

Interactivity Recognition Graph Neural Network (IR-GNN) Model for Improving Human–Object Interaction Detection
Abstract
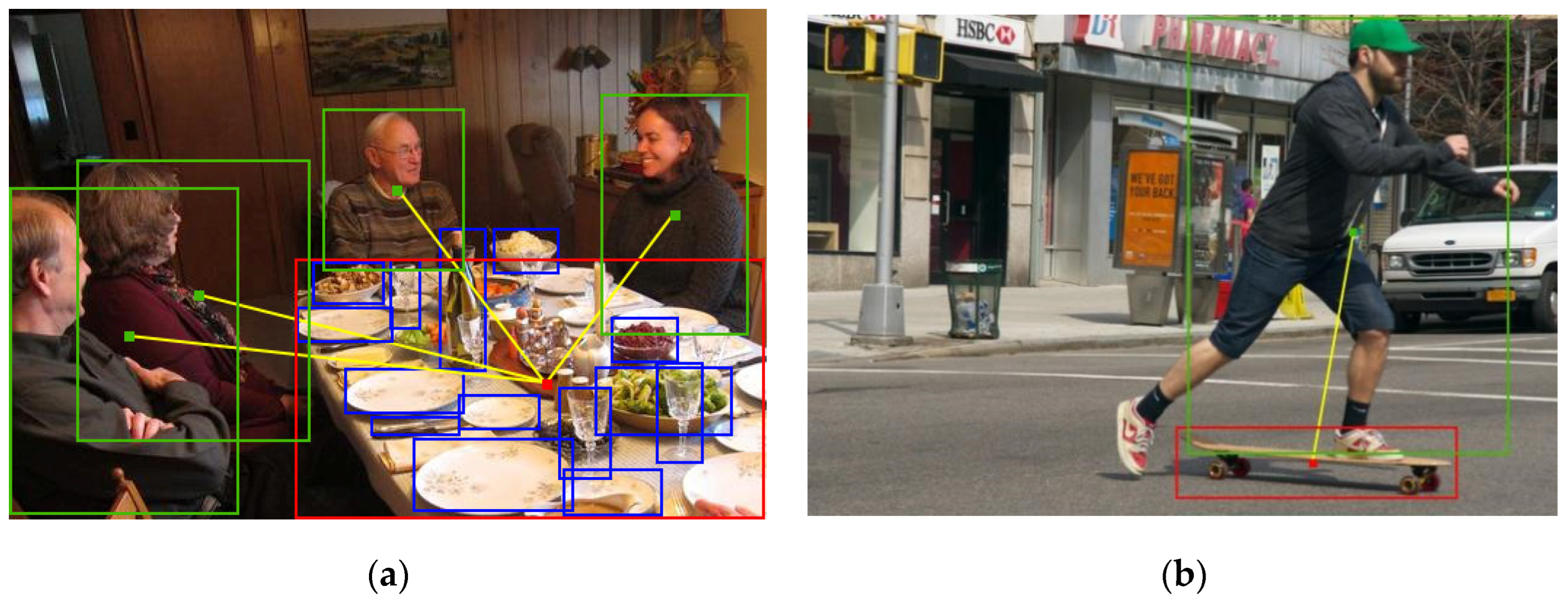
1. Introduction
- (1)
- We present interactivity identification graph neural networks that identify valid interacting human–object pairings to increase the accuracy of human–object interaction detection. Before HOI model inference, removing invalid interactive human–object pairs and carrying only valid interactive human–object pairs for HOI inference helps to improve HOI inference performance.
- (2)
- The advantage of our proposed model on the V-COCO and HICO-DET datasets is proved through experimental and comparative validation.
2. Related Works
2.1. Object Detection
2.2. Human–Object Interaction Detection
2.3. Relative Posture Spatial Detection
2.4. Graph Neural Network
2.5. Transformer-Based HOI Methods
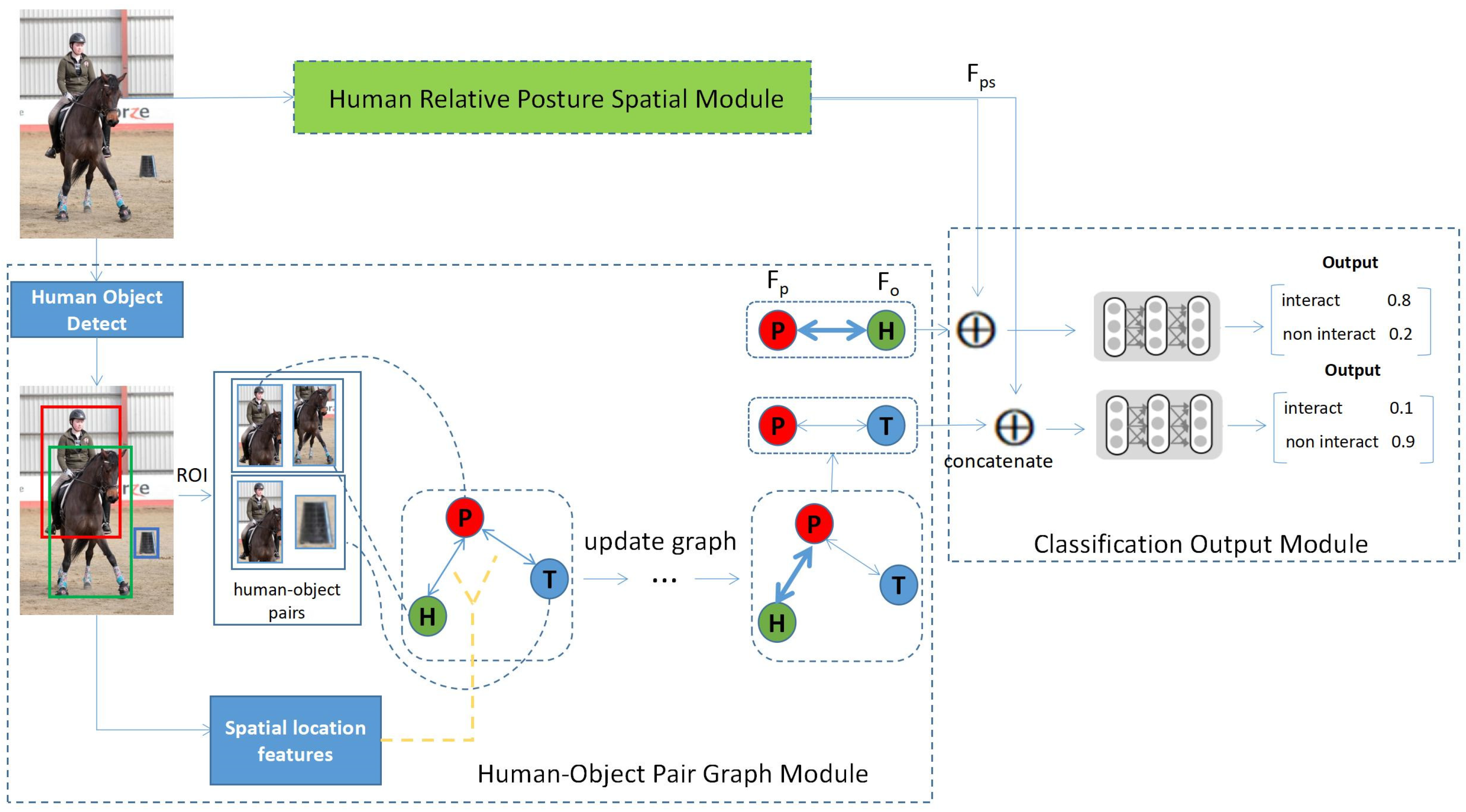
3. Methodology
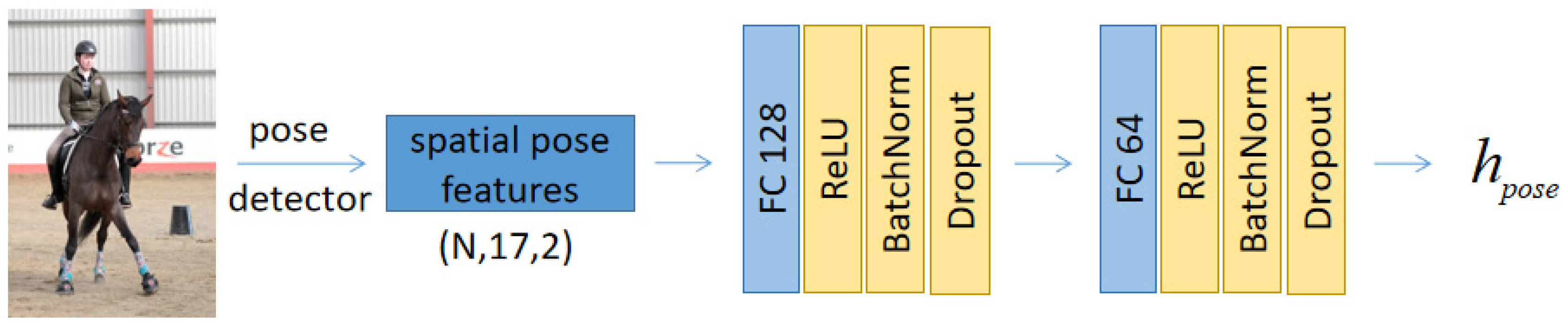
3.1. Human Relative Posture Spatial Module
3.2. Human–Object Pair Graph Module
3.2.1. Instance Feature Extraction of Persons and Objects
3.2.2. Spatial Location Features
3.2.3. Graph Model
3.3. Classification Output Module
4. Experiments
4.1. Experimental Configuration
4.1.1. Experimental Dataset
4.1.2. Evaluation Metrics
4.1.3. Experimental Setting Parameters
5. Result and Discussion
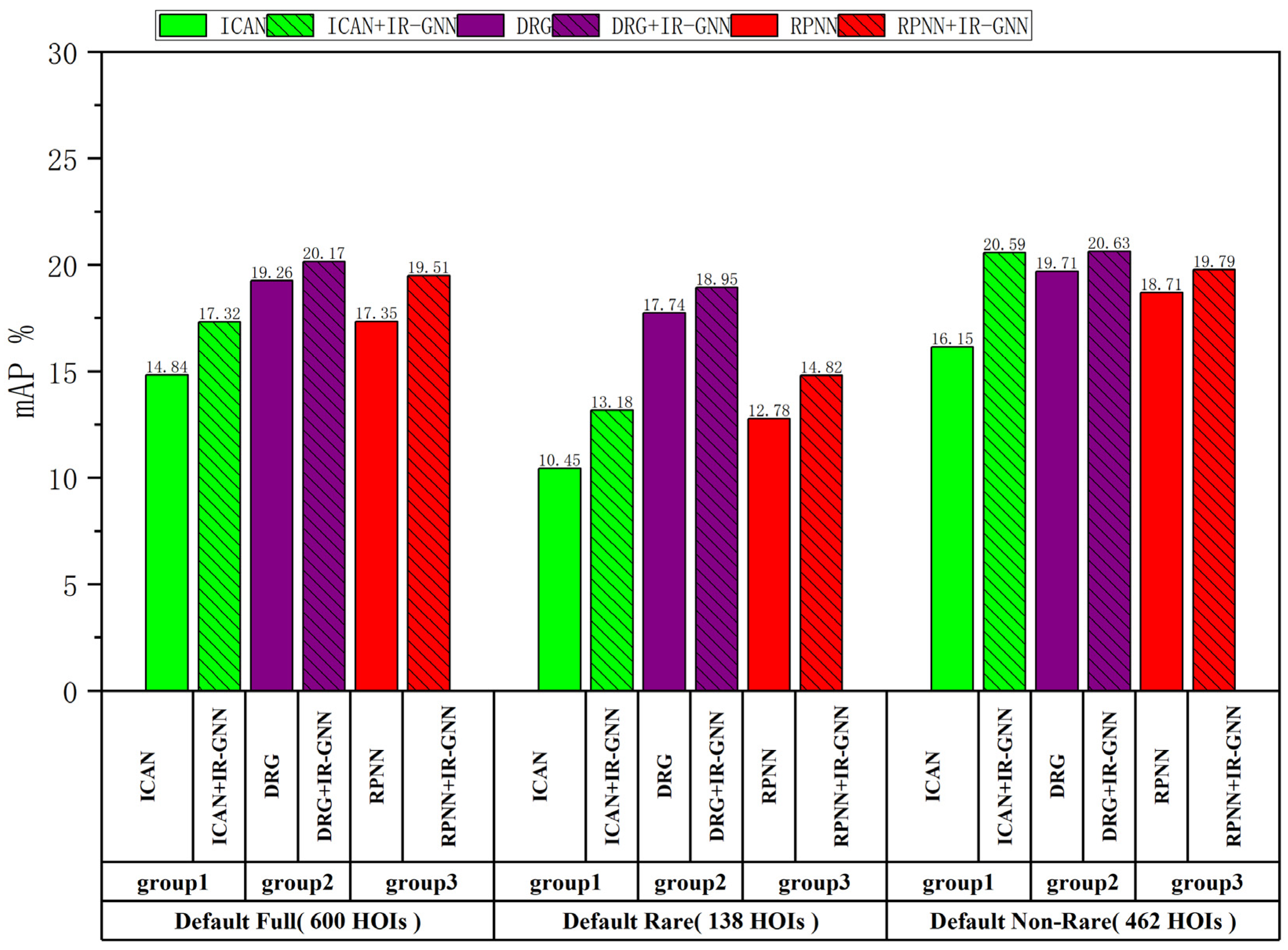
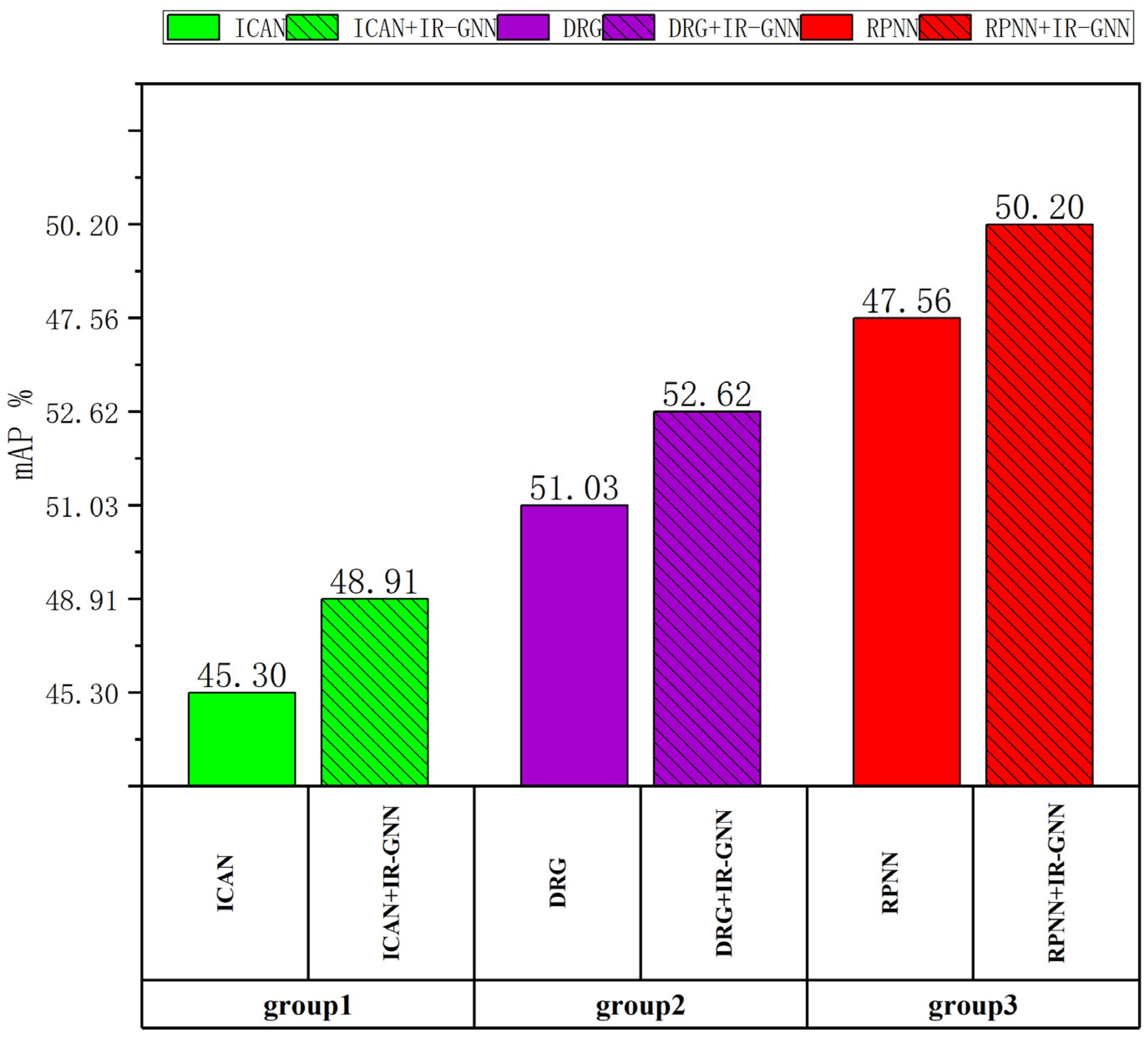
5.1. Comparison with Other Methods
- ICAN [7]. Using an instance-centered attention module, in order to extract contextual features that are complementary to the appearance features of local regions (person and object frames) to improve HOI detection.
- DRG [19]. The contextual information of the aggregated scenes, one of which is human centric and one object centric, was used to refine the prediction by exploiting the relationship between different HOIs. The model effectively captured distinguishing cues from the scenes to resolve ambiguities in local prediction.
- RPNN [20]. Detailed body part features were introduced, and the model incorporated a graph structure for feature refinement, and then the learnable graph model was extended from human and object appearance features to obtain a robust representation.
5.2. Ablation Experiment
5.3. Comparison with TIN
5.4. Qualitative Results
6. Conclusions and Future Work
- Eliminating invalidly interacting human–object pairs before HOI model inference and subjecting only validly interacting human–object pairs to HOI inference helps to improve HOI inference performance. We used our method to improve on existing state-of-the-art methods and conducted comparative experiments on the state-of-the-art methods. As can be seen from Figure 5 and Figure 6, the improved method was significantly better than the original method.
- The human posture information, attention mechanism, human-to-object distance spatial features as initial edge weights, and graph update operations in this paper’s approach all had an enhancing effect on the performance of the model. As can be seen from Table 1, significant results were obtained from ablation experiments in the HICO-DET and V-COCO datasets.
- The higher the rate of excluding false positive samples, the higher the accuracy of human–object interaction detection will be. As can be obtained from Table 2 and Table 3, our method performed better on excluding false interaction pairs, and on subsequent interaction detection experiments, our method removed more invalid interaction pairs, resulting in better results on the accuracy of human–object interaction detection.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sunaina, S.; Kaur, R.; Sharma, D. A Review of Vision-Based Techniques Applied to Detecting Human-Object Interactions in Still Images. J. Comput. Sci. Eng. 2021, 15, 18–33. [Google Scholar] [CrossRef]
- Khaire, P.; Kumar, P. Deep learning and RGB-D based human action, human–human and human–object interaction recognition: A survey. J. Vis. Commun. Image Represent. 2022, 86, 103531. [Google Scholar] [CrossRef]
- Li, Y.-L.; Liu, X.; Wu, X.; Li, Y.; Qiu, Z.; Xu, L.; Xu, Y.; Fang, H.-S.; Lu, C. HAKE: A Knowledge Engine Foundation for Human Activity Understanding. arXiv 2022, arXiv:2202.06851. [Google Scholar] [CrossRef]
- Ashraf, A.H.; Alsufyani, A.; Almutiry, O.; Mahmood, A.; Attique, M.; Habib, M. Weapons detection for security and video surveillance using cnn and YOLO-v5s. CMC-Comput. Mater. Contin. 2022, 70, 2761–2775. [Google Scholar] [CrossRef]
- Wu, B.; Zhong, J.; Yang, C. A visual-based gesture prediction framework applied in social robots. IEEE/CAA J. Autom. Sin. 2021, 9, 510–519. [Google Scholar] [CrossRef]
- Gkioxari, G.; Girshick, R.; Dollár, P.; He, K. Detecting and recognizing human-object interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Gao, C.; Zou, Y.; Huang, J.-B. ican: Instance-centric attention network for human-object interaction detection. arXiv 2018, arXiv:1808.10437. [Google Scholar]
- Fang, H.-S.; Cao, J.; Tai, Y.-W.; Lu, C. Pairwise body-part attention for recognizing human-object interactions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, Y.-L.; Zhou, S.; Huang, X.; Xu, L.; Ma, Z.; Fang, H.-S.; Wang, Y.; Lu, C. Transferable interactiveness knowledge for human-object interaction detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wan, B.; Zhou, D.; Liu, Y.; Li, R.; He, X. Pose-aware multi-level feature network for human object interaction detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Kolesnikov, A.; Kuznetsova, A.; Lampert, C.; Ferrari, V. Detecting visual relationships using box attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Wang, T.; Anwer, R.M.; Khan, M.H.; Khan, F.S.; Pang, Y.; Shao, L.; Laaksonen, J. Deep contextual attention for human-object interaction detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Qi, S.; Wang, W.; Jia, B.; Shen, J.; Zhu, S.C. Learning human-object interactions by graph parsing neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, H.; Zheng, W.-S.; Yingbiao, L. Contextual heterogeneous graph network for human-object interaction detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Xia, L.-M.; Wu, W. Graph-based method for human-object interactions detection. J. Cent. South Univ. 2021, 28, 205–218. [Google Scholar] [CrossRef]
- Liang, Z.; Liu, J.; Guan, Y.; Rojas, J. Visual-semantic graph attention networks for human-object interaction detection. In Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 6–9 December 2021. [Google Scholar]
- Ulutan, O.; Iftekhar, A.; Manjunath, B. Vsgnet: Spatial attention network for detecting human object interactions using graph convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, F.Z.; Campbell, D.; Gould, S. Spatio-attentive Graphs for Human-Object Interaction Detection. arXiv 2020, arXiv:2012.06060. [Google Scholar]
- Gao, C.; Xu, J.; Zou, Y.; Huang, J.-B. Drg: Dual relation graph for human-object interaction detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zhou, P.; Chi, M. Relation parsing neural network for human-object interaction detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Liu, H.; Mu, T.-J.; Huang, X. Detecting human—Object interaction with multi-level pairwise feature network. Comput. Vis. Media 2021, 7, 229–239. [Google Scholar] [CrossRef]
- Liang, Z.; Liu, J.; Guan, Y.; Rojas, J. Pose-based modular network for human-object interaction detection. arXiv 2020, arXiv:2008.02042. [Google Scholar]
- Sun, X.; Hu, X.; Ren, T.; Wu, G. Human object interaction detection via multi-level conditioned network. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020. [Google Scholar]
- Liao, Y.; Liu, S.; Wang, F.; Chen, Y.; Qian, C.; Feng, J. Ppdm: Parallel point detection and matching for real-time human-object interaction detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, T.; Yang, T.; Danelljan, M.; Khan, F.S.; Zhang, X.; Sun, J. Learning human-object interaction detection using interaction points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Kim, B.; Choi, T.; Kang, J.; Kim, H.J. Uniondet: Union-level detector towards real-time human-object interaction detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Chéron, G.; Laptev, I.; Schmid, C. P-cnn: Pose-based cnn features for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Zhou, H.; Ren, D.; Xia, H.; Fan, M.; Yang, X.; Huang, H. AST-GNN: An attention-based spatio-temporal graph neural network for Interaction-aware pedestrian trajectory prediction. Neurocomputing 2021, 445, 298–308. [Google Scholar] [CrossRef]
- Chao, Y.-W.; Chao, Y.W.; Liu, Y.; Liu, X.; Zeng, H.; Deng, J. Learning to detect human-object interactions. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (wacv), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Gupta, S.; Malik, J. Visual semantic role labeling. arXiv 2015, arXiv:1505.04474. [Google Scholar]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Gupta, T.; Schwing, A.; Hoiem, D. No-frills human-object interaction detection: Factorization, layout encodings, and training techniques. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Weinland, D.; Ronfard, R.; Boyer, E. Free viewpoint action recognition using motion history volumes. Comput. Vis. Image Underst. 2006, 104, 249–257. [Google Scholar] [CrossRef]
- Gorelick, L.; Blank, M.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2247–2253. [Google Scholar] [CrossRef]
- Liu, J.; Kuipers, B.; Savarese, S. Recognizing human actions by attributes. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Marszalek, M.; Laptev, I.; Schmid, C. Actions in context. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Wu, Q.; Teney, D.; Wang, P.; Shen, C.; Dick, A.; Hengel, A.V.D. Visual question answering: A survey of methods and datasets. Comput. Vis. Image Underst. 2017, 163, 21–40. [Google Scholar] [CrossRef]
- Zou, C.; Wang, B.; Hu, Y.; Liu, J.; Wu, Q.; Zhao, Y.; Li, B.; Zhang, C.; Zhang, C.; Wei, Y.; et al. End-to-end human object interaction detection with hoi transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11820–11829. [Google Scholar]
- Kim, B.; Lee, J.; Kang, J.; Kim, E.-S.; Kim, H.J. Hotr: End-to-end human-object interaction detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 74–83. [Google Scholar]
- Zhang, Y.; Pan, Y.; Yao, T.; Huang, R.; Mei, T.; Chen, C.-W. Exploring Structure-Aware Transformer Over Interaction Proposals for Human-Object Interaction Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19548–19557. [Google Scholar]
- Wang, H.; Jiao, L.; Liu, F.; Li, L.; Liu, X.; Ji, D.; Gan, W. IPGN: Interactiveness Proposal Graph Network for Human-Object Interaction Detection. IEEE Trans. Image Process. 2021, 30, 6583–6593. [Google Scholar] [CrossRef]
- Wang, M.; Zheng, D.; Ye, Z.; Gan, Q.; Li, M.; Song, X.; Zhou, J.; Ma, C.; Yu, L.; Gai, Y.; et al. Deep graph library: A graph-centric, highly-performant package for graph neural networks. arXiv 2019, arXiv:1909.01315. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment No. | Methods | V-COCO | HICO-DET |
|---|---|---|---|
| 0 | ICAN + IR-GNN | 48.91% | 17.32% |
| 1 | w/o human pose stream | 47.83% | 16.54% |
| 2 | w/o attention | 47.06% | 15.67% |
| 3 | w/o distance space | 46.19% | 15.12% |
| 4 | w/o in graph | 45.89% | 15.08% |
| V-COCO (Recall) | HICO-DET (Recall) | |
|---|---|---|
| TIN [9] | 65.98% | 64.76% |
| IR-GNN | 70.42% | 69.83% |
| V-COCO (mAP) | HICO-DET (mAP) | |
|---|---|---|
| TIN [9] | 48.70% | 17.22% |
| TIN + IR-GNN | 49.85% | 19.51% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Mohd Yunos, Z.; Haron, H. Interactivity Recognition Graph Neural Network (IR-GNN) Model for Improving Human–Object Interaction Detection. Electronics 2023, 12, 470. https://doi.org/10.3390/electronics12020470
Zhang J, Mohd Yunos Z, Haron H. Interactivity Recognition Graph Neural Network (IR-GNN) Model for Improving Human–Object Interaction Detection. Electronics. 2023; 12(2):470. https://doi.org/10.3390/electronics12020470
Chicago/Turabian StyleZhang, Jiali, Zuriahati Mohd Yunos, and Habibollah Haron. 2023. "Interactivity Recognition Graph Neural Network (IR-GNN) Model for Improving Human–Object Interaction Detection" Electronics 12, no. 2: 470. https://doi.org/10.3390/electronics12020470
APA StyleZhang, J., Mohd Yunos, Z., & Haron, H. (2023). Interactivity Recognition Graph Neural Network (IR-GNN) Model for Improving Human–Object Interaction Detection. Electronics, 12(2), 470. https://doi.org/10.3390/electronics12020470