
Design and Implementation of Low-Power IoT RISC-V Processor with Hybrid Encryption Accelerator

Abstract
:1. Introduction
2. Background
2.1. SM3 Algorithm
- (1)
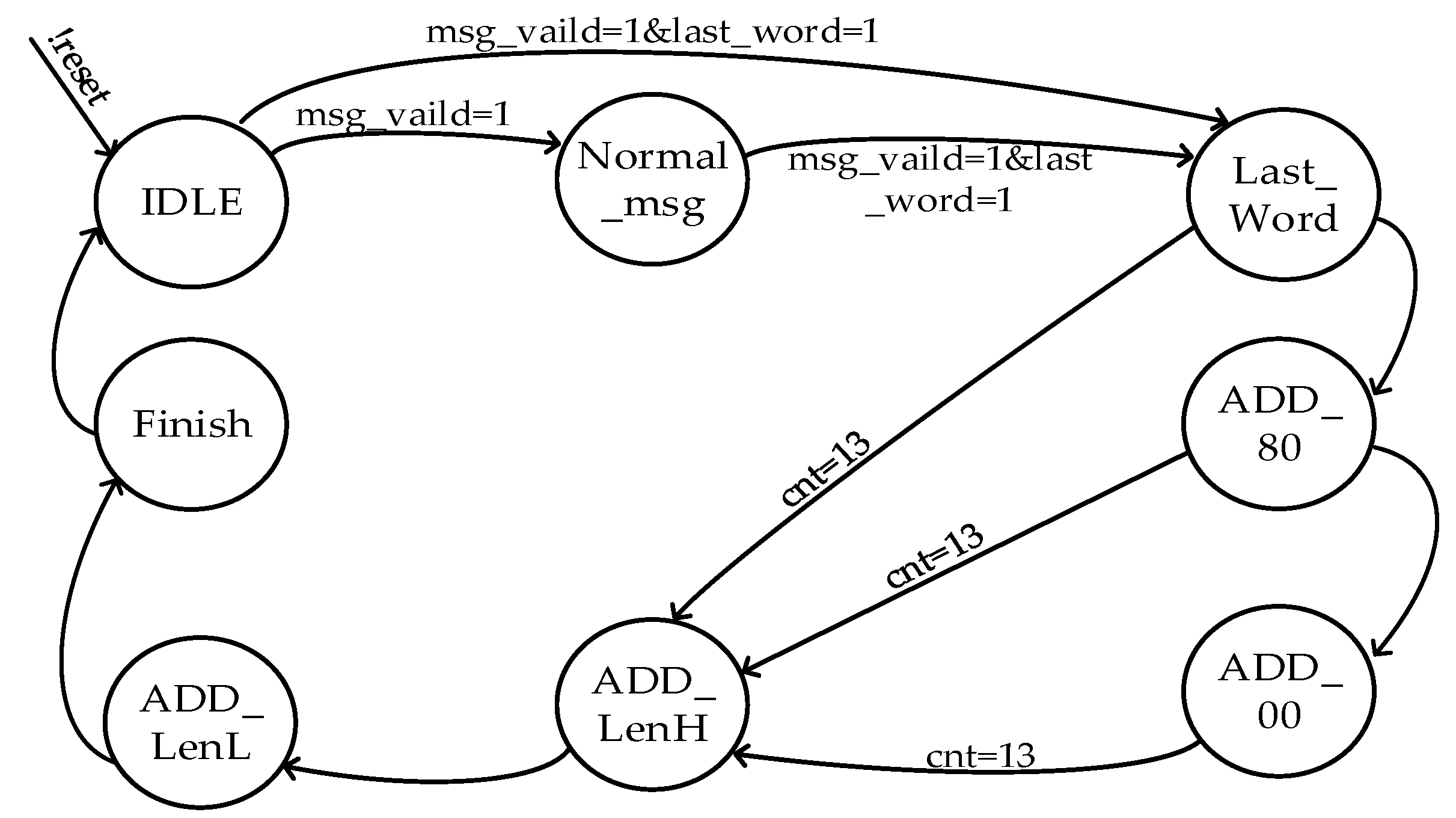
- Message padding. Firstly, the plain message is padded with a single bit “1” followed by bits “0” and a 64-bit string, which is the binary representation of the message length. After padding, the length of the final padded message is a multiple of 512.
- (2)
- Message expansion. The padded message is then divided into several message blocks as , , , . Each message block will be transformed into 132 words as , , , , , , , using the following method:
- The message block is divided into 16 words , , .
- is calculated by:Here, is a permutation function.
- is calculated by:
- (3)
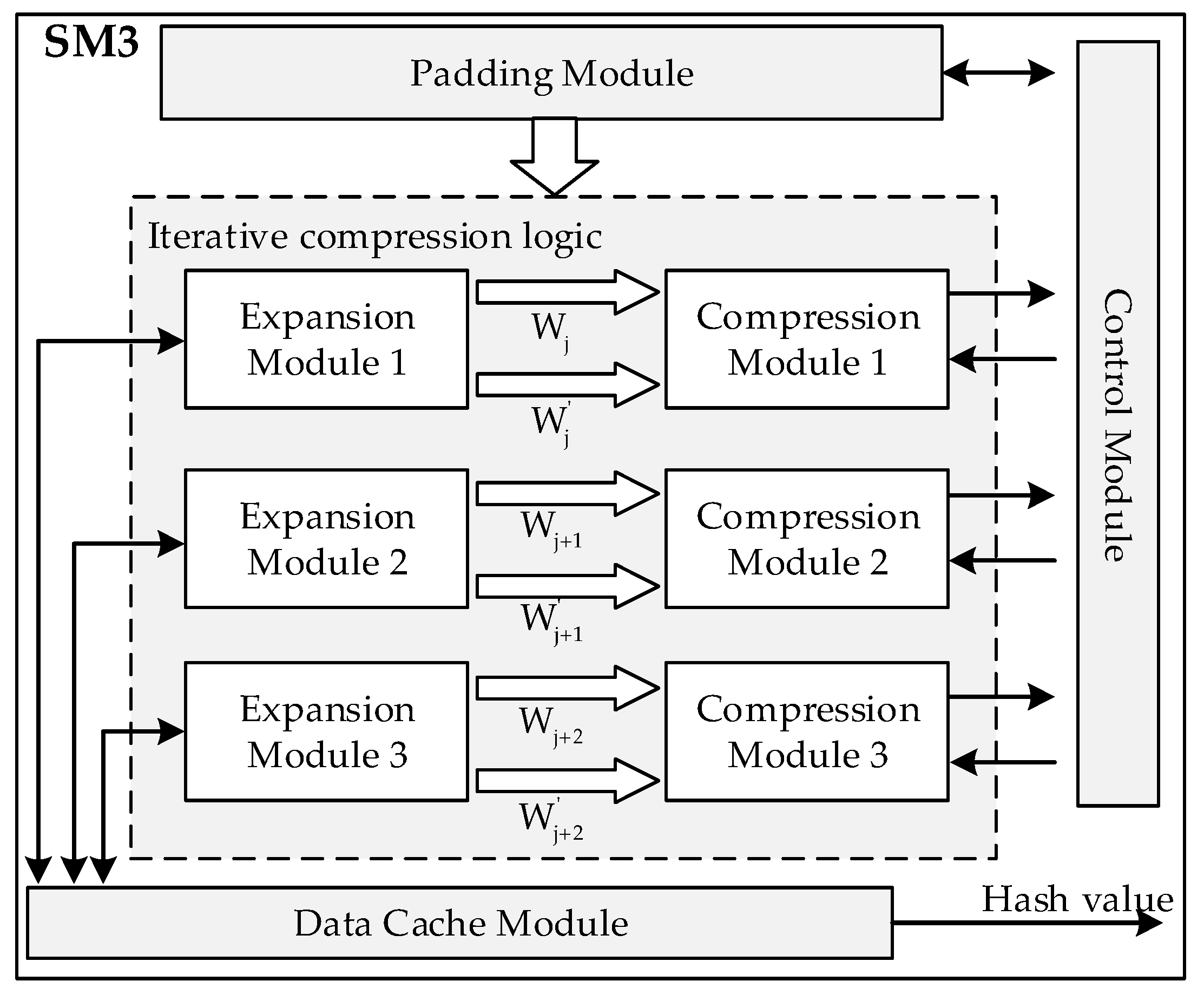
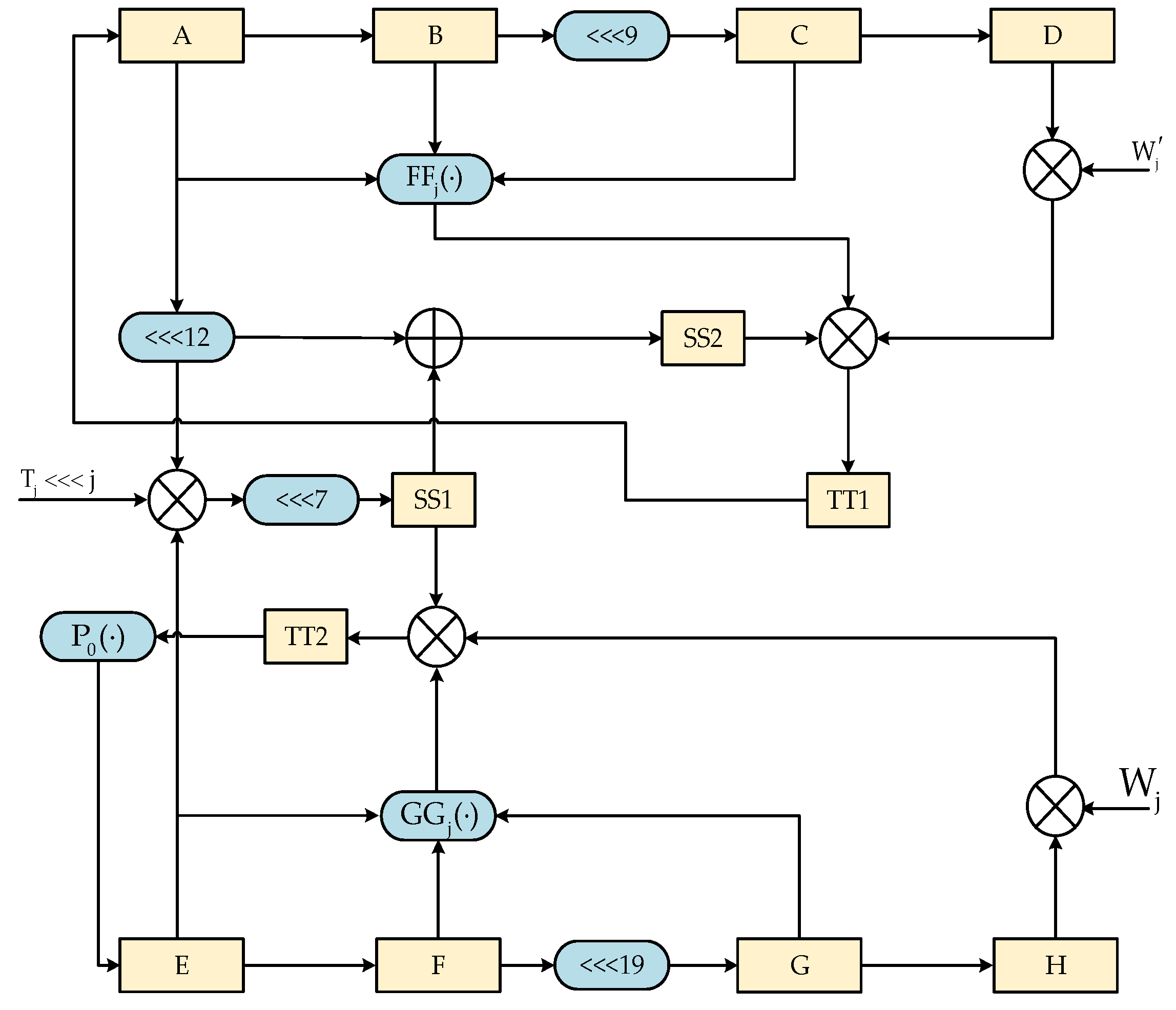
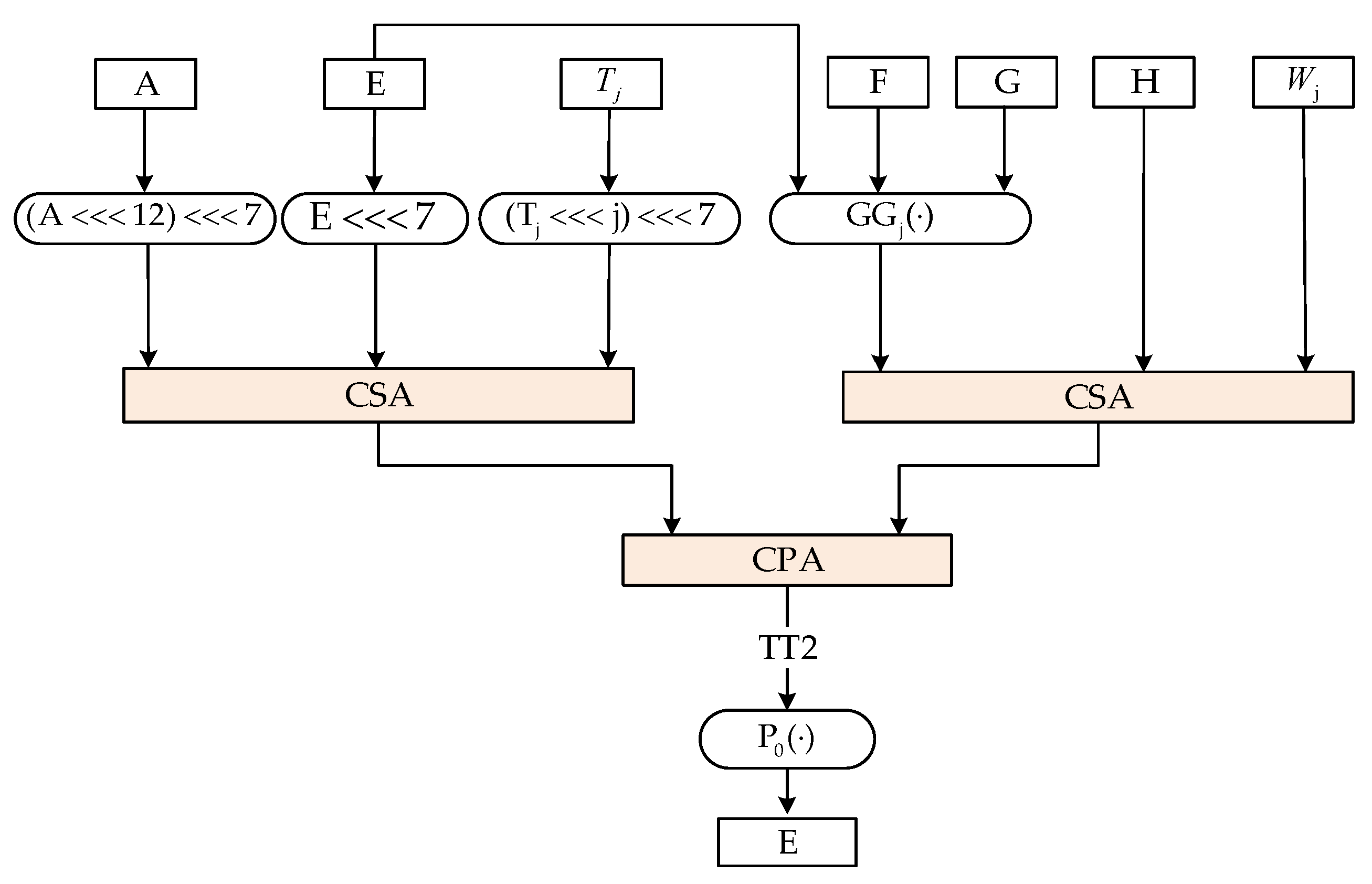
- Message compression. Then, the message block is processed by:where is the compression function. is the initial value of the compression function, which is a 256-bit constant as defined in the algorithm standard. The operation procedure of the compression function can be summarized as follows:where , , , , , , , and are a 32-bit word. , , , and are intermediate variables. is a constant. and are Boolean functions. is a permutation function. The final 256-bit hash value is:
2.2. SM4 Algorithm
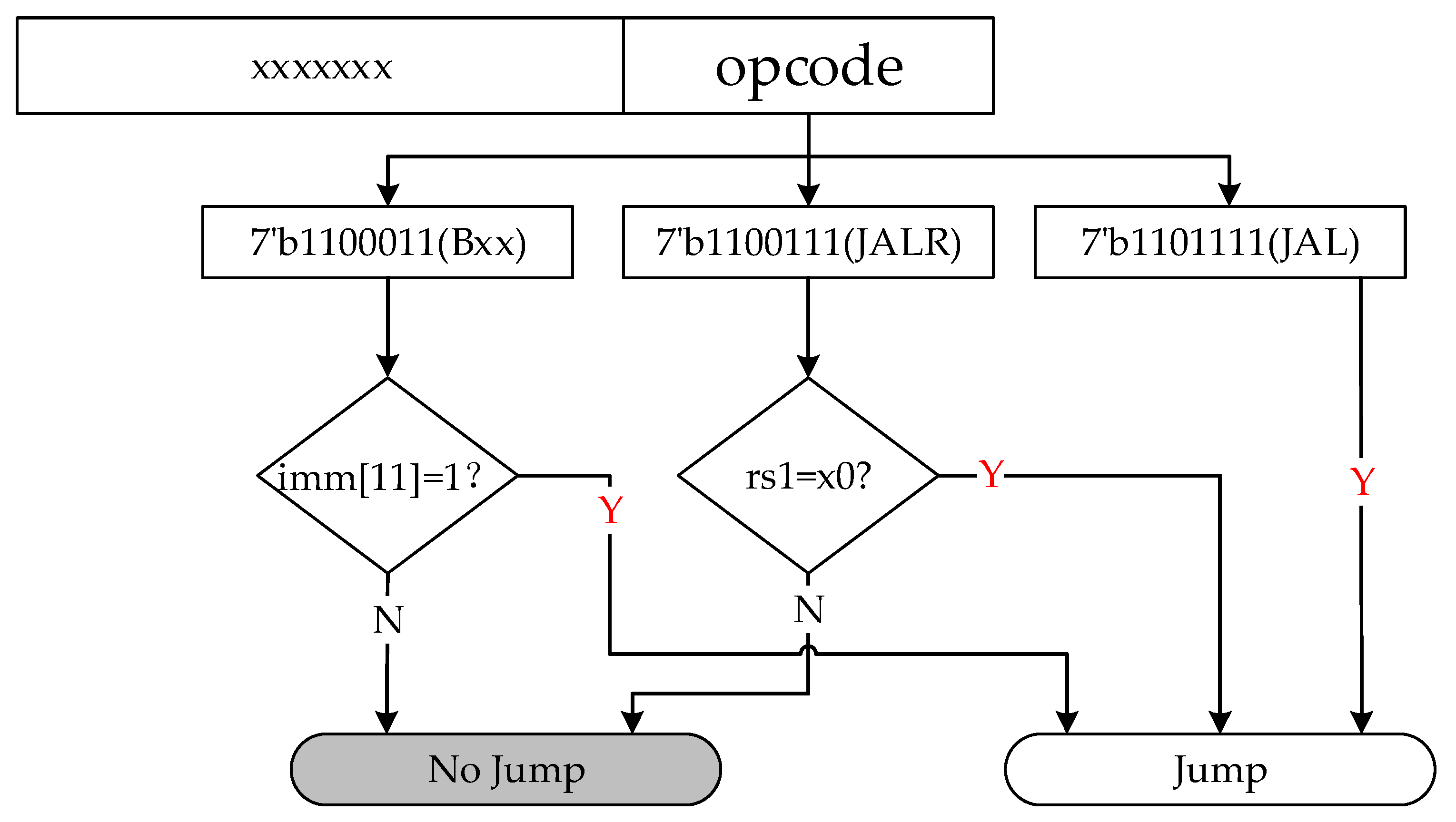
2.3. RISC-V Instruction Set
3. Hardware Implementation
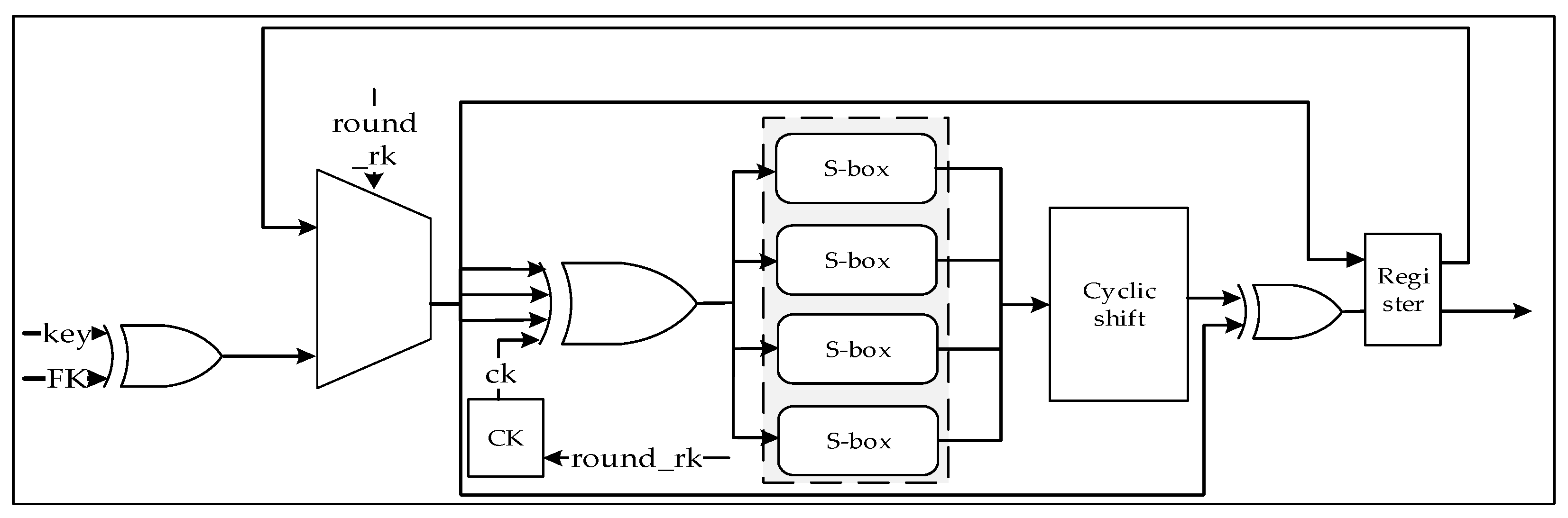
3.1. SM3 Algorithm Accelerator
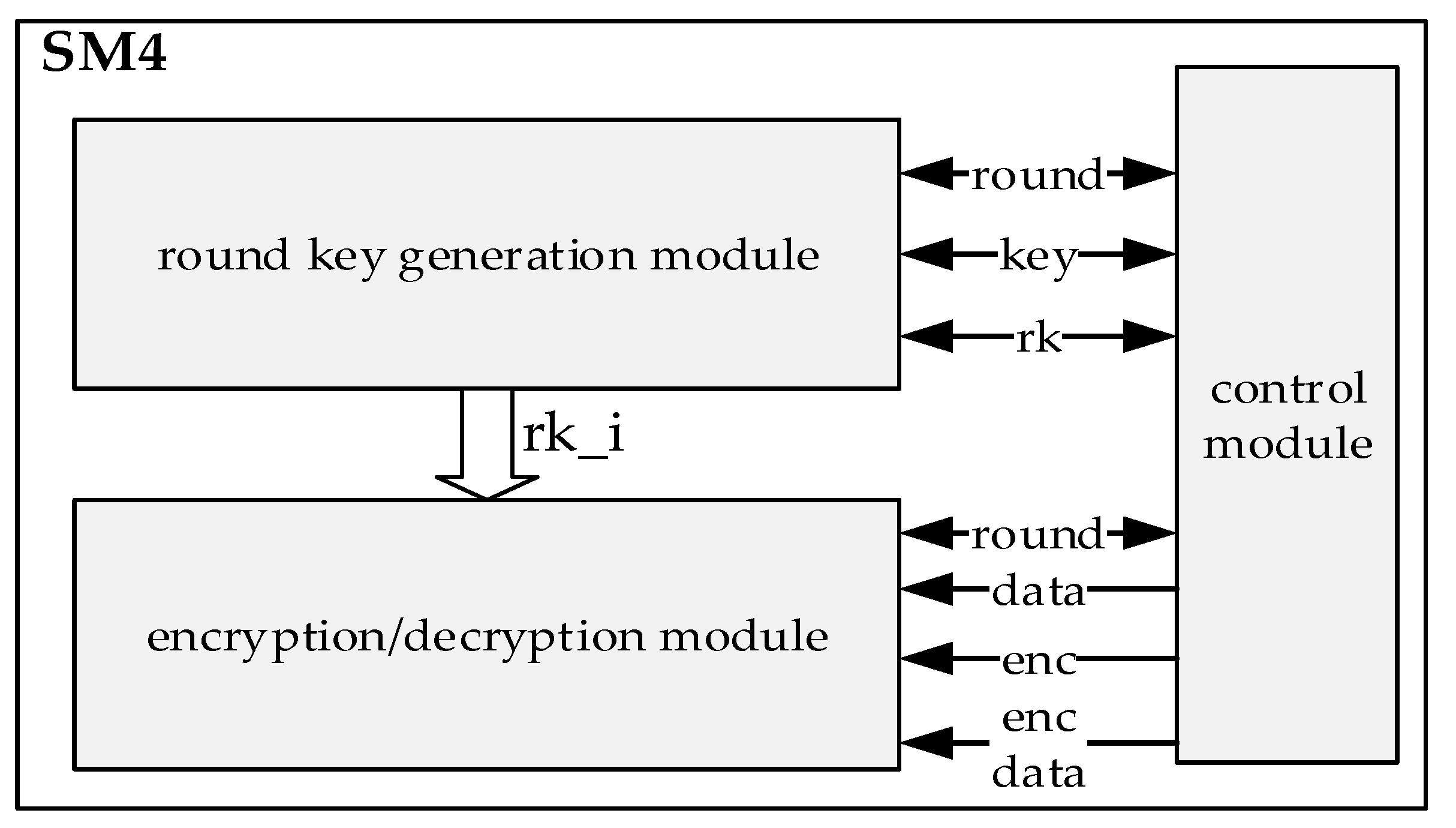
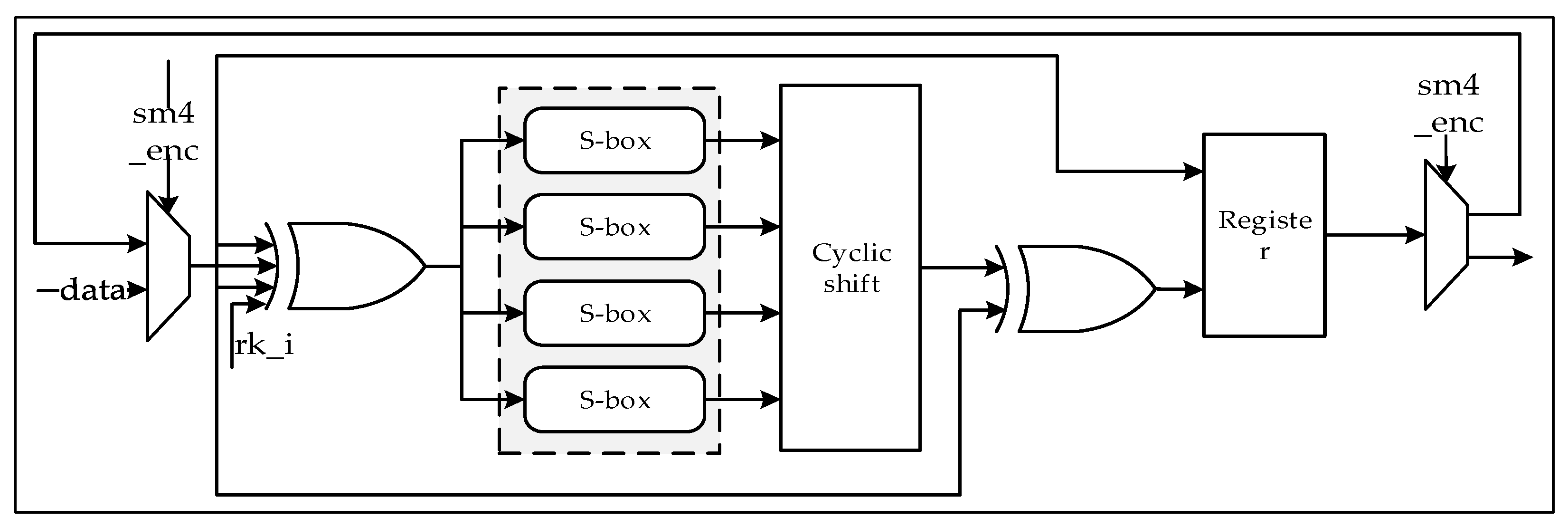
3.2. SM4 Algorithm Accelerator
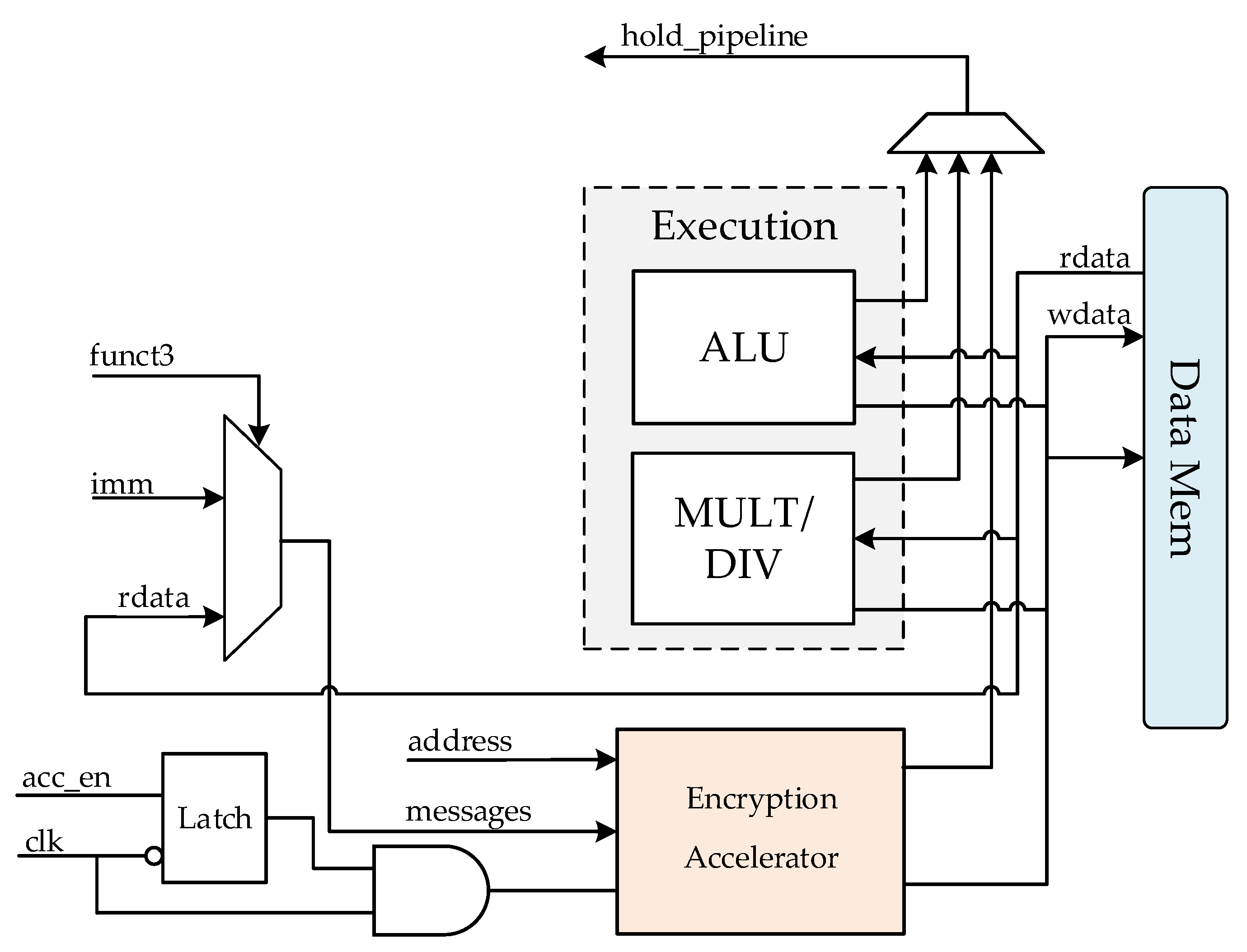
3.3. RISC-V Processor with Encryption Accelerator
4. Results
4.1. Performance Analysis
4.2. FPGA Implementation
4.3. ASIC Implementation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IoT | Internet of Things |
| RISC-V | Reduced Instruction Set Computing—Five |
| ISA | Instruction Set Architecture |
| AES | Advanced Encryption Standard |
| RSA | Rivest–Shamir–Adleman |
| MD5 | Message Digest Algorithm 5 |
| SHA-2 | Secure Hash Algorithm 2 |
| FPGA | Field-Programmable Gate Array |
| CMOS | Complementary Metal–Oxide–Semiconductor |
| ECC | Elliptic Curve Cryptography |
| CPU | Central Processing Unit |
| ALU | Arithmetic Logical Unit |
| SHA-256 | Secure Hash Algorithm 256-bit |
| ASIC | Application-Specific Integrated Circuit |
| FSM | Finite State Machine |
| RAW | Read After Write |
| LUT | Look Up Table |
References
- Bertino, E. Data Security and Privacy in the IoT. In Proceedings of the 19th International Conference on Extending Database Technology (EDBT), Bordeaux, France, 15–18 March 2016; pp. 1–3. [Google Scholar]
- Patil, P.; Sangeetha, M.; Bhaskar, V. Blockchain for IoT access control, security and privacy: A review. Wirel. Pers. Commun. 2021, 117, 1815–1834. [Google Scholar] [CrossRef]
- Bhanot, R.; Hans, R.; Applications, I. A review and comparative analysis of various encryption algorithms. Int. J. Secur. Its Appl. 2015, 9, 289–306. [Google Scholar] [CrossRef]
- Daemen, J.; Rijmen, V. AES Proposal: Rijndael; Free University of Brussels: Ixelles, Belgium, 1998. [Google Scholar]
- Huan, L.; Lei, Z.; Wenling, W.U. Fast software implementation of SM4. J. Univ. Chin. Acad. Sci. 2018, 35, 180. [Google Scholar]
- Milanov, E.J.R.L. The RSA Algorithm; Massachusetts Institute of Technology: Cambridge, MA, USA, 2009; pp. 1–11. [Google Scholar]
- Zhang, Y.; He, D.; Zhang, M.; Choo, K.-K.R. A provable-secure and practical two-party distributed signing protocol for SM2 signature algorithm. Front. Comput. Sci. 2020, 14, 143803. [Google Scholar] [CrossRef]
- Rivest, R. The MD5 Message-Digest Algorithm; Massachusetts Institute of Technology: Cambridge, MA, USA, 1992; pp. 1721–2070. [Google Scholar]
- Chaves, R.; Kuzmanov, G.; Sousa, L.; Vassiliadis, S. Improving SHA-2 hardware implementations. In Proceedings of the Cryptographic Hardware and Embedded Systems-CHES 2006: 8th International Workshop, Yokohama, Japan, 10–13 October 2006; pp. 298–310. [Google Scholar]
- Yu, L.; Wang, Z.; Wang, W. The application of hybrid encryption algorithm in software security. In Proceedings of the 2012 Fourth International Conference on Computational Intelligence and Communication Networks, Mathura, India, 3–5 November 2012; pp. 762–765. [Google Scholar]
- Shende, V.; Kulkarni, M. FPGA based hardware implementation of hybrid cryptographic algorithm for encryption and decryption. In Proceedings of the 2017 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques (ICEECCOT), Mysuru, India, 15–16 November 2017; pp. 416–419. [Google Scholar]
- Chandu, Y.; Kumar, K.R.; Prabhukhanolkar, N.V.; Anish, A.; Rawal, S. Design and implementation of hybrid encryption for security of IOT data. In Proceedings of the 2017 International Conference on Smart Technologies for Smart Nation (SmartTechCon), Bengaluru, India, 17–19 August 2017; pp. 1228–1231. [Google Scholar]
- Hui, Y.; Zesong, L. Research on real-time analysis and hybrid encryption of big data. In Proceedings of the 2019 2nd International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 25–28 May 2019; pp. 52–55. [Google Scholar]
- Zheng, X.; Xu, C.; Hu, X.; Zhang, Y.; Xiong, X. Systems. The software/hardware co-design and implementation of sm2/3/4 encryption/decryption and digital signature system. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2019, 39, 2055–2066. [Google Scholar] [CrossRef]
- Li, J.; Luo, Y.; Wang, F.; Gao, W.J.E. Design and Implementation of Real-Time Image Acquisition Chip Based on Triple-Hybrid Encryption System. Electronics 2022, 11, 2925. [Google Scholar] [CrossRef]
- Hu, Y.; Wu, L.; Wang, A.; Wang, B. Hardware design and implementation of SM3 hash algorithm for financial IC card. In Proceedings of the 2014 Tenth International Conference on Computational Intelligence and Security, Kunming, China, 15–16 November 2014; pp. 514–518. [Google Scholar]
- Mengdi, Z.; Xiaojuan, Z.; Yayun, Z.; Siwei, M. Overview of Randomness Test on Cryptographic Algorithms. J. Phys. Conf. Ser. 2021, 012009. [Google Scholar] [CrossRef]
- Cheng, Y. Study on the Encryption and Decryption of a Hybrid Domestic Cryptographic Algorithm in Secure Transmission of Data Communication. Int. J. Netw. Secur. 2022, 24, 947–952. [Google Scholar]
- Liu, Y.; Zhao, R.; Han, L.; Xie, J. Research and implementation of parallel optimization of SM3 algorithm based on multithread. In Proceedings of the 2022 7th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 15–17 April 2022; pp. 330–336. [Google Scholar]
- Zhou, M.; Ruan, S.; Liu, J.; Chen, X.; Yang, M.; Wang, Q. vTPM-SM: An Application Scheme of SM2/SM3/SM4 Algorithms Based on Trusted Computing in Cloud Environment. In Proceedings of the 2022 IEEE 15th International Conference on Cloud Computing (CLOUD), Barcelona, Spain, 10–16 July 2022; pp. 351–356. [Google Scholar]
- Jiang, Z.; Yan, W.; Ding, W.; Yue, L.; Ding, Q. SM4 Chaotic Masking Scheme against Power Analysis Based on FPGA. Int. J. Bifurc. Chaos 2022, 32, 2250110. [Google Scholar] [CrossRef]
- Rao, J.; Cui, Z.J.A.S. Chosen Plaintext Combined Attack against SM4 Algorithm. Appl. Sci. 2022, 12, 9349. [Google Scholar] [CrossRef]
- Wang, Z.; Dong, H.; Chi, Y.; Zhang, J.; Yang, T.; Liu, Q. Research and Implementation of Hybrid Encryption System Based on SM2 and SM4 Algorithm. In Proceedings of the 9th International Conference on Computer Engineering and Networks, Dalian, China, 22–24 October 2021; pp. 695–702. [Google Scholar]
- Waterman, A.S. Design of the RISC-V Instruction Set Architecture; University of California: Berkeley, CA, USA, 2016. [Google Scholar]
- Waterman, A.; Lee, Y.; Avizienis, R.; Patterson, D.A.; Asanovic, K. The RISC-V instruction set manual volume II: Privileged architecture version 1.7. Tech. Rep. 2015, 1–91. [Google Scholar]
- Flamand, E.; Rossi, D.; Conti, F.; Loi, I.; Pullini, A.; Rotenberg, F.; Benini, L. GAP-8: A RISC-V SoC for AI at the Edge of the IoT. In Proceedings of the 2018 IEEE 29th International Conference on Application-specific Systems, Architectures and Processors (ASAP), Milano, Italy, 10–12 July 2018; pp. 1–4. [Google Scholar]
- Patterson, D. 50 Years of computer architecture: From the mainframe CPU to the domain-specific tpu and the open RISC-V instruction set. In Proceedings of the 2018 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 11–15 February 2018; pp. 27–31. [Google Scholar]
- Patterson, D.; Waterman, A. The RISC-V Reader: An Open Architecture Atlas; Strawberry Canyon: Elsevie, CA, USA, 2017. [Google Scholar]
- De, D.; Das, J.C. Design of novel carry save adder using quantum dot-cellular automata. J. Comput. Sci. 2017, 22, 54–68. [Google Scholar] [CrossRef]
- Bahadori, M.; Kamal, M.; Afzali-Kusha, A.; Afsharnezhad, Y.; Salehi, E.Z.J.I. CL-CPA: A hybrid carry-lookahead/carry-propagate adder for low-power or high-performance operation mode. Integration 2017, 57, 62–68. [Google Scholar] [CrossRef]
- Bowhill, W.J.; Allmon, R.L.; Bell, S.L.; Cooper, E.M.; Donchin, D.; Edmondson, J.; Fischer, T.; Gronowski, P.; Jain, A.; Kroesen, P. A 300 MHz 64 b quad-issue CMOS RISC microprocessor. In Proceedings of the ISSCC’95-International Solid-State Circuits Conference, San Francisco, CA, USA, 5–17 February 1995; pp. 182–183. [Google Scholar]
- Ao, T.; He, Z.; Rao, J.; Dai, K.; Zou, X. A compact hardware implementation of SM3 hash function. In Proceedings of the 2014 IEEE 13th International Conference on Trust, Security and Privacy in Computing and Communications, Beijing, China, 24–26 September 2014; pp. 846–850. [Google Scholar]
- Yong-peng, Y.; Ying-jian, Y.; Wei, L.J. High speed ASIC design and implementation of SM3 algorithm. Microelectron. Comput. 2016, 33, 21–26. [Google Scholar]
- Zheng, X.; Hu, X.; Zhang, J.; Yang, J.; Cai, S.; Xiong, X.J.E. An efficient and low-power design of the SM3 hash algorithm for IoT. Electronics 2019, 8, 1033. [Google Scholar] [CrossRef]
- Ma, Y.; Xia, L.; Lin, J.; Jing, J.; Liu, Z.; Yu, X. Hardware performance optimization and evaluation of SM3 hash algorithm on FPGA. In Proceedings of the Information and Communications Security: 14th International Conference, ICICS 2012, Hong Kong, China, 29–31 October 2012; pp. 105–118. [Google Scholar]
- Zang, S.; Zhao, D.; Hu, Y.; Hu, X.; Gao, Y.; Du, P.; Cheng, S. A high speed SM3 algorithm implementation for security chip. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; pp. 915–919. [Google Scholar]
- Niu, Y.; Jiang, A. The low power design of SM4 cipher with resistance to differential power analysis. In Proceedings of the Sixteenth International Symposium on Quality Electronic Design, Santa Clara, CA, USA, 2–4 March 2015; pp. 470–474. [Google Scholar]
- Bu, X.; Wu, N.; Zhou, F.; Yahya, M.R.; Ge, F. ’A Compact Implementation of SM4 Encryption and Decryption Circuit’. In Proceedings of the Lecture Notes in Engineering and Computer Science: Proceedings of The World Congress on Engineering and Computer Science, San Francisco, CA, USA, 22–24 October 2019; pp. 22–24. [Google Scholar]
- Chen, G.W.; Qiao, S.S.; Yong, H. Design of Low Complexity SM4 Block Cipher IP Core. Sci. Technol. Eng. 2013. [Google Scholar]
- Fu, H.; Bai, G.; Wu, X. Low-cost hardware implementation of SM4 based on composite field. In Proceedings of the 2016 IEEE Information Technology, Networking, Electronic and Automation Control Conference, Chongqing, China, 20–22 May 2016; pp. 260–264. [Google Scholar]
- Zhenbo, H. Teach You to Design CPUs Hand-in-Hand; RISC-V Processor, People’s Posts and Telecommunications Press: Beijing, China, 2018. [Google Scholar]
- Chen, Y.; Chen, H.; Chen, S.; Han, C.; Ye, W.; Liu, Y.; Zhou, H.J.S. DITES: A Lightweight and Flexible Dual-Core Isolated Trusted Execution SoC Based on RISC-V. Sensors 2022, 22, 5981. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plaintext Message (Byte) | Traditional Software Schemes | Hardware Accelerator | Improvement Ratio | ||
|---|---|---|---|---|---|
| Encryption Time (us) | Throughput Rate (MB/s) | Encryption Time (us) | Throughput Rate (MB/s) | ||
| 32 | 135 | 0.24 | 1.02 | 31.37 | 131.24 |
| 64 | 238 | 0.27 | 1.48 | 43.24 | 159.73 |
| 128 | 447 | 0.29 | 1.94 | 65.98 | 229.35 |
| 256 | 760 | 0.34 | 2.86 | 89.51 | 264.69 |
| 512 | 1385 | 0.37 | 4.7 | 108.94 | 293.66 |
| 1024 | 2531 | 0.40 | 8.38 | 122.20 | 301.01 |
| 2048 | 5031 | 0.41 | 15.74 | 130.11 | 318.62 |
| Plaintext Message (Byte) | Traditional Software Schemes | Hardware Accelerator | Improvement Ratio | ||
|---|---|---|---|---|---|
| Encryption Time (us) | Throughput Rate (MB/s) | Encryption Time (us) | Throughput Rate (MB/s) | ||
| 16 | 42.76 | 0.39 | 0.66 | 23.08 | 59.18 |
| 256 | 376.96 | 0.68 | 10.26 | 23.82 | 35.03 |
| 1024 | 1461.31 | 0.70 | 40.98 | 23.83 | 34.04 |
| 2048 | 2888.32 | 0.71 | 81.94 | 23.83 | 33.56 |
| 8192 | 11,519.15 | 0.71 | 327.7 | 23.83 | 33.56 |
| 16,384 | 22,960.42 | 0.71 | 655.38 | 23.83 | 33.56 |
| This Work | [32] Standard | [33] | [34] | [35] | [36] | |
|---|---|---|---|---|---|---|
| Platforms (nm) | 90 | 130 | 65 | 130 | 130 | 40 |
| Frequency (MHz) | 50 | 200 | 526.3 | 36 | 216 | 415 |
| Gates (Gate) | 9537 | 12,956 | 5370 | 6036 | 9458 | 15,750 |
| Throughput (Mb/s) | 1040 | 1506 | 3368 | 263 | 1619 | 6400 |
| Throughput/Frequency | 20.8 | 7.53 | 6.4 | 7.3 | 7.5 | 15.4 |
| This Work | [37] Unpipelined | [37] Pipelined | [38] | [39] | [40] | |
|---|---|---|---|---|---|---|
| Platforms (nm) | 90 | 180 | 180 | 180 | 180 | 130 |
| Frequency (MHz) | 50 | 100 | 100 | 144.9 | 100 | 50 |
| Gates (Gate) | 7224 | 11,535 | 18,609 | 5740 | 8488 | 7612 |
| Throughput (Mb/s) | 190.64 | 570 | 2000 | 272.7 | 100 | 193.9 |
| Throughput/Frequency | 3.8 | 5.7 | 20 | 1.9 | 1.0 | 3.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Shao, L.; Huang, J.; Zou, W. Design and Implementation of Low-Power IoT RISC-V Processor with Hybrid Encryption Accelerator. Electronics 2023, 12, 4222. https://doi.org/10.3390/electronics12204222
Yang S, Shao L, Huang J, Zou W. Design and Implementation of Low-Power IoT RISC-V Processor with Hybrid Encryption Accelerator. Electronics. 2023; 12(20):4222. https://doi.org/10.3390/electronics12204222
Chicago/Turabian StyleYang, Sen, Lian Shao, Junke Huang, and Wanghui Zou. 2023. "Design and Implementation of Low-Power IoT RISC-V Processor with Hybrid Encryption Accelerator" Electronics 12, no. 20: 4222. https://doi.org/10.3390/electronics12204222
APA StyleYang, S., Shao, L., Huang, J., & Zou, W. (2023). Design and Implementation of Low-Power IoT RISC-V Processor with Hybrid Encryption Accelerator. Electronics, 12(20), 4222. https://doi.org/10.3390/electronics12204222