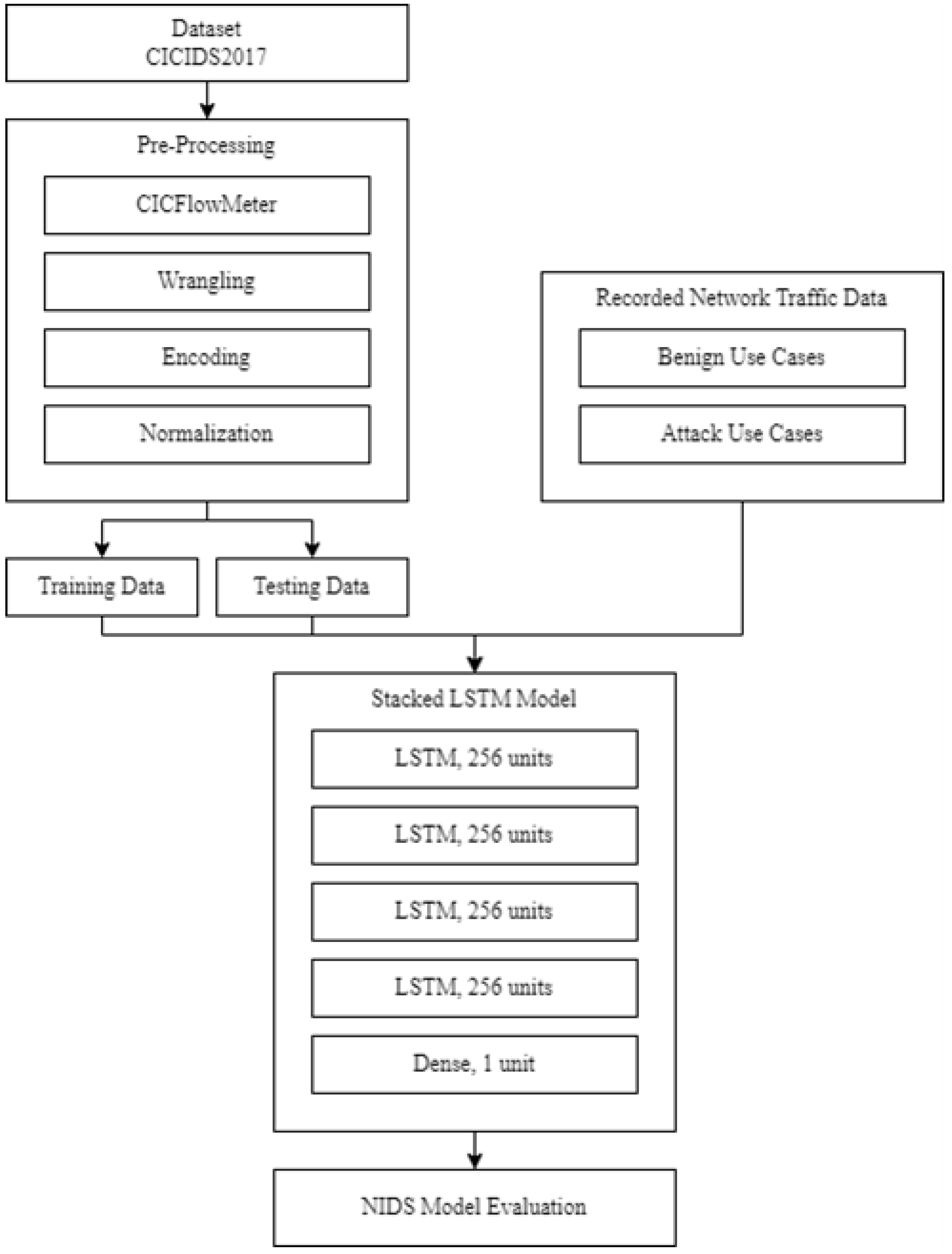
In this section, we present a summary of a review of relevant literature that was performed using the terms: “intrusion detection”, “network intrusion detection”, “anomaly detection”, “deep learning”, and “long short-term memory”.
2.1. Machine Learning, Deep Learning and Intrusion Detection
Since the inception of the first IDS in 1980 by James P. Anderson [
2] for the National Security Agency (NSA), a great deal of research has been used on its evolution to match the current reality in terms of network infrastructures. This first model strictly used signature-based detection and was designed to help system administrators review audit trails. In 1986, Dorothy E. Denning et al. [
3] proposed an evolution of James P. Anderson’s IDS model using both signature-based detection and anomaly-based detection methods. The authors proposed several statistical approaches for anomaly detection, but most implementations used a Markov Chain model. A few years later, in 1992, and with the increasing prominence of malware usage on information systems, Wang et al. [
6] proposed an anomaly-based detection method for IDS using a one-class Support Vector Machine (SVM) in conjunction with a Markov Chain model.
In the following years, most works focused on advancing anomaly-based detection capabilities, but most models still used statistical approaches. In 2009, Chih-Fong Tsai et al. [
9] proposed an IDS model using a hybrid learning model called triangle area nearest neighbours (TANN), which is composed of three stages: (1) extraction of cluster centres with a k-means algorithm, (2) new data formulation by triangle areas, and (3) application of a KNN classifier on the data. Using this model, the authors achieved a 97.0% detection accuracy rate.
Deep learning (DL) is a sub-field of Machine Learning (ML) that models the learning process using multiple layers of neurons forming a heavier artificial neural network (ANN). In fact, the word “deep” refers to the huge number of layers through which the data is transformed, and it was coined by Rina Dechter [
10] in 1986. While several researchers have improved DL over the following years, it was only by 2012 that it started to be implemented to solve various tasks. This happened mostly due to three reasons:
Advances to the algorithms, which enabled them to be used on a broader range of domains;
Increased availability of larger datasets to train the models;
Increased computing power, which enabled improved usage of DL systems. One key development for this was made by NVIDIA’s release of a new graphical processing unit (GPU) in 2009, which was used to increase the speed of DL systems a hundred times [
11].
As the scene was set for further research in how to apply DL to more domains, not long after, we started to see a new variant of anomaly-based detection methods for IDS. One of the first integration of an ANN for anomaly-based NIDS was published in 2008 by Jimmy Shum et al. [
7]. In 2011, Xianjin Fang et al. [
8] integrated an ANN in the popular open-source IDS “Snort”. To achieve this integration, Xianjin Fang et al. developed a custom detection plug-in for the IDS detection engine that, depending on the ANN model classification, could generate an alert file for the system’s administrator. In 2015, Jamal Esmaily et al. [
12] proposed an IDS model working with a hybrid approach, using both a Multilayer Perceptron (MLP) and a Decision Tree (DT) for classification, that achieved 99.7% detection accuracy on the KDD CUP 99 dataset [
13]. It consisted of a two-phase model: in the first phase, the dataset was trained on both MLP and DT models and outputted a binary classification of either “attack” or “normal”, after which the resulting classifications of both models were processed by another MLP network that outputted the final result (again, either “attack” or “normal”).
In a comprehensive study of different ML approaches for intrusion detection, Kunal et al. [
14] surveyed 19 different models by different authors to evaluate which one presented the best outcome. While not being able to identify a correlation between the different aspects of each model and their outcome, the author did document several possible approaches for further work.
Emmanuel Alalade et al. [
15] proposed an IDS for Smart Homes using an artificial immune system and extreme learning hybrid approach (AIS-ELM). The AIS was used for input optimization and pre-processing, and ELM for classification. In the authors’ framework, the resulting action was a notification to an arbitrary email to react locally to an attack.
In 2018, Nikita Lyamin et al. [
16] documented the challenges of using DL for intrusion detection in a VANET, which is a mobile ad hoc network applied to the context of vehicles. Despite acknowledging that existing protocols in vehicle-to-vehicle communications integrated into a DL model are capable of detecting a DoS attack, they concluded that it would be difficult to train such a model because there were not enough available data to train it and, even if there were, most DL methods required annotated datasets about a Denial of Service (DoS) class. On the same note, focusing on a specific kind of network attack, Irfan Sofi et al. [
17] explored the capabilities of four different ML algorithms (Naïve Bayes, DT, MLP and SVM) for the detection and analysis of modern types of Distributed Denial of Service (DDoS) attacks in 2017. The results showed the MLP model achieving the highest accuracy rate of the four tested models, with a 98.9% detection accuracy rate [
17]. The authors found that no public datasets were available for training and testing a model against modern DDoS attacks. Thus, they recorded their own dataset in a controlled environment. While this enabled the training and testing of a model, the volume of records was low: the dataset has approximately 75,000 records, and nearly 67,000 are “normal” records. In comparison, the KDD CUP 99 dataset, still widely used by research for IDS models, has 5,000,000 records.
Still focused on DDoS attack detection, Merlin Dennis et al. [
18] proposed two approaches for detecting these attacks in a software-defined network (SDN). The first was a statistical approach that implemented entropy computation and flow statistical analysis. The second was an ML approach that used a Random Forest classifier for detection. In the end, the first approach obtained a 92% accuracy, and the second achieved 97.7% accuracy. The authors also compared their ML approach against similar ones and accredited their success to using the random forest classifier, with fast computing times and resistance to noisy data, and implementing weighted voting instead of the more standard majority voting. Lingfeng Yang et al. [
19] also proposed an SDN framework capable of identifying and defending the network against DDoS attacks. For this, the authors defined a framework consisting of 3 parts: the traffic collection module, the DDoS attack identification module, and the flow table delivery module. The DDoS attack identification module resorted to an SVM network to identify the attacks, and the model was trained with the KDD CUP 99 dataset, obtaining a 99% accuracy. Abdulsalam Alzahrani et al. [
20], also working on SDN, went in a different direction and proposed an IDS as part of the SDN controller to detect pure intrusions on the network, instead of detecting DDoS attacks. After evaluating and comparing different ML algorithms, the authors concluded that the extra gradient boosting tree technique, XGBoost, was the more accurate one, showing a 95.55% accuracy.
In a different approach, Pablo Rivas et al. [
21] leveraged data from a honeypot network to train two models, an SVM and a CNN, to be able to detect DDoS attacks. The work published by the authors followed the Marist College’s effort to develop, deploy and maintain a HoneyNet—a network of honeypots—called Peitho (named after the Greek god). This network can then attract malicious actors that promptly try to attack it, sometimes even trying to use 0-day vulnerabilities. Peitho’s network data is then fed to an SVM model and a CNN model to compare the different accuracy results. The CNN outperformed the SVM, achieving results of 100% accuracy in identifying DDoS attacks after processing eight network packets and achieving 90% accuracy after just two network packets. Another example of an effective ML model for DDoS detection was proposed by Jian Zhang et al. [
22] with an approach of a gradient decision boosting tree to evaluate and optimize feature selection in a closed loop continuously.
2.2. Advanced Anomaly-Based Intrusion Detection Using Long Short-Term Memory Networks
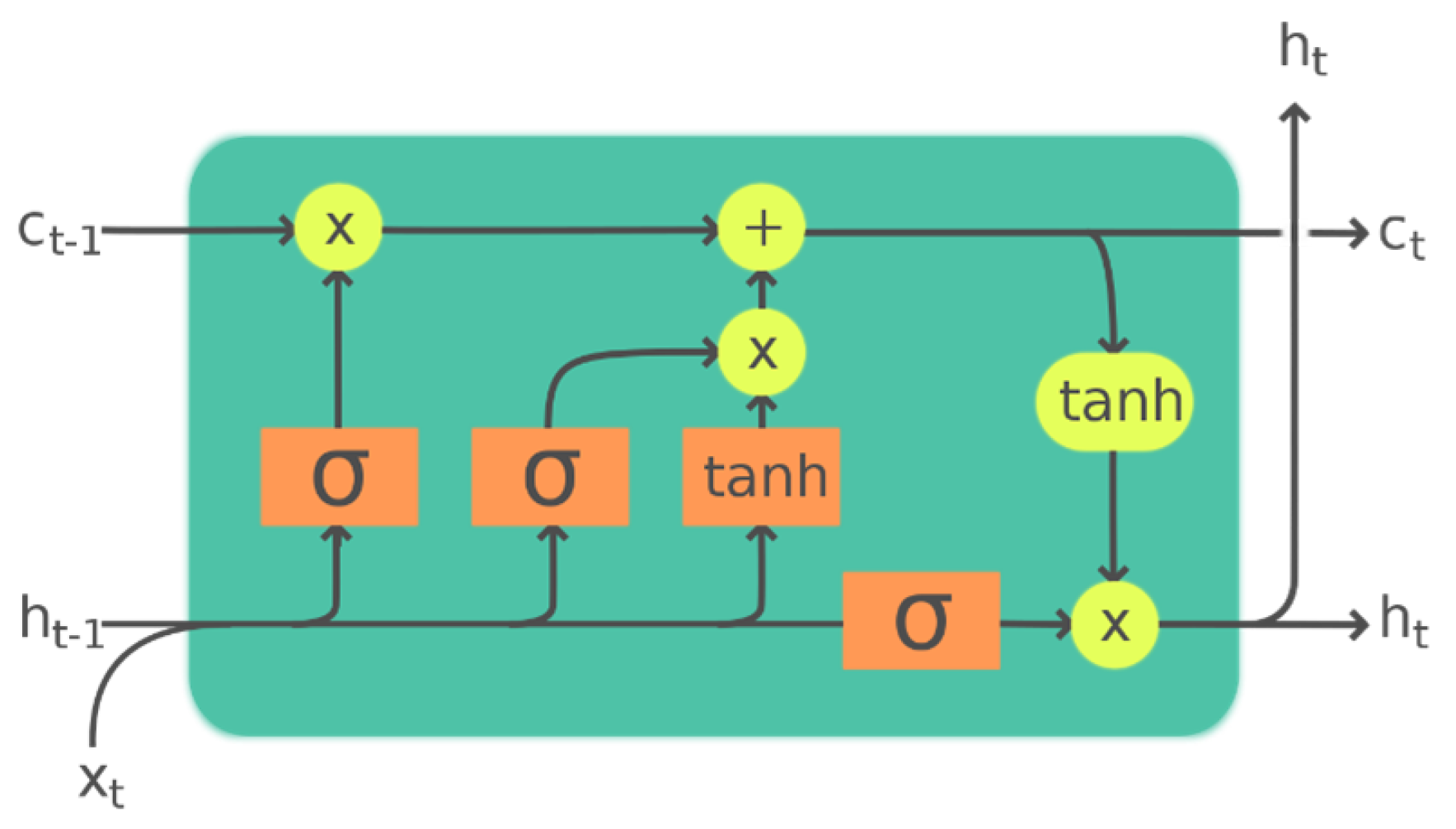
As researchers compared several different ML algorithms for intrusion detection, one model started to stand out: the long short-term memory network (LSTM) model. Proposed in 1995 by Hochreiter et al. as a subset of recursive neural networks (RNN) [
23], the name LSTM refers to the analogy that while a standard RNN has both long-term and short-term memory, the LSTM architecture provides a short-term memory for RNNs that can last several timesteps, thus the name long short-term memory. The authors published the LSTM technique as a proposal to solve the vanishing gradient problem, which happens when training an ANN with gradient-based learning methods and backpropagation [
24]. The neural network’s weights receive an update proportionate to the partial derivative of the error function concerning the current weight during each training iteration. The issue is that the gradient may become increasingly small in some situations, thereby preventing the weight from changing its value. This could prevent the neural network from being further trained in the worst-case scenario. LSTM intends to fight this problem by allowing gradients to flow unchanged while backpropagating. The result is a model that is capable of handling long-term dependencies. LSTMs were a step forward for what we could accomplish with RNNs. Xu et al. [
25] used an LSTM model to create descriptions for images. In 2015, Google [
26] started using LSTM models for its speech recognition services. More famously, OpenAI and DeepMind, two of the most prominent organizations for artificial intelligence research, started implementing LSTM models to beat humans in the video games Dota 2 and Starcraft II, respectively.
Following the ever-bigger trend of using LSTMs in DL problems, researchers started documenting its effects on intrusion detection. To research the trends in ML and DL algorithms applied to intrusion detection, M. Stampar et al. [
27] gathered and measured the number of publications on intrusion and detection, and artificial intelligence/machine learning during the period from 2010 to 2014. They found that the most common models were: ANN, Genetic algorithms, Fuzzy logic, KNN, Naïve Bayes, Decision Tree, Random Forest, SVM and Self-organizing map. The results revealed that the most investigated model was by far the ANN, with close to 1500 publications per year, presenting almost double the publications of the following one, the SVM, which shows close to 800 publications per year. In 2018, Ali Mirza et al. [
28] investigated different kinds of LSTM networks for intrusion detection, such as vanilla LSTM, Bi-LSTM (which is a bidirectional LSTM network) and Deep Auto LSTM (which the authors define as a network with five stacks of LSTMs). Omar Alsyaibani et al. [
29] also proposed a bidirectional LSTM network for intrusion detection. The authors iterated over 24 cycles different training parameters to find the most suitable configuration and trained the model for 100 epochs on the CICIDS2017 dataset, reaching an F1-Score of 97.75%. After 1000 epochs, the model reached a 98.37% F1-Score. Sara Althubiti et al. [
30] experimented with a different dataset, the CIDDS-001, using a single LSTM layer model for intrusion detection and achieved an unusually lower accuracy of 84.83%.
Jorge Meira [
31] compared four different intrusion detection techniques over the two most used datasets at the time: the KDD CUP 99 and the ISCX 2012 IDS. The techniques used were: Isolation forest, the Equal frequency with z-score and autoencoder, Z-score with nearest-neighbour and z-score with K-means. While on the KDD CUP 99 dataset, none of the techniques performed particularly better than the others, in the ISCX 2012 IDS dataset, the Z-score with nearest-neighbour performed significantly better than the competition.
In 2019, Thi-Thu-Huong Le et al. [
32] proposed a novel IDS framework to reduce the high false-positives rates that plagued anomaly-based IDSs. The framework proposed by the authors included a hybrid sequence forward selection algorithm with a decision tree to generate the best feature subset from the original feature set. Those features were used to train several models of RNNs, such as a traditional RNN, an LSTM and a GRU. The models were trained with the NSL-KDD 2010 IDS dataset and the ISCX 2012 IDS dataset. In the end, the RNN model showing the best performance was the LSTM, achieving an accuracy of 92% in the NSL-KDD dataset and 97.5% in the ISCX dataset.
One of the biggest challenges of a NIDS is processing the sheer dimension of a typical high network traffic dataset. Liang Zhang et al. [
33] proposed, in 2020, an improved LSTM IDS model based on a two-phase DL algorithm, where the first phase uses quantum particle swarm optimization (QPSO) for feature selection and dimensionality reduction, and the second phase uses an LSTM network for classification and therefore, intrusion detection. Running it over the KDD CUP 99 dataset, the model’s QPSO reduced the 41 features to 24 features, resulting in an upgrade of the LSTM from 83.47% to 97.79%, and an F1-Score of 96.65%. The authors state that the proposed model can be used in real network environments for intrusion detection.
In 2020, Arunavo Dey [
34] proposed a CNN-LSTM hybrid model for intrusion detection and trained it on the CICIDS2018 dataset. The author’s model outperformed similar works and achieved a 99.98% accuracy. The model used four different layers: a CNN layer, that performed the convolution operation on the input, an LSTM layer, an attention layer and finally, a dense layer. Amutha et al. [
35] proposed an IDS model that used a single LSTM layer for classification and trained it with the UNSWNB18IDS dataset [
36]. The authors achieved an accuracy of 99.96%. Lokesh Karanam et al. [
37] proposed another IDS model consisting of a CNN for feature selection and an LSTM for sequence analysis and classification. Thanks to the reduced dimensionality from the CNN feature selection, the computation time for the KDD CUP 99 dataset was reduced to one-tenth of previous works while maintaining a 99.6% accuracy. Another hybrid approach to intrusion detection using LSTM was proposed by Bhushan Deore et al. [
38] in 2022. The author’s model also consisted in a CNN for feature selection but, for the detection, the authors used a chimp-chicken swarm optimization-based deep LSTM. The results demonstrated that the proposed model outperformed other works models using vanilla CNNs and RNNs.
As recent network intrusion datasets are composed of high-dimensionality data, feature selection is a promising and important research direction to better implement ML and DL models in real-world deployments of anomaly-based NIDS. Joowha Lee et al. [
39] propose a NIDS using a Deep Sparse Autoencoder that uses DL as a pre-processing mechanism. The authors used the autoencoder to identify the optimal model, reconstruct the data, and then use the resulting dataset with an RF model with lower dimensionality. Using this architecture, the authors reduce the training and testing time of the RF model by approximately half. To reduce computational complexity, Mohammadnoor Injadat et al. [
40] propose a novel multi-stage optimized ML NIDS with an information gain-based feature selection methodology, which results in a reduction of 74% of the required training sample and 50% of the required feature size, while still maintaining the same accuracy performance as before the reductions for the CICIDS2017 and the UNSWNB2015 datasets. Di Mauro et al. [
41] review several recent works that implement ML techniques for network intrusion detection and perform several analyses such as feature correlation, time complexity, and performance. The authors find that using the appropriate feature selection algorithms can reduce the dataset size up to 95% for single-class datasets and up to 92% for multi-class datasets and can reduce close to 95% of the computational time required to train the model. Paired with these computational complexity reductions, in the KDDCUP99 dataset, the accuracy slightly drop from 99.93% to 99.71%.
In 2021, Jitti Abraham et al. [
42] published a review of the state-of-the-art for intrusion detection and prevention in networks using ML and DL, concluding that, while an ever-growing number of works are being published in this area, there is an absence of real-world network traffic analysis, and thus, the real impact of applying these models in a real-world scenario.
One of the challenges associated with using ML and DL models for real-world applications is the space and time complexity. Models with a large number of features can quickly exhaust system memory, as most ML and DL frameworks use exclusively the system memory for training. RNNs and their subclasses, such as the LSTM, can be negatively impacted by the added memory requirements, which effectively adds more computational complexity. Mario di Mauro et al. [
43] reviewed thirteen of the most prominent neural-based techniques relevant to intrusion detection, evaluated the current datasets used for intrusion detection and performed some experimental analysis, which includes single-class vs multi-class datasets time complexity analysis. In this analysis, the authors find that, as usual, single-class datasets result in lower errors than multi-class datasets. The authors also find that DL models are up to two orders of magnitude slower than other techniques due to the fully connected neurons between each layer. Shi Dong et al. [
44] propose a semi-supervised Double Deep Q-Network optimization method for network anomaly detection and perform a time complexity analysis of the proposal against frequently used ML and DL architectures. Although the training and prediction times are similar to previous works, the authors find that it is low enough for real-world deployment and usage. Charlotte Pelletier et al. [
45] compare Random Forests to RNNs and CNNs for image time series and conclude that RNNs might not be suited for large-scale datasets as they present a higher time complexity.









{kind=link}
{kind=link}
{kind=link}
{kind=link}