1. Introduction
With the rapid development of the era of big data and the internet, the issue of privacy leakage of massive user information and data [
1,
2] has become increasingly prominent. The exponential growth in data, combined with their diverse nature, has posed significant challenges in terms of data privacy and security. As a novel distributed machine learning framework, federated learning [
3] allows data to be stored on local mobile devices, coordinating model parameters across these devices to aggregate the model. This unique approach ensures that data remain decentralized, eliminating the need for centralized servers that often pose security risks. During federated learning, each mobile device uses local data for private training, eliminating the need for personal privacy data to be transmitted over the network. This method, to some extent, protects the data privacy of each mobile device and effectively addresses the “data island” problem [
4]. Consequently, more and more researchers are beginning to focus on the security and privacy of federated learning [
5,
6].
While federated learning offers a solution to some of the data privacy issues, ensuring the active participation of devices in the learning process remains a challenge. Devices incur training costs and communication overheads, which can sometimes discourage them from actively participating. In order to encourage the active participation of mobile devices in data sharing and improve the quality and efficiency of federated learning model training, numerous research solutions have been proposed and widely applied. For instance, Konečný et al. [
7] proposed two methods to reduce the cost of uplink communication, reducing the communication cost of federated learning by two orders of magnitude. Kim et al. [
8] introduced the architecture of Blockchain Federated Learning (BlockFL), in which local learning model updates can be exchanged and verified. Hardy et al. [
9] realized privacy data protection for each peer mobile device and provided a significantly enhanced federated learning environment for all mobile devices. Li et al. [
10] provided an asymptotically tight lower bound for the goals that communication compression may achieve. These research solutions, though innovative, often operate under the assumption that participating nodes are honest, which may not always be the case in real-world scenarios. Considering the heterogeneity of channel performance and the competitive relationship of data transmission on wireless channels in the federated learning framework, Zhao et al. [
11] proposed a new group asynchronous model synchronization method, significantly improving the training efficiency of federated learning. Chen et al. [
12] reduced the communication cost of each parameter of federated learning model training to below 1.78 bits through linear techniques based on sparse random projection, thus improving the learning efficiency of federated learning.
To address the challenges posed by potential dishonest nodes and to ensure optimal participation, game theory offers a promising approach. Katz et al. [
13] explored the relationship between game theory and security protocols, especially the problem of security protocols among distrustful participants. Game theory, with its ability to model and predict the behavior of rational agents, can be effectively utilized in the context of federated learning. Many scholars have introduced the idea of game theory into federated learning schemes, using participants’ rationality as a starting point to design reasonable utility functions to motivate participants to actively participate in model training. For example, He et al. [
14] proposed a new federated learning incentive model that encourages mobile nodes to participate in training tasks by maximizing collective utility functions. Martinez et al. [
15] proposed a distributed learning framework based on blockchain design to ensure data security, and made payments for gradient upload based on a new index of validation errors, effectively enhancing the enthusiasm of each node for model training. Zhou et al. [
16] used game theory and Micali–Rabin random vector representation technology to improve the communication efficiency of model training and ensured that all rational participants could obtain optimal utility returns. Zhu et al. [
17] built a decentralized parameter aggregation chain from the centralized parameter server in federated learning, incentivizing collaborating nodes to verify model parameters, enhancing trust between nodes, and thus improving the efficiency of federated learning. Stergiou et al. [
18] proposed a novel architectural scenario based on cloud computing, leveraging the innovative models of federated learning. Their proposed model aims to provide users with a more energy-efficient system architecture and environment, with the objective centered around data management. Wassan et al. [
19] introduced differential privacy in federated learning, employing the adaptive GBTM model algorithm for local updates. This approach aids in adjusting model parameters based on data characteristics and gradients.
Nevertheless, while the integration of game theory provides a mechanism to incentivize honest participation, there is still a need to address the communication overhead of federated learning. In order to effectively balance the relationship between model parameter privacy security, utility returns of all rational participants, and communication overhead during the federated learning process, we construct a new federated learning scheme using game theory, smart contracts, rational trust models, and function encryption techniques.
The specific work includes:
Introducing local training rational participants using game theory and rational trust models, reducing communication frequency, and constructing a trustworthy anti-collusion federated learning game scheme to reduce communication costs;
Using blockchain networks and smart contract technology to ensure no new malicious nodes can participate in model training during the federated learning process, and recording all participants’ trust values and transaction processes through smart contracts;
Ensuring model parameter privacy security through function encryption technology and achieving privacy-protected sharing between task publishers and data owners;
Proving the correctness and security of the scheme through analysis and experimental simulation, with empirical evidence showing that the scheme does, indeed, improve the learning efficiency of federated learning.
This paper is structured as follows. Following the introduction, we delve into the preliminary knowledge in
Section 2. In
Section 3, we introduce the “Credible Defense Against Collusion Game Model”.
Section 4 presents a detailed discussion of the “Credible Anti-Collusion Federal Learning Scheme”. In
Section 5, we analyze the proposed scheme. The experimental results are presented in
Section 6. Finally, we conclude the paper and discuss future prospects in
Section 7.
3. Credible Defense against Collusion Game Model
We have constructed a credible game model for federated learning that defends against collusion, ingeniously integrating the historical trust values of rational participants with the utility derived from completing training tasks. The goal is to delve deep into the learning efficiency of federated learning and to elevate the quality and accuracy of the training of federated learning models. This credible defense against collusion game model extensively draws from traditional federated learning and game theory. Starting from the perspective of participants’ self-interest, a logical and effective utility function is designed to motivate rational participants to actively engage in model training. In this model, every rational participant adopts respective behavioral strategies aiming to maximize their benefits. Any behavior that deviates from the established agreement will be met with stringent penalties and, concurrently, the individual’s historical trust value will be entirely reset.
In this context, smart contract technology plays a pivotal role. Initially, both task publishers and data owners establish the parameters and execution standards for federated learning tasks through smart contracts. This ensures the transparency and fairness of the tasks. When data owners complete model training and upload their results, the smart contract automatically verifies these results and, based on pre-defined criteria, metes out rewards or penalties. This not only obviates the need for manual verification but also guarantees that every participant acts in accordance with the agreement. Additionally, the smart contract logs the historical trust value of each data owner, providing task publishers with a continuously updated reference for trustworthiness. This process further strengthens the fairness and transparency of the system.
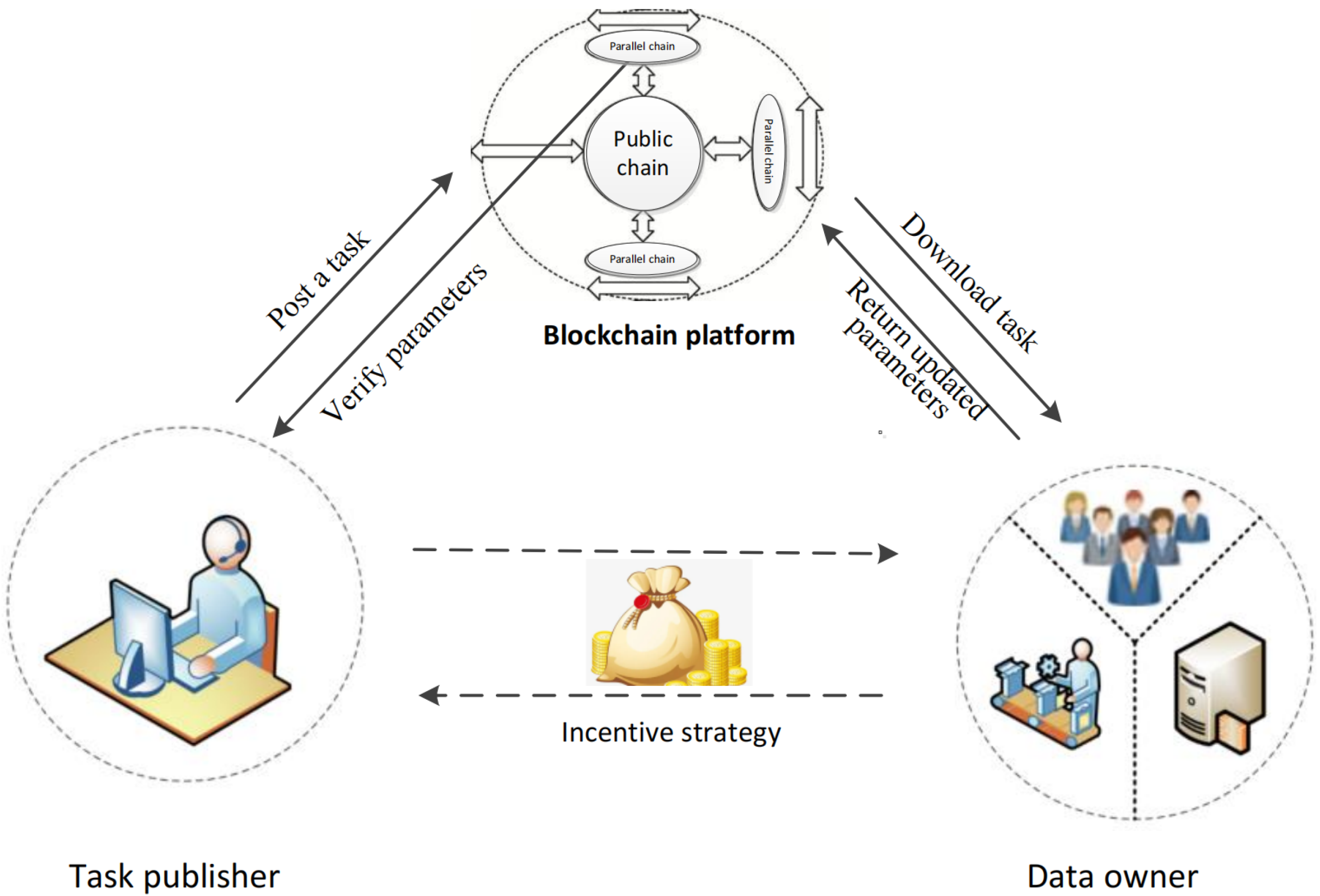
A schematic representation of the model participants is shown in
Figure 1. The specific steps of the model are as follows:
- Step 1:
Evaluate the historical trust value of data owners. During the model training phase, the task publisher lacks direct insight into each data owner’s work ethic. Thus, to predict the accuracy of model parameters post-task completion, the task publisher participating in federated learning needs to evaluate the historical trust value of each data owner. By opting for data owners with high historical trust values for model training, the learning efficiency of federated learning can be further enhanced.
- Step 2:
Execute federated learning tasks. The task publisher posts the global model training parameters to the blockchain and then selects apt data owners for executing model training tasks based on the analysis of historical trust values. Upon receiving the model parameters, data owners conduct private training based on their individual data and upload the training outcomes to the blockchain. Subsequently, the task publisher verifies the task results and evaluates the accuracy of the data owner’s work during the task’s execution.
- Step 3:
Analyze the execution task results. Data owners upload the updated model training parameters to the blockchain, after which the task publisher verifies these updated parameters. Given that function encryption technology is employed to safeguard the security of model parameters during task publication and verification, it becomes imperative to validate the authenticity of the updated model parameters.
- Step 4:
Compute the utility of rational participants. Once the task issuer retrieves the optimally updated global model parameters, the federated learning training task concludes. At this juncture, the utility function of rational participants must be computed. Analyzing the utility of each participant allows for gauging the efficiency and accuracy of the task.
3.1. Model Parameters
The main parameters involved in the game-theoretic trustworthy anti-collusion federated learning model proposed in this paper are shown in
Table 1 and described in detail in the text.
In the model, as all participants are rational, they will choose the optimal behavioral strategy to maximize their own benefits. Therefore, the credible defense against the collusion game model needs to maintain balance, and the parameters in the model should satisfy the following relationships:
There exists , otherwise the task publisher has no motivation to publish federated learning tasks;
There exists , otherwise the data owner has no motivation to accept model training tasks;
There exist and ; and , because only when the deposit and fine are large enough can participants be encouraged to follow the protocol execution honestly;
There exists , otherwise the data owner has the motivation to initiate a collusion strategy.
In the credible defense against the collusion game model of federated learning, since every rational participant is selfish and strives to maximize their own benefits, the personal utility of the participants is determined by their own behavioral strategies and the behavioral strategies of other participants in the model. Therefore, an effective credible defense against the collusion game model needs to reasonably design the rational participants, feasible strategies, utility functions, and anti-collusion mechanisms in the model to encourage all rational participants to actively participate in model training.
3.2. Participants
The primary entities to be modeled in the credible defense against the collusion game model are the rational participants within the model. This game model mainly involves two types of participants: one is the task publishers A who publish federated learning tasks, and the other is the mobile devices or data owners who perform model training tasks. As all participants are rational, task publishers A seek to maximize their own interests while ensuring optimal global parameters for model training. Similarly, data owners also seek to maximize their own interests while meeting the task execution requirements of the task publishers. Therefore, the set of participants in this model can be formally defined as .
3.3. Feasible Strategies
In this model, we assume that the behavioral strategy set of the rational task publishers A is , where denotes the behavioral strategy of “incentivizing” data owners and is assigned a value of 1; represents the strategy of “not incentivizing” data owners and is assigned a value of 0. Similarly, the behavior strategy set for selfish rational data owners is , where represents the “honest” strategy with a value of 1, and represents the “collusion” strategy with a value of 0.
In the credible defense against collusion game model, we assume that task publishers A first adopt a behavioral strategy to decide whether to incentivize data owners to honestly perform model parameter training tasks. Subsequently, data owners will adopt corresponding strategies to maximize their personal interests based on the behavioral strategy of task publishers A. Therefore, this game model is an asymmetric information game, in which each rational participant chooses the appropriate behavior strategy to update their local state and optimize their personal utility based on different sets of information.
3.4. Utility Functions
In this model, as all participants are rational, task publishers A always hope that data owners will honestly use their own data to perform model parameter training tasks; data owners always hope that task publishers A will give the maximum rewards to incentivize them to complete the model parameter training. At this time, the utilities of both sides are denoted as , respectively. However, rational participants may choose different behavior strategies to increase profits in order to maximize their personal interests. This can lead to the following situations:
If task publishers A choose not to send rewards to incentivize data owners , and all data owners choose to honestly perform model parameter training, the utilities of both sides are denoted as , respectively.
If task publishers A choose to send rewards to incentivize data owners , but data owners , in order to save training costs, choose to collude and send invalid model update parameters, the utilities of both sides are denoted as , respectively.
If all participants seek to maximize their benefits by saving costs, task publishers A choose not to send rewards and hope to obtain the optimal model training parameters; data owners will choose the collusion strategy. They will send the agreed model update parameters, thereby saving model parameter training costs. At this time, the utilities of both sides are denoted as , respectively.
When participants choose different behavior strategies in the model, the utilities obtained by both sides will also be different. The specific utility values, that is, the payoff matrix of the credible defense against the collusion game in federated learning, are shown in
Table 2.
The above is the utility gains obtained by each rational participant in the credible anti-collusion game model, according to different behavioral strategies. According to the behavioral strategy analysis of rational participants, the credible anti-collusion game model of federated learning can be divided into three stages:
After the task publisher A releases the model training task, they can choose to send a bonus to incentivize data owners to actively and honestly perform model training, or they can choose not to send rewards;
Rational data owner , based on the behavioral strategy of task publisher A, selects a reaction from its strategy set {honest, collusion};
After the rational task publisher A obtains the updated model parameters after training and verifies them, if the verification is passed, they need to pay the verification fee v; if the verification is not passed, the data owner pays this verification fee.
From the above analysis, we know that, due to the asymmetric information of each rational participant in the model, data owners will choose their own behaviors according to the behavioral strategies chosen by task publishers. Therefore, data owners will only maximize their benefits when they receive rewards, choose an honest behavioral strategy, and at this time, task publishers will also obtain the optimal model update parameters. At this time, the Nash equilibrium strategy set in the model is , with a utility of , which means is the Nash equilibrium state of this model.
While we acknowledge that the Nash Equilibrium guarantees a stable state where no player has an incentive to deviate unilaterally from their current strategy, it does not necessarily promise the global optimum. However, our emphasis on Nash Equilibrium is due to its significance in ensuring consistent participation and behavior from the rational participants in federated learning scenarios. This stable state, although it might not always be globally optimal, ensures a predictable and reliable system behavior, which is crucial for our approach.
3.5. Credible Anti-Collusion Mechanism
In the rational trust model, we designed a credible anti-collusion mechanism. Through the trust management mechanism, detailed records of the behavioral strategies of all rational data owners
are made and uploaded to the blockchain to prevent any participant from tampering or denying information. The trust management mechanism mainly records the trust value
of each rational data owner after each round of training
, as well as the life cycle
of each data owner
in the model. To fortify our federated learning approach against collusion and ensure participants’ genuine contributions, we employ the functional encryption technique. This technique guarantees the security of the uploaded model parameters throughout the task publication and validation phases. In the credible anti-collusion game model, the trust function of each rational data owner
after each round of
training is defined as:
The relationship of this function is as follows:
;
indicates whether participant follows the protocol in each round of training, that is, indicates that the participant is honestly executing the protocol, and indicates that the participant is betraying the protocol;
represents the life cycle of the rational data owner in the model. When the participant chooses to betray the protocol, the rational participant will lose the original trust value , and their life cycle and trust value will start over. only increases when choosing an honest behavioral strategy, and all trust values are recorded in the smart contract;
The parameter is a constant, and exists;
The parameter is a constant, and exists.
From the behavioral strategy analysis of rational participants, we know that the utility function of all participants is related to their individual behavioral strategies. In the credible anti-collusion model, the utility of each rational participant also depends on their personal trust value. Therefore, to better incentivize all rational participants to actively participate in model training, the utility function of data owners is defined as
, where
At this time, the utility of data owners includes the benefits obtained after completing the model training task and their personal trust value. Here, . To protect the personal interests of all honest rational participants in the model, when , rational participants choose an honest behavioral strategy. At this time, , and honest rational participants will get the maximum utility benefit. However, when , the rational data owner chooses a collusion strategy at this time, and the utility value is . At this time, the utility benefit obtained by the data owner is . Therefore, in this model, rational data owners, in order to maximize their own interests and improve their personal trust value, will not choose the collusion strategy. At this time, the strategy behavior set of both parties in the anti-collusion game model is still , with a utility of , and the model still reaches a Nash equilibrium state.
4. Credible Anti-Collusion Federal Learning Scheme
In our analysis of federated learning through a credible anti-collusion game framework, we find that a Nash equilibrium is achieved when the task publisher adopts an “incentive” strategy and the data owner opts for an “honest” behavior strategy. Within this strategic combination, all rational participants can maximize their utility gains. In this section, we leverage smart contract and functional encryption technologies to architect a game theory-based credible anti-collusion federated learning scheme. This scheme mandates that all rational participants complete model training tasks within designated time frames. Failing to do so will result in scheme termination and forfeiture of the deposit by those participants who exceed the stipulated timeframe. Our game-theory-driven credible anti-collusion federated learning approach unfolds in three phases: initialization, task execution, and utility payment.
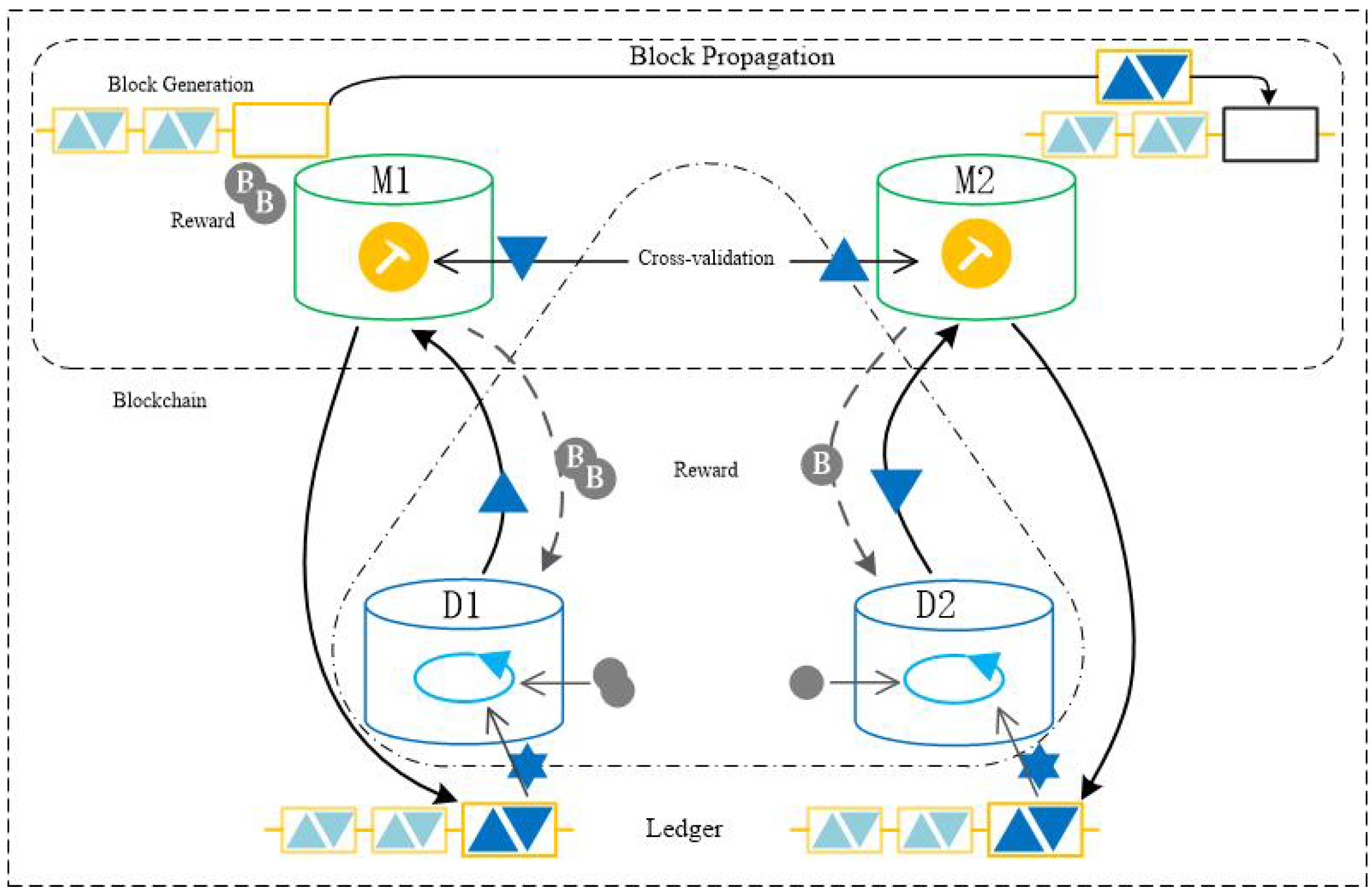
Figure 2 depicts the structure of the trusted federated learning system we have designed. Here, M1 and M2 could represent two different models or model updates in the federated learning process. They could signify different versions of the model or model updates from different participants. D1 and D2 might represent datasets or data updates from different participants in the federated learning process.
4.1. Initialization Stage
Assuming that the task publisher A in the scheme needs to update and optimize the model parameter m, the task publisher A and data owner participating in the execution of the scheme need to register in the well-deployed smart contract in order for the smart contract to store and distribute the deposits and bonuses of various participants. During this stage, the task publisher needs to encrypt the model parameter m to prevent the data privacy from being tampered with or leaked by malicious participants during transmission, and upload the encrypted model parameters to the blockchain before time , otherwise, the execution of the scheme will be terminated.
The encryption process of model parameter m uses function encryption technology. First, the system initialization algorithm generates an p-order prime group G. Then, through the secret key generation algorithm , initialize the entire system with the global security parameter and as input parameters, generate the main public key in the system model, where g is the generator of the prime group G, and the main private key , then publish the main public key on the blockchain. Then, use the encryption algorithm to encrypt the model parameter m with the main public key, protecting the privacy and security of the parameters. Here, the main public key and model parameters are used as input , and after encryption with function encryption technology, the encrypted ciphertext is returned, where the ciphertext is , , , and r is a random number.
4.2. Task Execution Phase
Once the global model parameters are encrypted, task publisher A uploads the encrypted model parameters to the blockchain, along with a preset function F that can operate on the encrypted global model parameters. This step ensures that only legitimate and rational data owners can access the encrypted model parameters to perform tasks. During this process, some rational data owners might deviate from the honest course in collusion with others to send updated model parameters that do not require training to the task publisher, all in order to enhance personal gains. The deadline for initiating such collusion is at point and, prior to this, rational participants can make a request for collusion; beyond this time point, they lose the right to initiate such behaviour.
In the absence of any data owners initiating collusion, those capable of performing the model training task will take action. For achieving data privacy protection and sharing, data owners do not need to directly acquire the original model parameters but only need to obtain the result of the preset function operating on the encrypted parameters. Every rational data owner selects the preset function F from the blockchain to decrypt and then perform model training. Here, algorithm provides a vector for each rational data owner and generates a key , i.e., , to obtain the result from the preset function. Subsequently, data owners decrypt , perform model training, and then re-encrypt the updated model parameters into a using function encryption technology, and upload to the blockchain for validation by the task publisher.
Upon receiving the encrypted model update parameters
, the task publisher uses decryption algorithm
to restore the model parameters. Here, the system master key
, the encrypted model update parameters
, and the key
are used as inputs to return the discrete logarithm based on the generator
g of group
G,
thereby obtaining the updated model parameters
. If validation is successful, the model updating proceeds to the next round until the optimal global model update parameters are obtained. If validation is not successful, the data owner
is penalized, and the penalty information is recorded in the smart contract for invoking transactions and achieving individual utility gains. Similarly, if a rational data owner
initiates collusion, then during the verification of Formula (5), due to the discretization of the function, the verification cannot pass. The data owners who deviate from the honesty principle will be penalized, and their individual trust values
will be reset to zero. At this point, the model training task also ends, directly entering the final utility payment stage.
4.3. Utility Payment Phase
Upon the completion of N rounds of global model updates and once the parameters reach the optimum state, the training task is considered accomplished. After the task ends, task publisher A will evaluate the quality of the parameters provided by each data owner and their performance index, then invoke the smart contract to calculate and distribute the training task rewards. This process needs to be completed within the time frame ; rational participants exceeding this time node will face penalties.
According to the analysis of game model, when task publisher A sends incentives to each data owner , rational data owners, in order to maximize their own benefits, will avoid colluding. That is, all rational participants will complete the model training task within the specified time. At this point, the utility gain of the task publisher A is ; similarly, the utility gain of rational data owner is also . In this situation, the global model will reach a Nash equilibrium state.
The blockchain will record the working status of all participants at this moment to prevent any malicious behaviour breaching the contract at the final stage of the plan, i.e., during the distribution of bonuses. After all participants have received their bonuses, the smart contract will return the deposits they submitted, thus marking the end of this federated learning task.
5. Scheme Analysis
This study proposes a reliable collusion-prevention federated learning scheme based on game theory, which regulates all rational participants’ strategic choices through the design of collusion-prevention game models and judges the existence of malicious behaviors that breach the contract based on each rational participant’s utility function. Therefore, we need to validate the correctness, safety, and communication complexity of the scheme. Simultaneously, for task publisher A and data owner , their published model parameter tasks should be privacy-preserving. However, since all data on the blockchain are publicly visible to all participants, we also need to validate the security and privacy of data model parameters in the scheme.
5.1. Correctness Analysis
In the scheme, all participants are involved in the collusion-prevention game model’s federated learning training tasks. If the rational task publisher A and data owner both follow the contract stipulations, selecting the appropriate behavioral strategy to execute the task, then all rational participants will obtain optimal utility gains. Next, we will prove the correctness of this scheme.
Theorem 1. The federated learning scheme is correct.
Proof. In this scheme, assume that the rational task publisher A wants to send the initial global model parameters m to data owner for model parameter training and update. Firstly, the task publisher A needs to encrypt the initial global model parameters m and preset function F and upload them to the blockchain within time . Then, within time , data owner , who is willing to accept this model parameter training task, needs to respond on the blockchain and query the responded data owner through the smart contract; at the same time, any data owner wishing to collude also needs to initiate collusion within this time.
Suppose there is a rational data owner
who chooses to initiate a collusion behavior strategy, i.e., deviating from the scheme to upload invalid updated model parameters, where
. In the subsequent verification, the data owners who chose to collude will not pass the verification, and the trust management mechanism will set the trust value
and the life cycle
of the colluding data owner
to zero, and the rational data owners who are cleared will be severely impacted in the subsequent work. If the life cycle growth process of the rational data owner
who is cleared after deviating from the scheme execution is 0,
,
,
,
,
, then their losses in subsequent work will be as follows:
As can be seen from the above formula, when the rational data owner chooses the collusion strategy for the first time, his life cycle is zeroed, and the loss is . When the life cycle of the rational participants who colluded grows back to , they will suffer a loss of , and their credibility will be recorded in the blockchain. For rational participants , in order to protect their credibility and gains, in this collusion-prevention game model, they will not choose the collusion strategy but will only choose the honest behavior strategy to maximize their own utility. Only the strategy set is a Nash equilibrium point of this model. Therefore, the reliable collusion-prevention federated learning scheme designed by this study based on game theory is correct. □
5.2. Security Analysis
Our scheme uses functional encryption technology to ensure the private and secure sharing of data model parameters during the trustworthy collusion-prevention federated learning process. The following will analyze the security of our scheme.
Theorem 2. This federated learning scheme is secure.
Proof. During the execution of the federated learning task, the initial global model parameters m are encrypted by task publisher A using functional encryption technology, then uploaded to the blockchain. In our scheme, all security parameters are generated and set through functional encryption technology. Our functional encryption is based on the Decisional Diffie–Hellman assumption (DDH), ensuring the indistinguishability of parameters in the encryption function. Let algorithm be an arbitrary probabilistic polynomial-time algorithm. When the security parameter is randomly input, a triplet is generated, where G is an p-order prime group with a generator g. At this time, if an independent parameter is randomly chosen, then and are distinguished with a non-negligible probability.
In our scheme, the functional encryption technology initializes the entire system through algorithm , generates a master public key and a master private key , where . After the model parameter m is encrypted by the master public key, ciphertext is returned. If there exists a malicious third party trying to tamper with the model information, then there will be a situation where . Since functional encryption technology is based on the DDH assumption, no random can distinguish and for a malicious attacker. Similarly, in the process of the data owner publishing the updated model parameters to the blockchain, no polynomial time attacker can distinguish and . Therefore, this game-theory-based trustworthy collusion-prevention federated learning scheme we designed is secure and satisfies basic semantic security. □
5.3. Communication Efficiency Analysis
In this section, we aim to demonstrate that our proposed solution can effectively reduce communication complexity. We compare our approach with traditional federated learning schemes to validate this claim.
In a traditional federated learning scheme, let us assume that the number of data owner nodes participating in the federated learning training task is . The transmission of model parameters between the task publisher and the data owners will require model parameters, where denotes the initial model parameters that the task publisher needs to send to the data owners. However, without using function encryption technology, each model parameter’s size is , where . Here, o represents the byte size of each model parameter after using function encryption technology, and represents the byte size of each model parameter without using function encryption technology.
Consequently, in a traditional federated learning scheme, the communication volume required for each round of training is , and the total communication volume is , where N denotes the total number of rounds in the federated learning training task. Assuming that d bytes can be transmitted per second, the total communication time is seconds. As there are no collusion request transmissions in a traditional federated learning scheme, the total communication complexity is .
To compare our solution’s communication complexity with the traditional scheme, we derive the following equations:
Here, represents the total communication time (in seconds) required in our scheme, and e denotes the byte size of each collusion request. The above formula is valid only when and . That is to say, only when the size of model parameters decreases after using function encryption technology, and when collusion request transmissions exist, can our solution’s communication complexity be reduced. Given that function encryption technology can effectively reduce the size of model parameters, and that collusion request transmission is a necessary condition to prevent collusion in our scheme, these two conditions can potentially be met. In conclusion, we can demonstrate that our solution has a lower communication complexity than traditional federated learning schemes.
6. Experiment and Evaluation
To effectively gauge the communication efficiency in model parameter training, the aggregation impact, and the incentive dynamics of various node types within our design, we orchestrated distributed training simulations involving multiple data owner nodes via a thread pool. The primary objective behind these systematic experiments is to meticulously evaluate the efficacy, adaptability, and resilience of our novel trustworthy anti-collusion federated learning framework. By delving into diverse parameters such as data distribution nuances, variations in client counts, dataset intricacies, and the strategic incorporation of game theory, our intent is to furnish a holistic understanding of the scheme’s practical feasibility, operational efficiency, and its fortified defenses against conceivable adversarial interferences. These rigorous assessments underscore our commitment to advancing the tenets of federated learning, emphasizing paramount security, privacy, and trust in distributed machine learning paradigms.
6.1. Experimental Setup
The series of experiments was conducted on a desktop computer equipped with an Intel Core i7-9700K CPU, 32GB RAM, and an NVIDIA GeForce RTX 2080 Ti GPU. This hardware configuration was designed to meet the demands of complex federated learning training and support the implementation of game theory simulations and privacy protection mechanisms. In terms of software, the experiment’s runtime environment was Ubuntu 18.04, with Python 3.8 as the programming language. The experiment mainly relied on TensorFlow 2.4 for deep learning modeling, NumPy 1.19 for numerical computation and data processing, Matplotlib 3.3.4 for visualizing results, and specific privacy protection libraries to implement measures such as differential privacy. The chosen datasets covered a variety of fields, including MNIST, CIFAR-10, and Fashion MNIST, ensuring a comprehensive assessment of model performance across different tasks and scenarios. To guarantee the consistency and repeatability of the experiments, the same random seed was used for all experiments, and each experiment’s results were computed based on the average of at least five independent runs, effectively minimizing the impact of random factors.
6.2. Performance Evaluation
6.2.1. Experiment 1: Impact of Data Distribution on Federated Learning Performance
Central to our investigative framework is the meticulous examination of the ramifications of data distribution, specifically within IID and non-IID paradigms, on the training potency of federated learning. Employing the MNIST dataset, an exemplar for handwritten digit discernment, we delineated a comparative analysis between the IID data spectrum, characterized by equitably distributed samples and uniform category delineations, and the non-IID spectrum, which could exhibit variances in sample metrics and categorical distributions. As illustrated in
Figure 3, the overarching model within the IID framework manifested a pronounced rapidity in convergence and superior precision. This revelation accentuates the pivotal role of data orchestration across federated learning clientele. Moreover, it serves as a testament to the fortitude and adaptability of our approach amidst the challenges proffered by non-uniform data landscapes, often emblematic of real-world dynamics.
Subsequent evaluations on datasets such as CIFAR-10 and Fashion MNIST reaffirmed these inferences, underscoring the robustness and pan-applicability of our federated learning architecture. The tangible performance differential between IID and non-IID constructs underscores the exigency for nimble stratagems in federated learning, particularly when traversing the multifaceted terrain of diverse client data orchestrations. Our elucidations not only shed light on these inherent conundrums but also chart a course for propitious advancements in the actualization of federated learning in pragmatic environs.
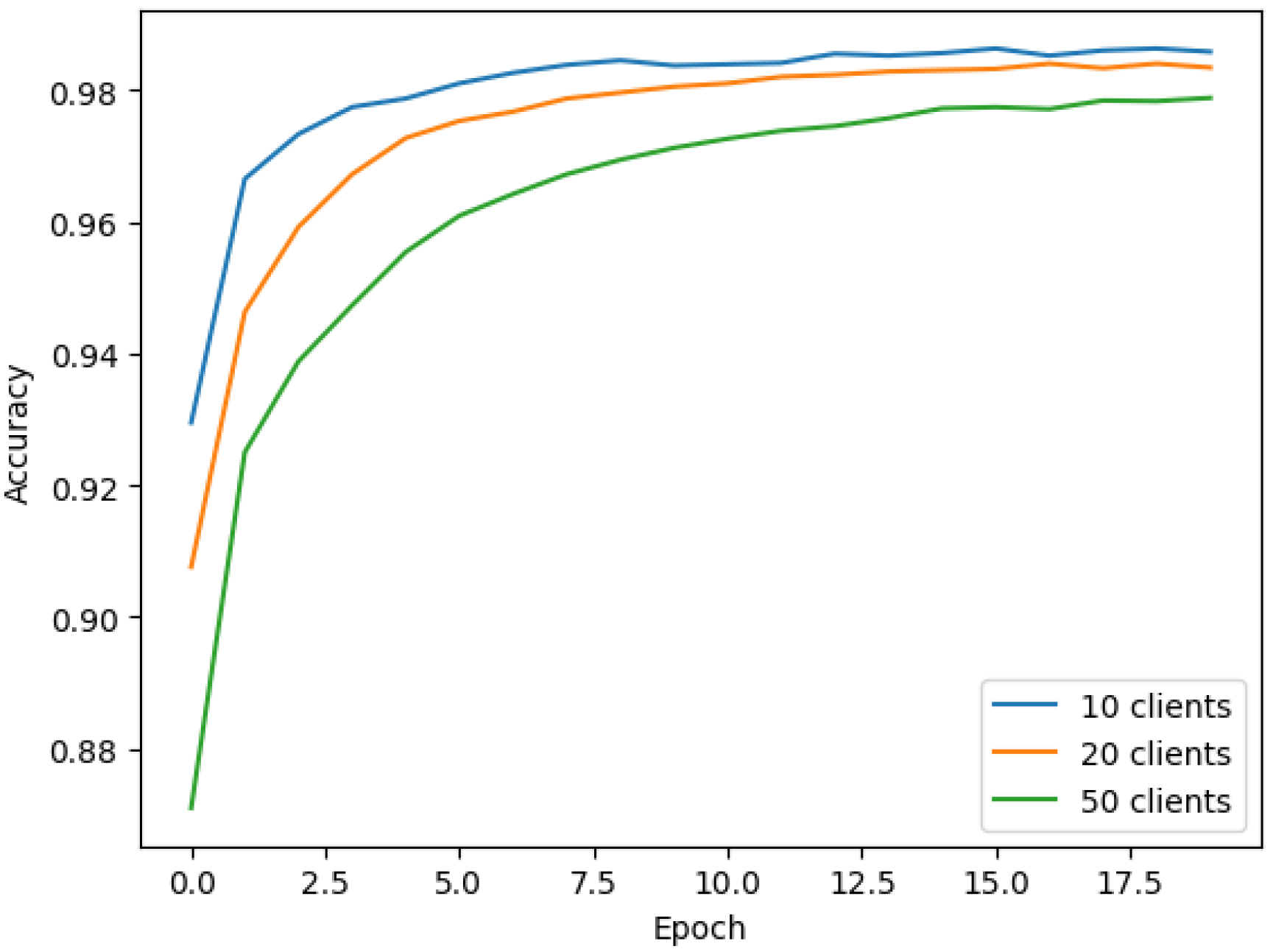
6.2.2. Experiment 2: Influence of Client Numbers on Federated Learning Performance
Examining the effect of varying client numbers (10, 20, and 50) on federated learning performance, this experiment used the MNIST dataset and an IID data split. After 20 federated learning communication rounds, the central server aggregated weights from each client, computed the global model weights, and redistributed them. The results showed how different client numbers impact model accuracy, with all scenarios achieving over 97% final accuracy (
Figure 4), suggesting our scheme’s robustness, scalability, and potential practical application value.
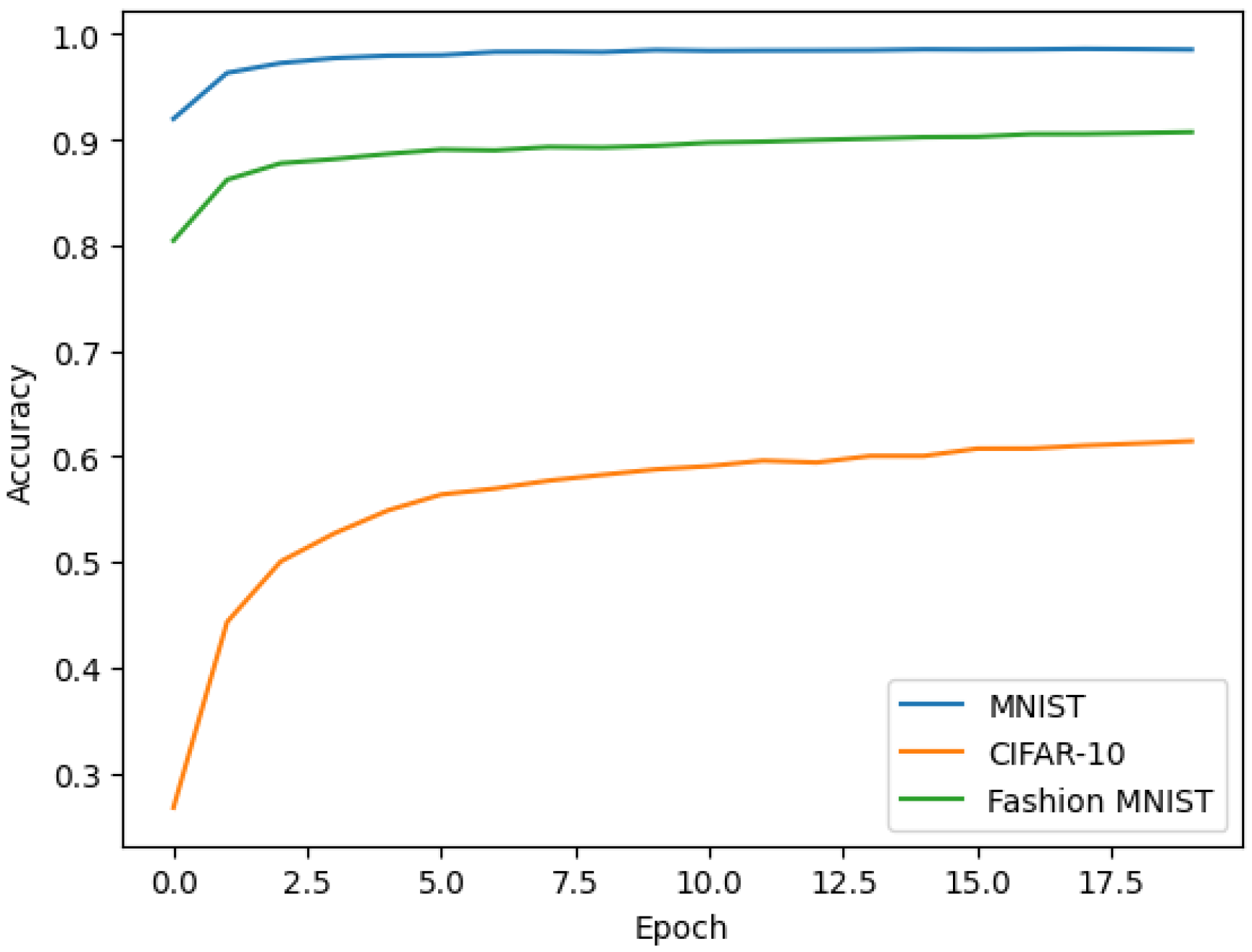
6.2.3. Experiment 3: Evaluation of Different Datasets on Federated Learning Performance
Aiming to assess the influence of various datasets on federated learning performance, this experiment used three datasets: MNIST, CIFAR-10, and Fashion MNIST, all split using IID and allocated to 10 clients. After 20 communication rounds, the results from each dataset were compared, with line graphs revealing accuracy dynamics (
Figure 5). This experiment highlights our scheme’s adaptability across different datasets and tasks, and the challenges and potential of federated learning.
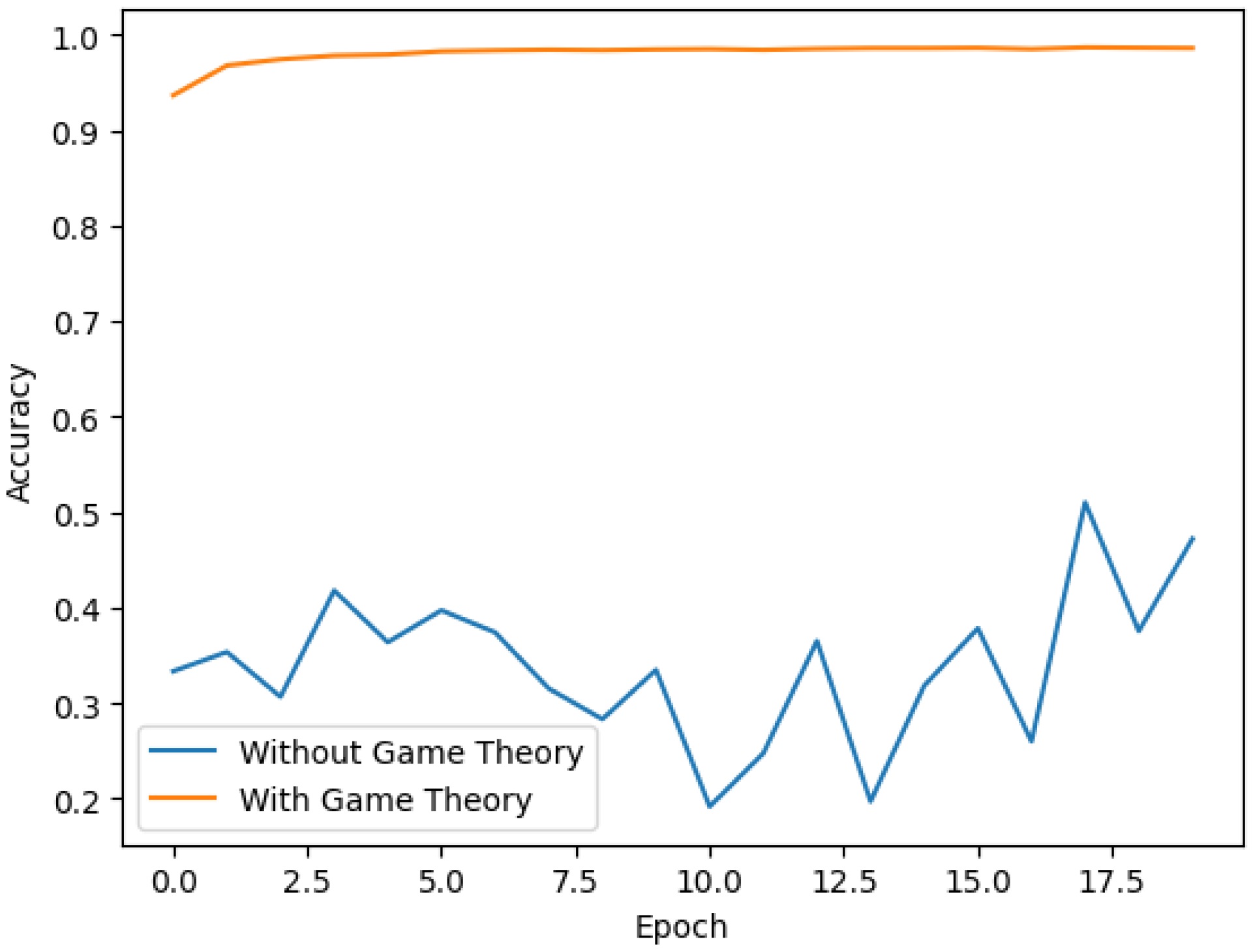
6.2.4. Experiment 4: Role of Game Theory in Trustworthy Anti-Collusion Federated Learning
This experiment delved into the significance of game theory in our federated learning scheme. Without a game theory strategy, we presumed that an initial 20% of clients might collude maliciously. In comparison, the scenario with game theory incorporated strategies to validate and adjust client weights. The results displayed in
Figure 6 showed that game theory significantly bolsters federated learning robustness, emphasizing its crucial role in enhancing federated learning system trustworthiness.
6.2.5. Experiment 5: Specific Impact of Privacy Protection Mechanisms on Model Performance
Focusing on the influence of various privacy protection mechanisms on model performance, this experiment compared four strategies: no privacy protection, low-noise differential privacy, high-noise differential privacy, and a custom privacy protection mechanism. Each weight adjustment and global update was influenced by the chosen privacy protection mechanism. A bar chart (
Figure 7) illustrates performance differences among the strategies, emphasizing the interplay between privacy protection and model performance and the importance and challenges of implementing privacy protection in federated learning.
6.3. Comparative Performance Analysis
In this section, we critically assess the efficacy of our game-theory-based trustworthy anti-collusion federated learning scheme by contrasting it with prevalent federated learning approaches. While all models start with identical parameters, the distinct methodologies employed for updating the model training parameters produce varied loss accuracies. Especially noteworthy is the behavior observed during equal communication rounds when the global model parameters attain a specified value. A meticulous evaluation underscores the unique loss accuracies our scheme achieves in comparison to its counterparts.
Table 3 encapsulates a systematic comparison of several federated learning strategies, benchmarking them on criteria like loss precision, communication rounds, and demonstrable security. In
Table 3, the symbol ‘√’ denotes the presence of provable security in the respective federated learning strategy, while the symbol ‘×’ indicates its absence.
Based on the empirical findings, several observations emerge.
In reference [
22], upon reaching the predetermined model parameter update value, the scheme registers a loss accuracy of 4.26 over 40 communication rounds. While this scheme lacks provable security, it innovatively introduces a sparse ternary compression framework tailor-made for federated learning environments. Reference [
23], on the other hand, achieves a loss accuracy of 2.12 after 36 communication rounds when the set model parameter update value is realized. This approach delineates both a foundational and personalized strategy for the joint training of deep feed-forward neural networks within federated learning. However, it falls short in affirming the security of its framework. Reference [
24] brings to the fore a federated learning scheme grounded in privacy protection and security. Here, a loss accuracy of 2.39 is noted over 37 communication rounds upon hitting the pre-established model parameter update threshold. Notably, this methodology has undergone rigorous security validation, effectively mitigating the privacy risks associated with federated learning model training data.
In contrast, our proposed scheme stands out, recording a remarkable loss accuracy of 1.98 with a mere 27 communication rounds upon achieving the set model parameter update value. Equally commendable is its verified security, further accentuating its superiority and robustness in the federated learning domain.
7. Conclusions
This study is dedicated to addressing the challenges posed by malicious participants and model parameter leakage in federated learning. To tackle these challenges, we introduced a game-theory-based trustworthy anti-collusion federated learning scheme. Guided by the principles of game theory and rational trust models, we strategically incentivized top-tier rational data owners to actively participate in federated learning training. Recognizing the paramount importance of the privacy and security of model parameters, we integrated blockchain networks and smart contract technologies. This integration not only reinforced the security framework for all rational participants and their parameters but also introduced a paradigm shift in the conventional methods of federated learning. Additionally, we adopted function encryption technology to ensure the secure and privacy-centric sharing of model parameters between task issuers and data owners. According to our experimental data, compared to honest nodes, the communication overhead for rational nodes decreased by 40%, while data accuracy improved by 15%.
In summary, our scheme achieves an optimal balance between communication overhead and data accuracy, offering a novel and effective solution for federated learning. In future research, we will continue to explore ways to enhance the learning efficiency of model training in a blockchain network where multiple task issuers simultaneously publish model training tasks, ensuring the privacy and security of all participants and data.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}