
MASA: Multi-Application Scheduling Algorithm for Heterogeneous Resource Platform

Abstract
:1. Introduction
- Designing a DRL-based multi-application scheduling algorithm-MASA, which consists of two parts: a neural network scheduler (NN-Scheduler) and a Heuristic scheduler, to solve heterogeneous resource management in a dynamic environment.
- Adopting a self-attention mechanism [10] in NN-Scheduler to realize feature vector extraction for multiple applications, and a hybrid allocation algorithm DEFT in Heuristic scheduler to reduce the idle time of PE and improve the actual performance of scheduling.
- Proposing optimizing methods for network training with respect to the practical problems of terminal heterogeneous resources. The Reward Dynamic Alignment (RDA) method is proposed to obtain the correct empirical data, initial episodes early termination method and asynchronous multi-agents joint training method to improve the speed and utility of network training.
2. Related Work
3. A Multi-Application Scheduling Formal Definition
3.1. Scheduling Scenario Description
3.2. Optimization Objective
| Algorithm 1. Flowchart of Heterogeneous Resource Simulation Environment |
|
4. Multi-Application Scheduling Algorithm (MASA) Based on DRL
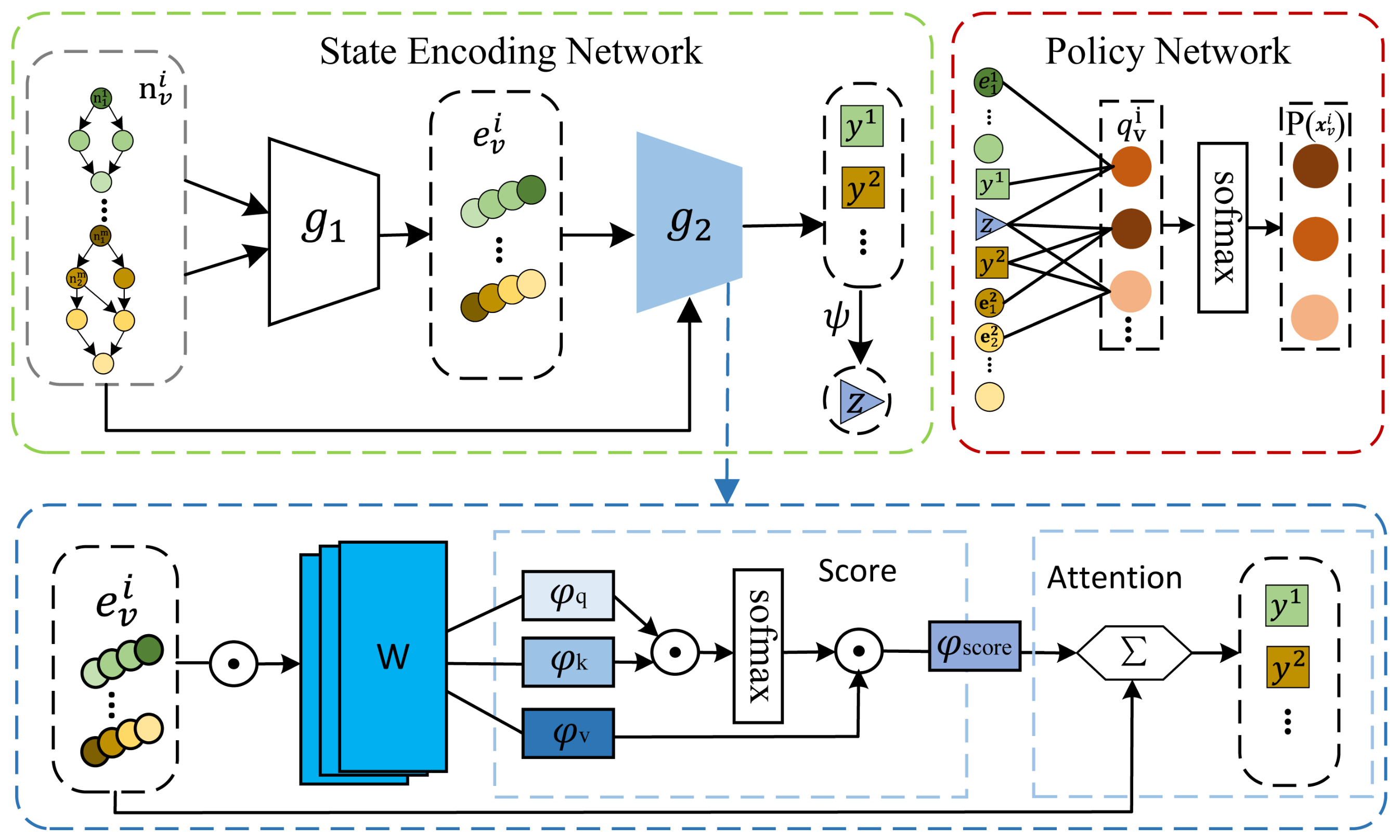
4.1. Framework of MASA
4.1.1. NN-Scheduler
- State encoding network
- 2.
- Policy network for task prioritization
4.1.2. Heuristic Scheduler
4.1.3. Description of the Empirical Data
- 1.
- State space
- 2.
- Action space
- 3.
- Reward
4.2. Network Training
| Algorithm 2. Training Algorithm |
|
4.2.1. Reward Dynamic Alignment Method
- 1.
- incorrect rewards
- 2.
- Implementation of RDA
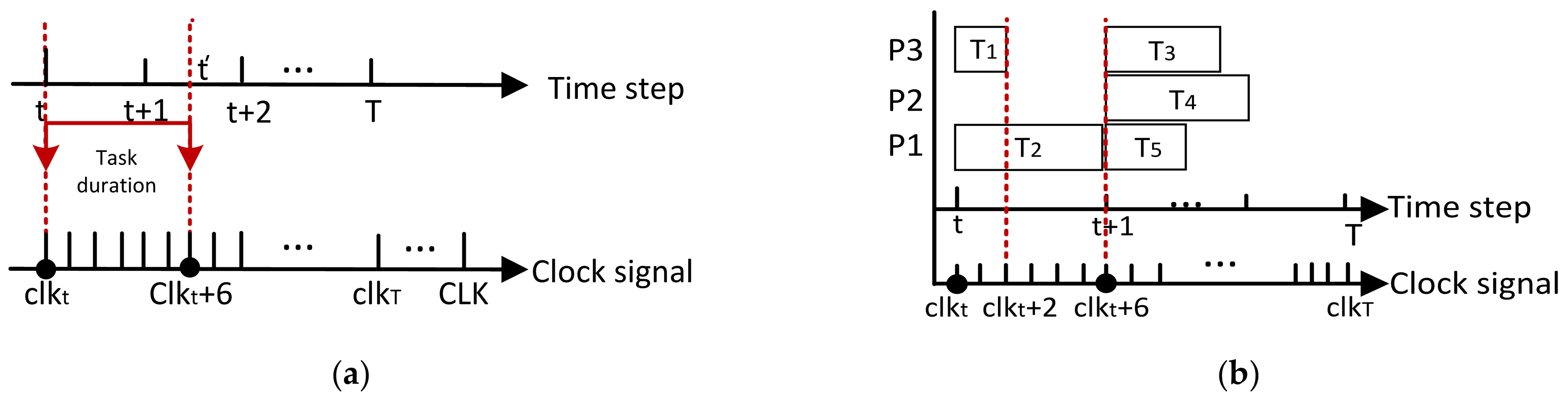
- Step 1: Decouple the empirical data associated with the time step to obtain the sequence as well as . T is the last interaction time step in the episodes. To obtain the sequences and , compute the on each clock signal and perform the computation independently of the interaction timestep. Here, CLK refers to the clock length of the simulation.
- Step 2: At the beginning of the action, memorize the clock signal , and at the end, memorize the clock signal . Use Equation (19) to calculate .
4.2.2. Early Termination of the Initial Episode Method
4.2.3. Asynchronous Multi-Agent Joint Training Method
5. Experiments
5.1. Experimental Environment Setting
5.2. Algorithm Performance Analysis
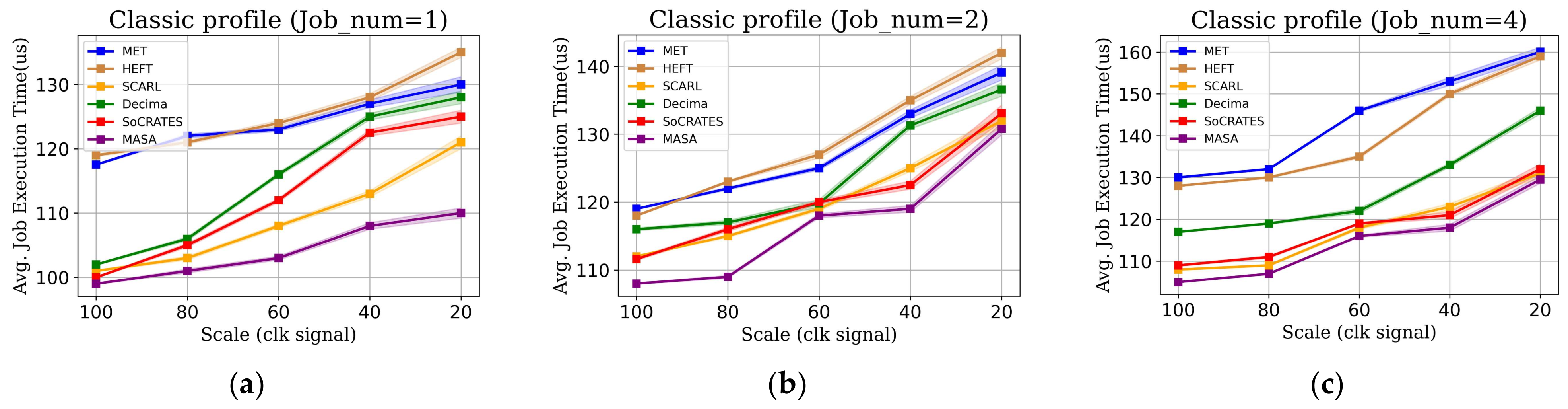
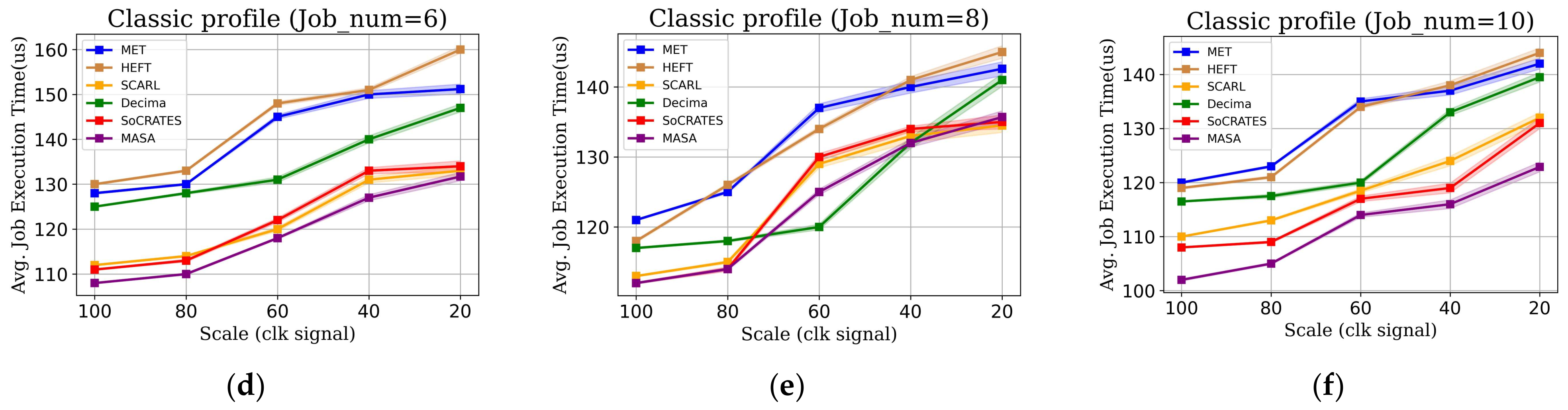

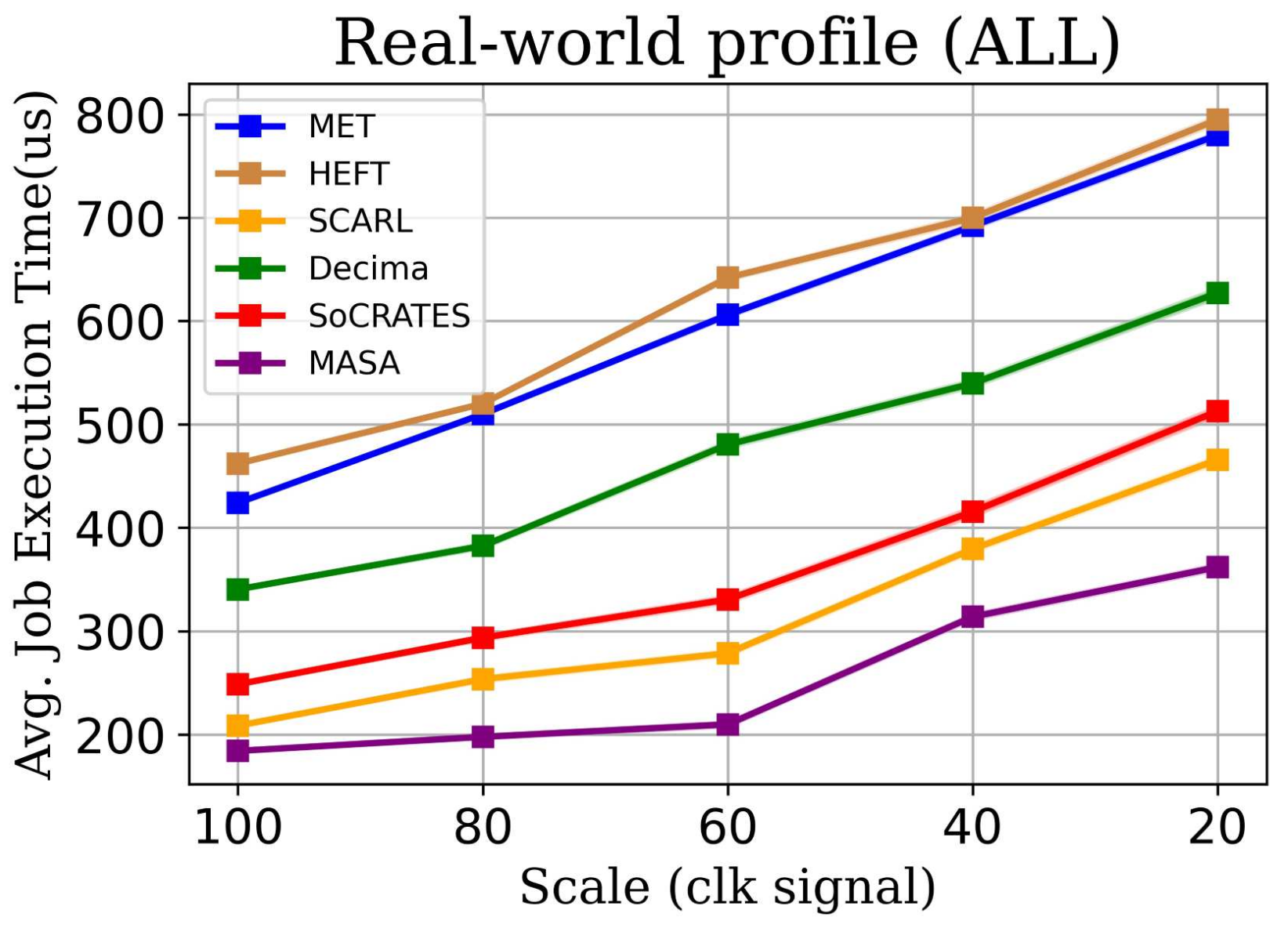
5.2.1. MASA in Classic DAG Environment
5.2.2. MASA in Real-World Environment
5.3. Ablation Experiment
5.3.1. Reward Dynamic Alignment Analysis
5.3.2. Asynchronous Multi-Agent Joint Training Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Venkataramani, A.; Chiriyath, A.R.; Dutta, A.; Herschfelt, A.; Bliss, D.W. The DASH SoC: Enabling the Next Generation of Multi-Function RF Systems. In Proceedings of the 2022 56th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 31 October–2 November 2022; pp. 905–912. [Google Scholar]
- Krishnakumar, A.; Ogras, U.; Marculescu, R.; Kishinevsky, M.; Mudge, T. Domain-Specific Architectures: Research Problems and Promising Approaches. ACM Trans. Embed. Comput. Syst. 2023, 22, 1–26. [Google Scholar] [CrossRef]
- Xie, G.; Zeng, G.; Li, Z.; Li, R.; Li, K. Adaptive dynamic scheduling on multifunctional mixed-criticality automotive cyber-physical systems. IEEE Trans. Veh. Technol. 2017, 66, 6676–6692. [Google Scholar] [CrossRef]
- Amarnath, A.; Pal, S.; Kassa, H.; Vega, A.; Buyuktosunoglu, A.; Franke, H.; Wellman, J.; Dreslinski, R.; Bose, P. HetSched: Quality-of-Mission Aware Scheduling for Autonomous Vehicle SoCs. arXiv 2022, arXiv:2203.13396. [Google Scholar]
- Mao, H.; Alizadeh, M.; Menache, I.; Kandula, S. Resource management with deep reinforcement learning. In Proceedings of the 15th ACM Workshop on Hot topics in Networks, Atlanta, GA, USA, 9–10 November 2016; pp. 50–56. [Google Scholar]
- Deng, S.; Zhao, H.; Xiang, Z.; Zhang, C.; Jiang, R.; Li, Y.; Yin, J.; Dustdar, S.; Zomaya, A.Y. Dependent function embedding for distributed serverless edge computing. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 2346–2357. [Google Scholar] [CrossRef]
- Wang, C.; Li, R.; Wang, X.; Taleb, T.; Guo, S.; Sun, Y.; Leung, V.C. Heterogeneous Edge Caching Based on Actor-Critic Learning With Attention Mechanism Aiding. IEEE Trans. Netw. Sci. Eng. 2023. [Google Scholar] [CrossRef]
- Chai, F.; Zhang, Q.; Yao, H.; Xin, X.; Gao, R.; Guizani, M. Joint Multi-task Offloading and Resource Allocation for Mobile Edge Computing Systems in Satellite IoT. IEEE Trans. Veh. Technol. 2023. [Google Scholar] [CrossRef]
- Liu, Z.; Huang, L.; Gao, Z.; Luo, M.; Hosseinalipour, S.; Dai, H. GA-DRL: Graph Neural Network-Augmented Deep Reinforcement Learning for DAG Task Scheduling over Dynamic Vehicular Clouds. arXiv 2023, arXiv:2307.00777. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, A.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Hartmanis, J. Computers and intractability: A guide to the theory of np-completeness (michael r. garey and david s. johnson). Siam Rev. 1982, 24, 90. [Google Scholar] [CrossRef]
- Bénichou, M.; Gauthier, J.; Girodet, P.; Hentges, G.; Ribière, G.; Vincent, O. Experiments in mixed-integer linear programming. Math. Program. 1971, 1, 76–94. [Google Scholar] [CrossRef]
- Lambora, A.; Gupta, K.; Chopra, K. Genetic algorithm-A literature review. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; pp. 380–384. [Google Scholar]
- Hassan, R.; Cohanim, B.; De Weck, O.; Venter, G. A comparison of particle swarm optimization and the genetic algorithm. In Proceedings of the 46th AIAA/ASME/ASCE/AHS/ASC Structures, Structural Dynamics and Materials Conference, Austin, TX, USA, 18–21 April 2005; p. 1897. [Google Scholar]
- Xie, Y.; Gui, F.; Wang, W.; Chien, C. A two-stage multi-population genetic algorithm with heuristics for workflow scheduling in heterogeneous distributed computing environments. IEEE Trans. Cloud Comput. 2021, 11, 1446–1460. [Google Scholar] [CrossRef]
- Rathnayake, U. Migrating storms and optimal control of urban sewer networks. Hydrology 2015, 2, 230–241. [Google Scholar] [CrossRef]
- Topcuoglu, H.; Hariri, S.; Wu, M. Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans. Parallel Distrib. Syst. 2002, 13, 260–274. [Google Scholar] [CrossRef]
- Chronaki, K.; Rico, A.; Casas, M.; Moretó, M.; Badia, R.M.; Ayguadé, E.; Labarta, J.; Valero, M. Task scheduling techniques for asymmetric multi-core systems. IEEE Trans. Parallel Distrib. Syst. 2016, 28, 2074–2087. [Google Scholar] [CrossRef]
- Kohútka, L.; Mach, J. A New FPGA-Based Task Scheduler for Real-Time Systems. Electronics 2023, 12, 1870. [Google Scholar] [CrossRef]
- Xie, G.; Peng, H.; Xiao, X.; Liu, Y.; Li, R. Design flow and methodology for dynamic and static energy-constrained scheduling framework in heterogeneous multicore embedded devices. ACM Trans. Des. Autom. Electron. Syst. (TODAES) 2021, 26, 1–18. [Google Scholar] [CrossRef]
- Hu, B.; Yang, X.; Zhao, M. Online energy-efficient scheduling of DAG tasks on heterogeneous embedded platforms. J. Syst. Architect. 2023, 140, 102894. [Google Scholar] [CrossRef]
- Sung, T.T.; Ryu, B. Deep Reinforcement Learning for System-on-Chip: Myths and Realities. IEEE Access 2022, 10, 98048–98064. [Google Scholar] [CrossRef]
- Mao, H.; Schwarzkopf, M.; Venkatakrishnan, S.B.; Meng, Z.; Alizadeh, M. Learning scheduling algorithms for data processing clusters. In Proceedings of the ACM Special Interest Group on Data Communication, Beijing, China, 19–23 August 2019; pp. 270–288. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2014; ISBN 1118625870. [Google Scholar]
- Zhou, Y.; Li, X.; Luo, J.; Yuan, M.; Zeng, J.; Yao, J. Learning to optimize dag scheduling in heterogeneous environment. In Proceedings of the 2022 23rd IEEE International Conference on Mobile Data Management (MDM), Paphos, Cyprus, 6–9 June 2022; pp. 137–146. [Google Scholar]
- Konda, V.; Tsitsiklis, J. Actor-critic algorithms. Adv. Neural Inf. Process. Syst. 1999, 12, 1008–1014. [Google Scholar]
- Sutton, R.S.; Mcallester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 12, 1057–1063. [Google Scholar]
- Arjona-Medina, J.A.; Gillhofer, M.; Widrich, M.; Unterthiner, T.; Brandstetter, J.; Hochreiter, S. Rudder: Return decomposition for delayed rewards. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Xiao, F.; Wang, L. Asynchronous consensus in continuous-time multi-agent systems with switching topology and time-varying delays. IEEE Trans. Autom. Control 2008, 53, 1804–1816. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Arda, S.E.; Krishnakumar, A.; Goksoy, A.A.; Kumbhare, N.; Mack, J.; Sartor, A.L.; Akoglu, A.; Marculescu, R.; Ogras, U.Y. DS3: A system-level domain-specific system-on-chip simulation framework. IEEE Trans. Comput. 2020, 69, 1248–1262. [Google Scholar] [CrossRef]
- Braun, T.D.; Siegel, H.J.; Beck, N.; Bölöni, L.L.; Maheswaran, M.; Reuther, A.I.; Robertson, J.P.; Theys, M.D.; Yao, B.; Hensgen, D. A comparison of eleven static heuristics for mapping a class of independent tasks onto heterogeneous distributed computing systems. J. Parallel Distrib. Comput. 2001, 61, 810–837. [Google Scholar] [CrossRef]
- Cheong, M.; Lee, H.; Yeom, I.; Woo, H. SCARL: Attentive reinforcement learning-based scheduling in a multi-resource heterogeneous cluster. IEEE Access 2019, 7, 153432–153444. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application Type | Application | Number of Tasks | Max Width, Depth |
|---|---|---|---|
| Real-world’ Communication Application | WiFi-TX | 27 | 5, 7 |
| WiFi-RX | 34 | 5, 10 | |
| Single-carrier Tx | 10 | 1, 10 | |
| Single-carrier Rx | 10 | 1, 10 | |
| Real-world’ Radar Application | range detection | 7 | 2, 6 |
| Temporal Mitigation | 10 | 2, 6 | |
| Classic DAG | 10 | random | |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Job queue capacity | 3 | Optimizer | Adam |
| Node input dimensions | 6 | Scale (job inject interval’ expectation) | 20/40/60/80/100 |
| Output dimensions | 8 | CLK (simulation length) | 10,000 |
| Maximum depth | 3 | (episode length’ expectation) | 10,000 |
| Hidden dimensions | [16, 8] | (number of Agent) | 1/2/4/6/8/10 |
| (learning rate) | 0.0001 | (entropy coefficient) | 0.1 |
| (learning rate) | 0.0003 | (discount factor) | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Q.; Wang, S. MASA: Multi-Application Scheduling Algorithm for Heterogeneous Resource Platform. Electronics 2023, 12, 4056. https://doi.org/10.3390/electronics12194056
Peng Q, Wang S. MASA: Multi-Application Scheduling Algorithm for Heterogeneous Resource Platform. Electronics. 2023; 12(19):4056. https://doi.org/10.3390/electronics12194056
Chicago/Turabian StylePeng, Quan, and Shan Wang. 2023. "MASA: Multi-Application Scheduling Algorithm for Heterogeneous Resource Platform" Electronics 12, no. 19: 4056. https://doi.org/10.3390/electronics12194056
APA StylePeng, Q., & Wang, S. (2023). MASA: Multi-Application Scheduling Algorithm for Heterogeneous Resource Platform. Electronics, 12(19), 4056. https://doi.org/10.3390/electronics12194056