1. Introduction
The rapid development of the Internet of Things (IoT) has completely transformed many industries, such as smart homes, smart agriculture, healthcare, and more [
1]. According to survey data, the number of IoT devices is projected to exceed 4.1 billion by 2025 [
2]. In everyday life, IoT devices play a crucial role in people’s lives. However, the extensive connectivity of these devices to the internet exposes them to various security risks. For example, IoT devices exchange information over the internet and are susceptible to numerous network attacks, compromising their security. According to a report by Nozomi Networks, new IoT botnet attacks increased rapidly in the first half of 2020, with 57% of IoT devices being vulnerable targets [
3]. Furthermore, attackers can launch denial-of-service (DoS) attacks, depleting network and device resources [
4]. Therefore, enhancing the security of IoT devices has become a critical area of research [
5]. To mitigate the risks posed by different types of attacks, researchers are developing intrusion detection systems to identify malicious behavior in networks. Intrusion detection systems monitor systems in real-time and issue warnings in case of any anomalies, thereby enhancing the security of communication.
In recent years, machine learning, with its rapid development, has found extensive applications in the field of intrusion detection [
6,
7]. Machine learning algorithms offer unique advantages compared to traditional detection methods. They can not only learn complex patterns and rules from large volumes of data but also handle high-dimensional and nonlinear data, making them more suitable for intrusion detection in complex systems. Furthermore, with the advancement of networks, a significant amount of network data, including samples of various intrusion and abnormal behaviors, has been accumulated. This rich dataset provides ample training samples for machine learning, ensuring excellent detection performance of machine learning algorithms. However, despite the achievements of machine learning algorithms, there are still some challenges and issues that need to be addressed.
The real-time capability of an IoT device intrusion detection system is a crucial consideration for ensuring network security. IoT devices typically have limited computational resources and storage capacity. Due to these resource constraints, the system may struggle to efficiently process and analyze a large amount of network traffic data, leading to delays or inability to meet real-time requirements in detection. Additionally, in the face of frequent network attacks on IoT devices and the constant evolution of attack techniques, intrusion detection systems are under increasing pressure to detect such attacks [
8]. The generation of a vast amount of network traffic data introduces significant redundancy and irrelevant features. Redundant features in the data can lead to overfitting during the model learning process, ultimately diminishing detection performance [
9]. One effective approach to address feature redundancy is feature selection. Feature selection plays a crucial role in machine learning-based intrusion detection systems, reducing the dimensionality of the dataset, lowering training time and computational costs, while improving model performance [
10]. Recently, metaheuristic algorithms have gained considerable attention in the field of feature selection due to their excellent global search capabilities [
11]. Commonly used metaheuristic algorithms include genetic algorithm (GA), particle swarm optimization (PSO) [
12], whale optimization algorithm (WOA) [
13], grey wolf optimization (GWO) [
14], and simulated annealing (SA), among others. Among these algorithms, GWO has garnered considerable interest due to its ease of implementation, fast convergence speed, and strong optimization capabilities. To better utilize GWO for feature selection problems, Emary et al. proposed a novel binary grey wolf optimization (BGWO) [
15]. Hsu et al. [
16] pointed out that hybrid feature selection methods outperform individual feature selection methods. Furthermore, recursive feature elimination (RFE), a wrapper feature selection method, strikes a good balance between accuracy and runtime, preserving a certain level of accuracy while reducing runtime. In this study, we propose a novel two-stage feature selection method that combines the strengths of BGWO and RFE. This method reduces the search space for feature subsets and eliminates redundant features.
Our main contributions are as follows:
We propose an intrusion detection system based on XGBoost, utilizing a novel two-stage feature selection method called BGWO-RFE-XGBoost. Initially, BGWO is used to preliminarily filter a large number of features, removing those that have minimal impact on the target variable. Then, RFE-XGBoost is employed for further fine-grained feature selection, resulting in the final feature subset. This two-stage feature selection method maximizes the accuracy and generalization capability of the model.
We conduct extensive experiments on five publicly available datasets in the IoT domain to validate the effectiveness of our approach. The results outperform other state-of-the-art methods in both binary and multi-class classification experiments. Particularly, experiments on the N-BaIoT dataset demonstrate that using the proposed hybrid feature selection method reduces the model’s runtime by 39.66% without sacrificing accuracy.
The rest of this paper is organized as follows:
Section 2 presents recent relevant research in the field of intrusion detection.
Section 3 describes the proposed method.
Section 4 presents the experimental details and results.
Section 5 concludes the paper and suggests future work.
2. Related Works
Recently, machine learning techniques have been widely applied in the field of intrusion detection in the Internet of Things (IoT) and have achieved excellent results. Intrusion detection systems based on machine learning are typically divided into two parts. The first part is data preprocessing, which involves preprocessing the data before feeding it into the model. This includes feature selection and handling imbalanced datasets, to provide better inputs to the model. The second part is the classifier, where selecting an appropriate model can maximize the intrusion detection rate. Therefore, many researchers have focused their efforts on these two aspects to create powerful intrusion detection systems. In this section, we will review the recent work.
Lazzarini et al. [
17] built an IoT intrusion detection system using an ensemble stacking approach. They combined four different deep learning models (MLP, DNN, CNN, and LSTM) to detect and classify attacks in IoT environments. Binary and multi-class experiments were conducted on the Ton-IoT and CIC-IDS2017 datasets. The results showed that the proposed method was able to detect the majority of attacks with particularly low false positive (FP) and false negative (FN) rates. However, this approach integrates four different models, which requires a significant amount of resources and further evaluation of its performance on real IoT devices. Alani [
18] used feature importance-based recursive feature elimination (RFE) for feature selection on the dataset, selecting the top 11 most important features. They used a decision tree (DT) classifier for classification and Shapley additive explanation (SHAP) to explain the selected features and classifier. The proposed method achieved an accuracy of 0.9997 on the WUSTL-IIOT-2021 dataset. Nizamudeen [
19] employed integer-grading normalization (I-GN) for data preprocessing and used opposition-based learning (OBL)-rat inspired optimizer (RIO) for feature selection to retain important features. Experiments on a combined dataset (NF-UQ-NIDS) showed improved detection accuracy compared to other state-of-the-art methods. Sharma et al. [
20] proposed an IoT intrusion detection system based on a deep neural network (DNN) model to better protect the security of internet devices. They used a generative adversarial network (GAN) to synthesize minority attack class data and employed the Pearson’s correlation coefficient (PCC) filter method for feature selection. Experimental results on the UNSW-NB15 dataset achieved an accuracy of 91% with balanced data.
Kareem et al. [
21] proposed a feature selection algorithm using the algorithm for bird swarms (BSA) to improve the performance of the gorilla troops optimizer (GTO). Experiments on the NSL-KDD, CICIDS-2017, UNSW-NB15, and Bot-IoT datasets demonstrated that the proposed GTO-BSA achieved better convergence speed and performance. Mohy-eddine et al. [
22] presented an IoT intrusion detection system based on the K-nearest neighbors (K-NN) algorithm, utilizing principal component analysis (PCA), univariate statistical tests, and genetic algorithm (GA) for feature selection. Experiments on the Bot-IoT dataset achieved a high accuracy of 99.99% while significantly reducing the prediction time. Liu et al. [
23] addressed the issue of excessive flow features affecting detection speed in IoT intrusion detection systems by proposing a feature selection method based on a genetic algorithm. Extensive experiments on the Bot-IoT dataset selected six features from 40 features, achieving an accuracy of 99.98% and an F1 score of 99.63%. Alweshah et al. [
24] proposed a novel wrapping feature selection algorithm that employed the emperor penguin colony (EPC) to explore the search space, selecting K-nearest neighbors (KNN) as the classifier. Experimental results on well-known IoT datasets showed improved accuracy and reduced feature size compared to methods such as the multi-objective particle swarm optimization (MOPSO). Hassan et al. [
25] used an improved binary manta ray foraging algorithm for feature selection to remove redundant and irrelevant features from the dataset, and utilized a random forest (RF) classifier for classification. The proposed method was evaluated on the NSL-KDD and CIC-IDS2017 datasets, selecting 22 and 38 features, respectively, and achieved accuracies of 98.8% and 99.3%. Mohiuddin et al. [
26] proposed a modified wrapper-based whale sine-cosine method to reduce the complexity of feature selection optimization, selecting important features, and used XGBoost as the classifier. Experimental results on the UNSW-NB15 dataset achieved accuracy rates of 99% and 91% for binary and multi-class classification, respectively, and an accuracy of 98% for binary classification on the CIC-IDS2017 dataset.
The literature review indicates that although the aforementioned methods have achieved relatively high detection performance, there is still room for improvement in detection rate and optimization of feature selection methods. Additionally, relying solely on a single feature selection method may not result in the optimal feature subset, which could impact the detection performance of the models.
3. Proposed Method
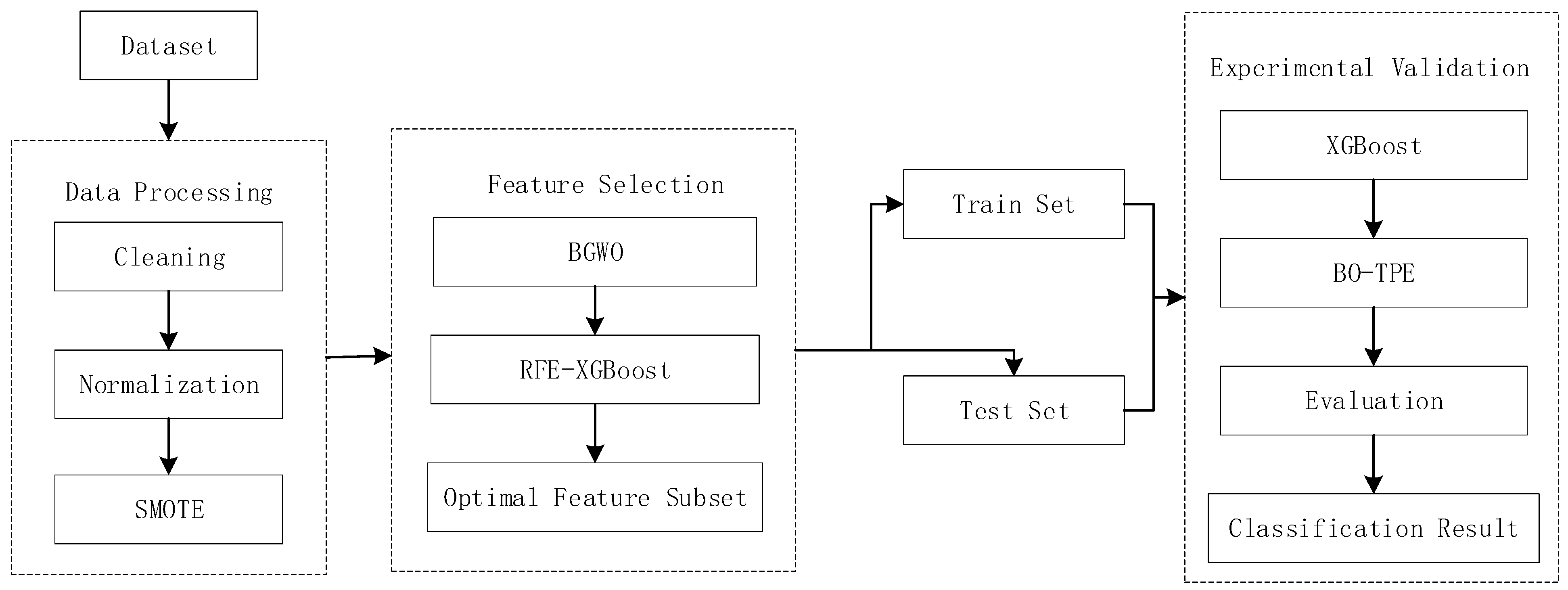
This section provides an introduction to the proposed method, and
Figure 1 illustrates the overall architecture. The first step involves dataset cleaning and normalization. The feature selection process consists of two stages. In the initial stage, BGWO is utilized to conduct a screening of the original feature set, removing redundant or irrelevant features. The resulting feature subset then undergoes further optimization using recursive feature elimination (RFE). During the recursive process, the XGBoost [
27] model is employed to rank the importance of each feature, and features with low scores are selected and eliminated. This iterative approach enables the identification of an optimal feature subset. To mitigate the impact of imbalanced data distribution on classifier results and enhance the detection rate of minority classes, we employ SMOTE technology. Once the data preprocessing phase is complete, the dataset is split into training and testing sets. Lastly, XGBoost is employed for classification, and Bayesian optimization with tree-structured Parzen estimator (BO-TPE) is utilized to optimize the model parameters, aiming to achieve optimal performance.
3.1. Proposed Feature Selection Method
3.1.1. Grey Wolf Optimization Algorithm
Meta-heuristic algorithms possess several advantages, including simplicity, flexibility, and powerful optimization capabilities, making them widely applicable in various research fields. Mirjalili et al. [
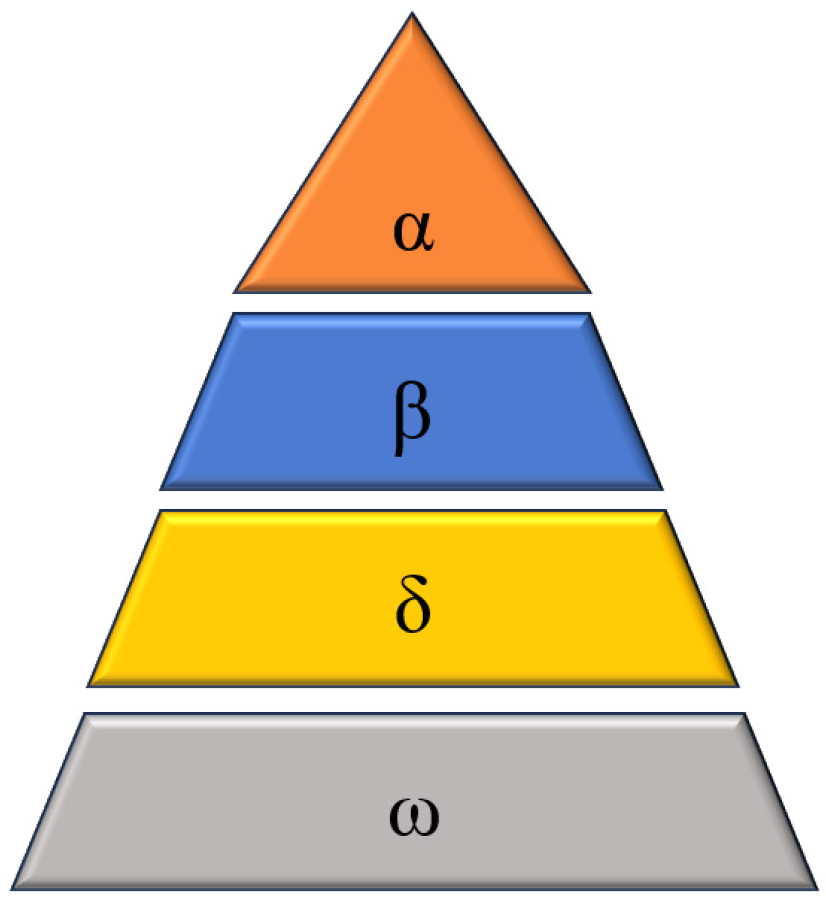
14] introduced the grey wolf optimization algorithm, a metaheuristic algorithm inspired by the hunting behavior of grey wolf populations. Grey wolves are skilled hunters that often collaborate in groups for successful prey capture. Within the grey wolf group, a strict social hierarchy exists, segmented into four distinct classes, as depicted in
Figure 2:
- (1)
The leader of the grey wolf group, known as the alpha (α) wolf, assumes decision-making responsibilities regarding hunting, sleeping arrangements, and other important matters.
- (2)
Beta (β) is the second-ranking member of the grey wolf class, standing second only to the α wolf in status.
- (3)
At the third level of the grey wolf hierarchy, we find the delta (δ) wolves, which typically fulfill roles such as lookouts and scouts. δ wolves are obliged to follow the leadership of the α and β wolves and exert authority over the lowest-ranked grey wolf, the omega (ω).
- (4)
ω wolves make up the largest population within the grey wolf group and are required to follow the directions of the α, β, and δ wolves. They always receive the last portion of food.
The GWO algorithm model summarizes the hunting process of grey wolves, which is divided into three stages: siege, hunting, and attacking prey.
- (1)
The stage of surrounding the prey. During the hunting process, the hunting behavior is expressed as follows:
Among these variables, represents the position of the prey that the grey wolf intends to hunt, while represents the position of the grey wolf itself. and are random vectors, with values between 0 and 1 in each dimension. As the iteration progresses, the component a linearly decreases from 2 to 0. Both and are coefficients corresponding to these positions.
- (2)
During the group hunting phase, grey wolves are capable of recognizing the location of the prey and strategically encircling it. The hunting group consists of alpha leaders, betas, and deltas, all actively participating in the hunt. The aforementioned process can be described mathematically, with the prey symbolizing a potential optimal solution. Assuming that alpha (α), beta (β), and delta (δ) wolves can swiftly identify potential prey (optimal solutions), the top three wolves in the group are updated to become the alpha, beta, and delta wolves after each iteration. Additionally, the omega (ω) wolves coordinate their positions based on alpha, beta, and delta, adjusting their own positions to gradually enclose the prey. The mathematical model representing this process can be expressed as follows:
In this context, , , and represent the distances between the current candidate grey wolf and the α, β, and δ wolves, respectively. Similarly, , , and respectively denote the estimated prey position based on the positions of grey wolves α, β, and δ in the current population. Additionally, , , and represent the positions of grey wolves α, β, and δ in the current population.
3.1.2. Binary Grey Wolf Optimization (BGWO)
The main focus of the feature selection problem is determining whether a specific feature should be included in the optimal subset constructed from a dataset. Mathematically, this can be described as selecting h features from a total of A features. In the context of intrusion detection, the chosen feature subset is used for classifying network traffic. In this case, the objective is to minimize h (the number of selected features) while maximizing the classification accuracy rate.
To apply the grey wolf optimization (GWO) algorithm to feature selection problems, a redesign of the algorithm is necessary. Emary et al. [
15] propose the binary grey wolf optimization (BGWO) algorithm specifically for this purpose. The following Algorithm 1 provides the BGWO algorithm.
In BGWO, the update formula is mainly as follows:
Among them, the crossover operation between the three solutions of
a,
b, and
c is represented as
. The binary vectors
,
, and
represent the α, β, and δ wolf pairs in the group. The influence of the movement of other grey wolves can be calculated using the following formulas.
Among them,
and
represent the position vector of the α wolf in dimension m and the binary step, respectively. Similarly,
and
,
and
represent the position vector and binary step of the β and δ wolves in dimension m, respectively.
,
, and
can be calculated using the following formulas.
Among them, rand belongs to the uniform distribution [0, 1].
,
, and
represent the continuous valued step size for α, β, and δ, respectively, in dimension m. This can be obtained using the following formulas.
| Algorithm 1 BGWO algorithm.
|
| Input: , Wolf pack size;
Maximum iterations; F, Features in the dataset. |
| Output: S, Optimal feature subset. |
| (1). Initialize three parameters a, p and q. |
| (2). Initializing the position of
grey wolves |
| (3). Sorting grey wolves by fitness value and selecting the top three (α, β, and δ wolves) |
| (4). i = 1
|
| While (i <
) |
|
For Each individual grey wolf in the pack |
| Calculate using Equations (10)–(12).
|
|
crossover among using Equation (9). |
|
End |
| I Updating the parameters a, p, and q. |
| II After updating the location, calculate the fitness value of each grey wolf. |
| III update α, β and δ. |
| End |
3.1.3. RFE-XGBoost
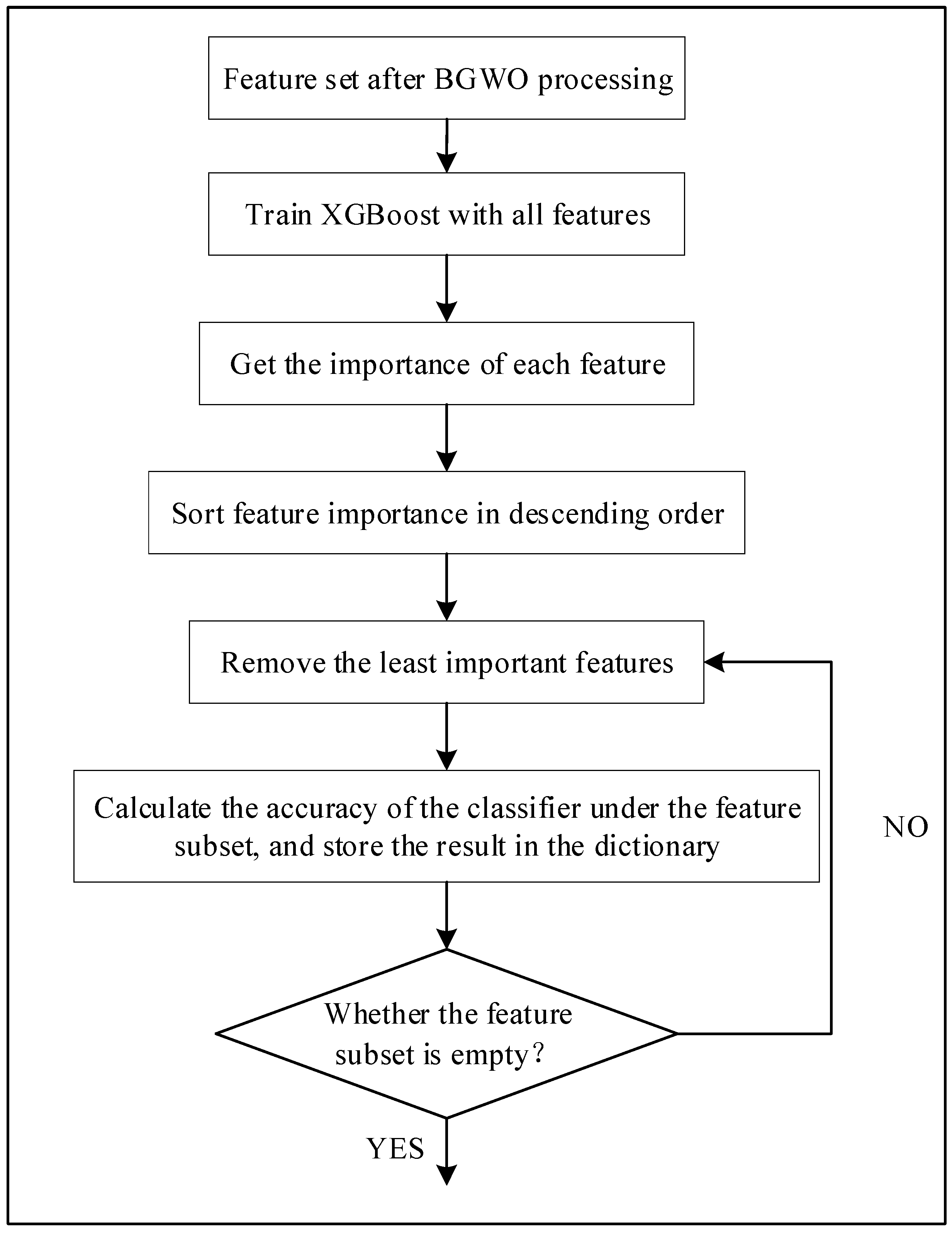
In network traffic data, redundant and irrelevant information is often present, which can adversely affect classifier predictions in terms of efficiency and accuracy. To tackle this issue, Recursive feature elimination (RFE) is utilized as a wrapper feature selection method. The RFE process involves iteratively removing the least important features, gradually reducing the number of feature subsets while maintaining classifier accuracy.
Figure 3 illustrates the XGBoost-RFE method. Initially, the full feature set is inputted into the XGBoost classifier, and the accuracy rate of the classifier under this feature set is computed. The importance of each feature is then calculated and ranked in descending order. In the subsequent step, the feature with the lowest importance in the ranking is eliminated, resulting in a new feature subset. This new subset is fed into the XGBoost classifier to evaluate the accuracy. The current feature subset and classifier accuracy are recorded. The second step is repeated until the feature subset becomes empty, with features being removed one by one. Finally, based on the saved classifier accuracy results, the feature subset with the highest accuracy is identified and considered as the optimal subset.
3.1.4. Two-Stage Feature Selection
After implementing the aforementioned feature selection techniques, the final optimal feature subset is obtained. This two-stage approach effectively eliminates irrelevant and redundant features, reduces feature dimensionality, and retains meaningful features, thereby enhancing both the accuracy and efficiency of the model. The two-stage feature selection method combines two different techniques to identify a superior feature subset, enhancing the performance and efficiency of the model. In the first stage, the BGWO algorithm is utilized, which simulates the hunting behavior of grey wolf groups to search for the optimal feature subset. BGWO is known for its ease of implementation, fast convergence, and strong optimization capabilities. It selects an initial optimal feature subset by dynamically adjusting the position of grey wolves based on their fitness evaluation and proximity to other wolves.
The generated feature subset in the first stage is then passed to the second stage, where the RFE-XGBoost algorithm is employed. RFE-XGBoost is a recursive feature elimination algorithm that utilizes the XGBoost algorithm to assess and rank features. It first trains an XGBoost model on the original feature set and then sequentially removes features with lower importance scores. This process continues until a predetermined number of features is obtained or the performance of the feature set reaches its maximum potential. By integrating the two-stage feature selection approach, irrelevant and redundant features can be effectively eliminated, reducing the dimensionality of the feature space while retaining informative features. This results in improved accuracy and efficiency for the model.
3.2. Extreme Gradient Boosting (XGBoost)
XGBoost [
27] is an integrated learning algorithm known for its high efficiency and flexibility, making it widely used in various fields. XGBoost combines a group of weak learners to create a powerful model through continuous iterative optimization. The XGBoost model is trained in an additive manner, with the t-th objective function defined as follows:
Among these, Ω represents the complexity penalty of the model, and CONSTANT is a constant value.
Formula (19) expands through Taylor’s formula, resulting in Formula (21).
The second derivative of the Taylor formula can be approximated as follows:
Here,
and
correspond to
and
, respectively, in the second derivative of Taylor’s formula, representing the first and second derivatives.
By substituting Equations (20), (23), and (24) into Equation (21), we can calculate the derivative. The solution is obtained from Equations (25) and (26).
can be expressed as a scoring function, used to measure the quality of the tree structure. The term refers to the solution for the weights.
3.3. Synthetic Minority Oversampling Technique (SMOTE)
In network traffic datasets, one common issue is the imbalanced distribution of data. This means that there are significantly more normal samples compared to attack samples. Unfortunately, this data imbalance can have a negative impact on the prediction results of the model. One technique used to address this issue is random oversampling, which involves duplicating samples from the minority class at random. However, this approach may lead to overfitting. To overcome this limitation, the synthetic minority oversampling technique (SMOTE) is widely used. SMOTE leverages the K-nearest neighbors (KNN) method to synthesize new and more representative samples in the minority class [
28]. By applying SMOTE sampling, the model can effectively learn the features of the minority class and improve its detection rate for minority categories. The steps involved in generating new samples using SMOTE are as follows:
Calculate the desired number of new samples that need to be generated.
Determine the K nearest neighbors for each sample in the minority class.
Randomly select N samples from the K nearest neighbors and perform random linear interpolation to create a new sample in the minority class.
3.4. Bayesian Optimization-Tree Parzen Estimator (BO-TPE)
Hyperparameter tuning can be categorized into four main types: traditional manual tuning, grid search, random search, and Bayesian search [
29]. Manual tuning relies heavily on experience and can be time-consuming. Grid search and random search do not effectively utilize the correlation between different hyperparameter combinations. On the other hand, Bayesian optimization is an adaptive method for hyperparameter search that predicts the next combination of hyperparameters likely to yield the greatest benefit based on the previously tested combinations. In this study, we utilize the Bayesian optimization-tree Parzen estimator (BO-TPE) technique [
30] to tune the hyperparameters of the model. BO-TPE offers excellent global search capability and is resistant to becoming trapped in local optima. During the initial iteration, random search is employed, and samples are drawn from the response surface to establish the initial distribution
, where θ and y represent the set of hyperparameters and their corresponding values on the response surface, respectively.
BO-TPE employs two density functions,
and
, as the generative model of variables [
29]. These functions are used to differentiate good samples from bad samples based on a predefined threshold y’, as shown below:
Next, the expected improvement (EI) is calculated for each step.
Finally, the optimal hyperparameter value is selected by maximizing the EI.
When optimizing the hyperparameters of the XGBoost model using BO-TPE, the key hyperparameters to consider are n_estimators, max_depth, and learning_rate. The hyperparameter n_estimators signifies the number of weak learners to be integrated, max_depth determines the maximum depth of the tree, and learning_rate represents the step size for each iteration.
5. Conclusions
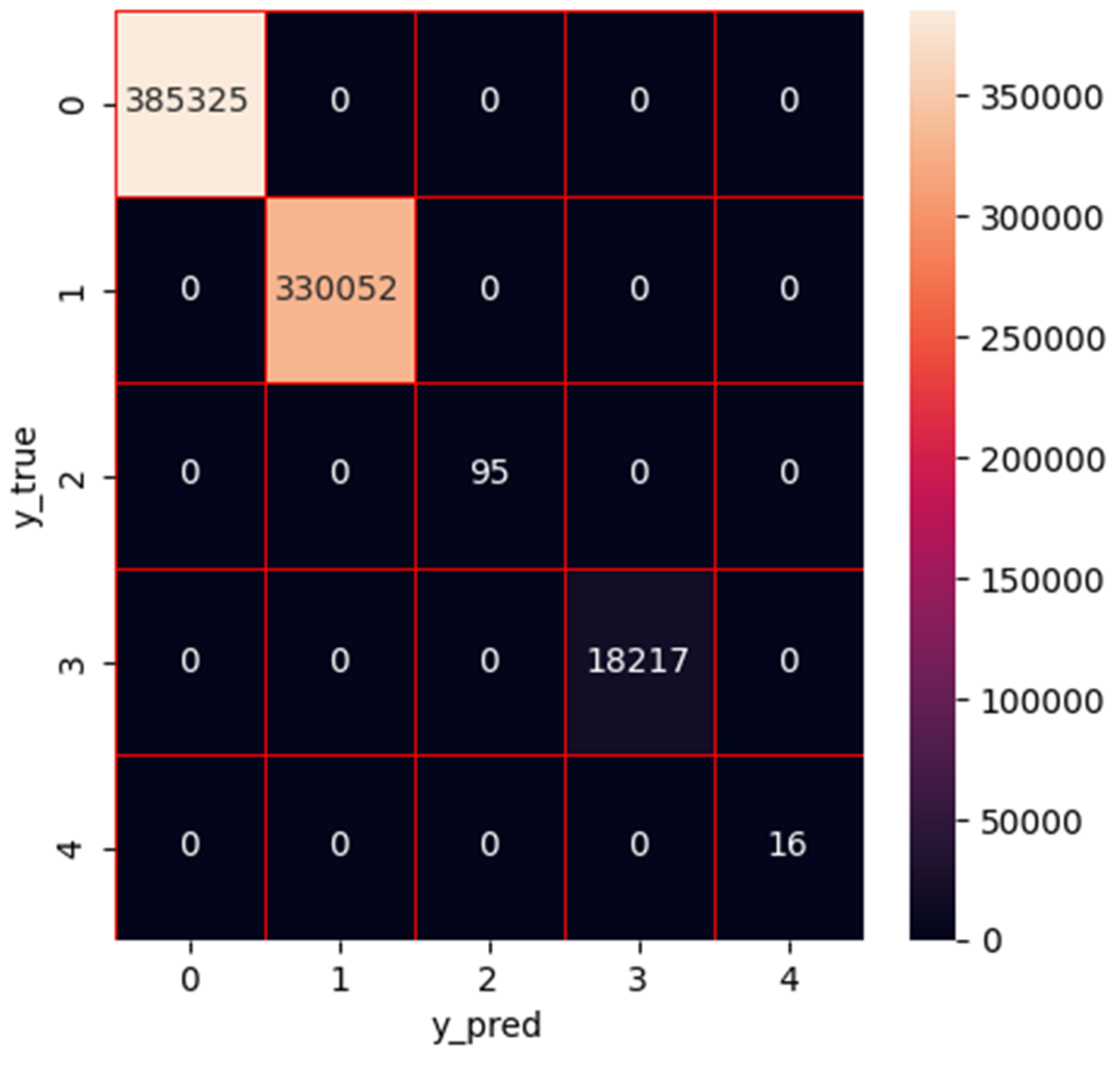
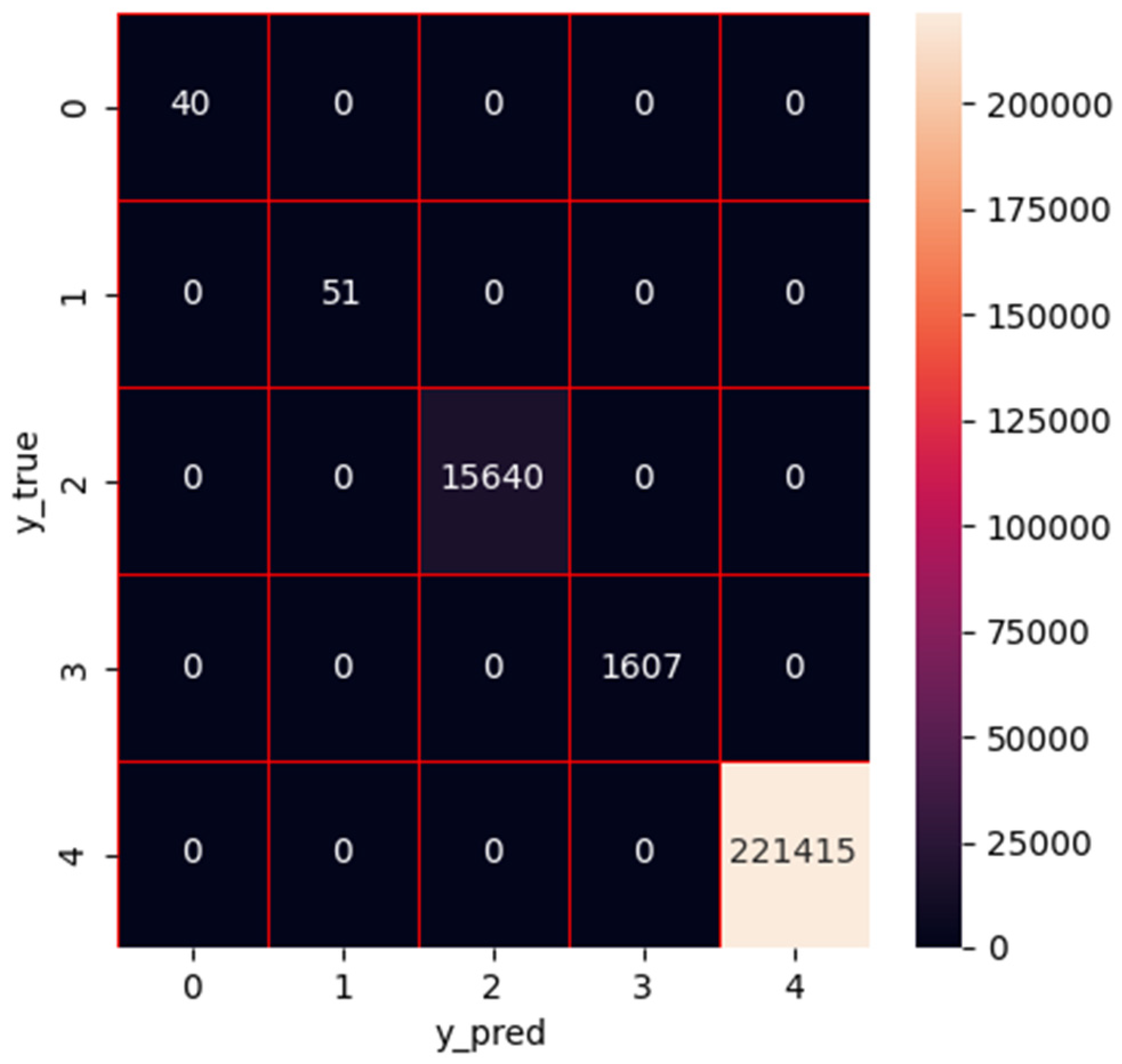
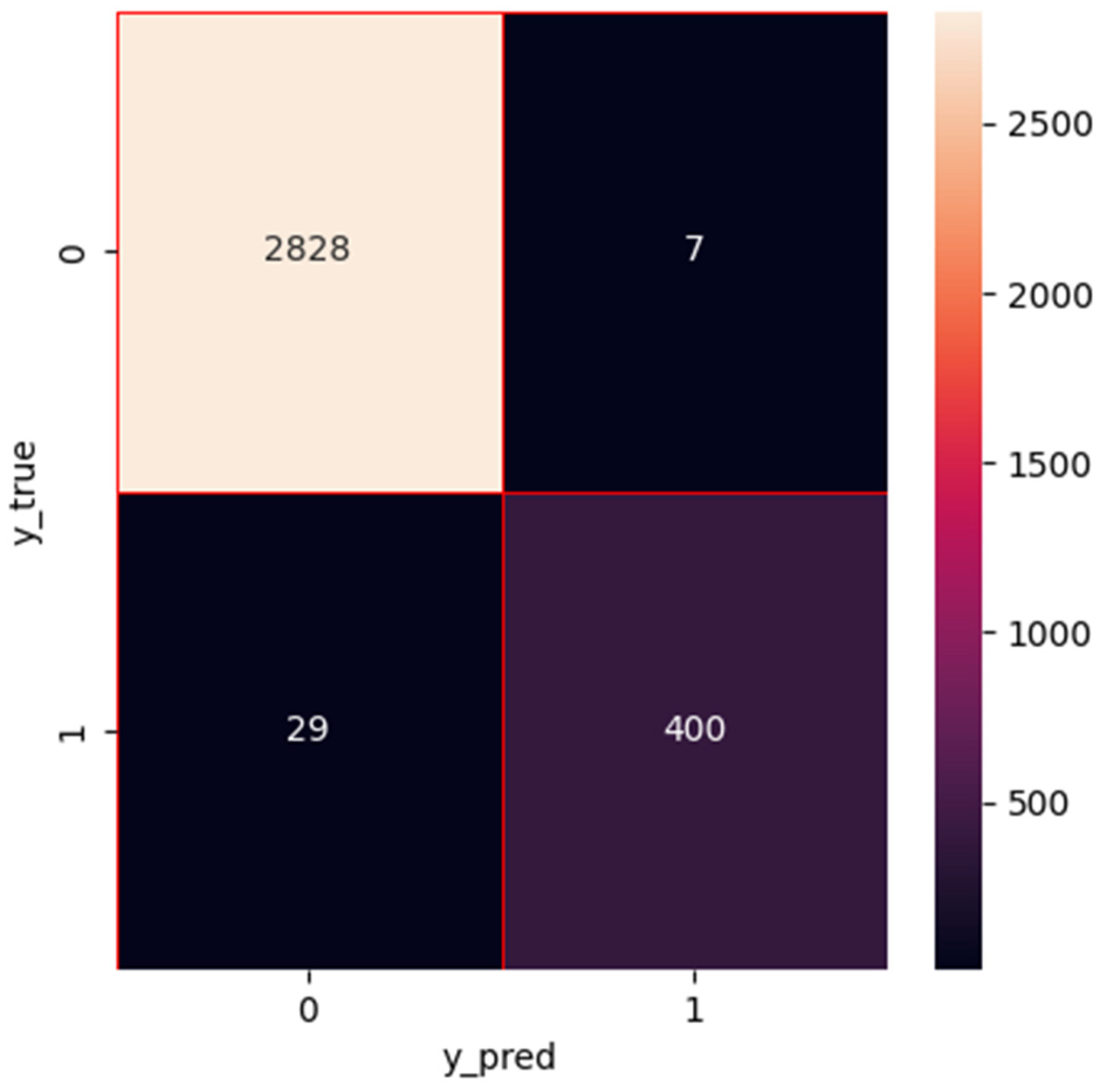
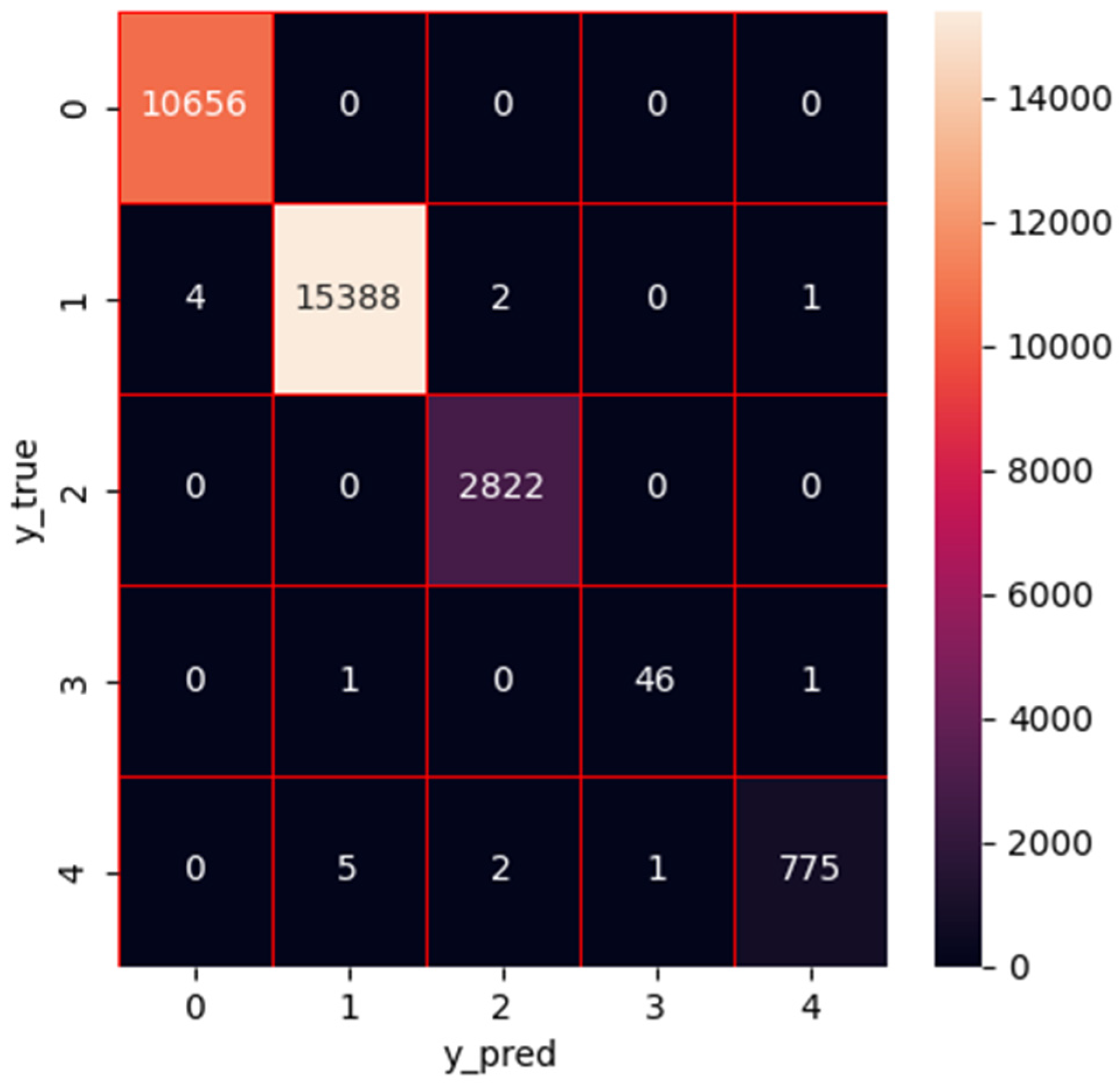
With the rapid development of the Internet of Things (IoT), the need to protect IoT network security has become increasingly urgent. In this paper, we propose an effective intrusion detection system to safeguard the security of IoT networks. The proposed intrusion detection system is based on the XGBoost classifier and utilizes the BGWO and RFE-XGBoost two-stage feature selection methods to identify the most important feature subsets. The class imbalance problem is addressed using the SMOTE method. The hyperparameters of the XGBoost classifier are optimized using the BO-TPE method. In our research, we conducted experiments on five commonly used public datasets in the field of IoT, involving binary and multi-class classification. The results demonstrate that our proposed method outperformed state-of-the-art methods in terms of accuracy, recall, precision, and F1 score on all five datasets, validating the effectiveness of our approach. While the proposed two-stage feature selection method is highly effective, extending this method to larger datasets presents challenges in terms of computational complexity, memory requirements, efficiency, generalization ability, and robustness. In the future, further research and solutions can be explored to address these issues and enhance the performance of feature selection algorithms.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}