1. Introduction
Visible Light Communications (VLC) represents a novel technology [
1,
2] where a data channel is established by means of visible light. The information is modulated over the light by quick radiation modulations that do affect the mean intensity and are undetectable by the human eye. The recent ubiquitous substitution of incandescent and fluorescent lamps with the more efficient Light Emitting Diode (LED) lamps, which are inherently compatible with VLC [
3], represents another push in the direction of the adoption of this new technology.
The fields of use and the new possibilities that this technology opens are very wide. For example, VLC can sustain or substitute the Wi-Fi or Bluetooth standards in homes and offices by exploiting the same lamps that are used for the ambient lighting. This approach not only implements more efficient energy consumption (the same energy source is exploited for both lighting and communication) but also frees frequencies from the overcrowded electromagnetic spectrum and helps to relax the frequency congestion [
4]. The applications that can benefit the several advantages of the VLC technology are numerous and typically divided into indoor [
5] and outdoor [
6]. They include, for example, biomedical data communication in air [
7] or even through the skin [
8], objects and people localization [
9], museal [
10], data networks in harsh environments [
11], vehicular communications [
12], and many others.
Most of the applications presented in recent literature employ the On-Off Keying (OOK) modulation [
13] for coding the informative bits in the light. This is a simple approach where the light is rapidly switched on/off, and it is implemented with basic electronics. In spite of its simplicity, this approach has been shown to be capable of supporting a bandwidth of hundreds of Mb/s over a short distance [
14]. However, higher rates can be attained only through more complex modulation schemes. For example, Orthogonal Frequency Division Multiplexing (OFDM) modulation, or wavelength division multiplexing (WDM), applied to a RGB LED allowed bandwidth well beyond the Gb/s [
15,
16]. Other experiments focus on achieving high communication distance, though with lower bandwidth: for example, a 50 m link is reported in [
17] at 19.2 kb/s rate.
In general, bandwidth performance is limited by the Signal-to-Noise Ratio (SNR), which, in turn, depends on distance. An improvement on SNR can be capitalized for a higher bandwidth, a longer distance, or a better trade-off between the two of them. Chirp coding and pulse compression represents a well-known technique for transmitting and recovering the data from noisy signals. Chirp coding has been developed especially in radar and applied for improving its penetration [
18], but it is now exploited in many other fields like, for example, biomedical investigations [
19] or sonar [
20].
At the best of our knowledge, the advantages that this method can provide to VLC applications are still to be investigated. A possible reason can be that real-time chirp coding and pulse compression is quite demanding for the calculation effort it requires. For example, a 10 µs chirp sampled at 10 Msps is compressed through a 100-tap correlator that needs 1000 M of operation per s (MOPs). Fortunately, Field Programmable Gate Arrays (FPGAs), thanks to the hundreds of Digital Signal Processors (DSPs) they are equipped with, support easily such a heavy calculation load [
21]. Thus, they represent a likely choice for the implementation of real-time chirp-modulated VLC applications.
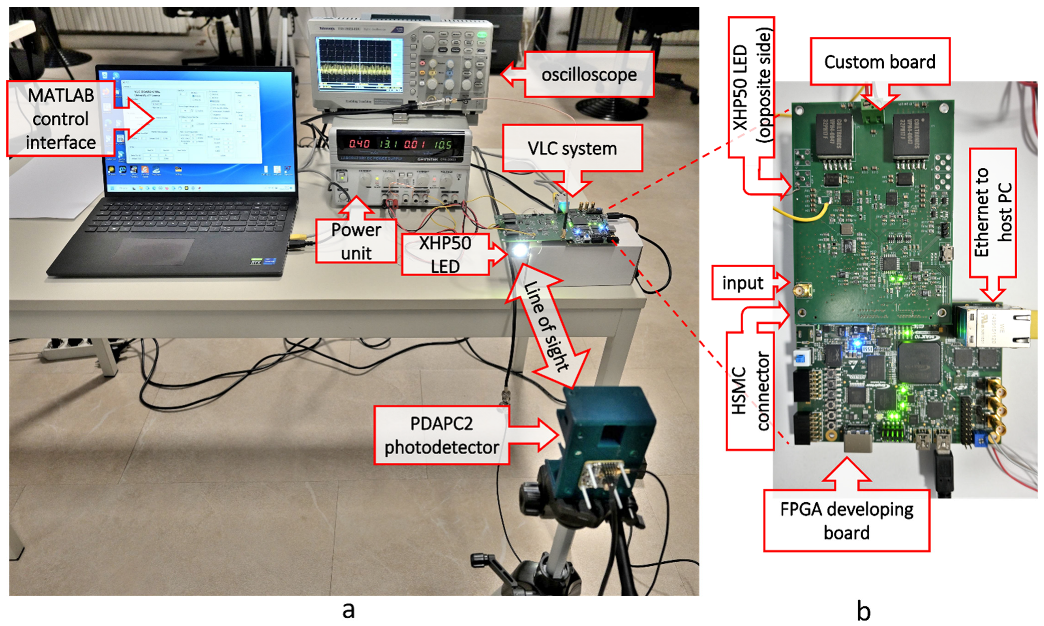
In this paper we present an ultra-low latency VLC link realized in real-time in FPGA through chirp coding in transmission (TX) and pulse compression in reception (RX). The data were subdivided in 24-bit packets, chirp-modulated in the FPGA, analog-converted, and transmitted through a phosphorous white LED (5000 K) [
3] powered with 1 A mean current. In reception, the signal received from a photodetector was amplified, digital-converted, and, in the FPGA, compressed and reconverted in packets of bits. In the experiments, 3 different chirps (1.7 MHz bandwidth and lengths of 4.48, 8.96, 17.92 µs, respectively) are tested. The gain in communication distance attainable by chirps with higher temporal durations are measured and compared to a theoretical model. For example, a 1.56 Mb/s link over a 2.12 m distance was demonstrated by employing the 4.48 µs chirp. The communication distance raised to 3.20 m for the 17.92 µs chirp. The latency, i.e., the time needed to the data packet from the input of the transmitter to the output of the receiver, was always below 40 us.
The paper proceeds with
Section 2, where the basics principles of the pulse compression are summarized;
Section 3 describes the employed communication protocol;
Section 4 reports about the implementations in FPGA of the chirp coder, the compressor, and the packet reconstruction;
Section 5 describes the experimental set-up;
Section 6 reports the measurements; finally,
Section 7 discusses the results, and
Section 8 closes the work.
3. Communication Protocol
3.1. Trasmission Modulation
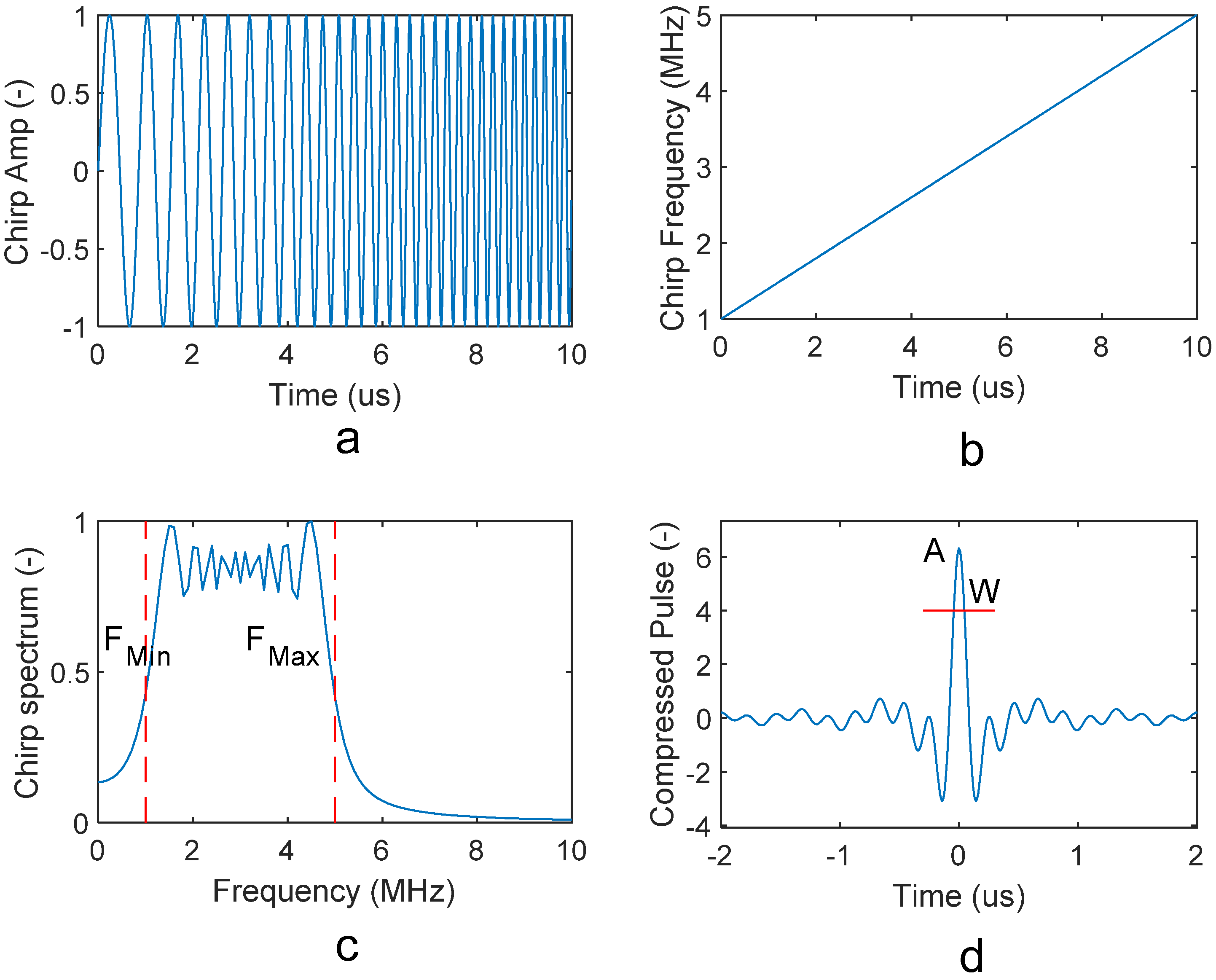
In the protocol proposed in this work, the data are represented by a continuous bitstream (0, 1 values) that feeds the modulator. The modulator applies the chirp coding as described below. Data are modulated by a linear chirp (1) selected among 3 different choices. These chirps feature the same frequency content but different temporal durations. The bandwidth
B = 1.7 MHz (
= 100 kHz,
= 1.8 MHz), common to the 3 of them, is selected to fit the features of the LED employed in the transmitter, like it will be clarified in
Section 5.2, and grants a temporal resolution of W = 1/
B = 588 ns. The durations of the chirps differ and are set to
= 4.48, 8.96 and 17.92 µs, respectively. The corresponding
BT was 6.8, 13.6, 27.2.
The modulator is implemented in a digital processor, where the signals are sampled at rate
= 80 ns (
). The 3 chirps are thus composed by
= 56, 112, 224 samples, respectively.
Table 1 summarizes the chirps features.
In this protocol we transmitted the chirp for every ‘1’ bit of the bitstream, whereas for ‘0′ bit the chirp was not transmitted. We transmitted a new bit every 8
, i.e., every 640 ns. This time fits with the system resolution of W = 1/B = 588 ns. Since a new chirp is potentially transmitted every 8
, the transmission signal is composed by the summation of more chirps overlapped with different phases. When a sequence of all ‘1’ is transmitted, the maximum number of chirps must be summed up for every time instant; this maximum is:
The maximum corresponds to
= 7, 14, 28 for the 3 chirps of
Table 1, respectively.
The transmission signal can be formally represented by:
Here
is the periodic extension of
with period
;
is the bit at position ‘x’ in the bitstream and has value ‘0’ or ‘1’;
is the sample index; and
represents the integer part of
.
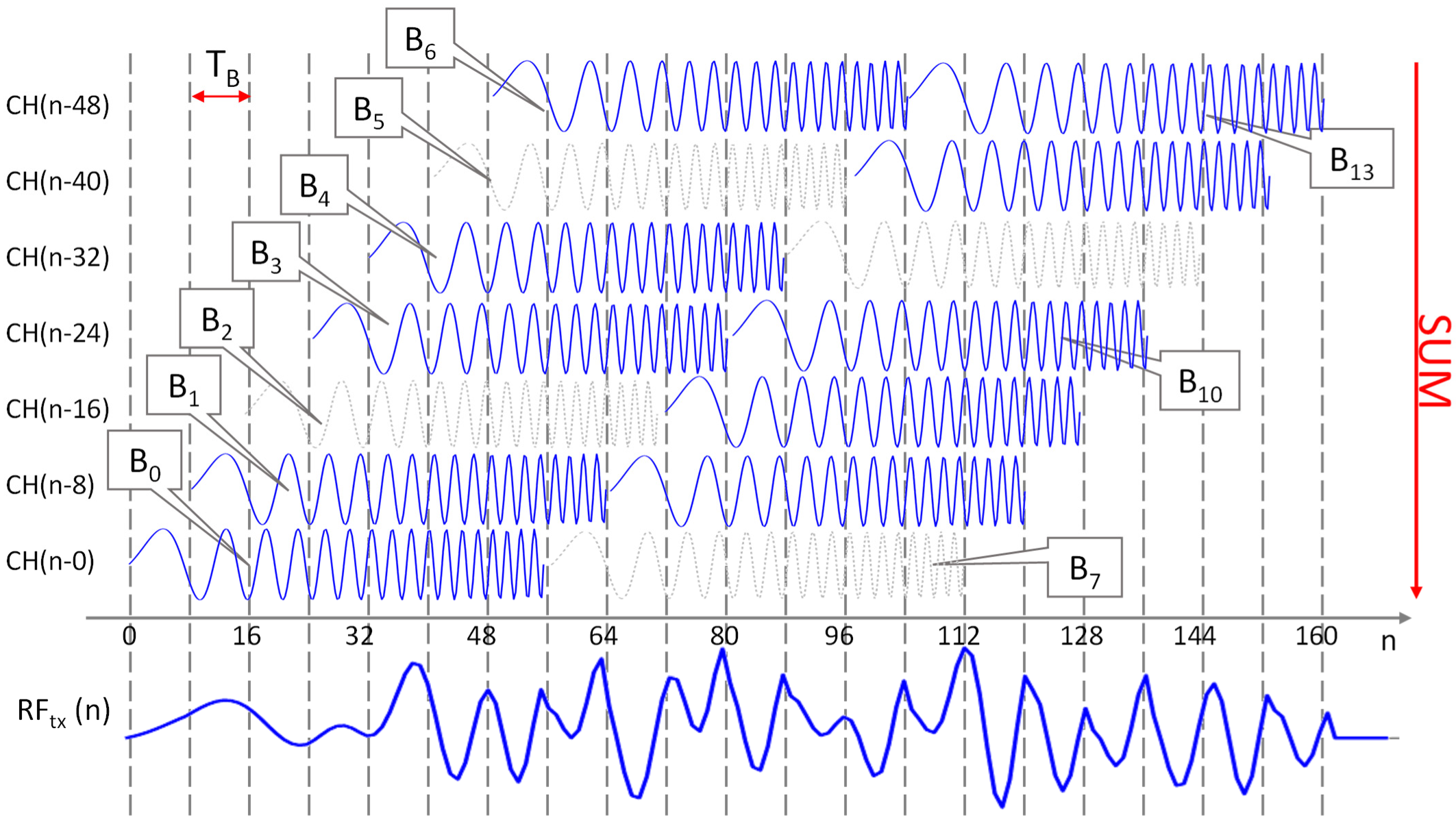
Figure 2 reports an example generated in MATLAB that clarifies the modulation scheme for the chirp with
4.48 µ.
The horizontal axis represents index sample n; the distance among the grid vertical lines is of = 8 samples. In the upper part, the seven rows report as many chirp signals delayed of one with respect to the previous. The chirps repeat periodically every = 7= 56 samples. In the example, the arbitrary bitstream “11011101011011” is transmitted with LSB first, and every chirp is labelled with the associated bit (Bit 0-13 in the figure). Chirps corresponding to ‘0’ and ‘1’ bits are represented in gray and blue colors, respectively. The transmission signal (n), shown in the bottom part of the figure, is obtained by summing the seven signals at the same temporal index. Each signal is a chirp if the bit is ‘1’ or a null signal if the bit is ‘0’.
The signal, calculated by (7), is converted to current and amplified. This is a 0-mean signal that cannot directly feed the LED. This signal is added to a constant current, that represents the mean LED luminosity. The resulting current, which is always positive, is applied to the transmission LED.
3.2. Format of the Data Packet
The data to be transmitted is organized in 24-bit packets with the simple format sketched in
Figure 3. Data to be transmitted (the payload) is subdivided in words of 16-bit each (i.e., 2-byte). A fixed preamble of 4-bit “1111” is added before the payload. It will help the receiver to synchronize to the packets’ boundaries. Finally, a 4-bit Check Redundancy Code (CRC) is appended at the end of each packet, so that the receiver can check the data integrity. In
Figure 3, the packet is represented with bits P
23-0, the payload is W
15-0, and the CRC has bits C
3-0.The CRC is calculated by subdividing the preamble and payload in 5 sub-words of 4-bit each, that are added. Carry to the 5th bit is discarded in the process:
The 24-bit packets are queued one after the other, with no delay in between. The sequence produces a bitstream that is coded with the chirps, like described above.
3.3. Reception Decoding
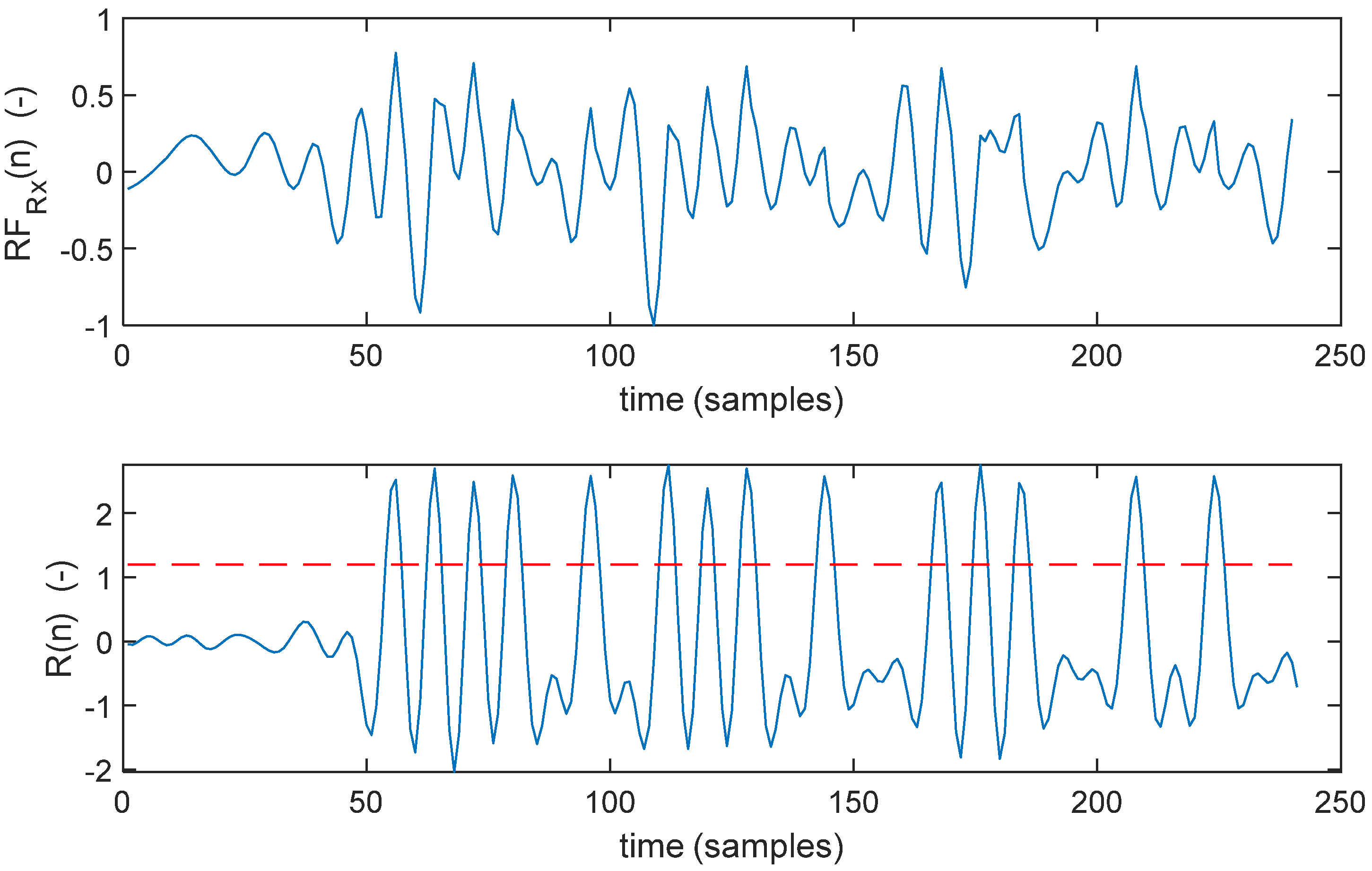
The signal received,
is band-pass filtered, amplified, and digitally converted at rate
. Then, it is correlated with the original chirp signal (2) according to the pulse compression technique. The resulting compressed signal
presents a ‘peak’ for every ‘1’ bit of the original bitstream and no peak for every ‘0’ bit. A simple amplitude threshold can be used to recover the bitstream.
Figure 4 shows, for example, the received and the compressed signals for the arbitrary bit sequence “111101011101001110010100” that corresponds to the 24-bit data packet with the 16-bit payload “0101110100111001”. The bitstream is recovered with a threshold at half-amplitude.
For every new bit that is decoded, the last 24-bit are considered a prospective packet. The preamble and the CRC are checked. If the result is negative, the process repeats with the next bit. If it is positive, the payload is extracted, and the process jumps to the next 24 bits. More details are given in the FPGA implementation.
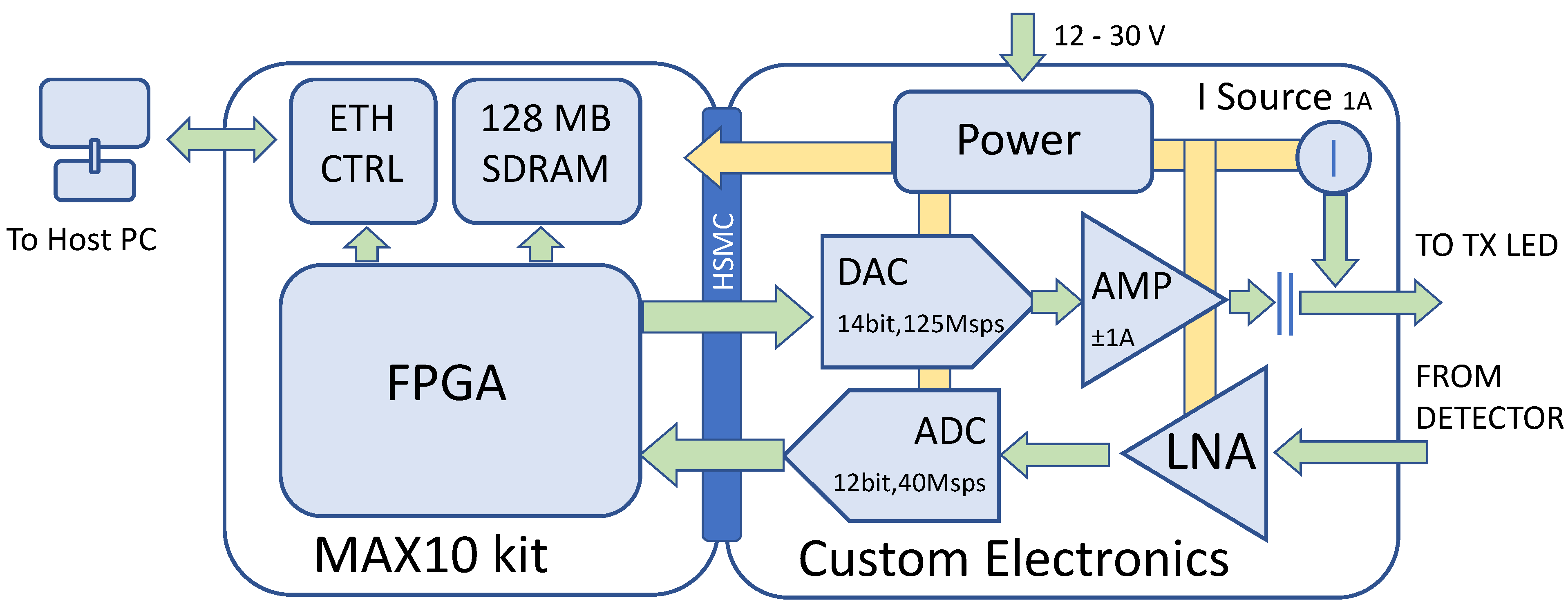
4. FPGA Implementation
The FPGA code was developed in very high-speed integrated circuits Hardware Description Language (VHDL) in Quartus Prime 20.1 (Intel Corp, Santa Clara, CA, USA). The code includes the transmitter and the receiver, detailed in the following sections.
4.1. The Transmitter
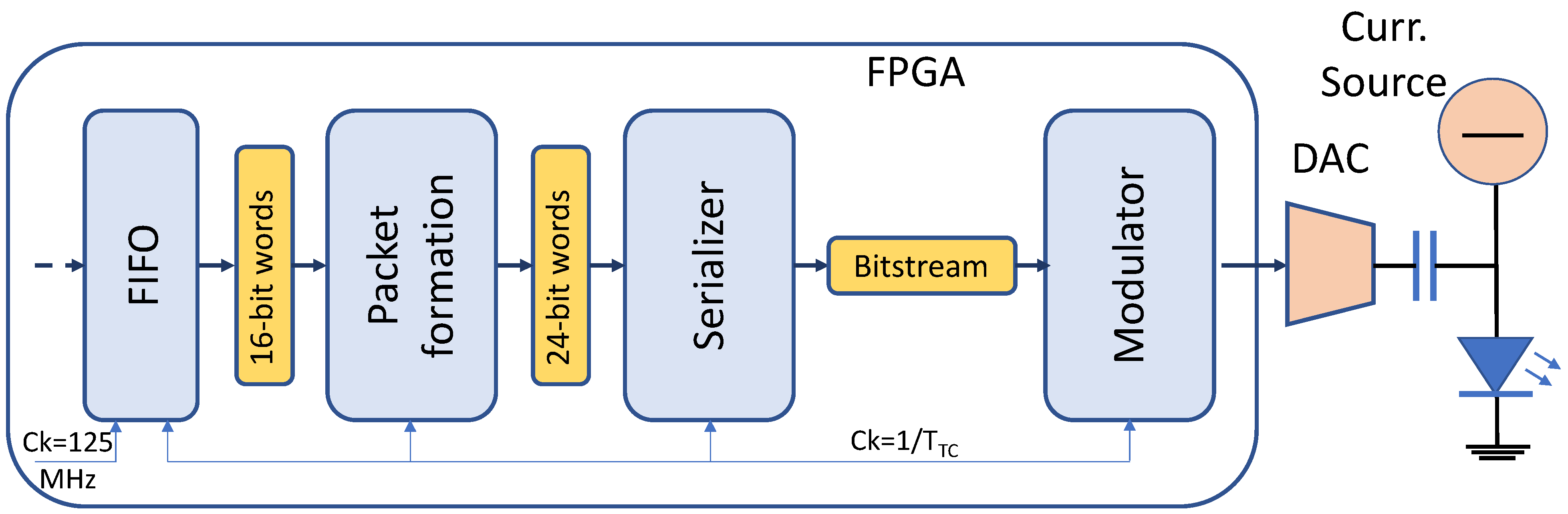
The architecture of the transmitter is sketched in
Figure 5. It is composed by several processing blocks connected through an Avalon
® streaming bus [
26]. Data, moved by the bus, cross all the blocks serially. The data flow is regulated through the backpressure technique implemented in the Avalon
® bus: each block, when it is not ready to sink data, rises a ‘busy flag’ that stalls the data flow from the previous block. On the other hand, the processing chain is designed so that each block grants the availability of data as soon as the successive block is ready to accept them. This way, the rate of the data flow along the chain is imposed by the last block, which is the “Modulator”. This architecture grants a constant and uninterrupted data flow at sample rate towards the Digital-to-Analog Converter (DAC) and the LED.
Data words to be transmitted are buffered in a First-In-First-Out (FIFO) memory. The FIFO separates the clock domains of the FPGA core that operates at 125 MHz from the transmitter domain that operates at the lower frequency of . The 16-bit payload is moved from the FIFO to the next block that formats the 24-bit packet. This block calculates the CRC and builds the packet by adding the CRC and the preamble. The 16-bit input words and 24-bit output words flow at the rate of one word for every 24 bits transmitted, i.e., = . Thus, the block has three clock cycles to process each word. This is a simple block, and no further details are here provided.
The next block is the Serializer, which sinks the 24-bit word in parallel and outputs it serially, providing the bitstream for the modulator. The output rate is . Similarly to the previous block, no further details are necessary for this simple step.
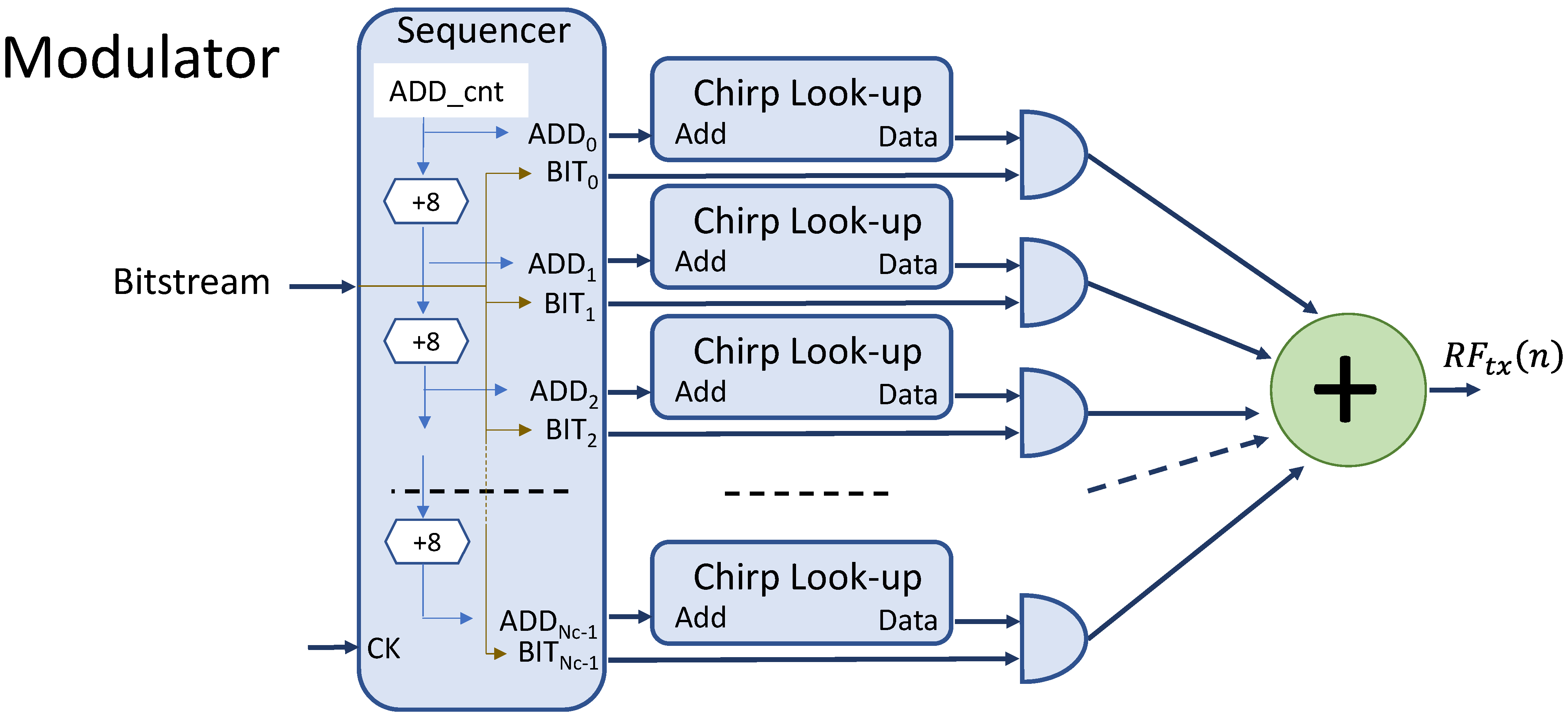
The modulator is by far the most complex part of the transmitter and deserves more attention. Its internal architecture is detailed in
Figure 6.
The modulator is fed by the bitstream prepared by the previous blocks and produces in outputs the samples of the signal that, once converted in current, are transferred to the LED. It works with the clock CK at rate , and thus every 8 CK cycles it accepts in input and processes a new bit. On the other hand, every CK cycle a new sample of is produced in output.
Although the architecture of the modulator is the same, its complexity scales with the chirp length. In fact, the number, Nc, of chirps to be added for each output sample rises with the chirp length, like stated by (6). The modulator should basically add the Nc chirps, suitably phased and masked by the corresponding data bit. This task is achieved by employing Nc identical look-up tables that store: the samples of the chirp; Nc ‘AND’ gates used for zeroing the corresponding look-up output; a Nc-input adder; and a sequencer block that generates the look-up addresses, the gates masking inputs, and the circuit timing.
The sequencer generates the addresses to the chirp look-up tables through the counter ADD_cnt followed by a chain of adders. The n-th address in the chain, ADDn (0 ≤ n ≤ Nc-1), is obtained by summing the value 8·n, so that the chirp n is delayed by 8 samples with respect to the chirp n-1. The sums are modulo , where is the number of chirp samples. Every CK cycle, the ADD_cnt is incremented. When the ADDn output is pushed back to 0 (because it reached ), the corresponding bit BITn is loaded with the next bit in the input bitstream. This bit feeds an input of the AND gate, so if the bit is zero, the chirp samples are zeroed; otherwise, the samples reach the adder unaffected. Finally, the adder performs the summation of the Nc chirps and produces the output sample. The adder is implemented in four pipelined stages to facilitate the FPGA time closure at the desired clock frequency.
The following pseudo-code clarifies how the sequencer calculates its outputs:
| Init: |
| ADD_cnt = 0 |
| Loop: |
| ADD_cnt = ADD_cnt + 1 |
| ADD0 = ADD_cnt |
| ADDn = Addn-1 + 8 (1 ≤ n ≤ Nc-1) |
| If ADDn = Ns (0 ≤ n ≤ Nc-1) |
| ADDn = 0 |
| BITn = Next BIT |
| End if |
| Wait next CK rising edge |
| End Loop |
4.2. The Receiver
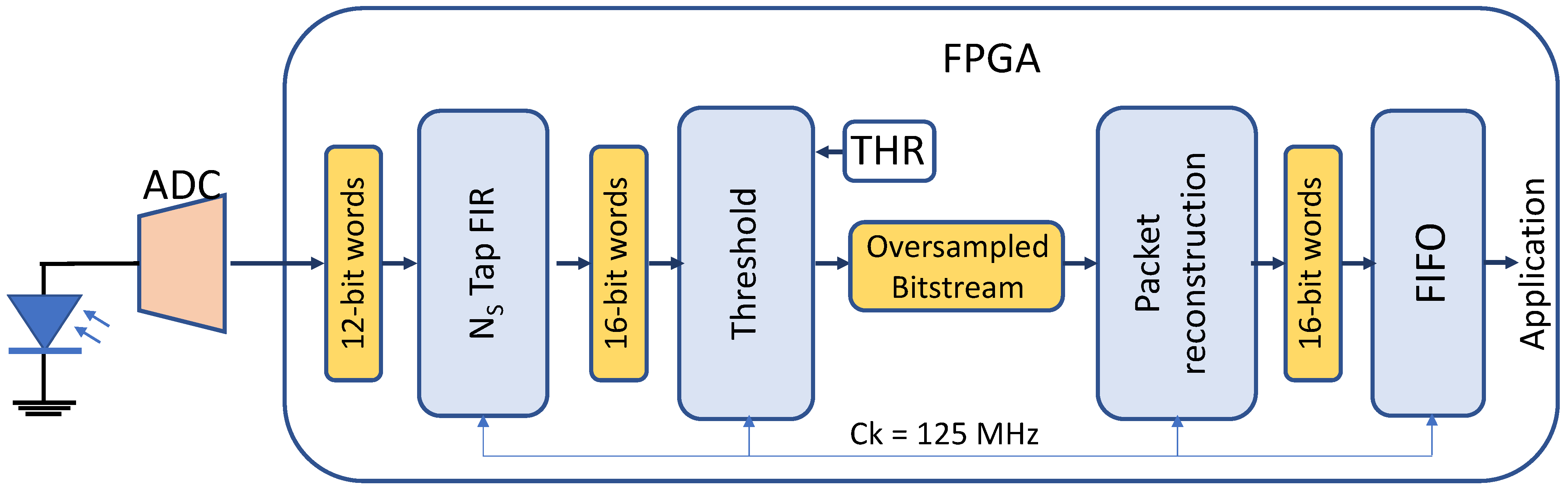
The architecture of the receiver is sketched in
Figure 7.
The signal received by the photodetector is amplified and converted to digital at the rate
and 12-bit resolution. The samples are then moved in the FPGA. Here, they enter the compressor filter that is realized through a Finite Impulse Response (FIR) filter at
taps, whose coefficients
are obtained by mirroring in time the chirp samples:
This approach is particularly beneficial for the FPGA implementation, since the FIR architecture is already available as Intellectual Property (IP) in the most diffuse integrated development environments for FPGA. In this case, we implemented the FIR through the FIRII core IP [
27] of Intel/Altera. The coefficients are expressed with a 16-bit resolution, and the filter output has a theoretical resolution of 34-bit for the 56-sample chirp up to 36-bit for the 224-sample chirp; however, only the 16 Most Significant Bits (MSBs) are moved to the next processing block.
The next block applies the threshold. It produces a single bit for every input word: 1 if the input value is over the threshold, 0 otherwise. The threshold is programmable, but a value of half-maximum works for most of the cases. Its output is the bitstream theoretically corresponding to the bitstream in input to the modulator integrated in the transmitter (see
Figure 5), but it should be noted that here the bitstream is oversampled by a factor of
.
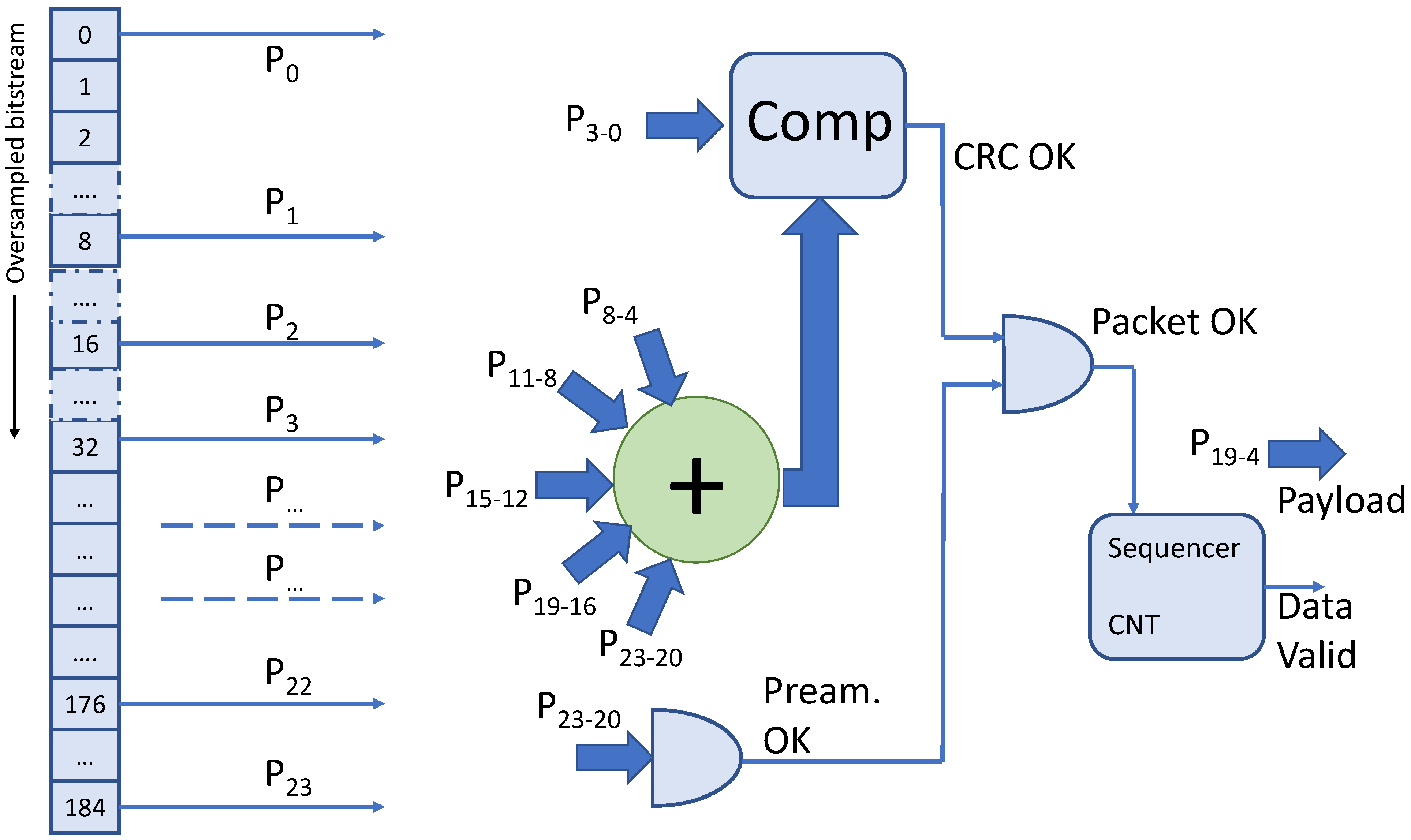
The packet reconstruction block locates the packets in the oversampled bitstream, verifies the checksum, and extracts the payload. Its architecture is detailed in
Figure 8.
The oversampled bitstream flows at rate in a shift-register with 185 flip-flops. From the shift register, the prospective 24-bit packet is extracted in parallel by under-sampling 1 bit every 8 shift positions. For every prospective packet, the preamble is searched in the P23-20 positions with a simple AND gate; the CRC is calculated and compared (COMP) to the sub-word P3-0. If both the aforementioned conditions are true, the sequencer activates the data valid and transfers the payload P19-4 in output. However, since the input bitstream is oversampled, there is the risk that the same packet is detected and outputted up to eight times. For this reason, the sequencer, after a packet is detected, starts a hold-off period where the packet detection is suspended. The packet lasts 24 bits that corresponds to 24 × 8 = 192 ; thus, the hold-off period must last from a minimum of 8 to a maximum of 192 . We used a value of 32.
The reconstructed packets are finally buffered in a FIFO memory, where they are available for the applications.
4.3. Implementation Performance
The transmitter and receiver described above are implemented in the 10M50DA FPGA of the MAX10 family produced by Intel/Altera.
Table 2 reports the resources required by each of the main blocks described in the previous sections for the implementations based on chirps with
= 56, 112 and 224 samples. The FPGA resources are subdivided in logic cells (LCs), 9k-bit memory blocks (M9ks), and Digital Signal Processors (DSPs), which are hardware multipliers in the 18 × 18 configuration. In the transmitter, the packet formation and serializer blocks require just few LCs, whereas the modulator, as expected, is by far more demanding for resources. Each chirp table, implemented in logics, needs from 120 to 220 LCs, depending on the chirp length. Since in the configuration with
= 56, 112, and 224 are implemented 7, 14, 28 tables, respectively, the total LCs required by the look-up tables are 840, 2520, 6160 for the 3 different configurations. The complete modulator requires a bit more LCs than those occupied by the look-ups, namely 1137, 4127, and 8120, respectively. Alternatively, we could have implemented the look-up tables in M9k memory resources. However, this is not an efficient solution, since each table stores at maximum 224 × 14 = 3136 bits, whereas the M9k includes 9216 bits with an apparent waste.
In the receiver, the compressor FIR requires from 438 to 1226 LCs, from 3 to 9 memory blocks and from 6 to 24 DSPs. The memories are needed for the realization of the -tap data shift register of the FIR; the DSPs are configured like 18 × 18 multipliers. The FIR clock is 125 MHz, i.e., 10-fold the data clock that is 12.5 MHz. The filter has 10 clock cycles for each input data, thus with 6 parallel multipliers it can perform up to 60 multiplications, which is sufficient to cover the 56 multiplications needed for 6. Ns = 56. A similar reasoning applies to the other values. The threshold, the sequencer, and the packet reconstruction blocks need few resources. The latter requires a M9k block as well, which implements the shift register.
In summary, the transmitter and receiver require from 2000 to LCs, 4 to 10 memory blocks, and 6 to 24 DSPs, depending on the configuration. The last row of
Table 2 shows how these figures compare to the resources of the 10M50 FPGA.
7. Discussion
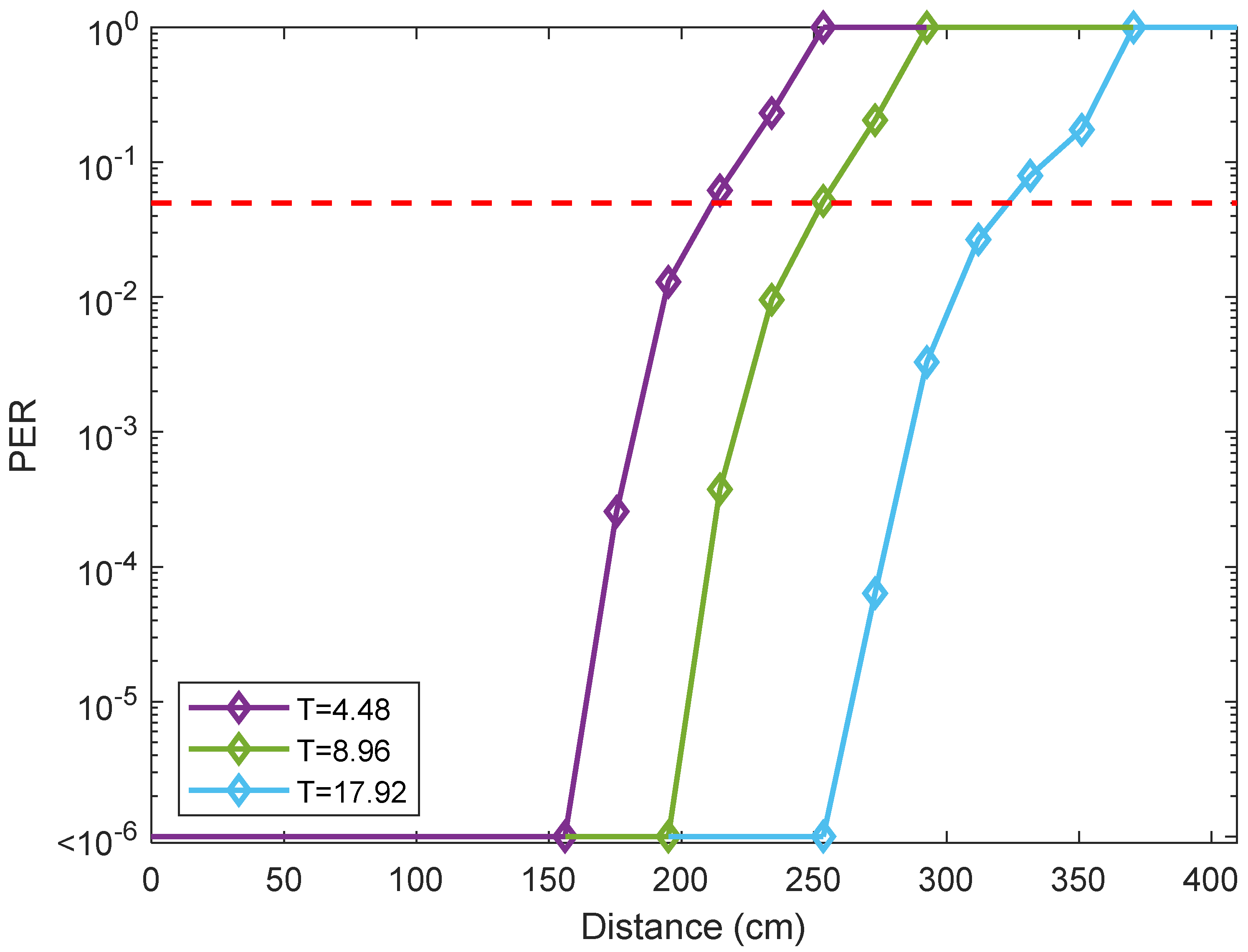
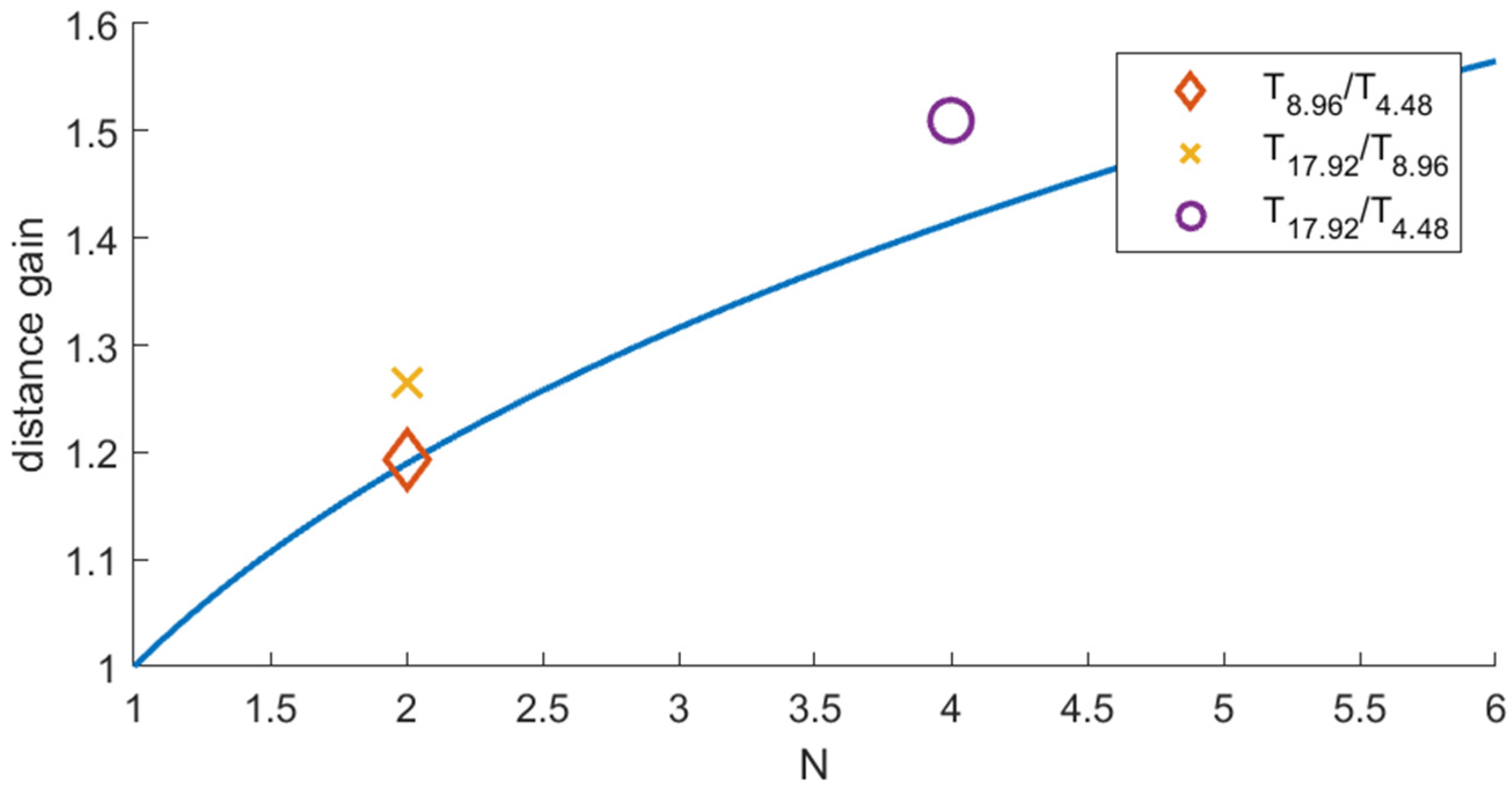
In this paper, the possibility of employing the chirp coding in VLC has been investigated and the performance of different chirp codes has been compared. The experiments confirmed (see
Figure 12) that the gain in communication distance achieved by different chirp temporal durations well fits the theoretical trend, given by (5). These results prove that the advantages of chirp modulation, which made this technique widely employed in other fields like radar and sonar, can be exploited in VLC as well. The SNR gain achievable by chirp modulation and pulse compression is related to the chirp temporal length, not to the chirp amplitude [
22,
23]. Communications at increasing distances can be obtained by employing chirp at increasing lengths, or low-energy links can be obtained by reducing the chirp amplitude and compensating by increasing its length.
However, for chirp modulation to have practical applications, it is necessary to demonstrate the feasibility of its real-time, low-latency implementation. In this work we shown an FPGA real-time implementation with a latency below 40 µs, suitable to satisfy even the most severe requirements of the current and next-future applications, like for example the industrial environment [
11] and motor control loops [
30]. The high calculation requirements of the pulse compressor are satisfied in real-time and ultra-low-latency environments by FPGAs only. However, different approaches are possible. For example, a processor can execute the same calculations with a higher latency and a lower throughput. On the other hand, the availability of the FPGA opens the possibility of applying in real-time, with a small latency cost, correction algorithms like Reed-Solomon [
31], Viterbi [
32], or others that can improve the robustness of the communication.
The aim of the presented experiments was not to stress for the maximum achievable distance or data rate. The communication distance can be further improved, for example, by increasing the optical gain with a lamp deflector and/or a lens at the receiver [
33]. On the other hand, in chirp modulation the bit rate is limited by the compressed pulse resolution W, that, in turn, is constrained by the chirp bandwidth. In these experiments we exploited all of the bandwidth available from the employed LED (about 1.8 MHz). Different LED technologies (e.g., non-phosphorous based) or the use of blue filters allow a higher bandwidth [
34], but this is typically achieved at the detriment of the received power.



















{kind=link}
{kind=link}
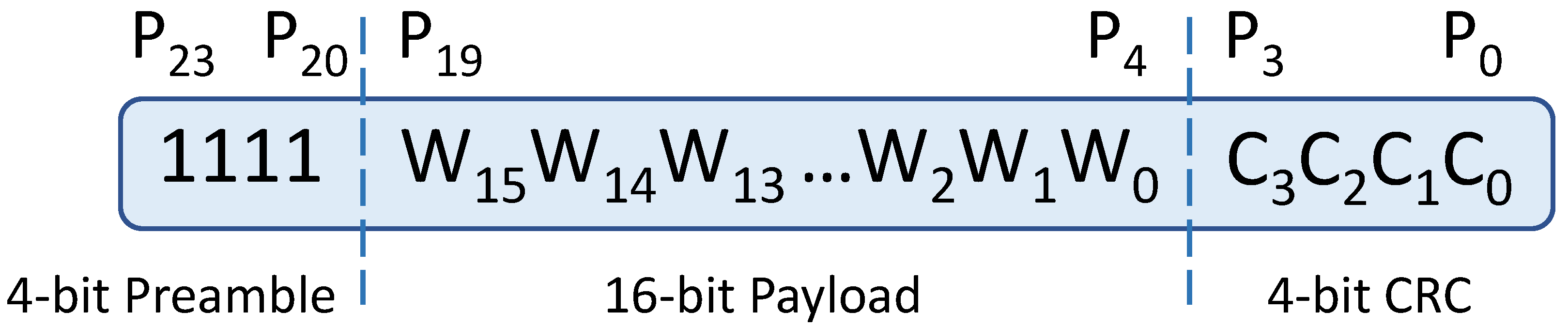{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}