
Lightweight Three-Dimensional Pose and Joint Center Estimation Model for Rehabilitation Therapy




Abstract
:1. Introduction
2. Literature Review: Related Work
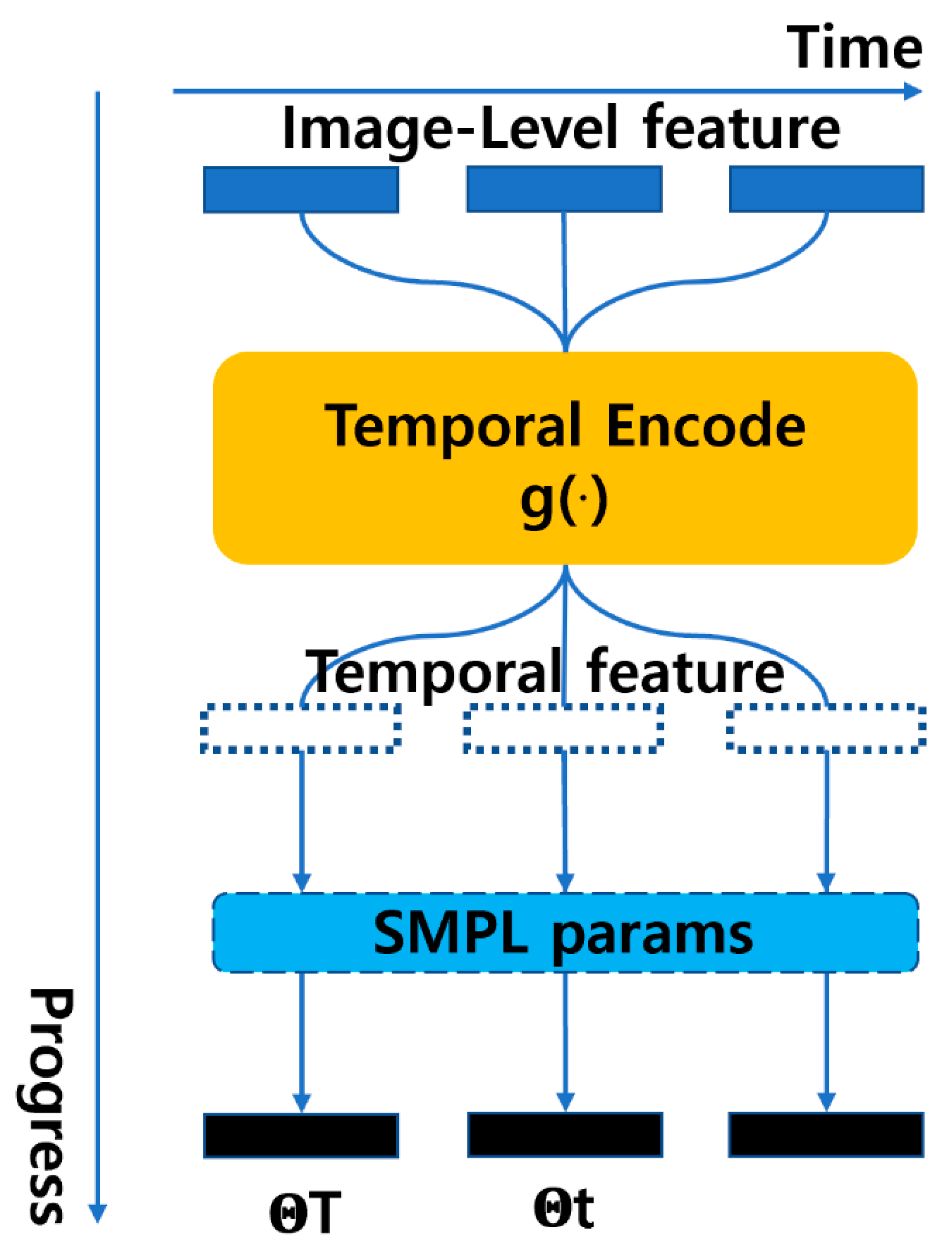
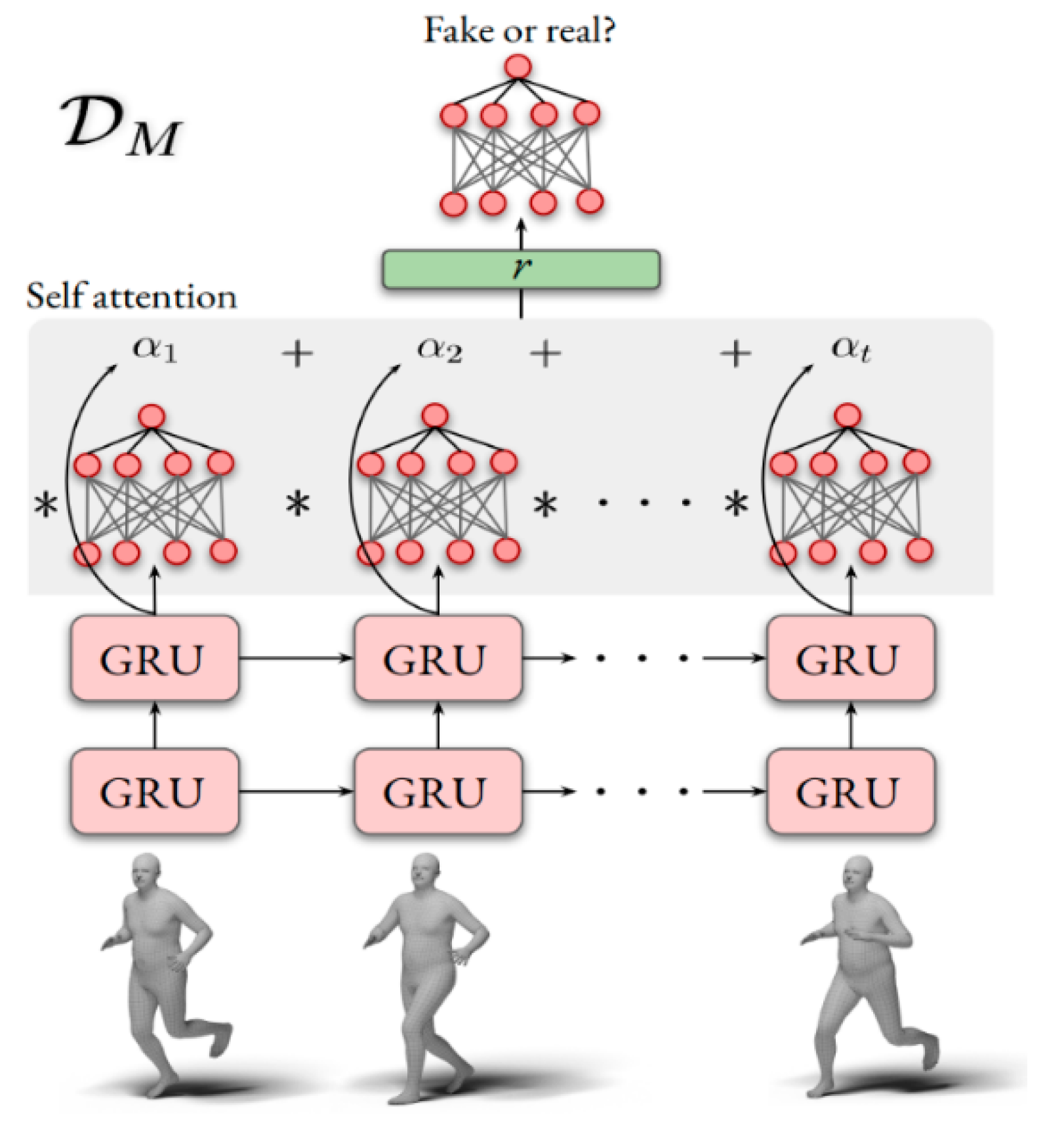
2.1. VIBE
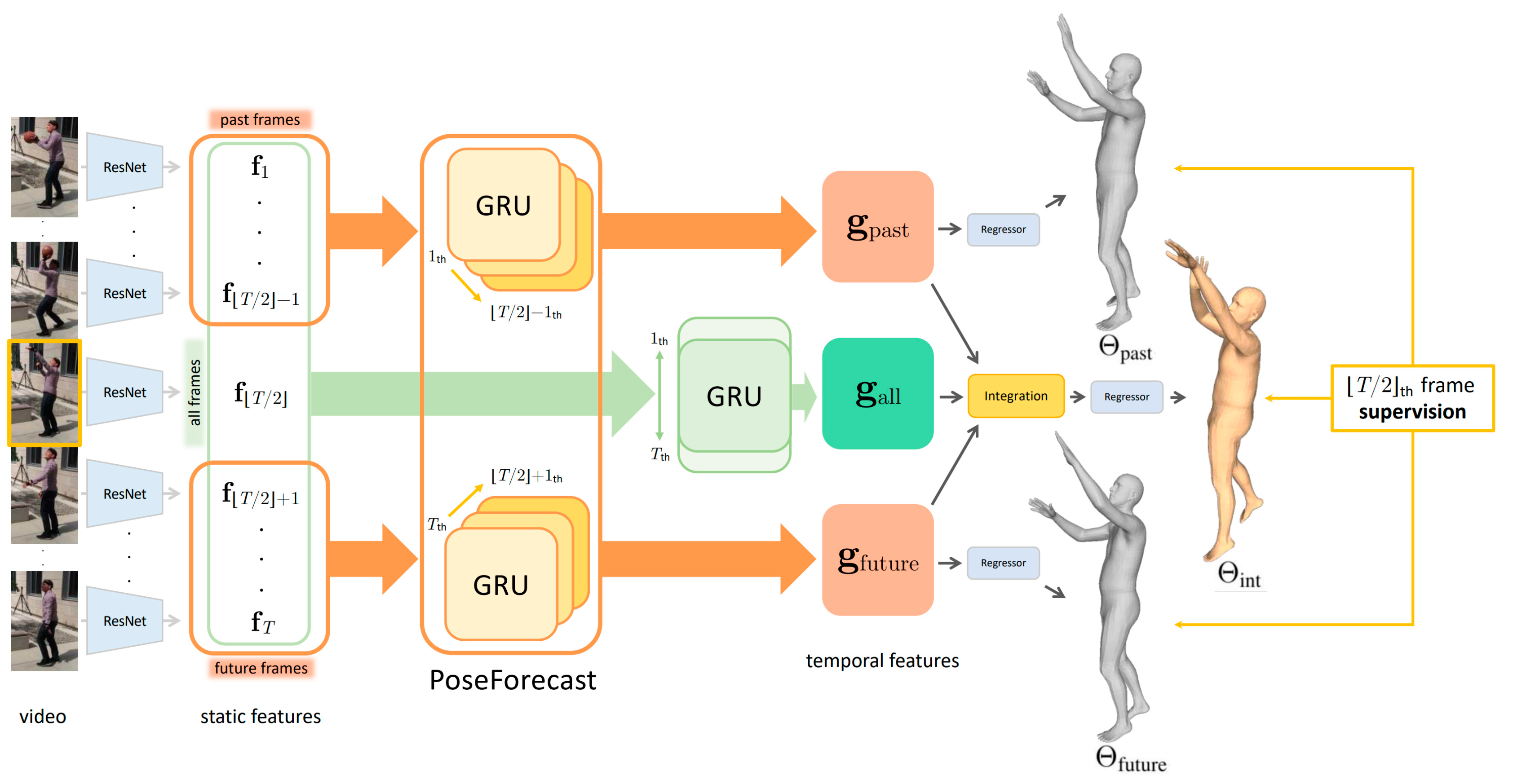
2.2. TCMR
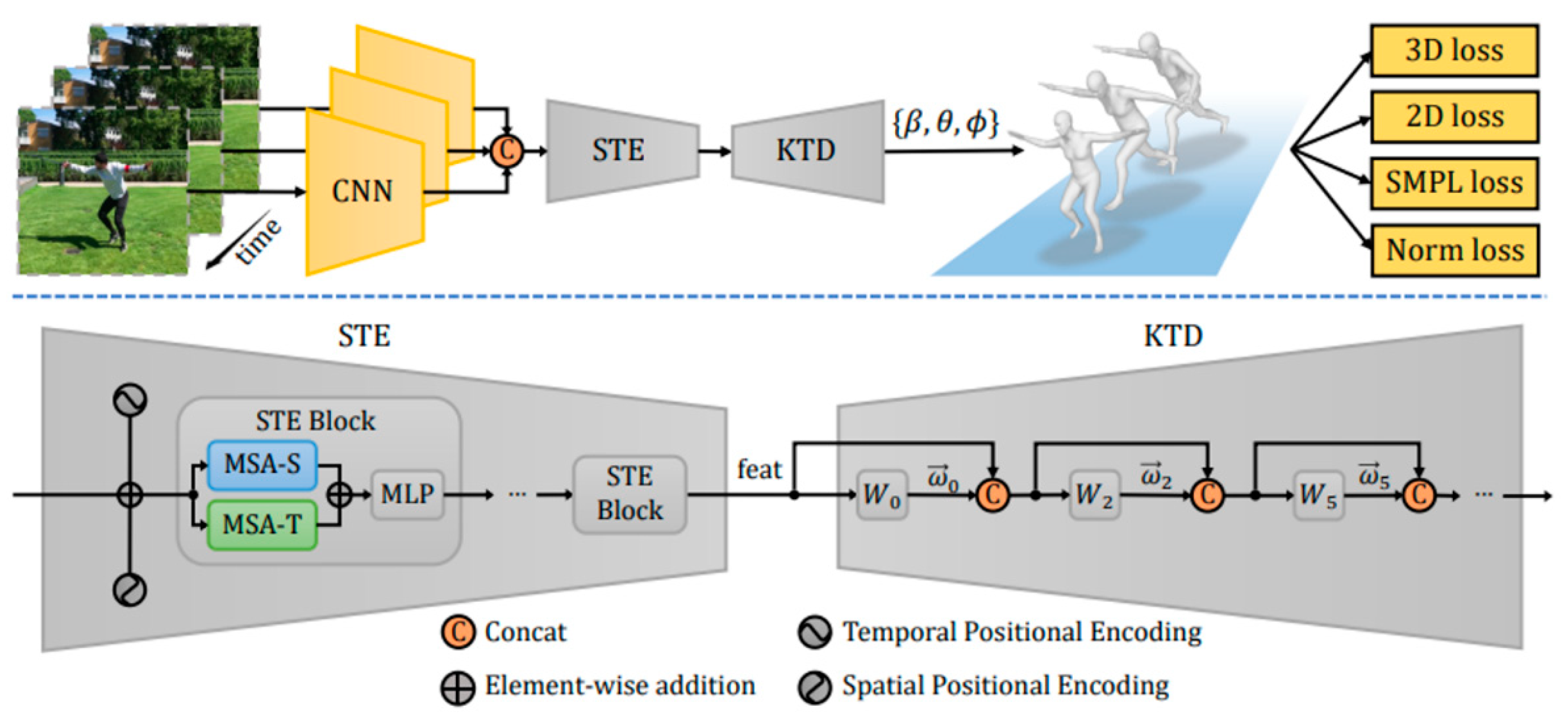
2.3. MAED
3. Methods
- A layer for converting the input images into patches;
- A class token that contains information on the entire image;
- Position embeddings that contain information on the position of the patches;
- A sequence composed of multiple transformer blocks;
- A normalization layer for the final output;
- A layer applied before the final output;
- The batch_size value is determined based on the shape of the input image.
4. Experiment and Results
- Procrustes-aligned mean-per-joint-position error (PA-MPJPE);
- Mean-per-joint-position error (MPJPE).
4.1. Comparison with Other Human Pose Estimation Methods
4.2. Core Analysis
4.3. Observations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pooyandeh, M.; Han, K.-J.; Sohn, I. Cybersecurity in the AI-Based Metaverse: A Survey. Appl. Sci. 2022, 12, 12993. [Google Scholar] [CrossRef]
- Wang, G.; Badal, A.; Jia, X.; Maltz, J.S.; Mueller, K.; Myers, K.J.; Niu, C.; Vannier, M.; Yan, P.; Yu, Z.; et al. Development of metaverse for intelligent healthcare. Nat. Mach. Intell. 2022, 411, 922–929. [Google Scholar] [CrossRef] [PubMed]
- Mozumder, M.A.I.; Sheeraz, M.M.; Athar, A.; Aich, S.; Kim, H.C. Overview: Technology Roadmap of the Future Trend of Metaverse based on IoT, Blockchain, AI Technique, and Medical Domain Metaverse Activity. In Proceedings of the 2022 24th International Conference on Advanced Communication Technology (ICACT), Pyeongchang-gun, Republich of Korea, 13–16 February 2022; pp. 256–261. [Google Scholar]
- Chaudhary, M.Y. Augmented Reality, Artificial Intelligence, and the Re-Enchantment of the World: With Mohammad Yaqub Chaudhary, “Augmented Reality, Artificial Intelligence, and the Re-Enchantment of the World”; and William Young, “Reverend Robot: Automation and Clergy”. Zygon 2019, 54, 454–478. [Google Scholar] [CrossRef]
- Ali, S.; Abdullah; Armand, T.P.T.; Athar, A.; Hussain, A.; Ali, M.; Yaseen, M.; Joo, M.-I.; Kim, H.-C. Metaverse in Healthcare Integrated with Explainable AI and Blockchain: Enabling Immersiveness, Ensuring Trust, and Providing Patient Data Security. Sensors 2023, 23, 565. [Google Scholar] [CrossRef] [PubMed]
- Afrashtehfar, K.I.; Abu-Fanas, A.S.H. Metaverse, Crypto, and NFTs in Dentistry. Educ. Sci. 2022, 12, 538. [Google Scholar] [CrossRef]
- Aaron, H. Can Computers Create Art? Arts 2018, 7, 18. [Google Scholar]
- Ahmad, S.F.; Rahmat, M.K.; Mubarik, M.S.; Alam, M.M.; Hyder, S.I. Artificial Intelligence and Its Role in Education. Sustainability 2021, 13, 12902. [Google Scholar] [CrossRef]
- Reitmann, S.; Neumann, L.; Jung, B. Blainder—A blender ai add-on for generation of semantically labeled depth-sensing data. Sensors 2021, 21, 2144. [Google Scholar] [CrossRef]
- Papastratis, I.; Chatzikonstantinou, C.; Konstantinidis, D.; Dimitropoulos, K.; Daras, P. Artificial Intelligence Technologies for Sign Language. Sensors 2021, 21, 5843. [Google Scholar] [CrossRef]
- Pataranutaporn, P.; Danry, V.; Leong, J.; Punpongsanon, P.; Novy, D.; Maes, P.; Sra, M. AI-generated characters for supporting personalized learning and well-being. Nat. Mach. Intell. 2021, 3, 1013–1022. [Google Scholar] [CrossRef]
- Jiang, S.; Ma, J.W.; Liu, Z.Y.; Guo, H.X. Scientometric Analysis of Artificial Intelligence (AI) for Geohazard Research. Sensors 2022, 22, 7814. [Google Scholar] [CrossRef] [PubMed]
- Gandedkar, N.H.; Wong, M.T.; Darendeliler, M.A. Role of Virtual Reality (VR), Augmented Reality (AR) and Artificial Intelligence (AI) in Tertiary Education and Research of Orthodontics: An Insight. Semin. Orthod. 2021, 27, 69–77. [Google Scholar] [CrossRef]
- Hu, L.; Tian, Y.; Yang, J.; Taleb, T.; Xiang, L.; Hao, Y. Ready player one: UAV-clustering-based multi-task offloading for vehicular VR/AR gaming. IEEE Netw. 2019, 33, 42–48. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L. Roles of artificial intelligence in construction engineering and management: A critical review and future trends. Autom. Constr. 2021, 122, 103517. [Google Scholar] [CrossRef]
- Minopoulos, G.M.; Memos, V.A.; Stergiou, K.D.; Stergiou, C.L.; Psannis, K.E. A Medical Image Visualization Technique Assisted with AI-Based Haptic Feedback for Robotic Surgery and Healthcare. Appl. Sci. 2023, 13, 3592. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, X.; Fang, S.; Shi, X. Construction and Application of VR-AR Teaching System in Coal-Based Energy Education. Sustainability 2022, 14, 16033. [Google Scholar] [CrossRef]
- Monterubbianesi, R.; Tosco, V.; Vitiello, F.; Orilisi, G.; Fraccastoro, F.; Putignano, A.; Orsini, G. Augmented, Virtual and Mixed Reality in Dentistry: A Narrative Review on the Existing Platforms and Future Challenges. Appl. Sci. 2022, 12, 877. [Google Scholar] [CrossRef]
- Badiola-Bengoa, A.; Mendez-Zorrilla, A. A systematic review of the application of camera-based human-pose estimation in thefield of sport and physical exercise. Sensors 2021, 21, 5996. [Google Scholar] [CrossRef]
- Jalal, A.; Akhtar, I.; Kim, K. Human Posture Estimation and Sustainable Events Classification via Pseudo-2D Stick Model andK-ary Tree Hashing. Sustainability 2020, 12, 9814. [Google Scholar] [CrossRef]
- Nguyen, H.; Nguyen, T.; Scherer, R.; Le, V. Unified End-to-End YOLOv5-HR-TCM Framework for Automatic 2D/3D Human PoseEstimation for Real-Time Applications. Sensors 2022, 22, 5419. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.L.; Ong, L.Y.; Leow, M.C. Comparative Analysis of Skeleton-Based Human-pose estimation. Future Internet 2022, 14, 380. [Google Scholar] [CrossRef]
- Patil, A.K.; Balasubramanyam, A.; Ryu, J.Y.; Chakravarthi, B.; Chai, Y.H. An open-source platform for human-pose estimationand tracking using a heterogeneous multi-sensor system. Sensors 2021, 21, 2340. [Google Scholar] [CrossRef]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A Simple Yet Effective Baseline for 3d Human-pose estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2659–2668. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human-pose estimation: New Benchmark and State of the Art Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Wang, J. Deep 3D human-pose estimation: A review. Comput. Vis. Image Underst. 2021, 210, 103225–103246. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 September 2014; pp. 1653–1660. [Google Scholar]
- Liu, Z.; Chen, H.; Feng, R.; Wu, S.; Ji, S.; Yang, B.; Wang, X. Deep Dual Consecutive Network for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Ganguly, A.; Rashidi, G.; Mombaur, K. Comparison of the Performance of the Leap Motion ControllerTM with a StandardMarker-Based Motion Capture System. Sensors 2021, 21, 1750. [Google Scholar] [CrossRef]
- Zhao, Y.S.; Jaafar, M.H.; Mohamed, A.S.A.; Azraai, N.Z.; Amil, N. Ergonomics Risk Assessment for Manual Material Handlingof Warehouse Activities Involving High Shelf and Low Shelf Binning Processes: Application of Marker-Based Motion Capture. Sustainability 2022, 14, 5767. [Google Scholar] [CrossRef]
- Filippeschi, A.; Schmitz, N.; Miezal, M.; Bleser, G.; Ruffaldi, E.; Stricker, D. Survey of Motion TrackingMethods Based on Inertial Sensors: A Focus on Upper Limb Human Motion. Sensors 2017, 17, 1257. [Google Scholar] [CrossRef]
- Khan, M.H.; Zöller, M.; Farid, M.S.; Grzegorzek, M. Marker-Based Movement Analysis of Human BodyParts in Therapeutic Procedure. Sensors 2020, 20, 3312. [Google Scholar] [CrossRef] [PubMed]
- Moro, M.; Marchesi, G.; Hesse, F.; Odone, F.; Casadio, M. Markerless vs. Marker-Based Gait Analysis: A Proof of Concept Study. Sensors 2022, 22, 2011. [Google Scholar] [CrossRef]
- Klishkovskaia, T.; Aksenov, A.; Sinitca, A.; Zamansky, A.; Markelov, O.A.; Kaplun, D. Development of Classification Algorithmsfor the Detection of Postures Using Non-Marker-Based Motion Capture Systems. Appl. Sci. 2020, 10, 4028. [Google Scholar] [CrossRef]
- Fang, W.; Zheng, L.; Deng, H.; Zhang, H. Real-Time Motion Tracking for Mobile Augmented/Virtual RealityUsing Adaptive Visual-Inertial Fusion. Sensors 2017, 17, 1037. [Google Scholar] [CrossRef]
- Adolf, J.; Dolezal, J.; Kutilek, P.; Hejda, J.; Lhotska, L. Single Camera-Based Remote Physical Therapy: Verification on a LargeVideo Dataset. Appl. Sci. 2022, 12, 799. [Google Scholar] [CrossRef]
- Song, J.; Kook, J. Mapping Server Collaboration Architecture Design with OpenVSLAM for Mobile Devices. Appl. Sci. 2022, 12, 3653. [Google Scholar] [CrossRef]
- Muhammad, K.; Khan, N.; Lee, M.Y.; Imran, A.S.; Sajjad, M. School of the future: A comprehensive study on the effectiveness ofaugmented reality as a tool for primary school children’s education. Appl. Sci. 2021, 11, 5277. [Google Scholar]
- Jung, S.; Song, J.G.; Hwang, D.J.; Ahn, J.Y.; Kim, S. A study on software-based sensingtechnology for multiple object control in AR video. Sensors 2010, 10, 9857–9871. [Google Scholar] [CrossRef]
- Schmitz, A.; Ye, M.; Shapiro, R.; Yang, R.; Noehren, B. Accuracy and repeatability of joint angles measuredusing a single camera markerless motion capture system. J. Biomech. 2014, 47, 587–591. [Google Scholar] [CrossRef]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. 2015, 34, 1–16. [Google Scholar] [CrossRef]
- Kocabas, M.; Athanasiou, N.; Black, M.J. VIBE: Video Inference for Human Body Pose and Shape Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5252–5262. [Google Scholar]
- Choi, H.; Moon, G.; Lee, K.M. Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Wan, Z.; Li, Z.; Tian, M.; Liu, J.; Yi, S.; Li, H. Encoder-decoder with Multi-level Attention for 3D Human Shape and Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Tung, H.Y.F.; Tung, H.W.; Yumer, E.; Fragkiadaki, K. Self-supervised learning of motion capture. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5242–5252. [Google Scholar]
- Mahmood, N.; Ghorbani, N.; Troje, N.F.; Pons-Moll, G.; Black, M.J. AMASS: Archive of Motion Capture As Surface Shapes. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A.A.A.; Tzionas, D.; Black, M.J. Expressive Body Capture: 3D Hands, Face, and Body from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Luo, Z.; Golestaneh, S.A.; Kitani, K.M. 3D human motion estimation via motion compression and refinement. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Yang, S.; Heng, W.; Liu, G.; Luo, G.; Yang, W.; Yu, G. Capturing the motion of every joint: 3D human pose and shape estimation with independent tokens. In Proceedings of the ICLR 2023 International Conference on Learning Representations, International Conference on Learning Representations (ICLR 2023), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- von Marcard, T.; Henschel, R.; Black, M.J.; Rosenhahn, B.; Pons-Moll, G. Recovering accurate 3D human pose in the wild using imus and a moving camera. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 601–617. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3. 6m: Large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.H.P.; Yi, H.; Höschle, M.; Safroshkin, M.; Alexiadis, T.; Polikovsky, S.; Scharstein, D.; Black, M.J. Capturing and inferring dense full-body human-scene contact. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13274–13285. [Google Scholar]
- Tripathi, S.; Müller, L.; Huang, C.H.P.; Taheri, O.; Black, M.J.; Tzionas, D. 3D human-pose estimation via intuitive physics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 4713–4725. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VIBE [42] | TCMR [43] | MAED [44] | |
|---|---|---|---|
| Overview | Extracts frame features from videos. Utilizes bidirectional GRUs to incorporate temporal information and generate latent variables. | Does not rely on static image features. Predicts 3D human poses using temporal data. | Built upon the SMPL model. Models spatial and temporal features based on image features. |
| Objective | Estimates SMPL human body model parameters (pose and shape). Represents human body movements. | Combines temporal features of the current frame with those of previous and subsequent frames to estimate a 3D human mesh. | Models spatial and temporal information to estimate a 3D human mesh. Utilizes SMPL to compute 3D joints and their 2D projections. |
| Improvements | Enhances pose estimation by utilizing past and future frame information. Combines comprehensive loss for each element with the corresponding motion discriminator loss. | Utilizes bidirectional GRUs to extract temporal features. Integrates temporal features to predict 3D mesh for the current frame. | Employs various multi-head self-attention methods. Models spatial and temporal information. Stacks STE blocks to build a complex model. |
| 3DPW [50] | H3.6M [51] | ||||
|---|---|---|---|---|---|
| Models | Backbone | PA-MPJPE [↓] | MPJPE [↓] | PA-MPJPE [↓] | MPJPE [↓] |
| VIBE | ResNet-50 | 52.9 | 83.2 | 42.4 | 65.4 |
| (Kocabas et al., 2020) [42] | (from Spin) | ||||
| TCMR | ResNet-50 | 56.8 | 96.1 | 41.7 | 62.1 |
| (Choi et al., 2021) [43] | (from Spin) | ||||
| MAED | ResNet-50 | 50.7 | 93.1 | 38.7 | 56.4 |
| (Wan et al., 2021) [44] | |||||
| INT | ResNet-50 | 49.7 | 90.0 | 39.1 | 57.1 |
| (Yang et al., 2023) [49] | |||||
| Our Model | ResNet-50 | 49.0 | 87.9 | 39.3 | 57.0 |
| MOYO | RICH | ||||
|---|---|---|---|---|---|
| Models | Backbone | PA-MPJPE [↓] | MPJPE [↓] | PA-MPJPE [↓] | MPJPE [↓] |
| INT | ResNet-50 | 36.8 | 74.3 | 48.2 | 80.7 |
| (Yang et al., 2023) [49] | |||||
| Our Model | ResNet-50 | 36.7 | 74.4 | 47.8 | 80.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.; Ku, G.; Yang, C.; Lee, J.; Kim, J. Lightweight Three-Dimensional Pose and Joint Center Estimation Model for Rehabilitation Therapy. Electronics 2023, 12, 4273. https://doi.org/10.3390/electronics12204273
Kim Y, Ku G, Yang C, Lee J, Kim J. Lightweight Three-Dimensional Pose and Joint Center Estimation Model for Rehabilitation Therapy. Electronics. 2023; 12(20):4273. https://doi.org/10.3390/electronics12204273
Chicago/Turabian StyleKim, Yeonggwang, Giwon Ku, Chulseung Yang, Jeonggi Lee, and Jinsul Kim. 2023. "Lightweight Three-Dimensional Pose and Joint Center Estimation Model for Rehabilitation Therapy" Electronics 12, no. 20: 4273. https://doi.org/10.3390/electronics12204273
APA StyleKim, Y., Ku, G., Yang, C., Lee, J., & Kim, J. (2023). Lightweight Three-Dimensional Pose and Joint Center Estimation Model for Rehabilitation Therapy. Electronics, 12(20), 4273. https://doi.org/10.3390/electronics12204273