
Multimodel Collaboration to Combat Malicious Domain Fluxing

 ,
,  and
and
Abstract
:1. Introduction
- Improve detection accuracy: A single detection model may not be able to cover all malicious behaviors and variants comprehensively. Therefore, utilizing multiple models for collaborative detection can enhance the accuracy of detection. Each model can emphasize different features or algorithms, thereby increasing the detection rate of malicious software and reducing false positives.
- Counteract the evolution of malicious software: Malicious software evolves rapidly, with new variants constantly emerging. By employing multiple detection models, the sensitivity to different variants of malicious software can be increased, enabling a timely detection and response to new threats.
- Compensate for the limitations of a single model: Each detection model has its own limitations. Some models may perform well in specific types of malicious behaviors while being less accurate in others. A collaborative detection with multiple models can compensate for these limitations by integrating and analyzing the results of multiple models, thereby improving overall detection performance.
- Enhance robustness and stability: A single model can be susceptible to false positives or false negatives, thereby impacting the robustness and stability of the entire system. Collaborative detection with multiple models can mitigate this issue by integrating and analyzing the detection results from multiple models, reducing the probability of false positives and false negatives and improving the system’s robustness and stability.
- This paper analyzes DGA domain names from multiple perspectives in terms of both artificial features and neural network advanced features. In this paper, 34 artificial features are extracted from three aspects, namely, string structure, language characteristics, and distribution statistics, and deep neural networks are used to actively mine the advanced features of domain name characters to detect DGA domain names through traditional machine learning methods and deep learning methods.
- A multimodel decision-making framework based on statistical learning is proposed. This statistical learning-based approach provides the same comparison criteria for heterogeneous models, determines the prediction labels based on the performance of the samples in each type of sample set as well as a predetermined level of significance, and produces decision results with a certain level of confidence through voting, If the prediction labels of all models do not have sufficient confidence, the combined confidence and credibility metric comprehensively evaluates the prediction quality of the models and selects the highest quality prediction as the final decision result.
- In this paper, we design and implement a DGA detection algorithm based on statistical learning. The detection algorithm takes domain name strings as the research object, uses four heterogeneous methods, XGBoost, B-RF, LSTM, and CNN, to detect DGA domain names, evaluates the prediction quality of these heterogeneous methods based on statistical learning, and generates the DGA detection results. The detection algorithm analyzes DGA domain names from multiple perspectives from the artificial features and high-level features unearthed by the neural network, improves the detection effect, and can effectively identify the elimination of invalid prediction results in the decision-making process, maximize the stability of the algorithm, and is a real-time, lightweight detection method.
2. Related Work
3. Feature Engineering
- Structural features: This paper extracted six structural features, which represent the characteristics of the domain name in the string structure. The specific information is shown in Table 1. We used and as examples to illustrate the specific values of these features, where d1 is a well-known normal domain name, and is a malicious domain name. For a better understanding, the fourth feature in Table 1 is introduced in detail below.(#4) tld_dga: It indicates whether the top-level domain name is frequently related to malicious activities. It is a Boolean value (‘0’ indicates that the top-level domain name is not related to malicious activities, “1” indicates related, and “0” indicates unrelated).
- Linguistic features: This paper extracted a total of 15 linguistic features. This type of feature mainly focuses on the differences in language patterns between normal domain names and DGA domain names. It has a great effect on machine learning classifiers. Table 2 lists these features’ information, and specific values for and , where , . Below is a detailed introduction to features #7, #11, #12, #14, #15, #16, and #18 in Table 2.
- (#7) uni_domain: It indicates the number of unique characters in the secondary domain name, which is the number of characters that only appear once.
- (#11) sym_sld: It refers to the ratio of the frequency of the three special symbols “.”, “-”, and “_” in a secondary domain name to the total length of the secondary domain name.
- (#12) hex_sld: It refers to the ratio of the number of hexadecimal characters (0–9 and a–f) to the total length of the secondary domain name in the secondary domain name.
- (#14) vow_sld: It refers to the ratio of vowel characters (“a”, “e”, “i”, “o”, “u”) to the total length of the secondary domain name in the secondary domain name.
- (#15) con_sld: It refers to the ratio of consonant characters (“b”, “c”, “d”, “f”, etc.) to the total length of a secondary domain name.
- (#16) repeat_letter_sld: It refers to the ratio of the number of characters with a frequency greater than 1 in a secondary domain name to the total length of the secondary domain name.
- (#18) cons_con_ratio_sld: It refers to the ratio of the total length of subsequences composed of continuous consonants in a secondary domain name to the total length of the secondary domain name.
- (#20) gib_value_sld: Using the Gibberish method to detect the readability of secondary domain name strings, this feature is a Boolean value, where “1” indicates the string is readable, and “0” indicates the string is unreadable and difficult to pronounce.
- (#21) hmm_log_prob_sld: This feature uses a hidden Markov model (HMM) to measure the readability of secondary domain names, thus distinguishing between normal and malicious domains. Due to the fact that normal domain names generally use combinations of common words or abbreviations of certain words to form domain names, this method selects common English words or abbreviations to construct an HMM model. In general, the HMM coefficient of normal domain names will be higher, greater than −100, while the HMM coefficient of DGA domain names is lower, less than −100, due to being randomly generated.
- Statistical features: This paper extracted 13 statistical features that distinguish normal domain names from DGA domain names from the perspective of character distribution. The basic information of these features is summarized in Table 3, and we take and as examples to illustrate the specific selection of these features’ values. We provide a detailed introduction to features #22, #23, #25, #28, #31, #33, and #34 in Table 3.
- (#22) entropy_sld: It represents the Shannon entropy value of the secondary domain name, which can measure the randomness of the secondary domain name. Generally, the randomness of a normal domain name is low, with the Shannon entropy being low. However, the randomness of the DGA domain name generated by the algorithm is high, and the corresponding entropy value is also high.
- (#23) gram2_med_sld: It refers to the median frequency of the occurrence of binary (2-gram) character groups in the secondary domain name string. In natural language, the distribution of n-gram character groups is uneven, so this feature can distinguish between normal domain names and DGA domain names from the perspective of the frequency of n-gram character groups.
- (#25) gram2_cmed_sld: This feature is also the median frequency of the occurrence of binary (2-gram) character groups. The difference from feature #23 is that before calculating the feature, it is necessary to copy the secondary domain name to construct a new string. Assuming “baidu” is the secondary domain name, we use “baidubaidu” to calculate the feature. Repetitive operations can increase the length of a string, which is beneficial for the calculation of n-grams, especially for shorter domain names. In addition, repetitive operations can also amplify the characteristics of the string and facilitate classification. Assuming the secondary domain name is “aaaa”, repeating it to form “aaaaaaaa” will make the character string look even more abnormal.
- (#28) avg_gram2_rank_sld: This feature represents the average frequency of all 2-gram character groups in the secondary domain name.
- (#31) std_gram2_rank_sld: This feature represents the standard deviation of the frequency of all 2-gram character groups in the secondary domain name and can measure the degree of dispersion of these character groups.
- (#33) gni: It refers to the Gini value of characters in a secondary domain name, calculated as shown in formula 1. In the formula, n represents the number of unique characters in the secondary domain name (#8), and represents the frequency of unique characters appearing in the secondary domain name.
- (#34) cer: It represents the classification of character errors in a secondary domain name, calculated as shown in Formula (2). represents the frequency of the unique character appearing in the secondary domain name.
4. Multimodel Detection
4.1. XGBoost Model Training
4.2. B-RF Model Training
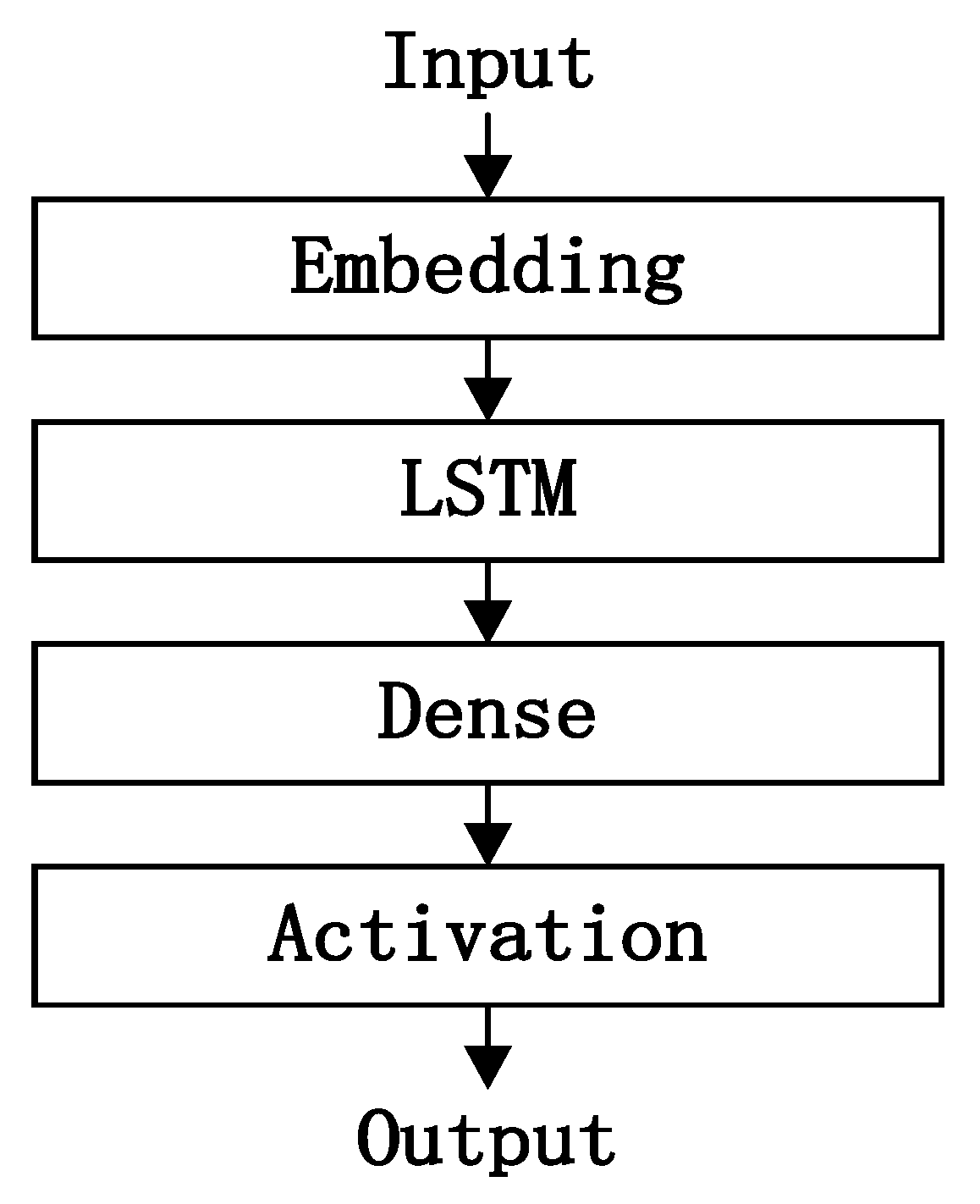
4.3. LSTM Model Training
4.4. CNN Model Training
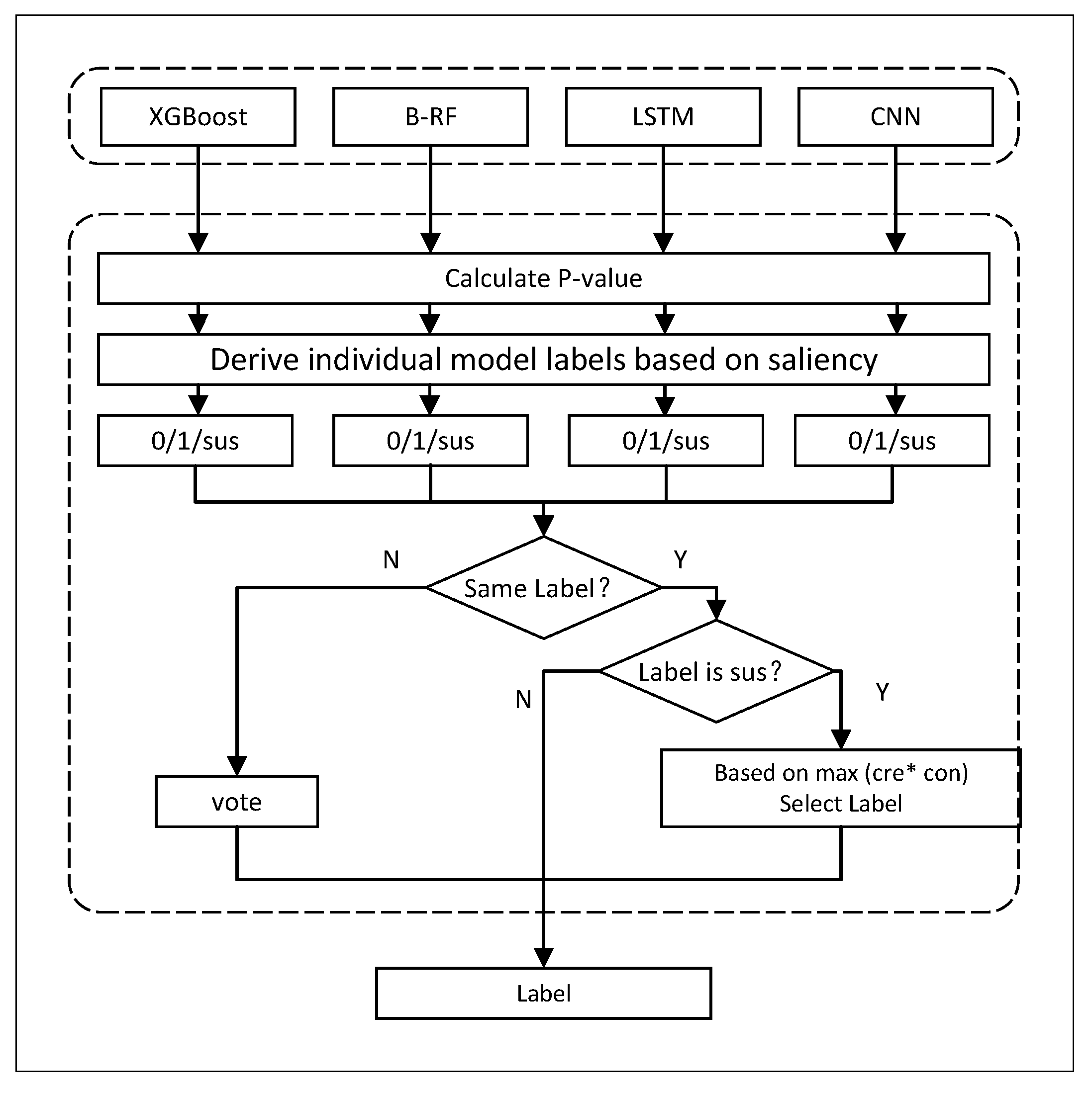
4.5. DGA Domain Name Detection Based on Statistical Learning
4.5.1. Determining Basic Model Prediction Labels
| Algorithm 1: Determine a single model label based on p-value and confidence level |
Input: confidence level , of the sample Output: 1: if and 2: 3: else if and 4: 5: else if 6: rejecting predicted outcomes 7: |
4.5.2. Multimodel Collaborative Prediction Based on Statistical Learning
- If the label results of all models are 1 or 0, it indicates that the decision results of all basic models are consistent and have a certain level of confidence in this result. Therefore, the label is directly output as the final result.
- If the label results of all models are “suspicious”, it indicates that the prediction quality of all models is lower than . In this case, it is necessary to calculate the confidence and credibility values of each model for the sample based on the p-value and comprehensively evaluate the prediction quality of the basic model from two perspectives. When the confidence and credibility are both large, it indicates that the sample points are similar to the predicted category and have significant differences from other categories, indicating that the basic model has a higher classification quality for . Therefore, this article used the product (cre * con) method to select the model with the highest quality from these basic models and uses the prediction label of this model as the final result.
- If the label results of all models are inconsistent, a vote is taken to determine the label (“suspicious” results are not included). If there is an equal number of votes, the final label is selected based on the combination of confidence and credibility.
5. Experimental Process and Results Analysis
5.1. Experimental Data and Data Preprocessing
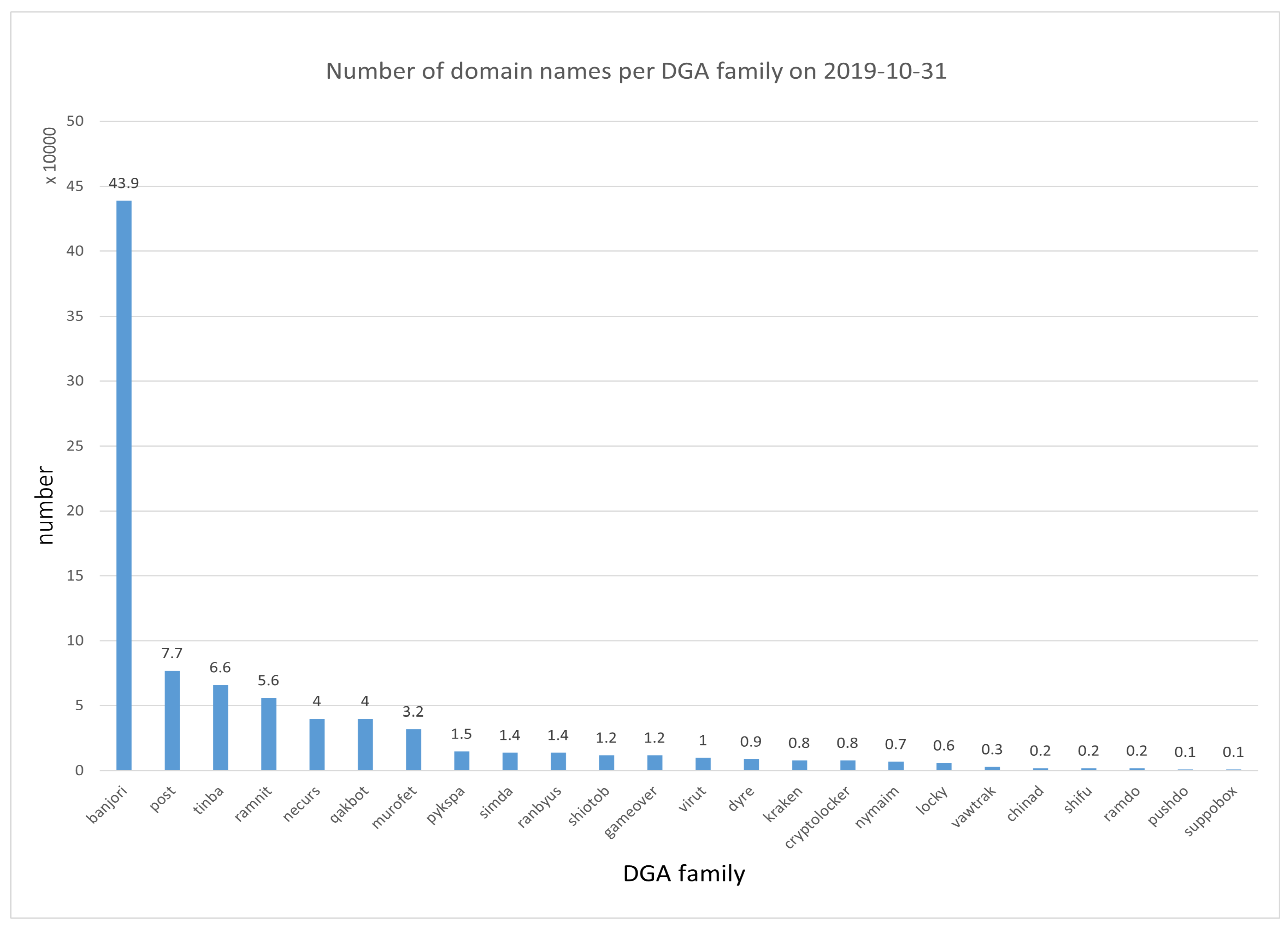
5.1.1. Dataset
5.1.2. Data Preprocessing
- Convert alphabetical characters in domain names to lowercase.
- Remove all domain names starting with “–”. Because a domain name starting with ‘–’ is an Internationalized Domain Name (IDN), the DGA algorithm will not generate an IDN domain name.
- Using “.” as a separator, remove domain names with more than four segments.
- Remove domain names from www.com and www.com.cn.
- Remove duplicate data.
5.1.3. Evaluation Criteria
- TP (true positive): it refers to the cases where the model correctly identifies a domain name as malicious, and it is indeed malicious.
- TN (true negative): it refers to the cases where the model correctly identifies a domain name as benign, and it is indeed benign.
- FP (false positive): it refers to the cases where the model incorrectly identifies a domain name as malicious, whereas it is actually benign.
- FN (false negative): it refers to the cases where the model incorrectly identifies a domain name as benign, whereas it is actually malicious.
- : represents the ratio of the number of correctly classified samples to the total number of samples.
- : represents the ratio of the true number of positive samples to the number of positive samples in the classification results.
- : represents the proportion of correctly classified positive samples to all positive samples, .
- : Represents the harmonic mean of the accuracy rate and the recovery rate. When the value is high, it means that both the accuracy rate and the recovery rate are high.
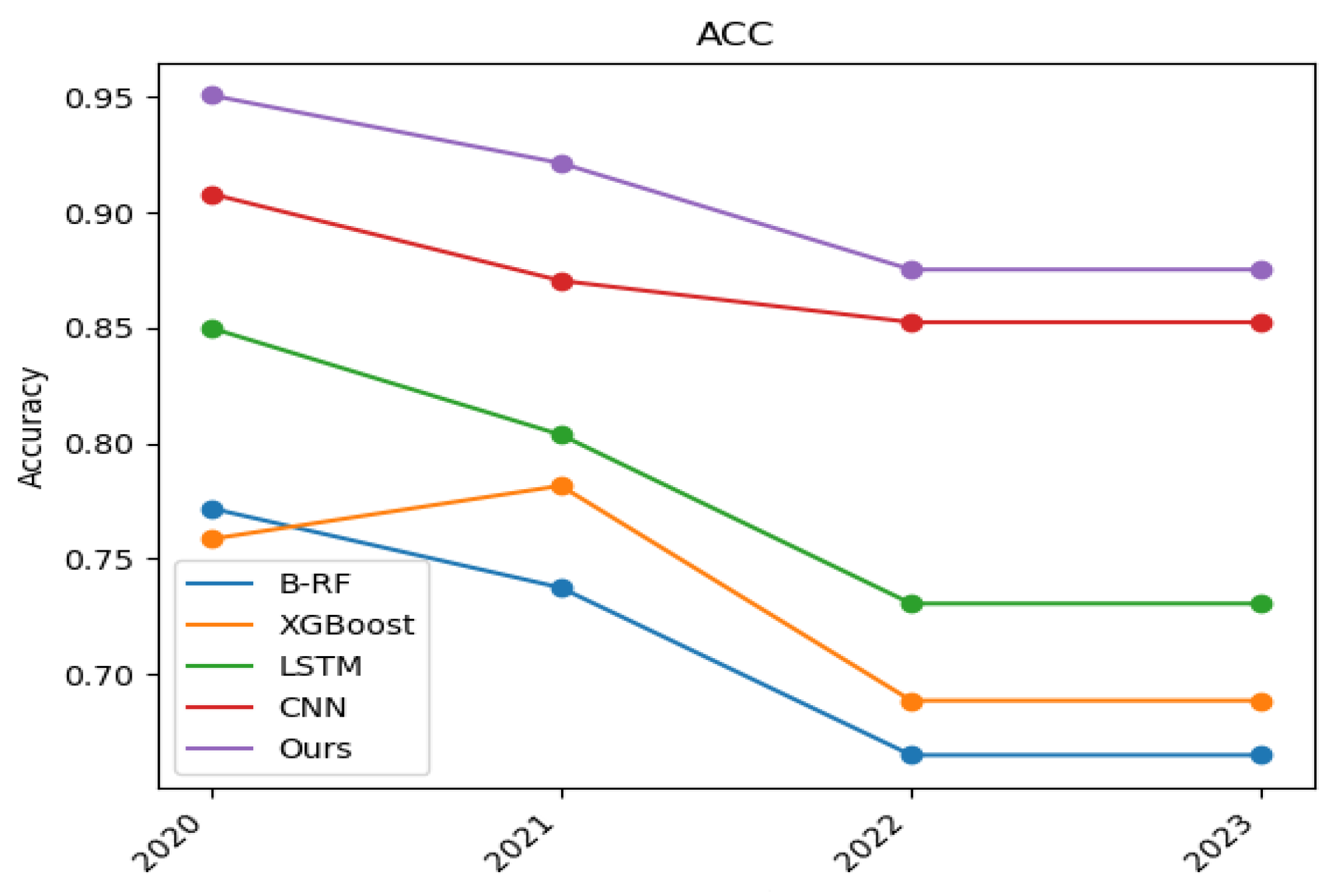
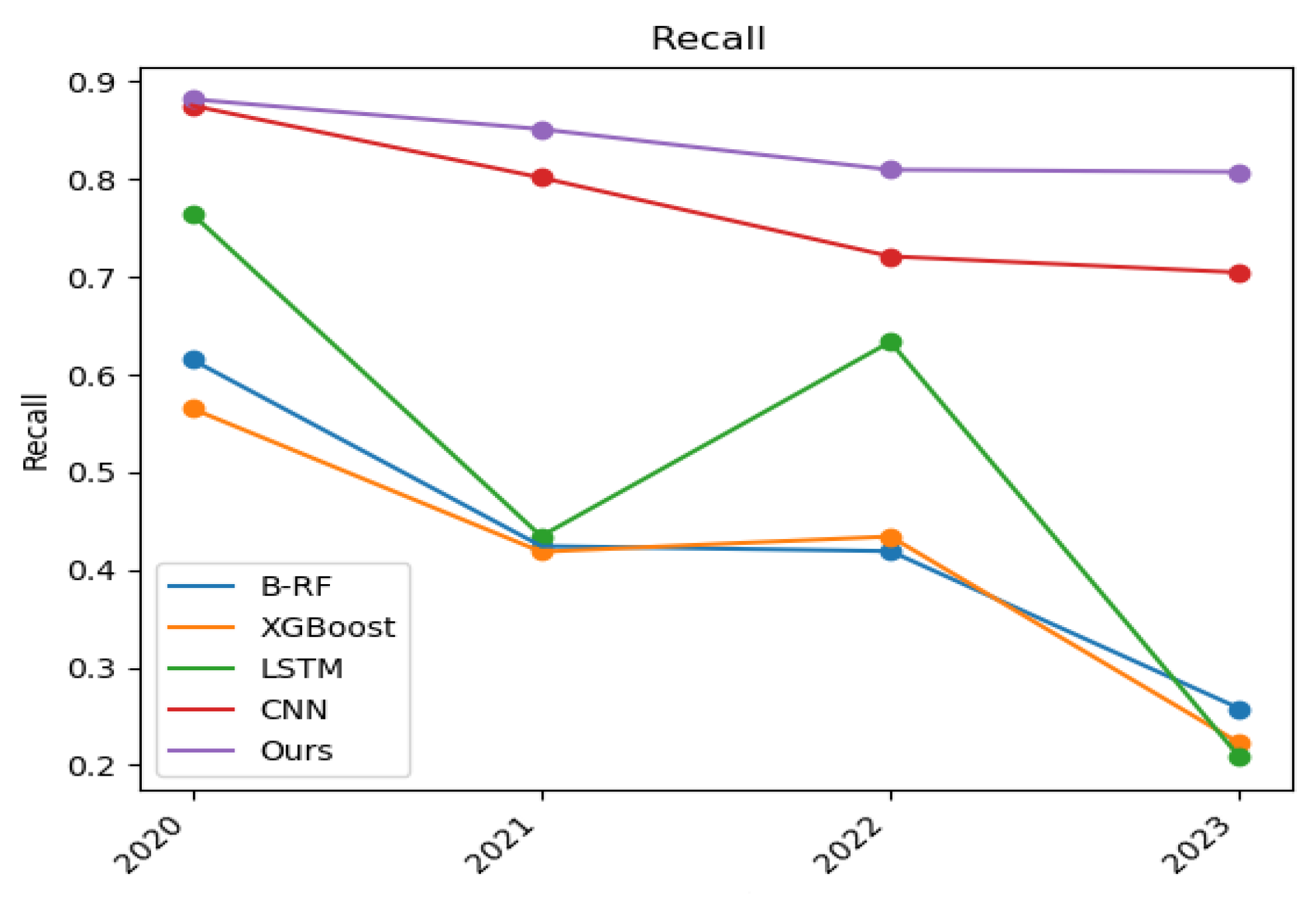
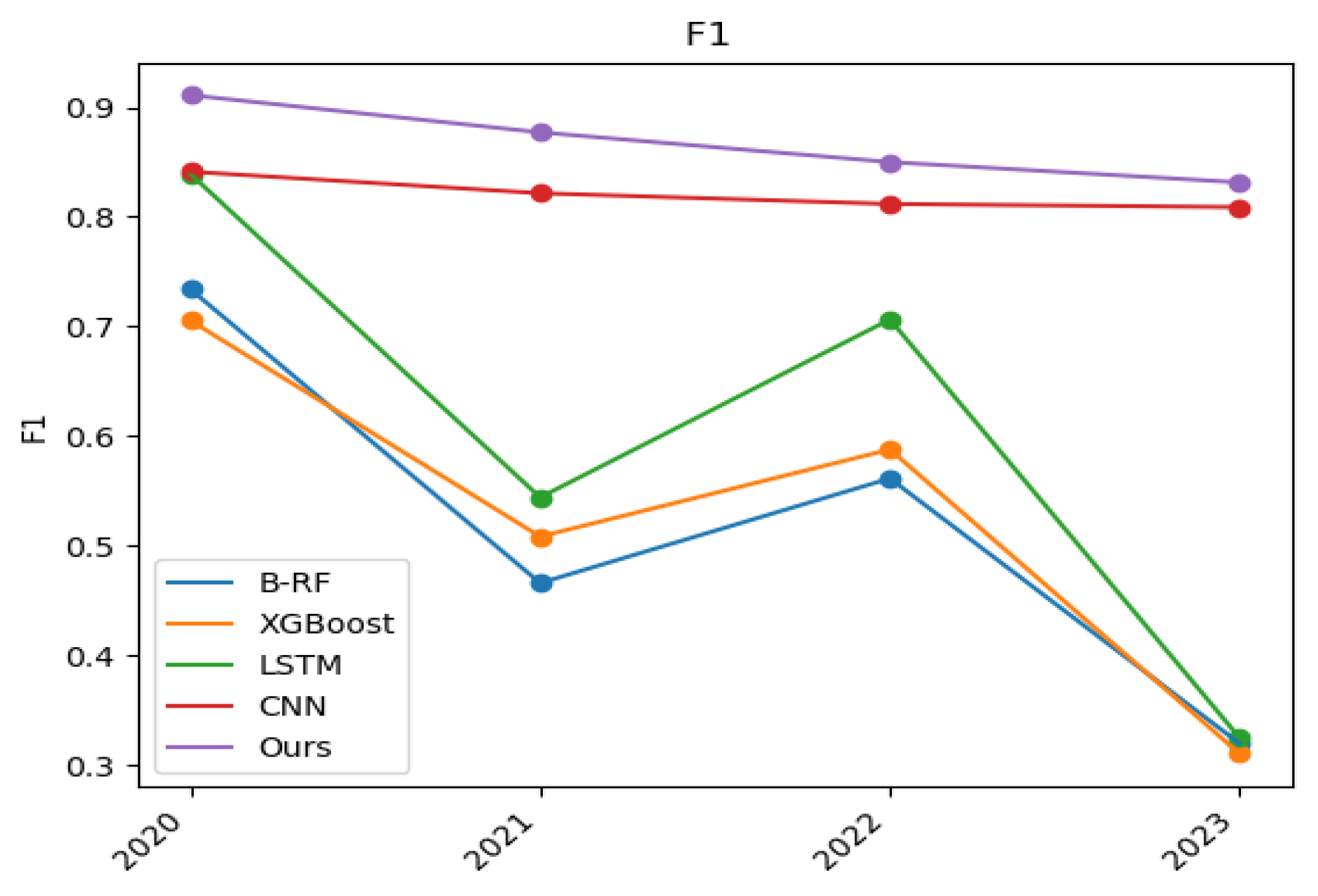
5.2. Experimental Results and Analysis
5.3. Summary
6. Conclusions and Future Work
6.1. Conclusions
6.2. Future Work
- The detection method proposed in this paper contains four heterogeneous methods, XGBoost, B-RF, LSTM, and CNN, and provides a unified comparison standard for these heterogeneous models using statistical learning, which has strong scalability and provides a new way of thinking for multimodel detection of DGA domain names, so more and better detection methods can be considered for integration into this algorithm in future research to further improve the detection capability of the algorithm.
- In this paper, we studied the binary classification problem in DGA detection, and in future research, we can try to apply this detection algorithm to the DGA family multiclassification problem. By extending the algorithm to classify different DGA families, a more comprehensive understanding of the diverse nature of DGA domains can be achieved.
- Incorporating explainability: In future research, it would be valuable to enhance the interpretability and explainability of the detection algorithm. By providing insights into the decision-making process of the model and the importance of different features, users can gain a better understanding of how the algorithm detects DGA domains.
- Real-time detection: This study mainly focuses on offline detection of DGA domains. In future research, it would be beneficial to explore real-time detection methods that can effectively identify DGA domains in a timely manner. This would enable the algorithm to be deployed in dynamic environments, such as network security systems, where quick detection and response are crucial.
- Robustness to adversarial attacks: Investigating the robustness of the detection algorithm against adversarial attacks would be an important direction for future research. Adversarial attacks aim to deceive the algorithm by introducing subtle modifications to the input data. Developing techniques to enhance the algorithm’s resilience to such attacks would be valuable in practical applications.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wagan, A.A.; Li, Q.; Zaland, Z.; Marjan, S.; Bozdar, D.K.; Hussain, A.; Mirza, A.M.; Baryalai, M. A Unified Learning Approach for Malicious Domain Name Detection. Axioms 2023, 12, 458. [Google Scholar] [CrossRef]
- Chen, S.; Lang, B.; Chen, Y.; Xie, C. Detection of Algorithmically Generated Malicious Domain Names with Feature Fusion of Meaningful Word Segmentation and N-Gram Sequences. Appl. Sci. 2023, 13, 4406. [Google Scholar] [CrossRef]
- Wang, H.; Tang, Z.; Li, H.; Zhang, J.; Cai, C. DDOFM: Dynamic malicious domain detection method based on feature mining. Comput. Secur. 2023, 130, 103260. [Google Scholar] [CrossRef]
- Abu Al-Haija, Q.; Alohaly, M.; Odeh, A. A Lightweight Double-Stage Scheme to Identify Malicious DNS over HTTPS Traffic Using a Hybrid Learning Approach. Sensors 2023, 23, 3489. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, H.; Li, X.; Yang, W.; Wu, X. A Novel Phishing Website Detection Model Based on LightGBM and Domain Name Features. Symmetry 2023, 15, 180. [Google Scholar] [CrossRef]
- Liang, Y.; Cheng, Y.; Zhang, Z.; Chai, T.; Li, C. Illegal Domain Name Generation Algorithm Based on Character Similarity of Domain Name Structure. Appl. Sci. 2023, 13, 4061. [Google Scholar] [CrossRef]
- Wei, L.; Wang, L.; Liu, F.; Qian, Z. Clustering Analysis of Wind Turbine Alarm Sequences Based on Domain Knowledge-Fused Word2vec. Appl. Sci. 2023, 13, 10114. [Google Scholar] [CrossRef]
- Chaganti, R.; Suliman, W.; Ravi, V.; Dua, A. Deep learning approach for SDN-enabled intrusion detection system in IoT networks. Information 2023, 14, 41. [Google Scholar] [CrossRef]
- Rahali, A.; Akhloufi, M.A. MalBERTv2: Code Aware BERT-Based Model for Malware Identification. Big Data Cogn. Comput. 2023, 7, 60. [Google Scholar] [CrossRef]
- Zhai, Q.; Zhu, W.; Zhang, X.; Liu, C. Contrastive refinement for dense retrieval inference in the open-domain question answering task. Future Internet 2023, 15, 137. [Google Scholar] [CrossRef]
- Antonakakis, M.; Perdisci, R.; Nadji, Y.; Vasiloglou, N.; Abu-Nimeh, S.; Lee, W.; Dagon, D. From Throw-Away Traffic to Bots: Detecting the Rise of DGA-Based Malware. In Proceedings of the 21st USENIX Security Symposium (USENIX Security 12), Bellevue, WA, USA, 8–10 August 2012; pp. 491–506. [Google Scholar]
- Plohmann, D.; Yakdan, K.; Klatt, M.; Bader, J.; Gerhards-Padilla, E. A Comprehensive Measurement Study of Domain Generating Malware. In Proceedings of the 25th USENIX Security Symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; USENIX Association: Austin, TX, USA, 2016; pp. 263–278. [Google Scholar]
- Al lelah, T.; Theodorakopoulos, G.; Reinecke, P.; Javed, A.; Anthi, E. Abuse of Cloud-Based and Public Legitimate Services as Command-and-Control (C&C) Infrastructure: A Systematic Literature Review. J. Cybersecur. Priv. 2023, 3, 558–590. [Google Scholar]
- Sui, Z.; Shu, H.; Kang, F.; Huang, Y.; Huo, G. A Comprehensive Review of Tunnel Detection on Multilayer Protocols: From Traditional to Machine Learning Approaches. Appl. Sci. 2023, 13, 1974. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, Y.; Liu, W.; Zhang, M.; Lin, D. Linear Private Set Union from Multi-Query Reverse Private Membership Test. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 337–354. [Google Scholar]
- Eltahlawy, A.M.; Aslan, H.K.; Abdallah, E.G.; Elsayed, M.S.; Jurcut, A.D.; Azer, M.A. A Survey on Parameters Affecting MANET Performance. Electronics 2023, 12, 1956. [Google Scholar] [CrossRef]
- Ogundokun, R.O.; Arowolo, M.O.; Damaševičius, R.; Misra, S. Phishing Detection in Blockchain Transaction Networks Using Ensemble Learning. Telecom 2023, 4, 279–297. [Google Scholar] [CrossRef]
- Bubukayr, M.; Frikha, M. Effective Techniques for Protecting the Privacy of Web Users. Appl. Sci. 2023, 13, 3191. [Google Scholar] [CrossRef]
- Davuth, N.; Kim, S.R. Classification of malicious domain names using support vector machine and bi-gram method. Int. J. Secur. Its Appl. 2013, 7, 51–58. [Google Scholar]
- Vinayakumar, R.; Soman, K.; Poornachandran, P.; Sachin Kumar, S. Evaluating deep learning approaches to characterize and classify the DGAs at scale. J. Intell. Fuzzy Syst. 2018, 34, 1265–1276. [Google Scholar] [CrossRef]
- Mowbray, M.; Hagen, J. Finding domain-generation algorithms by looking at length distribution. In Proceedings of the 2014 IEEE International Symposium on Software Reliability Engineering Workshops, Naples, Italy, 3–6 November 2014; pp. 395–400. [Google Scholar]
- Woodbridge, J.; Anderson, H.S.; Barford, P. Inferring domain generation algorithms with a Viterbi algorithm variant. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1010–1021. [Google Scholar] [CrossRef]
- Schüppen, S.; Teubert, D.; Herrmann, P.; Meyer, U. FANCI: Feature-based Automated NXDomain Classification and Intelligence. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; USENIX Association: Baltimore, MD, USA, 2018; pp. 1165–1181. [Google Scholar]
- Yu, S.; Wu, J.; Xiang, Y. A novel method for DGA domain name detection based on character n-gram and sequence pattern. Secur. Commun. Netw. 2017, 2017, 4176356. [Google Scholar]
- Yadav, S.; Reddy, A. Detecting algorithmically generated domain names with entropy-based features. In Proceedings of the 2013 ACM conference on Computer and Communications Security, Berlin, Germany, 4–8 November 2013; pp. 447–458. [Google Scholar] [CrossRef]
- Zhao, D.; Li, H.; Sun, X.; Tang, Y. Detecting DGA-based botnets through effective phonics-based features. Future Gener. Comput. Syst. 2023, 143, 105–117. [Google Scholar] [CrossRef]
- Bilge, L.; Balduzzi, M.; Kirda, E. Dissecting Android malware: Characterization and evolution. In Proceedings of the 2011 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 22–25 May 2011; pp. 95–110. [Google Scholar] [CrossRef]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Gritzalis, D. Detecting DGA-based botnets using DNS traffic analysis. IEEE Trans. Dependable Secur. Comput. 2016, 13, 218–231. [Google Scholar]
- Zhao, C.; Zhang, Y.; Wang, Y. A Feature Ensemble-based Approach to Malicious Domain Name Identification from Valid DNS Responses. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Zhao, N.; Jiang, M.; Zhang, X.; Liu, Y. Detection of DGA domains using deep learning. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Zhang, Q.; Ma, W.; Wang, Y.; Zhang, Y.; Shi, Z.; Li, Y. Backdoor attacks on image classification models in deep neural networks. Chin. J. Electron. 2022, 31, 199–212. [Google Scholar] [CrossRef]
- Zheng, J.; Zhang, Y.; Li, Y.; Wu, S.; Yu, X. Towards Evaluating the Robustness of Adversarial Attacks Against Image Scaling Transformation. Chin. J. Electron. 2023, 32, 151–158. [Google Scholar] [CrossRef]
- Sun, X.; Yang, J.; Wang, Z.; Liu, H. Hgdom: Heterogeneous graph convolutional networks for malicious domain detection. In Proceedings of the NOMS 2020-2020 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 20–24 April 2020; pp. 1–9. [Google Scholar]
- Li, C.; Xie, J.; Cheng, Y.; Zhang, Z.; Chen, J.; Wang, H.; Tao, H. Research on the Construction of High-Trust Root Zone File Based on Multi-Source Data Verification. Electronics 2023, 12, 2264. [Google Scholar] [CrossRef]
- Li, X.; Lu, C.; Liu, B.; Zhang, Q.; Li, Z.; Duan, H.; Li, Q. The Maginot Line: Attacking the Boundary of {DNS} Caching Protection. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 3153–3170. [Google Scholar]
- Ashiq, M.I.; Li, W.; Fiebig, T.; Chung, T. You’ve Got Report: Measurement and Security Implications of {DMARC} Reporting. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 4123–4137. [Google Scholar]
- Xu, C.; Zhang, Y.; Shi, F.; Shan, H.; Guo, B.; Li, Y.; Xue, P. Measuring the Centrality of DNS Infrastructure in the Wild. Appl. Sci. 2023, 13, 5739. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Yu, B.; Gray, D.L.; Pan, J.; Cock, M.D.; Nascimento, A.C.A. Inline DGA Detection with Deep Networks. In Proceedings of the IEEE International Conference on Data Mining Workshops, Orleans, LA, USA, 18–21 November 2017. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Pochat, V.L.; Van Goethem, T.; Tajalizadehkhoob, S.; Korczyński, M.; Joosen, W. Tranco: A research-oriented top sites ranking hardened against manipulation. arXiv 2018, arXiv:1806.01156. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Feature | Note | ||
|---|---|---|---|---|
| 1 | domain_len | Length of SLD.TLD | 9 | 23 |
| 2 | sld_len | Length of secondary domain name | 5 | 16 |
| 3 | tld_len | Length of top domain name | 3 | 6 |
| 4 | tld_dga | Whether some malicious top-level domain names are included | 0 | 1 |
| 5 | tokens_sld | Number of tokens divided by “-” | 0 | 0 |
| 6 | flag_dig_tld | Does it start with a number? | 0 | 1 |
| # | Feature | Note | ||
|---|---|---|---|---|
| 7 | uni_domain | Number of unique characters in the domain name | 8 | 13 |
| 8 | uni_sld | Number of unique characters in the secondary domain name | 5 | 12 |
| 9 | uni_tld | Total number | 3 | 3 |
| 10 | digits_sld | Total number | 0 | 3 |
| 11 | sym_sld | Proportion of special characters | 0.0 | 0.0 |
| 12 | hex_sld | Ratio of hexadecimal characters | 0.6 | 0.56 |
| 13 | dig_sld | Number proportion | 0.0 | 0.19 |
| 14 | vow_sld | Proportion of vowel letters | 0.6 | 0.19 |
| 15 | con_sld | Proportion of consonant characters | 0.4 | 0.63 |
| 16 | repeat_letter_sld | Proportion of duplicate characters | 0.0 | 0.19 |
| 17 | rep_char_ratio_sld | Ratio of repeated characters to unique characters | 0.0 | 0.25 |
| 18 | cons_con_ratio_sld | Proportion of continuous consonants | 0.0 | 0.38 |
| 19 | cons_dig_ratio_sld | Proportion of consecutive numbers | 0.0 | 0.13 |
| 20 | gib_value_sld | Gib written detection | 1 | 0 |
| 21 | hmm_log_prob_sld | HMM written detection | 0.0 | −999 |
| # | Feature | Note | ||
|---|---|---|---|---|
| 22 | entropy_sld | Shannon entropy | 2.32 | 3.45 |
| 23 | gram2_med_sld | 2-Gram median of metacharacter frequency | 4.38 | 3.32 |
| 24 | gram3_med_sld | 3-Gram median of metacharacter frequency | 3.17 | 1.56 |
| 25 | gram2_cmed_sld | 2-Gram median of metacharacter frequency | 4.23 | 3.32 |
| 26 | gram3_cmed_sld | 3-Gram median of metacharacter frequency | 3.17 | 1.49 |
| 27 | avg_gram1_rank_sld | 1-Gram average value of metacharacter frequency sorting | 8.2 | 15.56 |
| 28 | avg_gram2_rank_sld | 2-Gram average value of metacharacter frequency sorting | 130.17 | 588.88 |
| 29 | avg_gram3_rank_sld | 3-Gram average value of metacharacter frequency sorting | 1783.4 | 7640.06 |
| 30 | std_gram1_rank_sld | 1-Gram standard deviation of metacharacter frequency sorting | 5.19 | 11.55 |
| 31 | std_gram2_rank_sld | 2-Gram standard deviation of metacharacter frequency sorting | 71.10 | 440.15 |
| 32 | std_gram3_rank_sld | 3-Gram standard deviation of metacharacter frequency sorting | 1062.69 | 8081.53 |
| 33 | gni | Gini value | 0.8 | 0.90 |
| 34 | cer | character classification error | 0.8 | 0.81 |
| xgb = XGBClassifier(silent=True,objective=‘binary:logistic’) |
| nes = [50, 100] |
| depth = [3, 5, 10] |
| child = [2, 4, 6] |
| ga = [2, 0.3, 0.5] |
| colsample = [0.6, 0.8, 1] |
| lr = [0.2, 0.1, 0.01] |
| gird_par = dict(n_estimators = nes, max_depth = depth, min_child_weight = child, gamma = ga, colsample_bytree = colsample, learning_rate=lr) |
| clf = GridSearchCV(xgb, gird parameters, cv=5, n_jobs=-1, scoring=’neg_log_loss’) |
| clf.fit(x_train, y_train) |
| cv_result = pd.DataFrame.from_dict(clf.cv_results_) |
| best_param = clf.best_params |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| n_ estimators | 100 | gamma | 0 |
| max_depth | 10 | colsample_bytree | 0.6 |
| min_child_weight | 2 | learning_rate | 0.2 |
| brf = RandomForestClassifier(random_state=23, n_jobs=-1) |
| nest = [50, 100] |
| crit =[‘gini’, ‘entropy’] |
| feature = [15, 20, 30] |
| gird _par = dict(n_estimators=nest, criterion=crit, max_feature=feature) |
| clf = GridSearchCV(brf, gird parameters,cv=5, n _jobs=-1, scoring=‘neg_log_loss’) |
| clf.fit(x _train, y_train) |
| cv_result = pd.DataFrame.from_dict(clf.cv_results_) |
| best_param = clf.best_params |
| Parameter | Value |
|---|---|
| n_ estimators | 100 |
| max_feature | 15 |
| criterion | entropy |
| model = Sequential() |
| model.add(Embedding(max_features,128, input_length=max_len)) |
| mode1.add(LSTM(128)) |
| model.add(Dropout(0.5)) |
| mode1.add(Dense(1)) |
| model.add(Activation(‘sigmoid’)) |
| model.compile(loss=‘binary_crossentropy’, optimizer=‘adam’) |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| bacth_ size | 128 | epoch | 10 |
| max_feature | 40 | dropout | 0.5 |
| max_len | 60 | learning_rate | 0.001 |
| optimizer | adam |
| def getconvmodel(self, kernel_size, filters): |
| model = Sequential() |
| model.add(Conv1D(filters=filters, input_shape=(128,128), kernel_size=kernel_size, |
| padding=‘same’, activation=‘relu’, strides=1)) |
| model.add(Lambda(lambda x: k.sum(x, axis=1), output_shape=(filters,))) |
| model.add(Dropout(0.5)) |
| return model |
| main_input = Input(shape=(self.max_len,), dtype=‘int32’) |
| embedding = Embedding(input_dim=self.max_features, output_dim=128, |
| input_length=self.max_len)(main_input) |
| conv1 = self.getconvmodel(2,256)(embedding) |
| conv2 = self.getconvmodel(3,256)(embedding) |
| conv3 = self.getconvmodel(4,256)(embedding) |
| conv4 = self.getconvmodel(5,256)(embedding) |
| merged = Concatenate()([conv1, conv2, conv3, conv4]) |
| middle = Dense(1024, activation=‘relu’)(merged) |
| middle = Dropout(0.5)(middle) |
| middle= Dense(1024, activation=‘relu’)(middle) |
| middle = Dropout(0.5)(middle) |
| output = Dense(1, activation=‘sigmoid’)(middle) |
| model = Model(inputs=main_input, outputs=output) |
| model.compile(loss=‘binary_crossentropy’, optimizer=’adam’) |
| return model |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| bacth_ size | 128 | epoch | 10 |
| max_feature | 40 | dropout | 0.5 |
| max_len | 60 | learning_rate | 0.001 |
| optimizer | adam |
| CPU | 4 cores |
| Memory | 8G |
| Operating system | Ubuntu 16.04 64 bit |
| Python version | 3.6 |
| Python library version | tensorflow2.2.0, keras2.4.3 |
| Dataset | Data Size |
|---|---|
| C_DGA | 15,713,816 |
| Tranco_K26W-1m | 1,000,000 |
| DGA Domain Name Sample | Benign Sample |
|---|---|
| q4z1an1ca8icv1cl501sukun.biz | google.com |
| geb3jnercfn28qeq.org | facebook.com |
| 1ihowds1u8fcu8kzuy549uytaj.com | windowsupdate.com |
| hpgkofoukqshvmt.info | yahoo.com |
| Positive | Negative | |
|---|---|---|
| True | TP (true positive) | TN (true negative) |
| False | FP (false positive) | FN (false negative) |
| Dataset | Data Size |
|---|---|
| Training set | 1,419,148 |
| Testing set | 354,788 |
| Total | 1,773,936 |
| Model Name | ACC | Precision | Recall | F1 | |
|---|---|---|---|---|---|
| 1 | B-RF | 0.97551 | 0.96976 | 0.98063 | 0.97516 |
| 2 | XGBoost | 0.97554 | 0.96982 | 0.98062 | 0.97518 |
| 3 | LSTM | 0.97480 | 0.97066 | 0.979193 | 0.97490 |
| 4 | CNN | 0.96944 | 0.95212 | 0.98859 | 0.97001 |
| 5 | B-RF + XGBoost | 0.97498 | 0.97500 | 0.97496 | 0.97498 |
| 6 | LSTM + CNN | 0.97554 | 0.97613 | 0.97404 | 0.97833 |
| 7 | B-RF + XGBoost + LSTM | 0.97771 | 0.97498 | 0.98059 | 0.97778 |
| 8 | B-RF + XGBoost + CNN | 0.97768 | 0.97472 | 0.98081 | 0.97775 |
| 9 | B-RF + LSTM + CNN | 0.97791 | 0.97562 | 0.98032 | 0.97796 |
| 10 | XGBoost + LSTM + CNN | 0.97554 | 0.97661 | 0.97851 | 0.97756 |
| 11 | XGBoost + B-RF + LSTM + CNN | 0.97908 | 0.97712 | 0.98113 | 0.97912 |
| DGA Family | Number | B-RF | XGBoost | LSTM | CNN | Ours |
|---|---|---|---|---|---|---|
| bamital | 104 | 0.98076 | 0.94230 | 1.00000 | 1.00000 | 1.00000 |
| conficker | 497 | 0.73440 | 0.74849 | 0.75653 | 0.72434 | 0.77464 |
| cryptolocker | 1000 | 0.98700 | 0.98700 | 0.99100 | 0.98600 | 0.99400 |
| dyre | 1000 | 1.00000 | 1.00000 | 1.00000 | 0.99700 | 1.00000 |
| emotet | 446,590 | 0.99153 | 0.99074 | 0.99527 | 0.99521 | 0.99543 |
| feodo | 263 | 1.00000 | 0.99661 | 1.00000 | 1.00000 | 1.00000 |
| fobber-v1 | 299 | 1.00000 | 1.00000 | 1.00000 | 1.00000 | 1.00000 |
| gameover | 12,000 | 1.00000 | 1.00000 | 0.99983 | 0.99981 | 1.00000 |
| necurs | 8188 | 0.94589 | 0.94687 | 0.95994 | 0.95346 | 0.96433 |
| nymaim | 478 | 0.82383 | 0.82642 | 0.82642 | 0.78497 | 0.86139 |
| padcrypt | 168 | 0.97619 | 0.97619 | 0.97023 | 0.96428 | 0.98809 |
| pykspa-v1 | 44,702 | 0.89168 | 0.89224 | 0.96470 | 0.96085 | 0.96492 |
| pykspa-v2-fake | 800 | 0.86875 | 0.88250 | 0.84750 | 0.84000 | 0.89375 |
| pykspa-v2-real | 198 | 0.69697 | 0.83333 | 0.86868 | 0.84848 | 0.87878 |
| ranbyus | 10,920 | 0.99340 | 0.99322 | 0.99505 | 0.99587 | 0.99688 |
| rovnix | 179,991 | 0.98386 | 0.88268 | 0.99660 | 0.99745 | 0.99860 |
| virut | 9740 | 0.74589 | 0.76324 | 0.75657 | 0.71899 | 0.78839 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nie, Y.; Liu, S.; Qian, C.; Deng, C.; Li, X.; Wang, Z.; Kuang, X. Multimodel Collaboration to Combat Malicious Domain Fluxing. Electronics 2023, 12, 4121. https://doi.org/10.3390/electronics12194121
Nie Y, Liu S, Qian C, Deng C, Li X, Wang Z, Kuang X. Multimodel Collaboration to Combat Malicious Domain Fluxing. Electronics. 2023; 12(19):4121. https://doi.org/10.3390/electronics12194121
Chicago/Turabian StyleNie, Yuanping, Shuangshuang Liu, Cheng Qian, Congyi Deng, Xiang Li, Zhi Wang, and Xiaohui Kuang. 2023. "Multimodel Collaboration to Combat Malicious Domain Fluxing" Electronics 12, no. 19: 4121. https://doi.org/10.3390/electronics12194121
APA StyleNie, Y., Liu, S., Qian, C., Deng, C., Li, X., Wang, Z., & Kuang, X. (2023). Multimodel Collaboration to Combat Malicious Domain Fluxing. Electronics, 12(19), 4121. https://doi.org/10.3390/electronics12194121