
Robust and Lightweight Deep Learning Model for Industrial Fault Diagnosis in Low-Quality and Noisy Data



Abstract
1. Introduction
- We investigated the impact of three sound data pre-processing methods (the Hilbert transform, DWT, and the STFT) on deep learning model performance.
- We investigated the model performance on lower data qualities and with random noise, with the goal of gauging model performance in real-world factory settings.
2. Related Works
3. Feature Engineering
3.1. Discrete Wavelet Transform (DWT)
3.2. Hilbert Transform
3.3. Short-Time Fourier Transform (STFT)
4. Model Architecture
4.1. CNN
4.2. CNN–LSTM
5. Experimental Results
5.1. MIMII Dataset
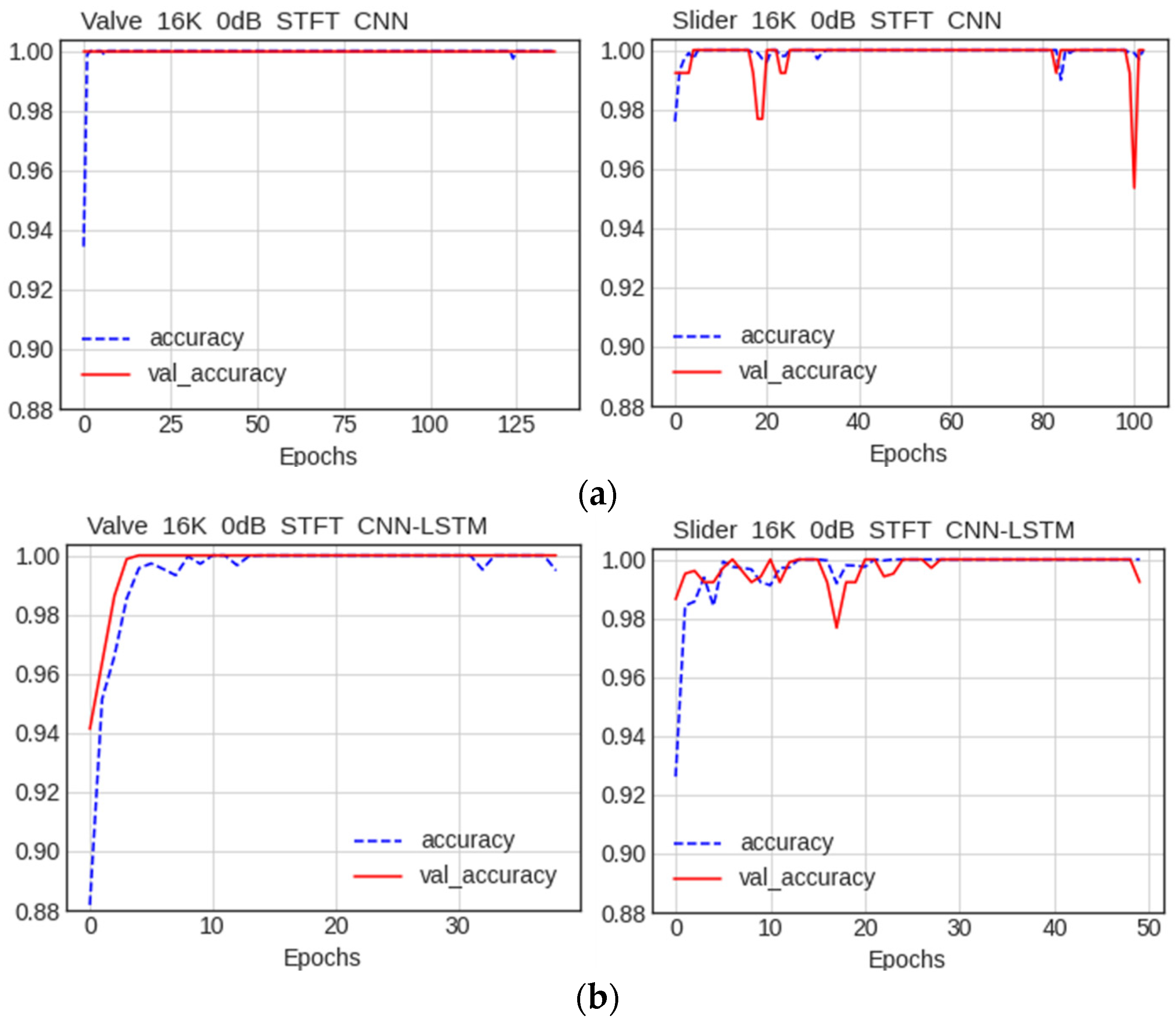
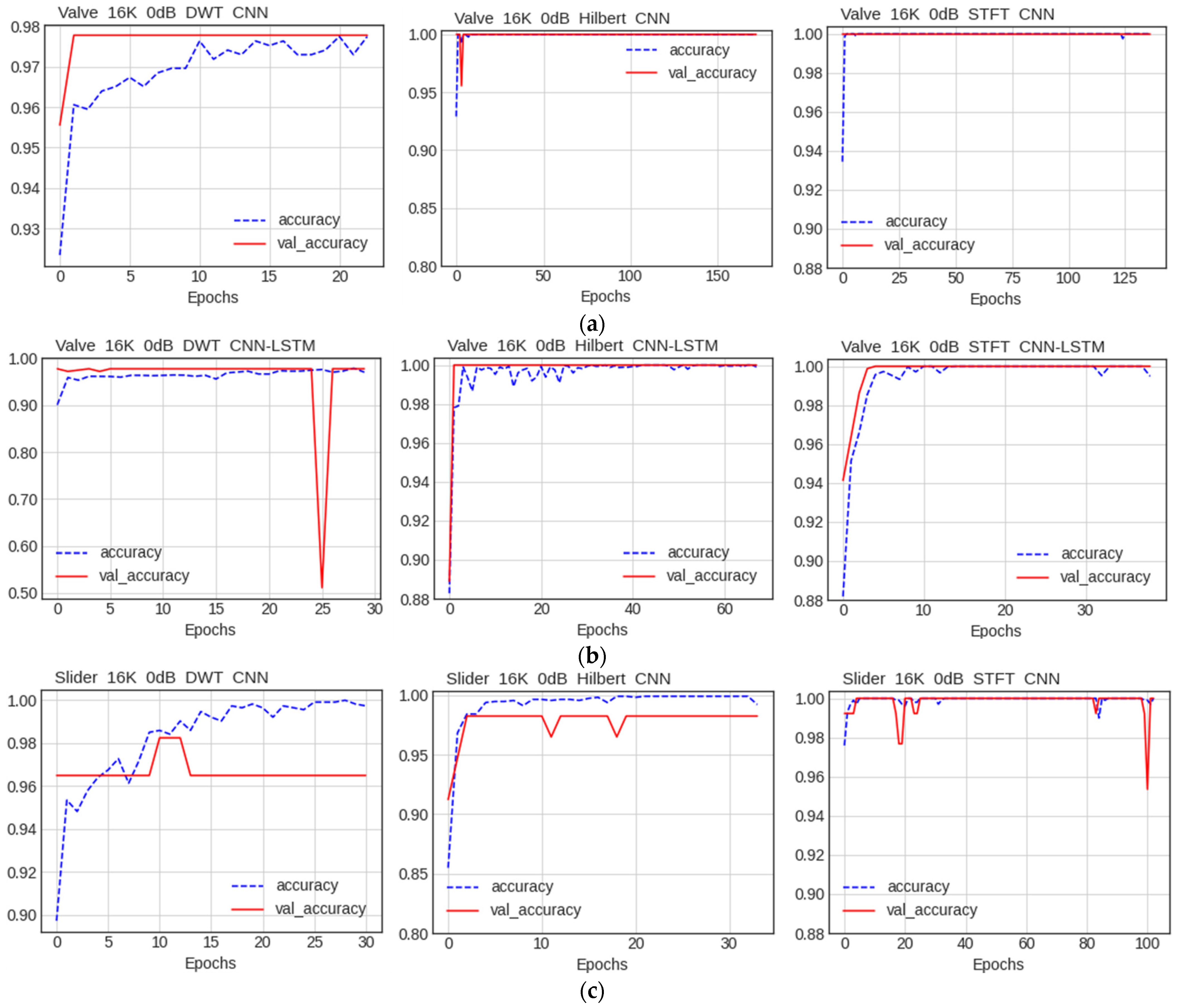
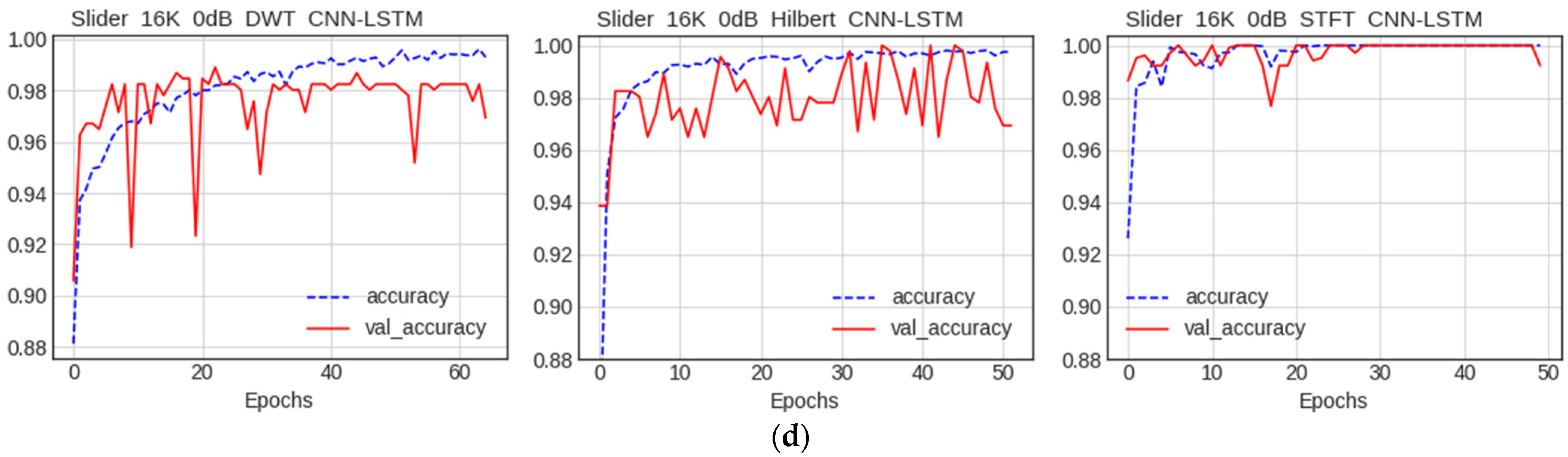
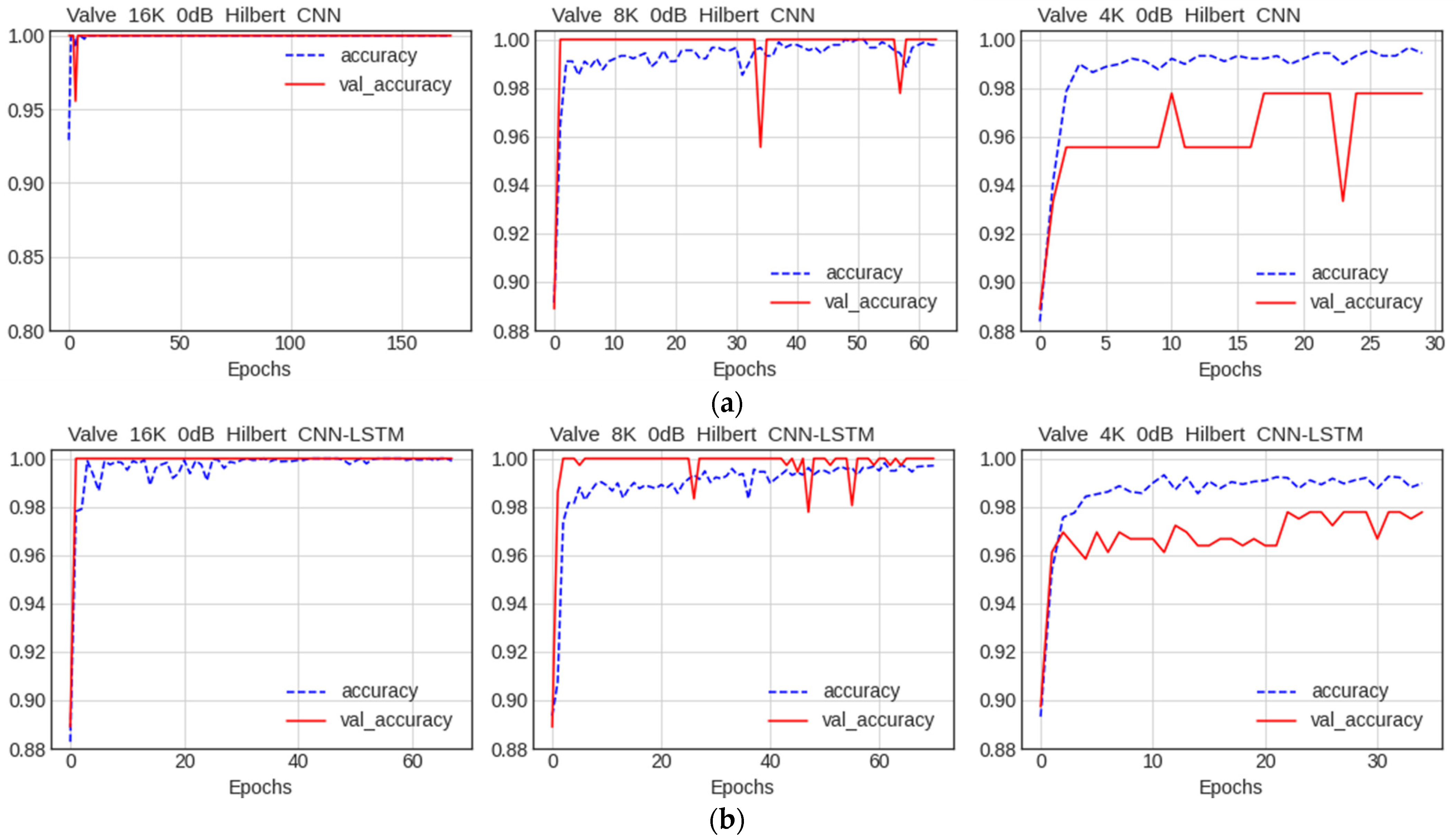
5.2. Comparison between CNN and CNN–LSTM Models
5.2.1. Comparison of Accuracy
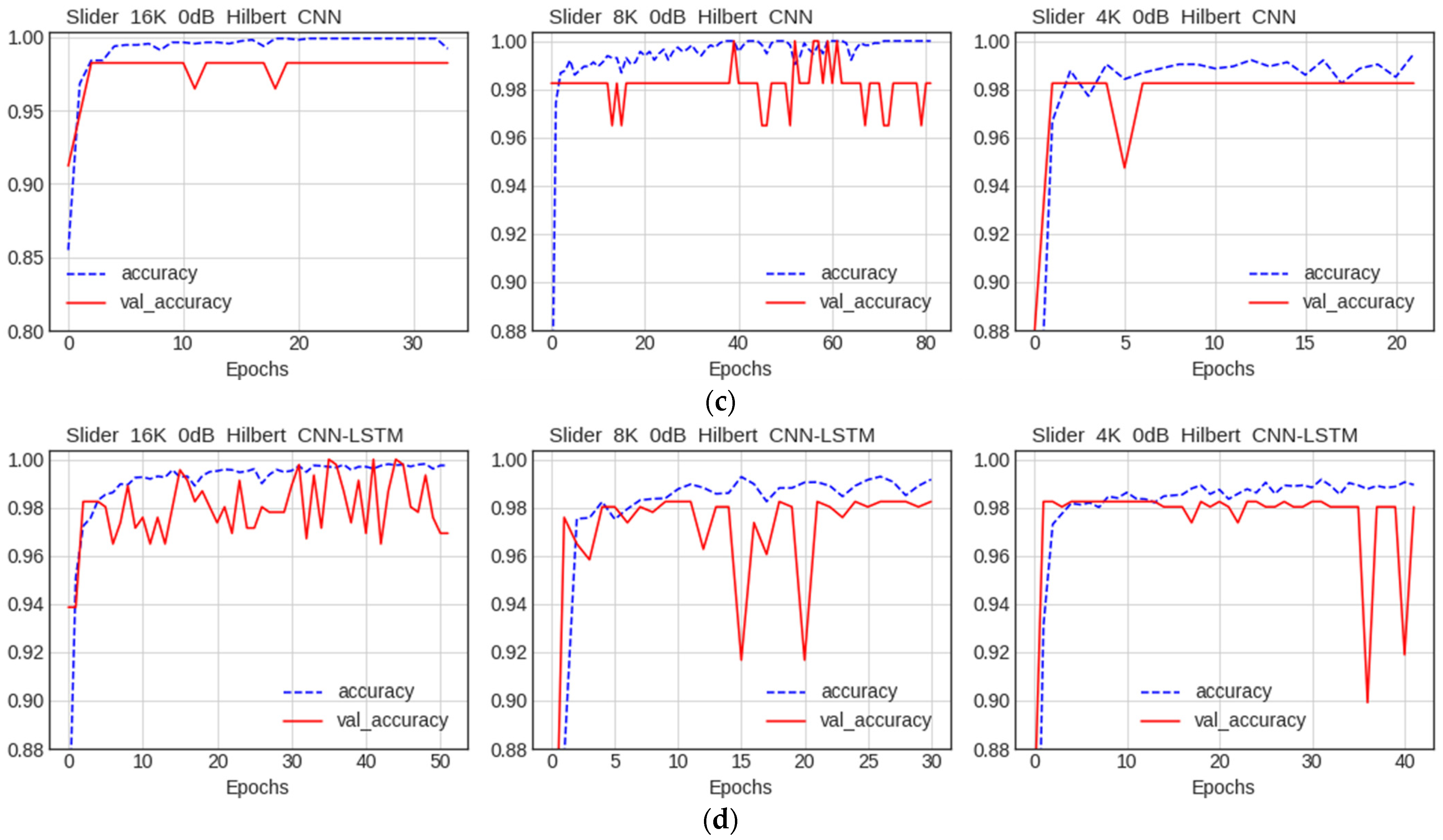
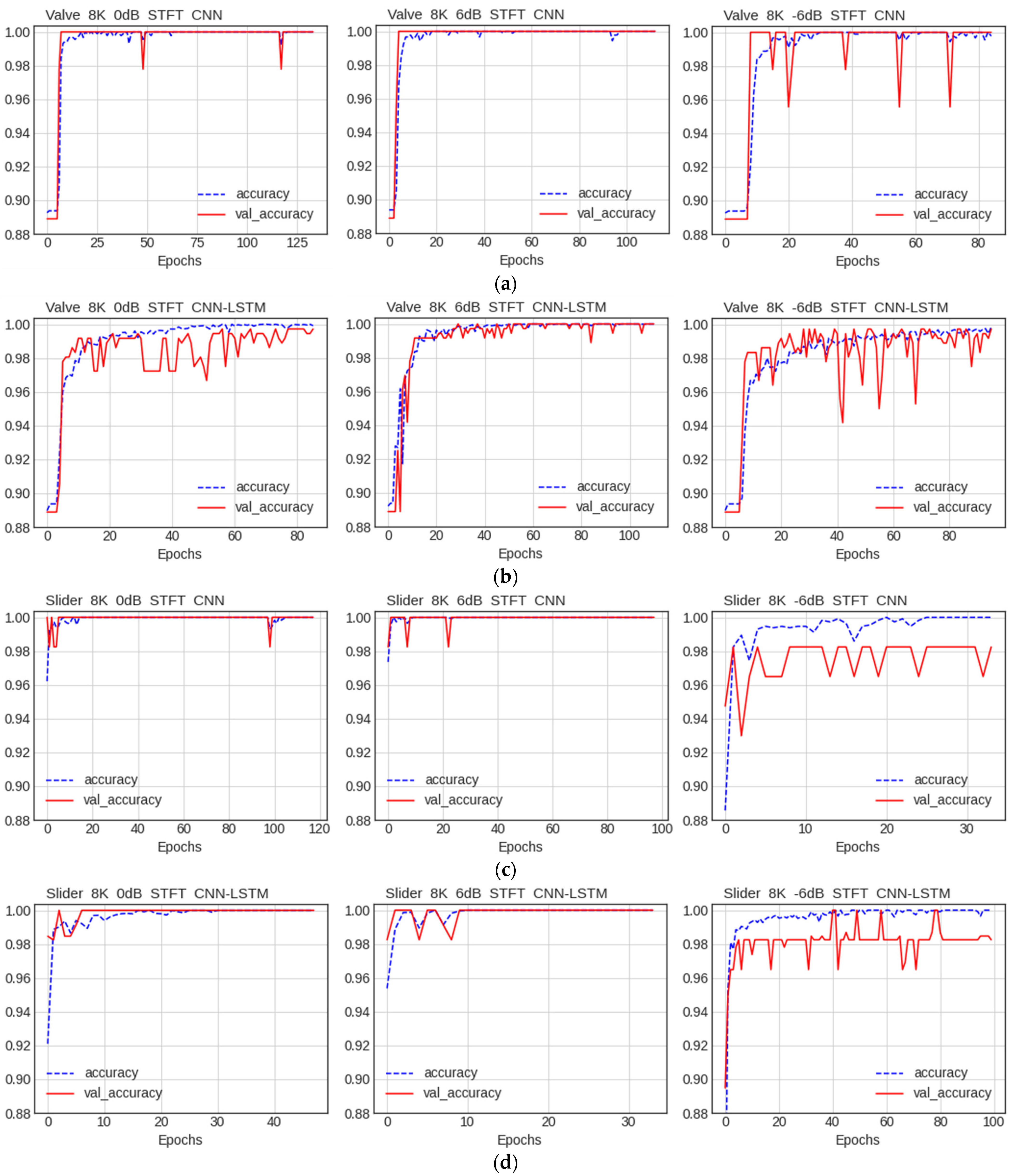
5.2.2. Comparison of Performance by Condition
Comparison of Accuracy among Data Preprocessing Methods
Comparison of Accuracy by Data Quality
Comparison of Accuracy by Noise
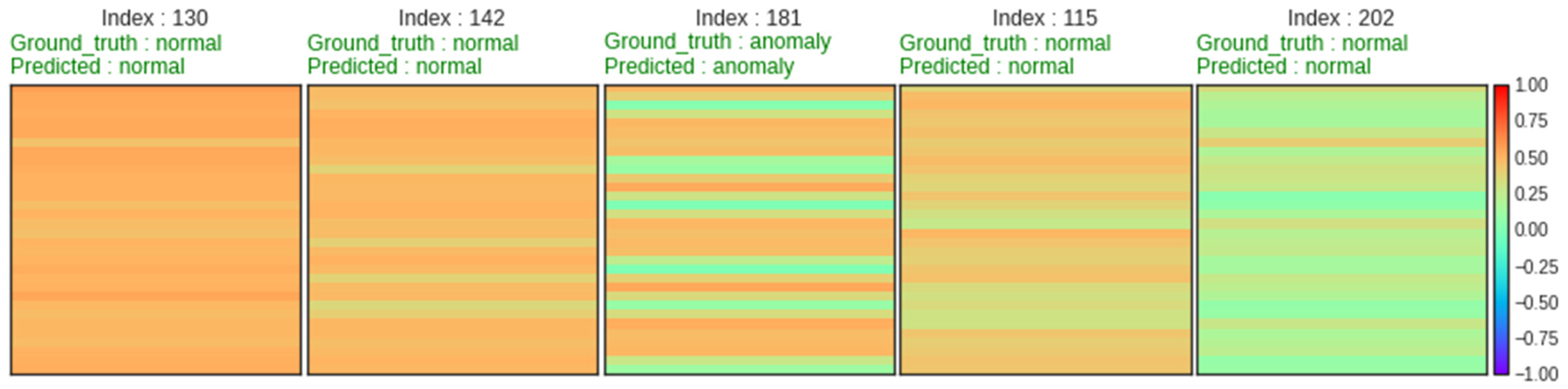
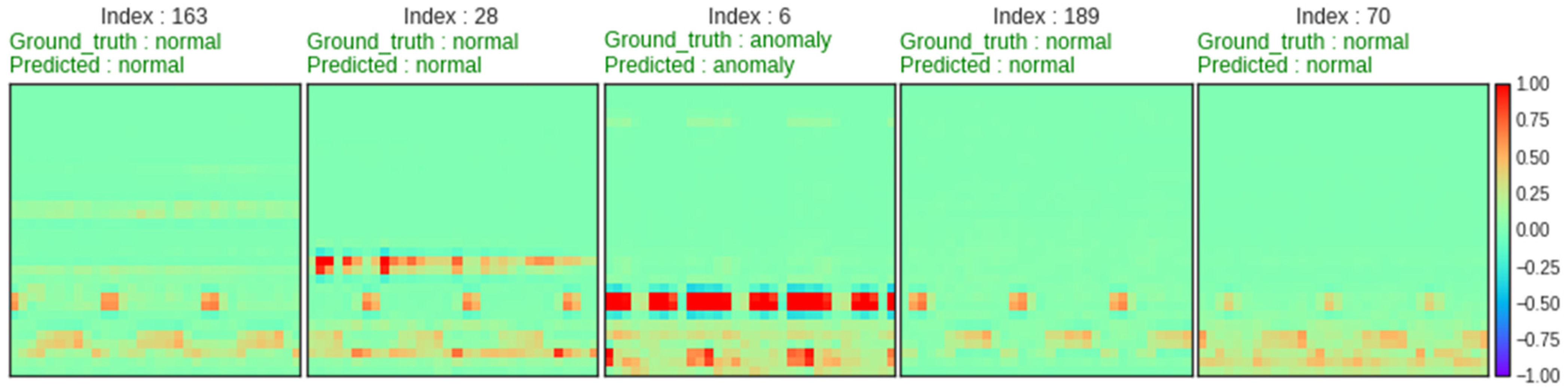
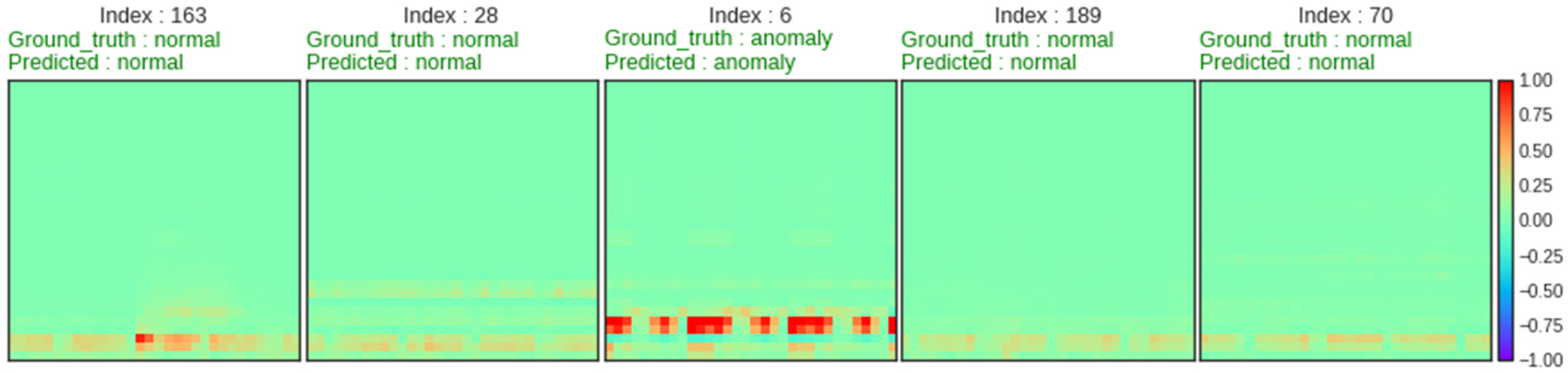
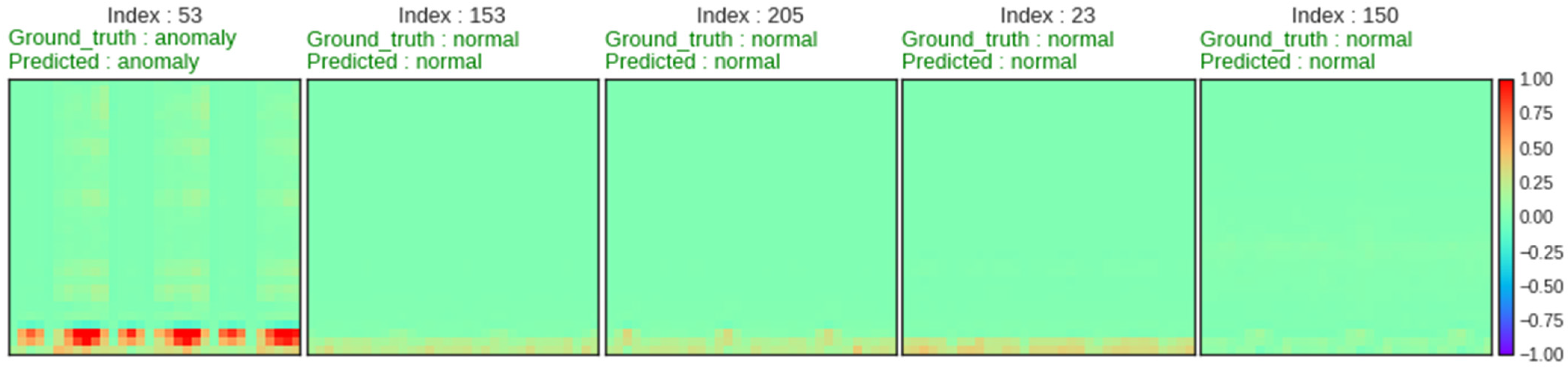
5.3. Model Evaluation
6. Discussion and Comparison with Similar Works
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Çınar, Z.M.; Nuhu, A.A.; Zeeshan, Q.; Korhan, O.; Asmael, M.; Safaei, B. Machine learning in predictive maintenance towardssustainable smart manufacturing in industry 4.0. Sustainability 2020, 12, 8211. [Google Scholar] [CrossRef]
- Tanuska, P.; Spendla, L.; Kebisek, M.; Duris, R.; Stremy, M. Smart anomaly detection and prediction for assembly processmaintenance in compliance with industry 4.0. Sensors 2021, 21, 2376. [Google Scholar] [CrossRef]
- He, W.; Chen, B.; Zeng, N.; Zi, Y. Sparsity-based signal extraction using dual Q-factors for gearbox fault detection. ISA Trans. 2018, 79, 147–160. [Google Scholar] [CrossRef] [PubMed]
- Wei, Y.; Li, Y.; Xu, M.; Huang, W. A review of early fault diagnosis approaches and their applications in rotating machinery. Entropy 2019, 21, 409. [Google Scholar] [CrossRef] [PubMed]
- Saufi, S.R.; Ahmad, Z.A.B.; Leong, M.S.; Lim, M.H. Challenges and opportunities of deep Learning models for machinery faultdetection and diagnosis: A Review. IEEE Access 2019, 7, 122644. [Google Scholar] [CrossRef]
- Cao, X.; Wang, Y.; Chen, B.; Zeng, N. Domain-adaptive intelligence for fault diagnosis based on deep transfer learning from scientific test rigs to industrial applications. Neural Comput. Appl. 2021, 33, 4483–4499. [Google Scholar] [CrossRef]
- Purohit, H.; Tanabe, R.; Ichige, K.; Endo, T.; Nikaido, Y.; Suefusa, K.; Kawaguchi, Y. MIMII Dataset: Sound dataset for malfunctioning industrial machine investigation and inspection. arXiv 2019, arXiv:1909.09347. [Google Scholar]
- Hong, G.; Suh, D. Supervised-learning-based intelligent fault diagnosis for mechanical equipment. IEEE Access 2021, 9, 116147–116162. [Google Scholar] [CrossRef]
- Tama, B.A.; Vania, M.; Kim, I.; Lim, S. An efficientnet-based weighted ensemble model for industrial machine malfunction detection using acoustic signals. IEEE Access 2022, 10, 34625–34636. [Google Scholar] [CrossRef]
- Yong, L.Z.; Nugroho, H. Acoustic Anomaly Detection of Mechanical Failure: Time-Distributed CNN-RNN Deep Learning Models. In Control, Instrumentation and Mechatronics: Theory and Practice; Springer: Singapore, 2022; pp. 662–672. [Google Scholar]
- Tagawa, Y.; Maskeliūnas, R.; Damaševičius, R. Acoustic anomaly detection of mechanical failures in noisy real-life factory environments. Electronics 2021, 10, 2329. [Google Scholar] [CrossRef]
- Kim, M.; Ho, M.T.; Kang, H.-G. Self-supervised Complex Network for Machine Sound Anomaly Detection. In Proceedings of the 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; pp. 586–590. [Google Scholar]
- Gu, X.; Li, R.; Kang, M.; Lu, F.; Tang, D.; Peng, J. Unsupervised Adversarial Domain Adaptation Abnormal Sound Detection for Machine Condition Monitoring under Domain Shift Conditions. In Proceedings of the 2021 IEEE 20th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), Banff, AB, Canada, 29–31 October 2021; pp. 139–146. [Google Scholar]
- Thoidis, I.; Giouvanakis, M.; Papanikolaou, G. Semi-supervised machine condition monitoring by learning deep discriminative audio features. Electronics 2021, 10, 2471. [Google Scholar] [CrossRef]
- Hojjati, H.; Armanfard, N. Self-Supervised Acoustic Anomaly Detection Via Contrastive Learning. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 3253–3257. [Google Scholar]
- Gaetan, F.; GabrieL, M.; Olga, F. Canonical polyadic decomposition and deep learning for machine fault detection. arXiv 2021, arXiv:2107.09519. [Google Scholar]
- Zabin, M.; Choi, H.-J.; Uddin, J. Hybrid deep transfer learning architecture for industrial fault diagnosis using Hilbert transform and DCNN–LSTM. J. Supercomput. 2022, pp, 1–20. [Google Scholar] [CrossRef]
- Cabal-Yepez, E.; Garcia-Ramirez, A.G.; Romero-Troncoso, R.J.; Garcia-Perez, A.; Osornio-Rios, R.A. Reconfigurable monitoring system for time-frequency analysis on industrial equipment through STFT and DWT. IEEE Trans. Industr. Inform. 2012, 9, 760–771. [Google Scholar] [CrossRef]
- Tao, H.; Wang, P.; Chen, Y.; Stojanovic, V.; Yang, H. An unsupervised fault diagnosis method for rolling bearing using STFT and generative neural networks. J. Franklin Inst. 2020, 357, 7286–7307. [Google Scholar] [CrossRef]
- Beniteza, D.; Gaydeckia, P.A.; Zaidib, A.; Fitzpatrickb, A.P. The use of the Hilbert transform in ECG signal analysis. Comput. Biol. Med. 2001, 31, 399–406. [Google Scholar] [CrossRef] [PubMed]
- Feldman, M. Hilbert transform in vibration analysis. Mech. Syst. Signal Process. 2011, 25, 735–802. [Google Scholar] [CrossRef]
- Shensa, M.J. The discrete wavelet transform: Wedding the a trous and Mallat algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Normal | Abnormal | Sum |
|---|---|---|---|
| Fan | 1011 | 407 | 1418 |
| Valve | 991 | 119 | 1110 |
| Pump | 1006 | 101 | 1107 |
| Slide rail | 1068 | 356 | 1424 |
| Quality | Model | SNR | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| 16 K | CNN | 0 dB 6 dB −6 dB | 1.0 0.9943 1.0 | 1.0 0.9937 1.0 | 1.0 1.0 1.0 | 1.0 0.9968 1.0 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 1.0 0.9950 0.9992 | 1.0 0.9936 1.0 | 1.0 0.9936 0.9936 | 1.0 0.9936 0.9968 | |
| 8 K | CNN | 0 dB 6 dB −6 dB | 0.9887 1.0 0.9491 | 1.0 1.0 0.9629 | 0.9874 1.0 0.9811 | 0.9936 1.0 0.9719 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 0.9992 1.0 0.9272 | 1.0 1.0 0.9239 | 1.0 1.0 0.9937 | 1.0 1.0 0.9575 | |
| 4 K | CNN | 0 dB 6 dB −6 dB | 0.9887 1.0 0.9039 | 1.0 1.0 0.9277 | 0.9937 1.0 0.9685 | 0.9968 1.0 0.9476 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 0.9936 1.0 0.8997 | 1.0 1.0 0.8983 | 0.9937 1.0 1.0 | 0.9968 1.0 0.9464 |
| Quality | Model | SNR | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| 16 K | CNN | 0 dB 6 dB −6 dB | 1.0 1.0 1.0 | 1.0 1.0 1.0 | 1.0 1.0 1.0 | 1.0 1.0 1.0 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 1.0 0.9983 0.9983 | 1.0 0.9952 0.9952 | 1.0 1.0 1.0 | 1.0 0.9976 0.9976 | |
| 8 K | CNN | 0 dB 6 dB −6 dB | 1.0 1.0 0.9717 | 0.9937 1.0 0.9753 | 1.0 1.0 0.9937 | 0.9968 1.0 0.9844 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 0.9908 0.9992 0.9632 | 1.0 1.0 0.9277 | 1.0 0.9936 0.9685 | 1.0 0.9968 0.9476 | |
| 4 K | CNN | 0 dB 6 dB −6 dB | 1.0 1.0 0.9661 | 0.9298 1.0 0.9751 | 1.0 1.0 0.9874 | 0.9636 1.0 0.9812 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 0.9654 0.9985 0.9435 | 1.0 1.0 0.8983 | 1.0 1.0 1.0 | 1.0 1.0 0.9464 |
| Quality | Model | SNR | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| 16 K | CNN | 0 dB 6 dB −6 dB | 0.9912 0.9956 0.9824 | 0.9941 1.0 1.0 | 0.9941 0.9941 0.9766 | 0.9941 0.9970 0.9881 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 0.9923 0.9945 0.9868 | 1.0 1.0 0.9884 | 0.9883 0.9941 1.0 | 0.9941 0.9970 0.9941 | |
| 8 K | CNN | 0 dB 6 dB −6 dB | 0.9868 0.9955 0.9691 | 0.9883 0.9941 0.9657 | 0.9941 1.0 0.9941 | 0.9912 0.9970 0.9797 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 0.9780 0.9906 0.9768 | 0.9883 0.9883 0.9604 | 0.9824 1.0 1.0 | 0.9853 0.9941 0.9798 | |
| 4 K | CNN | 0 dB 6 dB −6 dB | 0.9911 0.9911 0.9647 | 0.9883 0.9941 0.9602 | 1.0 0.9941 0.9941 | 0.9941 0.9941 0.9768 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 0.9895 0.9911 0.9576 | 0.9882 0.9883 0.9491 | 0.9882 1.0 0.9882 | 0.9882 0.9941 0.9682 |
| Quality | Model | SNR | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| 16 K | CNN | 0 dB 6 dB −6 dB | 1.0 1.0 0.9932 | 1.0 1.0 0.9911 | 1.0 1.0 1.0 | 1.0 1.0 0.9955 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 1.0 1.0 0.9932 | 1.0 1.0 0.9911 | 1.0 1.0 1.0 | 1.0 1.0 0.9955 | |
| 8 K | CNN | 0 dB 6 dB −6 dB | 1.0 1.0 0.9823 | 1.0 1.0 0.9940 | 1.0 1.0 0.9823 | 1.0 1.0 0.9881 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 1.0 1.0 0.9911 | 1.0 1.0 0.9941 | 1.0 1.0 0.9941 | 1.0 1.0 0.9941 | |
| 4 K | CNN | 0 dB 6 dB −6 dB | 1.0 1.0 0.9955 | 1.0 1.0 1.0 | 1.0 1.0 0.9941 | 1.0 1.0 0.9970 |
| CNN–LSTM | 0 dB 6 dB −6 dB | 1.0 1.0 0.9955 | 1.0 1.0 1.0 | 1.0 1.0 0.9941 | 1.0 1.0 0.9970 |
| Model | WMV [9] | CNN (Ours) | SCRLSTM [8] | CNN–LSTM (Ours) |
|---|---|---|---|---|
| Feature Extraction | MFCC | DWT, Hilbert, STFT | Mel-spectrogram | DWT, Hilbert, STFT |
| Architecture | EfficientNet-B0 (4 millions) EfficientNet-B5 (28.5 millions) EfficientNet-B7 (64 millions) | Conv2D (32, 32, 32) Conv2D (32, 32, 64) MaxPooling2D (16, 16, 64) Dropout (16, 16, 64) Flatten (16,384) Dense (256) Dropout (256) Dense (1) | Conv2D (360, 144, 10) MaxPooling2D (180, 72, 10) Conv1D (180, 72, 54) TimeDistributed (180, 3888) LSTM (180, 54) LSTM (180, 54) LSTM (180, 108) LSTM (180, 108) LSTM (108, 2) | Conv2D (32, 32, 32) Conv2D (32, 32, 64) MaxPooling2D (16, 16, 64) Dropout (16, 16, 64) Conv2D (16, 16, 64) MaxPooling2D (8, 8, 64) Dropout (8, 8, 64) Conv2D (8, 8, 64) TimeDistributed (8, 512) LSTM (8, 64) LSTM (8, 64) Dense (8, 64) Dropout (8, 64) Dense (8, 1) |
| Number of Parameters | 96,500,000~ | 4,213,633 | 1,045,330 | 277,633 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, J.; Lee, S. Robust and Lightweight Deep Learning Model for Industrial Fault Diagnosis in Low-Quality and Noisy Data. Electronics 2023, 12, 409. https://doi.org/10.3390/electronics12020409
Shin J, Lee S. Robust and Lightweight Deep Learning Model for Industrial Fault Diagnosis in Low-Quality and Noisy Data. Electronics. 2023; 12(2):409. https://doi.org/10.3390/electronics12020409
Chicago/Turabian StyleShin, Jaegwang, and Suan Lee. 2023. "Robust and Lightweight Deep Learning Model for Industrial Fault Diagnosis in Low-Quality and Noisy Data" Electronics 12, no. 2: 409. https://doi.org/10.3390/electronics12020409
APA StyleShin, J., & Lee, S. (2023). Robust and Lightweight Deep Learning Model for Industrial Fault Diagnosis in Low-Quality and Noisy Data. Electronics, 12(2), 409. https://doi.org/10.3390/electronics12020409