survey. IEEE Access 2021, 9, 142950–142971. [Google Scholar] [CrossRef]
- Zhang, F.; Luo, C.; Xu, J.; Luo, Y.; Zheng, F.-C. Deep learning based automatic modulation recognition: Models, datasets, and challenges. Digit. Signal Process. 2022, 129, 10365. [Google Scholar] [CrossRef]
- Hong, D.; Zhang, Z.; Xu, X. IEEE Automatic Modulation Classification using Recurrent Neural Networks. In Proceedings of the 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017. [Google Scholar]
- Li, L.; Dong, Z.; Zhu, Z.; Jiang, Q. Deep-Learning Hopping Capture Model for Automatic Modulation Classification of Wireless Communication Signals. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 772–783. [Google Scholar] [CrossRef]
- Li, W.; Xie, W.; Wang, Z. Complex-Valued Densely Connected Convolutional Networks. In Data Science; Zeng, J., Jing, W., Song, X., Lu, Z., Eds.; Springer: Berlin/Heidelberg, Germany; Singapore, 2020; pp. 299–309. [Google Scholar]
- Zeng, Z.; Sun, J.; Han, Z.; Hong, W. SAR Automatic Target Recognition Method Based on Multi-Stream Complex-Valued Networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5228618. [Google Scholar] [CrossRef]
- Tu, Y.; Lin, Y.; Hou, C.; Mao, S. Complex-Valued Networks for Automatic Modulation Classification. IEEE Trans. Veh. Technol. 2020, 69, 10085–10089. [Google Scholar] [CrossRef]
- Zhang, F.; Luo, C.; Xu, J.; Luo, Y. An Autoencoder-Based I/Q Channel Interaction Enhancement Method for Automatic Modulation Recognition. IEEE Trans. Veh. Technol. 2023, 72, 9620–9625. [Google Scholar] [CrossRef]
- Bassey, J.; Li, X.; Qian, L. A Survey of Complex-Valued Neural Networks. arXiv 2021, arXiv:2101.12249v1. [Google Scholar]
- Hirose, A. Complex-Valued Neural Networks (Studies in Computational Intelligence); Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Hirose, A. Complex-valued neural networks: The merits and their origins. In 2009 International Joint Conference on Neural Networks; IEEE: Atlanta, GA, USA, 2009; pp. 1237–1244. [Google Scholar]
- Kim, S.; Yang, H.-Y.; Kim, D. Fully Complex Deep Learning Classifiers for Signal Modulation Recognition in Non-Cooperative Environment. IEEE Access 2022, 10, 20295–20311. [Google Scholar] [CrossRef]
- Hirose, A.; Yoshida, S. Comparison of Complex- and Real-Valued Feedforward Neural Networks in Their Generalization Ability. In Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2011; pp. 526–531. [Google Scholar]
- Lee, C.; Hasegawa, H.; Gao, S. Complex-Valued Neural Networks: A Comprehensive Survey. IEEE/CAA J. Autom. Sin. 2022, 9, 1406–1426. [Google Scholar] [CrossRef]
- Hirose, A. Continuous complex-valued back-propagation learning. Electron. Lett. 1992, 28, 185. [Google Scholar] [CrossRef]
- Hirose, A. Dynamics of fully complex-valued neural networks. Electron. Lett. 1992, 28, 1492. [Google Scholar] [CrossRef]
- Hirose, A. Complex-valued neural networks: Distinctive features. Stud. Comput. Intell. 2006, 400, 17–56. [Google Scholar]
- Hirose, A. Recent Progress in Applications of Complex-Valued Neural Networks. In Proceedings of the International Conference on Artifical Intelligence & Soft Computing, Zakopane, Poland, 13–17 June 2010. [Google Scholar]
- Hirose, A.; Yoshida, S. Generalization Characteristics of Complex-Valued Feedforward Neural Networks in Relation to Signal Coherence. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 541–551. [Google Scholar] [CrossRef]
- Nitta, T. On the critical points of the complex-valued neural network. In Proceedings of the 9th International Conference on Neural Information Processing, 2002, ICONIP ’02, Singapore, 18–22 November 2002. [Google Scholar]
- Arjovsky, M.; Shah, A.; Bengio, Y. Unitary Evolution Recurrent Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; p. 4. [Google Scholar]
- Danihelka, I.; Wayne, G.; Uria, B.; Kalchbrenner, N.; Graves, A. Associative Long Short-Term Memory. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; p. 48. [Google Scholar]
- Wisdom, S.; Powers, T.; Hershey, J.R.; Le Roux, J.; Atlas, L. Full-Capacity Unitary Recurrent Neural Networks. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 9 December 2016; p. 29. [Google Scholar]
- Trabelsi, C.; Bilaniuk, O.; Zhang, Y.; Serdyuk, D.; Subramanian, S.; Santos, J.; Mehri, S.; Rostamzadeh, N.; Bengio, Y.; Pal, C. Deep Complex Networks. In Proceedings of the ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Marseet, A. Application of Convolutional Neural Network Framework on Generalized Spatial Modulation for Next Generation Wireless Networks. Graduate Thesis, Rochester Institute of Technology, Rochester, NY, USA, April 2018. [Google Scholar]
- Chang, Z.; Wang, Y.; Li, H.; Wang, Z. IEEE Complex CNN-Based Equalization for Communication Signal. In Proceedings of the 4th IEEE International Conference on Signal and Image Processing (ICSIP), SE University, Wuxi, China, 19–21 July 2019. [Google Scholar]
- Krzyston, J.; Bhattacharjea, R.; Stark, A. Complex-Valued Convolutions for Modulation Recognition using Deep Learning. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Xu, J.; Wu, C.; Ying, S.; Li, H. The Performance Analysis of Complex-Valued Neural Network in Radio Signal Recognition. IEEE Access 2022, 10, 48708–48718. [Google Scholar] [CrossRef]
- Zhang, F.; Luo, C.; Xu, J.; Luo, Y. An Efficient Deep Learning Model for Automatic Modulation Recognition Based on Parameter Estimation and Transformation. IEEE Commun. Lett. 2021, 25, 3287–3290. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. arXiv 2019, arXiv:1709.01507. [Google Scholar]
- O’Shea, T.J.; Roy, T.; Clancy, T.C. Over-the-Air Deep Learning Based Radio Signal Classification. IEEE J. Sel. Top. Signal Process. 2018, 12, 168–179. [Google Scholar] [CrossRef]
- Liu, X.; Yang, D.; El Gamal, A. Deep Neural Network Architectures for Modulation Classification. In Conference Record of the Asilomar Conference on Signals Systems and Computers, Proceedings of the 51st IEEE Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; IEEE: Atlanta, GA, USA, 2017; pp. 915–919. [Google Scholar]
- Xu, J.; Luo, C.; Parr, G.; Luo, Y. A Spatiotemporal Multi-Channel Learning Framework for Automatic Modulation Recognition. IEEE Wirel. Commun. Lett. 2020, 9, 1629–1632. [Google Scholar] [CrossRef]
| Dataset | Modulation Schemes | Sample Dimension | Dataset Size | SNR Range (dB) |
|---|---|---|---|---|
| RML2016.10a | 11 classes (8PSK, BPSK, CPFSK, GFSK, PAM4, 16QAM, AM-DSB, AM-SSB, 64QAM, QPSK, WBFM) | 128 × 2 | 220,000 | −20:2:18 |
| RML2018.01a | 24 classes (OOK, 4ASK, 8ASK, BPSK, QPSK, 8PSK, 16PSK, 32PSK, 16APSK, 32APSK, 64APSK, 128APSK, 16QAM, 32QAM, 64QAM, 128QAM, 256QAM, AM-SSB-WC, AM-SSB-SC, AM-DSB-WC, AM-DSB-SC, FM, GMASK, OQPSK) | 1024 × 2 | 2,555,904 | −20:2:30 |
| Model | ResNet | CLDNN | MCLDNN | PET-CGDNN |
|---|---|---|---|---|
| Input | I/Q | I/Q | I/Q, I and Q | I/Q |
| Convolution Layers | 4 | 3 | 5 | 2 |
| Kernel Size | 3 × 1, 3 × 2, 3 × 1, 3 × 1 | 8 × 1 | 8 × 2, 7, 7, 8 × 1, 5 × 2 | 2 × 8, 1 × 5 |
| Convolution Channels | 256, 256, 80, 80 | 50 × 3 | 50 × 4 | 75, 25 |
| LSTM Layers | 0 | 1 | 1 | 0 |
| LSTM Units | 0 | 50 × 1 | 128 × 1 | 0 |
| Dense | 2 (128, C *) | 1 (256, C *) | 3 (128, 128, C *) | 1 (C *) |
| Model | CV-ResNet | CV-PET-CSGDNN |
|---|---|---|
| Input | I/Q | I/Q |
| Complex Convolution | 4 | 2 |
| Kernel Size | 3, 3, 3, 3 | 8, 5 |
| Convolution Channels | 64,64,20,20 | 75, 25 |
| Complex-valued GRU | 0 | 1 (128) |
| Complex-valued Dense | 2 (128, C *) | 1 (C *) |
| Dataset | A (6:2:2) | B (3:4:4) | |
|---|---|---|---|
| Model | |||
| PET-CGDNN | 60.60% | 60.29% | |
| CV-PET-CGDNN | 60.90% | 61.67% | |
| CV-PET-CSGDNN | 61.50% | 62.89% | |
| Model | Data- Sets | Capacity * | Training Time (Second /Epoch) | Test Time (ms/Sample) | Average Accuracy (All SNR) | Average Accuracy (≥0 dB) | Highest Accuracy |
|---|---|---|---|---|---|---|---|
| ResNet | A | 3098 K | 11.085 | 11.381 | 42.51% | 65.89% | 69.78% |
| B | 2660 K | 431.620 | 12.211 | 39.55% | 57.89% | 62.23% | |
| CLDNN | A | 76 K | 23.055 | 0.540 | 59.14% | 87.22% | 88.45% |
| B | 80 K | 527.657 | 1.958 | 44.93% | 64.85% | 69.38% | |
| MCLDNN | A | 405 K | 19.379 | 0.023 | 60.51% | 89.37% | 90.73% |
| B | 408 K | 427.981 | 0.850 | 61.84% | 90.86% | 97.29% | |
| PET-CGDNN | A | 71 K | 12.200 | 0.010 | 60.60% | 89.80% | 91.27% |
| B | 75 K | 181.658 | 0.237 | 60.25% | 87.80% | 95.45% | |
| CV-ResNet | A | 364 K | 11.980 | 0.010 | 46.27% | 69.45% | 71.45% |
| B | 2660 K | 183.692 | 0.397 | 49.97% | 74.95% | 84.15% | |
| CV-PET-CSGDNN | A | 86 K | 15.147 | 0.023 | 61.50% | 90.90% | 92.32% |
| B | 90 K | 384.298 | 0.827 | 62.92% | 91.67% | 97.75% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Hou, S.; Fang, S.; Hu, H.; Ma, Z. A Novel Complex-Valued Hybrid Neural Network for Automatic Modulation Classification. Electronics 2023, 12, 4380. https://doi.org/10.3390/electronics12204380
Xu Z, Hou S, Fang S, Hu H, Ma Z. A Novel Complex-Valued Hybrid Neural Network for Automatic Modulation Classification. Electronics. 2023; 12(20):4380. https://doi.org/10.3390/electronics12204380
Chicago/Turabian StyleXu, Zhaojing, Shunhu Hou, Shengliang Fang, Huachao Hu, and Zhao Ma. 2023. "A Novel Complex-Valued Hybrid Neural Network for Automatic Modulation Classification" Electronics 12, no. 20: 4380. https://doi.org/10.3390/electronics12204380
APA StyleXu, Z., Hou, S., Fang, S., Hu, H., & Ma, Z. (2023). A Novel Complex-Valued Hybrid Neural Network for Automatic Modulation Classification. Electronics, 12(20), 4380. https://doi.org/10.3390/electronics12204380