
A 100-Gb/s PAM-4 DSP in 28-nm CMOS for Serdes Receiver

 , ,
, , 
Abstract
:1. Introduction
2. Architecture of DSP
3. Crucial Techniques
3.1. High-Speed Techniques
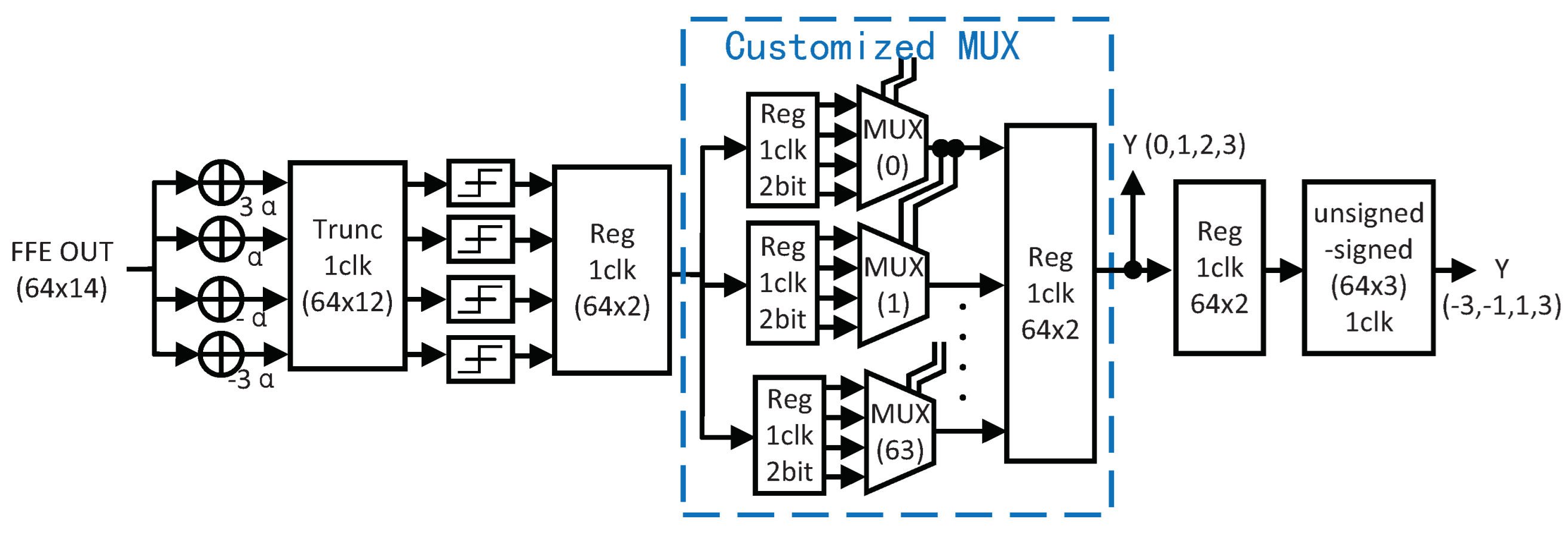
3.1.1. Speculative DFE with Customized MUX
3.1.2. Fixed-Point Operation Strategy
3.2. Lower-Power Techniques
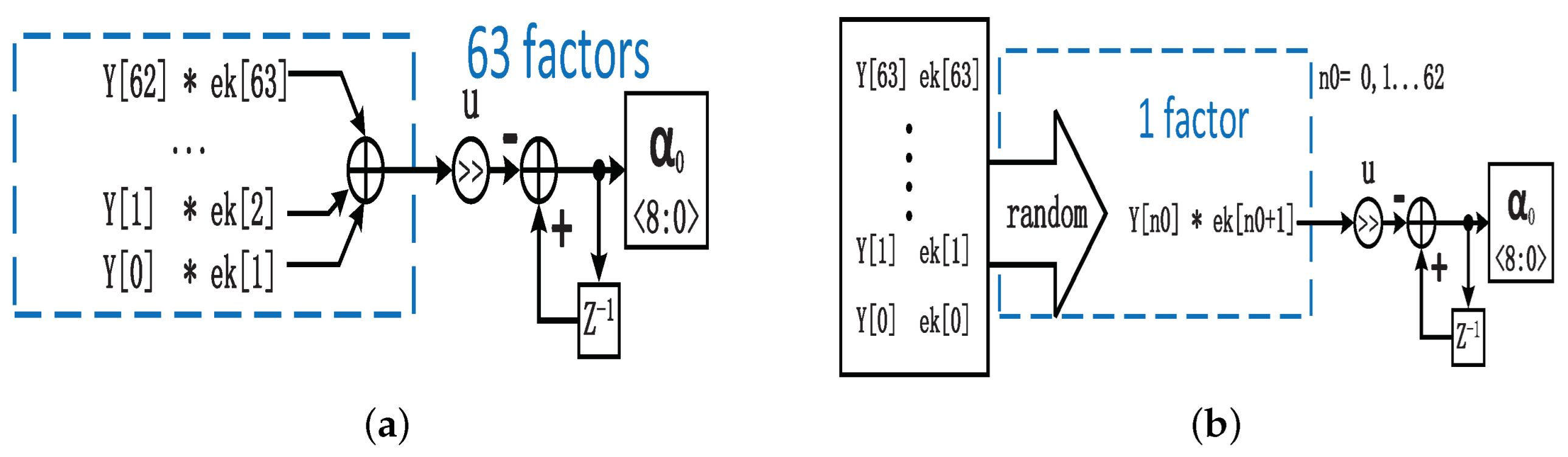
3.2.1. Random-Data-Selection-Based LMS Implementation
3.2.2. Sigma-Delta-Based Average
3.3. Influence of Input Data Quantization
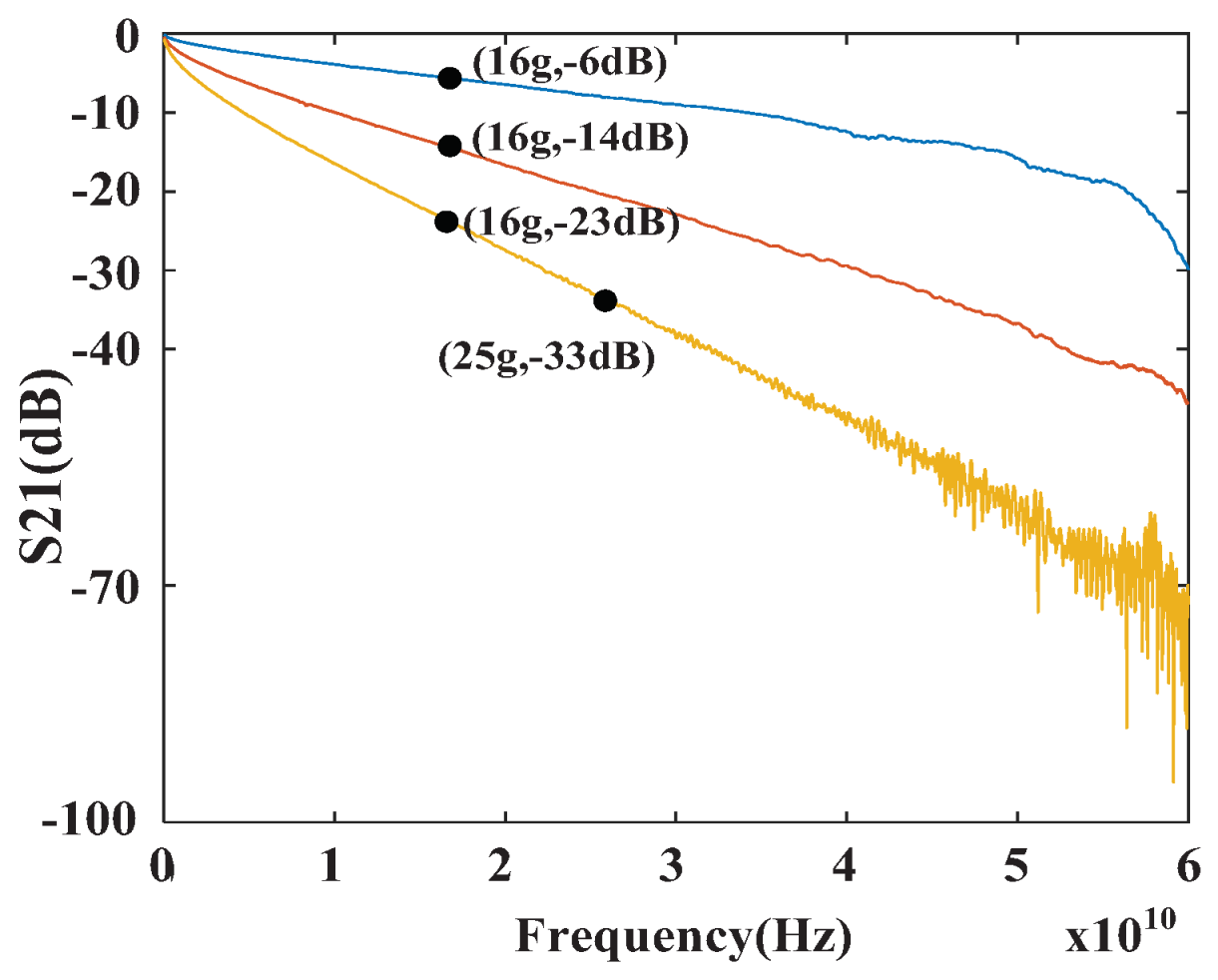
4. Simulation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Parallel LMS Theory Derivation
References
- de Abreu Farias Neto, P.W.; Hearne, K.; Chlis, I.; Carey, D.; Casey, R.; Griffin, B.; Ngankem, F.S.F.N.; Hudner, J.; Geary, K.; Erett, M.; et al. A 112-134-Gb/s PAM4 Receiver Using a 36-Way Dual-Comparator TI-SAR ADC in 7-nm FinFET. IEEE-Solid-State Circuits Lett. 2020, 3, 138–141. [Google Scholar] [CrossRef]
- El-Gammal, K.A.; Hassan, A.N.; Ibrahim, S.A. A 10 Gbps ADC-Based Equalizer for Serial I/O Receiver. In Proceedings of the 2015 10th International Design & Test Symposium (IDT), Amman, Jordan, 14–16 December 2015. [Google Scholar]
- Upadhyaya, P.; Poon, C.F.; Lim, S.W.; Cho, J.; Roldan, A.; Zhang, W.; Namkoong, J.; Pham, T.; Xu, B.; Lin, W.; et al. A Fully Adaptive 19-58-Gb/s PAM-4 and 9.5-29-Gb/s NRZ Wireline Transceiver With Configurable ADC in 16-nm FinFET. IEEE J.-Solid-State Circuits 2019, 54, 18–28. [Google Scholar] [CrossRef]
- Nekouei, F.; Talebi, N.Z.; Kavian, Y.S.; Mahani, A. FPGA Implementation of LMS Self Correcting Adaptive Filter (SCAF) and Hardware Analysis. In Proceedings of the 2012 8th International Symposium on Communication Systems, Networks & Digital Signal Processing (CSNDSP), Poznan, Poland, 18–20 July 2012. [Google Scholar]
- Trakultritrung, A.; Thanangchusin, E.; Chivapreecha, S. Distributed Arithmetic LMS Adaptive Filter Implementation without Look-Up Table. In Proceedings of the 2012 9th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Phetchaburi, Thailand, 16–18 May 2012. [Google Scholar]
- Kiran, S.; Cai, S.; Zhu, Y.; Hoyos, S.; Palermo, S. Digital Equalization With ADC-Based Receivers. IEEE Microw. Mag. 2019, 50, 62–79. [Google Scholar] [CrossRef]
- Lin, C.; Wu, A. Soft-Threshold-Based Multilayer Decision Feedback Equalizer (STM-DFE) Algorithm and VLSI Architecture. IEEE Trans. Signal Process. 2005, 53, 3325–3336. [Google Scholar]
- Upadhyaya, P.; Poon, C.F.; Lim, S.W.; Cho, J.; Roldan, A.; Zhang, W.; Pham, J.N.T.; Pham, T.; Pham, T. A Fully Adaptive 19-to-56Gb/s PAM-4 Wireline Transceiver with a Configurable ADC in 16nm FinFET. In Proceedings of the 2018 IEEE International Solid-State Circuits Conference—(ISSCC), San Francisco, CA, USA, 11–15 February 2018. [Google Scholar]
- Roshan-Zamir, A.; Iwai, T.; Fan, Y.H.; Kumar, A.; Yang, H.W.; Sledjeski, L.; Palermo, S. A 56-Gb/s PAM4 Receiver With Low-Overhead Techniques for Threshold and Edge-Based DFE FIR- and IIR-Tap Adaptation in 65-nm CMOS. IEEE J.-Solid-State Circuits 2019, 54, 672–684. [Google Scholar] [CrossRef]
- Li, H.; Hsu, C.-M.; Sharma, J.; Jaussi, J.; Balamurugan, G. A 100 Gb/s-8.3dBm-Sensitivity PAM-4 Optical Receiver with Integrated TIA, FFE and Direct-Feedback DFE in 28 nm CMOS. IEEE J.-Solid-State Circuits 2021, 57, 44–53. [Google Scholar] [CrossRef]
- Guo, S.; Ding, L.; Jin, J. A 16/32GB/s NRZ/PAM4 Receiver with Dual-Loop CDR and Threshold Voltage Calibration. In Proceedings of the 2019 IEEE 13th International Conference on ASIC (ASICON), Chongqing, China, 29 October–1 November 2019. [Google Scholar]
- IEEE Std 802.3; IEEE Standard for Ethernet. IEEE: New York, NY, USA, 2018.
- Xu, D.; Kou, Y.; Lai, P.; Cheng, Z.; Cheung, T.Y.; Moser, L.; Liu, X.; Zhang, Y.; Lam, M.P.; Jia, H.; et al. A Scalable Adaptive ADC/DSP-Based 1.25-to-56 Gbps/112 Gbps High-Speed Transceiver Architecture Using Decision-Directed MMSE CDR in 16 nm and 7 nm. In Proceedings of the 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Width | 8 | 9 | 10 |
|---|---|---|---|
| VEC | 5.01 | 4.84 | 4.69 |
| VEOR | 6.93 | 7.38 | 7.57 |
| Type | Sum Factor | Sum Pipeline | Technology | Clock (Hz) | No.Adders | Power |
|---|---|---|---|---|---|---|
| Full | 63 | 3 | 28 nm | 1 G | 12,676 | 20.5 mW |
| Random | 1 | 1 | 28 nm | 1 G | 1290 | 2.0 mW |
| Type | Order | Technology | Channel | Clock (Hz) | No.Adders | Power |
|---|---|---|---|---|---|---|
| Moving average | 4 | 28 nm | 64 | 1 G | 36,140 | 43 mW |
| Sigma-delta | 1 | 28 nm | 64 | 1 G | 10,407 | 14 mW |
| References | This Work | [10] | [13] | [1] |
|---|---|---|---|---|
| Technology | 28 nm CMOS | 28 nm CMOS | 7 nm FinFET | 7 nm FinFET |
| Data rate | 100 Gb/s | 100 Gb/s | 112 Gb/s | 134 Gb/s |
| Data formate | PAM4 | PAM4 | PAM4 | PAM4 |
| Equalization | 16-tap FFE,1-tap DFE | 2-tap FFE,2-tap DFE | 32-tap FFE,1-tap DFE | CTLE,16-tap FFE,1-tap DFE |
| Channel | 33 dB | - | 35 dB | 33 dB |
| Area | 1.2 mm2 | 5.5 mm2 | - | 0.383 mm2 |
| Supply | 0.9 V | - | 0.75 V/0.9 V/1.2 V | 0.88 V/1.2 V/1.5 V |
| DSP power efficiency | 7.22 pJ/bit | 3.9 pJ/bit | 3.0 pJ/bit | 5.1 pJ/bit |
| BER | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Liu, M.; Zheng, X.; Xiao, G.; Yuan, G.; Hao, Q.; Jin, Z. A 100-Gb/s PAM-4 DSP in 28-nm CMOS for Serdes Receiver. Electronics 2023, 12, 257. https://doi.org/10.3390/electronics12020257
Li W, Liu M, Zheng X, Xiao G, Yuan G, Hao Q, Jin Z. A 100-Gb/s PAM-4 DSP in 28-nm CMOS for Serdes Receiver. Electronics. 2023; 12(2):257. https://doi.org/10.3390/electronics12020257
Chicago/Turabian StyleLi, Weijie, Min Liu, Xuqiang Zheng, Guangxing Xiao, Guojun Yuan, Qinfen Hao, and Zhi Jin. 2023. "A 100-Gb/s PAM-4 DSP in 28-nm CMOS for Serdes Receiver" Electronics 12, no. 2: 257. https://doi.org/10.3390/electronics12020257
APA StyleLi, W., Liu, M., Zheng, X., Xiao, G., Yuan, G., Hao, Q., & Jin, Z. (2023). A 100-Gb/s PAM-4 DSP in 28-nm CMOS for Serdes Receiver. Electronics, 12(2), 257. https://doi.org/10.3390/electronics12020257