
SC-YOLOv8: A Security Check Model for the Inspection of Prohibited Items in X-ray Images

Abstract
:1. Introduction
- (1)
- A new dataset (LSIray) is provided, which contains high-quality X-ray images of 21 types and sizes of baggage and objects, covering some common categories that have been neglected in previous studies.
- (2)
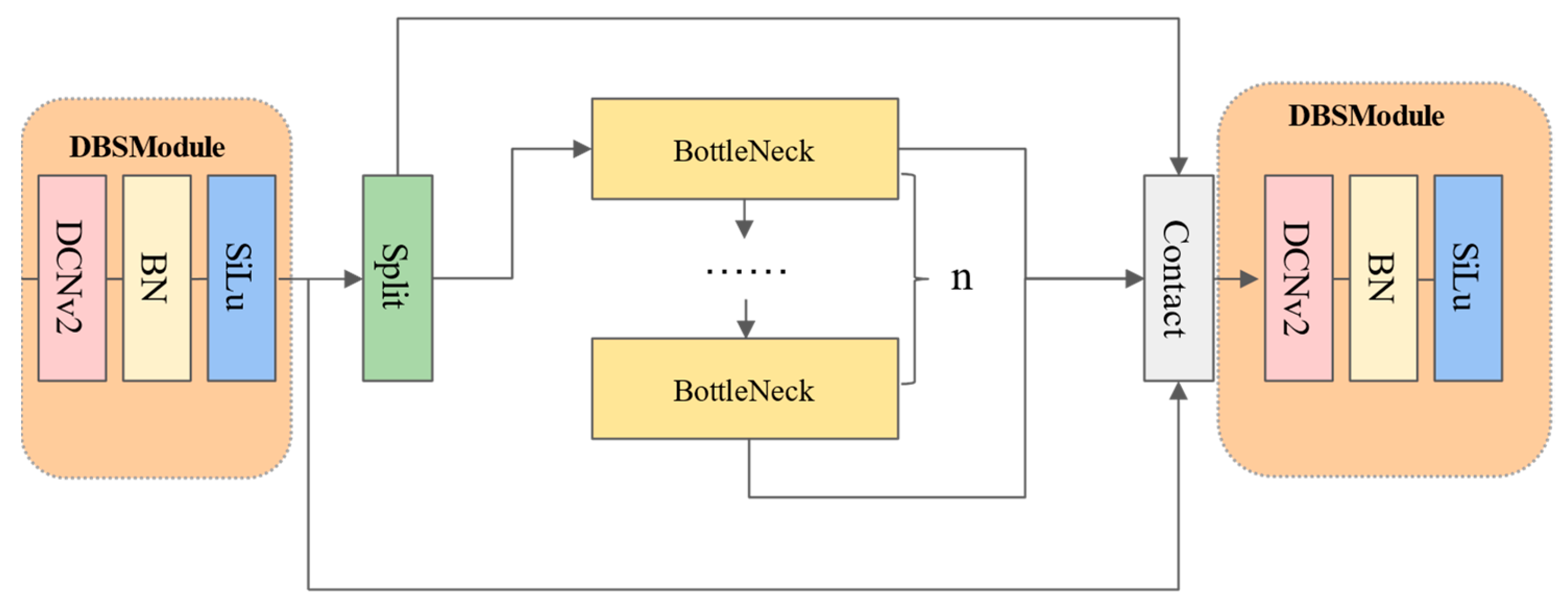
- A new CSPnet Deformable Convolution Network (C2F_DCN) module based on deformable convolution has been introduced to the model. It can adaptively change the position and shape of the receptive field to accommodate targets with different shapes and angles, improving the localization capability of the model.
- (3)
- To enhance the robustness and accuracy of target recognition in complicated scenarios, a Spatial Pyramid Multi-Head Attention module (SPMA) is introduced to the model. This module enables the model to simultaneously utilize different levels and aspects of feature information.
- (4)
- Numerous experiments on the LSIray dataset are conducted, and the method is contrasted with other methods, showing that this method has significant advantages in various metrics.
2. Related Work
2.1. X-ray Security Image Datasets and Benchmarks
2.2. Object Detection
3. The LSIray Dataset
3.1. Data Collection
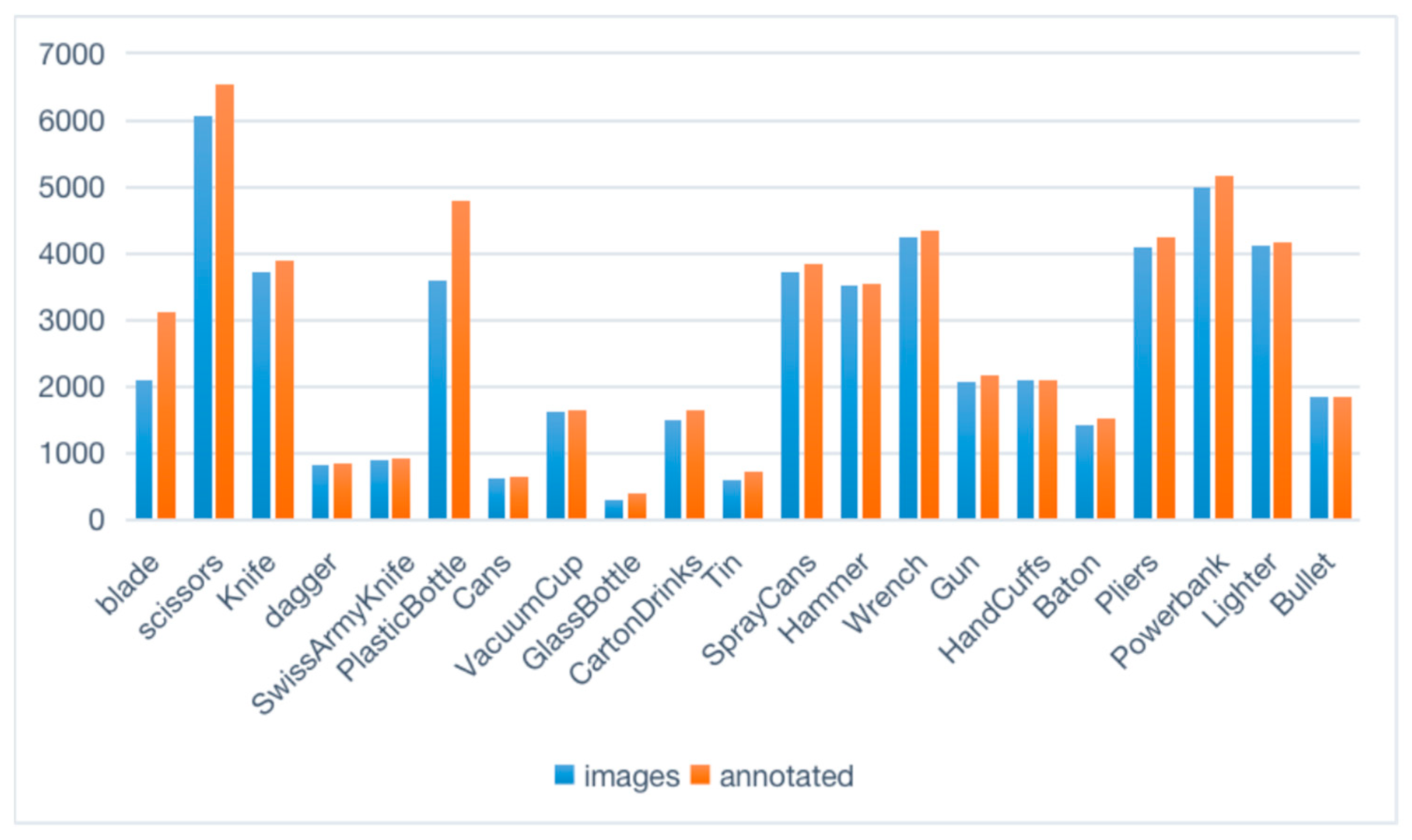
3.2. Data Statistics
4. The Proposed SC-YOLOv8 Algorithm
4.1. Adaptation of Modules with Variable Shapes
4.2. Spatial Pyramid Multi-Head Attention Module
5. Experiments
5.1. Details
5.2. Evaluation Metrics
5.3. Experimental Result Analysis
5.4. Evaluation of Different Categories
5.5. Experiments on the OPIXray Dataset
5.6. Ablation Experiment
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Akcay, S.; Breckon, T. Towards automatic threat detection: A survey of advances of deep learning within X-ray security imaging. arXiv 2020, arXiv:2001.01293. [Google Scholar] [CrossRef]
- Mery, D.; Saavedra, D.; Prasad, M. X-ray Baggage Inspection with Computer Vision: A Survey. IEEE Access 2020, 8, 145620–145633. [Google Scholar] [CrossRef]
- Wei, Y.; Liu, X.; Liu, Y. Research on the application of high-efficiency detectors into the detection of prohibited item in X-ray images. Appl. Intell. 2021, 52, 4807–4823. [Google Scholar] [CrossRef]
- Rafiei, M.; Raitoharju, J.; Iosifidis, A. Computer Vision on X-ray Data in Industrial Production and Security Applications: A Comprehensive Survey. IEEE Access 2023, 11, 2445–2477. [Google Scholar] [CrossRef]
- Kolte, S.; Bhowmik, N. Dhiraj Threat Object-based anomaly detection in X-ray images using GAN-based ensembles. Neural Comput. Appl. 2022, 1–16. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Guo, S.; Tang, S.; Zhu, J.; Fan, J.; Ai, D.; Song, H.; Liang, P.; Yang, J. Improved U-net for guidewire tip segmentation in X-ray fluoroscopy images. In Proceedings of the 2019 3rd International Conference on Advances in Image Processing, Chengdu, China, 8–10 November 2019. [Google Scholar]
- Chaudhary, A.; Hazra, A.; Chaudhary, P. Diagnosis of chest diseases in X-ray images using deep convolutional neural network. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019. [Google Scholar]
- Lu, J.; Tong, K.-Y. Towards to Reasonable Decision Basis in Automatic Bone X-ray Image Classification: A Weakly-Supervised Approach. Proc. Conf. AAAI Artif. Intell. 2019, 33, 9985–9986. [Google Scholar] [CrossRef]
- Miao, C.; Xie, L.; Wan, F.; Su, C.; Liu, H.; Jiao, J.; Ye, Q. SIXray: A Large-Scale Security Inspection X-ray Benchmark for Prohibited Item Discovery in Overlapping Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Huang, S.; Wang, X.; Chen, Y.; Xu, J.; Tang, T.; Mu, B. Modeling and quantitative analysis of X-ray transmission and backscatter imaging aimed at security inspection. Opt. Express 2019, 27, 337–349. [Google Scholar] [CrossRef] [PubMed]
- Akcay, S.; Breckon, T.P. An evaluation of region based object detection strategies within x-ray baggage security imagery. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar] [CrossRef]
- Akcay, S.; Kundegorski, M.E.; Willcocks, C.G.; Breckon, T.P. Using Deep Convolutional Neural Network Architectures for Object Classification and Detection Within X-ray Baggage Security Imagery. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2203–2215. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shu, Y.; Zhang, D. Detection and Recognition of Security Detection Object Based on Yolo9000. In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 23 September 2018. [Google Scholar] [CrossRef]
- Mery, D.; Riffo, V.; Zscherpel, U.; Mondragón, G.; Lillo, I.; Zuccar, I.; Lobel, H.; Carrasco, M. GDXray: The Database of X-ray Images for Nondestructive Testing. J. Nondestruct. Evaluation 2015, 34, 42. [Google Scholar] [CrossRef]
- Wei, Y.; Tao, R.; Wu, Z.; Ma, Y.; Zhang, L.; Liu, X. Occluded Prohibited Items Detection: An X-ray Security Inspection Benchmark and De-occlusion Attention Module. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar] [CrossRef]
- Zhao, C.; Zhu, L.; Dou, S.; Deng, W.; Wang, L. Detecting Overlapped Objects in X-ray Security Imagery by a Label-Aware Mechanism. IEEE Trans. Inf. Forensics Secur. 2022, 17, 998–1009. [Google Scholar] [CrossRef]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chandra, M.A.; Bedi, S.S. Survey on SVM and their application in image classification. Int. J. Inf. Technol. 2018, 13, 1–11. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; p. 29. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, W.; Fu, C.-Y.; Berg, A.-C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; Kaiming, P.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tao, R.; Wei, Y.; Jiang, X.; Li, H.; Qin, H.; Wang, J.; Ma, Y.; Zhang, L.; Liu, X. Towards real-world X-ray security inspection: A high-quality benchmark and lateral inhibition module for pro-hibited items detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Yuan, J.; Zhang, N.; Xie, Y.; Gao, X. Detection of Prohibited Items Based upon X-ray Images and Improved YOLOv7. J. Phys. Conf. Series. 2022, 2390, 012114. [Google Scholar] [CrossRef]
- Dai, J.; Qi, X.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Zhang, H.; Chang, H.; Ma, B.; Wang, N.; Chen, X. Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/cvf Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Liu, D.; Tian, Y.; Xu, Z.; Jian, G. Handling occlusion in prohibited item detection from X-ray images. Neural Comput. Appl. 2022, 34, 20285–20298. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | Classes | Baggage Image | Annotated | Type | Application | Availability |
|---|---|---|---|---|---|---|---|
| GDXray [16] | 2015 | 3 | 8150 | 1552 | Real | C + O | √ |
| Dbf6 [13] | 2017 | 6 | 11,627 | 11,627 | Real | C + O | × |
| Dbf3 [14] | 2018 | 3 | 7603 | 7603 | Real | C + O | × |
| SASC [15] | 2018 | 2 | 3250 | 3250 | Unknown | C + O | × |
| SIXray10 [11] | 2019 | 6 | 88,372 | 8929 | Real | C + O | √ |
| SIXray100 [11] | 882,802 | ||||||
| SIXray1000 [11] | 1,054,231 | ||||||
| OPIXray [17] | 2020 | 5 | 882,802 | 8885 | Synthetic | C + O | √ |
| CLCXray [18] | 2022 | 12 | 1,054,231 | 9565 | Simulated and Real | C + O | √ |
| LSIray (Ours) | 2023 | 21 | 8885 | Real | C + O + I | √ |
| Model | mAP | mAP_50 | mAP_75 | mAP_s | mAP_m | mAP_l |
|---|---|---|---|---|---|---|
| ATSS_lA [18] | 0.724 | 0.875 | 0.832 | 0.819 | 0.35 | 0.755 |
| YOLOv3 [30] | 0.699 | 0.893 | 0.823 | 0.702 | 0.348 | 0.668 |
| SSD [29] | 0.62 | 0.879 | 0.737 | 0.625 | 0.318 | 0.647 |
| faster-rcnn [24] | 0.739 | 0.915 | 0.856 | 0.736 | 0.414 | 0.702 |
| Dynamic_rcnn [39] | 0.742 | 0.924 | 0.862 | 0.778 | 0.425 | 0.733 |
| Fcos [40] | 0.727 | 0.905 | 0.826 | 0.734 | 0.358 | 0.691 |
| YOLOv5 | 0.647 | 0.875 | 0.764 | 0.667 | 0.330 | 0.686 |
| YOLOv8 | 0.813 | 0.933 | 0.895 | 0.809 | 0.490 | 0.775 |
| SC-YOLOv8 (ours) | 0.827 | 0.939 | 0.906 | 0.848 | 0.493 | 0.819 |
| Class | Box(P) | Box(R) | mAP50 | mAP50-95 |
|---|---|---|---|---|
| SC-YOLOv8/YOLOv8 | SC-YOLOv8/YOLOv8 | SC-YOLOv8/YOLOv8 | SC-YOLOv8/YOLOv8 | |
| All | 0.954/0.945 | 0.917/0.91 | 0.943/0.94 | 0.842/0.83 |
| Blade | 0.988/0.982 | 0.984/0.984 | 0.994/0.991 | 0.803/0.792 |
| Scissors | 0.977/0.979 | 0.968/0.946 | 0.986/0.984 | 0.857/0.844 |
| Knife | 0.953/0.968 | 0.906/0.885 | 0.946/0.942 | 0.843/0.838 |
| Dagger | 0.993/0.985 | 0.989/0.989 | 0.99/0.989 | 0.94/0.924 |
| SwissArmyKnife | 0.998/0.993 | 1/1 | 0.995/0.995 | 0.842/0.818 |
| PlasticBottle | 0.909/0.926 | 0.907/0.922 | 0.962/0.963 | 0.829/0.821 |
| Cans | 0.986/0.97 | 0.793/0.784 | 0.895/0.867 | 0.812/0.782 |
| VacuumCup | 0.935/0.954 | 0.994/0.965 | 0.985/0.984 | 0.899/0.886 |
| GlassBottle | 0.525/0.495 | 0.231/0.269 | 0.341/0.325 | 0.289/0.287 |
| CartonDrinks | 0.982/0.989 | 0.971/0.983 | 0.987/0.992 | 0.864/0.854 |
| Tin | 0.949/0.921 | 0.921/0.916 | 0.961/0.957 | 0.849/0.839 |
| SprayCans | 0.958/0.956 | 0.925/0.922 | 0.964/0.961 | 0.875/0.869 |
| Hammer | 0.996/0.987 | 0.989/0.984 | 0.995/0.995 | 0.962/0.961 |
| Wrench | 0.988/0.978 | 0.978/0.973 | 0.985/0.983 | 0.938/0.923 |
| Gun | 0.938/0.936 | 0.984/0.953 | 0.991/0.984 | 0.86/0.853 |
| HandCuffs | 0.989/0.985 | 1/1 | 0.995/0.995 | 0.943/0.94 |
| Baton | 0.964/0.964 | 0.977/0.966 | 0.987/0.986 | 0.91/0.882 |
| Pliers | 0.991/0.991 | 0.993/0.986 | 0.995/0.995 | 0.931/0.92 |
| Powerbank | 0.944/0.936 | 0.959/0.936 | 0.983/0.977 | 0.851/0.845 |
| Lighter | 0.944/0.965 | 0.819/0.789 | 0.894/0.888 | 0.727/0.718 |
| Bullet | 0.955/0.955 | 0.961/0.961 | 0.975/0.975 | 0.853/0.853 |
| Method | Folding_Knife | Straight_Knife | Scissor | Utility_Knife | Tool_Knife | AVG |
|---|---|---|---|---|---|---|
| S-YOLOv4 [41] | 81.44 | 41.07 | 94.70 | 68.25 | 83.67 | 73.83 |
| DOAM [17] | 81.37 | 41.50 | 95.12 | 68.21 | 83.83 | 74.01 |
| MLM [42] | 83.04 | 48.73 | 96.54 | 73.19 | 87.03 | 77.70 |
| YOLOv8 | 88.5 | 82.8 | 96.3 | 82.7 | 89.8 | 88.02 |
| Ours | 91.1 | 82.8 | 97.3 | 85.7 | 89.3 | 89.24 |
| C2F_DCN | MHSA | mAP@0.5:0.95 | AR |
|---|---|---|---|
| 0.813 | 0.798 | ||
| √ | 0.823 | 0.802 | |
| √ | 0.822 | 0.799 | |
| √ | √ | 0.827 | 0.805 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, L.; Ma, C.; Liu, Y.; Jia, J.; Sun, J. SC-YOLOv8: A Security Check Model for the Inspection of Prohibited Items in X-ray Images. Electronics 2023, 12, 4208. https://doi.org/10.3390/electronics12204208
Han L, Ma C, Liu Y, Jia J, Sun J. SC-YOLOv8: A Security Check Model for the Inspection of Prohibited Items in X-ray Images. Electronics. 2023; 12(20):4208. https://doi.org/10.3390/electronics12204208
Chicago/Turabian StyleHan, Li, Chunhai Ma, Yan Liu, Junyang Jia, and Jiaxing Sun. 2023. "SC-YOLOv8: A Security Check Model for the Inspection of Prohibited Items in X-ray Images" Electronics 12, no. 20: 4208. https://doi.org/10.3390/electronics12204208
APA StyleHan, L., Ma, C., Liu, Y., Jia, J., & Sun, J. (2023). SC-YOLOv8: A Security Check Model for the Inspection of Prohibited Items in X-ray Images. Electronics, 12(20), 4208. https://doi.org/10.3390/electronics12204208