1. Introduction
In recent years, there have been significant advancements in remote sensing software and hardware technology [
1,
2,
3,
4,
5], leading to its increasing applicability in various industries. Among the different remote sensing techniques, hyperspectral imaging [
6] has gained considerable attention. By combining spatial features with high-resolution spectral data from different objects, it enables the detection of subtle features in ground object spectra. This fine spectral resolution provides abundant information for applications in diverse fields, such as geology, medical diagnosis, vegetation survey, agriculture [
7], environment, military, aerospace, and others.
To effectively utilize the rich information contained in hyperspectral images, a range of techniques have been investigated for hyperspectral data processing, such as decomposition, monitoring, clustering, and classification [
8]. Initially, supervised methods were prevalent in this research domain. For instance, Farid et al. [
9] introduced a hyperspectral image classification method using support vector machines (SVMs) in 2004. However, an SVM is less adept at handling high-dimensional data and encounters difficulties when applied to large-scale training samples. As a result, researchers directed their efforts toward improving spectral sensors based on SVMs [
10].
Yuliya et al. [
11] proposed a novel method for the precise spectral–spatial classification of hyperspectral images at the pixel level. This approach improves classification accuracy by taking into account both spectral and spatial information.
In recent years, the field of image processing has undergone a revolutionary change with the advent of deep learning technologies, particularly the introduction of deep convolutional neural networks (CNNs). This progress has had a significant impact on remote sensing image processing technology, ushering in a new era of deep CNN-based classification techniques. Xiaorui Ma et al. [
12] proposed an improved network, called the spatial update depth automatic encoder (SDAE), for extracting and utilizing deep features from hyperspectral images. While this method can generate high-quality spatial and spectral features without requiring manual code definitions, it lacks automation in its network parameters.
Subsequently, deep convolutional neural network (CNN) models [
13] have been developed for hyperspectral image classification, utilizing multiple convolutional and pooling layers to extract nonlinear, discriminative, and invariant deep features from HSIs [
14]. In addition to deep CNN models, other deep learning architectures, such as recursive neural networks [
15,
16], deep belief networks [
17], generative adversarial networks [
18,
19], and capsule networks [
20], have demonstrated promising results in hyperspectral image classification.
The CNN, with its non-contact and high-precision processing capabilities, has become widely utilized in image processing due to its ability to eliminate the need for manual image preprocessing and complex feature extraction operations. In hyperspectral image (HSI) processing, there are three main methods: the CNN spatial extractor, CNN spectral extractor, and CNN spectral–spatial extractor. Hu et al. [
21] proposed an architecture for classifying the spectral domain of hyperspectral images, consisting of an input layer, a convolution layer, a maximum pooling layer, a fully connected layer, and an output layer. Because hyperspectral data are typically 3D, 3D CNNs are employed to extract both the spectral and spatial features from these images. Li et al. [
22] presented a 3D CNN framework for accurate HSI classification, effectively extracting combined spectral and spatial features without the need for pre- or postprocessing steps. Roy S. K. et al. [
23] introduced a mixed-spectrum CNN approach for HSI classification, employing a 3D CNN to extract spatial–spectral features from spectral bands and then using a 2D CNN to capture more abstract spatial information.
HSI data are characterized by a combination of 2D spatial and 1D spectral information, which is distinct from 3D target images. To address this difference, He et al. [
24] proposed a multiscale 3D deep convolutional neural network that can simultaneously learn 2D multiscale spatial features and 1D spectral features from HSI data in an end-to-end fashion. The effectiveness of this method has been demonstrated through its good classification results on publicly available HSI datasets.
A CNN [
25] possesses powerful feature extraction capabilities and can be seen as a type of multilayer perceptron (MLP) [
26]. It takes advantage of local connections and weight sharing to reduce the number of parameters and overall model complexity. When applied to image data, its benefits become even more prominent. A CNN is able to autonomously extract two-dimensional image features, including the color, texture, shape, and image topology, making it widely used for extracting informative features from images. There are numerous well-established frameworks available for a CNN, each tailored to different tasks. Selecting an appropriate framework for classification tasks is of utmost importance. Furthermore, a CNN predominantly performs feature extraction through convolutional kernel operations, and the size of the convolutional kernel also affects the network’s ability to effectively extract features.
Despite the impressive performance of the CNN model in HSI classification, it is not without limitations. First and foremost, the model may overlook important input information, and the 3D features it extracts tend to mix both spatial and spectral information. While 2D feature extraction mainly captures abstract spatial information, it may not be able to effectively process spectral information. A CNN is a vector-based method that treats inputs as a set of pixel vectors [
27]. In the case of HSIs, which consists of hundreds of spectral bands forming two-dimensional images of ground objects, it possesses a sequential data structure. Therefore, a CNN may encounter difficulties in processing hyperspectral pixel vectors, resulting in information loss [
28]. In addition, HSIs typically comprise hundreds of bands, making it challenging for the CNN model to capture the sequential correlation between distant bands.
By employing STN [
29] to obtain the optimal inputs for CNN-based HSI classification, DropBlock is introduced as a regularization technique for the precise classification of HSIs. An expandable subspace clustering method [
30] integrates the learning of concise dictionaries and robust subspace representation, while introducing adaptive spatial regularization to enhance model robustness. Additionally, an efficient solver based on an alternating direction method of multipliers (ADMM) is presented to alleviate the computational complexity of the resulting optimization problem. Experimental results demonstrate that this method exhibits good performance and effectiveness in high-dimensional spectral image clustering. Weisheng Dong [
31] achieved denoising of hyperspectral images by modifying the 3D U-net to encode rich multiscale information. Moreover, by decomposing the 3D filtering into 2D spatial filtering and 1D spectral filtering, a significant reduction in the number of network parameters is achieved, thereby lowering the computational complexity.
The year 2017 witnessed the introduction of the Transformer network to the field of natural language processing. This model revolutionized the field by relying solely on the attention mechanism [
32], which effectively captures global dependencies from input sequences. In 2021, the ViT model [
33] was proposed, marking the first successful application of the transformer architecture in computer vision tasks. However, a significant challenge in this context is the conversion of image pixels into sequence data while mitigating issues of excessive complexity, computational load, and high dimensionality.
In 2021, He et al. introduced an improved transformer model called Dense-Transformer, which incorporates dense connections to capture spectral relationships in sequences and utilizes a multilayer perceptron for classification tasks [
34]. The Dense-Transformer addresses the issue of vanishing gradients commonly encountered during the training of traditional transformer networks.
Le et al. proposed the spectral–spatial feature tokenization converter (SSFTT) method, which focuses on capturing spectral–spatial features and high-level semantic features [
35]. They constructed a spectral–spatial feature extraction module to obtain low-level features and introduced a Gaussian-weighted feature marker for feature transformation. The transformed features were then fed into the converter encoder module for learning and representation. However, the SSFTT’s spectral–spatial classifier relies on 2D and 3D convolutional kernels for feature extraction. Given that hyperspectral data encompass both spectral and spatial information, using a single convolutional kernel for extracting features can result in the loss of spectral dimension feature information.
Therefore, in this paper, we propose a novel hyperspectral classification framework called transposed CNN-transformer feature extraction. This framework combines multiscale convolution and feature labeling techniques. Additionally, we introduce a cross-sinusoidal attention mechanism and a transposed convolution pair to facilitate the rapid and accurate propagation of the feature information within the network. By integrating these components with a multiscale CNN and feature labeling, we achieve an improved classification performance even when faced with limited training samples.
In order to further extract deep spectral–spatial information and reduce the loss of important spectral–spatial features, as well as achieve higher classification accuracy on small training datasets, this paper makes the following main contributions:
(1) In this paper, we propose the spectral Inception module for extracting hyperspectral imaging spectral sequences. This module employs multiscale 3D convolution kernels to preserve the spectral–spatial information of different feature scales. By performing dimensionality reduction and data enhancement, our approach effectively captures both local and global spectral features.
(2) We propose a spatial transposed Inception module to extract HSI spatial information by utilizing multiscale 2D convolution kernels and connecting the output of the transposed convolutional layer with the initial input to enhance the feature information and facilitate the transmission and reconstruction of spectral–spatial information within the network.
(3) We propose a multi-head cross-sinusoidal threshold attention mechanism that combines convolution kernel spectra and spatial patch tokens, using sine functions to limit the dot product size of Q, K, and V. This ensures that the attention output values fall within the effective range of the activation function due to the periodicity of sine.
2. Multiscale Transposed CNN-Transformer Feature Extraction
The MSSTT framework, proposed in this paper, is depicted in
Figure 1 below. It consists of three modules: spectral–spatial information enhancement and extraction using Inception, spatial information enhancement and transmission through transposed Inception, and location-coded feature labeling and cross-sinusoidal limit attention for transformer feature classification.
The first step in our approach involves information extraction. Initially, we employ the 3D Inception module to extract the spectral–spatial information, followed by the utilization of the transposed 2D Inception module to extract the spatial information. The second step focuses on feature position coding. The flattened feature information is marked using standard normal functions. The position information is then marked twice using sine and cosine pairs. These marked sequences are subsequently input into the transformer for feature extraction. In the third step, an improved attention mechanism is employed to determine the relationship between the sequence and spatial features. This enhanced attention mechanism helps capture significant feature dependencies within the data. Finally, we obtain the classification results based on the spatial–spectral characteristics obtained from the previous steps.
2.1. Inception-Based Spectral–Spatial Information Enhancement Extraction
The original hyperspectral data are represented by , where s denotes the number of bands in the spectrum. In this study, PCA is employed to reduce the HSI bands from s to b. Following the removal of the background pixels, the 3D Inception module is applied to enhance and extract the spectral–spatial information.
The strong correlation between spectral bands often leads to redundant information. Although dimensionality reduction can improve computational efficiency, it may also result in some loss of information. To address this issue, we design three convolutional kernels to enhance the preserved main component data and maximize the utilization of the retained spectral–spatial information. The process is illustrated below:
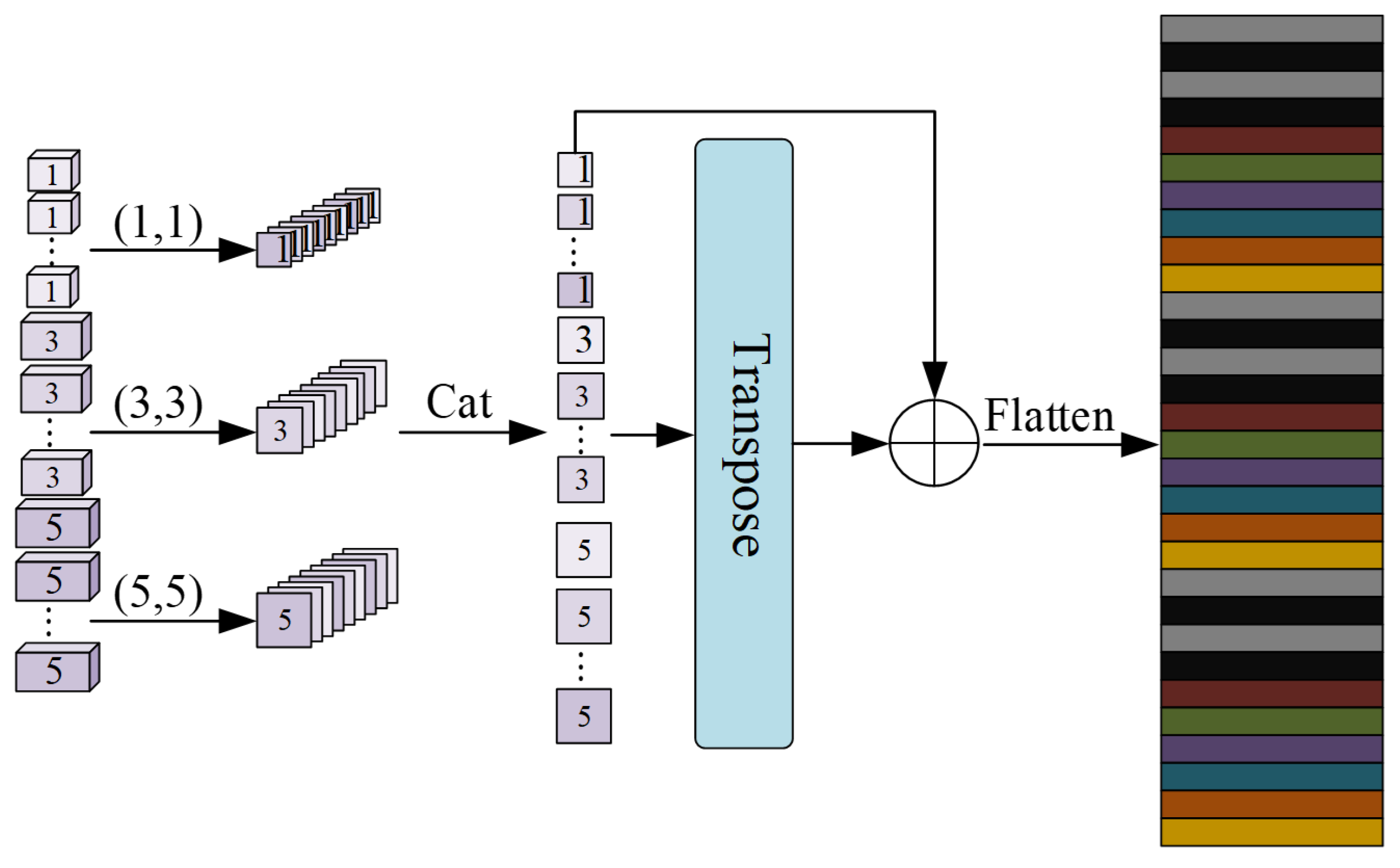
We have designed three 3D convolution kernels [
36] with different sizes to extract the spectral–spatial information: (1, 1, 1), (3, 3, 3), and (5, 5, 5). When using a 1-sized convolution kernel, the padding is set to 0. For a 3-sized convolution kernel, the padding is set to 1, and for a 5-sized convolution kernel, the padding is set to 2. These convolution kernels are then applied to extract features from the preprocessed dataset, denoted as
. Afterward, the 3D feature sequences obtained from each of the three convolution kernels are concatenated. This operation enhances the preserved components and incorporates the sequence information of varying sizes, thereby increasing the richness of the features. The expanded multiscale feature information is subsequently fed into the spatial feature extraction layer.
2.2. Spatial Transpose Inception Module
To optimize the extraction and enrichment of HSI spatial features, we design three 2D convolution kernels with varying sizes: (1, 1), (5, 5), and (7, 7). For the 1-sized convolution kernel, the padding is set to 0. For the 3-sized convolution kernel, the padding is set to 1, and for the 5-sized convolution kernel, the padding is set to 2.
These three 2D convolution kernels are then applied to the output
from the previous layer to extract the features. The 2D feature sequences obtained from each of the three convolution kernels are concatenated to further enhance the acquired spatial information. This can be expressed mathematically as follows:
To enhance the input feature information in the transformer model, we utilize transpose convolution [
37]. This technique aids in reconstructing and facilitating the transmission of feature information within the network. The output of the transpose convolution is subsequently connected to the 3D Inception module. A visual representation of this connection is illustrated in
Figure 2 below.
The 3D Inception module generates eight feature cubes per layer, each with dimensions of , resulting in an overall size of . To align the dimensions, these cubes are stitched together in the fourth dimension, resulting in a size of . However, the desired output dimension for the two-dimensional Inception module is three dimensional. To accommodate this, the sequence obtained after the stitching process is adjusted to (240, 13, 39). Each layer of the 2D Inception module generates 64 feature patches with dimensions of , resulting in a size of . These patches are then concatenated in the second dimension, resulting in a final size of .
We maintain the feature dimensions as after applying the transpose convolution, and we ensure that the dimensions remain unchanged by connecting the transpose output with the first 2D convolution output. Finally, feature labeling is accomplished by flattening the feature sequence acquired from the transposed 2D Inception output.
2.3. Positional Embedding
To comprehensively describe the features of ground objects, we semantically label the features extracted by the Inception module. Given a feature map X, we can obtain the corresponding semantic label T by using the following formula:
where
;
is a transposed function;
,
represent a weight matrix initialized with a normal distribution;
and
are dotted to map features
to the semantic group; and
and
are dotted to the semantic group.
Geographic information is arranged in spectral order. The location and order are very important. Similarly, the position and order of the features extracted by the Inception module are also very important.
In the formula, pos represents the location and i represents a dimension. Each dimension of position coding corresponds to a sinusoidal curve. While the relative position calculated using sine and cosine is linear, the relative position direction may be lost. To address this, we employ a coding mechanism that utilizes sine and cosine functions to record the relative position between feature semantics. This encoding mechanism helps capture the spatial relationships between different features.
2.4. HSI Multi-Heads Cross-Sin Attention
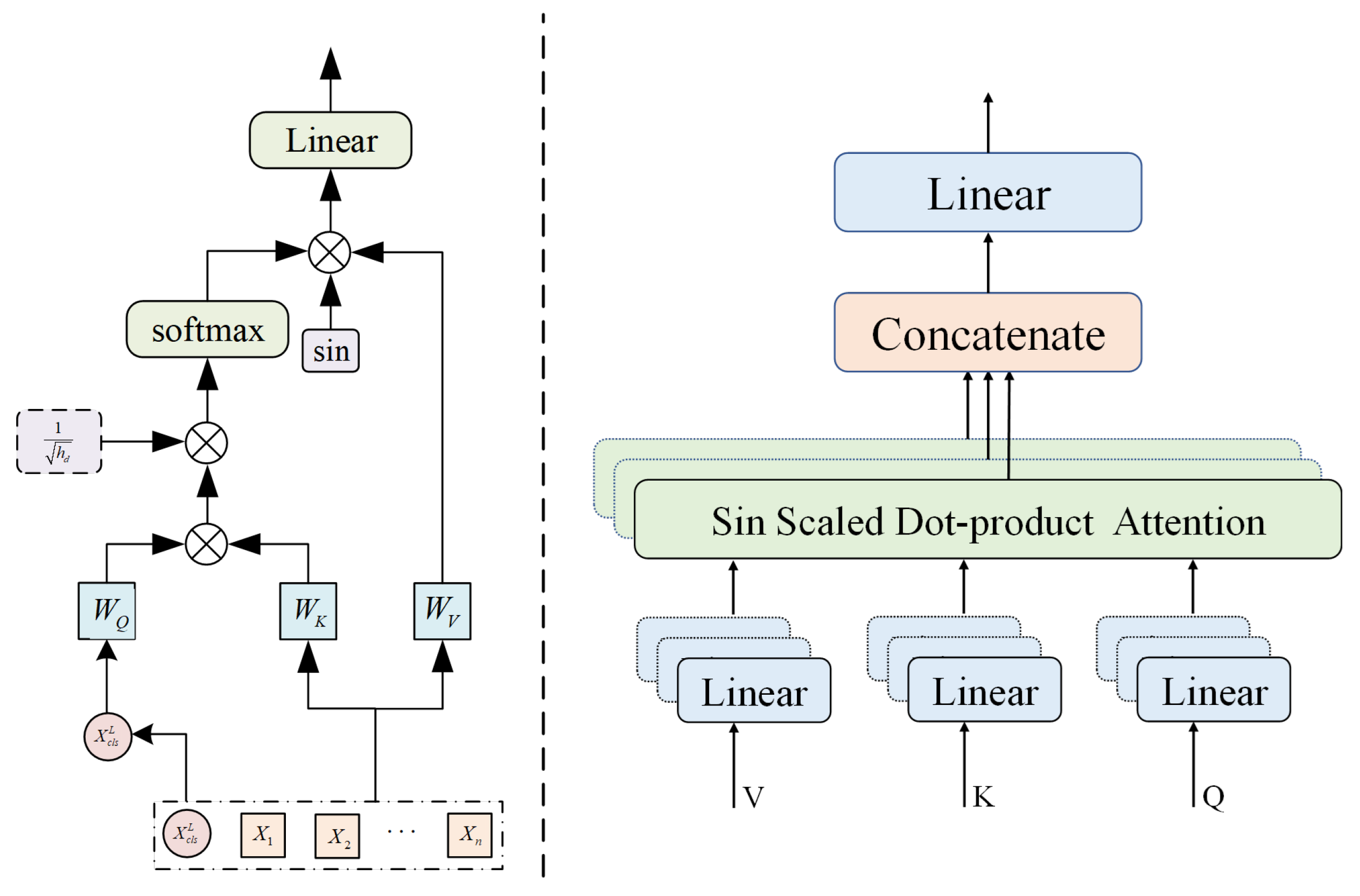
The tokens have a crucial role in learning the abstract representation of the entire HSI patch by exchanging information among themselves. This process takes place within the transformer architecture. The encoded tokens are input into the transformer encoder, which consists of six stacked layers. Each layer comprises two sub-layers.
After normalization, the
tokens are passed through the attention layer. In this layer, the key and value components form a source. By comparing the query with each key, the similarity between them is calculated to determine the weight coefficient of the corresponding value for each key. The weighted sum of the values is then computed to obtain the final attention score. The specific implementation of this process is as follows:
The variables
Q,
K, and
V correspond to query, key, and value, respectively. To prevent the dot product of
Q,
K, and
V from becoming too large, the softmax function is shifted to the region with a minimal gradient. In this design, a sine function is employed to constrain the dot product of
Q,
K, and
V, as illustrated in the following formula:
The average of a single attention head can suppress information from different positions and representation subspaces. One head is likely to extract features from a limited region. In contrast, multiple heads can simultaneously extract features from a particular region and take averages, which is more effective for extracting important information. Linear projections of
Q,
K, and
V h times allow the model to jointly extract information from different positions and representation subspaces.
Furthermore, multiple sinusoidal attention heads are employed for feature extraction. The attention weights generated by each head are combined by concatenation and then multiplied with their respective weight matrix to yield the ultimate attention coefficients. This approach facilitates the amalgamation of information from multiple heads, thereby enriching the overall representation and capturing diverse aspects of the input data. The schematic diagram is shown in
Figure 3 below.
The figure illustrates the linear transformation of the feature sequence to obtain Q, K, and V. It calculates the relevance between the Q of the current sequence and the key information K of itself, as well as the relevance between the Q of the current sequence and the key information K of other sequences, resulting in the correlation coefficients between the current sequence and other sequences. In the case of multiple attention heads, the correlation operation is performed multiple times on the same Q to obtain multiple sets of attention coefficients, which are then averaged. The correlation coefficients of each sequence, when multiplied with their respective V, yield the final attention matrix. To ensure that the output falls within the activation region of the activation function, a sine function constraint is added to the dot product between Q and V during the final multiplication. The left part of the figure describes the computation process of the multi-head attention mechanism, while the right part provides an illustration of the multi-head attention mechanism.
The denominator of the dot product of Q and K in cross-sin multi-head attention is , where = embedding dimension/number of heads. The Q, K, and V scaling dot product operation adds a sine to limit the dot product range. As shown in the self-focus module, if the number of headers exceeds one, Cross sin AT will become a multi header cross focus, and when doing so, it can be represented as MCross-sinAT.
3. Experimental Results
Large networks and training datasets can result in a proliferation of model parameters and extended computation time, thereby impeding the implementation and adoption of the algorithm. Consequently, a major objective of this algorithm was to minimize the model parameters and training sets while upholding high-precision classification outcomes. To ascertain the feasibility and advancement of the proposed approach, verification and comparative tests were conducted on three publicly accessible datasets: India Pine, Pavia University, and Salinas. These tests were designed to assess the efficacy and performance of the algorithm vis-à-vis existing methods.
3.1. Hyperspectral Dataset
The India Pines dataset contains imaging data captured by AVRIS sensors at a designated testing site in northwest Indiana, with a specific emphasis on Indian pine vegetation. The dataset consists of 145 × 145 pixels and incorporates 224 spectral reflection bands after excluding 20 water absorption bands and noise bands. It possesses a spatial resolution of 20 m and encompasses 16 distinct land cover categories. To visually illustrate the underlying surface,
Figure 4 depicts both true and pseudo-colored mappings. For convenience,
Table 1 provides a comprehensive list of the specific land cover categories that are included in the India Pines dataset.
The Pavia University dataset consists of imaging data gathered by ROSIS sensors at the University of Pavia. It encompasses 610 × 340 pixels and comprises 103 spectral bands after excluding 12 noise bands. The dataset has a spatial resolution of 1.3 m and includes nine distinct land cover categories.
Figure 5 presents a visual depiction of the bottom surface using both true and pseudo-color mapping. Additionally,
Table 1 offers an exhaustive list of the specific land cover categories incorporated in the Pavia University dataset.
The Salinas dataset comprises imaging data captured by AVIRIS sensors over the Salinas Valley in California, USA. It encompasses 512 × 217 pixels and contains 204 frequency bands after eliminating 20 frequency bands with a low signal-to-noise ratio. With a spatial resolution of 3.7 m, it encompasses 16 distinct land cover categories.
Figure 5 illustrates a true and pseudo-color map representing the bottom surface, while
Table 1 provides a comprehensive list of the land cover categories included in the Salinas dataset.
3.2. Experimental Setting
(1) Evaluation metrics: To quantitatively assess the efficacy of this method and other methods, four evaluation metrics were employed: the overall accuracy (OA), average accuracy (AA), kappa coefficient (k), and individual classification accuracies for each land cover category. A higher value for each metric signifies a superior classification performance of the method.
(2) Machine configuration: The hardware configuration was an AMD Ryzen 7 5800 h CPU, an NVIDIA GeForce RTX 3060 graphics card, and 32 GB of memory. This machine is called the Lenovo R9000P, a wireless router product of China’s Lenovo Group, headquartered in Beijing, China. The software configuration included implementing all experiments using the PyTorch framework, a deep learning framework developed by the Facebook AI Research team. The programming language used for writing the programs is Python 3.8, which was developed by Dutch computer scientist Guido van Rossum in the early 1990s. The network parameters were set with Adam as the initial optimizer, and the initial learning rate was set to 0.001. Batch learning was employed with a batch size of 128, and each dataset was trained for 1000 epochs. The model parameters with the highest classification accuracy were saved.
3.3. Parameter Setting
In the parameter analysis, we investigated various parameters that impacted the classification performance and computational time of the network. Specifically, we concentrated on the input cube size, the configuration of the spectral convolution layer, and the layout of the spatial convolution layer. In order to determine the most suitable parameters for our experiments, we conducted relevant experiments. For additional information on the remaining parameter settings, please refer to
Section 3.2.
Figure 6 depicts the framework for five sets of experiments, which employed patch sizes of 9, 11, 13, 15, and 17. These experiments were performed on the India Pines, Pavia University, and Salinas datasets to explore the optimal parameters.
As shown in
Figure 6, it is evident that different patch sizes have an impact on the accuracy of ground object recognition by the network. Specifically, a larger patch size is associated with higher classification accuracy. Notably, when the patch size is set to 13, there are notable improvements in accuracy across the three datasets. However, increasing the patch size beyond 13 does not result in further enhancements in classification accuracy. From an operational perspective, opting for a smaller patch size allows for a faster computational speed. Therefore, we determined the final experimental patch size to be 13.
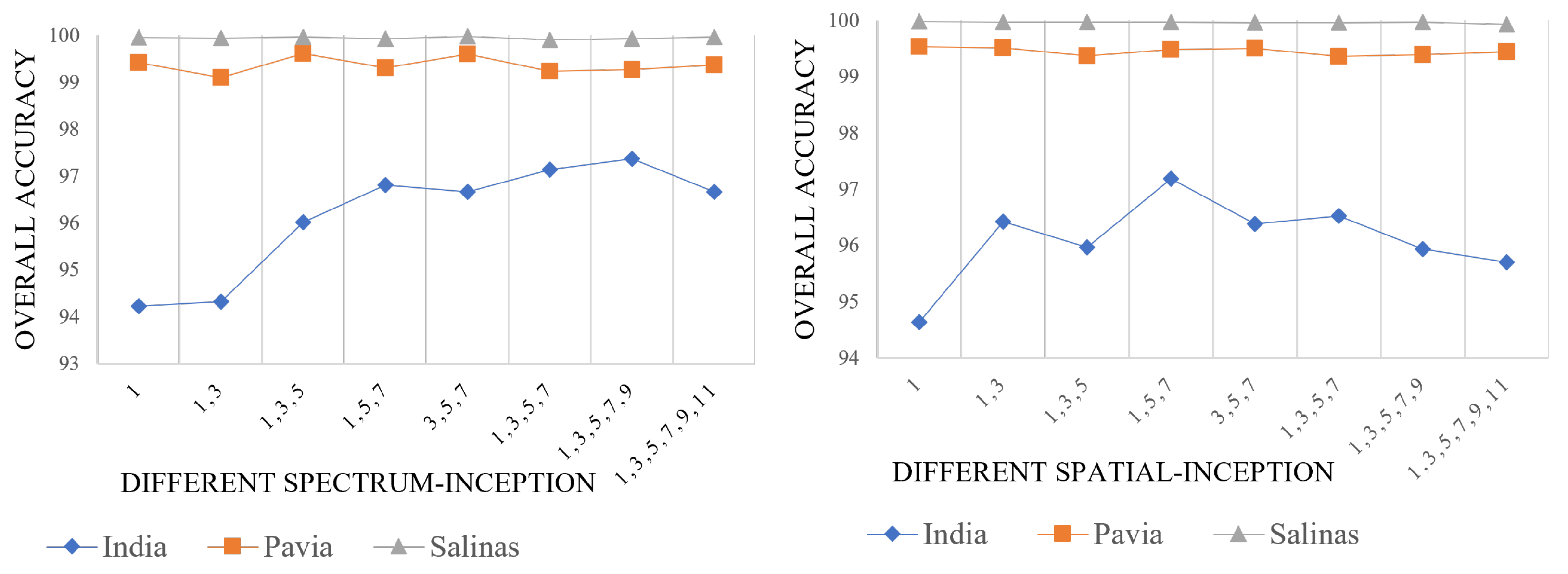
To extract the spectral and spatial features from hyperspectral images, we developed eight distinct sets of spectral and spatial Inception modules. These modules were utilized for feature extraction in our experiments. The experimental results were then evaluated using three datasets: India Pines, Pavia University, and Salinas. The depiction of the experimental outcomes can be observed in
Figure 7.
Figure 7 demonstrates the impact of the spectral and spatial Inception modules, which consist of different sizes of 3D and 2D convolution kernels, on classification accuracy. In terms of spectral Inception, variations in module sizes have a noticeable effect on the classification of the India dataset. Within a specific range, larger Inception modules yield higher classification accuracy. The impact on the Pavia and Salinas datasets shows minor fluctuations. In order to maintain accuracy while improving computational efficiency, a spectral Inception composed of 3D convolution kernels with scales of 3, 5, and 7 was selected to extract the spectral information from the HSI.
As for spatial Inception, different-sized modules have a significant effect on the classification accuracy of the India dataset. However, once their convolution combinations exceed a certain size, the classification accuracy tends to decrease. Similar slight fluctuations are observed for the impact on the Pavia and Salinas datasets. Taking into account the need to maintain accuracy while improving the model’s running speed, a spatial Inception composed of 2D convolution kernels with scales of 1, 5, and 7 was chosen to extract the spatial information from the HSI.
Based on the aforementioned comparative experiments, we determined that setting the patch size of the multiscale CNN-transformer network to 13 × 13 yielded the optimal classification performance. For the spectral Inception module, it was found that using 3D convolution kernels at scales 3, 5, and 7 produced the best results. Similarly, for the spatial Inception module, employing 2D convolution kernels at scales 1, 5, and 7 proved to be the most effective. As a result of these configurations, the classification outcomes are shown in
Table 2.
The data in the table represent the percentage of correct classifications, where a larger value indicates a better classification performance and more correctly classified samples.
3.4. Spatial Transposed Inception and Multi-Head Cross-Sin Attention Comparison Experiment
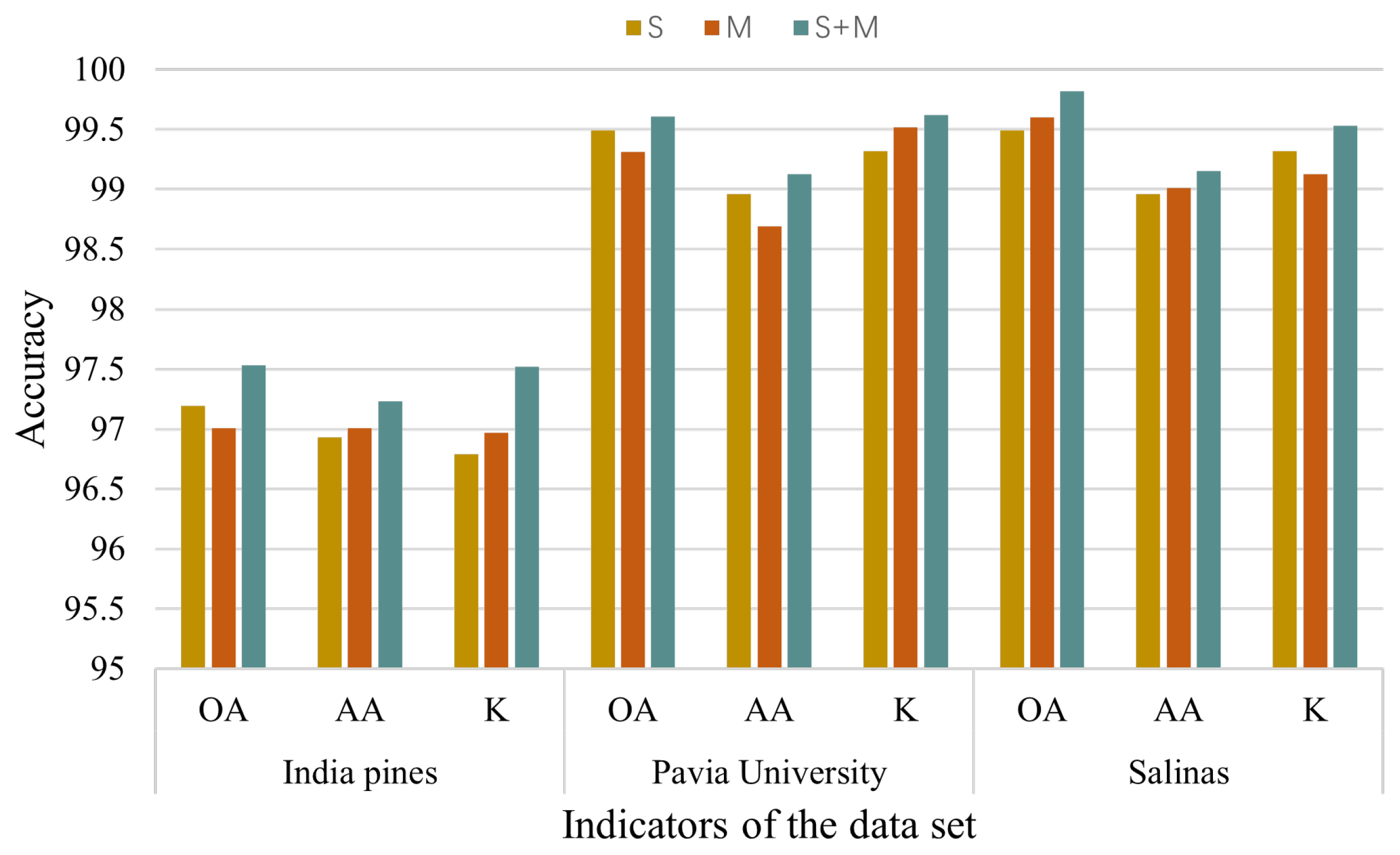
In order to independently validate the improvements brought by the spatial Inception module and the multi-head cross-sin attention module, we conducted a comparative study using a controlled variable approach. We treated the spatial Inception module and the multi-head cross-sin attention module as variables while keeping the other parameters constant. By adjusting the inclusion of these modules in the network and evaluating the results on three commonly used datasets, we obtained the validation outcomes presented in
Figure 8 below.
Figure 8 illustrates the results of our experiments. In (a), the left column shows the experimental outcomes without the spatial Inception module, while the right column displays the outcomes with the inclusion of the spatial Inception module. It is evident that the network utilizing the spatial Inception module achieved higher classification accuracy, demonstrating the superiority of this module. Similarly, in (b), the left column presents the experimental results without the multi-head cross-sin attention module, while the right column exhibits the results with the multi-head cross-sin attention module. It can be concluded that the network incorporating the multi-head cross-sin attention module achieves superior classification performance, confirming the improvements brought by this module.
The results presented in
Figure 9 demonstrate that the simultaneous inclusion of both the spatial transposed Inception and multi-head cross-sin attention modules has a positive impact on classification performance. Specifically, it leads to enhancements in the overall classification accuracy and average classification accuracy, as well as other metrics.
3.5. Comparison of Different Network Classification Results
In order to demonstrate the effectiveness of the proposed method in this study, we conducted comparative experiments on three datasets: India Pines, Pavia University, and Salinas. By analyzing and comparing the classification accuracy of the SSTN [
38], SSRN [
39], SSFTT, and MSSTT, we further substantiated the novelty and innovation of the method presented in this paper. The results of the comparative experiments can be summarized as follows.
Table 3 presents the overall accuracy (OA) of the SSTN, SSRN, SSFTT, and MSSTT methods for the OA, average accuracy (AA), Kappa coefficient (Kaappa), and individual ground features in the India Pines dataset. The data in the table represent the percentage of correct classifications, where a larger value indicates a better classification performance and more correctly classified samples. It is evident that the MSSTT approach proposed in this study outperforms the other three methods in terms of classification accuracy. The classification results are visualized in
Figure 10.
From
Figure 10, it can be observed that compared to the ground truth image, SSTN and SSRN exhibit errors in multiple land cover classifications. SSFTT shows some improvement in classification performance compared to the previous two methods but still exhibits errors in various land cover categories, such as Corn-notill and Soybean-notill. The proposed method, MSSTT, generates a final classification map that is closest to the ground truth image.
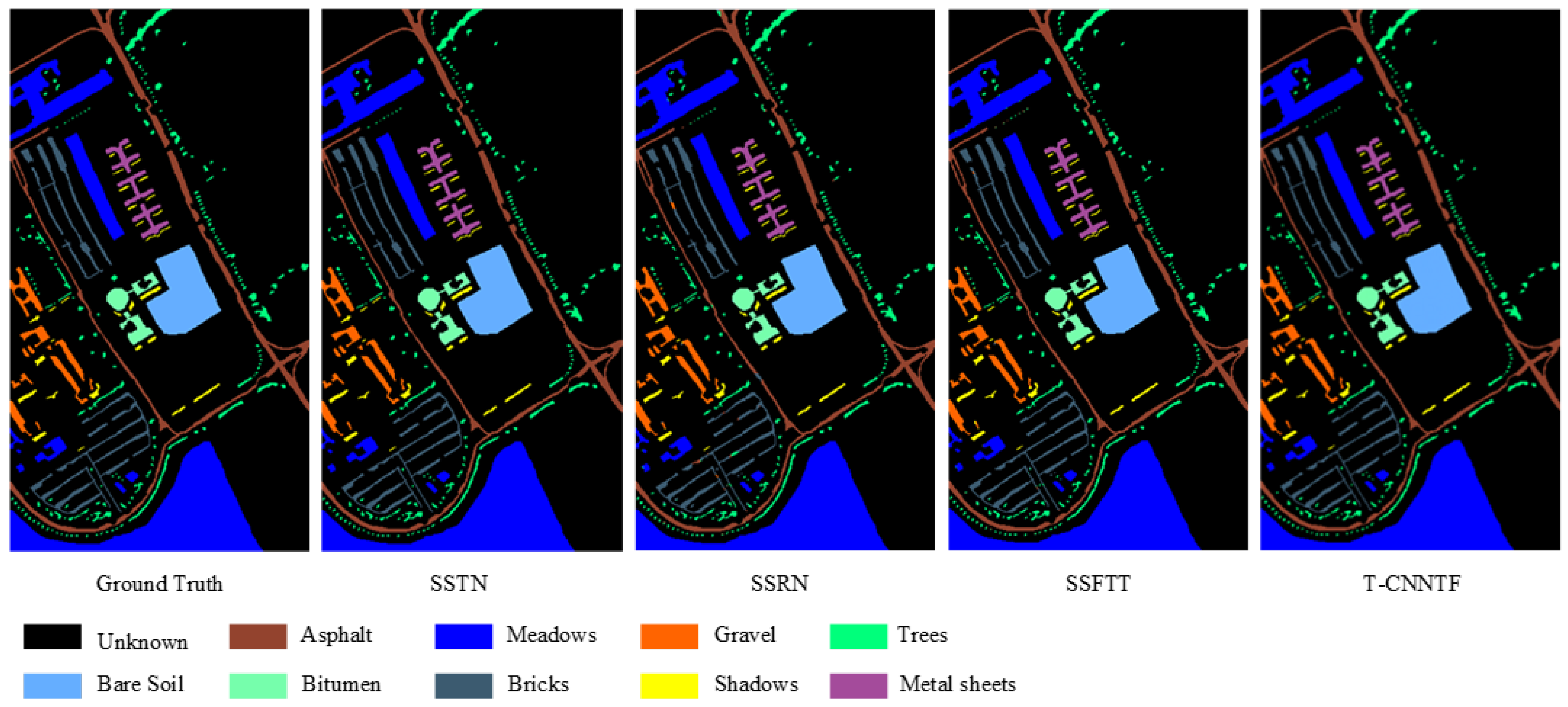
Table 4 presents the overall accuracy (OA) of the SSTN, SSRN, SSFTT, and MSSTT methods for the OA, average accuracy (AA), Kappa coefficient (Kappa), and individual ground features in the Pavia University dataset. The data in the table represent the percentage of correct classification, where a larger value indicates a better classification performance and more correctly classified samples. It is evident that the MSSTT approach proposed in this study outperforms the other three methods in terms of classification accuracy. The classification results are visualized in
Figure 11.
From
Figure 11, it can be observed that compared to the ground truth image, SSTN exhibits errors in multiple land cover classifications, such as Bare Soil and Bricks. SSRN also exhibits errors in the classification of Bricks. SSFTT shows errors in multiple land cover categories, such as Gravel and Shadows. The proposed method, MSSTT, generates a final classification map that is closest to the ground truth image.
Table 5 presents the overall accuracy (OA) of the SSTN, SSRN, SSFTT, and MSSTT methods for the OA, average accuracy (AA), Kappa coefficient (Kappa), and individual ground features in the Salinas dataset. The data in the table represent the percentage of correct classification, where a larger value indicates a better classification performance and more correctly classified samples. It is evident that the MSSTT approach proposed in this study outperforms the other three methods in terms of classification accuracy. The classification results are visualized in
Figure 12.
From
Figure 12, it can be observed that compared to the ground truth image, SSTN, SSRN, and SSFTT all exhibit errors in the classification of Grapes untrained. The proposed method, MSSTT, generates a final classification map that is closest to the ground truth image.
The classification visualization results of SSTN, SSRN, SSFTT, and MSSTT on the India Pines, Pavia University, and Salinas datasets are depicted in
Figure 10,
Figure 11 and
Figure 12. Among these methods, the classification result map obtained using MSSTT exhibits the cleanest and most accurate alignment with the ground reality map. Conversely, the results of SSTN, SSRN, and SSFTT display noticeable noise across all three datasets. Specifically, on the India Pines dataset, SSTN, SSRN, and SSFTT demonstrate relatively poor classification performance for the blue, yellow, and pink regions in the middle. In contrast, the proposed method in this study significantly improves the identification of these three color regions. On the Pavia University dataset, SSTN misidentifies the light blue area, SSRN incorrectly classifies the middle dark gray area as dark brown, and SSFTT misclassifies the brown area in the lower left corner as yellow. In contrast, the MSSTT approach performs closest to the actual ground image in terms of accurate identification. Regarding the Salinas dataset, SSTN and SSRN both misidentify the middle gray area, while SSFTT misclassifies the green area. In comparison, the recognition by MSSTT is almost identical to the real ground image.
These observations lead to the conclusion that the method proposed in this paper maintains optimal boundary regions, further validating the classification performance of MSSTT.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}