



RETRACTED: A Global Structural Hypergraph Convolutional Model for Bundle Recommendation


Abstract
:1. Introduction
- We propose a novel model named the SHCBR, which introduces the hypergraph structure to explicitly model complex relationships between entities in bundle recommendation tasks. We directly connect three types of nodes with a hyperedge without introducing additional nodes and edges. By constructing a relational hypergraph containing three types of nodes, we can explore existing information from a global perspective, effectively alleviating the dilemma of data sparsity.
- We design a special matrix propagation rule and personalized weight operation in the proposed structural hypergraph convolutional neural network (SHCNN). Using items as links, we leverage efficient hypergraph convolution to learn node representations considering the high-order information. Since the relational hypergraph structure naturally incorporates higher-order associations, it is enough to generate node representations with one layer of SHCNN, further enhancing model efficiency;
- Experiments on two real-world datasets indicate that our SHCBR outperforms existing state-of-the-art baselines by 11.07–25.66% on Recall and 16.81–33.53% on NDCG. The experimental results further validate that hypergraphs provide a novel and effective method to tackle bundle recommendation tasks.
2. Related Work
2.1. Bundle Recommendation
2.2. Hypergraph Learning
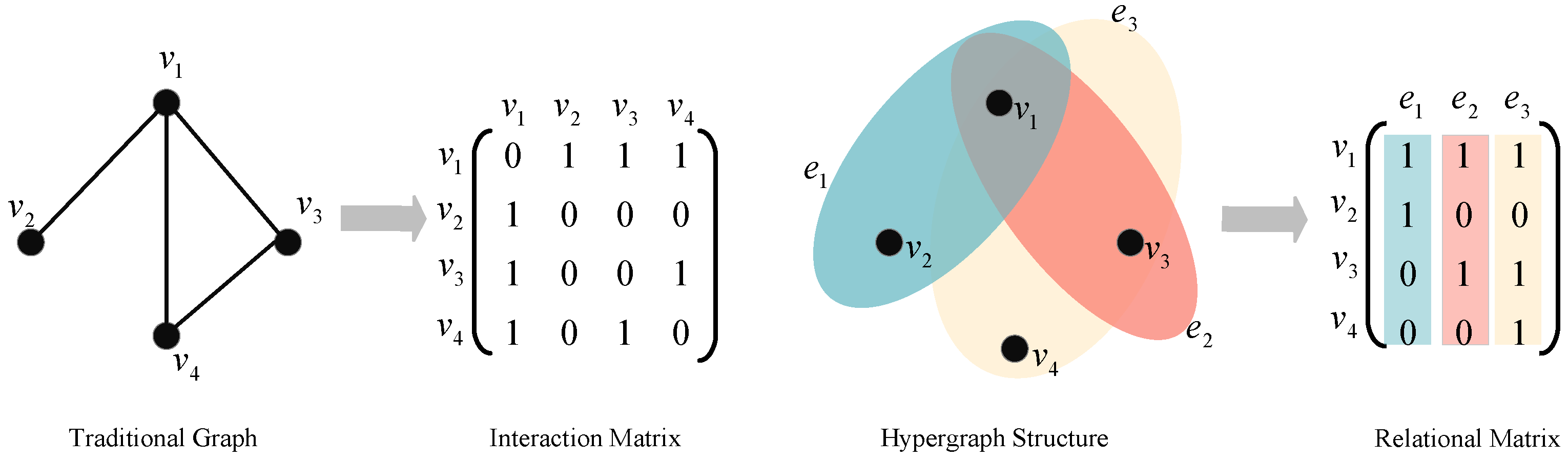
3. Preliminary
3.1. Problem Formulation
3.2. Bundle Hypergraph Definition
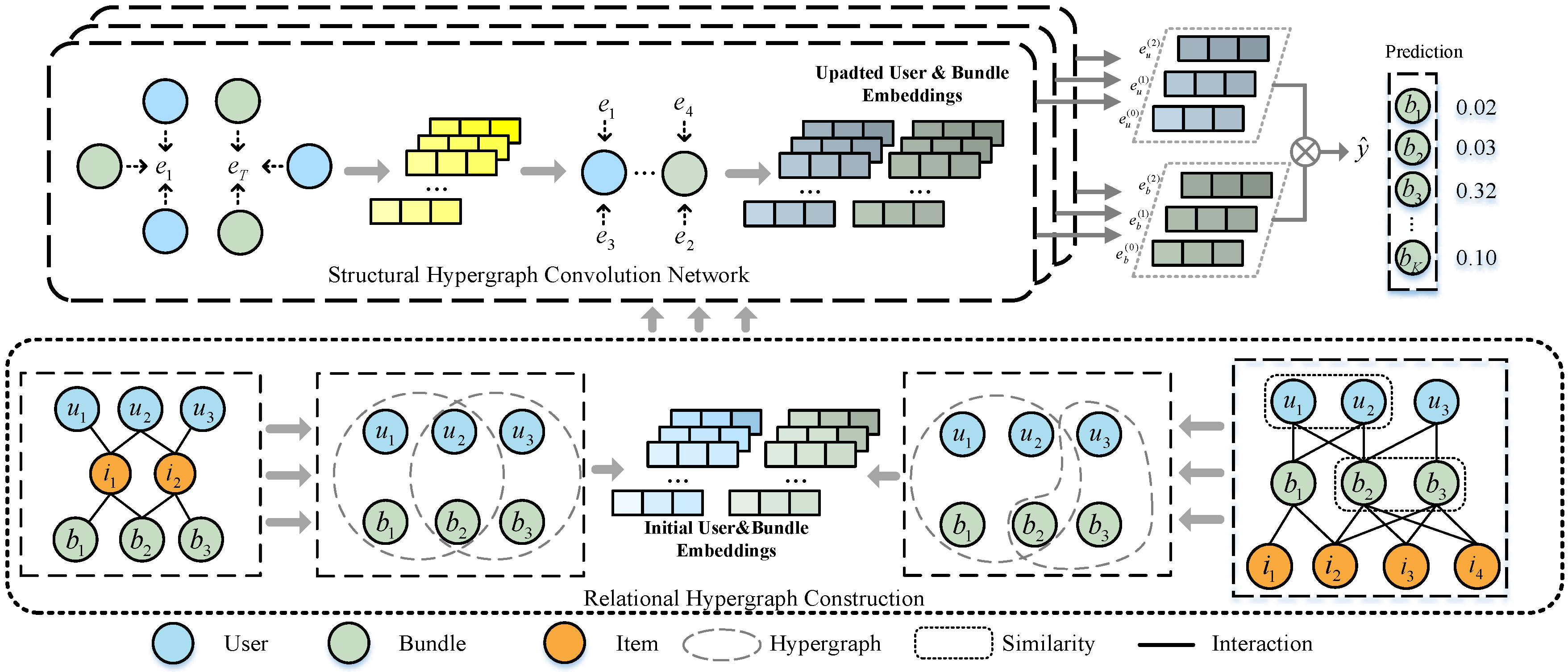
4. Method
4.1. Relational Hypergraph Construction
4.2. Structural Hypergraph Convolutional Neural Networks
4.3. Matrix Propagation Rule
4.4. Model Prediction and Training
5. Experiment
- RQ1: How does our SHCBR compare in performance to previous models?
- RQ2: How do key components influence the SHCBR’s performance?
- RQ3: How do different parameter settings affect the SHCBR’s results?
5.1. Experiment Settings
5.1.1. Datasets and Metrics
- NetEase: This is a dataset constructed using data provided by a Chinese music platform, Netease Cloud Music (http://music.163.com, accessed on 7 August 2017). As a social music software, it allows users to freely choose their favorite songs and add them to their favorites. Users can also choose to listen to playlists bundled with different songs.
- Youshu: This is a dataset constructed by the famous Chinese book review website Youshu (https://www.yousuu.com/, accessed on 7 August 2017). Youshu allows users to create their own booklists with different styles and types. Additionally, it can provide users with a bundle of related books.
5.1.2. Baselines
- MFBPR [24]: This is a popular MF model based on BPR loss optimization, which is widely used for implicit feedback.
- RGCN [50]: RGCN is a method based on graph convolutional networks that is specifically designed to handle multi-relational graphs.
- LightGCN [13]: This is an efficient and lightweight model that incorporates both graph neural networks and collaborative filtering ideas.
- BundleNet [5]: BundleNet constructs a tripartite graph consisting of users, bundles, and items, which utilizes GNN to learn node representation of entities.
- DAM [28]: DAM is a deep learning model that incorporates attention mechanisms to facilitate the acquisition of comprehensive bundle representations.
- BGCN [18]: BGCN leverages the powerful ability of GNN in learning from higher-order connections on graphs, modeling the complex relations between users, items, and bundles.
- MIDGN [19]: MIDGN designed a multi-view intent resolution graph network, using a graph neural network to separate user intent from different perspectives.
5.1.3. Implementation Details and Environment
5.2. Performance Comparison and Analysis
5.3. Ablation Study of SHCBR
- . This model removes the module of the relational hypergraph construction. In this part, we exclude the similarity overlap matrix form the user–bundle adjacency matrix. At the same time, we also eliminate the construction of the structural hypergraph matrix. We discover that SHCBR outperforms significantly , demonstrating the effectiveness of the relational hypergraph construction module. Moreover, the experimental results also highlight the importance of the hypergraph structure in capturing node feature.
- . This model removes the part of the structural hypergraph convolutional neural networks. Here, we replace the structural hypergraph convolutional neural networks with a simple graph convolutional neural network. It is apparent that SHCBR outperforms . This is due to simple graph convolutional neural networks have limited aggregation capabilities compared to hypergraph convolutional neural networks. This demonstrates the superiority of our proposed structural hypergraph convolutional neural networks.
- . This model removes the special matrix propagation rule module but retains other designs of SHCBR. It can be observed that SHCBR is only slightly superior than . Although SHCBR is not highly competitive compared to , we can still see that the special matrix propagation rule is helpful for improving model performance.
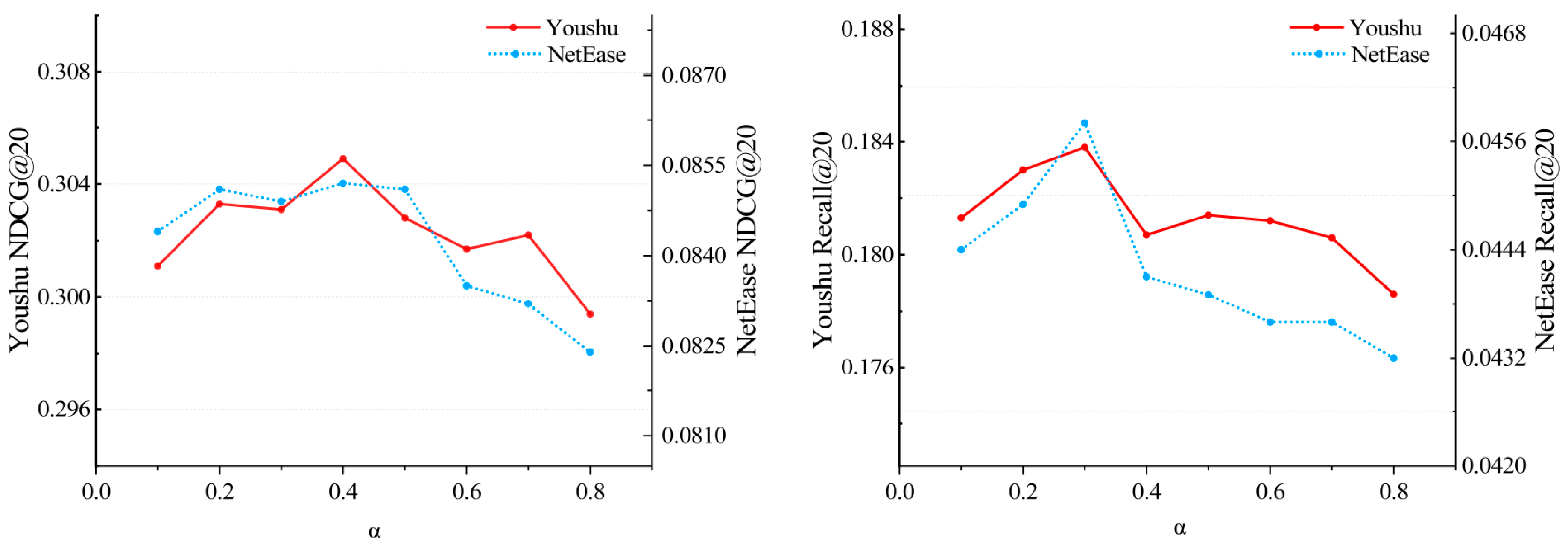
5.4. Hyper-Parameters Analysis
5.5. Experimental Efficiencies
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, S.; Sun, F.; Zhang, W.; Xie, X.; Cui, B. Graph neural networks in recommender systems: A survey. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Covington, P.; Adams, J.; Sargin, E. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar]
- Cao, D.; Nie, L.; He, X.; Wei, X.; Zhu, S.; Chua, T. Embedding factorization models for jointly recommending items and user generated lists. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 585–594. [Google Scholar]
- Pathak, A.; Gupta, K.; Mcauley, J. Generating and personalizing bundle recommendations on steam. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 1073–1076. [Google Scholar]
- Deng, Q.; Wang, K.; Zhao, M.; Zou, Z.; Wu, R.; Tao, J.; Fan, C.; Chen, L. Personalized bundle recommendation in online games. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, 19–23 October 2020; pp. 2381–2388. [Google Scholar]
- Zheng, Z.; Wang, C.; Xu, T.; Shen, D.; Qin, P.; Huai, B.; Liu, T.; Chen, E. Drug package recommendation via interaction-aware graph induction. In Proceedings of the Web Conference, Ljubljana, Slovenia, 19–23 April 2021; pp. 1284–1295. [Google Scholar]
- Zhu, T.; Harrington, P.; Li, J.; Tang, L. Bundle recommendation in ecommerce. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, Australia, 6–11 July 2014; pp. 657–666. [Google Scholar]
- Su, Y.; Zhang, R.; Erfani, S.; Xu, Z. Detecting beneficial feature interactions for recommender systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 4357–4365. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.-S. Neural graph collaborative filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Wu, S.; Tang, Y.; Zhu, Y.; Wang, L.; Xie, X.; Tan, T. Session-based recommendation with graph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 346–353. [Google Scholar]
- Wang, Z.; Wei, W.; Cong, G.; Li, X.-L.; Mao, X.-L.; Qiu, M. Global context enhanced graph neural networks for session-based recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 169–178. [Google Scholar]
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; Yin, D. graph neural networks for social recommendation. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 417–426. [Google Scholar]
- Guo, Z.; Wang, H. A deep graph neural network-based mechanism for social recommendations. IEEE Trans. Ind. Inform. 2020, 17, 2776–2783. [Google Scholar] [CrossRef]
- Chang, J.; Gao, C.; He, X.; Jin, D.; Li, Y. Bundle recommendation and generation with graph neural networks. IEEE Trans. Knowl. Data Eng. 2021, 35, 2326–2340. [Google Scholar] [CrossRef]
- Zhao, S.; Wei, W.; Zou, D.; Mao, X. Multi-view intent disentangle graph networks for bundle recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; pp. 4379–4387. [Google Scholar]
- Bretto, A. Hypergraph theory. In An Introduction. Mathematical Engineering; Springer: Cham, Switzerland, 2013; Volume 1. [Google Scholar]
- Liu, Q.; Ge, Y.; Li, Z.; Chen, E.; Xiong, H. Personalized travel package recommendation. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 407–416. [Google Scholar]
- Xie, M.; Lakshmanan, L.V.; Wood, P.T. Breaking out of the box of recommendations: From items to packages. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 151–158. [Google Scholar]
- Marchetti-Spaccamela, A.; Vercellis, C. Stochastic on-line knapsack problems. Math. Program. 1995, 68, 73–104. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-thieme, L. BPR: Bayesian personalized ranking from implicit feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar]
- Chen, Y.-L.; Tang, K.; Shen, R.-J.; Hu, Y.-H. Market basket analysis in a multiple store environment. Decis. Support Syst. 2005, 40, 339–354. [Google Scholar] [CrossRef]
- Fang, Y.; Xiao, X.; Wang, X.; Lan, H. Customized bundle recommendation by association rules of product categories for online supermarkets. In Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC), Guangzhou, China, 18–21 June 2018; pp. 472–475. [Google Scholar]
- Wibowo, A.T.; Siddharthan, A.; Masthoff, J.; Lin, C. Incorporating constraints into matrix factorization for clothes package recommendation. In Proceedings of the 26th Conference on User Modeling, Adaptation and Personalization, Singapore, 8–11 July 2018; pp. 111–119. [Google Scholar]
- Chen, L.; Liu, Y.; He, X.; Gao, L.; Zheng, Z. Matching user with item set: Collaborative bundle recommendation with deep attention network. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 2095–2101. [Google Scholar]
- Xiong, H.; Liu, Z. A situation information integrated personalized travel package recommendation approach based on TD-LDA model. In Proceedings of the 2015 International Conference on Behavioral, Economic and Socio-Cultural Computing (BESC), Nanjing, China, 30 October–1 November 2015; pp. 32–37. [Google Scholar]
- Kipf, T.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Sun, J.; Wang, N.; Liu, X. IMBR: Interactive Multi-relation Bundle Recommendation with Graph Neural Network. In Proceedings of the International Conference on Wireless Algorithms, Systems, and Applications, Dalian, China, 24–26 November 2022; pp. 460–472. [Google Scholar]
- Liu, Z.; Sun, L.; Weng, C.; Chen, Q.; Huo, C. Gaussian Graph with Prototypical Contrastive Learning in E-Commerce Bundle Recommendation. arXiv 2023, arXiv:2307.13468. [Google Scholar]
- Ma, Y.; He, Y.; Zhang, A.; Wang, X.; Chua, T. CrossCBR: Cross-view contrastive learning for bundle recommendation. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 1233–1241. [Google Scholar]
- Yadati, N.; Nitin, V.; Nimishakavi, M.; Yadav, P.; Louis, A.; Talukdar, P. NHP: Neural hypergraph link prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, 19–23 October 2020; pp. 1705–1714. [Google Scholar]
- Xu, Y.; Zhang, H.; Cheng, K.; Liao, X.; Zhang, Z.; Li, Y. Knowledge graph embedding with entity attributes using hypergraph neural networks. Intell. Data Anal. 2022, 26, 959–975. [Google Scholar] [CrossRef]
- Gao, Y.; Zhang, Z.; Lin, H.; Zhao, X.; Du, S.; Zou, C. Hypergraph learning: Methods and practices. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2548–2566. [Google Scholar] [CrossRef]
- Zhou, D.; Huang, J.; Schölkopf, B. Learning with hypergraphs: Clustering, classification, and embedding. Adv. Neural Inf. Process. Syst. 2006, 19. [Google Scholar]
- Huang, Y.; Liu, Q.; Metaxas, D. Video object segmentation by hypergraph cut. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1738–1745. [Google Scholar]
- Gao, Y.; Wang, M.; Tao, D.; Ji, R.; Dai, Q. 3-D object retrieval and recognition with hypergraph analysis. IEEE Trans. Image Process. 2012, 21, 4290–4303. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Wang, M.; Zha, Z.; Shen, J.; Li, X.; Wu, X. Visual-textual joint relevance learning for tag-based social image search. IEEE Trans. Image Process. 2012, 22, 363–376. [Google Scholar] [CrossRef] [PubMed]
- Feng, Y.; You, H.; Zhang, Z.; Ji, R.; Gao, Y. Hypergraph neural networks. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3558–3565. [Google Scholar]
- Bai, S.; Zhang, F.; Torr, P. Hypergraph convolution and hypergraph attention. Pattern Recognit. 2021, 110, 107637. [Google Scholar] [CrossRef]
- Wang, M.; Liu, X.; Wu, X. Visual classification by ℓ1-hypergraph modeling. IEEE Trans. Knowl. Data Eng. 2015, 27, 2564–2574. [Google Scholar] [CrossRef]
- Yu, Z.; Li, J.; Chen, L.; Zheng, Z. Unifying multi-associations through hypergraph for bundle recommendation. Knowl.-Based Syst. 2022, 255, 109755. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Rosas, F.; Zhu, T. A hypergraph-based framework for personalized recommendations via user preference and dynamics clustering. Expert Syst. Appl. 2022, 204, 117552. [Google Scholar] [CrossRef]
- Peng, D.; Zhang, S. GC–HGNN: A global-context supported hypergraph neural network for enhancing session-based recommendation. Electron. Commer. Res. Appl. 2022, 52, 101129. [Google Scholar] [CrossRef]
- Maas, A.; Hannun, A.; Ng, A. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the International Conference on Machine Learning (ICML 2013), Atlanta, GA, USA, 16–21 June 2013; p. 3. [Google Scholar]
- Clevert, D.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Wang, X.; Liu, X.; Liu, J.; Wu, H. Relational graph neural network with neighbor interactions for bundle recommendation service. In Proceedings of the 2021 IEEE International Conference on Web Services (ICWS), Chicago, IL, USA, 5–10 September 2021; pp. 167–172. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | NetEase | Youshu |
|---|---|---|
| User | 18,528 | 8039 |
| Item | 22,864 | 4771 |
| Bundle | 123,628 | 32,770 |
| User–item | 1,128,065 | 138,515 |
| User–bundle | 302,303 | 51,337 |
| Bundle–item | 1,778,065 | 176,667 |
| Avg. bundle interactions | 16.32 | 6.39 |
| Avg. item interactions | 60.88 | 17.23 |
| Avg. bundle size | 77.80 | 37.03 |
| User–item density | 0.05% | 0.05% |
| User–bundle density | 0.07% | 0.13% |
| Method | NetEase | Youshu | ||||||
|---|---|---|---|---|---|---|---|---|
| Recall @20 | NDCG @20 | Recall @40 | NDCG @40 | Recall @20 | NDCG @20 | Recall @40 | NDCG @40 | |
| MFBPR | 0.0355 | 0.0181 | 0.0600 | 0.0246 | 0.1959 | 0.1117 | 0.2735 | 0.1320 |
| RGCN | 0.0407 | 0.0210 | 0.0670 | 0.0280 | 0.2040 | 0.1069 | 0.3017 | 0.1330 |
| LightGCN | 0.0496 | 0.0254 | 0.0795 | 0.0334 | 0.2286 | 0.1344 | 0.3190 | 0.1592 |
| BundleNet | 0.0391 | 0.0201 | 0.0661 | 0.0271 | 0.1895 | 0.1125 | 0.2675 | 0.1335 |
| DAM | 0.0411 | 0.0210 | 0.0690 | 0.0281 | 0.2082 | 0.1198 | 0.2890 | 0.1418 |
| BGCN | 0.0491 | 0.0258 | 0.0829 | 0.0346 | 0.2347 | 0.1345 | 0.3248 | 0.1593 |
| MIDGN | 0.0678 | 0.0343 | 0.1085 | 0.0451 | 0.2682 | 0.1527 | 0.3712 | 0.1808 |
| Ours | 0.0852 | 0.0458 | 0.1304 | 0.0561 | 0.3049 | 0.1838 | 0.4123 | 0.2112 |
| Imp% | 25.66% | 33.53% | 20.18% | 24.39% | 13.68% | 20.37% | 11.07% | 16.81% |
| Method | NetEase | Youshu | ||
|---|---|---|---|---|
| Recall@20 | NDCG@20 | Recall@20 | NDCG@20 | |
| 0.0801 | 0.0397 | 0.2879 | 0.1743 | |
| 0.0797 | 0.0411 | 0.2838 | 0.1716 | |
| 0.0832 | 0.0441 | 0.2978 | 0.1806 | |
| 0.0852 | 0.0458 | 0.3049 | 0.1838 | |
| Method | Time for Train per Epoch | Time for Test |
|---|---|---|
| BundleNet | 1610 s | 5 s |
| DAM | 1805 s | 5507 s |
| BGCN | 92 s | 3 s |
| MIDGN | — | — |
| SHCBR | 32 s | 3 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Yuan, M. RETRACTED: A Global Structural Hypergraph Convolutional Model for Bundle Recommendation. Electronics 2023, 12, 3952. https://doi.org/10.3390/electronics12183952
Liu X, Yuan M. RETRACTED: A Global Structural Hypergraph Convolutional Model for Bundle Recommendation. Electronics. 2023; 12(18):3952. https://doi.org/10.3390/electronics12183952
Chicago/Turabian StyleLiu, Xingtong, and Man Yuan. 2023. "RETRACTED: A Global Structural Hypergraph Convolutional Model for Bundle Recommendation" Electronics 12, no. 18: 3952. https://doi.org/10.3390/electronics12183952
APA StyleLiu, X., & Yuan, M. (2023). RETRACTED: A Global Structural Hypergraph Convolutional Model for Bundle Recommendation. Electronics, 12(18), 3952. https://doi.org/10.3390/electronics12183952