
Robot Manipulation Skills Transfer for Sim-to-Real in Unstructured Environments



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Motivations
1.2. Literature Overview
1.3. Contributions and Organization
2. Robot Admittance Control
2.1. Admittance Controller
2.2. Position Controller
3. Reinforcement Learning
3.1. Fundamental Reinforcement Learning
3.2. eNAC Method
3.2.1. Natural Gradient in the Actor Section
3.2.2. Advantage Function Estimation in the Critic Section
3.2.3. Stochastic Action Selection
3.2.4. Admittance Control Based on the eNAC Algorithm
| Algorithm 1 Robot Admittance Control based on the eNAC Algorithm. |
| Input: initial training parameters, desired training episodes Output: policy parameter while interaction times < desired training episodes do reset to initial state repeat generate action according to policy and status record reward update status: until end of episode if discounted reward qualifies then Critic part: update based on (14) Actor part: update based on (10) end if end while |
4. Contact Task Experiments
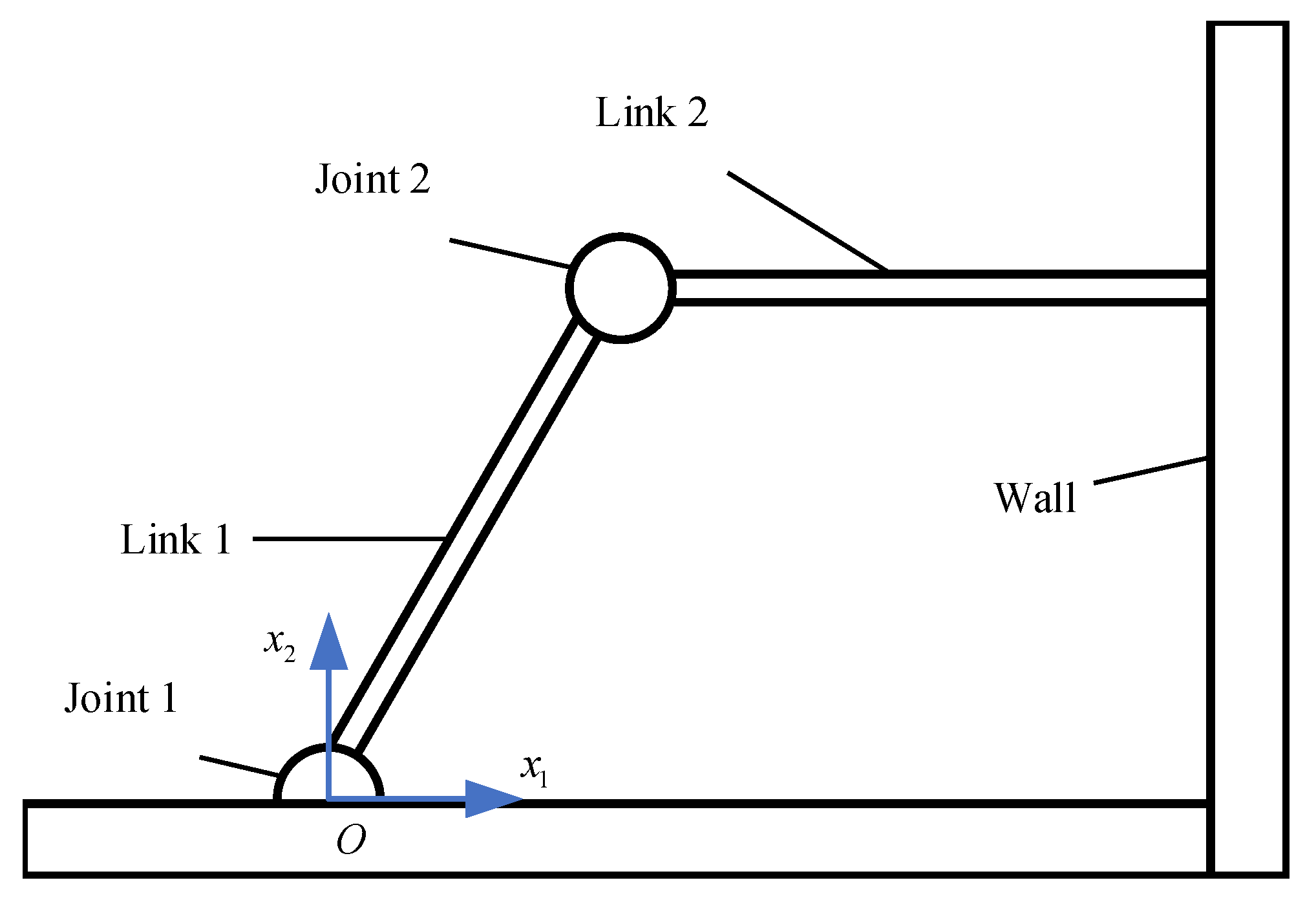
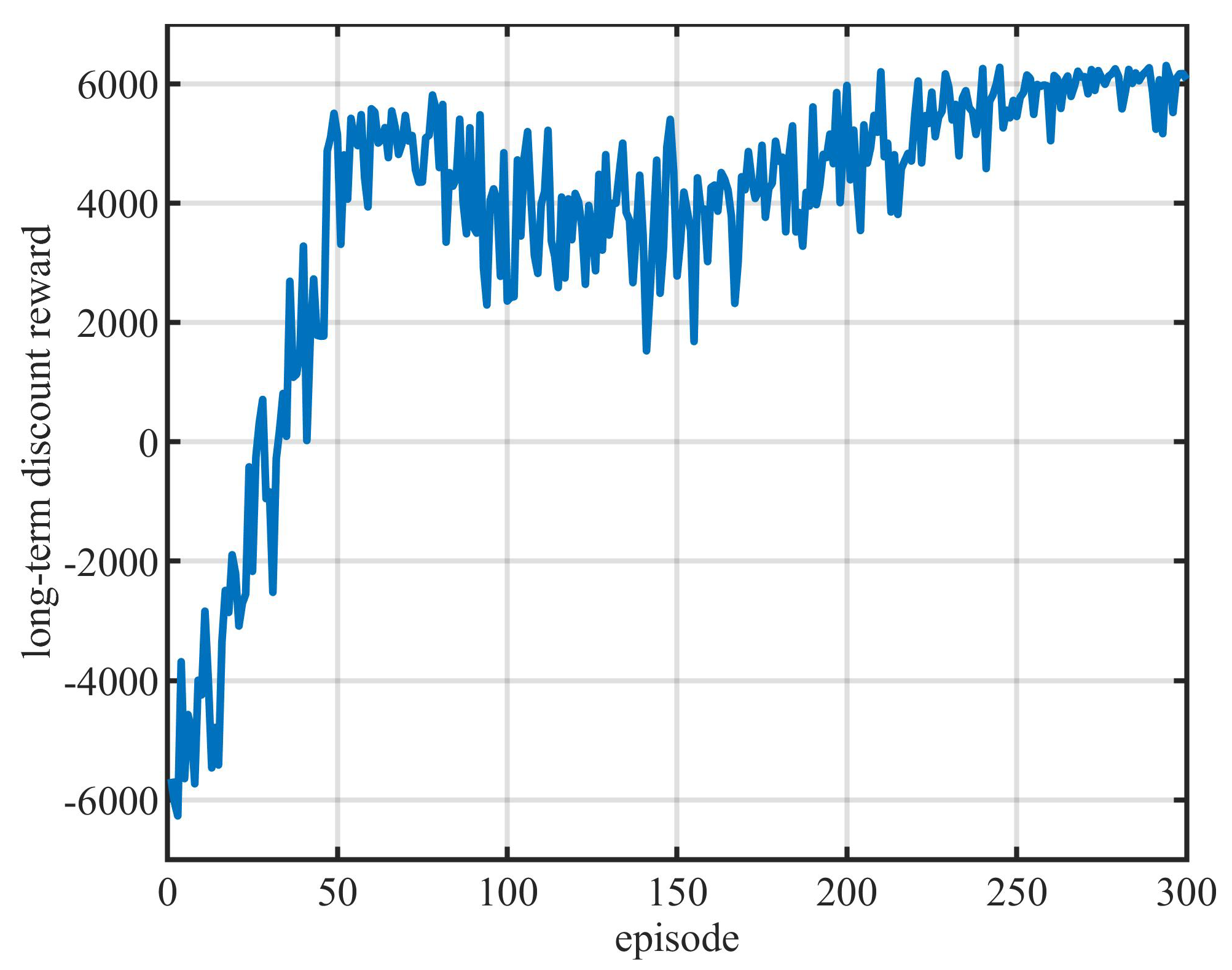
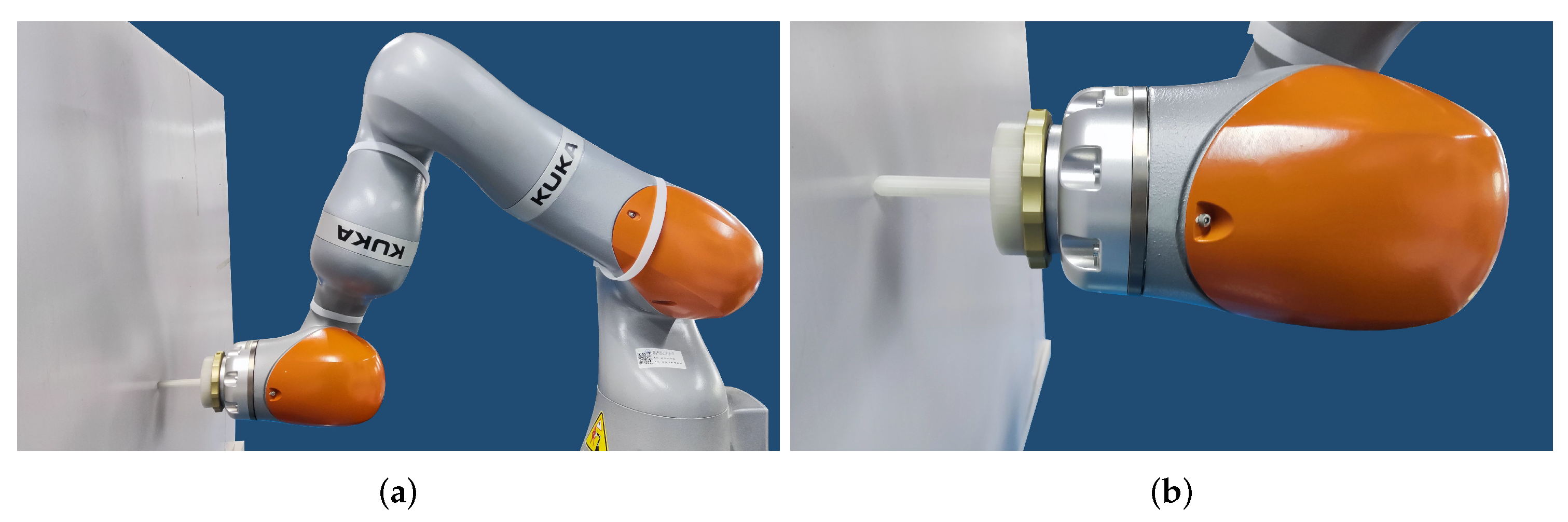
4.1. Moving along a Wall of Unknown Stiffness with a Constant Force
4.2. Opening a Door with Unknown Dynamics
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Prabakaran, V.; Elara, M.R.; Pathmakumar, T.; Nansai, S. Floor Cleaning Robot with Reconfigurable Mechanism. Autom. Constr. 2018, 91, 155–165. [Google Scholar] [CrossRef]
- Bollini, M.; Tellex, S.; Thompson, T.; Roy, N.; Rus, D. Interpreting and Executing Recipes with a Cooking Robot. In Experimental Robotics; Desai, J.P., Dudek, G., Khatib, O., Kumar, V., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2013; Volume 88, pp. 481–495. [Google Scholar] [CrossRef]
- Wang, Z.; Majewicz Fey, A. Deep Learning with Convolutional Neural Network for Objective Skill Evaluation in Robot-Assisted Surgery. Int. J. CARS 2018, 13, 1959–1970. [Google Scholar] [CrossRef] [PubMed]
- Siciliano, B.; Sciavicco, L.; Villani, L.; Oriolo, G. Robotics Modelling, Planning and Control; Advanced Textbooks in Control and Signal Processing; Springer: London, UK, 2009. [Google Scholar] [CrossRef]
- Dini, P.; Saponara, S. Model-Based Design of an Improved Electric Drive Controller for High-Precision Applications Based on Feedback Linearization Technique. Electronics 2021, 10, 2954. [Google Scholar] [CrossRef]
- Bernardeschi, C.; Dini, P.; Domenici, A.; Saponara, S. Co-Simulation and Verification of a Non-linear Control System for Cogging Torque Reduction in Brushless Motors. Int. Conf. Softw. Eng. Form. Methods 2020, 12226, 3–19. [Google Scholar] [CrossRef]
- Sheng, X.; Zhang, X. Fuzzy Adaptive Hybrid Impedance Control for Mirror Milling System. Mechatronics 2018, 53, 20–27. [Google Scholar] [CrossRef]
- Fu, Y.; Lin, W.; Yu, X.; Rodriguez-Andina, J.J.; Gao, H. Robot-Assisted Teleoperation Ultrasound System Based on Fusion of Augmented Reality and Predictive Force. IEEE Trans. Ind. Electron. 2022, 1–8. [Google Scholar] [CrossRef]
- Cao, H.; Chen, X.; He, Y.; Zhao, X. Dynamic Adaptive Hybrid Impedance Control for Dynamic Contact Force Tracking in Uncertain Environments. IEEE Access 2019, 7, 83162–83174. [Google Scholar] [CrossRef]
- Lin, W.; Liu, C.; Guo, H.; Gao, H. Hybrid Visual-Ranging Servoing for Positioning Based on Image and Measurement Features. IEEE Trans. Cybern. 2022, 1–10. [Google Scholar] [CrossRef]
- Stolt, A.; Linderoth, M.; Robertsson, A.; Johansson, R. Force Controlled Robotic Assembly without a Force Sensor. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St Paul, MN, USA, 14–18 May 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1538–1543. [Google Scholar] [CrossRef]
- Nouri, M.; Fussell, B.K.; Ziniti, B.L.; Linder, E. Real-Time Tool Wear Monitoring in Milling Using a Cutting Condition Independent Method. Int. J. Mach. Tools Manuf. 2015, 89, 1–13. [Google Scholar] [CrossRef]
- Peters, J.; Schaal, S. Policy Gradient Methods for Robotics. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–13 October 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 2219–2225. [Google Scholar] [CrossRef]
- Dayanidhi, S.; Hedberg, A.; Valero-Cuevas, F.J.; Forssberg, H. Developmental Improvements in Dynamic Control of Fingertip Forces Last throughout Childhood and into Adolescence. J. Neurophysiol. 2013, 110, 1583–1592. [Google Scholar] [CrossRef]
- Campeau-Lecours, A.; Otis, M.J.D.; Gosselin, C. Modeling of Physical Human–Robot Interaction: Admittance Controllers Applied to Intelligent Assist Devices with Large Payload. Int. J. Adv. Robot. Syst. 2016, 13, 172988141665816. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; Adaptive Computation and Machine Learning Series; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Jung, S.; Hsia, T.; Bonitz, R. Force Tracking Impedance Control of Robot Manipulators Under Unknown Environment. IEEE Trans. Contr. Syst. Technol. 2004, 12, 474–483. [Google Scholar] [CrossRef]
- Peters, J.; Vijayakumar, S.; Schaal, S. Reinforcement Learning for Humanoid Robotics. In Proceedings of the Third IEEE-RAS International Conference on Humanoid Robots, Karlsruhe-Munich, Germany, 29–30 September 2003; pp. 1–20. [Google Scholar]
- Kim, B.; Park, J.; Park, S.; Kang, S. Impedance Learning for Robotic Contact Tasks Using Natural Actor-Critic Algorithm. IEEE Trans. Syst. Man Cybern. B 2010, 40, 433–443. [Google Scholar] [CrossRef]
- Beltran-Hernandez, C.C.; Petit, D.; Ramirez-Alpizar, I.G.; Nishi, T.; Kikuchi, S.; Matsubara, T.; Harada, K. Learning Force Control for Contact-rich Manipulation Tasks with Rigid Position-controlled Robots. IEEE Robot. Autom. Lett. 2020, 5, 5709–5716. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv 2018, arXiv:1801.01290. Available online: http://xxx.lanl.gov/abs/1801.01290 (accessed on 5 March 2022).
- Siciliano, B.; Khatib, O. (Eds.) Springer Handbook of Robotics; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Lee, K.; Buss, M. Force Tracking Impedance Control with Variable Target Stiffness. IFAC Proc. Vol. 2008, 41, 6751–6756. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. Adv. Neural Inf. Process. Syst. 1999, 7, 1057–1063. [Google Scholar]
- Park, J.; Kim, J.; Kang, D. An RLS-Based Natural Actor-Critic Algorithm for Locomotion of a Two-Linked Robot Arm. In Computational Intelligence and Security; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3801, pp. 65–72. [Google Scholar] [CrossRef]
- Stulp, F.; Buchli, J.; Ellmer, A.; Mistry, M.; Theodorou, E.A.; Schaal, S. Model-Free Reinforcement Learning of Impedance Control in Stochastic Environments. IEEE Trans. Auton. Ment. Dev. 2012, 4, 330–341. [Google Scholar] [CrossRef]
- Dini, P.; Saponara, S. Design of Adaptive Controller Exploiting Learning Concepts Applied to a BLDC-Based Drive System. Energies 2020, 13, 2512. [Google Scholar] [CrossRef]
- Dini, P.; Saponara, S. Processor-in-the-Loop Validation of a Gradient Descent-Based Model Predictive Control for Assisted Driving and Obstacles Avoidance Applications. IEEE Access 2022, 10, 67958–67975. [Google Scholar] [CrossRef]
- Safeea, M.; Neto, P. KUKA Sunrise Toolbox: Interfacing Collaborative Robots with MATLAB. IEEE Robot. Autom. Mag. 2019, 26, 91–96. [Google Scholar] [CrossRef]
- Corke, P. Robotics, Vision and Control; Springer Tracts in Advanced Robotics; Springer International Publishing: Cham, Switzerland, 2017; Volume 118. [Google Scholar] [CrossRef]



















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, Z.; Ye, C.; An, H.; Lin, W.; Wang, Z. Robot Manipulation Skills Transfer for Sim-to-Real in Unstructured Environments. Electronics 2023, 12, 411. https://doi.org/10.3390/electronics12020411
Yin Z, Ye C, An H, Lin W, Wang Z. Robot Manipulation Skills Transfer for Sim-to-Real in Unstructured Environments. Electronics. 2023; 12(2):411. https://doi.org/10.3390/electronics12020411
Chicago/Turabian StyleYin, Zikang, Chao Ye, Hao An, Weiyang Lin, and Zhifeng Wang. 2023. "Robot Manipulation Skills Transfer for Sim-to-Real in Unstructured Environments" Electronics 12, no. 2: 411. https://doi.org/10.3390/electronics12020411
APA StyleYin, Z., Ye, C., An, H., Lin, W., & Wang, Z. (2023). Robot Manipulation Skills Transfer for Sim-to-Real in Unstructured Environments. Electronics, 12(2), 411. https://doi.org/10.3390/electronics12020411